基于CNN特征提取及模型融合的飛機液壓系統故障診斷
2020-10-21 11:36:54李時奇趙東標申珂楠豐嬴政
機械制造與自動化 2020年5期
李時奇,趙東標,申珂楠,豐嬴政
(南京航空航天大學 機電學院,江蘇 南京 210016)
0 引言
智能故障診斷是未來飛機液壓系統故障診斷發展的趨勢之一[1-2]。國內通常采用小波包分解或者信息熵等方法對復雜的液壓系統壓力信號進行特征提取,然后輸入BP神經網絡或者支持向量機等學習器進行故障診斷分類[3-5]。這些特征提取的方法對人的經驗要求比較高:不具備通用性;對于多傳感器壓力信號難以有效融合;單一模型有較大過擬合風險。
針對上述問題,提出了一種卷積神經網絡(CNN)特征提取加多模型融合的故障診斷方法。使用一維多通道CNN可以直接接收多傳感器一維壓力時間序列,從而實現多傳感器融合。選取少量數據對CNN進行有監督訓練提取特征。再用提取出的特征訓練如線性多分類、決策樹、支持向量分類、k鄰近等學習器分別對其進行故障診斷。最后使用Stacking技術對這些模型進行融合。使用Amesim軟件對典型飛機液壓系統建模并進行故障仿真,驗證了算法效果。結果表明,本文算法在準確率和訓練用時上更優。
1 算法理論介紹
1.1 一維多通道CNN
由于飛機液壓系統的壓力信號是一維時間序列曲線,而且不同位置的多個傳感器可以采集多條曲線,為同時將多個傳感器的一維時間序列輸入CNN,采用一維多通道CNN。網絡中的所有卷積層、池化層均使用一維結構。
設Hl為第l層的輸入特征圖,S為卷積操作的結果,Hl+1為卷積層的輸出特征圖,K為卷積核,i代表特征圖上的索引,p代表卷積核上索引,c為通道的索引,Hl(∶,c)為通道c的特征圖,b為偏移量,f(x)為激活函數,則一維多通道卷積公式如下[6]:
S(i)=∑c∑pHl(i+p,c)K(p)
(1)
Hl+1=f(S+b)
(2)
池化操作分為最大池化和均值池化。設第l層為池化層,k為池化窗口的大小,p代表池化窗口上的索引。最大池化和均值池化操作公式分別為式(3)和式(4):

(3)
(4)
1.2 線性多分類器
對數幾率回歸(logistic regression, LR)是一種用線性回歸模型的預測結果去逼近真實標記的對數幾率,雖然名字是“回歸”,實際上是一種分類算法。設x為輸入向量,y為輸出標記,w和b為待學習的權重和偏置。公式如下:
(5)
當y>0.5時預測為正類,y<0.5時預測為反類,y=0.5時可以隨機預測。通過OvO(One vs. One)或者OvR(One vs. Rest)等拆分策略可以推廣到多分類[7]。
1.3 決策樹分類器
決策樹通過樹型結構對樣本進行學習。樹的節點代表某個屬性,該節點下的路徑代表屬性的不同取值。每個葉節點代表某個類。隨機森林(random forest, RF)[8]是多個決策樹通過bagging策略集成的, RF能引入隨機性,有效減少過擬合。
1.4 支持向量分類器
支持向量機(support vector machine, SVM)通過尋找一個超平面劃分兩類樣本,離超平面最近的幾個訓練樣本稱為“支持向量”,兩個不同類別的支持向量到超平面距離和稱為“間隔”,支持向量機算法試圖找到間隔最大的超平面來劃分不同類[9]。SVM同樣可以使用拆分策略推廣到多分類。
1.5 k鄰域分類器
k鄰近算法(k- nearest neighbor,KNN)的訓練過程就是保存訓練集所有數據。當新的樣本輸入時,計算訓練集中距離它最近的k個樣本,根據這k個樣本的類別來決定新樣本的類別[10]。
2 算法流程
圖1為算法流程示意圖。首先對典型飛機液壓系統進行Amesim建模,通過改變某些部件參數來模擬飛機液壓系統的常見故障。采集不同故障狀態以及正常狀態的壓力信號,進行歸一化處理并通過劃窗重采樣進行數據集增強。將訓練集分為A和B兩個子集。用A集數據對CNN進行有監督訓練。再將數據集B輸入訓練好的CNN,提取中間層的特征,將中間提取出的特征輸入其他學習器進行訓練。之后將多個學習器的結果用Stacking融合技術融合。最后將測試集輸入訓練好的模型,驗證算法效果。
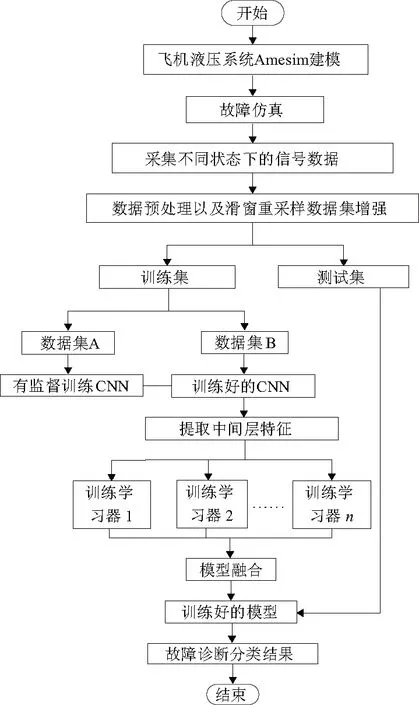
圖1 算法流程示意圖
2.1 CNN特征提取
CNN各個層的結構如表1所示。CNN可以接受一維多通道數據,可將不同飛機液壓系統中不同傳感器獲取到的一維壓力時間序列輸入CNN。表中filter指卷積核(又叫濾波器)或者池化濾波器。filter大小1100指窗口大小為100的卷積核在特征圖上滑動,步長指的是filter在特征圖上滑動步長。
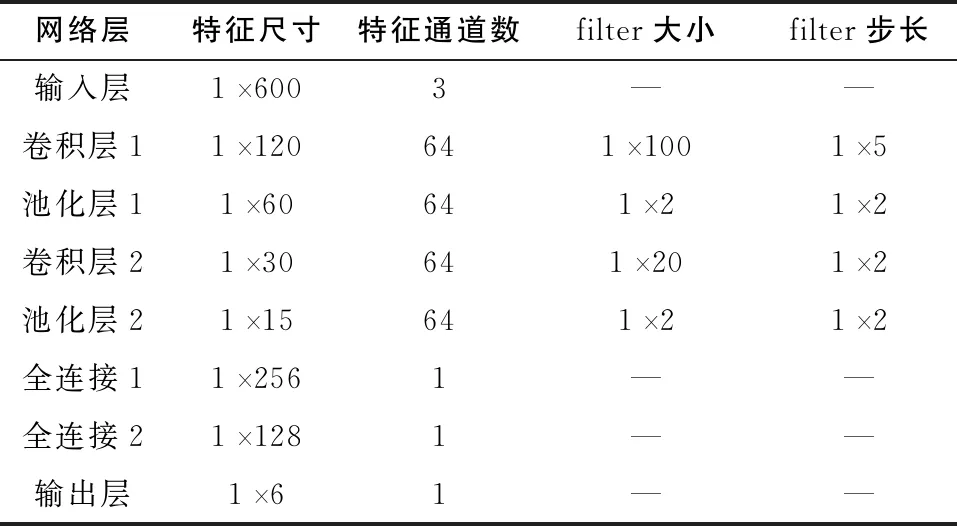
表1 CNN各層參數
用A集監督訓練CNN,目的是讓CNN的每一層獲得不錯的權重從而使網絡具備提取抽象特征能力。將B集輸入到訓練好的網絡,提取全連接層2尺寸為128的特征。此時向量的總數據維度從1 800降到了128,此時的特征已經過濾掉一些無效信息并提取到有用的抽象特征,能極大地加快訓練速度,簡化訓練難度,提高訓練準確率。
2.2 Stacking模型融合技術
Stacking模型融合技術[11]是一種兩級的模型融合技術,將初級學習器學習到的分類結果作為次級學習器的輸入,再進行一次學習。
Stacking模型融合技術示意圖如圖2、圖3所示。首先需要每個學習器使用k折交叉驗證(圖中k=5)。將原訓練集分為k折,用k-1折訓練,預測剩下的1折,預測結果作為次級學習器的輸入,重復k次,每次用不同的折劃分。對于測試集,將k次的結果取平均值。用不同初級學習器重復相同操作,最終次級學習器的輸入特征為n個初級學習器的預測結果(圖中n=4)。用次級學習器對新生成的訓練集進行訓練,預測新測試集,得到最終結果。

圖2 Stacking融合每個學習器訓練步驟
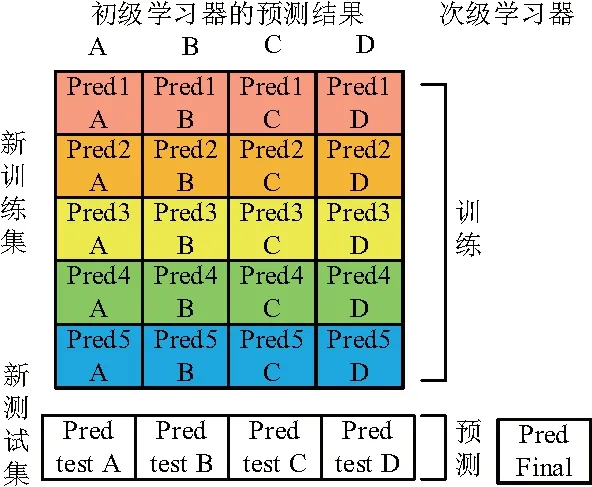
圖3 Stacking融合多學習器融合步驟
由于不同學習器的學習原理有所差異,通過融合可以互相彌補不足,提高總準確率的同時減少過擬合的風險。
3 算例分析
3.1 飛機液壓系統故障仿真及數據生成
圖4為典型飛機液壓系統Amesim模型。為簡化模型,只保留液壓系統核心部件以及一個用于故障診斷的作動器,其余作動器均用“液壓用戶”代替。
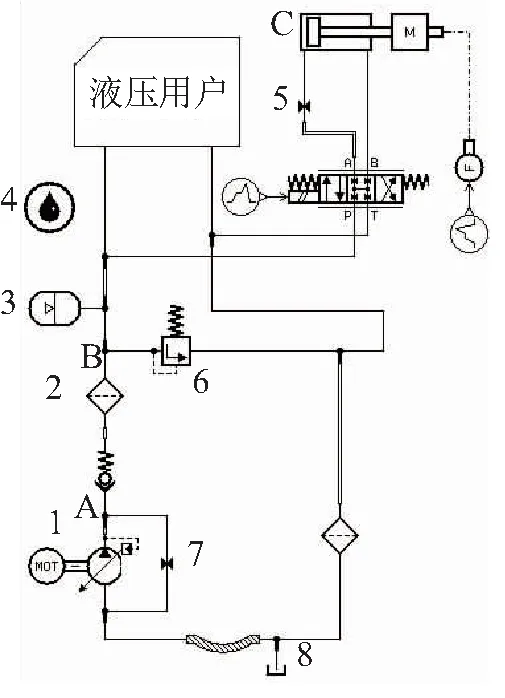
圖4 典型飛機液壓系統 Amesim模型
表2為Amesim模型中各元件參數以及含義[12]。
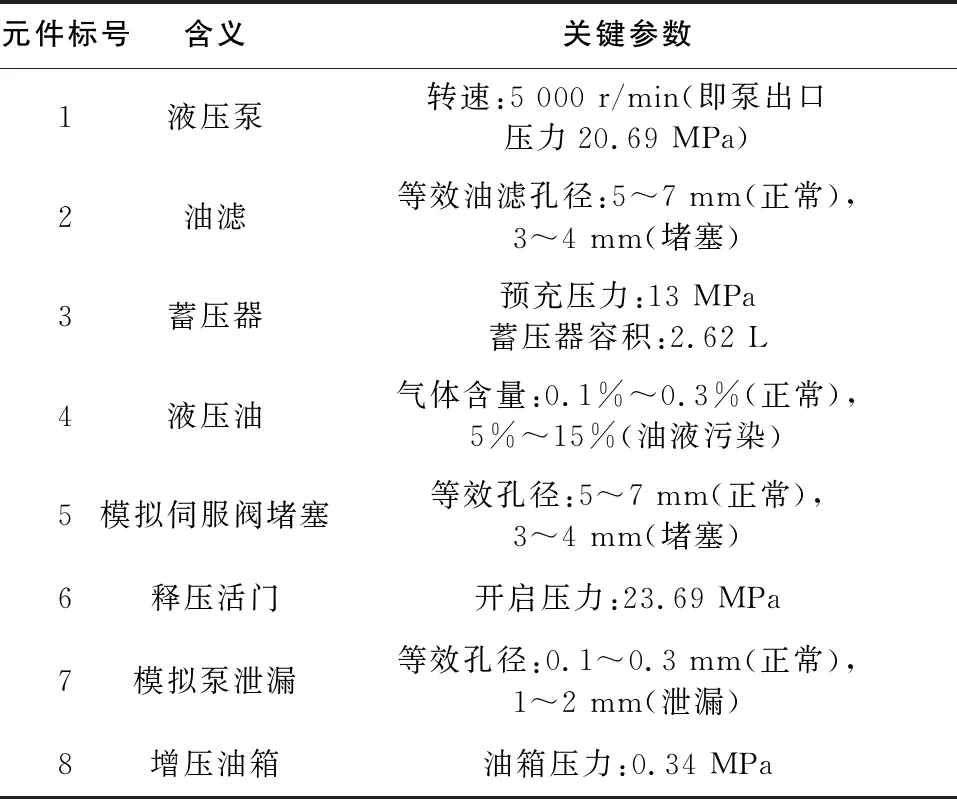
表2 飛機液壓系統Amesim模型參數
系統故障模擬方法如下:通過在泵兩端并聯溢流閥模擬泵泄漏;改變油濾等效孔徑參數模擬油濾堵塞;改變液壓油中氣體含量模擬液壓油污染;用伺服閥和作動器直接串聯溢流閥模擬伺服閥堵塞;改變作動器內泄漏參數模擬作動器內泄漏。5種故障狀況加上正常情況共6種類別,類別標號和類別編碼如表3所示。
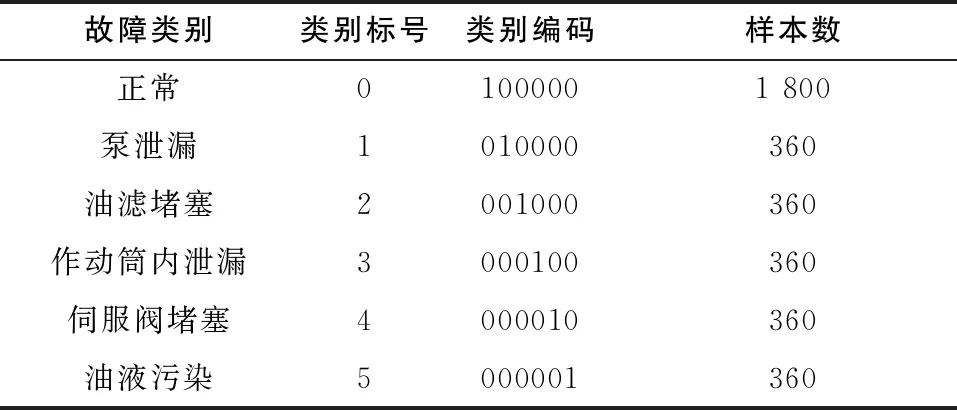
表3 故障類別表
取仿真時長為18s,提取圖4中A、B、C 3處的壓力信號進行故障診斷。設采樣周期為0.01s,取長度為6s的曲線用于故障診斷。將6s的窗口在18s的曲線上滑動取點來增強數據集。通過在正常或者故障范圍內微調參數多次仿真可以增加數據量。最終每個樣本含3條(A、B、C 3個位置)6s的曲線,即原始輸入特征的尺寸為16003。
圖5為液壓油污染情況以及正常情況下泵出口壓力曲線對比圖。由圖可知液壓油氣體含量上升導致的污染會使壓力曲線滯后。
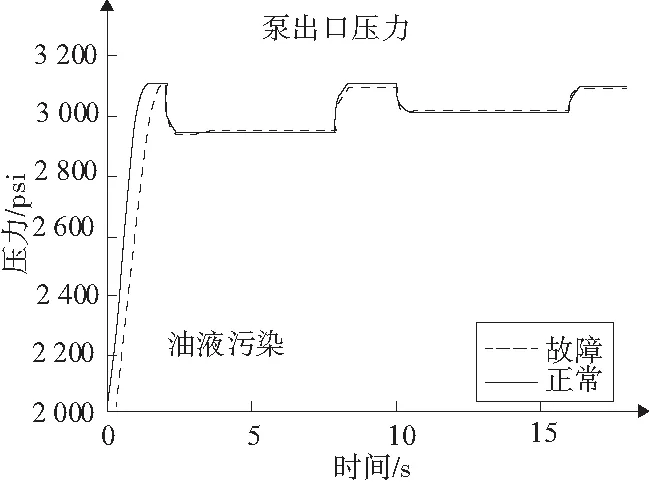
圖5 故障與正常情況壓力曲線對比圖
3.2 CNN特征提取效果分析
若用在A集上訓練的CNN直接預測B集的故障診斷結果,準確率僅為84.3%,這是因為A集只占總數據集的很少一部分,但是足夠提取出有效的特征用于下一步訓練。
圖6為A集大小對CNN訓練時間以及最終準確率的影響。圖7為從CNN不同中間層提取的特征對后續訓練時間以及最終準確率的影響。由圖可知,為使準確率高的同時訓練時間盡可能少, A集大小取20%,提取CNN中間層的卷連接層2作為特征進行下一步訓練。
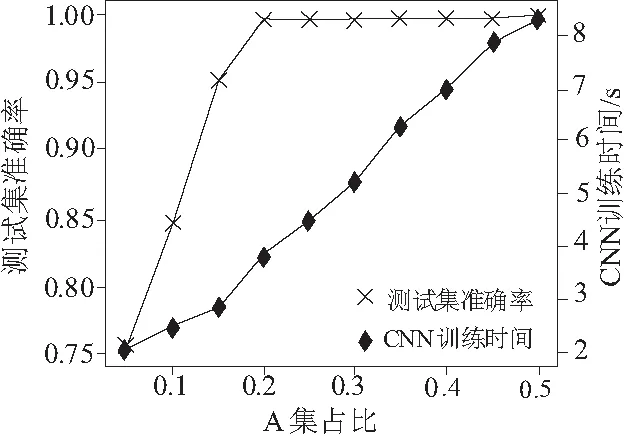
圖6 A集占比對結果的影響

圖7 CNN不同層特征訓練結果
3.3 故障診斷結果分析
表4為各學習器用CNN提取到的特征進行訓練(表中i)與直接用原始輸入壓力曲線訓練(表中ii)的對比。由表可知,經過CNN提取到的特征能極大加快訓練速度,提高故障診斷的準確率,降低模型大小。
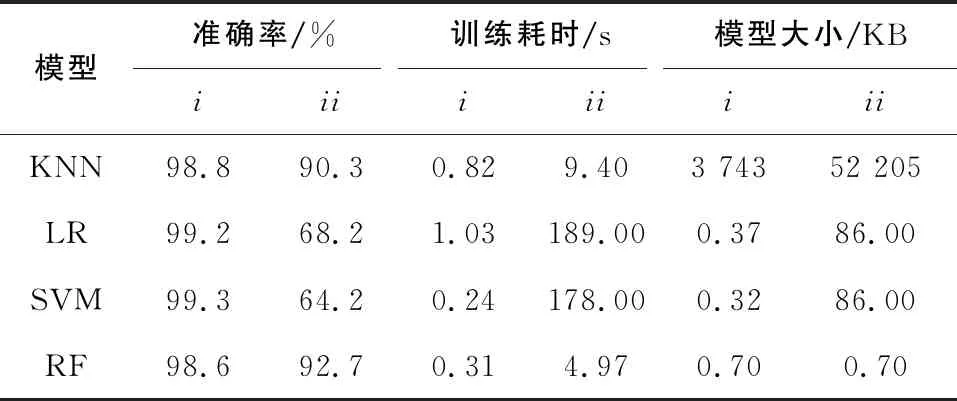
表4 用特征與用原始數據訓練對比
表5為用不同次級學習器進行Stacking融合的比較
以及和直接用簡單投票法融合的準確率比較。可以看到,使用LR作為次級學習器準確率最高。

表5 不同模型融合方法比較
圖8為Stacking模型融合后與各個模型的對比。由圖可知,融合后的模型比所有原模型的準確率都要高。
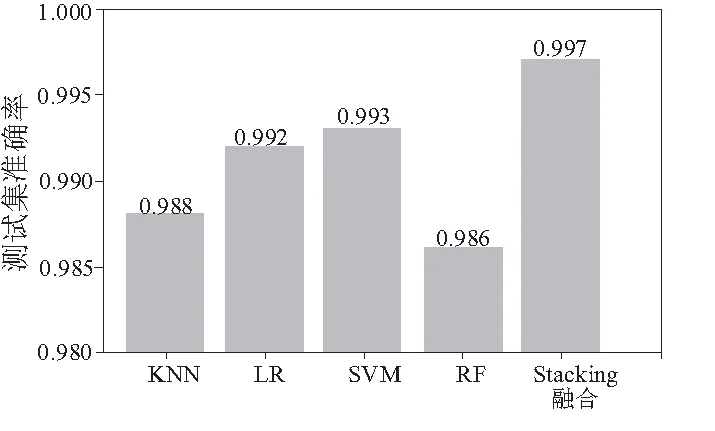
圖8 Stacking模型融合與各個模型對比圖
表6為CNN特征提取加Stacking模型融合與直接用CNN訓練全部數據集進行故障診斷的對比。由表可知,在準確率方面多模型融合略高,在訓練耗時上多模型融合更少,但是所占的空間更大。

表6 兩種方法效果對比
4 結語
本文采用CNN特征提取加Stacking多模型融合技術對飛機液壓系統進行了故障診斷。使用Amesim軟件對典型飛機液壓系統建模并進行故障仿真來驗證算法效果,結果如下:
1)使用少量數據監督訓練CNN也能提取出不錯的中間特征,用提取出的特征訓練比用原始輸入信號訓練在各方面都有較大提升。
2)Stacking多模型融合準確率高于各個單一模型。
3)相比于直接用CNN訓練全部數據集進行故障診斷,CNN特征提取加多模型融合訓練速度明顯更快,準確率也有少量提升。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年23期)2014-02-27 14:19:15
