基于魯棒主成分分析的多聚焦圖像融合
2020-10-28 01:47:24王書朋
計算機技術與發展 2020年10期
王書朋,蔣 藝
(西安科技大學 通信與信息工程學院,陜西 西安 710054)
0 引 言
由于成像設備受光學鏡頭景深的限制,只能對聚焦區域內的物體產生清晰的圖像,而聚焦區域以外的物體在圖像中都是模糊的[1]。為了克服物理設備的限制,多聚焦圖像融合技術將來自同一場景的兩幅或多幅聚焦區域不同的圖像進行融合生成單幅全聚焦圖像,使同一場景下的所有目標都清晰地呈現出來,從而便于人們后期對圖像進行分析和處理。然而現有的多聚焦圖像融合算法通常難以準確地區分聚焦區域和非聚焦區域,導致融合圖像中聚焦區域的邊界處有偽影的現象。針對該問題,該文擬提出一種新的多聚焦圖像融合方法。
現有的多聚焦圖像融合方法可以分為三類:基于空間域的方法、基于變換域的方法和基于深度學習的方法。基于空間域的方法[2-3]主要是依據某種清晰度指標,直接從源圖像中選擇清晰的部分組合成融合圖像,但這類方法容易受到噪聲的影響,融合結果中通常存在塊效應問題[4]。基于變換域的方法是通過某種變換將圖像分解成不同頻帶的系數,然后選取不同的融合規則得到融合系數,最后通過逆變換生成融合圖像。如基于多尺度變換的方法[5-6]、基于稀疏表示的方法[7]等。這類方法比基于空間域的方法能更好地提取圖像的邊緣和輪廓等特征,但圖像分解過程中會缺失部分高頻分量的信息,融合結果中易產生振鈴效應[8]。近年來,機器學習及深度學習理論不斷發展[9-10]。Liu等人[11]將CNN引入到多聚焦圖像融合中,通過訓練CNN模型直接生成焦點圖,克服了手動設計聚焦區域檢測方法的難題。多聚焦圖像融合的關鍵是準確區分源圖像中的聚焦區域和非聚焦區域。魯棒主成分分析(robust principal component analysis,RPCA)是一種新的聚焦點檢測算法,該算法可以將圖像分解成代表背景的低秩分量和代表圖像顯著性特征的稀疏分量。楊明偉等人[12]用RPCA分解源圖像得到稀疏分量,然后對稀疏分量進行三方向一致性和區域生長法處理。Zhang等人[13]用引導濾波器對稀疏分量進行處理得到增強圖像,用增強圖像與源圖像之前的差值圖像提取背景區域,從而確定聚焦區域的位置。盡管這類方法可以避免振鈴效應,提高了融合決策圖的準確性,但基于像素值取大和空間頻率的融合規則沒有得到最優的聚焦區域檢測結果,融合圖像中有嚴重的塊效應,且聚焦區域的邊界有暈影的現象。
為解決上述問題,該文提出了一種基于RPCA的多聚焦圖像融合方法。該方法首先通過RPCA將源圖像分解為低秩和稀疏分量。針對低秩分量,利用CNN構建權重圖,可以較好地區分聚焦區域和非聚焦區域。對于稀疏分量,采用基于拉普拉斯能量和的方法構建稀疏分量的融合決策圖,然后用引導濾波器優化決策圖,使決策圖的邊緣與源圖像保持一致,避免偽輪廓。從主觀和客觀兩個方面將所提算法與其他七種經典算法進行比較。實驗結果表明,所提方法可以準確區分聚焦區域和非聚焦區域,融合圖像中聚焦區域的邊界清晰且不會引入偽影。
1 魯棒主成分分析
為了解決主成分分析(PCA)魯棒性不佳的問題,Wright等人[14]提出了魯棒主成分分析(RPCA)理論,它的基本思想是數據矩陣在最優化準則下可以表示為一個低秩矩陣和一個系數矩陣的和。假設有一個輸入矩陣I∈NH×W,那么該矩陣可以分解為:
I=L+S
(1)
其中,L是低秩矩陣,S是稀疏矩陣,輸入矩陣I的大小為H×W。
與其他稀疏表示方法類似,RPCA采用核規范作為近似稀疏約束:
(2)
其中,rank(?)是矩陣的秩,‖?‖0是0范數矩陣,λ是加權參數且λ>0。
在一般情況下,這種分解是NP難問題。由于一個矩陣的秩與它的非零奇異值的個數相等,可以用矩陣的核范數近似代替矩陣的秩,用0范數等價為1范數,則稀疏矩陣可以轉化為以下凸優化問題:
(3)
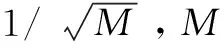

圖1 多聚焦圖像的RPCA分解
2 所提算法
為了準確地檢測源圖像中的聚焦區域,提出了基于RPCA的多聚焦圖像融合方法。該方法的框圖如圖2所示。
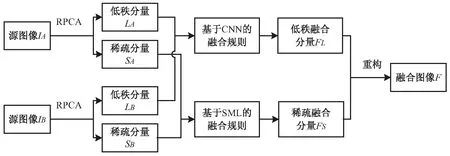
圖2 算法框圖
首先,輸入兩幅聚焦區域不同的源圖像IA和IB,用RPCA對這兩幅源圖像進行分解,得到低秩分量LA、LB和稀疏分量SA、SB。然后,針對低頻分量包含源圖像整體結構和細節的特性,采用基于CNN的融合規則構建決策圖。針對稀疏分量包含聚焦區域的邊緣和紋理特性,采取基于引導濾波[15]改進的拉普拉斯能量和(SML)的融合規則。最后,將融合后的低秩分量FL和稀疏分量FS重構得到融合圖像F,即F(i,j)=FL(i,j)+FS(i,j),(i,j)為像素點的位置。
2.1 融合低秩分量
低秩圖像包含源圖像大部分的結構和能量,一般的融合規則很難準確地區分聚焦區域和非聚焦區域的邊界。實際上,在多聚焦圖像融合過程中,決策圖的生成可以看成二分類問題,CNN對解決這類問題是有效的[11]。因此通過圖3中的CNN模型對低秩分量進行特征提取和分類,將低秩圖像利用滑窗技術分成大小為16×16的圖像塊,卷積層和池化層用于特征提取,全連接層用于分類。然后判斷兩幅低秩圖像相同位置處的圖像塊哪個是清晰的,哪個是模糊的。最終得到低秩分量的融合決策圖。
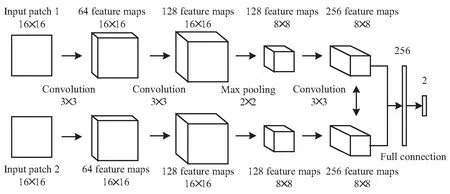
圖3 CNN模型
為了降低網絡訓練的復雜度,文中的CNN模型為暹羅網絡[16],使兩個分支獲得相同的權重,每個分支包含了三個卷積層和一個最大池化層[11],第三個卷積層的輸出特征圖可以表征不同源圖像聚焦區域的特征。如果輸入圖像塊過大,可能同時包含聚焦區域和非聚焦區域,會導致聚焦邊界的誤判。當圖像塊過小時,圖像中包含的特征信息過少,可能會降低圖像分類的準確性,所以該文將訓練的圖像塊大小設為16×16。卷積核的大小及步長分別為3×3和1,池化層的池化因子和跨度分別為2×2和2,將每個分支得到的256個特征級聯后與256維特征向量全連接,最后再與2維特征向量全連接。經Softmax層分類后,輸出值的大小即為這一對輸入圖像塊的聚焦屬性。
基于CNN的低秩分量融合規則步驟如下:首先將兩幅RPCA分解得到的低秩圖像LA和LB輸入到訓練好的CNN模型中進行焦點檢測得到得分圖Smap,Smap中的每個系數表示來自兩個低秩圖像相同位置處的一對圖像塊的聚焦特性。當Smap∝1時,說明LA聚焦,LB散焦;當Smap∝0時,說明LA散焦,LB聚焦。
然后對得分圖進行閾值分割得到初始的二值圖像:
(4)
(5)
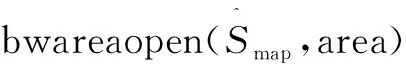
最后,利用所獲得的決策圖融合低秩圖像,得到低秩融合圖像FL。
FL(i,j)=DL(i,j)LA(i,j)+
(1-DL(i,j))LB(i,j)
(6)
流程如圖4所示。

圖4 基于CNN的低秩圖像融合
2.2 融合稀疏分量
傳統的圖像清晰度檢測的方法有方差、空間頻率和SML等,文獻[17]從主觀和客觀評價兩個方面證明,SML比其他清晰度檢測的方法具有更好的性能。所以該文對稀疏分量采用基于SML的融合規則。
首先分別計算稀疏分量SA和SB的SML值,得到SMLA和SMLB。像素點(i,j)處的SML值可通過如下公式計算:

(7)
其中,局部窗口的大小為m×n,文中m=n=3。拉普拉斯算子ML定義為:
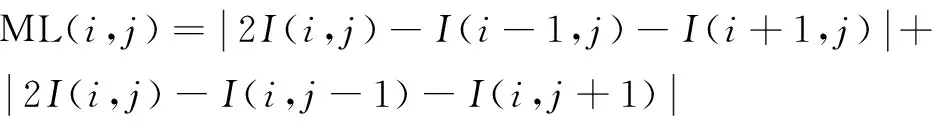
(8)
其中,I(i,j)是像素點(i,j)處的像素值。
然后根據如下公式得到稀疏分量的初始融合決策圖G:
(9)
然而,初始決策圖中部分像素會出現不連貫的現象,因此需要對初始決策圖進行優化處理。引導濾波[7]是一種邊緣保持濾波器,具有較好的保留邊緣和去除噪聲的能力。該文用引導濾波器對決策圖G進行平滑濾波,提高決策圖的空間一致性,公式如下:
DS=Guidedfilter(I,G,R,eps)
(10)
其中,DS是通過引導濾波器處理后的稀疏分量決策圖,I是引導圖像。為了使決策圖的邊緣與源圖像保持一致,該文用兩幅源圖像的均值作為引導圖像,即I=(IA+IB)/2。R表示引導濾波器的半徑,R值越大,平滑效果越好,但邊緣保持能力下降。eps表示正則化參數,eps值越大,濾波效果越明顯。該文將R設為7,eps設為0.01。
最后,通過下式可得融合后的稀疏分量FS:
FS(i,j)=DS(i,j)SA(i,j)+
(1-DS(i,j))SB(i,j)
(11)
3 實驗結果及分析
為了驗證所提算法的有效性,從主觀視覺感知和客觀評價指標兩個方面將文中方法與七種方法進行比較,包括基于非下采樣輪廓波變換的方法[5](NSCT)、基于NSCT與SR相結合的方法[7](NSCT-SR)、基于引導濾波的方法[18](GF)、基于密度尺度不變特征變換的方法[3](DSIFT)、基于稀疏分解和背景檢測的方法[13](RPCA)、基于脈沖耦合神經網絡的方法[10](PCNN)、基于卷積神經網絡的方法[11](CNN)。實驗選取了2種不同類型的灰度圖像[18]進行對比分析。
CNN模型的訓練樣本是由ILSVRC 2012中的自然圖像生成的。將每個源圖像使用標準偏差為2,大小為7×7的高斯濾波器處理后,獲得五種具有不同模糊程度的模糊圖像。對于每類模糊圖像和源圖像,隨機采樣20對大小為16×16的圖像塊,總共獲得100萬對清晰和模糊的圖像塊。用Softmax損失函數作為網絡的目標函數,用隨機梯度下降法最小化損失函數。在訓練過程中,批處理的大小設置為128。使用Xavier算法[14]初始化每個卷積層的權重,學習率為0.000 1。
3.1 主觀分析
圖5是“pepsi”圖像及不同方法的融合結果。從圖5(c)和(d)中可以看出,NSCT和NSCT-SR方法使融合圖像丟失了部分邊緣信息,可樂瓶左側的輪廓模糊。GF方法的融合圖像中桌子的底部細節保留不完整。DSIFT方法可以較好地提取源圖像中大部分的細節。圖5(g)顯示,基于RPCA的方法錯誤提取了源圖像中條形碼的聚焦區域,融合圖像的視覺效果最差。PCNN的融合圖像有重影。圖6是圖5中方框區域的放大圖。NSCT和NSCT-SR算法在圖6(c)(d)中聚焦區域的偽輪廓是明顯的。DSIFT和RPCA算法使字母的邊界有一些擴展,且RPCA算法的空間連續性較差,PCNN的融合結果中字體嚴重模糊。CNN和文中方法不會引入偽影,融合結果具有較高的視覺質量。

圖5 源圖像“pepsi”及不同方法的融合結果

圖6 圖5中方框區域的放大圖
圖7是源圖像“office”及不同方法的融合結果。NSCT和NSCT-SR方法在融合圖像中的電腦區域引入了明顯的偽影,DSIFT、RPCA和PCNN方法使鬧鐘邊界處有不同程度的模糊,部分細節丟失并引入較多的人造紋理。CNN的融合結果中桌子邊緣不清晰。圖8是圖7中方框區域的放大圖。除所提算法以外,其余七種算法在人的頭部都引入了偽邊界,還有一些白色的偽影,人耳的輪廓模糊,圖像視覺質量較差。文中方法的結果圖對比度較高,人耳和頭部細節保留完整,輪廓清晰,圖像融合效果更好。

圖7 源圖像“office”及不同方法的融合結果

圖8 圖7中方框區域的放大圖
3.2 客觀評價
為了定量評估不同融合方法的性能,選擇三種客觀評價指標對實驗結果進行評估:結構相似性[19](SSIM)、基于人類視覺感知的度量[20](QCB)、邊緣梯度算子[21](QAB/F)。其中,SSIM根據圖像的結構評估融合圖像和源圖像之間的相似性,SSIM值越大,融合結果與源圖像的結構相似度越高。QCB是描述圖像視覺特性的度量,QCB值越大,圖像的對比度越高,視覺效果越好。QAB/F通過度量融合結果包含源圖像的邊緣信息量來評估融合性能,QAB/F值越大,融合圖像中包含的邊緣信息量越多。
表1列出了上述三種融合圖像的客觀評價結果。文中方法在QCB和QAB/F兩種指標上都取得了最大值,說明基于文中方法的融合結果中包含充分的紋理細節信息。其中有兩幅圖像在指標SSIM上并未取得最大值,但是與最大值之間的差距較小,說明融合圖像與源圖像在結構上保持良好的一致性。這是因為利用RPCA對圖像進行分解,增強了算法的魯棒性。同時設計了基于卷積神經網絡和SML的融合規則,提高了決策圖的準確性,使融合圖像更符合人類視覺感知。

表1 不同圖像融合結果的客觀指標
4 結束語
提出了一種基于RPCA分解的多聚焦圖像融合方法。首先利用RPCA將源圖像分解為低秩和稀疏分量。然后利用基于CNN的融合規則得到低秩分量的融合決策圖,可以更好地提取圖像的細節信息。對于稀疏分量,采用基于SML值取大的方法構建決策圖,再用引導濾波器對決策圖進行優化,提高了決策圖的空間一致性。最后通過重構得到最終的融合圖像。將所提方法與七種經典方法進行比較,從主觀和客觀的分析結果可以表明,所提方法能準確地提取聚焦區域,充分保留了源圖像的細節信息,融合結果更自然。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
