基于BP神經網絡的圖書館志愿者崗位分配
2020-10-28 07:14:48程龍閱
無線電工程 2020年11期
程龍閱,吳 翔,鄭 睿,余 童
(1.安徽師范大學 物理與電子信息學院,安徽 蕪湖 241000;2.安徽師范大學 圖書館,安徽 蕪湖 241000)
0 引言
圖書館志愿者是自愿無償地為圖書館提供義務服務的人員[1]。圖書館有組織地開展志愿者的服務工作,無論是對圖書館、志愿者,還是對接受服務的讀者而言,都有十分重要的意義。志愿者的組織可以提高圖書館的服務水平及范圍,既為讀者提供人性化服務,也為體現志愿者的奉獻精神和自身價值,發揚優良的社會風貌提供了平臺[2]。而對志愿者進行合理的崗位分配,是圖書館讀者服務工作順利開展的基礎。
當前,國內外文獻對于圖書館志愿者的研究,主要集中在圖書館志愿者的招募[3]、培訓和激勵[4]、社會志愿者與圖書館間的合作[5]、志愿者建設圖書館的動機和形式的研究[6]、志愿者間的跨國互助交流[7]等方面,在圖書館志愿者與崗位之間的研究相對較少。近年來,趙琛[8]等根據公共圖書館志愿者崗位設置的總體情況及存在的問題進行分析,就如何發揮志愿者作用,提出崗位具體設置優化方案、有效的配套保障措施等建議。主要研究對志愿者崗位的優化,及志愿者入崗后的培訓、激勵等,忽略了志愿者入崗前合理分配崗位的積極作用。張燕[9]等結合公共圖書館實際館情,根據志愿者服務意向,合理分配服務崗位,開展特色讀者服務。僅在理論上說明了合理分配志愿者崗位的重要性,未結合實際進一步研究如何給志愿者合理地分配崗位。
近年來,深度學習神經網絡已經全面滲透到圖書館的各個領域[10]。國內外相關研究已在圖書館信息檢索[11-12]、信息分類與編目系統[13]和知識服務評價體系[14]等領域取得相應成果。但目前缺少將神經網絡應用于圖書館志愿者崗位分配問題的研究。在神經網絡運用于崗位分配方面的研究僅有2011年袁珍珍[15]等運用BP神經網絡構建了空中交通管制員的崗位匹配測算模型;2015年,曾慶婷[16]等運用BP神經網絡構建了國有大中型煤炭企業關鍵崗位人崗素質匹配模型。但以上研究均是針對某一個特定崗位,根據專家打分法確定相關人員的多項勝任力指標得分作為BP網絡的輸入,將網絡綜合評判后的得分作為網絡的輸出,從而得出該人員對崗位的勝任情況,是一種多輸入單輸出的BP神經網絡崗位匹配模型,未涉及到對多崗位分配問題的研究。由于圖書館志愿者的特點與崗位的數量相對較多,因此需要構建多輸入多輸出的網絡模型,為圖書館志愿者分配適合的崗位。
據以上分析可知,BP神經網絡可用于崗位分配的模型研究。BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋神經網絡,具有自組織、自學習、自適應的能力;且可以對復雜的模式進行識別與分類[17]。由于圖書館志愿者的特點和崗位相對較多,且之間存在一些較復雜的關系,僅應用管理學的方法,較難把大多數志愿者分配到最適合的崗位,體現“人盡其用”的原則。因此,本文首次提出將BP神經網絡與圖書館志愿者的崗位分配相結合,構建多輸入多輸出的BP網絡圖書館志愿者崗位分配模型,為圖書館志愿者的崗位分配優化配置。
1 樣本數據的采集與處理
由于將BP神經網絡應用于崗位識別的研究,前提條件是需要一定數量的樣本集對網絡進行訓練與測試。為了獲取到更加真實有效的數據信息,首先要通過調研確定網絡輸入、輸出端神經元的數目;其次再采用問卷調查的方式,通過對當前工作優秀的圖書館志愿者開展問卷調查,從而獲取到一定數量的網絡訓練、測試樣本集。
1.1 樣本數據的選取
對于輸入端神經元的確定,采用文獻[18-20]實地調研的方法,通過查閱文獻及請教學校有經驗的圖書館管理人員,了解并研究作為圖書館志愿者需要哪些重要特質,并最終確定選取6種特點,作為BP神經網絡的輸入端神經元數目。輸入端神經元分別用X1~X6表示。網絡輸入端指標集如表1所示。

表1 網絡輸入端指標集Tab.1 Index set of network input
對于輸出端神經元的確定,采用文獻[18-20]及實地調研的方法,通過查閱文獻及到校圖書館實地調研,了解并研究圖書館志愿的崗位設置情況,并最終確定選取5種志愿者崗位,作為BP神經網絡輸出端神經元數目。輸出端神經元分別用Y1~Y5表示。網絡輸出端指標集如表2所示。

表2 網絡輸出端指標集Tab.2 Index set of network output
上文所選取的圖書館志愿者的特點與崗位之間具有一定復雜關系。從客觀角度分析,如書庫管理崗位的志愿者主要是負責將圖書館的圖書上架擺放到對應的位置,需要付出一定的體力勞動,所以這個崗位上的志愿者相比應該會具有較高的吃苦耐勞精神、較好的耐心細心的品質;閱讀指導崗位的志愿者主要是負責為來館讀者、學生推薦好書或適合他們專業的書籍,能夠準確迅速地幫助每位學生查找到他們所需要的書籍,所以這個崗位上的志愿者應該具有較好的文理學修養、較好的溝通能力,但同時在開朗熱心的性格及耐心細心的品質方面可能也有一定比重的要求。
圖書館志愿者的每個崗位,對志愿者的特點的要求是不同的、多樣的,且之間存在一定的比重關系。某位志愿者在自身崗位所需的特點方面表現較好,但可能在其他崗位所需的特點方面也有較好的表現。因此,想要給不同特點的志愿者用神經網絡的方式分配到合適的崗位,研究特點與崗位分配之間復雜的關系,還需一定數量的樣本數據作為研究。
1.2 樣本數據的采集與處理
為了獲取圖書館志愿者特點與其適合崗位之間的復雜關系,需要采用問卷調查的方式。同時為了確保所得問卷數據的有效性,問卷對象選擇當前正在從事圖書館志愿者工作,且在其崗位上表現優秀的志愿者。
1.2.1 問卷調查的設計
網絡的輸入是志愿者特點X1~X6,針對這些特點,問卷中對每個特點分別設置5個問題進行得分的考察。每個特點的總得分范圍為整數0~10。得分越接近10說明該志愿者的這方面特點表現越好,越接近0說明該志愿者不具有這方面的特點。
網絡的輸出是志愿者崗位Y1~Y5,由于這些志愿者在其崗位上表現優秀,因此認為他們的特點是適合該崗位的。設某志愿者在Yi崗位上表現優秀,那么他的崗位輸出序列在Yi上則為1。同時考慮到志愿者的特點與其崗位之間的關系復雜,他們可能還適合別的崗位,因此在問卷中設置相應問題,讓志愿者選出自己還可以勝任哪個崗位。設某志愿者選的崗位為Yj,那么在該崗位上輸出則為0.5。除了Yi,Yj外其他崗位序列輸出均為0。
以部分問卷調查的數據為例,如一位書庫管理崗位的志愿者特點得分為9,6,5,5,4,2,他還可以選擇適合他的崗位是圖書加工,因此輸出為1,0.5,0,0,0;另一位館內向導崗位的志愿者特點得分為6,4,10,7,3,7,他還可以選則適合他的崗位是幫助特殊讀者,輸出則為0,0,1,0,0.5。
1.2.2 樣本數據的處理
在獲取了樣本數據后,需要對網絡的輸入端數據進行處理,使之成為標準的BP神經網絡訓練樣本。由于網絡的輸入X1~X6是0~10的整數,所以需要對其進行歸一化處理:
(1)
式中,X為轉換過后的輸入數據;Xk為轉換前的樣本數據實際值;Xmax,Xmin分別為轉換前樣本數據序列中的最大值和最小值。
網絡的輸出端數據,在采集過程中只取1,0.5或0作為判斷是否適合某個崗位,輸出端數據均在0~1之間,因此,可直接使用,不做歸一化處理。
2 基于BP神經網絡的圖書館志愿者崗位分 配方法
在獲取了BP網絡的輸入、輸出端神經元數目和樣本數據后,需要將BP神經網絡運用到圖書館志愿者崗位分配中,構建基于BP網絡的圖書館志愿者崗位分配模型,并對其理論可行性進行研究。
2.1 崗位分配模型的構建
在基于BP算法的多層前饋網絡的應用中,單隱層神經網絡的應用最為普遍,只要隱含層的節點數足夠多,含一個隱含層的BP神經網絡就可以以任意精度逼近一個非線性函數[21]。
將圖書館志愿者的特點X1~X6作為輸入,圖書館志愿者崗位Y1~Y5作為輸出,采用3層BP神經網絡,構建圖書館志愿者崗位分配模型,如圖1所示。
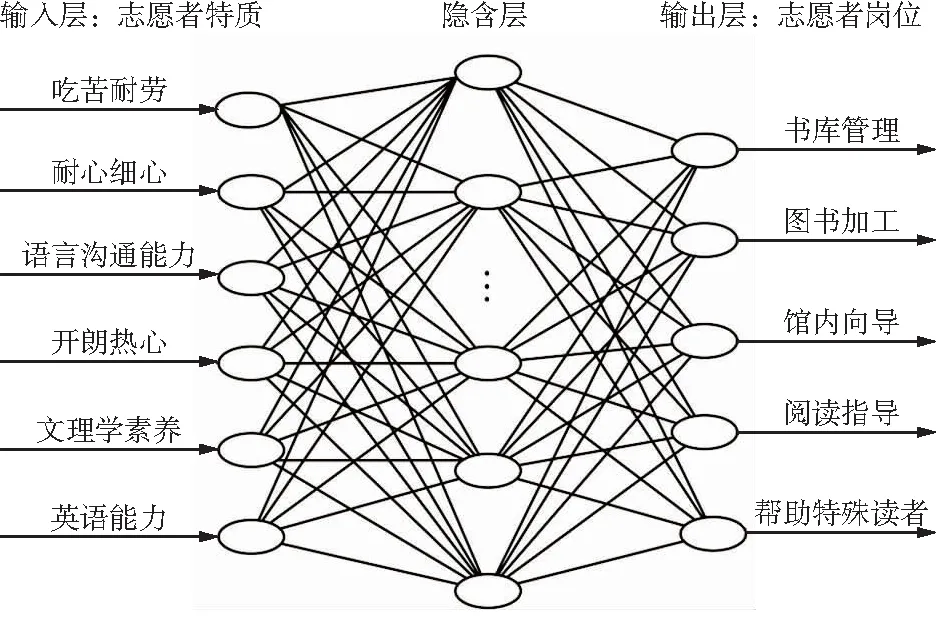
圖1 BP神經網絡圖書館志愿崗位分配模型Fig.1 Library volunteer post assignment model diagram of BP neural network
圖1中,輸入層的6個神經元是圖書館志愿者特點的個數。輸出層5個神經元數是圖書館志愿者崗位的個數。隱含層神經元個數的選取為[22]:
(2)
式中,n為輸入層神經元數目;m為輸出層神經元數目;a為[1,10]之間的常數,取a的值代入式(2)用試湊法確定最佳神經元數。
2.2 崗位分配模型理論分析
在構建了基于BP神經網絡的圖書館志愿者崗位分配模型后,對網絡模型在理論上進行分析,分為訓練與測試2個階段。
2.2.1 網絡模型訓練過程
網絡模型的訓練過程分為2個階段:第1階段是輸入已知樣本,圖書館志愿者的特點及崗位用(X,Y)表示,通過設置的網絡結構和前一次迭代的權值和閾值,從網絡第一層向后計算各神經元的輸出;第2階段是對權值和閾值的修改,從最后一層向前計算各權值和閾值對總誤差的影響梯度,從而對各權值和閾值進行修改,直到達到目標誤差或達到最大迭代次數為止。結合基于BP網絡的圖書館志愿者崗位分配模型,其訓練過程包括[23]:
① 對BP網絡崗位分配模型初始化。根據輸入樣本(X,Y)確定網絡的輸入層節點數志愿者的特點X1~X6,用n表示,隱含層節點數用l表示;輸出層節點數志愿者的崗位Y1~Y5,用m表示。
② 確定隱含層節點的輸出。根據志愿者的任意一個特點輸入為Xi,輸入層和隱含層的連接權值ωij,及隱含層閾值aj,計算隱含層輸出H:
(3)
式中,l為隱含層節點數;f(·)為隱含層激活函數,激活函數都是單極性Sigmoid函數,表達式為:
(4)
③ 確定輸出層節點崗位分配序列的輸出。根據隱含層輸出H,隱含層與輸出層連接權值ωjk和輸出層閾值bk,得到BP神經網絡預測輸出T:
(5)
④ 計算誤差。根據網絡的預測輸出T和期望輸出O,計算網絡預測誤差e:
ek=OK-Tk,k=1,2,…,m。
(6)
⑤ 權值和閾值更新。根據網絡預測誤差e更新網絡連接權值ωij,ωjk和隱含層、輸出層閾值a,b:
j=1,2,…,l,
(7)
ωjk=ωjk+ηHJek,j=1,2,…,l;k=1,2,…,m,
(8)
(9)
bk=bk+ek,k=1,2,…,m。
(10)
⑥ 依據BP網絡崗位分配模型設置的目標誤差條件判斷算法是否結束,若不滿足條件,返回步驟②。
2.2.2 網絡模型測試過程
將網絡訓練好后,輸入測試樣本對網絡的性能進行測試。在網絡的測試階段,網絡的預測輸出數據,會出現多位小數的情況。由于是對志愿者與崗位分配的研究,所以輸出層的預測輸出數據和問卷采集的輸出端數據Y1~Y5一致,只取1,0.5或0來代表其是否適合某個崗位。因此,對預測輸出數據需做轉換處理:
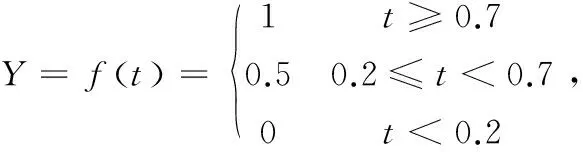
(11)
式中,t為測試階段網絡的預測輸出;Y為網絡轉換后的輸出。當t≥0.7時,Y取1;當0.2≤t<0.7時,Y取0.5;當t<0.2時,Y取0。
3 實驗與分析
為了驗證上述基于BP神經網絡的圖書館志愿者崗位分配的有效性,開展實驗與分析。
3.1 問卷樣本數據示例
在校圖書館對志愿者開展問卷調查,首先平均選取在志愿者崗位Y1~Y5上工作優秀的志愿者各60人左右;再向他們共發放問卷320份,實際回收并選取300份有效問卷。通過問卷調查所得數據,隨機在每個崗位上選取2份樣本數據,共10份數據,經過對輸入、輸出數據進行歸一化處理后,部分問卷處理結果如表3所示。

表3 歸一化處理后的樣本數據示例Tab.3 Sample data after normalization
表3中數據是經過歸一化處理后的數據。每個崗位隨機選取2位志愿者的調查信息作為展示,共10位,其中,X1~X6為志愿者性格的得分情況,越接近1說明該志愿者的某一特點表現越好;Y1~Y5為志愿者的崗位分配情況,1視為最為適合該崗位,0.5視為比較適合的崗位,0視為不適合的崗位。
3.2 實驗參數
3.2.1 軟件環境
實驗軟件為:主機(Win7 64位)的操作系統、Matlab Version 8.2 (R2019a)。
3.2.2 神經網絡參數
網絡的訓練樣本為從5個崗位的問卷調查樣本數據中各隨機選取54份左右,共270份;測試樣本為剩余的30份。
網絡的神經元:BP神經網絡的輸入層神經元數為6,輸出層神經元數為5,隱含層神經元數經過反復測試,最終確定為13。
網絡的訓練參數:網絡訓練的目標誤差為0.01,最大迭代次數為2 000,學習速率為0.5,網絡初始權值閾值隨機分配。
3.3 實驗結果
3.3.1 網絡性能分析
基于上述實驗參數,將300組樣本數據集用于神經網絡的訓練與測試,訓練誤差性能曲線如圖2所示。

圖2 BP神經網絡誤差性能曲線Fig.2 BP neural network error performance curve
圖2中顯示的是誤差性能隨著迭代次數增加逐漸下降的曲線。橫坐標值是訓練次數,縱坐標值是網絡的均方誤差。收斂目標設為0.01,最大迭代次數為2 000。從圖2中可以看出,網絡在第10次迭代前快速收斂,在第10次左右后緩慢收斂,最終在57次時均方誤差達到網絡的預設目標誤差值。
3.3.2 測試結果
在網絡訓練完成的基礎上,用30組測試樣本數據對網絡進行測試。輸入為每位志愿者的性格得分,輸出為每位志愿者的5個崗位的得分。得到網絡預測值與真實值之間的擬合圖,因為有5個崗位,所以每個崗位上分別對應著30組樣本的輸出值,分別如圖3~圖7所示。
在書庫管理崗位上30位志愿者的崗位預測情況如圖3所示。從圖中可以看出,對于此崗位30組樣本的預測值與真實值之間為完全擬合,沒有出現誤差。

圖3 書庫管理崗位預測值與真實值對比Fig.3 Predicted and actual values comparison chart of stack room management post
在圖書加工崗位上30位志愿者的崗位預測情況如圖4所示。從圖中可以看出,對于此崗位在第16個樣本處,真實輸出為0.5,也就說明該志愿者還適合的崗位是圖書加工;但預測值輸出為0,認為不適合的崗位是圖書加工;第22個樣本處,真實輸出為0.5,預測輸出為0;第29個樣本處,真實輸出為0,預測輸出為0.5。因此在第16,22,29三個樣本處出現誤差。
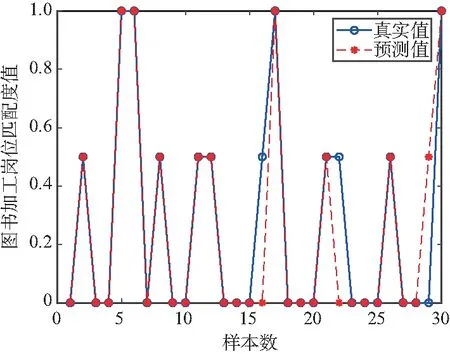
圖4 圖書加工崗位預測值與真實值對比Fig.4 Predicted and actual values comparison chart of book processing post
在館內向導崗位上30位志愿者的崗位預測情況如圖5所示。從圖中可以看出,對于此崗位30組樣本的預測值與真實值之間為完全擬合,沒有出現誤差。

圖5 館內向導崗位預測值與真實值對比Fig.5 Predicted and actual values comparison chart of library guide post
在閱讀指導崗位上30位志愿者的崗位預測情況如圖6所示。從圖中可以看出,對于此崗位在第7和第29個樣本處預測值與真實值之間沒有完全擬合。因此在第7和29兩個樣本處出現誤差。

圖6 閱讀指導崗位預測值與真實值對比Fig.6 Predicted and actual values comparison chart of reading guide post
在幫助外國讀者崗位上30位志愿者的崗位預測情況如圖7所示。從圖中可以看出,對于此崗位在第10個樣本處,預測值與真實值之間沒有完全擬合。因此在第10個樣本處出現誤差。
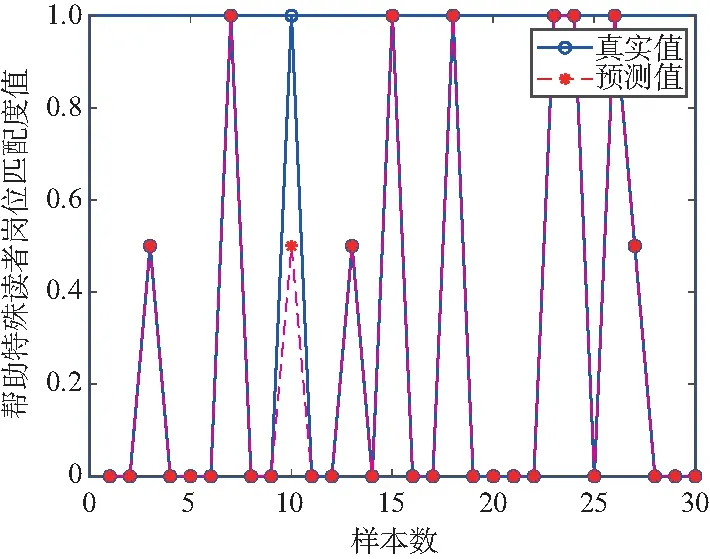
圖7 幫助特殊讀者崗位預測值與真實值對比Fig.7 Predicted and actual values comparison chart of special reader assistance post
綜合圖3~圖7的分析,30組樣本的崗位預測中,分別在第7,10,16,22,29的5組樣本處存在較大誤差,可視為誤差樣本,剩余的25組樣本的預測結果是正確的。因此,基于BP神經網絡的圖書館志愿崗位分配模型的預測識別率為83.3%。其中有少量誤差現象可能是因為存在一些不可避免的人為主觀因素的影響,比如,一位書庫管理崗位的志愿者認為自己還適合幫助外國讀者的崗位,但他可能僅僅是想提高自身的英語能力,而沒有考慮自己是否可以勝任的情況。所以,不影響BP神經網絡對圖書館志愿者崗位分配的整體分類效果。
上述結果表明,基于BP神經網絡的圖書館志愿者崗位分配模型能夠用于圖書館志愿者的崗位分類,實驗證明該模型,可在多入多出的崗位預測中取得較好的分類效果。
4 結束語
針對當前對圖書館志愿者與崗位分配之間的研究,還存在偏理論、缺乏定量定性的智能化的模型等不足,結合國內學者采用BP神經網絡構建崗位匹配模型的方向,提出了構建基于BP神經網絡的圖書館志愿者崗位分配模型。仿真試驗結果表明,該模型在對圖書館志愿者的崗位分類上有著良好的效果,能夠滿足在實際中對大多數圖書館志愿者合理分配崗位的要求,具有良好的應用前景,但由于網絡的訓練樣本數據中會有少數因志愿者主觀因素而導致的誤差數據,預測精度還有待提高。因此,獲取到更為準確的樣本數據,完善圖書館志愿者崗位分配指標體系是下一步研究的重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
小太陽畫報(2018年1期)2018-05-14 17:19:25
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
光學精密工程(2016年6期)2016-11-07 09:07:19
