智慧校園背景下圖書館個性化推薦服務系統設計?
2020-11-04 10:47:26歐瓊妍
圖書館學刊 2020年10期
歐瓊妍
(南寧師范大學圖書館,廣西 南寧530001)
隨著時代的發展,我國高等院校信息化建設逐步加快,智慧校園建設漸成趨勢。智慧校園是通過運用信息技術,進行大數據分析,得出更加科學的決策,以便開展更加合理的項目,進而實現科研技術的發展和人才的培養與社會需求的協調統一。在智慧校園的背景下,很多高校圖書館以此為契機開始進行創新改造,增添了多種信息服務設備和資源,將圖書館服務體系建設納入智慧校園建設之中,既能夠增強圖書館的服務水平,也能發揮圖書館的效能與作用。筆者擬就智慧校園背景下圖書館的個性化推薦服務系統進行設計和研究。
1 圖書館個性化推薦系統概述
高校圖書館個性化推薦系統是通過分析借閱數據,發現不同用戶的個性化需求,有針對性地為用戶推薦圖書的自動化、智能化讀者服務系統。該系統采用個性化推薦技術,其服務不同于以往用戶自行檢索查詢的被動方式,而是以用戶需求為中心,根據用戶的信息需求特征,主動地為其推送匹配的圖書信息。這種服務方式不但有助于圖書館的人性化發展,有利于提升用戶的滿意度,也能夠有效提高圖書借閱率和利用率。
個性化推薦服務作為一種智慧圖書館服務,是智慧校園建設過程中一個重要的組成部分。個性化推薦系統能夠對不同讀者的個性化需求進行區分,給讀者以自主化、人性化的圖書館服務體驗。
1.1 個性化推薦服務的形式
智慧圖書館應當注重用戶個體需求和借閱習慣的發掘分析,這是實現個性化推薦服務的前提條件。圖書館用戶在這一系統運行的過程中,具有至關重要的地位,推薦服務系統應當以用戶為本,發揮用戶需求在系統中的主導作用,這樣系統推薦的圖書才更容易被用戶喜歡。目前,我國許多高校圖書館都開始采用集個性化需求挖掘與分析服務、個性化信息智能定制服務以及個性化信息推送服務于一體的個性化推薦服務。
1.2 個性化推薦服務的組成
個性化推薦系統最初應用于人們日常生活,是作為購物網站等商業領域的商品智能化展示功能。這一系統的研究融合了多種學科知識,其研制過程中需要使用到心理學、人類學、信息學、社會學、管理學等多個學科領域的理論和技術。圖書館個性化推薦服務系統正是在傳統個性化推薦系統的基礎上發展而來的,它面向高校圖書館借閱讀者群體,根據用戶的個性化需求推薦符合讀者趣味和習慣的圖書。個性化推薦系統包括讀者建模、推薦讀者建模、推薦算法建模3 個部分。其中推薦讀者建模是核心部分。

圖1 個性化推薦系統的基本模塊組成
2 個性化推薦服務體系與功能
2.1 個性化推薦服務體系
個性化推薦服務體系可以搜集用戶的偏好圖書數據,并在此基礎上進行數據分析和整合。該體系能為智慧圖書館建設提供重要的支撐,也能提高讀者借閱圖書的便捷性,讓讀者享受到更加高質量的服務。智慧圖書館可借助館內的信息設備,根據讀者借閱習慣、偏好等有用信息,為讀者提供個性化、智能化的圖書推薦服務。個性化推薦服務體系主要包括以下內容:(1)圖書館搜集并分析用戶數據信息。通過讀者信息監測系統、讀者信息傳輸系統等信息技術和手段,搜集讀者存儲在設備上的圖書借閱數據和信息,并從圖書館規定和讀者需求出發,利用信息化系統分析和處理這些數據。(2)圖書館分類處理讀者的個性化信息。將這些信息按照相關性、特殊性和重要程度進行分類,并為讀者數據信息的整合打下基礎。(3)圖書館從整體上集中整合讀者的信息數據。把信息的隱藏價值分析出來,不斷探尋讀者借閱數據與需求的內在聯系,在整合各種信息的前提下,審查系統的科學性和合理性,不斷完善個性化圖書推薦服務體系,從而為讀者提供更高質量的圖書推薦服務。
2.2 個性化推薦系統功能分析
圖書館個性化推薦系統應具備針對用戶需求量身定制圖書信息的功能。在系統提供個性化服務的過程中,要保證讀者所獲取的圖書館服務信息是有價值的,不能是無效或者失效的信息。不同權限級別的用戶在行使其權限登錄個性化服務系統后,能夠獲取的個性化推薦信息也不同,讀者可根據自己的需求自行選擇圖書。在個性化服務系統中,權限是一種身份和專業的區分,如果學生來自不同的專業,甚至來自不同的學校,那么系統就會針對個性化需求和專業特點來提供相應的信息服務。
在智慧校園建設過程中,圖書館信息系統除了提供圖書信息查詢服務之外,還要提供預訂圖書、文獻互助、傳遞文件、參考咨詢等服務。在系統運行時,應當確保服務信息的準確性、及時性和有效性,從而讓用戶享受更高質量的個性化信息服務。
圖書館在推薦圖書時,可同時提供專業的個性化服務,從讀者的借閱歷史中發現其偏好的書籍類型,并向讀者主動推送與其喜歡書籍相近的圖書目錄,這是個性化服務中的關鍵內容。憑借這種方式,可有效幫助讀者在浩如煙海的書籍信息中快速獲取有用信息,大大節省了讀者查閱和搜集資料花費的時間,增強讀者選擇圖書資源的針對性,提高讀者利用圖書館服務的效率。
3 個性化推薦系統設計
3.1 功能模塊設計
筆者設計的個性化推薦系統具有數據信息的挖掘、采集和推薦3 個主要的功能,該系統的功能模塊結構如圖2所示。
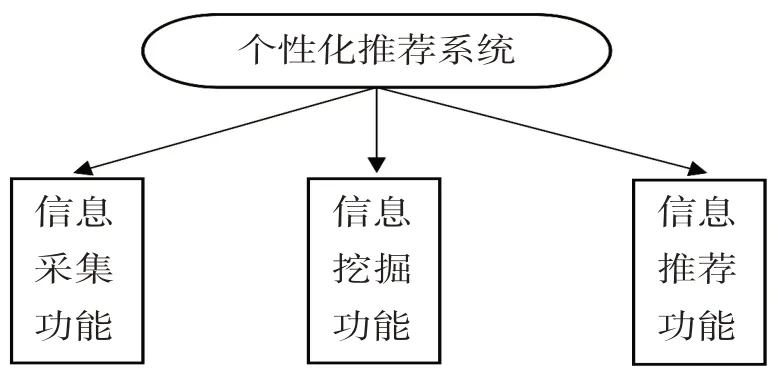
圖2 圖書館個性化推薦系統模塊
(1)信息采集功能模塊。建立這一功能模塊的目的是為了對用戶的閱讀數據進行篩選和處理,清除有缺失的、無意義的甚至是有害的信息,從而為發掘更有價值的數據信息打下基礎。該模塊運行時,系統能夠以特別的手段來處理用戶個體的閱讀數據信息,將不同格式的信息轉化成更容易分析比較的格式,將不同種類的信息分類處理,將相同種類的信息合并處理。
(2)信息挖掘功能模塊。該功能模塊是建立在信息分類、聚類和關聯的基礎之上的。在利用信息采集功能模塊收集到用戶的有用信息后,可依據用戶的需求和偏好,對這些信息進行深入的挖掘,并將挖掘出的關鍵信息納入圖書館的數據庫,可在數據庫中對這些信息進行特別的定義,以標注信息的獨特性。
(3)信息個性化推薦功能模塊。在圖書館數據信息處理的方法中,聚類分析技術是最為常見的一種方法,該技術通過信息整合和轉化,能在很大程度上提高系統的運行效率。而在這一過程中往往還會用到特別的數據分析技術,分析之后要將分析結果導入特定的數據庫,進而為圖書的個性化推薦奠定基礎,并在用戶進行信息檢索時為其提供幫助。
3.2 個性化推薦服務系統整體架構
在智慧校園背景下,圖書館個性化推薦服務系統所采用的設計框架是當前廣泛使用的SSH框架。這一框架在系統開發設計過程中很容易操作,能夠顯著提高系統的研發效率,在不同結構之下都可以為系統設計提供幫助。另外,在SSH 框架下進行二次開發也很方便,應用SSH 框架有利于日后的系統維護。運用SSH框架建立的系統架構如圖3所示。
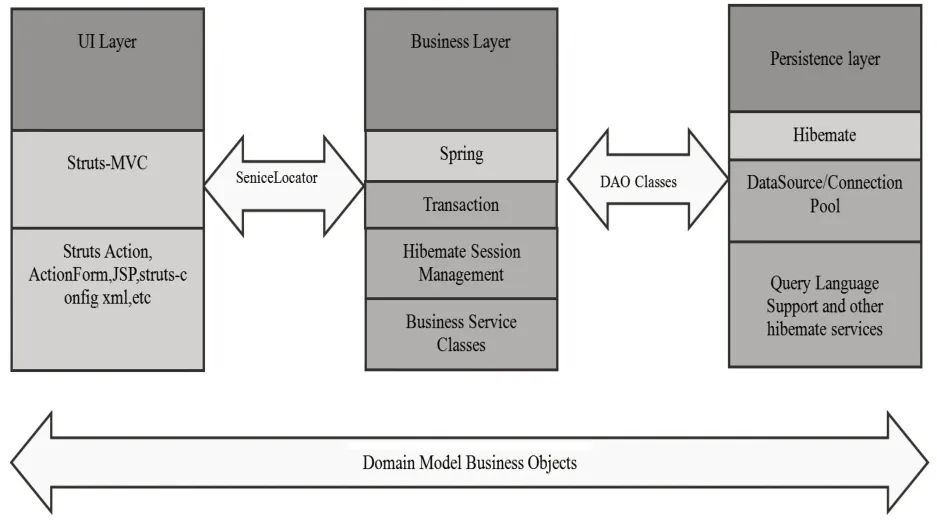
圖3 SSH框架系統架構
(1)用戶層。用戶層通過對組件化開發模式的運用,建立良好的窗口交互系統,并利用JSP 技術,構建人性化的交互界面,這一界面相當于一座橋梁,在讀者和系統之間形成了有效的聯系,大大增強了系統的交互性。
(2)業務層。為了更大程度地保障用戶界面的交互需求,該系統構架采用了目前普遍使用的“Struts+Spring+Hibernate”技術,能夠保障系統的各項功能得到最大化利用。
(3)挖掘層。通過應用專業的系統分析工具,堅持聚類和分類的思想,深入挖掘用戶數據背后隱性的個性化需求和愛好,并將挖掘分析結果導入特定數據庫中存儲。
(4)數據層。數據層由系統相關數據庫構成,可在此以結構圖的形式表示數據庫之間的關聯性。
4 個性化推薦服務系統的實現
4.1 數據準備
在對個性化推薦系統進行設計之前,應當分別從圖書館的圖書文獻信息、歷史搜索信息、用戶借閱信息、系統推薦信息和人機交互信息等幾個方面,對信息管理平臺的數據進行分類處理,從而為個性化推薦服務系統的實現提供必要的數據信息。
4.2 建立用戶信息需求模型
建立符合用戶需求的信息模型,在系統建設過程中至關重要。這一模型可以對讀者感興趣的圖書數據進行分析,以更好地為讀者提供圖書推薦服務。用戶的信息需求模型包括興趣模型和數據挖掘模型。基于興趣模型,可以建立多條有效的信息需求途徑,具體的途徑關系如圖4所示。圖書館服務系統利用個性化推薦算法,可形成讀者的興趣模型,該算法能夠全面監測并篩選讀者的歷史借閱信息和用戶偏好,并在此基礎上匯總成興趣檢索目錄,以保證興趣需求模型的有效運行。建立興趣模型,是為了有的放矢地提供服務,進一步滿足用戶的需求,用戶興趣模型的建立是以圖書館對用戶信息的挖掘分析為基礎的,為準確客觀把握用戶的興趣愛好和信息需求傾向,圖書館必須采用大數據分析等多種技術手段,建立數據挖掘模型。
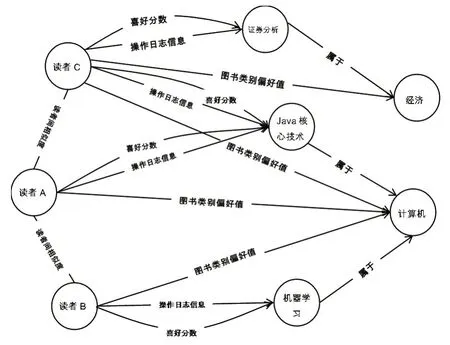
圖4 用戶信息需求模型
4.3 基于協同推薦算法的應用
存儲在個性化推薦系統中的用戶檢索信息數量非常龐大,為在滿足讀者需求的同時達到圖書利用效率的最大化,應當利用相關算法協助處理數據。
(1)皮爾森相似度關聯。皮爾森相似度被用來表示兩個變量間的線性關系。皮爾森系數值在[-1,1]間發生變化。當皮爾森系數等于0時變量之間不具有線性關系;當皮爾森系數大于0 時,兩個變量之間呈正相關關系,一個變量隨著另一變量的增加而增加;相反的,當皮爾森系數小于0時,兩個變量之間呈負相關關系,
(2)歐幾理德距離相似度。歐幾里得相似度是一種計算距離相似度的算法,也是一種很容易理解的算法,這種算法把數據作為坐標,觀測者通過繪制坐標軸并計算直線距離,即可表示數據之間的關系。
(3)余弦相似度。為了比較數據空間中個體差異情況,需要用到余弦相似度,即向量空間中兩個向量夾角的余弦值。與距離相似度相比,余弦相似度強調的是個體在方向上的差異性。
(4)調整余弦的相似度。對向量夾角求余弦值即可獲得余弦相似度。隨著向量維度的不同,計算得到的余弦值可能也有所不同。在評分計算時,A和B用戶的評分分別取自在(1,2)和(4,5)之間時,計算余弦值為0.98,A 和B 用戶得出的結果相近,但其實B卻在內容上與A完全相反。這時可對余弦計算進行調整,將評分期望都設為3,那么A 和B 用戶的評分就可以分別在(-2,-1)和(1,2)中進行選擇,之后再進行余弦值計算,結果為負數時表示A和B的差異性很小。
(5)Pearson 相關度。Pearson 相關度可以用來表示用戶的偏好。首先對用戶的興趣程度賦值,設分值為1時用戶不感興趣,設分值為2時用戶感興趣,之后再將Pearson相關系數進行變換處理。
(6)谷本系數相似度度量。與以上幾種算法相比,谷本系數算法對于評分沒有要求,這一點非常獨特,谷本系數算法更注重數據與用戶之間的邏輯相關性,可以用布爾邏輯體系來構建用戶和數據的聯系。
4.4 系統運行條件
在設計個性化推薦服務系統時,要對系統的穩定性、兼容性和拓展性進行提前考慮。筆者研究開發該系統,應用的是目前常用的操作系統,使用Windows7 系統作為系統客戶端,用Windows Server2008 作為服務器,用MySQL 作為數據庫,使用360安全瀏覽器來訪問系統,足以保障系統的安全性。
5 結語
在智慧校園建設中很多圖書館都結合學科特點和用戶的自身需求,設計出了各種具有針對性的個性化推薦服務系統。然而這些在不同框架體系下運行的個性化推薦系統也面臨著諸多問題。在個性化推薦服務系統中,有很多地方都需要進一步發展和完善,尤其是系統的功能模塊,更應當注重用戶數據的搜集和挖掘。只有這樣,才能讓讀者普遍享受高質量的圖書信息服務。因此,發展個性化推薦服務系統是大勢所趨,其根本目的是為了提升圖書館信息服務的質量和效率。
猜你喜歡
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小太陽畫報(2018年1期)2018-05-14 17:19:25
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
