基于Kmeans聚類的XGBoost集成算法研究
2020-11-09 07:29:18羅春芳張國華劉德華朱定歡
計算機時代 2020年10期
羅春芳 張國華 劉德華 朱定歡


摘? 要: 針對分類問題中的模型泛化能力,提出了基于Kmeans聚類的XGBoost基分類器集成算法,以提升整體算法的泛化能力。首先,訓練數據集獲得多個XGBoost模型;然后,通過Kmeans算法對不同模型的實驗結果聚類;最后,對每個分類簇中泛化能力最優(yōu)的分類器進行集成。在對某公司實際分類問題中應用該算法,結果表明,該算法的泛化能力有很大程度的提升。
關鍵詞: Kmeans聚類; XGBoost; 集成算法; 泛化能力
中圖分類號:TP391? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2020)10-12-03
Abstract: Aiming at the model generalization ability of classification problem, a K-means clustering based XGBoost base classifier ensemble algorithm is proposed in this paper to improve the generalization ability of the whole algorithm. Firstly, training data sets to obtain multiple XGBoost models; then clustering the experiment results of different models with K-means algorithm; finally, integrating the classifiers with the best generalization ability in each cluster. The algorithm was applied to practical classification problems, the results show that the generalization ability of the algorithm is greatly improved.
Key words: K-means clustering; XGBoost; ensemble algorithm; generalization ability
0 引言
近年來,隨著數據科學的不斷進步,XGBoost(eXtreme Gradient Boosting)算法被商業(yè)、網絡、股票分析、電子產品等領域廣泛應用[1]。XGBoost是一種在梯度提升算法(GBDT)基礎上改進的學習算法[2],其特點為復雜度低、并行效果好、計算精度高[3],但其泛化能力有待提升。本文選擇Bagging多模型融合思想, 采用多個XGBoost基分類器,使得每個基分類器只擬合部分樣本下的部分特征屬性,然后用Kmeans聚類,進而提升其泛化能力。
其思路為:首先,抽取樣本訓練多個XGBoost基分類器模型,然后,采用Kmeans算法聚類多個基分類器模型中的實驗結果,最后,集成每個分類簇中泛化能力最優(yōu)的基分類器。
1 基于Kmeans聚類的XGBoost集成
1.1 Kmeans 聚類算法
Kmeans算法穩(wěn)定性好,聚類效果佳,而且與數據的輸入順序無關,亂序處理時,可獲得同樣的結果,可很大程度上避免亂序帶來的煩擾,是一種經典的聚類算法[4]。
1.1.1 Kmeans算法思路
先在數據集中隨機選取[K]個樣本為聚類初始中心點;然后計算其余所有樣本與[K]個樣本點的歐式距離,比較樣本點與[K]個中心點的[K]個距離值,離哪個中心點距離最近就歸為哪一類;之后重新計算簇中心點,并且一直重復前面的步驟,直到簇中心點位置收斂時結束。
1.1.2 Kmeans算法步驟
⑴ 選點:從樣本中隨機選取[K]個樣本作為初始中心點;
⑵ 歸類:計算其余樣本與[K]個樣本點的歐氏距離并比較,將樣本與距離最近的中心點歸為一類;
⑶ 計算:重新計算簇中心點,一直重復前面的步驟, 直到簇中心點的位置收斂時結束。
1.2 XGBoost算法
XGBoost是由Tianqi Chen等2015年提出,在GBDT基礎上,加入目標函數的二次泰勒展開項和模型復雜度的正則項[5],使得目標函數與實際數據相差更小,達到減少數據誤差,提高預測準確度的一種算法。該方法計算精度高,并行效果好,具有很好的解釋性,在工業(yè)界中得到了廣泛的應用。具體思路如下:
1.3 Bagging集成
Bagging是經典的集成學習方法[6],是通過綜合多個弱學習器的學習結果,共同完成同一個學習任務的過程。其集成原理為:有放回重復抽取[N]個樣本集,每個樣本集中有[M]個樣本,分別訓練[N]個學習模型,從而獲得[N]個弱學習器[7]。
其具體算法如下:
⑴ 在原數據集中有放回任意抽取[M]個樣本,共進行[N]次,獲得具有[M]個樣本的[N]個樣本集;
⑵ 將[N]個樣本集分別對應訓練成[N]個弱學習模型,得到[N]個弱學習器;
⑶ 將[N]個弱學習器輸出結果對應投票,得到最終分類結果。
1.4 基于Kmeans聚類的XGBoost基分類器集成算法
為了在采用XGBoost提升模型精度的同時,進一步提高模型泛化能力,本文融入了Kmeans和Bagging的思想,提出了基于Kmeans聚類的XGBoost基分類器集成算法,具體流程如圖1所示。
算法具體步驟如下:
① 對訓練集[D]有放回任意抽取[M]個樣本,獲得具有[M]個樣本的樣本集;
② 訓練基分類器[hn],得到樣本的訓練結果;
⑷ 將步驟⑶中的[N]個基分類器的結果用Kmeans聚類,選出每個分類簇下的最佳基分類器;
⑸ 對選出的多個最佳基分類器的輸出結果根據簡單投票法投票,輸出最終預測結果。
2 實驗結果與分析
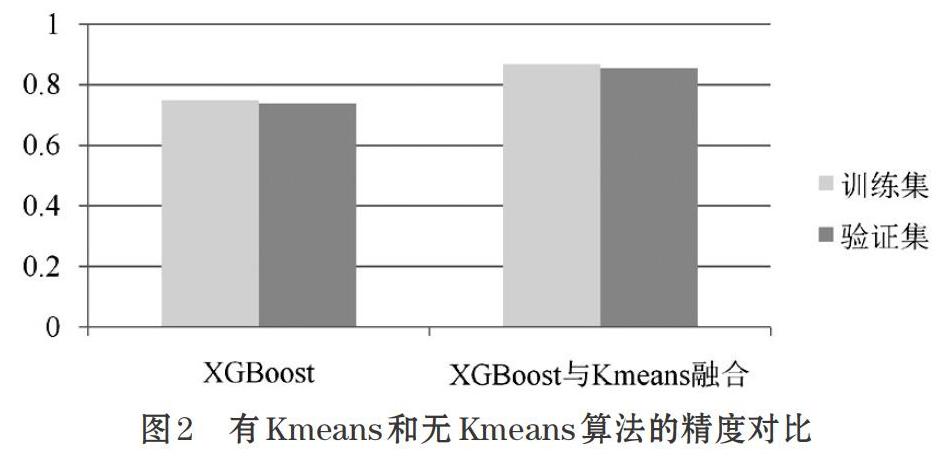
本文數據集樣本量為689945個數據,共有51個特征。對數據進行分類后,所得預測結果精度對比如圖2所示。
從結果可知,通過多XGBoost模型集成的數據經Kmeans聚類后,整體的泛化能力得到了提升。
3 結束語
文中提出的基于Kmeans聚類下的XGBoost集成算法研究,采用多個XGBoost基分類器,每個基分類器只擬合部分樣本下的部分特征屬性增加其差異性,從而提升整體算法的泛化能力。通過實驗結果可知,Kmeans聚類的XGBoost集成算法在提高訓練精度的同時提高了算法的泛化能力。
參考文獻(References):
[1] 蔣晉文,劉偉光.XGBoost算法在制造業(yè)質量預測中的應用[J].智能計算機與應用,2017.7(6):58-60
[2] 謝冬青,周成驥.基于Bagging策略的XGBoost算法在商品購買預測中的應用[J].現代信息科技,2017.1(6):80-82
[3] 王燕,郭元凱.改進的XGBoost模型在股票預測中的應用[J].計算機工程與應用,2019.55(20):202-207
[4] 魏杰.基于K-means聚類算法改進算法的研究[J]. 信息通信,2018.5:14-15
[5] 徐樹喬.基于XGBoost的Bagging方法的電信客戶流失預測應用研究[D].華南理工大學碩士學位論文,2019.
[6] 元慧,王文劍,郭虎升.一種基于特征選擇的SVM? Bagging集成方法[J].小型微型計算機系統,2014.35(11):2533-2537
[7] 蔣蕓,陳娜,明利特,周澤尋,謝國城,陳珊.基于Bagging的概率神經網絡集成分類算法[J].計算機科學,2013.40(5):242-246
