基于字典學習的主動聲吶目標分類方法
2020-11-10 11:54:14孫同晶
聲學技術 2020年5期
王 紅,孫同晶,劉 桐
(杭州電子科技大學通信信息傳輸與融合技術國防重點學科實驗室,浙江杭州310018)
0 引 言
主動聲吶目標分類[1-2]作為水聲信號處理的重要研究方向之一,在國防和民用方面都有重要應用價值。主動聲吶是常用的水聲設備[3-4],通過接收發射脈沖信號與目標沖擊響應的卷積,得到攜帶大量反映目標本質信息的回波信號,用于水下目標分類研究。典型分類方法[5-8]分為特征提取和分類器設計兩個部分,如 Li等[9]利用分數傅里葉變換頻譜對水雷回波信號進行特征提取,然后利用主成分分析對特征進行壓縮后再放入支持向量機(Support Vector Machine,SVM)分類器進行分類。但當海洋環境復雜以及研究目標為小物體時,接收的目標回波信號較弱,基于原信號的分類方法無法滿足研究需求。
1993年,Mallat等[10]結合稀疏表示理論解決了低信噪比信號的處理問題。稀疏表示[11]利用信號在變換域(字典)中具有稀疏的特性,有效地去除了信號的噪聲[12],提高了信噪比。稀疏表示是由字典中有限的列向量線性表示信號的過程,因此,字典的設計直接影響稀疏表示性能。研究初期,信號的表示大多基于通用的固定字典,如余弦變換基、傅里葉變換基[13]和小波基[14]等。而后,研究者們提出了學習字典的方法,其中 K-奇異值分解算法(K-Singular Value Decomposition,K-SVD)算法K-SVD[15]是目前最常用的字典學習算法,最早由Aharon等提出,因其快速的計算效率,受到了廣泛的關注[16-18]。基于訓練學習的字典帶有目標信號類別信息(由目標信號樣本作為初始字典訓練出的最貼近目標特性的學習字典,具有對同類別目標更有效的信息),本文基于字典學習這一優勢,提出一種基于字典學習的稀疏表示分類方法,根據回波信號學習出帶有類別信息的學習方式,以重構信號與原信號的匹配度作為分類策略進行分類,有望提高水下目標分類方法的性能。
1 稀疏表示分類基本原理
1.1 稀疏表示原理
稀疏表示是逼近思想的一種衍生。設一個回波信號Y,線性逼近過程是將Y投影到正交基ψ={ψ1ψ2… ψN} 上,以ψ中N個向量ψi線性表示Y:

基于信號逼近的思想,定義稀疏表示:設N維希爾伯特(Hilbert)空間有一組正交字典D={d1,d2,…,dN},di為原子函數,將 Y表示為K(K?N)個原子的線性組合形式:

把待表示信號Y考慮為一個M×1的向量,一般而言,該向量大多數元素不為0,稀疏表示就是將信號Y在字典D上表示成具有很多0元素向量X的過程,使得數據具有稀疏性,字典D是一個M×N的矩陣。稀疏表示原理如圖1所示。
為了用盡可能少的原子表示信號的本質特征,獲得待表示信號Y的最稀疏形式,限定稀疏系數非0項的個數為ε,求解如下優化問題:


圖1 稀疏表示原理圖Fig.1 Schematic diagram of sparse representation
l0-范數是一個多項式復雜程度的非確定性問題(NP-hard problem),很難直接優化求解。由于l1-范數表示計算非零元素絕對值之和,是l0-范數的最優凸近似,并且更好優化求解,因此,使用l1-范數替代l0-范數,優化問題等價于如下問題:

當優化目的為得到與信號Y誤差最小的稀疏表示形式時,改寫優化問題為

式中,γ表示誤差最大值。
1.2 稀疏表示分類
典型的稀疏表示分類方法是基于信號在字典中呈現稀疏狀態,用一組原子函數線性地表示信號,在滿足一定稀疏度的條件下,獲取對原始信號的良好近似,并捕捉信號內在的本質特征,得到特征明顯的稀疏信號。在此基礎上選擇并提取特征,最后結合分類器對信號進行分類。
本文提出了基于字典學習的稀疏表示水下目標分類方法(Dictionary Learning-Sparse Representation Classification,DLSRC),該方法與典型稀疏表示分類方法在原理上都是基于信號在字典中呈稀疏狀態,將信號表示為稀疏形式,不同點在于分類方法。本文采用學習的類別字典進行分類,以重構信號與測試信號的匹配度作為分類策略,實現目標分類。
2 基于字典學習的主動聲吶目標稀疏表示分類方法
2.1 基于字典學習的稀疏表示水下目標分類
本文提出的DLSRC方法,是由字典學習算法得到各類別字典,通過各字典重構信號,根據重構信號與原信號的匹配度來判斷數據的類別,DLSRC方法框圖如圖2所示。將實測信號分為訓練集和測試集導入Matlab程序中,訓練集由字典學習算法訓練出具有類別信息的字典,測試集賦初始類別標簽。

圖2 DLSRC方法總框圖Fig.2 General block diagram of DLSRC method
具體步驟如下:
(1)導入實測信號:將信號分為訓練集和測試集導入Matlab軟件中;
(2)加噪聲:利用Matlab軟件通過仿真給所有信號加入高斯噪聲;
(3)訓練字典:采用K-SVD算法訓練出各類對應的字典,分別標記為字典1、字典2、字典3、字典4;
(4)標記測試信號:每類測試集附上各自的初始類別標簽(測試集本身沒有標簽,此步是為了計算分類模型的準確率);
(5)計算稀疏系數:測試信號分別放入各類別字典中,經過正交匹配追蹤(Orthogonal Matching Pursuit,OMP)算法得到不同的稀疏系數(每個測試信號產生4個稀疏系數);
(6)重構數據:由各類別字典及對應的稀疏系數重構出對應的數據;
(7)計算匹配率:計算測試信號與其對應重構數據的匹配率(每個測試信號對應4個匹配度);
(8)判定標簽:找到與測試信號匹配率最高的重構信號,判定類別與其對應字典相同;
(9)計算準確率:判斷初始類別標簽和新的類別標簽是否相同,相同即分類正確,統計正確個數,得到準確率。
2.2 基于訓練學習的字典構造
K-SVD算法主要由稀疏編碼和更新字典兩個步驟迭代。首先,由OMP算法計算稀疏編碼矩陣,然后逐列更新字典(奇異值分解方法),同時在當前字典下更新稀疏編碼矩陣,最后反復迭代、更新,直到收斂或滿足結束條件。K-SVD算法的流程圖如圖3所示。

圖3 K-SVD字典學習算法流程圖Fig.3 Flow chart of k-SVD dictionary learning algorithm
通過求解如式(4)的優化問題,得到最優字典D。具體實現步驟如下:
(1)初始化:設訓練集為字典D的初始矩陣,初始化稀疏編碼矩陣X為0矩陣;
(2)稀疏編碼:已知字典D,用OMP算法稀疏編碼近似求解稀疏系數X,懲罰項可以寫為

(3)更新字典和稀疏系數:已知稀疏系數 X,固定除當前更新原子di外其它K-1項原子,剝離原子di的貢獻,逐列更新字典D。目標函數為


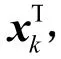
(4)迭代更新 D和 X,直到收斂或滿足結束條件。
2.3 稀疏編碼方法
稀疏表示中,字典學習和稀疏分解均用到了稀疏編碼計算稀疏系數。1993年,Mallat等[10]提出了匹配追蹤(Matching Pursuit,MP)算法。為了改進MP算法收斂速度慢這一缺點,研究者們提出了正交匹配追蹤(OMP)算法[19],引入施密特正交化,對每一步分解所選擇的全部原子進行正交化處理,由于殘差總是與被選擇過的原子正交,一個原子不會被重復選擇,加快了收斂速度。目標函數為


(1)給定字典D,初始化殘差 e0=y,y為信號;
(2)選擇與殘差內積絕對值最大的原子,表示為φ1;
(3)將被選中的原子φ1作為列組成矩陣φt(每次循環不清空),計算φt的正交投影算子矩陣P,通過目標函數計算殘差e1。
(4)對殘差迭代執行(2)、(3)步,在迭代過程中被選擇過的原子均與殘差正交,不會重復選中,φt為所有被選擇過的原子組成的矩陣;
(5)達到設定迭代次數或殘差小于設定值時,計算結束。
OMP算法的流程如圖4所示。
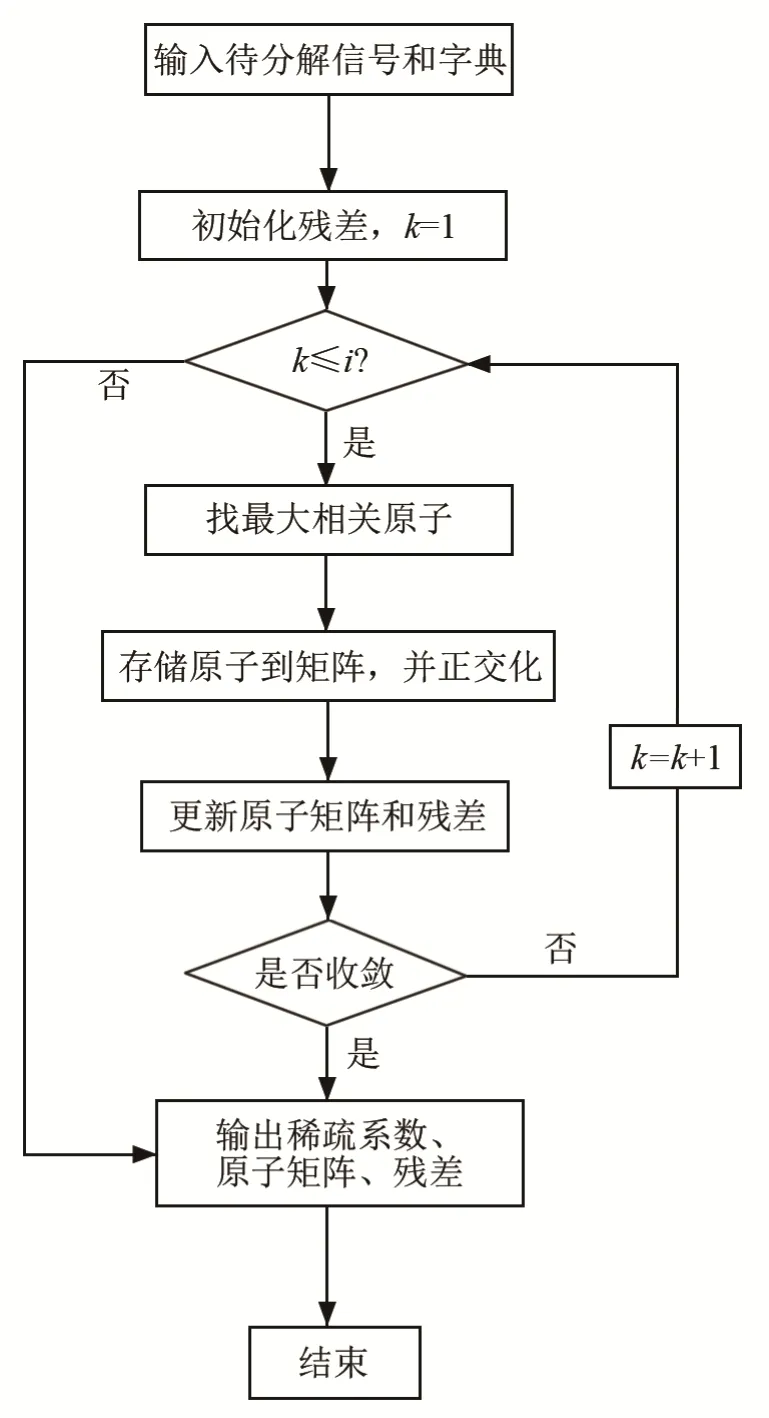
圖4 OMP算法流程圖Fig.4 Flow chart of OMP algorithm
2.4 分類策略
本方法以測試信號與重構信號的匹配度[20]作為分類策略,匹配率根據l2-范數計算。首先,分別計算原信號和重構信號誤差和兩者總和的l2-范數,然后,將結果減去誤差的l2-范數,最后計算其在總和中的占比。匹配度越高,信號越相似。其數學模型為

基于字典學習的稀疏表示分類的判別方法為:每一個測試信號通過 4類字典稀疏重構,得到 4個重構信號,分別計算重構信號與當前測試信號的匹配度,得到匹配度最高的重構信號,其對應字典可以最好地重構當前測試信號,隨即判定當前測試信號類別與對應字典類別相同。
3 基于字典學習的稀疏表示分類方法在主動聲吶目標分類中的應用
在消聲水池中,利用主動聲吶發射脈沖信號,接收4類目標的回波信號。為了產生不同信噪比的回波信號,將原始回波信號加入高斯噪聲,形成信噪比分別為-5、-3、0、3、6 dB的弱信號,然后采用本文提出的DLSRC方法對其進行水下弱目標分類。對信號進行短時傅里葉變換,提取頻域信號作為特征與支持向量機(SVM)、K-最近鄰(KNN)和柔性最大值(Softmax)分類器結合作為對比方法。
3.1 實測目標回波信號
測試條件:入射信號為線性調頻信號、頻率范圍為100~200 kHz、脈寬為0.5 ms。
測試目標:包括空心鋁管、實心 PVC管、實心鋁圓柱和加肋圓柱殼體4類形似小型目標。這4類目標的原始回波信號如圖5所示。
圖5 4類目標原始回波信號Fig.5 The original echo signals of four types of targets
3.2 基于DLSRC方法的主動聲吶目標分類和對比分析
本文的DLSRC分類方法的核心是由實測信號訓練學習的字典。這實質上是對龐大數據集的降維表示,使得字典保留了目標的大部分特征,當測試樣本集過大時,當前學習字典無法表示的特征會更多,出現的分類錯誤率也會相應增大。學習字典稀疏表示測試樣本的過程則是利用計算殘差與字典原子最大內積的方法,找到最適合表示當前測試信號的有限原子,再由這些有限原子得到含噪信號的近似(更接近于目標的無噪信號),可以有效地去除大部分噪聲,降低信號中噪聲對分類結果的影響,提高對低信噪比信號的分類準確率。
對此,從三個角度測試說明DLSRC方法分類性能。在不同測試樣本數和不同信噪比的情況下,分析測試樣本數和信噪比對本方法的影響,在信噪比分別為-5、-3、0、3、6 dB時對比DLSRC方法與其他分類方法的準確率,分析本方法的優勢。
3.2.1 不同測試集樣本數時DLSRC方法的準確率
固定訓練集樣本數,分別使用120、200和400個測試信號下測試DLSRC方法的準確率,說明測試信號數量對分類器的影響。結果如圖6~7所示。
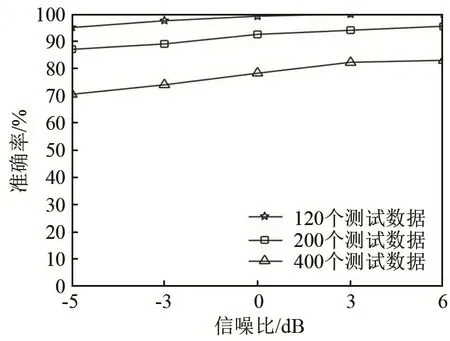
圖6 不同樣本數的測試集分類準確率對比Fig.6 Comparison of classification accuracy of test sets with different sample numbers
由圖6可知,在120個測試信號、信噪比大于3 dB情況下,分類準確率達到 100%。由此可見DLSRC分類方法受測試集樣本數量影響較大,信噪比不變時,測試集樣本數越少,分類準確率越高。說明本方法對小樣本分類效果較好;反之,在測試樣本集過大時效果欠佳,為了得到更高的分類準確率,可以對字典學習算法進行改進。
3.2.2 不同信噪比時DLSRC方法的準確率
固定訓練集樣本數和測試集樣本數,在信噪比分別為-5、-3、0、3、6 dB時對比DLSRC方法的準確率,說明不同信噪比對分類方法的影響。結果如圖7所示。
由圖7可知,在相同測試集樣本數、不同信噪比時,DLSRC方法的分類準確率結果較為接近,驗證了該方法中稀疏表示重構的去噪能力,使得該方法受信噪比的影響較小。
3.2.3 DLSRC方法與其他分類方法分類準確率對比
在200個測試樣本數下,信噪比分別為-5、-3、0、3、6 dB時,DLSRC 方法的準確率與其他分類方法進行對比。對比采用頻域信號結合支持向量機(SVM)、K-最近鄰(KNN)和柔性最大值(SoftMax)分類器的方法。其中SoftMax分類器是Logistic回歸推廣到多類分類的形式,常用于神經網絡分類中,具有良好的分類效果。結果如圖8~9所示。

圖7 不同信噪比時DLSRC法的分類準確率Fig.7 Classification accuracy of DLSRC method under different SNR
由圖8~9可知,與其他3種分類方法相比,DLSRC方法的優勢在于不同信噪比情況下的分類準確率較為穩定,且在低信噪比時可以達到較高的準確率。由圖8可知,SVM受信噪比影響較大,不適合對低信噪比信號進行分類;由圖9可以看出,對比受信噪比影響較小的KNN和SoftMax分類方法,DLSRC方法在各個信噪比下的準確率均較高,具有更好的分類效果。對比結果驗證了DLSRC方法分類準確率較高,且在低信噪比信號下也可以達到較好的分類效果,具有良好的分類性能和抗噪性能。
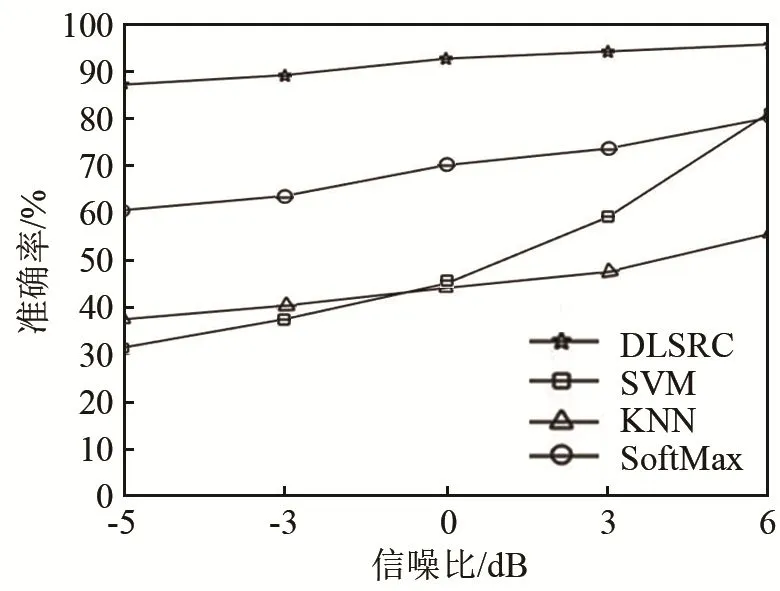
圖8 不同信噪比下4種不同分類方法的對比圖Fig.8 Comparison of four different classification methods under different SNR
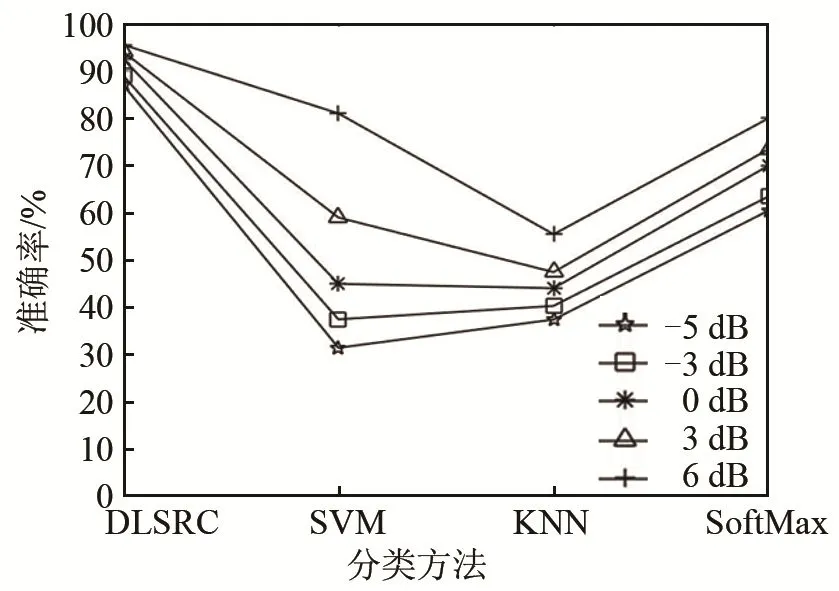
圖9 4種不同方法的分類準確率對比Fig.9 Comparison of classification accuracy of four different methods
4 結 論
本文針對主動聲吶目標分類問題,基于稀疏表示理論和字典學習,提出了基于學習字典的稀疏表示分類方法(DLSRC)。實現了4類低信噪比的主動聲吶弱目標的分類,并與SVM、KNN和SoftMax方法進行了對比分析。
結果表明,DLSRC分類方法更適用于小樣本分類,在測試集樣本數過大時準確率降低,且本方法受信噪比的影響較小,說明對于低信噪比弱信號的處理能力較好。由DLSRC分類方法與其他分類方法的對比結果可知,DLSRC分類方法在不同信噪比時相對其他3種方法具有更好的分類準確率。綜上,DLSRC分類方法在小樣本和低信噪比信號分類時具有良好性能,但對于大樣本分類效果欠佳。初步分析,其原因在于 K-SVD字典學習算法不適用于處理大樣本數據。為解決這一問題,今后需要在 K-SVD字典學習算法基礎上加以改進,研究如何提高類別字典的信號表示能力。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年11期)2018-08-04 03:25:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
