面向知識遷移的跨領域推薦算法研究進展*
2020-11-15 11:09:56劉柏嵩孫金楊
計算機與生活 2020年11期
任 豪,劉柏嵩,孫金楊
寧波大學 信息科學與工程學院,浙江 寧波 315211
1 引言
隨著網(wǎng)絡信息化時代的到來,各類信息呈指數(shù)性增長,出現(xiàn)嚴重“信息過載”問題。如何從海量數(shù)據(jù)中按需高速獲取有效信息成為亟需解決的問題,各類推薦算法應運而生。傳統(tǒng)的推薦算法包括基于內容的推薦[1-3]、基于協(xié)同過濾的推薦[4-7]和基于混合方法的推薦[8-11]三種,其中基于協(xié)同過濾的推薦應用廣泛,推動了電商領域的發(fā)展。
近幾年推薦系統(tǒng)在學術界和工業(yè)界大熱,推薦算法在不同的場景下發(fā)揮著重要作用。然而,數(shù)據(jù)稀疏問題和冷啟動問題已然成為制約推薦系統(tǒng)進一步發(fā)展的重要瓶頸。遷移學習作為機器學習方法的補充和擴展,利用已有的來自不同領域的與當前任務相關的數(shù)據(jù)來幫助解決目標領域中標簽數(shù)據(jù)稀少或者無標簽數(shù)據(jù)問題,旨在從和目標域相似或相關的源域中遷移合適的領域知識,輔助解決目標域任務,已在圖像處理、自然語言處理領域得到運用。近年來,遷移學習被用來解決推薦中的數(shù)據(jù)稀疏[12]和冷啟動[13-14]問題,這類推薦算法統(tǒng)稱為跨領域推薦算法(cross-domain recommendation)[15-16]。
2 跨域推薦概念及其技術
2.1 相關定義
不同任務中域的劃分不盡相同,目前在推薦任務中域尚未有統(tǒng)一的劃分標準。目前取得較為廣泛認同的推薦中的域的定義為:具有某個特定推薦系統(tǒng)中所需的某些共享屬性的項目集合構成一個域,其中共享屬性可以是文本屬性、評分、標簽、類別等[17-18]。本文中的域遵從此定義。
跨領域推薦是將不同領域的知識和信息融合,通過發(fā)現(xiàn)并利用輔助數(shù)據(jù)域中的可遷移知識來提高目標域的推薦性能,從而做出更加綜合全面的推薦。其中,跨領域推薦任務定義如下:
定義1(跨領域推薦任務)設UA和UB分別是域A和域B中的兩個具有某種特征(用戶偏好)的用戶集合,IA和IB分別是域A和域B中的兩個具有某種特征(商品屬性)的項目集合,則兩種不同的跨域推薦任務可以歸納如下:
(1)利用源域A中用戶和項目信息提高目標域B中的項目的推薦質量;
(2)將來自兩個不同域中的項目進行聯(lián)合推薦。
文中跨領域推薦任務均指第一種情況。
2.2 遷移學習技術及其分類
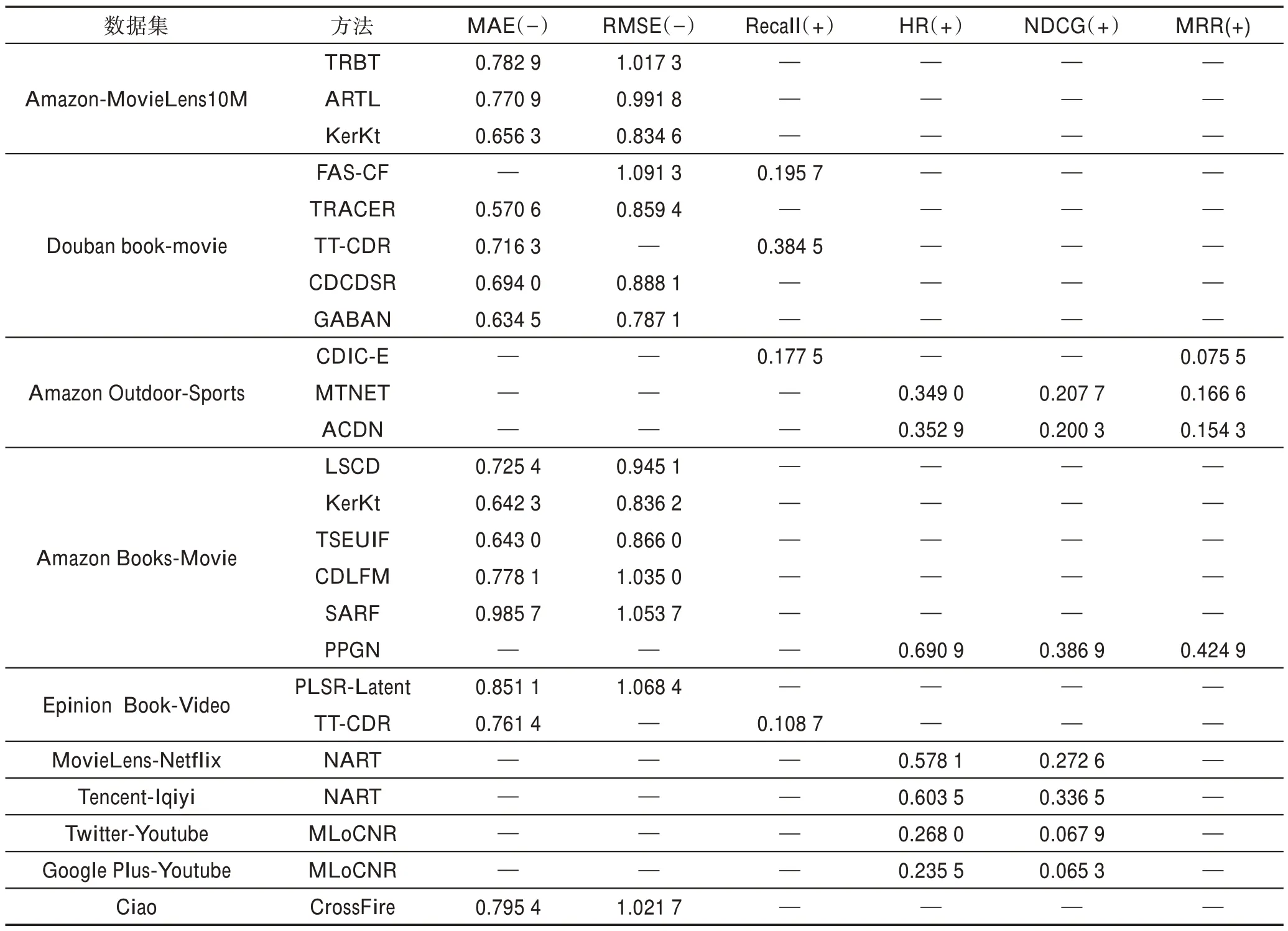
定義2(遷移學習(transfer learning))給定源域Ds以及源任務Ts,目標域Dt和目標任務Tt,當Ds≠Dt或者Ts≠Tt時,利用Ds和Ts中學習到的fs(?)來提高目標預測函數(shù)ft(?)的預測準確性,則遷移學習任務可表示為 合理應用遷移學習可作為傳統(tǒng)機器學習算法的補充,解決其無法解決的問題,傳統(tǒng)機器學習和遷移學習從域和任務兩個角度的對比如表1 所示。但如何避免“負遷移”是應用遷移學習時不可避免的問題。有效避免“負遷移”需考慮兩個問題:“遷移什么”以及“如何遷移”。從“遷移什么”層面上看,Pan等[19]將遷移學習分為四類,即基于實例的遷移學習、基于特征表示的遷移學習、基于參數(shù)的遷移學習和基于知識關系的遷移學習。而在“如何遷移”層面上,不同任務場景中有不同的遷移方法,接下來將以跨領域推薦場景為例重點闡述如何展開有效知識遷移。 Table 1 Comparisons between machine learning and transfer learning表1 傳統(tǒng)的機器學習和遷移學習的比較 類似于遷移學習,深度遷移學習同樣需要考慮“負遷移”問題。顯然,在深度遷移學習中需要遷移的是那些含有更多有用信息的、可在不同域間共享的、有利于目標任務解決的非線性特征;而從“如何遷移”角度,文獻[20]給出一種深度遷移學習的分類方法,其描述見表2,后文中關于深度跨域推薦算法的分類沿用此分類方法。 Table 2 Classification of deep transfer learning表2 深度遷移學習的分類方法 傳統(tǒng)跨域推薦,即基于遷移學習的跨領域推薦算法,通過建立輔助域和目標域間知識遷移橋梁,借助矩陣分解、因子分解、張量分解等方法提取出合適的領域知識,將其遷移到目標域中輔助解決目標任務,提高目標任務的性能。不同推薦場景中,知識遷移方法不同,主要包括評分模式共享、隱含特征映射/轉換和域關聯(lián)三種。 評分模式,又稱“密碼本”,是由輔助域數(shù)據(jù)壓縮而成的富含信息的聚類級的評分矩陣,常用于輔助域和目標域的用戶項目不重疊時建模用戶簇對于項目簇的隱含行為偏好,通過將用戶-項目交互矩陣“共聚類”提取“密碼本”,重構目標評分矩陣補全缺數(shù)數(shù)據(jù),實現(xiàn)數(shù)據(jù)稀疏條件下的跨域推薦。如ACTL(adaptive codebook transfer learning)[21]以矩陣分解作為基本模型,動態(tài)調整提取密碼本的規(guī)模以提高算法性能;LSCD(low-rank and sparse cross-domain)[22]加入低秩約束解決基于稀疏評分矩陣的跨域推薦問題;CD-MDTF(cross domain multi-dimension tensor factorization)[23]以多維度的張量分解替代矩陣分解,考慮用戶-項目交互情況的同時考慮時間因子對推薦結果的影響。 以上方法均是從單個輔助域的評分數(shù)據(jù)中遷移領域知識,雖可初步解決推薦中數(shù)據(jù)稀疏問題,但是單個輔助域中的可遷移信息有限,易發(fā)生過擬合且無法保證知識的有效正遷移。近年來從多個輔助域中提取“密碼本”的方式得到重視。MINDTL(multiple incomplete domains transfer learning)[24]從多個相關的非完全稠密域的評分中提取評分模式,并以此預測目標評分矩陣,其中評分矩陣的近似估計方法如下: 式中,Bn表示從第n個輔助域中提取的“密碼本”,Utgt和Vtgt分別表示從目標域的評分矩陣分解得到的非負用戶項目矩陣,W是掩碼,用于控制待預測的評分矩陣的規(guī)模。該算法的不足在于要求引入的多個輔助域數(shù)據(jù)相互關聯(lián)。Zhuang 等[25]放寬了引入輔助域時的數(shù)據(jù)相關性約束,提出TRACER(transfer collaborative filtering framework from multiple sources via consensus regularization),對多個輔助域評分數(shù)據(jù)聯(lián)合因子分解,通過加入一致正則項實現(xiàn)各輔助域中“密碼本”的相似性約束。該方法只強調了域間的共有特性而忽略了域間特有信息,導致推薦效果不理想。Jiang 等[26]考慮了域間特有信息的重要性,提出基于低秩系數(shù)分解的方法DLSCF(deep low-rank sparse collective factorization)。該方法分別從多個輔助域中提取共享評分模式和特有評分模式,再利用分層模型得到隱含因子和隱含子類之間的從屬關系,通過域間隱含因子類間關系約束保證知識的正遷移以實現(xiàn)數(shù)據(jù)異構場景下的跨域推薦。 將單個輔助域拓展到多個輔助域增加可遷移信息能夠提高算法性能,但僅利用輔助域的評分信息增大了數(shù)據(jù)引入的代價卻未充分利用其他可用輔助信息,降低數(shù)據(jù)的利用率。于是,充分挖掘輔助域中知識關系成為了增加正遷移的另一種解決辦法。王俊等[27]提出基于共享模式、隱含因子和連接圖三元橋式的TRBT(triple-bridge transfer)模型,考慮域間特有信息以解決正遷移不足的問題,模型框架如圖1 所示。其目標函數(shù)如下: 其中,Z是評分矩陣R的指示矩陣,當R中有評分缺失時Z的取值是0,反之則為1。V0、U0分別表示用戶和項目的可遷移特征,S表示通過連接圖挖掘的用戶/項目的可遷移的興趣模式信息,B是輔助域和目標域中的共享信息,B′則是域間特有信息,將跨域遷移信息分成[B,B′]可保留領域間共有信息,同時能夠很好地反映領域的相關性。GU=tr(UTLUU),LU=DU-WU,其中LU是拉普拉斯矩陣,WU是用戶i和用戶j余弦相似度矩陣,DU是由WU的行元素之和生成的一個對角矩陣,GV的計算方法類似。GU和GV的引入,強調了共享評分對于項目或者用戶的不同側重,增加了模式遷移的多樣性。SKP(sharing knowledge pattern)[28]則將用戶屬性信息加入推薦過程以解決跨域正遷移不足問題。引入其他可用的輔助信息增加可用的數(shù)據(jù)量可緩解數(shù)據(jù)稀疏帶來的影響,但在輔助域數(shù)據(jù)和目標域數(shù)據(jù)存在不一致性或者沒有明顯關聯(lián)的情況下,該類方法反而會加重“負遷移”。 Fig.1 Model of TRBT圖1 TRBT 模型圖 隱含因子(latent factor)是常用的域間用戶行為和項目屬性的稠密表示,用于實現(xiàn)用戶偏好和項目屬性之間匹配,在域間數(shù)據(jù)沒有明確關聯(lián)但共享隱含空間時作用效果極佳。基于隱含特征映射/轉換的跨域推薦方法通過一定的特征映射/轉換,將源域數(shù)據(jù)和目標域數(shù)據(jù)映射到相同的特征空間,從而建立域間關聯(lián)并以此作為域間知識遷移的橋梁,解決不同領域的用戶行為的異構問題。 Zhang 等將域間域內的實體對應關系加入矩陣分解過程中,提出基于核誘導的知識遷移的跨域推薦算法KerKT(kernel-induced knowledge transfer)[29]。利用領域自適應調整重疊實體的特征空間,基于擴散核補全法[30]將兩個領域間的不重疊的實體進行關聯(lián),通過重疊實體實現(xiàn)知識有效轉移,從而緩解數(shù)據(jù)稀疏性問題。實驗表明,本算法在不同的場景下可將預測的精準性提高1.13%至20%不等,同時實驗結果亦證明了即便在域間僅有較小重疊度的情況下,領域知識的跨域遷移也是可行的,但該方法僅適用域間實體有重疊的情況。SCT(semantic correlation in tagging systems)[31]則利用跨域標簽間的語義關聯(lián)跨域對齊用戶和項目的特征表示,識別域間相似的用戶和項目,實現(xiàn)數(shù)據(jù)稀疏條件下的跨域推薦。該方法放寬了需實體重疊的適用條件,但其能否準確識別領域間相似用戶和相似項目直接影響推薦效果,適用范圍受限。 文獻[32]提出的CDLFM(cross domain collaborative filtering algorithm based on a linear decomposition model)考慮到用戶在評分行為上的相似關系,將用戶相似度融入到矩陣分解中,同時為了在稀疏域中全面刻畫用戶偏好,作者提出從用戶不感興趣點、評分差異性及評分行為相似性三個維度計算用戶相似度。為實現(xiàn)跨領域的知識遷移,文中提出基于領域的梯度增強樹(gradient Boosting trees,GBT)方法學習特定用戶的高階特征映射函數(shù)來對齊用戶隱含特征。具體來說,每一個冷啟動用戶u∈UT都可以在源域中找到與之具有相似評分行為的鏈接用戶v并以此為遷移橋梁,利用用戶v在源域和目標域中的潛在特征對計算出域間的特征的映射關系,其中f(x)按式(3)完成第m次梯度增強: 根據(jù)用戶u在源域中的潛在特征和特征映射函數(shù)按式(4)~式(6)得到項目的預測評分: 其中,hm(x;αm)為參數(shù)化函數(shù),ηm為學習率,λ是防止過擬合的衰減參數(shù),Vt是目標域中的項目的隱含特征表示。盡管文章中提出了三種不同的計算用戶相似度的方法,但其算法性能受到單一跨域知識遷移模式約束。隨后,吳彥文等[33]提出采用聯(lián)合用戶側重和項目側重的多元知識遷移模式預測目標域評分實現(xiàn)數(shù)據(jù)稀疏條件下的跨域推薦。更有一些學者借助隱含特征映射/轉換基本思想創(chuàng)造性地將跨域推薦問題轉化成分類問題[34]、回歸問題[35-36]等,用常見的機器學習算法加以解決,為跨域推薦提供了新的求解思路。 域間關聯(lián)是目前傳統(tǒng)跨領域推薦算法中常見的另一個重要的方法。該類算法通過利用額外輔助域中除隱含特征和評分信息以外的其他外部信息建立域間知識遷移的橋梁,增加跨領域推薦的準確性和合理性,同時增加輔助域數(shù)據(jù)的利用率。常用的域間關聯(lián)信息包括物品標簽及其語義關系、用戶社交信任關系、域間關聯(lián)規(guī)則等。ITTCF(item-based tag transfer collaborative filtering)[37]摒棄了大部分跨域推薦算法中僅從用戶評分模式中挖掘可遷移知識的單一輔助方式,將用戶的行為反饋(即標簽)和數(shù)值型的評分信息相結合,通過層次標簽聚類、主題偏好遷移多種方式解決跨域推薦問題。Ma 等[38]則將評分數(shù)據(jù)與用戶社會信任關系結合融入到推薦中來,提出了跨領域信任感知推薦模型TT-CDR(transitive trustaware cross-domain recommendation)。依據(jù)用戶間的社交關系為每個領域單獨建立一個基于上下文感知的信任關系傳遞網(wǎng)絡,并在此基礎上利用基于信任關系傳遞感知的概率分解模型挖掘用戶間的社會信任,建模用戶間的間接信任關系,最后利用非線性用戶特征向量的映射連接不同領域的用戶反饋,實現(xiàn)跨域項目預測。由于無法自動挖掘社交信任關系而需要給定先驗的用戶間信任關系,因此該方法不適用于關系動態(tài)變化的情況。UP-CDRSs(user profile as a bridge in cross-domain recommender systems)[39]則自動計算用戶信任關系并以此作為域間關聯(lián)橋梁,通過最大化后驗概率學習用戶和物品的隱含因子,將二者的點積結果對未評級物品做出評分預測以實現(xiàn)跨領域推薦。類似的方法還有CDIE-C(cross-domain item embedding method based on co-clustering)[40]、FAS-CF(fusion auxiliary similarity collaborative filtering)[41]等。 除了直接利用跨領域數(shù)據(jù)間的直接關聯(lián)外,從領域數(shù)據(jù)中挖掘跨域間接關聯(lián)也是解決跨域推薦問題的新的方法。考慮到用戶社會關系和行為偏好間互惠關系,Shu 等提出了CrossFire(cross media joint friend and item recommendation)[42],利用平臺間用戶-用戶相關性以及平臺內用戶-項目交互關系挖掘不同平臺間的領域關聯(lián)特征,融合跨媒體信息解決跨媒體推薦中兩媒體不能直接鏈接問題。圖2 是CrossFire 算法框架。通過基于項目的稀疏遷移學習、跨媒體的評分行為遷移學習和跨媒體的社交關系遷移學習三方面的計算提取跨域共享特征實現(xiàn)項目和朋友的聯(lián)合推薦。在項目的稀疏遷移學習部分將給定的項目特征矩陣Xi近似分解為DVi,其中D是從源域和目標域中提取的共享特征矩陣,用于跨域知識遷移;同時為了滿足項目特征的幾何位置描述以及跨域項目特征的統(tǒng)一編碼約束依GraphSC(graph regularized sparse coding)[43]和MMD(maximum mean discrepancy)[44]思想加入正則項,按式(7)方式得到項目的稀疏表示Vi,i=1,2,…,p: Fig.2 Frame of CrossFire圖2 CrossFire 模型框架 再將項目的稀疏表示通過映射矩陣Q的作用得到項目的隱含特征表示,完成跨媒體的評分行為遷移學習。類似的,引入用戶-項目共享交互矩陣P建模用戶在不同社交媒體上的共享隱含特征,構建跨媒體用戶關聯(lián),實現(xiàn)跨媒體朋友推薦。該算法較好地利用社交網(wǎng)絡實現(xiàn)推薦問題,但由于領域間沒有直接關聯(lián)造成領域特征表示存在語義偏差,推薦的精準性有待提高。 獲取可遷移特征的質量逐漸成為影響跨域推薦性能進一步提高的重要因素,加之可利用輔助數(shù)據(jù)的異構性,傳統(tǒng)跨域推薦算法僅利用從評分數(shù)據(jù)中提取線性特征來實現(xiàn)推薦的局限性顯現(xiàn),推薦結果不能滿足實際要求。于是,研究者們開始將目光轉向深度遷移學習,試圖用深度學習方法解決跨領域推薦問題。現(xiàn)有的深度跨域推薦算法按照深度遷移學習技術的不同可分為基于特征映射、基于網(wǎng)絡/實例、基于對抗遷移三大類。 該類算法借助于深度學習方法將不同領域的特征向量映射到相同的特征空間,在新的特征空間中對齊不同域的用戶/項目向量表示,消除因特征非對齊對推薦結果的影響,解決跨域推薦問題。Zhu 等[45]提出一種基于遷移學習的隱含因子跨域映射模型,在矩陣分解的基礎上利用深度神經(jīng)網(wǎng)絡映射跨領域特征,同時將不同領域間用戶和項目的評分稀疏度引入,作為一種網(wǎng)絡訓練的指示因子,提高評分數(shù)據(jù)的利用率。該算法保留了矩陣分解較好的解釋性又注重非線性特征的提取,但未考慮域間數(shù)據(jù)特征不一致性的影響。為此,Gao 等[46]提出了僅需項目側輔助信息的神經(jīng)注意力跨域推薦算法NATR(neural attentive transfer recommendation),引入維度適應單元解決跨域數(shù)據(jù)不一致性問題,其網(wǎng)絡結構如圖3。其中,遷移增強嵌入層以隱因子模型(latent factor model,LFM)作為基準模型,將實值的用戶與項目的稀疏向量分別映射成稠密向量,結合維度適應單元解決項目向量遷移過程中不同領域內向量表示的維數(shù)偏差問題;項目級注意力層和域級注意力層則充分利用注意力機制強區(qū)分性,分別在構建用戶表示時區(qū)分不同項目的重要度和在跨域遷移過程中動態(tài)調整領域知識對推薦結果的影響因子;結果預測層將求得的用戶偏好特征向量與項目特征向量進行點積操作計算預測評分以實現(xiàn)跨領域推薦。SARFM(sentimentaware review feature mapping framework)[47]通過用戶評論中的情感感知實現(xiàn)不同領域的文本特征對齊,解決跨域情感偏差問題。SSCDR(CDR framework based on semi-supervised mapping)[48]則以重疊用戶作為錨點,通過半監(jiān)督學習、k近鄰聚類等方法計算冷啟動用戶的偏好特征實現(xiàn)跨領域推薦。該方法雖能解決新用戶的推薦問題,但由于其要求兩個域有重疊的用戶,固無法解決新系統(tǒng)的冷啟動問題。 Fig.3 Model of NATR圖3 NATR 模型 基于特征映射的深度跨域推薦算法主要依據(jù)的數(shù)據(jù)大部分依舊是評分數(shù)據(jù),輔助數(shù)據(jù)的使用不多,算法性能受到數(shù)據(jù)稀疏性影響依舊明顯。 不同于傳統(tǒng)意義上的基于網(wǎng)絡的遷移學習保留預訓練網(wǎng)絡中一部分結果或模型參數(shù)直接應用目標任務,在跨域推薦場景下的基于網(wǎng)絡的深度遷移學習則是對已有網(wǎng)絡進行整體改進,組合重構新的網(wǎng)絡模型,常見的網(wǎng)絡改進方法有兩種:(1)保留原始網(wǎng)絡基本結構,增加某些層或者改變某些層以構成新網(wǎng)絡;(2)以固有的某些網(wǎng)絡結構作為整體模型的一部分,經(jīng)拼接重組組成新的網(wǎng)絡。He等[49]利用第一種網(wǎng)絡遷移方法改進MVDNN(multi-view deep neural network)[50]模型提出GCBAN(general cross-domain framework via Bayesian neural network),其網(wǎng)絡模型如圖4 所示。該算法考慮到域間用戶和項目的協(xié)同關系在推薦中的作用,以用戶向量和項目向量的交互結果替代MVDNN 網(wǎng)絡中用戶/項目的原始特征編碼作為全連接層的輸入;除此之外,考慮到以定值作為權重無法表示網(wǎng)絡的不確定性,GCBAN 以貝葉斯后驗概率替代點估計,有效避免數(shù)據(jù)稀疏時的“過擬合”問題。值得一提的是,本方法中除了利用評分信息以外,還引入用戶和項目的屬性信息提升推薦效果。而MTNet(memory&transfer network)[51]則采 用第二類模型改進方法將記憶網(wǎng)絡和遷移網(wǎng)絡兩個網(wǎng)絡拼接,以記憶網(wǎng)絡提取最有用的特征,以遷移網(wǎng)絡選擇可遷移的知識,最后通過特征共享交互層耦合兩個獨立網(wǎng)絡,實現(xiàn)基于非結構性文本信息的跨域推薦。要求源域和目標域的用戶完全重疊限制了該算法模型的適用性。類似方法,文獻[52]以LSTM(long short-term memory)作為基礎模型進行多層堆疊共同建模用戶行為,捕獲高階用戶-項目交互關系,同時在模型中加入注意力機制以及時間感知因子實現(xiàn)跨網(wǎng)絡的在線推薦問題;考慮到LSTM 只能從左到右或者從右到左單向建模,而圖神經(jīng)網(wǎng)絡則可有效地建模信息間的復雜高階關系,Zhao 等[53]提出以GNN(graph neural network)作為基礎模型的PPGN(preference propagation graphnet),通過構建用戶偏好傳播圖模型捕獲跨領域特征偏好的高階傳播關系,實現(xiàn)跨域推薦。 基于實例的深度遷移跨域推薦算法將不同域的特征加權重構,動態(tài)調整不同特征在目標網(wǎng)絡和輔助網(wǎng)絡中的地位,同樣采用現(xiàn)有網(wǎng)絡整體改進或重組的方式實現(xiàn),亦可看成是基于網(wǎng)絡的深度跨域推薦的一部分。Hu 等[54]利用NCF(neural collaborative filtering)[55]對復雜用戶-項目高維非線性交互關系的有效性提出CoNet(collaborative cross networks)。該模型以前饋神經(jīng)網(wǎng)絡作為基本網(wǎng)絡架構,由三個隱含層和兩個十字交叉單元共同組成,其中交叉連接單元是將CSN(cross-stitch networks)[56]中的實數(shù)權值用關系轉移矩陣替代的一種改進,用于動態(tài)調整不同特征空間的可遷移特征的權重,實現(xiàn)特征的雙向跨域遷移。該算法是目前關于深度跨域推薦算法模型性能比較中常見的基礎模型。Liu 等[57]則在CoNet的基礎上將事先由ILGNET[58]提取的項目的高級審美特征連同用戶和項目的隱含向量一并作為CSN 的輸入,提出新的跨域推薦算法ACDN(aesthetic preference cross-domain network),其網(wǎng)絡結構如圖5 所示。該模型中以圖片信息作為輔助信息,從多模態(tài)數(shù)據(jù)中提取有用數(shù)據(jù)以增強跨域推薦的性能。由于CoNet和ACDN 都需要以相同用戶作為跨域遷移的橋梁,而在實際中不同領域間完全共享用戶的可能性極低,且易造成用戶的隱私泄露問題,因此算法的適用性受限。 Fig.4 Model of GCBAN圖4 GCBAN 模型 Fig.5 Model of ACDN圖5 ACDN 模型 該類深度跨域推薦算法不再依賴于評分數(shù)據(jù),更多地關注于從反饋信息如文本信息、用戶行為序列信息中挖掘用戶的偏好,結合深度學習技術破除跨域推薦的數(shù)據(jù)稀疏性影響;但是,大部分算法是從某個用戶角度出發(fā)進行跨域推薦的,這對于冷啟動問題的解決產(chǎn)生一定的限制。 Goodfellow 等提出的GAN(generative adversarial networks)是對抗學習的代表方法之一,其核心結構由生成器G 和判別器D 組成,G 用于生成最接近真實數(shù)據(jù)的虛假數(shù)據(jù),D 則試圖完美區(qū)分真實數(shù)據(jù)和“逼真”的虛假數(shù)據(jù),通過D 和G 的博弈對抗達到兩者都可學習到最理想的輸出的效果。基于對抗的深度跨域推薦算法是將GAN 融入到跨領域推薦中解決跨域推薦中特征的領域適應問題。其中對抗學習的思想主要體現(xiàn)在三方面:(1)借鑒GAN 中最大-最小博弈的對抗式目標函數(shù)優(yōu)化模型參數(shù);(2)借鑒其生成模型-判別模型對抗式結構設計網(wǎng)絡模型;(3)對抗式網(wǎng)絡訓練。 Wang 等[59]提出第一個基于判別對抗網(wǎng)絡的跨域推薦算法RecSys-DAN(discriminative adversarial networks for CDR)以解決單模態(tài)和多模態(tài)下的數(shù)據(jù)稀疏和數(shù)據(jù)不平衡問題。不同于標準GAN 只有一組G和D,該算法在源域和目標域中分別設定一組生成器,在目標域中設定一個判別器D f,其中k∈{s,t} 代表{源域,目標域},i∈{u,v,f}代表{用戶,項目,用戶與項目的交互}。G 用于從已知的數(shù)據(jù)中完美地學習到各域內用戶和項目的隱含特征表示,D 則要學習一個映射函數(shù),使得盡可能多的目標域特征可由源域特征經(jīng)過映射近似表示,實現(xiàn)域間的特征的跨域對齊,為此和D f的學習函數(shù)設定如下: 特別的,在本算法中用戶和項目的交互即為用戶對項目的評分Y,;由于源域中已知評分情況,故源域的生成器G 以監(jiān)督學習方式得到相應的特征表示。Yuan 等[60]則將判別器-生成器結構作為基本框架提出一種基于深度域適應的跨領域推薦方法(deep domain adaptation cross-domain recommendation,DARec),模型結構如圖6 所示。兩個自動編碼器分別從源域和目標域的稀疏評分矩陣中提取用戶偏好特征,并以此作為交叉嵌入模塊的輸入,經(jīng)交叉嵌入模塊的作用將域間用戶偏好特征充分混合后輸入到對抗結構中,聯(lián)合完成評分模式提取、評分預測以及域分類,最終實現(xiàn)跨域評分預測。考慮到推薦場景不同會影響推薦結果的精準性,DiscoGAN[61]將時間和所處場景作為考量維度之一融入到GAN 中,以對抗訓練的方式學習場景特征向量,實現(xiàn)在不同時間場景下服裝的智能化推薦。 Fig.6 Model of U-DARec圖6 U-DARec 模型 基于對抗的深度跨領域推薦算法將對抗學習思想融入到了跨領域推薦中來,通過設定不同的生成器和判別器達到預測目標用戶的評分情況,算法的可解釋性有了一定的提升,但是由于GAN 固有局限性使得該類算法的穩(wěn)定性有待進一步研究。 傳統(tǒng)跨域推薦算法大都是采用兩段式學習方法,而深度跨域推薦算法由于其采用不同的深度學習技術,因此大多數(shù)算法模型是“端到端”的,實時性相對較高。兩大類算法解決問題的方法各有側重,傳統(tǒng)跨域推薦算法以矩陣分解或張量分解作為基準模型,可解釋性相對較高,評分信息利用較為充分,評分的準確性以及稀疏性對推薦結果的影響較大,忽略了非線性特征的提取和利用;深度跨領域推薦則將各種有效的深度學習方法應用到跨域推薦中,相交于傳統(tǒng)跨域推薦具有以下幾點優(yōu)勢:(1)可學習更多層次的非線性特征,而這些特征往往是低維的;(2)無需通過復雜的計算提取特征,可以借助于DNN(deep neural networks)、注意力機制、圖神經(jīng)網(wǎng)絡等方式實現(xiàn);(3)部分算法更加關注于高階復雜的用戶行為關系的抽取,更全面地表述用戶特征。 不同的知識遷移場景以及依賴數(shù)據(jù)類型會對算法的有效性產(chǎn)生影響。表3 和表4 從定性角度分別從遷移技術、依賴數(shù)據(jù)類型、基礎模型、算法適用性及重點解決問題幾個方面對傳統(tǒng)跨域推薦算法和深度推薦算法進行總結,并指出各類算法的優(yōu)缺點;同時,為增加算法間的宏觀可比性,增加各算法的定量分析,總結如表5,同時本文中對當前主流的跨領域推薦算法的評價指標進一步的總結如表6。 從表3 和表4 各類算法模型的依賴的數(shù)據(jù)類型角度來看,傳統(tǒng)跨域推薦算法以用戶對項目的評分為主,輔以添加部分用戶側屬性和項目側屬性信息,特別是基于評分模式和基于隱含特征映射兩類跨域推薦算法大部分都是以評分數(shù)據(jù)為基礎,利用矩陣分解或者張量分解為基本模型,目標域的數(shù)據(jù)的稀疏性對算法模型的性能影響較大;而深度跨域推薦算法則是重點從用戶項目側屬性信息以及用戶與項目的交互信息中挖掘用戶的興趣偏好,這也使得整個深度跨域推薦中領域間用戶的依賴程度較高。 與模型依賴數(shù)據(jù)直接相關的便是各類算法模型對用戶特征的描述能力。當前的跨域推薦算法主要通過以下幾個方法完成數(shù)據(jù)用戶特征的提取:(1)用戶與項目的交互信息、用戶間的社交關系等顯示反饋信息;(2)用戶側屬性信息和項目側的屬性信息等輔助顯示信息;(3)用戶的隱式反饋信息,如用戶的瀏覽序列。由于用戶顯示反饋信息以評分信息為主,該類信息具有線性性,基于矩陣分解的算法對該類數(shù)據(jù)的利用率較高,但是由于其固有條件的約束,這類算法只能挖掘用戶的線性特征,而實際情況下用戶的非線性特征偏好往往包含更多的可用信息,這也是深度跨域推薦算法產(chǎn)生的原因。從表4 總結可以看出,無論是基于隱含特征映射、基于網(wǎng)絡和實例的深度遷移還是基于對抗的深度遷移都主要依賴于隱式反饋信息提取用戶的非線性偏好,為全面提取非線性特征同時增加數(shù)據(jù)的利用率,ACDN 從圖片特征中提取用戶的高維審美偏好作為整體偏好特征的補充,SARFM 從評論文本中提取用戶的特征偏好。從整體上看,由于深度學習在非線性特征的學習上的優(yōu)越性使得深度跨域推薦算法在用戶特征的描述以及提取能力上明顯高于傳統(tǒng)的跨域推薦算法。 Table 3 Summary of traditional cross-domain recommendation algorithms表3 傳統(tǒng)跨領域推薦算法總結 Table 4 Summary of cross-domain recommendation algorithms with deep transfer learning表4 深度跨域推薦算法小結 Table 5 Comparison of experimental results of cross-domain recommendation algorithms表5 跨領域推薦算法實驗結果比較 Table 6 Summary on use of evaluation indices of main cross-domain recommendation algorithms表6 主要跨領域推薦算法評價指標使用總結 從模型的適用條件上看,傳統(tǒng)跨域推薦對域間用戶的重疊程度依賴性低,甚至可以在用戶和項目都完全無交集的情況下完成推薦,對用戶的隱私保護有一定的考慮,這使得傳統(tǒng)跨域推薦算法在現(xiàn)實條件下適用的范圍更廣,可方便實現(xiàn)跨系統(tǒng)推薦,甚至是跨媒體推薦;而深度跨域推薦則大都從某用戶的角度出發(fā),用戶信息的跨域共享成為了推薦的重要條件,但是當前的方法基本是一個ID 即為一個用戶,而“一人多賬號”和“多人共用一個賬號”問題較為常見,如何準確定位用戶問題有待進一步的研究。 從各類算法重點解決實際問題角度來看,傳統(tǒng)跨域推薦著重于數(shù)據(jù)稀疏問題的解決,少部分算法通過添加標簽關系、用戶社會關系等輔助信息在冷啟動的條件下發(fā)揮作用(如CD-MDTF、KerKT、CDLFM、CDIE-C 等);而深度跨域推薦算法除了數(shù)據(jù)稀疏和冷啟動問題以外,考慮解決現(xiàn)實推薦場景下的隱私保護、在線推薦和跨域推薦中的行為異構問題,這是因為深度學習技術對其輸入數(shù)據(jù)的約束性較小。 算法模型的可解釋性一直是推薦領域需要重點攻克的問題,跨領域推薦算法中亦然。由于傳統(tǒng)跨域推薦算法以矩陣分解為基礎模型,故此類算法主要通過概率矩陣分解角度增加其可解釋性(如UPCDRSs)、引入概率圖模型(如TRBT)和引入外部知識庫(如社交關系、標簽等)等方式提高推薦結果的可解釋性;深度跨領域推薦算法則依賴于各種不同的深度模型,總結如表4。類似于傳統(tǒng)跨域推薦算法,該類算法可從概率估計(如SSCDR、GCBAN 等)角度增加結果的可解釋性,部分算法通過注意力機制對不同的項目進行加權選擇以提取更加準確的用戶偏好,提高結果的可解釋性。除此之外,MTNet 引入記憶網(wǎng)絡提取用戶偏好特征的同時增加模型的可解釋性。但由于端到端模型中間結果的不可見性增加了結果可解釋的難度,更加有效的可解釋性方法需要進一步探究。 從表5 可以看出,同一模型在不同的跨域場景下表現(xiàn)出來較大的差異性,這是因為不同場景下數(shù)據(jù)稀疏性不同,加之可用的輔助信息利用程度不同,也對推薦結果產(chǎn)生影響。同時可以看出,在相同條件下,深度跨域推薦的性能相對較高;當可用的輔助信息較多的時候,性能會有所改善;從表6 中不同算法模型驗證實驗評價指標的對比可以看出,常用的評價指標可分為評分預測類(以MAE(mean absolute error)和RMSE(root mean squared error)為主)和排序加權類(NDCG(normalized discounted cumulative gain)、MRR(mean reciprocal rank)、HR(hit ratio)等)兩大類,主要用于衡量推薦的準確性。其中傳統(tǒng)跨域推薦算法更加傾向于使用評分預測類指標,這與其主要依賴的數(shù)據(jù)類型是評分有關,部分算法由于依賴數(shù)據(jù)的多樣性,同時采用預測類指標和排序類指標,試圖全面評價模型。但是不同場景下模型的有效性還有更多可以探索的方面,因此如何有效地全面地對各算法模型進行橫向的評價仍有待深入研究。 目前跨領域推薦算法作為解決推薦中的數(shù)據(jù)稀疏和冷啟動的有效解決方法得到學術界和工業(yè)界的足夠重視,是當前推薦領域的重點和熱點研究方向之一。綜合上一章的對比分析可看出,現(xiàn)有的跨領域推薦算法存在以下幾點不足:(1)算法的適用性有限;(2)推薦結果的可解釋性不佳;(3)數(shù)據(jù)本身挖掘不足,導致成本增加;(4)算法的評價指標單一。為此,本文總結以下幾點可能的研究方向: (1)新深度跨領域推薦算法 跨域推薦涉及不同的推薦對象以及推薦場景,無法建立統(tǒng)一的推薦模型,需要根據(jù)推薦對象、可用信息以及推薦場景考慮構建各有側重的推薦模型;再者,輔助信息來之不易,應當充分利用已獲得的輔助信息(如時序關系、地理位置等),但目前此類信息利用尚不充足,需要研究更多的新的深度跨域推薦算法解決上述問題。 (2)跨域推薦的可解釋性問題 跨域推薦算法除直接展現(xiàn)推薦結果外,還應適當給出推薦的理由,提升用戶對推薦結果的接受度。一直以來,推薦系統(tǒng)的可解釋性問題都是業(yè)界研究的重點和難點,對于跨域推薦亦然。傳統(tǒng)跨域推薦算法利用矩陣分解來增加可解釋性,但其限制性較大,推薦結果不能滿足實際要求;而在目前的深度跨域推薦中,已知的僅是輸入數(shù)據(jù)和輸出結果,其中間過程的不可見性降低結果的可解釋性,同時引入輔助域的合理性與否的可解釋性亦不足,需要考慮從更多方面入手提高跨域推薦的可解釋性。 (3)序列推薦與跨領域推薦相結合 一般來說,用戶的消費行為之間總是具有某種隱含的因果關聯(lián),用戶行為序列可有效建模此類關系,序列推薦算法可充分利用用戶行為序列信息。但是,單域序列推薦常常對歷史物品中選擇合適的物品給出下一項推薦候選而無法推薦全新的物品,跨領域推薦作為提高推薦多樣性和新穎性的方法可以有效地對單域序列推薦存在的問題進行補充,實現(xiàn)智能化的精準推薦。當前尚無此類研究。 (4)豐富跨領域推薦的評價指標 現(xiàn)有的跨領域推薦算法的評價指標沿用了傳統(tǒng)推薦中對評分預測正確率、準確率等指標,基本沒有涉及到新穎性、全面性和多樣性方面的評價,雖然可以初步達到衡量算法性能的目的,但是相較于傳統(tǒng)的推薦,跨領域推薦面臨的問題更復雜,解決問題更多樣,使用的數(shù)據(jù)集也不同,簡單的評價指標無法全面對跨域算法進行評價。因此,提出新的跨域推薦算法的評價指標是必然之勢。

3 傳統(tǒng)跨領域推薦算法
3.1 基于評分模式共享的跨域推薦算法



3.2 基于隱含特征映射/轉換的跨域推薦算法


3.3 基于域關聯(lián)的跨域推薦算法


4 深度跨域推薦算法
4.1 基于特征映射的深度跨域推薦算法

4.2 基于網(wǎng)絡/實例的深度跨域推薦算法


4.3 基于對抗的深度跨領域推薦算法


5 跨域推薦算法模型比較分析


6 研究趨勢與展望
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
