線上多節點日志流量異常檢測系統的研究*
2020-11-15 11:09:58王曉東趙一寧肖海力王小寧遲學斌
計算機與生活 2020年11期
王曉東,趙一寧,肖海力,王小寧,遲學斌
1.中國科學院 計算機網絡信息中心,北京 100190
2.中國科學院大學,北京 100049
1 引言
中國國家高性能計算環境是由國內眾多超算中心和高校的計算集群組成的國家級大型高性能計算環境,采用中國科學院計算機網絡信息中心自主研發的網格環境中間件SCE[1]聚合了大量的通用計算資源,為全國眾多高校和研究機構的用戶提供了優質的計算服務。環境中Linux 系統的syslog 服務會產生大量日志,用于記錄系統中發生的各類事件信息,這些信息包含各種潛在的異常情況,對其進行分析具有重要意義。由于環境中的每個節點都會產生大量的系統日志,這使得最終的日志文件變得極為龐大,直接采用人工觀察的方法處理這些日志顯然是一項不可能完成的任務,因此需要使用一些機器學習方法對環境中的日志進行檢測分析。
基于機器學習的檢測分析技術主要分為兩大類:誤用檢測和異常檢測[2]。誤用檢測屬于機器學習中的有監督算法,建模時需要人工將所有訓練樣本標記為“正常”和“異常”后才能進行學習訓練并更新模型參數。異常檢測屬于無監督學習算法。其主要思想是根據已知的大量數據建立模型基線,然后找到偏離模型基線的少量數據作為異常。大規模分布式環境中多節點產生的日志比較復雜,因為這些日志通常是開發人員為了開發方便而打印的一些原始想法,其中包括錯誤、跟蹤和程序內部狀態等信息,因此利用這些信息是非常困難的。同時這些信息都是非結構化的,不利于機器識別。此外,日志的數據量非常龐大,人工標注后再使用機器學習方法進行分析顯然是難以完成的任務,因此使用無監督的異常檢測方法較為合適。在先前的工作中已經初步實現了使用機器學習算法對環境中的日志流量進行檢測,然后針對異常日志流量進行聚類。然而該方法屬于離線算法,并且在異常結果分析時使用的聚類算法需要人工參與并設定聚類參數,而本文方法在建模時可以更加精細地自動化確定模型參數,并更進一步探索如何進行模型持久化以及如何進行線上檢測。
系統的整體流程除了設定少量閾值以及流量模式的定義需要人工參與外,得到異常日志流量模式的過程全自動化進行,并且在線上檢測時也能自動化得到異常結果并將其進行分類歸納,這樣使得系統管理員對系統日志流量的監控變得簡單。具體來說,本文有兩個貢獻點:
第一,實現了兩階段異常檢測的方法,包括線下模型自動化建立和線上實時結果分析。在線下模型建立的過程中無須人工參與即可找到流量異常情景。在線上分析時,可將結果實時自動化展示。整個處理過程對操作者的要求不高,進行檢測時不需要有機器學習的專業知識。
第二,在線下建模和線上預測時使用了國家高性能計算環境中產生的真實日志進行實驗,實驗結果證明了該方法顯著降低了人工分析的工作量。
2 相關研究
本章簡單討論一下日志模式分類、數據挖掘相關的日志分析以及在線日志分析的相關研究。
2.1 日志模式分類方法的相關研究
Vaarandi[3]在對日志文件數據進行模式分類時使用了一個名叫SLCT(simple logfile clustering tool)的聚類算法,該聚類算法是基于Apriori 頻繁項集的算法,因此需要使用者手動輸入調整支持閾值。之后,他又在文獻[4]中改進了日志的聚類算法,并取名為LogHound,該算法是一種基于廣度優先搜索的頻繁項集挖掘算法,可以從日志中挖掘頻繁模式。該算法結合了廣度優先和深度優先算法的特點,同時考慮了事件日志數據的特殊屬性,因此比SLCT 更接近地反映Apriori 算法。在此基礎上,Makanju 等人[5]引入了IPLoM(iterative partitioning log mining)算法,該算法是一種用于挖掘事件日志簇的新算法。與SLCT 不同,IPLoM 是一個層次聚類算法,它以整個事件日志作為分析起點,并在三個步驟中迭代分區。與SLCT 類似,IPLoM 將單行日志中的位置視為單詞匹配點,因此對單詞位置的移位操作敏感。基于層次聚類的特點,IPLoM 算法不需要提供支持閾值,而是需要其他一些參數(如分區值和簇優度值),這些參數對分區的劃分進行細粒度的控制。IPLoM相對于SLCT 的一個優點是能夠使用尾部通配符(例如Interface**)來檢測日志的行模式。而本文在處理日志模式分類時,考慮線上分析的實時性,匹配時需要快速得出結果,因此這里采用基于字符匹配的分類算法,之后針對國家高性能計算環境的系統日志進行分類,代碼壓縮率和后續特征創建都顯示出了不錯的效果。
2.2 數據挖掘技術相關的日志分析研究
一些學者在分析日志并尋找異常消息的領域進行了研究,比如Xu 等人[6]通過源代碼匹配日志的模式,找出相關變量,然后通過匹配日志模式,找到其中變量并使其作為主成分分析方法的輸入數據,最后根據主成分分析的最大可分性檢測異常的日志文件。Fronza 等人[7]使用隨機索引為代表的日志序列,根據每條日志中的操作提取特征,然后使用支持向量機關聯序列到故障或無故障的類別上,以此來預測系統故障。Weiss 等人[8]研究了從有標簽特征的事件序列中預測稀少事件的問題,他們使用了基于遺傳算法的機器學習系統,能夠在預測稀有任務上達到比較好的結果。Yamanishi 和Maruyama[9]提出了一種新的動態系統日志挖掘方法,以更高的置信度檢測系統故障,并發現計算機設備間的連續報警模式。Yuan 等人[10]提出了一個名為Sher-Log 的工具,它利用運行時日志提供的信息來分析源代碼,以推斷在失敗的生產運行期間必須或可能發生的事情,它不需要重新執行程序,也不需要知道日志的語義即可推斷關于執行失敗的控制和數據值信息。Peng等人[11]應用文本挖掘技術將日志文件中的消息分類為常見情況,通過考慮日志消息的時間特性來提高分類準確性,并利用可視化工具來評估和驗證用于系統管理有趣的時間模式。本文中使用Xu 等人[6]描述的異常檢測方法,但是輸入的日志類別是通過字符匹配得到的,同時研究對象為日志類型的有序排列,在得到未知的異常日志流量模式上更有優勢。
2.3 在線日志分析的相關研究
典型的在線日志分析程序通常基于控制臺日志或者安全審計日志等進行分析。比如文獻[12-13]中進行的在線日志分析研究程序,它們通過手動輸入如正則表達式這樣的規則來匹配待分析日志中的對應字符串,通過這種方式就可以找到需要關注的日志條目。然而這種手動輸入規則的方式,處于線上運行時,可能會經常更新軟件或者模型基線,這樣會使得每當需要更新的時候,都需要人工重新編輯規則匹配新出現的日志條目。而本文在日志分析處理的整個流程中,完全使用無監督的方法建立日志模式庫和異常模式庫,線上分析時采用間隔一段時間就自動更新模型的方式進行診斷,這樣可以保證模型具有時效性。同樣的,日志模式匹配時也不需要人工參與編寫任何規則。
3 兩階段線上異常檢測方法
3.1 線下數據處理
本節回顧了日志預處理的步驟并重點分析模型建立時需要持久化的數據,這些數據是線上分析時的基礎。整個線下數據處理過程分為:預處理、異常檢測模型的建立與異常流量序列聚類、日志流量模型的建立三部分,下面分別詳細介紹。
3.1.1 日志數據預處理
Syslog 系統日志屬于非結構化數據,為了后續使用各種機器學習方法進行分析,必須要將這些數據轉換成可以進行處理的結構化數據,在實踐中,需要將日志進行分類,即每一條日志都可以確定成唯一的一種類型,這就要求能得到一個日志倉庫,里面存儲所有已知的日志類型。生成日志倉庫的核心是如何判定兩條日志是否屬于同一類型。判定日志類型時,為了使判定過程實時快速,Zhao 等人[14]提出了字符匹配法來確定兩條日志的相似度,并且在文獻[15]中改進了該算法。算法將日志中的每一個單詞作為一個基本單元,然后對其進行匹配,并基于最長公共子序列得到匹配的單詞數目,最后與兩條日志的總單詞數進行比較來計算相似度。具體來說,假設待匹配的兩條日志分別為l′和l,其包含的單詞數量分別為m和n,則兩條日志的相似度的計算公式如下:

其中,|LCS(l,l′)|代表兩條日志最長公共子序列匹配的單詞數。比如以下三條日志:
l1:Received disconnect from IP1
l2:Received disconnect from IP2
l3:Accepted publickey for User1 from IP3
設閾值為0.5,其中l1 和l2 這兩條日志的前三個字符相匹配,后一個字符不匹配,因此根據式(1),可以計算得到S()l1,l2=3×2/(4+4)=0.8 >0.5,說明l1、l2 為同一種類型的日志,同理可以計算出l1 和l3 這兩條日志的相似度S(l1,l3)=0 <0.5,說明l1、l3 為不同類型的日志。
在實踐中,遍歷所有線下日志,然后和日志倉庫中的每條日志進行相似度計算,如果得到的相似度大于給定閾值,則認為日志倉庫中已存在該類型的日志并進行下一條日志的比較,否則將這條日志加入到日志類型倉庫。為了進行線上模型預測,將這一步算法完成后得到的日志類型倉庫保存下來,并記作Pattern。
得到日志類型倉庫后,即可進行日志數據的預處理工作。實際操作時,將日志流量的監控確定在一個固定的時段內,因此輸入到異常檢測模型中的基本數據單元是以時間片進行切分的,將單個時間片內順序出現的所有日志稱作“日志流量序列”。將流量序列中的每條日志和日志倉庫中的日志類型進行匹配,可以得到一條以日志類型為屬性的向量,向量的每一個位置的數值代表該條流量序列中對應類型日志出現的次數。該日志流量序列向量組生成后即完成了預處理步驟。整個日志預處理流程如圖1所示,圖中右下角的表格即預處理步驟完成后輸出的數據表。
3.1.2 線下異常檢測模型的建立與異常流量序列聚類
主成分分析(principal component analysis,PCA)是一種常用的機器學習算法,該算法可以自動找到數據的比例中心,該中心代表數據的正常空間。在建模階段,首先將3.1.1 小節得到的日志流量序列向量組作為輸入數據,設輸入數據組成的矩陣為P,則使用PCA 異常檢測模型的目的是捕捉到轉換矩陣PPT中的主導模式,該模式可以計算出所有流量數據中的異常流量序列,具體比較方式是計算出每一個流量序列到正常空間的距離,該距離越大,則代表這條流量序列更可能是一個異常。該距離的閾值使用文獻[6]中提出的Qα,該閾值即表示1-Qα置信水平下的SPE殘差函數公式。在建模階段,需要得出線下數據的異常流量序列向量,因此需要計算每條日志流量序列到正常子空間Sd的距離,該距離通過ya=(1-PPT)y計算,如果SPE=|ya|2>Qα,則標記該條流量向量是異常的。為了進行線上模型預測,在這一步計算完成后將建立好的模型矩陣P以及異常判定分位點Qα保存下來。
根據歷史數據建立完成異常檢測模型后,可以初步篩選出異常的流量序列,但是這些序列直接進行人工識別仍然會存在問題,因為每條流量序列都包含多條日志以及各個節點的信息,這些日志流量代表的異常應該進一步聚類,以便人工分析。日志的流量實際上代表不同日志事件按順序出現,因此繼續使用最長公共子序列進行兩條流量信息的相似度判定,只不過這次對比的最小單元是一種日志類型。這也符合實際的問題設置,因為不同日志按照順序出現恰好是一種異常流量模式的體現。比如單獨出現一次T4(認證失敗)類型的日志,可能是由于用戶不小心密碼輸入錯誤引起的。但是如果在一定的時間片內,同一個主機頻繁出現T4(認證失敗)類型日志、T10(密碼錯誤)類型日志、T0(連接斷開)類型日志,則說明該類型序列可能是一種暴力破解密碼進行登錄的嘗試。
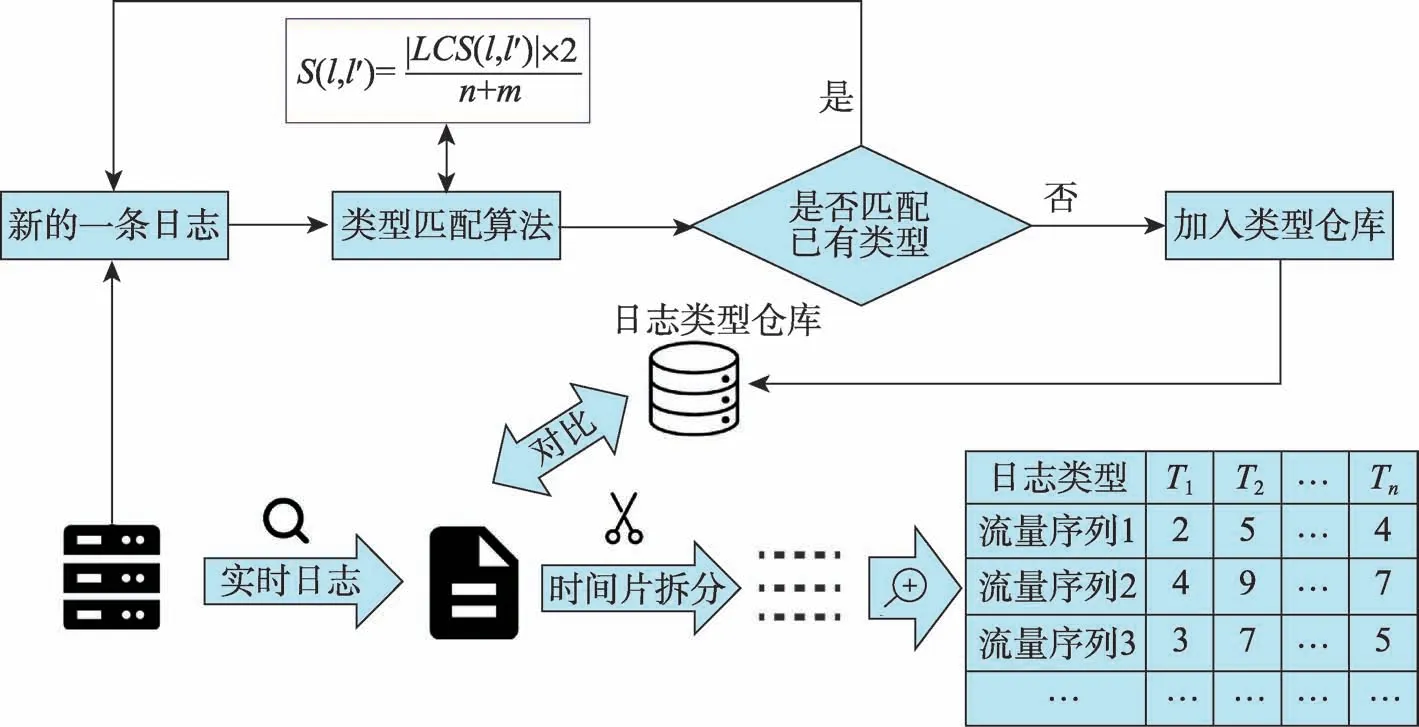
Fig.1 Flow chart of log preprocessing step圖1 日志預處理流程圖
基于以上考量,最終確定兩條日志流量序列的相似度計算公式如下所示:

其中,|*|代表類型序列* 的長度,S1和S2分別代表兩個待比較流量序列,S代表這兩條流量序列的最長公共子序列,比如圖2 所示的兩個日志流量序列S1=[T7,T11,T3,T2],S2=[T7,T11,T5,T6,T2]。則可得|S1|=4,|S2|=5,|S|=3,最后根據式(2)可計算出兩條日志流量序列的距離是d=3。
根據以上的距離計算公式,可以使用聚類算法對異常流量數據進行聚類,最終可以將所有異常序列分成幾個小類,以便后續分析。
3.1.3 線下日志流量模型的建立
第3.1.2 小節介紹了如何將日志流量信息通過無監督機器學習方法進行異常篩選和聚類分析,最后將所有異常流量序列分成幾個小類。然而在實踐中,不可能將所有異常流量序列都保存下來,因此本小節需要對每一類異常流量序列進一步分析,并為其找到一個代表性流量序列,以便對該數據進行持久化從而可以在后續線上運行時進行異常流量序列的匹配。
在對每一類異常流量進行分析時,考慮到流量本身是一個序列性數據,為了能將單條流量數據映射到向量空間,需要將序列數據轉換為數量數據。在實際操作中,直接使用每條流量數據中每種類型日志出現的次數作為其數量化的結果,然后將所有流量數據都抽象成其數量化的結果并做成表格,如圖3 左上角所示,其中每一行代表一條流量數據,每一列代表該類型日志出現的數目,該表格整體代表上一小節中分好類的其中一類異常流量數據的總體。下一步首先計算出表格中各個日志類型的平均值,然后遍歷該類型流量序列的所有數據,計算每一個流量序列與平均值序列的距離,此時的距離公式可以直接使用歐幾里德距離。最后找到該距離最小的那條流量序列作為該類流量序列總體的代表。通過以上步驟得到的流量序列代表既滿足數量上靠近平均流量值,又滿足序列上的順序對應,因此結果滿足了問題設定,總體流程如圖3 的上半部分所示。
在得到一類異常流量序列的代表后,按照上一小段介紹的方法循環所有異常流量序列類,最終就能為每一種異常流量序列類都對應地找到一條流量序列代表,整個流程圖見圖3 的下半部分。之后即可將這些代表作為待匹配流量序列模式并保存,為后續線上異常檢測提供基礎。最終,為了進行線上模型預測,這一步計算完成后需要保存的數據是所有異常流量的序列代表集合Moed。
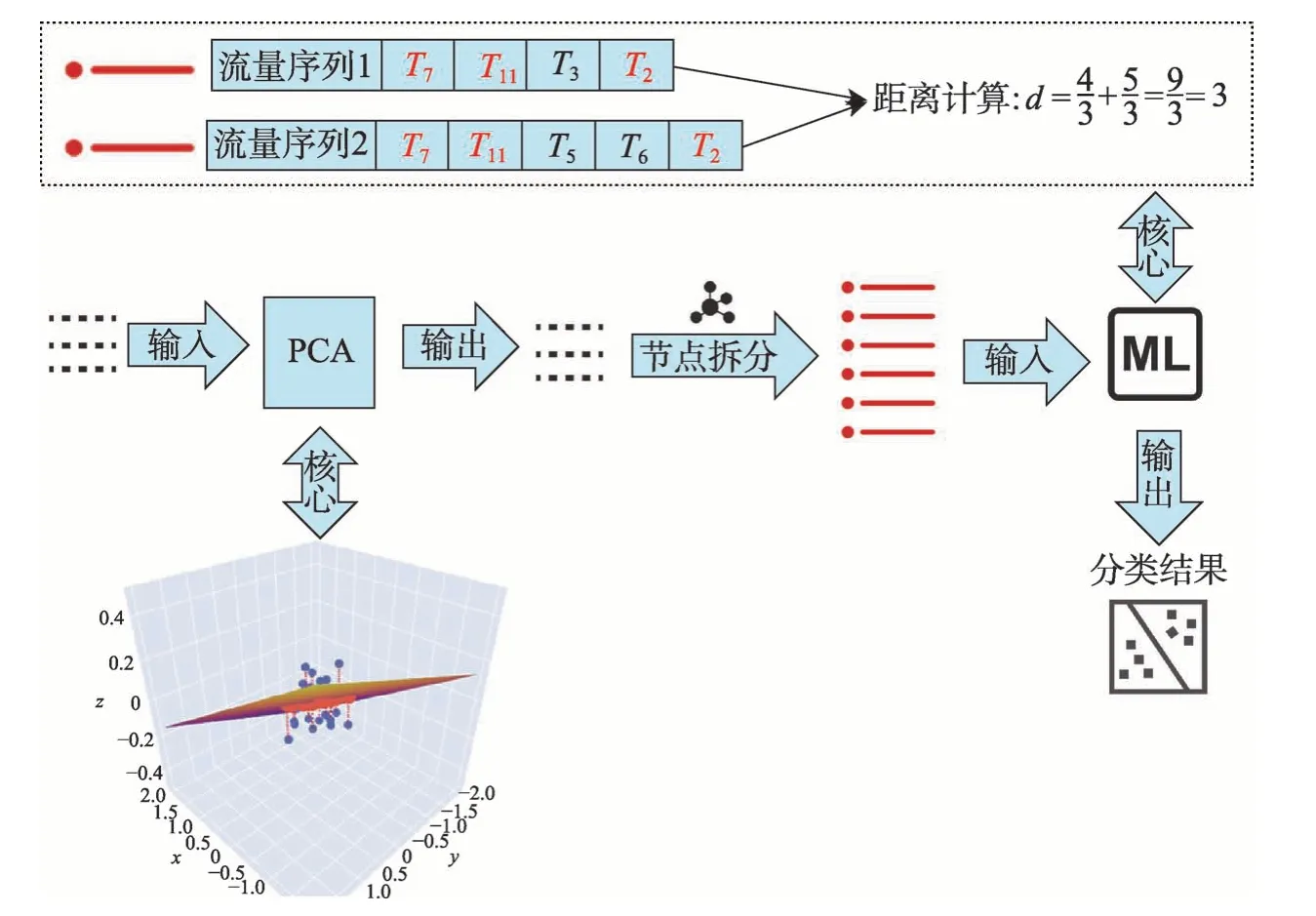
Fig.2 Flow chart of log flow anonymous detection and classification圖2 日志流量異常檢測與分類流程圖
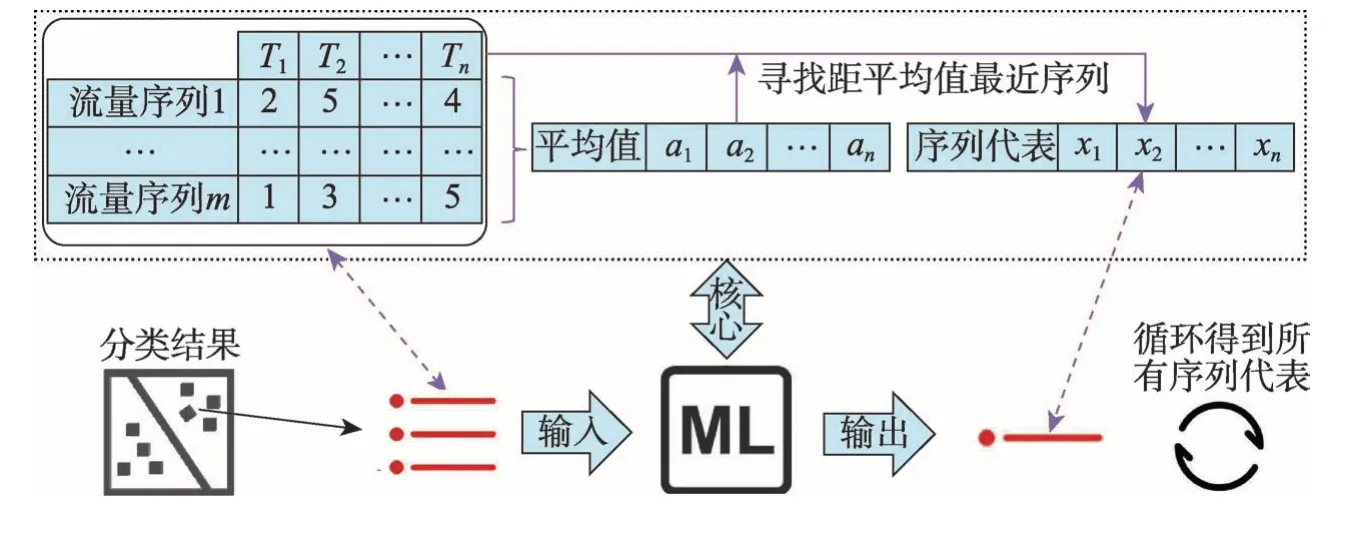
Fig.3 Flow chart of selecting logs for flow exceptions圖3 流量異常代表日志挑選流程圖
3.2 線上異常檢測
第3.1節詳細介紹了如何進行線下模型建模,表1展示了線下模型建立時得到的持久化數據。本節重點介紹如何進行線上實時預測并顯示結果。在線上預測時可以分為兩個階段,預處理階段和異常匹配階段。
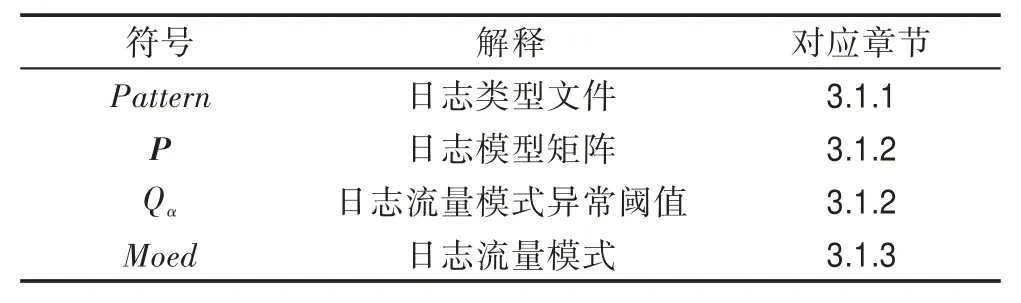
Table 1 Persistent data symbol,interpretation and corresponding sections表1 持久化數據符號、解釋以及對應章節
3.2.1 預處理階段
線上的流量檢測是實時的,而在線下建立流量檢測模型時用已經確定的時間片對日志進行分割,因此在線上流量檢測時需要使用相同的時間間隔進行處理,這樣才能保證線上檢測時流量數據適合線下建立的模型。在這種情況下,按照3.1 節中建模時的時間間隔搜集日志數據并得到單個時間片內的所有日志后,還需要將其處理成適合模型的輸入向量,該向量的每一個位置代表不同日志類型在該時間片內出現的次數,為了保證向量數據的一致性,日志類型的位置要與模型建立時日志類型的順序一致。這里匹配單條日志的方法是將該單條日志與Pattern文件中的所有日志模式遍歷并分別進行相似度的計算,計算公式見3.1.1 小節中的式(1),計算時如果相似度的結果大于閾值0.5,即將該日志作為此類型,并在向量的對應類型數據上加1,如果所有計算結果都不到0.5,則將計算得到的相似度最高結果對應的日志類型作為該條日志的實際類型。按照這樣的處理方式,即可得到該時間片的日志流量向量,最后將預處理得到的向量設為V。
3.2.2 異常匹配階段
在異常匹配階段,首先讀取線下建模時保存的矩陣P和閾值Qα,然后將3.2.1 小節得到的向量V與矩陣P進行異常分數的計算,即Score=(1-PPT)V。該異常分數和閾值進行比較即可得出此流量是否異常,即如果Score>Qα,則認為該流量時間片為異常。
另外,每一個流量序列還需要和實際的異常模式進行對比,來確定異常的種類。在實踐中,先將該條流量序列的所有數據按照節點分開,然后將得到的每一個節點的流量序列數據分別和流量模式文件Moed中的每個流量序列模式進行匹配,匹配時使用式(1)進行計算并得到單個節點在該時間片的流量和每種異常流量的相似度,然后將結果保存。在進行異常評價時,使用其中相似度最大的結果并記作Score。
目前已經得到了線上診斷時一個流量時間片所需的所有數據:單個流量時間片的異常分數Score和閾值Qα,該流量時間片內所有主機對應的異常相似度列表以及其中最大的相似度Sim。最后需要將這些結果進行疊加并能夠清晰地展示給相關運維人員,具體細節將在下一章的實驗部分介紹。
4 實驗結果與分析評價
本章將第3 章介紹的方法用于國家高性能計算環境系統在實際工作中產生的系統日志中。選取系統日志的secure 類別日志作為實驗數據。在第一階段使用了2018 年9 月的日志數據進行線下模型的建立,并得出異常基線以及異常流量模式數據,在第二階段將2018 年10 月的日志作為線上測試數據,進行實際的流量分析診斷,下面詳細介紹實驗結果。
4.1 日志異常檢測和篩選的分析評價
在使用日志數據進行線下模型建立時按照3.1節所描述的方法進行,首先計算出各個時間片的Q值,然后和模型的閾值Qα比較,如果大于閾值則認為該時間片是異常時間片。各個時間片的Q值和閾值Qα如圖4 所示。
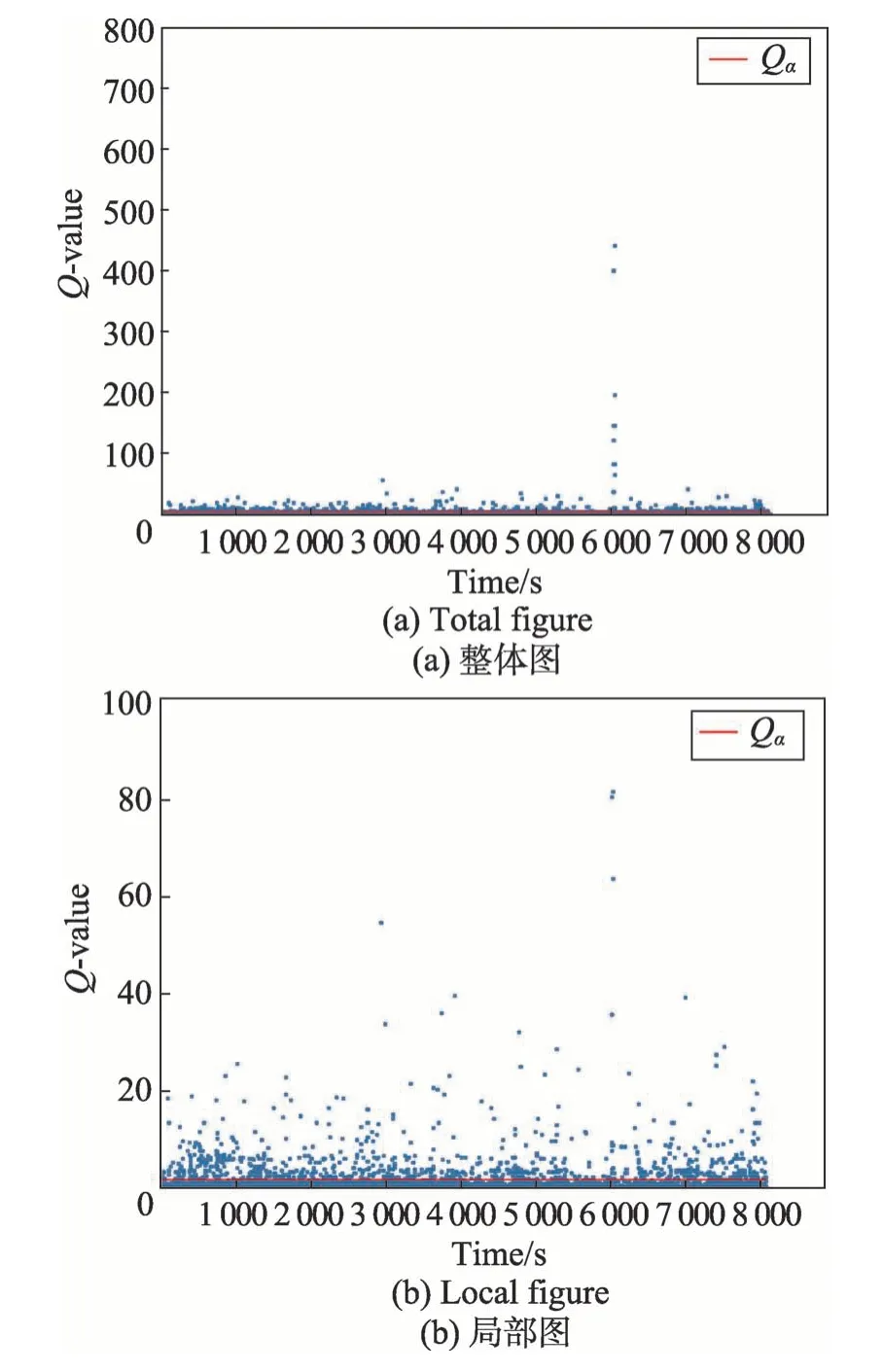
Fig.4 Q-value and threshold Qα of secure logs圖4 secure類型日志的Q 值和閾值Qα
從圖4 可以看出,異常類型時間片均勻地分布在整個日志周期的時間片內。得到所有正異常流量時間片后,還需要進一步過濾,具體的做法是首先統計出正常、異常時間片中不同類型日志出現數量的分布,計算出其對應正常、異常日志和出現數量的中位數來進行后續比較。根據比較的差值來得出正常、異常時間片主要差異的日志類型。通過該差異進行了過濾。最終統計得出了一共有8 134 個時間片段,挑出了908 個異常時間片段,時間片按照節點拆分后得到了16 240 條異常節點的類型序列,過濾后有676條異常節點的類型序列。
4.2 日志層次聚類和關鍵類型挑選的分析評價
在本節中,將4.1 節得到的大量異常日志流量序列按照3.1.2 小節的方法進行層次聚類的相關實驗。在進行層次聚類時,需要根據聚類結果的好壞來調整聚類參數,因此這里首先要選擇一種判別聚類方法性能的評價指標,由于應用的場景是高性能計算環境中的日志,數據量大并且模型每隔一段時間都需要更新重建,因此無法事先人工打好聚類標簽,整個過程需要使用完全無監督的方式進行。考慮到上述因素,這里選擇使用適合于無監督的聚類評價方式,輪廓系數(silhouette coefficient)法[16]。該方法結合內聚度和分離度兩種因素,其中輪廓系數得分較高的模型具有較好的聚類性能。單個樣本的輪廓系數計算公式如下:

其中,a代表樣本與同類數據中所有其他點之間的平均距離。b代表樣本與下一個最近聚類簇中所有其他點之間的平均距離。最終整體的輪廓系數是計算出所有樣本的輪廓系數后取平均值得到的,因此輪廓系數得分越高,說明此時的聚類結果使得同一種類之間聚集得比較緊密,同時不同的類之間聚集得比較遠,因此可以判定此時的聚類效果較好。
在使用層次聚類時有三個關鍵參數需要定義:(1)不同數據之間的距離度量方法;(2)不同簇之間的距離度量方法;(3)最終的聚類數目。不同數據之間距離定義按照3.1.2 小節的式(2)進行計算。不同簇間距離度量方法具有三種不同的選擇,分別為:平均距離標準方法(average)、最小距離標準方法(single)和最大距離標準方法(complete)。在對聚類數目進行選擇時,考慮到聚類的數目不能太多,因此就將實驗區間定義為3 到30種聚類數目。按照上述描述的結果,分別對不同的情況進行聚類實驗,并計算出對應聚類結果的輪廓系數。最終實驗結果圖如圖5 所示。
如圖5 所示,橫坐標代表不同聚類數目,縱坐標代表輪廓系數值,3 條折線代表不同的簇間距離度量方法。根據實驗結果,程序可以自動選擇對應最佳的參數。例如實驗中使用的線下數據最終的最佳參數是:聚類的簇間度量方法是最大距離標準方法(complete),聚類數目是3。根據上述參數,程序最終進行聚類后顯示出3種異常情景:
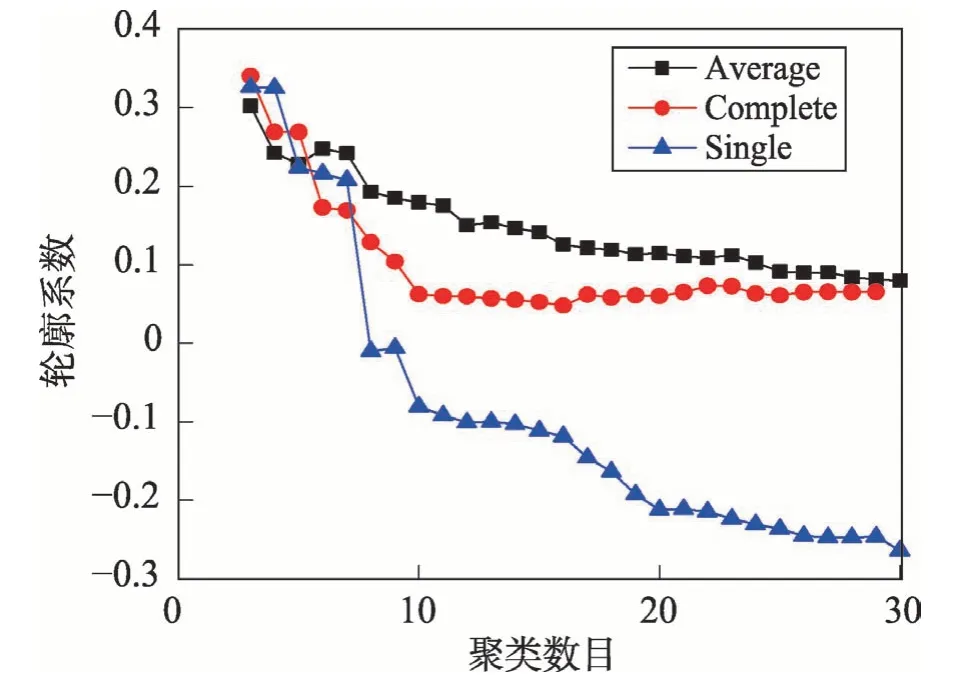
Fig.5 Silhouette coefficient for different parameters圖5 不同參數對應的輪廓系數值
情景1 該情景下出現最多的日志類型是T10(failed password for invalid user User0 from X.X.X.X port XX ssh2)和T4(pam_unix(sshd:auth):authentication failure; logname=uid=0 euid=0 tty=ssh ruser=rhost=X.X.X.X)。該種異常日志流量模式表明此時間段內可能有人進行暴力入侵系統的行為。
情景2 該情景下出現最多的日志類型是T14(sshd*pam_unix(sshd:session):session opened for user User1 by (uid=0))和T13(sshd*Accepted publickey for User1 from X.X.X.X port XX ssh2)。該種異常日志流量模式表明此時間段內出現大量登錄的行為,說明該段時間為用戶訪問高峰。
情景3 該情景下出現最多的日志類型是T39(sshd*error:no more sessions)和T0(sshd*Connection closed by::1)。該種異常日志流量模式表明該時間段內建立用戶會話數量超過限制,可能需要人工干預。
分別將這些情景定義為非法用戶攻擊、用戶訪問高峰、會話數超限,并將這些模式結果保存。
4.3 線上異常檢測實例對比分析
在實踐中已經完成了線上異常檢測程序的整體搭建與運行,整個流程分為兩個階段。
第一階段目標是完成線上日志的類型解析,該階段需要在程序中輸入線下模型日志的路徑和線上待分析日志的路徑,然后才能進行解析,已經完成了該階段的界面輸入以及正確的日志解析結果,如圖6所示。解析完成后就得到了待分析日志按時間片拆分后的日志類型序列。
第二階段需要完成的工作是待分析日志的實時預警以及分析結果的可視化展示。在3.2.2 小節中,已經構建好了異常實時監測模型并計算出異常結果Score、Qα以及Sim,為了將這些異常結果利于可視化展示,需要將結果進行合并,其中異常流量的結果可能會超過異常值比較多的比率,因此在計算時使用比值的方式,即Score/Qα,而異常相似度的Sim本身的值在0 到1 之間,因此可以直接乘以流量的異常來表示在該流量異常的情況下節點的流量為對應異常模式的可能性。最終,確定的異常分數計算公式如下:

通過式(4)進行流量分數的計算并將該值的大小進行可視化展示,其中顏色越深代表該值越大。其中一個時間片內異常的分數如圖7 所示。

Fig.6 Parsing of online code圖6 線上代碼解析
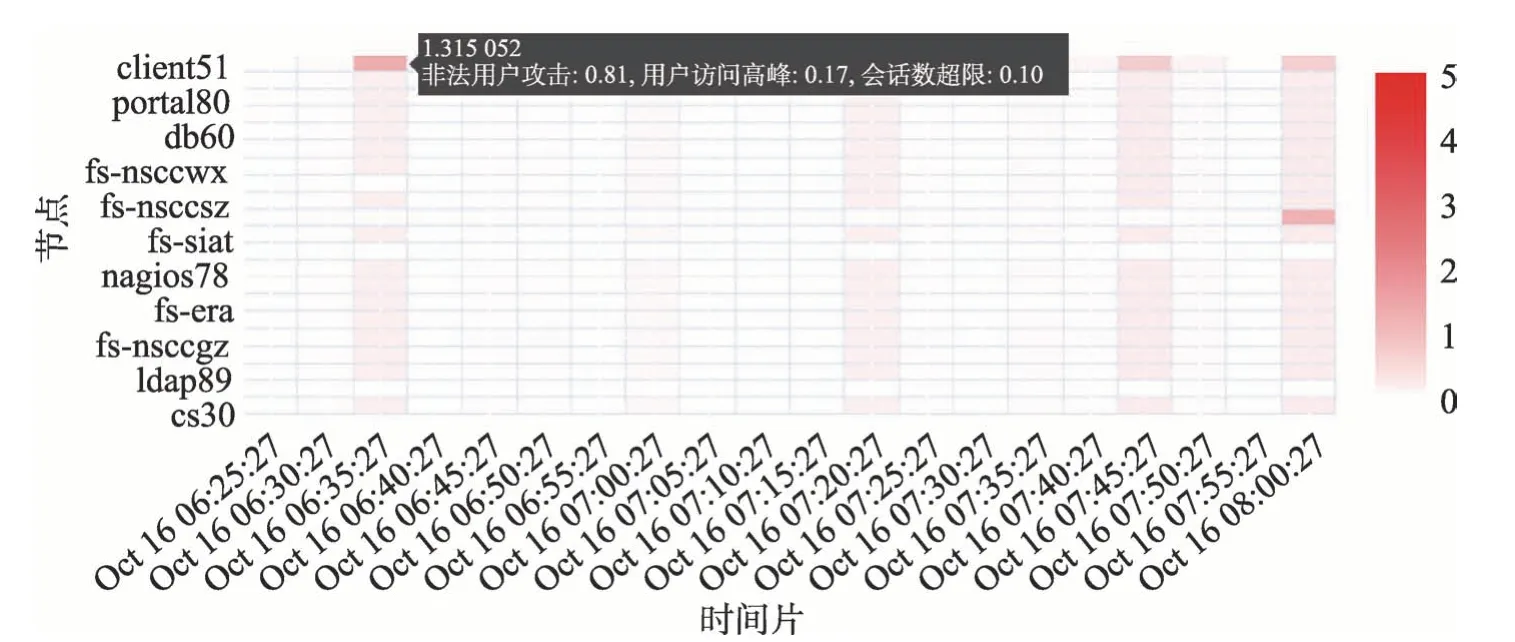
Fig.7 Anonymous score圖7 異常分數
圖7 的橫坐標代表不同的時間片,縱坐標代表不同的節點。該圖在實際運行時會根據時間流逝動態地向左運動,這里僅截取一小部分作為代表。如圖7所示,線上檢測時根據式(4)計算出的各個時間片的異常分數值可以明顯地展示出來:如果該時間片的流量有異常,則整體都會顯示出深色,其中和異常流量模式匹配的相似度最高的節點顏色最深。此時如果點擊該節點的時間片,則可以顯示出各種異常流量相似度的具體信息,如圖7 中左上角的黑色框所示。然后系統運維人員還可以進一步調出該節點在該時間片內的所有日志,通過真實日志的跟蹤顯示給出進一步分析。該可視化的結果以及異常情景的自動化匹配大大減少了人工工作量。在實際工作中,由于模型是根據歷史數據訓練并構建的,在進行檢測時可能出現新的異常流量模式,因此采用的策略是間隔一段時間使用新搜集的數據進行模型的迭代更新。
該系統已全部搭建完成,并已在網上(http://114.115.172.217/online)公布了示例程序。
5 結束語
本文介紹了一個無監督異常檢測系統,該系統自動挖掘系統日志的異常日志流量模式。系統的整個流程可以自動找到系統日志的異常時間段,并得到時間段內不同節點的日志序列。該序列通過進一步聚類可以自動得到異常情景模式序列并保存,之后還可以在線上實時進行檢測,最終檢測的結果可以實時顯示,使得系統運維人員可以方便地進行分析。
本文只是針對單一日志異常流量進行了一些前期探索工作,未來還有很多值得關注的研究點。今后的工作主要針對以下幾個方面:不同種類的日志,通過不同種類日志的關聯關系進行分析,以找到更全面的異常日志流量模式;基于日志類型序列的角度進行更多不同維度的日志分析方法研究,例如日志類型序列的關聯性分析等。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
