計算機技術驅動的未識甲骨字考釋研究
2020-11-16 07:46:04焦清局劉國英
殷都學刊 2020年3期
焦清局,劉國英
(安陽師范學院 計算機與信息工程學院,河南 安陽 455000)
一、前言
文字是文明的標志,也是一個民族的化石和印記。甲骨文是一種刻在龜甲與獸骨上的文字,是漢字漢語的鼻祖,承載著真正的中華基因。在甲骨學領域中,未識甲骨字的考釋一直是甲骨學家研究的重要內容。到目前為止,在已發現的約4378個甲骨文字中,已釋讀字僅有1682字,剩下的字考釋難度非常大[1]。傳統的考釋方法主要依靠甲骨文專家的知識和猜測:首先,甲骨文專家利用已有知識對未識甲骨字進行“隸定(對甲骨字進行模糊語義猜測)”,然后,通過相應的文獻對“隸定”的語義進行驗證。傳統的考釋方法存在以下缺點:一是在“隸定”和驗證階段需要研究者具備大量的甲骨文專業知識。然而,由于人的生理、認知等因素的影響,研究者無法掌握完備的專業知識;二是傳統方法只是從孤立的拓片信息“隸定”未識甲骨字語義。但是,甲骨文是一種成熟的文字系統,這種孤立的研究方法可能會導致考釋結果的不正確。因此,用傳統的方法對甲骨字進行考釋的進程緩慢。隨著對甲骨學研究的日益增多,以及甲骨學知識數據的規范化和數字化,中外研究者采用計算機技術對甲骨文字進行分析,并采用人工智能方法對甲骨字的語義進行建模和計算,從而可能突破甲骨文考釋瓶頸,獲得新的進展,從而促進甲骨學的發展。目前計算機技術輔助的甲骨學研究文獻并不多,這些文獻主要集中在甲骨文的輸入和可視化、識別、語義分析、甲骨拓片綴合、數據庫構建等方面的研究。
與現在的漢字不同,甲骨字都是篆刻的文字,其在計算機上輸入非常困難。因此,甲骨字的輸入為用計算機技術研究甲骨文起著重要的作用。劉永革等人通過建立甲骨字圖片化字庫,實現了甲骨字的可視化輸入[2]。此種輸入方法可以根據圖片數據輸入甲骨字6199個(包含異形體)。史創明和劉永革首先把甲骨字矢量化,并把其輸出為可伸縮矢量圖形(Scalable Vector Graphics,SVG)格式[3];然后通過編程把SVG格式的甲骨字顯示在網頁中。此種方法可以作為甲骨字文本輸入的一種有效補充。為了解決甲骨字輸入、編輯和印刷方面的難題,栗青生和王蕾設計了方便的甲骨文圖文編輯系統[4]。不僅如此,栗青生等人通過引入筆段和筆元的概念解決甲骨字異體字和合體字的輸入問題[5]。肖明等人利用模糊信息分析理論對象形碼編碼的模型進行研究[6],得出了甲骨文編碼的最佳碼長大致接近于3,從而為甲骨字進行編碼提供了理論基礎。顧紹通等人通過對甲骨字形的拓撲結構分析后, 整理出569 個甲骨字部件[7],并把這些部件映射到26個計算機鍵位上,根據甲骨字部件和鍵位映射關系即可輸入甲骨字。
在甲骨文字識別方面,早在1996年,復旦大學的李鋒通過抽象甲骨字的無向圖特征識別甲骨字[8]。利用相似的方法,栗青生等人首先抽象甲骨字關鍵點;然后連接關鍵點形成甲骨字圖;最后通過圖匹配算法識別甲骨字[9]。2014年,高峰等人首先利用語境分析生成的候選字庫得到對應的甲骨文語義構件向量,然后結合Hopfield網絡識別的結果計算待識別的甲骨文模糊字的匹配度,根據匹配度識別甲骨字[10]。由于甲骨異體字在拓撲結構上的穩定性,2016年,顧紹通利用拓撲圖形描述甲骨文字,并結合拓撲配準的方法識別甲骨文字[11]。2017年,劉永革和劉國英通過提取甲骨字圖像中的特征,并結合支持向量機(Support Vector Machine,SVM)識別甲骨字[12]。
在語義分析方面,2012年,袁冬等人提出基于實例的甲骨文釋文機器翻譯方案,并實現一個簡易的甲骨文字與現代漢字的映射系統[13]。2015年,高峰等人在一個融合甲骨文和現代漢語的語義知識庫之上,通過對甲骨卜辭的可拓語言建模分析釋義問題[14]。同年,熊晶等人結合語義網絡技術,利用關系資源描述框架(Resource Description Framework, RDF)抽象甲骨學中的實體及其關系,通過語義搜索發現實體間的語義關聯, 為甲骨文字的語義研究提供支持[15]。
甲骨拓片是計算機學家研究甲骨文最直接和原始的數據,是構成語義的基本單元。但是由于甲骨質脆和時代久遠,出土時甲骨片多已裂成碎片。只有將這些碎片綴合在一起,才能更好地了解甲骨拓片描述的事件、場景以及內容。老一代甲骨學家已成功綴合了大量的甲骨片。然而,手工的甲骨片綴合方法非常耗時,王愛民等人提出了基于甲骨片圖像的輪廓信息綴合方法[16]。該算法首先提取甲骨片的邊界片段;其次,計算甲骨片的輪廓特征,甲骨片的輪廓即為甲骨片的形狀。甲骨片的輪廓特征在整個綴合過程中起著重要的作用。在此算法中,王愛民等人采用Freeman鏈碼表示輪廓線段,并用傅里葉描述子計算輪廓片段的特征;最后,計算不同甲骨片的匹配程度。如果兩個甲骨片的匹配程度大于0.8,那么這兩個拓片應綴合在一起。從真實數據的驗證結果表明該算法具有一定的有效性。
甲骨文數據庫的構建為計算甲骨學研究提供堅實的數據基礎,也是計算甲骨學研究的開始。甲骨文數據庫的構建一般要具備5個特點:一是原始性,即數據庫中的甲骨片具有原始性,最好是出土甲骨片,這樣能保證圖片的真實性;二是正確性,數據庫收錄的拓片、字庫、部首、字形等信息要經過甲骨學專家的認證;三是全面性,構建的甲骨文數據庫能全面提供有關甲骨文的各方面信息,如甲骨字的部首、字形、所在的拓片、拓片的出土地、現存地、相關的研究文獻等全面信息;四是可共享性,構建的甲骨文數據庫能提供世界上任何地點的甲骨文研究專家使用;五是及時性,即構建的數據庫要根據甲骨文的研究及時更新數據庫中的信息。如新發現的拓片、新的研究文獻、新的甲骨片綴合信息等要及時更新到數據庫中。
2004年,江銘虎等人構建了包含甲骨文字庫、甲骨文知識庫和句法分析、計算機甲骨文輔助辨識等信息的數據庫[17]。該甲骨文字庫包含甲骨文字3600余字,并對可釋讀的約1400個甲骨字進行了詳細的計算機標注,其中包括專有名詞120余個,這些甲骨文字全部可通過拼音輸入,并可給出對應的現代漢語解釋。安陽師范學院甲骨文信息處理教育部重點實驗室開發了甲骨文大數據庫(http://jgw.aynu.edu.cn),該數據庫包含了甲骨拓片、拓片上甲骨字注釋、甲骨文文獻、甲骨字庫、甲骨字輸入法等信息。該數據庫是一個甲骨學研究較為全面的數據庫,并及時更新最新甲骨學研究文獻。
盡管計算機技術輔助的甲骨學研究取得了一定的進展,但是對未識甲骨字語義預測方面進展緩慢。本文以上下文語境和字形信息入手,首先通過建模捕捉甲骨字的上下文語境和字形信息;其次把未識甲骨字語義預測轉化為計算機技術可處理的問題;最后設計相應的算法預測未識甲骨字的模糊和精準語義。文中提出的研究思路有助于推動甲骨學考釋的進程。
二、未識甲骨字的模糊語義預測
2.1 甲骨字上下文語境信息的建模
在甲骨學研究中,甲骨字的上下文語境信息和字形在預測語義的過程中起著重要的作用。上下文語境主要表現為甲骨字在拓片中與其它甲骨字的鄰近關系,以及甲骨字與其它甲骨字在所有拓片中共同出現的頻率。字形主要表現為整體甲骨字、部首、構件(可能是不代表任何語義的字的一部分)在不同時代的演變過程。在以計算機技術輔助的未識甲骨字語義預測過程中,我們需要建模捕捉甲骨字的上下文語境信息和字形信息。
復雜網絡是抽象復雜系統最為有力的工具。在復雜網絡中,結點代表某個事物或概念,邊代表事物與事物或概念與概念之間的相互關聯關系。通過構建甲骨字的網絡可以捕捉甲骨字的上下文語境信息。在自然語言處理領域,共現網絡可以反映文字在段落中的線性關系。在共現網絡中,結點表示文字,邊表示文字在一個窗口中的鄰接關系。在構建文字的共現網絡過程中,一是要確定在多大的窗口內表示文字之間的鄰接關系;二是如何確定鄰接關系。在構建甲骨字網絡時,窗口的大小為一個甲骨拓片中所有甲骨字的個數。而兩個字的鄰接關系可以是緊密相連的兩個字,即只計算相鄰兩個字之間的權重(m=2)。圖1[18]給出了構建共現網絡時需要計算的兩個字之間的權重(m=2,上圖)。下圖給出的m=6時,計算的文字之間的權重值:即要計算6個字(w1,w2,w3,w4,w5,w6)中任意兩個字之間的權重。在構建甲骨字共現網絡時,m值設置為一個拓片中甲骨字的總個數。因此,對于一個拓片,我們需要計算拓片中任意兩個甲骨字之間的權重。與構建以往共現網絡不同,焦清局等人計算的兩個甲骨字之間(甲骨字i和j)的權重[19],不是甲骨字i和j在一個拓片上的權重,而是它們在不同拓片上的權重和。構建甲骨字共現網絡(網絡矩陣為M)的步驟如下[19, 20](見圖2):第一,選定一片甲骨拓片,假設此拓片上的兩個甲骨字i和j,我們可以使用公式(1)和(2)定義甲骨字i和j之間的權重wij,并把wij值賦予Mij。公式(1)中的interal值可以用公式(2)計算,如果甲骨字i和j之間沒有殘缺甲骨字,那么interal的值為lj-li;在一些拓片中,有些甲骨字之間存在殘缺情況。如果甲骨字i和j之間有殘缺的情況,那么interal的值之間除了lj-li,可加入一個參數β,β表示殘缺甲骨字之間的權重。在文獻[20]中,焦清局等人把β的值設置為2。在甲骨字共現網絡構建過程中,兩個甲骨字i和j之間的權重由i和j在不同拓片上的權重相加得到。
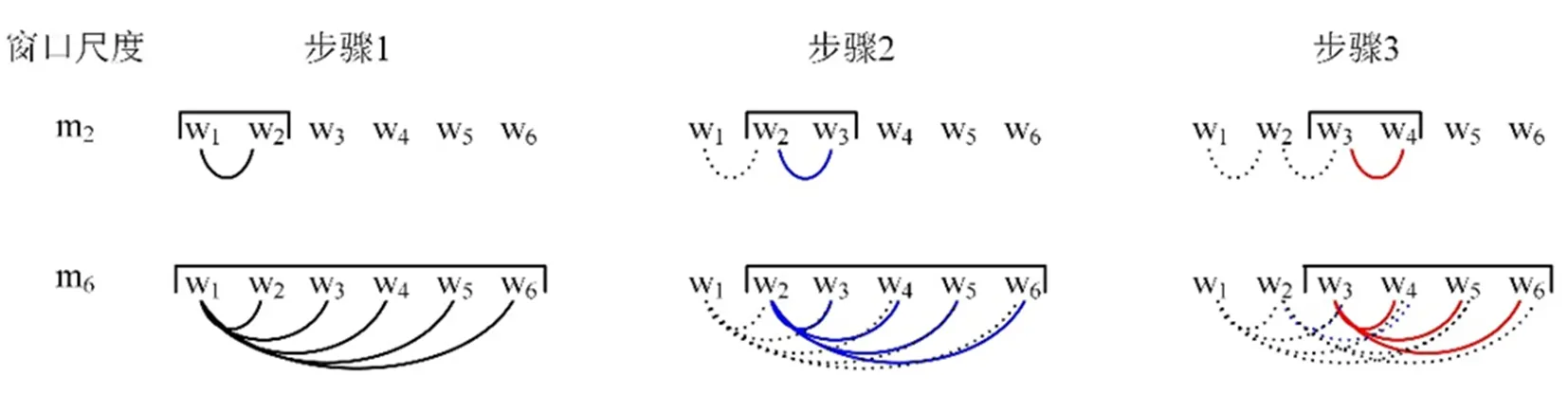
圖1 共現網絡構建示意圖[18]
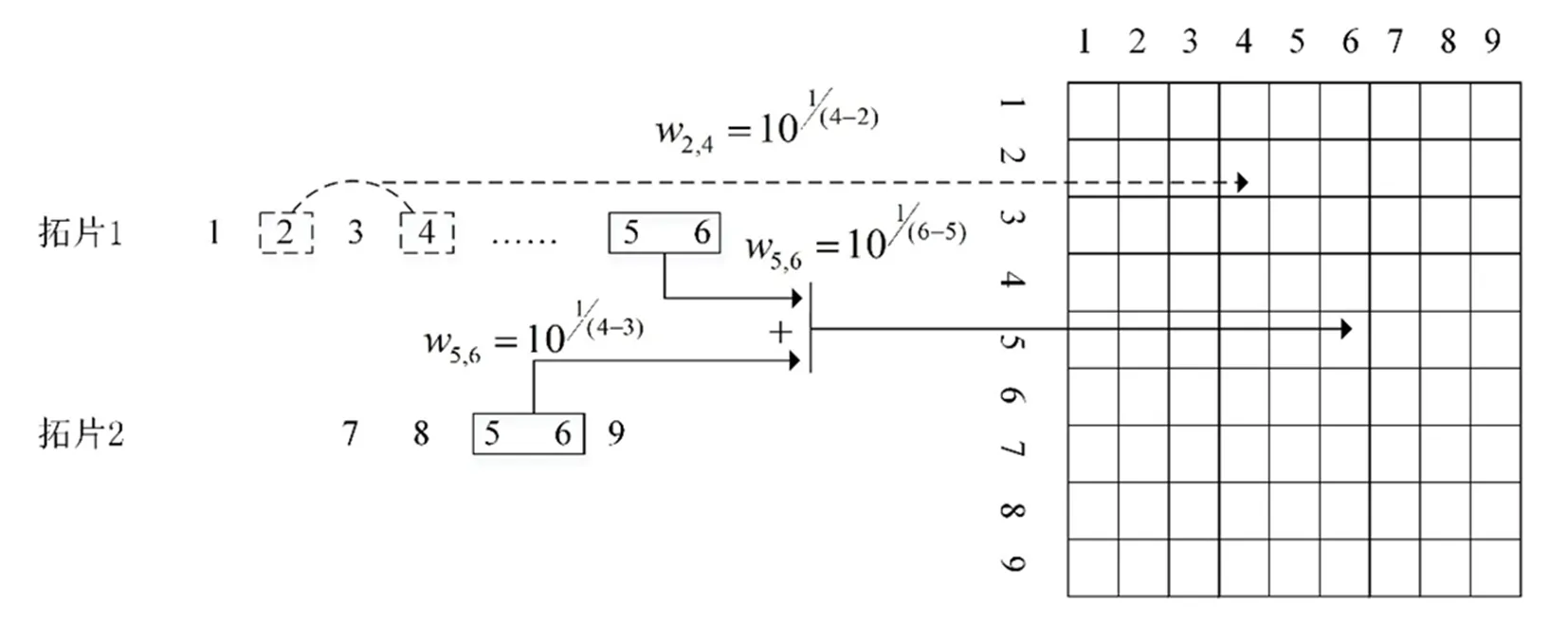
圖2 甲骨字網絡矩陣構建示意圖[19]
(1)
interal={lj-li
β+(lj-li)
(2)
在公式(2)中,lj和li表示甲骨字j和i在拓片中的順序位置,并且lj的位置在li的后面。
2.2 未識甲骨字考釋難易程度
在預測未識甲骨字語義之前,我們應該確定哪些未識甲骨字容易考釋。容易考釋的未識甲骨字應具備以下特點:一是未識甲骨字應該在不同的拓片中多次出現;二是未識甲骨字的信息豐富,即未識甲骨字所在的拓片應含有多個甲骨字;三是未識甲骨字的可用信息較多,即未識甲骨字周圍的甲骨字盡可能是已識字。總之,一個未識甲骨字的可用信息越多,此字被破譯的可能性就越大。在甲骨字網絡中,參數S[20]可以計算未識甲骨字的考釋難易程度。
(3)
在公式(3)中,Si表示甲骨i字的考釋難易程度系數,Nn和Un分別表示已識和未識甲骨字的個數,wih和wik分別表示甲骨字i與已識和未識甲骨字連接的權重。由于連接的權重和值較大,我們對其取對數。在S中我們可以看出,如果一個未識甲骨字i與已知甲骨字連接個數越多,并且權重越大,分子就越大;并且此未識甲骨字i與未知甲骨字連接個數越少,權重越小,分母就越小,S值就越大。未識甲骨字i可利用的信息就越多,i字的語義被預測的可能性就大。如果一個已識甲骨字j與其它已識甲骨字連接的權重越大、而與其它未識甲骨字連接的權重越小,Sj的值就越大,為預測其它未識甲骨字提供的信息就越少。總之,在甲骨文字系統中,對于一個已識甲骨字j,如果它的Sj值越大,甲骨字j對破譯未識甲骨字提供的可用信息就越少;對于一個未識甲骨字i,如果它的Si值越大,說明可用信息越多,被破譯的可能性就越大。
2.3 基于模塊結構的未識甲骨字模糊語義預測
模糊語義是甲骨字的較為籠統的語義,如甲骨字描述了哪種場景:戰爭、祭祀、打獵等。在甲骨學領域,描述某一場景往往需要多個甲骨字。而在計算機領域,描述同一場景的甲骨字往往具有很強的局部性,進而形成一個類別。我們可以把描述同一場景的甲骨字識別問題轉化為計算機領域中的分類問題。特別是在本文中,由于我們用甲骨字網絡捕捉上下文語境信息。因此,我們可以用網絡分割的方法預測未識甲骨字的模糊語義。在復雜網絡中,模塊識別是網絡分割的一種典型的方法。模塊結構[21]是復雜網絡的一種重要屬性。模塊是網絡的一個子網絡,它要求模塊中的結點緊密相連,而模塊間的結點連接稀疏。以圖3中的網絡為例,根據模塊的定義和模塊挖掘算法,網絡可以分為3的模塊:結點1、2、3、4(簡寫為1-4)構成一個模塊,結點5-7、8-12分別構成另外兩個模塊。模塊結構的重要特點是模塊內的結點具有相同的屬性。利用此特點可以預測網絡中未知結點的屬性(見圖3):在含有8-12結點的模塊中,如果結點12的屬性未知,而結點8-11描述的是殷商時代“祭祀”的場景語義,那么可以預測結點12也是用來描述“祭祀”的場景。
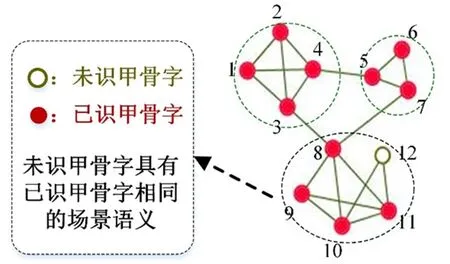
圖3 基于模塊結構的未識甲骨字場景語義預測模型
基于模塊結構的未識甲骨字模糊語義預測的核心任務是設計有效的模塊識別算法。在設計模塊識別算法時需要注意甲骨字網絡模塊的獨特性,即甲骨文字系統的兩個特點:一是描述場景語義所使用的甲骨字個數較少;二是同一個甲骨字可能會參與不同場景語義的描述。甲骨文字系統中的兩個特點在復雜網絡中表現為:一是甲骨字網絡中的模塊尺度較小,模塊中含有的結點較少;二是模塊中的結點具有一定的重疊性。這些特性說明,甲骨字網絡的模塊結構具有很強的局部網絡性質。
2.4 語境和字形信息融合的未識甲骨字語義預測
基于模塊結構的未識甲骨字模糊語義預測只使用上下文語境信息,并沒有使用甲骨字的字形信息。因此,預測的語義準確度并不高。為了提高語義預測的準確度,需要引入字形信息。在網絡分割的算法中,我們可以把字形信息作為網絡分割的輔助信息加入到算法中,進而提高分類的準確性。甲骨文字的部首在甲骨文系統中具有統領的含義,即具有相同部首的甲骨字可能描述相似的場景。在上下文語境信息中加入部首信息可以有效提高未識甲骨字語義預測的正確性。
深度學習由于其強大的功能,被應用到各個領域,并產生了一些高性能的算法,如深度卷積網絡,遞歸神經網絡等。這些算法在圖像、視頻和語音的識別等領域都取得了成功地應用。卷積神經網絡[22]是深度學習應用最成功的領域之一。卷積神經網絡首先利用卷積抽取圖像的局部特征;然后利用池化過程減少冗余信息,保留重要信息,達到降低時間復雜度的目的;最后采用非線性激活函數輸出圖像特征。卷積、池化和非線性激活函數構成一個卷積層,而卷積神經網絡通過融合較深的卷積層抽取圖像的有效特征。卷積神經網絡在圖像分類、目標檢測、圖像分割方面均取得前所未有的準確率。雖然卷積神經網絡具有良好的性能,但是對圖(或稱網絡)數據中結點特征的抽取性能不佳。如語言網絡、社會網絡和生物網絡等圖數據。這些數據屬于非歐式空間的數據,傳統的離散卷積無法提取結點特征。圖卷積網絡[23]借鑒卷積神經網絡的思想對圖數據進行卷積,并完成圖的結點分類。圖卷積網絡主要任務是把圖中的結點以及結點特征輸入到一個函數中,輸出為圖中各個結點的特征信息,并利用這些結點特征實現結點分類、鏈路預測等任務。我們可以以圖卷積網絡為工具,以甲骨字網絡為輸入參數,甲骨字部首信息為結點特征向量,實現甲骨字網絡的分割,進而預測未識甲骨字的模糊語義。
三、未識甲骨字的精準語義預測
精準地預測未識甲骨字的語義比預測模糊語義難度要大。精確預測未識甲骨字的語義需要推理甲骨字到現代漢字的演變過程。如果一個具有演變過程的甲骨字,再輔助上下文語境信息即可精確預測未識甲骨字的語義。因此,利用計算機技術學習甲骨字的演變規律是精準預測未識甲骨字的主要任務。我們可以先使用先驗知識訓練人工智能方法的模型,然后利用訓練的模型預測未識甲骨字的演變過程,進而精確推理其語義。但是,利用人工智能的方法學習甲骨字的演變過程存在很大的挑戰性。比如,在演變過程中,有些字使用了假借字,而假借字在演變過程中具有很強的字形波動性,字形的波動性會導致訓練模型不準確。
四、總結
未識甲骨字的語義預測是甲骨文信息處理研究中最為重要的內容。上下文語境信息和字形信息是預測未識甲骨字語義的重要因素。本文通過構建甲骨字共現網絡捕捉上下文語境信息,并利用圖卷積網絡為工具,以甲骨字部首為特征預測未識甲骨字的模糊語義。除此之外,我們以甲骨字演變為線索提供給讀者一個精準預測未識甲骨字語義的思路。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
當代修辭學(2010年1期)2010-01-23 06:35:10
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
