面向天河2A系統的基于蒙特卡羅方法的粒子輸運異構協同計算 *
2020-11-30 07:36:30李彪,劉杰,2
計算機工程與科學 2020年11期
李 彪,劉 杰,2
(1.國防科技大學并行與分布處理國家重點實驗室,湖南 長沙 410073,2.復雜系統軟件工程湖南省重點實驗室,湖南 長沙 410073)
1 引言
1.1 粒子輸運簡介
輸運理論是研究微觀粒子在介質中遷移統計規律的數學理論。這里“微觀粒子”指的是中子、光子、分子、電子和離子等。輸運理論研究大量粒子在空間或者某種介質中運行時,由于各粒子位置、動量和其他特征量的變化而引起的各種有關物理量隨時空變化所表現出來的非平衡統計運動規律[1]。
19世紀中后葉的分子運動論導致粒子輸運理論發展的開端。1872 年,Boltzmann 推導出了Maxwell分子速度分布函數隨時空變化的非線性積分-微分方程,該方程也常被稱為粒子輸運方程或者Boltzman方程[1]。粒子輸運方程描述的分布函數具有7個獨立變量,包括3個空間變量、2個方向角度變量、1個能量變量和1個時間變量。由于實際情況的復雜性,通常不能采用解析方式進行直接求解,只能通過數值模擬求解。
目前常用的求解粒子輸運問題的數值方法分成2類[2]:一類是“確定性方法”,這類方法通過對變量進行離散,將粒子輸運方程轉化為一組線性代數方程,然后通過求解此代數方程組來獲得精確解或近似解;另一類方法是“蒙特卡羅MC(Monte Carlo)方法”,也稱非確定性方法或概率論方法。它是基于統計理論的數值方法,對所要研究的問題構造一個隨機概率模型來模擬大量粒子的運動,以獲得感興趣的物理量分布。
本文研究的是關于粒子輸運中的非確定性方法。
1.2 蒙特卡羅方法在粒子輸運上的應用
蒙特卡羅MC方法亦稱隨機模擬法,是20世紀40年代中期電子計算機誕生后發展起來的一門計算科學[3]。它是通過計算機來對中子行為進行隨機模擬的數值方法,是一種以概率統計理論為指導的非常重要的數值計算方法。
通常蒙特卡羅方法可以粗略地分成2類[3]:一類是所求解的問題本身具有內在的隨機性,利用計算機直接模擬這種隨機的過程。例如,在中子輸運理論中,要求建立單個中子在給定幾何系統中的真實運動歷史,通過對大量中子歷史的跟蹤,得到充分的隨機試驗值(或稱抽樣值),然后用統計的方法得出隨機變量某個數值特征的估計量,用此估計量作為問題的解。另一類是所求解問題可以轉化為某種隨機分布的特征數,比如隨機事件出現的概率,或者隨機變量的期望值。通過隨機抽樣的方法,以隨機事件出現的頻率估計其概率,或者以抽樣的數字特征估算隨機變量的數字特征,并將其作為問題的解。這種方法多用于求解復雜的多維積分問題。
1.3 基于MC方法的異構協同計算
由于功耗和散熱問題日益突出,單塊芯片的性能已經不能單純地從提高頻率來獲取提升,摩爾定律將會消亡[4],于是工業界逐漸轉向多核處理器。但是,隨著技術的發展,多核處理器中每個內核的設計越來越復雜,并且頻率較高,功耗較大,嚴重阻礙了多核處理器中核數的擴展。為了進一步提升性能,同時滿足功耗和散熱的要求,出現了由眾多相對簡單的內核構建的眾核協處理器,如 NVIDIA公司推出的 GPU[5]、Intel公司推出的MIC協處理器[6]和本文所探討的國產加速器Matrix2000等。與多核處理器相比,這些眾核加速器的內核相對簡單,且頻率較低,但數量眾多,能夠以合理的功耗實現更高的性能。
近十年來,異構加速器快速發展,TOP500排行中排名靠前的超算系統的體系結構均采用了異構協同模式,許多研究人員對已有的求解粒子輸運問題的方法在各種加速平臺上做了許多相關的研究工作。
楊博[7]提出了一種針對CPU/GPU混合異構系統的深穿透粒子輸運MC模擬異構協同算法,針對GPU的計算和訪存特點,給出了一種基于粒子數的任務劃分方法和高效并行數據結構以及線程間的并行規約方法。相比運行在Intel Xeon X5670上的MC程序,該算法獲得了3.4的加速比,并在TianHe-1A的64個結點進行了測試,結果表明該算法具有良好的性能和可擴展性。
崔顯濤[8]基于MC方法,提出了一種面向CPU/MIC混合異構系統的粒子輸運并行算法,針對MIC訪存特點提出了適于程序并行的高速數據結構和基于靜態分配的任務劃分方式。相比運行在CPU端的程序串行程序,改進的MC程序獲得了8.6倍的加速比。
在多能群MC粒子輸運領域,近些年來有許多研究和探索,Bergmann 等人[9]基于GPU開發了一個MC粒子輸運框架WARP(Weaving All the Random Particles)。WARP的目的是使以前的基于事件的輸運算法適應新的基于GPU硬件而開發的連續能量Monte Carlo中子輸運代碼。Hamilton等人[10]基于Shift程序包開發了一個在GPU上運行的連續能量Monte Carlo中子輸運求解器,并把程序移植到了超算系統Summit上,在耗盡燃料的SMR(Small Modular Reactor)核心配置上,進行了1 024個結點的弱擴展測試,結果顯示其并行效率接近93%,這說明GPU對性能提升顯著。
本文的工作與文獻[8,9]的接近,都是只考慮單群的MC程序,不過本文的異構算法設計是基于不同于GPU和MIC體系結構的國產加速器Matrix2000,且研制的程序可以移植到大規模結點上,另外,還針對MC程序的數據通信進行了優化,取得了顯著的性能提升。
2 粒子輸運MC模擬
MC模擬是通過對大量中子歷史的跟蹤來獲取大量的隨機試驗結果,并對這些結果進行統計方法處理,最終以得到的統計量作為問題的解。 所謂一個中子的歷史,是指該中子從源出發,在介質中隨機游走,經過各種核反應作用,直到中子歷史結束或稱中子“死亡”。所謂“死亡”是指中子被吸收、穿出系統、被熱化,或達到能量權下限或時間上限。其中時間、能量的載斷是無條件的,而權截斷是有條件的,由俄羅斯輪盤賭決定[11]。
圖1是一個中子歷史的循環過程。初始時,從粒子源出發的一個粒子的位置、方向、能量等參數是確定的,隨后粒子的運動方向和與原子核的碰撞類型服從特定的概率分布,在經歷了一系列碰撞過程之后,粒子歷史趨向于結束。有幾種不同類型的結束,比如達到時間與能量界限、逃脫出系統或達到權下限。在這一個過程中,下一次碰撞僅與當前碰撞后粒子的位置、能量以及方向相關,完全獨立于先前的碰撞。 因此,這一過程是一個典型的馬爾可夫過程。所以,只要知道粒子與原子核碰撞的規律,那么粒子的軌跡就可以用蒙特卡羅方法正確地模擬出來,從而得到所關心的解[12]。

Figure 1 Simulation of particle transport process圖1 模擬粒子輸運過程
3 通信模式優化
3.1 串行阻塞通信模式
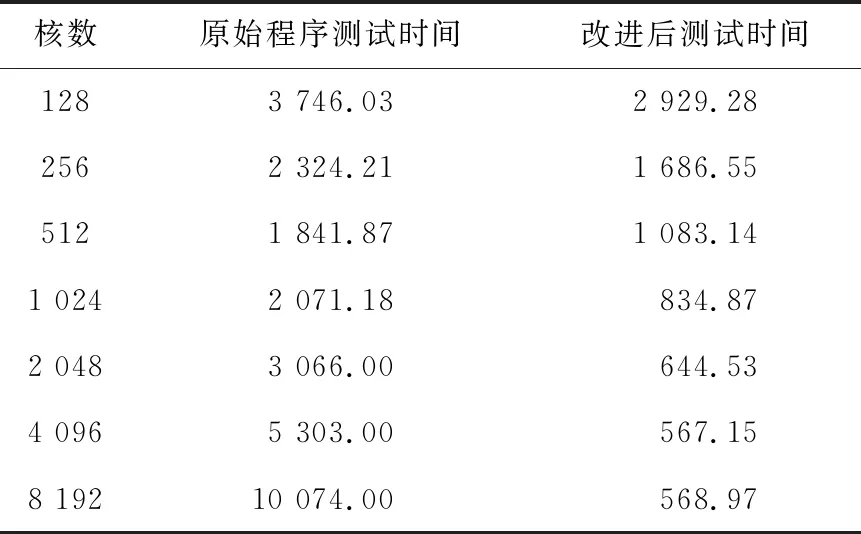
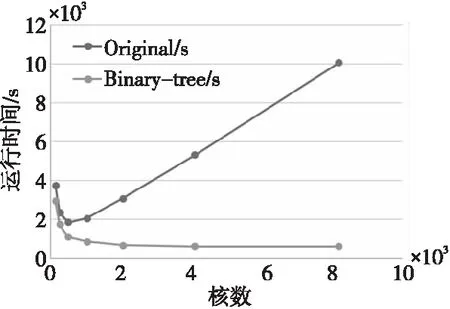
通過測試MC程序的強擴展性發現,當進程數大于256時,效率急速下降,達到1 024進程時基本上已經沒有加速效果了,這對移植MC程序到大規模系統上產生了巨大障礙。經過仔細分析程序的通信模式發現,由于計算結果數據收集的通信模式是主從模式,導致等待時間過長。
首先0號進程初始化任務,接著把數據發送給其他所有從進程,從進程接收到數據后開始計算,并在從進程的計算結束后設置同步柵欄,直到所有從進程的計算都結束后,0號進程才開始收集從進程發送過來的結果數據。數據的收集過程中所有從進程都向主進程阻塞發送數據,主進程進行阻塞接收,先到的信息先被處理。對于主進程來說這是一個串行處理過程,此通信方式會造成通信瓶頸,核數越多,對程序性能的影響越大。圖2展示了P個進程的通信過程。
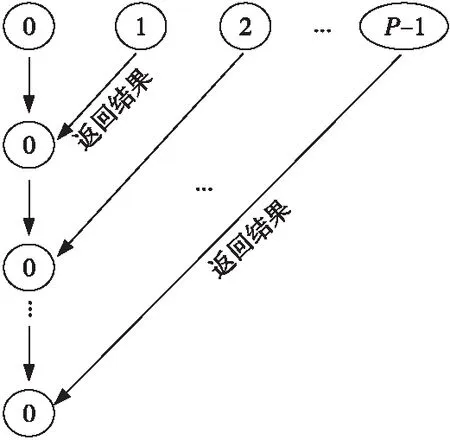
Figure 2 Serial data collection mode圖2 串行數據收集模式
3.2 優化后的二叉樹通信模式
考慮到MC程序0號進程對收集到的數據只進行簡單的統計處理,所以可以通過逐層進行兩兩進程通信,實現局部統計處理,最終把統計結果匯總到0號進程。本文采用二叉樹通信模式來實現這種通信過程,假設總進程數為2K+res,其中,K,res都是大于或等于0的整數,且滿足條件0≤res<2K,為了滿足二叉樹的通信模式,排在前面的2*res個進程先就近奇偶進程號兩兩通信,并把通信過程中已發送過信息的進程剔除,不參與下次通信,從而下一階段通信的進程數變為2K。接著對2K個進程號重排,前2*res個進程號除以2,其余進程依次減去res,得到新的2K個進程的標識號,下一階段就是進行二叉樹通信,算法1描述了具體的通信過程。為了方便描述,圖3展示了7個進程的通信過程,括號里的數字表示重排后的進程標識號。
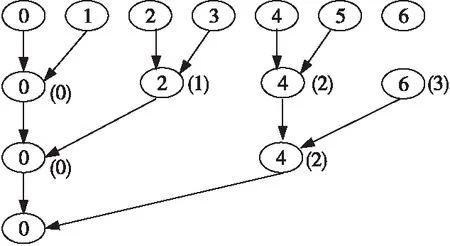
Figure 3 Binary tree data collection mode圖3 二叉樹數據收集模式
改進后的數據收集模式,通信復雜度由2K+res減少為log (2K+res),極大地減少了通信時間,也避免了大規模通信時從進程同時向主進程發送數據導致的程序阻塞。
4 基于CPU/Matrix2000的異構協同算法
4.1 Matrix2000加速器
天河2A系統中,每個結點由2顆Intel Xeon 微處理器和2顆Matrix2000加速器組成,如圖4所示。每個Intel Xeon微處理器包含12核,工作頻率為2.2 GHz,采用英特爾Ivy Bridge微架構,峰值性能0.211 2 TFLPOS。每個Matrix2000加速器包含128核,由4個超結點組成,每個超結點包含32個計算核,其中超結點支持64核超線程技術,峰值性能2.457 6 TFLOPS@1.2 GHz,有8個DDR4內存通道,支持×16 PCIE 3.0 EP工作模式。
算法1二叉樹通信偽代碼
//假設總進程數為2K+res,0≤res<2K
1mask=1;
2if(myid< 2*res)then/*前2*res個進程先通信,使下一階段通信進程個數為2K*/
3if(myid%2!=0)then//奇數號進程
4dest=myid-1;
5new_id=-1/*進程號置為-1,不參與下次通信*/
6myid進程SENDmsgtodest;
7else//偶數號進程
8src=myid+1;
9new_id=myid/2;//重排后新的進程號
10myid進程RECVmsgfromsrc
11endif
12else
13new_id=myid-res;/*其余的進程重排后的進程號*/
14endif
15if(new_id!=-1)then/*重排后的2K個進程進行通信*/
16while(mask<2K)do//二叉樹通信模式
17if(mask&new_id)then/*獲取重排號之后的偶數進程號*/
18newsrc=new_id|mask;
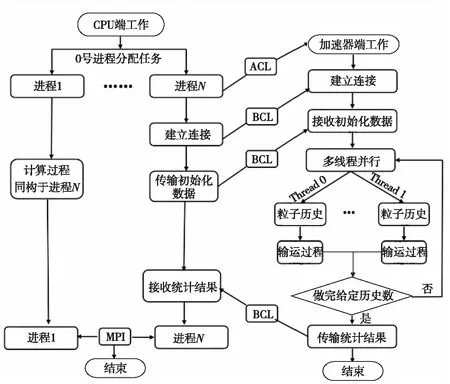
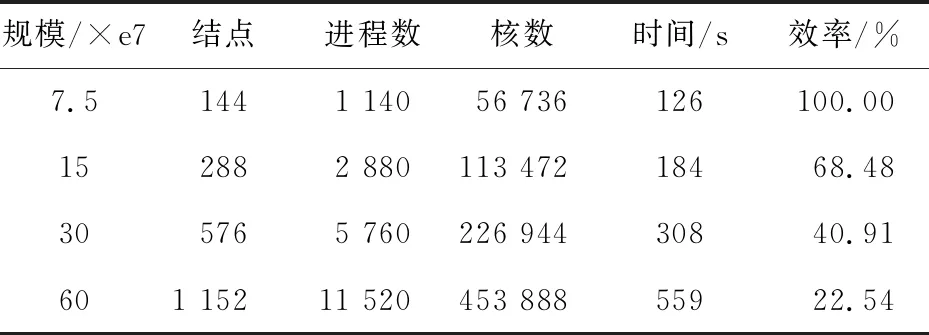
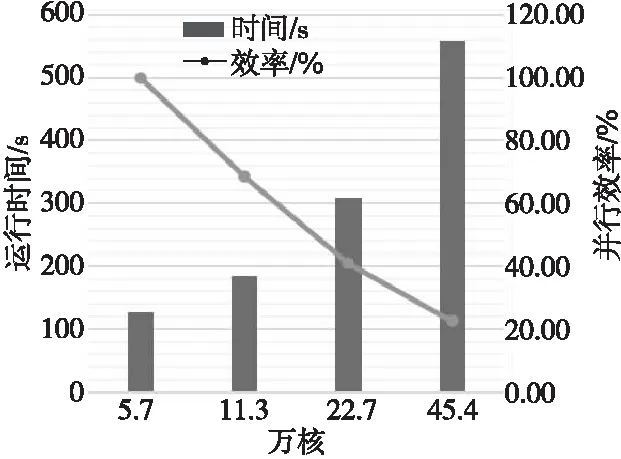
19if(newsrc 20src=newsrc*2 21else 22src=newsrc+res 23endif 24 RECVmsgfromsrc 25else 26newdest=new_id& ~mask 27if(newdest 28dest=newdest* 2 29else 30dest=newdest+res 31endif 32 SENDmsgtodest 33 exit//發送過消息后,此進程就退出通信 34endif 35mask= 2*mask 36endwhile 37endif Figure 4 Structure of Tianhe-2A system node圖4 天河2A系統結點結構 天河2A系統支持3種異構通信模式OpenMP4.5、ACL和BCL,其中BCL是一種簡單高效的對稱傳輸接口,CPU和協處理器之間數據通信利用PCIE總線進行傳輸,底層通過SCIF來實現。BCL相比OpenMP4.5更底層,程序移植也更復雜,但是傳輸速率更快,移植后的程序靈活性更好。基于BCL接口的異構程序需要編譯2套程序,CPU和加速器分別編譯一套程序,2套程序分別在CPU端和加速器端同時運行,其中運行時加速器端的程序需要通過ACL傳送到加速器端并啟動。 圖5給出了基于CPU/Matrix2000的MC程序的異構模式流程。首先,CPU端0號進程啟動MPI進行進程初始化,0號進程負責讀取文件數據,并把總計算任務按照粒子數均等的方式分配給從進程對應的子任務,再將子任務的初始化數據傳輸給對應的從進程。每個從進程控制一個Matrix2000超結點,通過ACL把加速器端的程序傳輸到Matrix2000端并啟動程序,利用BCL使CPU端與 Matrix2000超結點建立連接,CPU端把初始化數據傳輸到Matrix2000端,加速器端完成CPU端數據接收后就利用多線程技術并行跟蹤每個粒子歷史,直到所有粒子歷史全部完成計算,加速器統計結果數據并把數據通過BCL傳輸給對應的CPU進程,再由MPI實現進程間的傳輸。整個異構控制的過程中,CPU主要負責傳輸數據,Matrix2000主要負責計算。 Figure 5 Flowchart of heterogeneous logic 圖5 異構模式邏輯流程圖 Matrix2000中一個超結點包含32核,支持64核超線程技術,為了充分發揮Matrix2000的性能,通過OpenMP指令實現線程級細粒度并行,算法2描述了具體算法偽代碼。加速器端接收CPU端發送過來的數據,接著做初始的工作,針對粒子輸運模塊進行多線程并行。每個線程跟蹤一個粒子,完成當前粒子跟蹤后,進入time_to_stop判斷是否所有粒子數都已完成,如果未完成,當前線程臨界更新粒子數變量nps++,更新后的第nps個粒子分配給當前線程進行跟蹤模擬。這種調度方式類似迭代塊大小等于1的dynamic調度。 算法2Matrix2000加速器上的OpenMP線程級并行 1 假設線程數為T,加速器分配到M個粒子,粒子編號區間為(nps,nps+M-1); 2 #pragma omp parallel;/*開啟多線程,每個線程跟蹤一個粒子,完成后繼續跟蹤下一個粒子*/ 3forall threadsdo 4 各個線程初始化自己的私有變量; 5omp_set_lock(&lock);/*設置鎖,當前只有獲得鎖的線程才能更新共享數據*/ 6 更新共享變量; 7while(!time_to_stop())do/*判斷當前是否完成M個粒子數追蹤*/ 8nps=nps+1;/*未完成,更新nps,追蹤第nps個粒子*/ 9 更新共享變量; 10omp_unset_lock(&lock);/*釋放鎖,使得多線程可以調用hstory并行追蹤粒子*/ 11 callhstory();/*線程各自調用hstory()函數,互不干涉,完成輸運過程*/ 12omp_set_lock(&lock);/*設置鎖,進入time_to_stop()中訪問共享數據*/ 13endwhile 14 更新共享變量;/*完成M個粒子數追蹤,進行數據更新*/ 15omp_unset_lock(&lock); 16endfor 相比Intel MIC協處理器Offload模式多線程技術以及OpenMP4.5提供的異構模式,本文的異構模式中的CPU與Matrix2000加速器并不是主從關系,而是對等的關系。Matrix2000加速器端啟動的是單獨的一套程序,所有的數據傳輸和初始化工作在啟動多線程之前已經完成,所以Matrix2000上的OpenMP不需要通過編譯指導語句來傳輸數據和設置各種變量屬性,使得程序結構設計更簡單、更靈活。 測試平臺為天河2A系統,由于ACL和BCL指令只提供C/C++的接口,本文需要對MC程序插入C語言的通信控制接口,CPU端的程序采用Intel的編譯器和基于高速網的mpich3.2進行編譯;加速器端采用自定義交叉編譯器進行編譯,支持OpenMP指令。 單結點硬件配置為2顆Intel E5-2692 v2 @2.20 GHz(12 核/顆)+8個超結點Matrix2000,每個超結點通過超線程技術實現45核多線程并行。 MC程序的輸入文件參數除問題規模隨具體實驗設置外,均保持默認值。 考慮到數據的通信僅在CPU端進程之間進行,而并不涉及到加速器,所以本節僅在CPU上進行對比測試,表1給出了通信優化前后的測試結果。 Table 1 Test results before and after communication optimization 分析圖6可以發現,原始程序測試結果中,512核是拐點,小于512核時程序還有加速效果,大于512核時測試時間反而急速上升,已經沒有加速效果,表明此時計算能力不是瓶頸,數據通信占主要耗時。相反,優化了通信模式的程序測試時,運行時間隨進程數遞增逐漸下降,沒有出現進程數越多測試時間反而上升的現象,當大于2 000核時耗時趨于穩定,這是由于粒子數計算規模受限,增加進程數的優勢已經不明顯導致的。可以設想如果計算規模增加進程數越多,優化通信后的程序會比原始程序效果更好。 Figure 6 Comparison of two communication modes圖6 通信模式對比圖 本節對基于CPU/Matrix2000的異構MC程序進行弱擴展測試,每個結點啟動10個CPU進程,其中8個進程分別和結點內的8個Matrix2000超結點進行異構計算,剩余2個進程協同計算,每個超結點使用48核多線程,表2給出了弱擴展測試結果,圖7給出了相應測試結果的柱狀圖。 Table 2 Weakly scalable test Figure 7 Bar and curve chart of weakly scalabletest result on Tianhe-2A圖7 天河2A弱擴展測試結果柱狀圖 表2說明弱擴展到45萬核時,相對5萬核并行效率保持在 22.54%。 分析圖7可以得到,雖然研制的程序可以運行到45萬核,但是可以看到,隨著核數增大并行效率的下降趨勢很明顯。結合程序與加速器體系結構分析,導致并行效率下降迅速的原因主要有2點:首先,MC程序的粒子輸運部分的計算不是數據密集型,在中子的歷史過程中充滿了大量粒子條件狀態的判斷,程序的邏輯控制語句居多,這與Matrix2000加速器適合程序邏輯控制簡單、數據計算密集的條件相沖突;其次,在程序的OpenMP多線程部分,雖然開啟了多線程技術,但是粒子歷史的模擬追蹤過程中各個線程都涉及更新共享數據,需要設置臨界區,在臨界區內同時只能有一個線程更新共享數據,其他線程只能等待,這會影響多線程的并行效率。 本文在現有粒子輸運蒙特卡羅模擬程序的基礎上,提出了一種面向CPU/Matrix2000異構系統的粒子輸運異構協同算法,基于天河2A系統的異構通信模式BCL和ACL,針對CPU和加速器各自設計了一套不同的代碼,在CPU端通過ACL實現加速器端代碼的啟動,利用BCL進行CPU與Matrix2000之間的通信,進而提出了一種CPU與加速器Matrix2000之間的簡單高效的對稱通信模式。優化了原MC程序的串行數據收集通信模式,提出了新的二叉樹通信模式,極大地減少了通信時間,加速比可達17.7。通過優化通信模式,以及基于MPI-ACL-OpenMP編程框架,本文實現的基于CPU-Matrix2000異構協同計算的并行程序,可以弱擴展到45萬核,相對5萬核并行效率保持在22.54%。作為未來工作,將探索如何繼續增強該異構程序的擴展性,以更好地發揮出HPC平臺的算力優勢。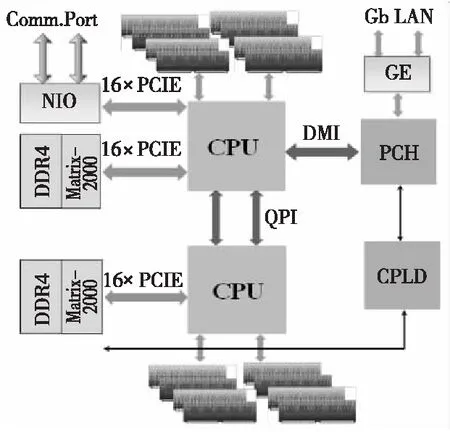
4.2 異構編程模型
4.3 OpenMP線程級并行
5 實驗及結果分析
5.1 測試環境及參數
5.2 通信優化測試
5.3 異構算法測試
6 結束語
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58人大建設(2019年12期)2019-05-21 02:55:44瞭望東方周刊(2017年42期)2017-12-05 18:49:38環球時報(2017-03-30)2017-03-30 06:44:45Coco薇(2016年2期)2016-03-22 02:42:52中國衛生(2015年3期)2015-11-19 02:53:32Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56民主與科學(2014年3期)2014-02-28 11:23:03教育與職業(2014年7期)2014-01-21 02:35:04
