基于憶阻器的計算存儲融合體系結構研究進展 *
2020-11-30 07:36:30方旭東吳俊杰
計算機工程與科學 2020年11期
關鍵詞:結構
方旭東,吳俊杰
(1.國防大學聯合作戰學院,北京 100091,2.國防科技大學計算機學院量子信息研究所兼高性能計算國家重點實驗室,湖南 長沙 410073)
1 引言
進入21世紀后,人類正加速邁入數字化時代,大數據、云計算、人工智能等的發展方興未艾,它們離不開海量數據的支撐。根據IDC(International Data Corporation)預測,人類所有的數量容量將從2018年的33 ZB快速上升到2025年的175 ZB,并且這種上升趨勢正在加劇[1]。
另一方面,傳統的基于CMOS工藝的存儲技術已經接近發展的極限,依靠縮小器件尺寸提高存儲器容量和密度的方法在可以預見的未來將變得不可行。所以,必須尋找不同于傳統CMOS器件存儲機理的新型存儲介質,來制造速度更快、容量更大、功耗更低、體積更小、壽命更長、可靠性更高的存儲器。
一個不容忽視的問題是,當前的計算機普遍采用馮·諾依曼體系結構,其運算和存儲分離的特性,使得存儲器和處理器多年來發展極不對稱,導致了存儲墻(Memory Wall)的出現,嚴重影響計算機性能的持續增長[2]。為了緩解甚至最終解決存儲墻問題,必須尋求新的計算使能器件。
憶阻器被發現是除電阻、電容、電感之外的第4種基本電路元件[3,4]。憶阻器具有可作為下一代存儲器件的諸多優異特性,包括高密度、低功耗、高耐久度、易于集成、CMOS工藝兼容性等特性,而且與動態隨機存取存儲器(DRAM)不同,憶阻器具有非易失特性,存儲的信息在掉電情況下也不會丟失[5]。
更為重要的是,憶阻器被證明具有融合計算和存儲的能力,被認為是一種全新的計算使能器件。2010年,惠普實驗室的研究人員實現了基于憶阻器的蘊含狀態邏輯(Stateful Logic),并證明這種計算是邏輯完備的[6]。這表明可以通過狀態邏輯計算對基于憶阻器的存儲結構中的數據進行直接處理,從而實現運算和存儲的有機融合。
此外,憶阻器所展現的阻值隨通過電量漸變的特性,和神經元細胞之間通過突觸傳遞信號的機制類似,使得憶阻器適合用于模擬神經元細胞,實現神經擬態計算[7-10]。
憶阻器所具備的優異特性,使得它成為一種使能器件,有望成為下一代存儲器件。基于憶阻器的計算存儲融合結構有望緩解甚至解決存儲墻問題,值得對其進行深入的研究。
然而,當前憶阻器尚處于實驗室制備階段,相關研究主要集中在器件機理和制備的層面,結構級研究較少,而面向應用的體系結構級研究則更少。鑒于此,本文按照從原理到結構再到應用的順序,對該領域相關研究進行綜述。首先詳細分析了狀態邏輯的實現原理以及改進方法,接著梳理了基于憶阻器交叉桿的狀態邏輯設計方法,然后概括了基于憶阻器的數據存儲結構的設計原理和實現結構,并探討了面向應用的計算存儲融合體系結構技術,最后進行總結和展望。
2 狀態邏輯計算
自從憶阻器被發現以來,關于憶阻器的應用研究如火如荼,涉及多個領域[11,12],主要有非易失性存儲器[13,14]、狀態邏輯計算[6,15 - 18]、神經擬態計算[7 - 10,19 - 22]等。在前2類應用中,憶阻器作為數字器件,主要利用其狀態可在高阻態HRS(High Resistive State)和低阻態LRS(Low Resistive State)快速翻轉的特性;在第3類應用中,憶阻器作為模擬器件,主要利用憶阻器阻值可根據外界電壓激勵連續變化的特性,模擬生物神經元細胞突觸實現神經擬態學習,以及構建混沌電路[23]。
本文內容限定于憶阻器狀態邏輯相關研究,即將憶阻器作為一種數字器件。狀態邏輯計算是基于憶阻器的高低阻態切換所實現的計算,計算的輸入輸出都采用憶阻器的阻值表示[6,16,24 - 27]。
2.1 實現原理
蘊含邏輯(Implication Logic)作為第1種被提出的狀態邏輯,具有十分重要的意義[6]。它證明了憶阻器電路可以進行狀態邏輯計算,實現計算和存儲的融合。蘊含邏輯的電路和真值表如圖1[6]所示。
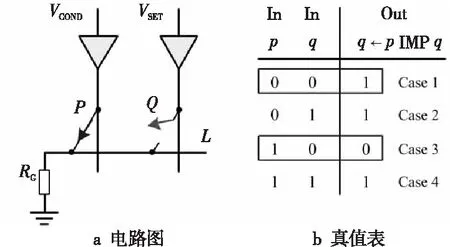
Figure 1 HP implication logic圖1 惠普蘊含邏輯
從圖1a中可以看出,蘊含電路由2個憶阻器P和Q,一個接地電阻RG,及水平與垂直納米線構成。水平納米線與垂直納米線通過憶阻器相連,并通過負載電阻RG接地。RG阻值介于憶阻器2個阻態的阻值之間,即ROFF>>RG>>RON。這里ROFF表示憶阻器高阻態的阻值,代表邏輯0,RON表示憶阻器低阻態的阻值,代表邏輯1。憶阻器P和Q具有閾值效應,閾值電壓的絕對值為VT,即只有當施加在憶阻器上的電壓的絕對值大于VT時,憶阻器的阻態才可能變化。若同時對P和Q施加電壓脈沖VCOND和VSET,即可完成蘊含操作,結果保存在Q的阻值中。此處,VCOND被稱為條件脈沖,VSET被稱為置位脈沖,p和q代表憶阻器P和Q的邏輯值。蘊含邏輯的工作原理可根據P的初始狀態,分以下2種情況解釋:
(1)當P處于高阻態(p=0)時,由于ROFF>>RG,所以RG上的電壓幾乎為0,于是Q2端的電壓VQ≈VSET(>VT)。此時,無論Q處于哪種狀態,都將被置為低阻態(q=1)。上述情況對應于圖1b中真值表的Case 1和Case 2。
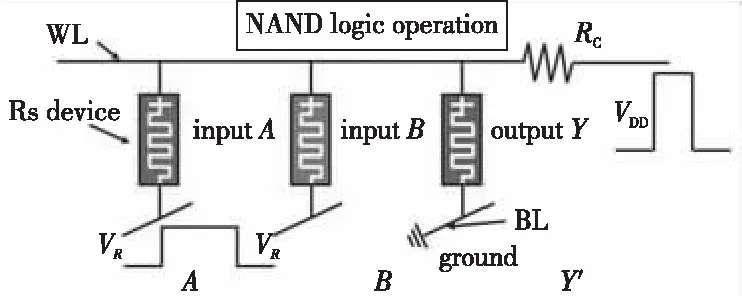
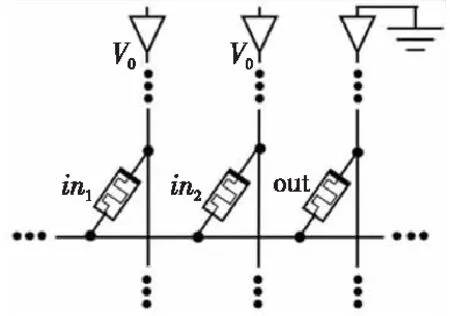
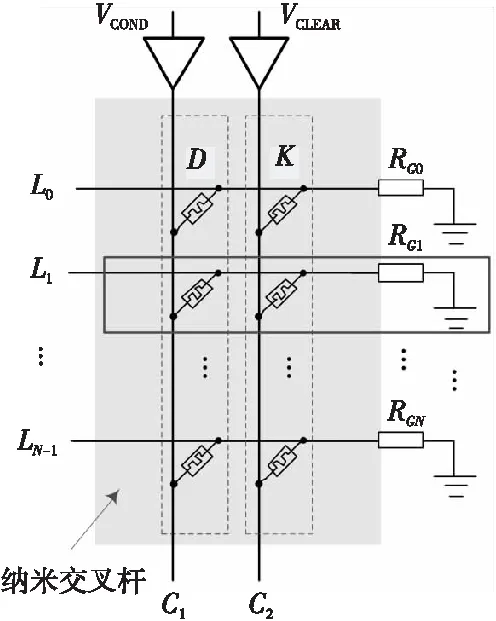
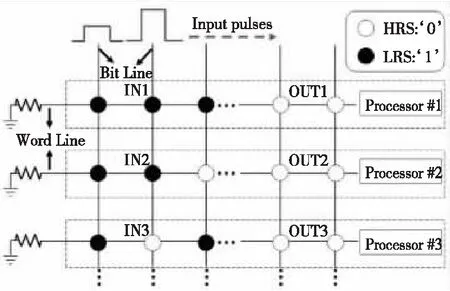
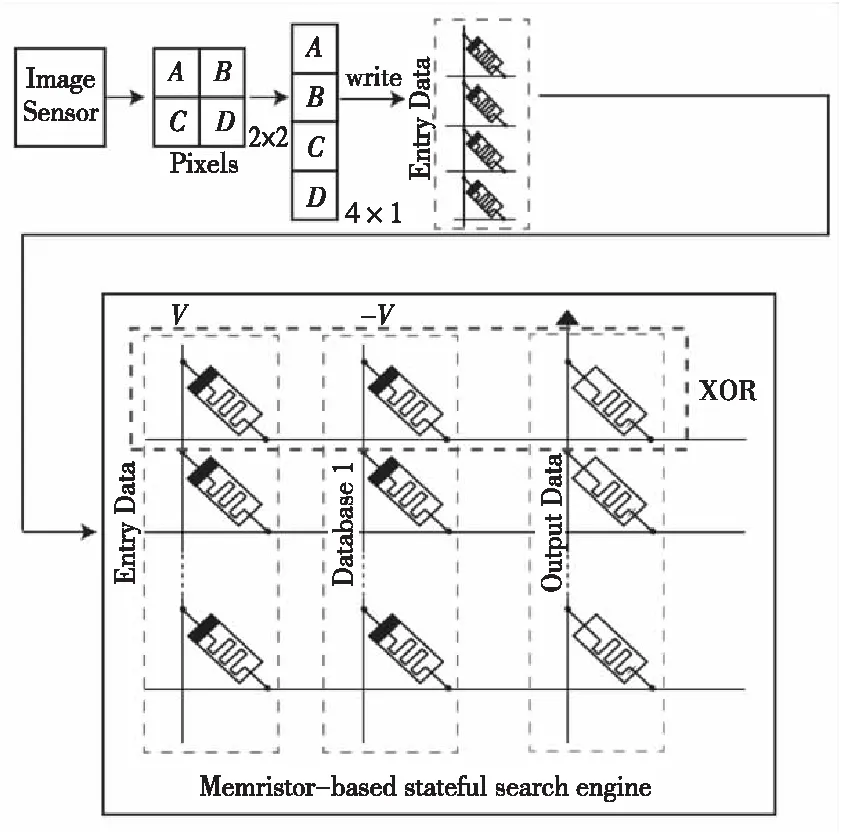
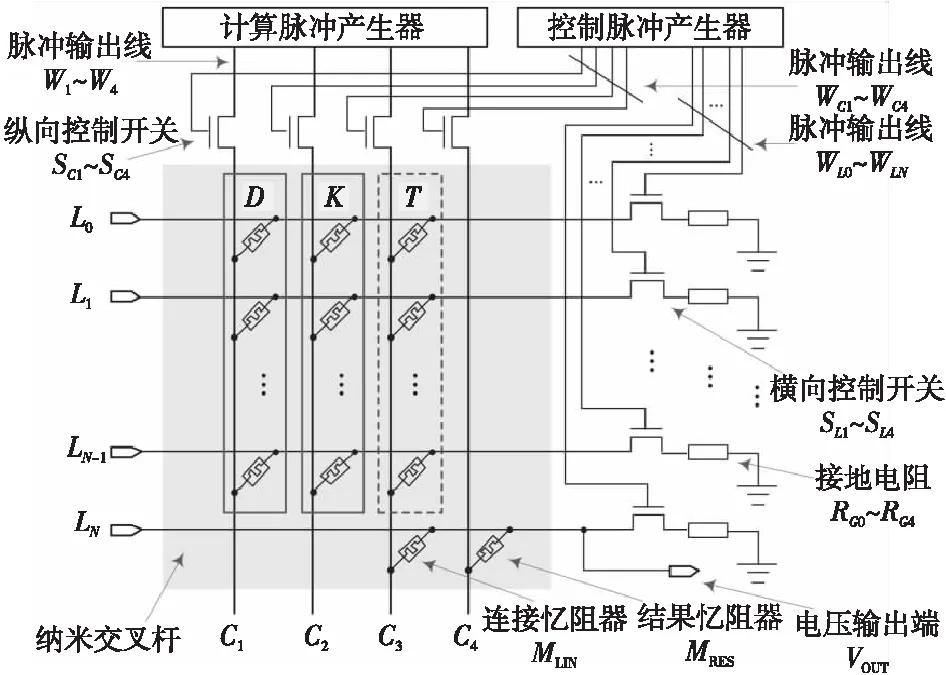
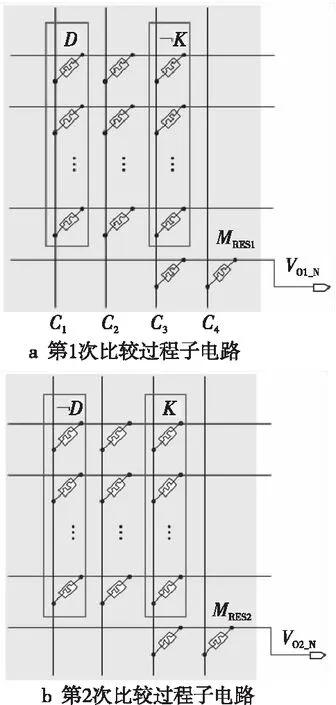
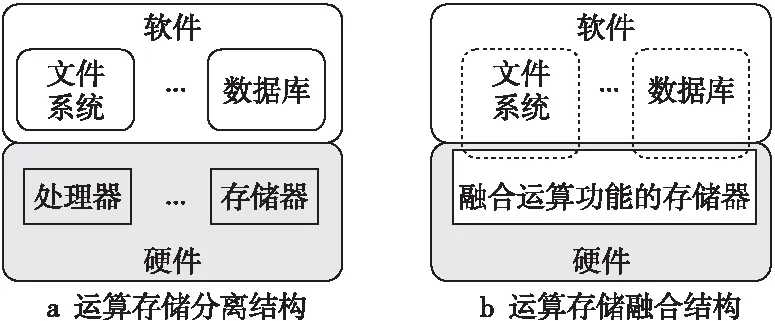
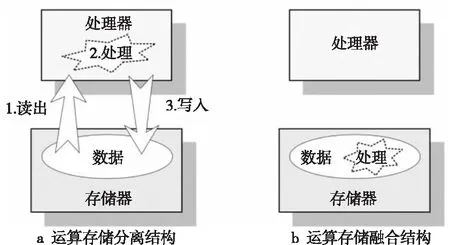
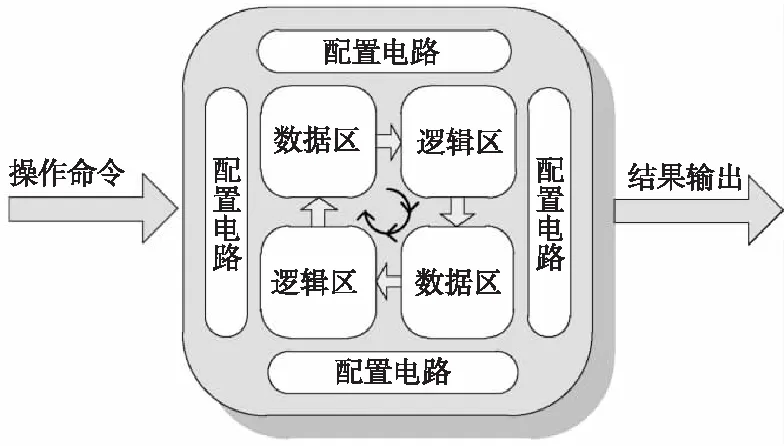
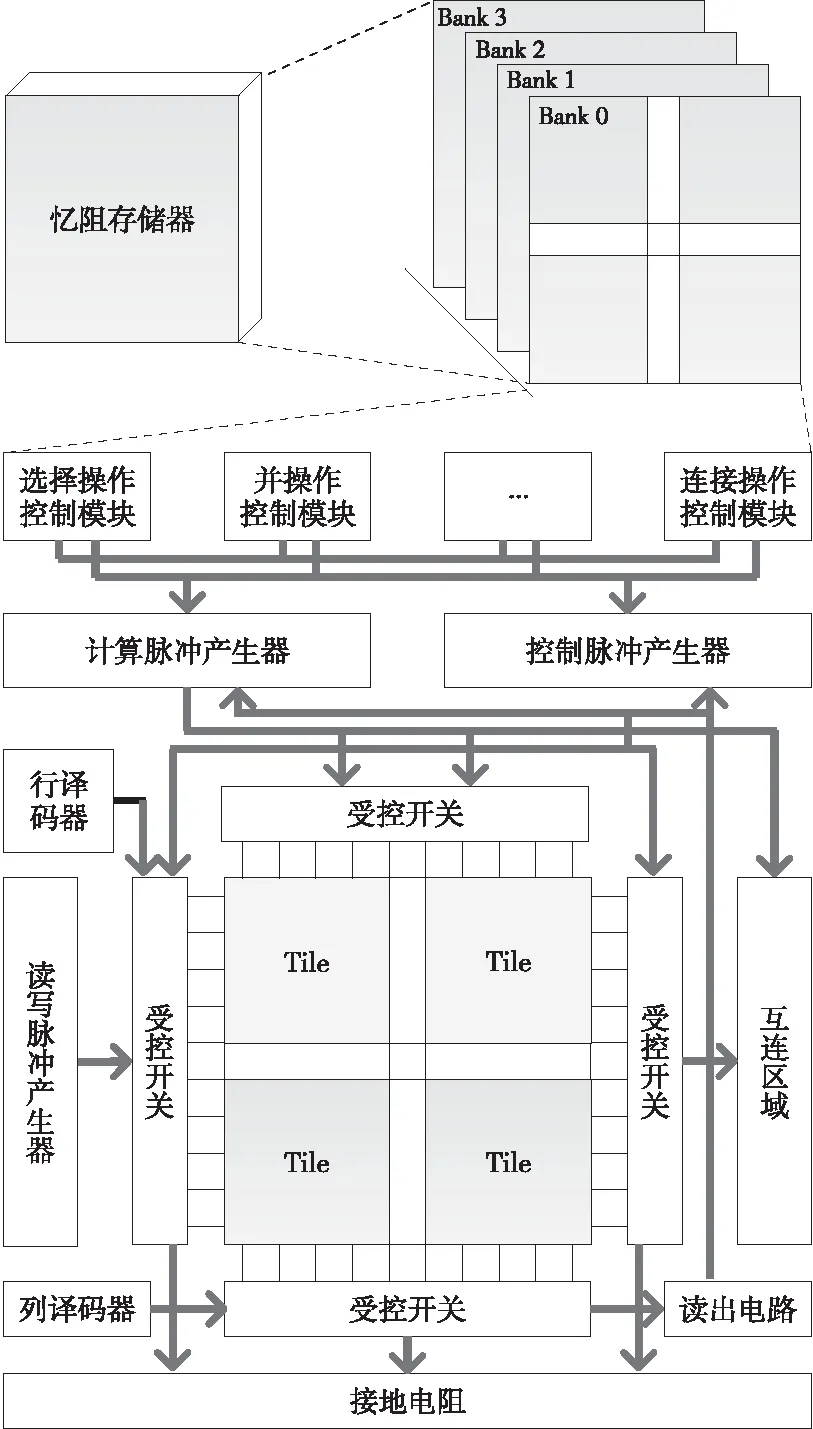
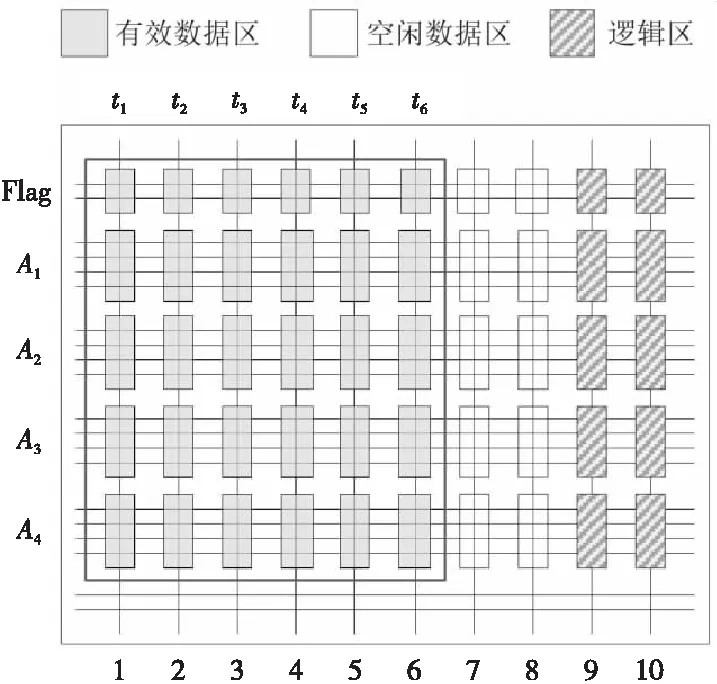
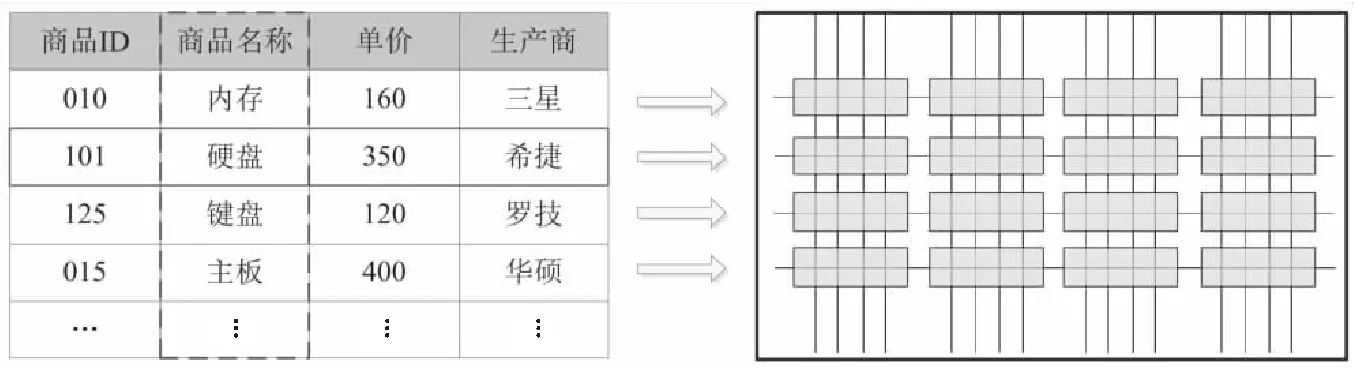
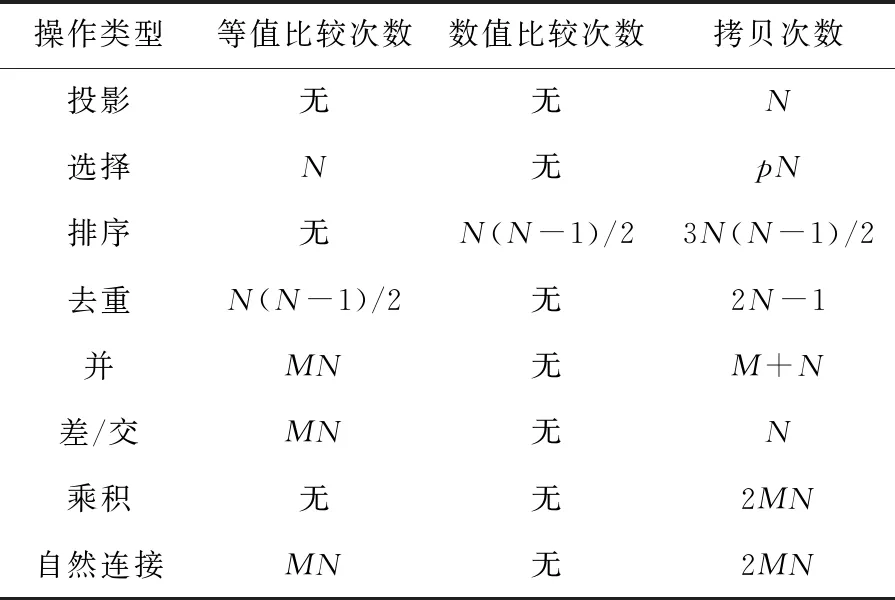
(2)當P處于低阻態(p=1)時,由于RG>>RONO,所以RG上的電壓幾乎為VCOND,于是Q2端的電壓VQ≈VSET-VCOND( 綜合上述2種情況,P和Q的狀態蘊含被計算出來,結果保持在Q的阻值中。 從圖1b的真值表可以看出,如果Q初始時處于高阻態(q=0),蘊含操作等價于對憶阻器P的值進行取反的FALSE操作。而如果單獨對一個憶阻器施加一個清零電壓脈沖VCLEAR(|VCLEAR|>VT),可以直接將憶阻器的阻值切換到高阻態(邏輯“0”)。 根據數理邏輯的基本原理可知,蘊含與取反運算構成邏輯完備集{IMP,FALSE},所有布爾邏輯運算都可以基于蘊含和取反操作實現。也就是說,基于憶阻器的狀態邏輯計算是完備的,可以實現所有的邏輯計算。 由惠普提出的蘊含邏輯,雖然是邏輯完備的,但也存在一定問題,主要表現在2個方面:一是運算效率較低,蘊含邏輯雖然是完備的,但復雜邏輯操作分解為蘊含邏輯需要較多操作步驟,效率較低,需要尋找與非(NAND)或者或非(NOR)等更高效的原子操作;二是運算過程會破壞輸入,圖1所示的蘊含邏輯中,憶阻器Q參與狀態邏輯計算,并保存計算結果,輸出結果有可能覆蓋輸入值,因此運算過程會破壞輸入。 3M1R邏輯就是對惠普蘊含邏輯的一種改進[17,28]。3M1R邏輯基本計算結構由通過字線WL(Word Line)和位線BL(Bit Line)相連的3個憶阻器A、B、Y和1個分壓電阻RC構成,如圖2[17]所示。通過在A和B上施加電壓脈沖VR,在Y上施加電壓脈沖VDD,3M1R可以1步實現與非(NAND)操作,而IMP邏輯和FALSE邏輯需要分3步才能實現NAND邏輯。3M1R電路結構本質上和惠普蘊含邏輯是一樣的,所以它也具備邏輯完備性,它的優點是邏輯操作不會破壞輸入狀態。 Figure 2 Schematic of the NAND gate in 3M1R圖2 3M1R實現NAND的邏輯電路 而MAGIC邏輯采用另一種改進思路[18]。MAGIC在實現或非(NOR)邏輯時,其基本電路單元由2個正向并聯的憶阻器和1個反向憶阻器串聯構成,如圖3[18]所示。和3M1R一樣,MAGIC不會破壞輸入狀態。和IMP、3M1R相比,MAGIC可以較高效地實現所有的邏輯操作,并且采用全憶阻器實現,從而容易實現交叉桿集成。此外,MAGIC運算時只需要1個電壓V0就可實現邏輯操作。MAGIC的缺點是脈沖電壓V0約束要求很高,實現不同的邏輯運算時的V0值不同,實際實現難度較大。 Figure 3 Schematic of the NOR gate in MAGIC圖3 MAGIC實現NOR的邏輯電路 有一類狀態邏輯的實現,是通過憶阻器2端不同的輸入電壓來實現憶阻器狀態翻轉,從而實現狀態邏輯計算的[29,30]。它的狀態轉化可以根據有限狀態機得出,但輸入輸出量綱不同,使得它們進行大規模交叉桿集成時難度更大。 還有一類狀態邏輯通過將多個單極性/雙極性憶阻器串聯/并聯,以對外呈現新的阻值切換特性,從而實現更高效的邏輯計算[15,31,32]。比如,DBM(Dual-Bit-Memristor)器件通過新的制備方法得到,等效于將1個單極性憶阻器和1個多極性憶阻器串聯到一起,從而得到更高效的狀態邏輯操作效率[32]。然而,這類器件的制備相對復雜,需要在器件復雜度和狀態邏輯操作效率之間進行折衷。 所有的狀態邏輯實現歸根結底是基于憶阻器阻值的條件切換特性,通過時間維度上的分步迭代來實現邏輯功能。狀態邏輯的最大優勢在于邏輯完備的計算在存儲中發生,而且代表輸入、輸出的物理量都是阻值,可以方便實現級聯,甚至可通過流水線實現并行邏輯操作。狀態邏輯具有的計算和存儲融合能力,使得這種計算結構有可能超越經典的馮·諾依曼體系結構。 第2節中提到狀態邏輯計算是單比特的計算,為了充分發揮狀態邏輯在存儲位置直接進行計算的優勢,必須將狀態邏輯從單個比特位拓展到多個比特位,或者說并行計算的模式。為了實現并行狀態邏輯計算,首先應該在交叉桿中實現基本邏輯的并行操作。更進一步,應該設計出基于更通用的、抽象層次更高的公共操作,為高層操作實現提供基礎。 基于憶阻器交叉桿結構,將基本蘊含邏輯操作從一維(單比特)擴展到多維(多比特并行)是非常直觀的。圖4[33]展示了規模為2×N的交叉桿,它由N條水平納米線和2條垂直納米線組成,其中存儲了2個N位數據D(d0d1…dN-1)和K(k0k1…kN-1)。垂直納米線稱為字線,水平納米線稱為位線。那么,圖4中任意一條位線上的2個憶阻器,以及該位線的接地電阻這三者組成了1個單比特與(AND)邏輯電路。所以,N條位線上一共有N個與邏輯電路。如果在字線C1和C2上分別施加電壓脈沖VCOND和VCLEAR,那么N個與操作將并行執行[33]。執行完成后,K中存儲的數據是D和K按位與的結果。按同樣的方法,可以將基本狀態邏輯擴展成為對應的并行邏輯。和單比特狀態邏輯相比,并行狀態邏輯有望將操作的效率提高N倍,N表示位線長度,即并行度。 Figure 4 Schematic of the parallel AND gate圖4 并行與邏輯實現電路 iMemComp進一步給出了動態實現并行狀態邏輯操作的方法[34]。iMemComp將交叉桿的每一行都稱為一個“處理器”,即由一條字線和多條位線交叉處的憶阻器形成邏輯門電路。這些一位的“處理器”在交叉桿中同時受到電壓激勵,從而實現并行狀態邏輯計算,如圖5[34]所示。圖5中HRS指高阻態(邏輯0),LRS指低阻態(邏輯1),IN和OUT分別指代輸入和輸出憶阻器。 Figure 5 Parallel computing schematic in iMemComp based on multiple one-bit processors圖5 iMemComp中多個單比特“處理器”并行邏輯計算結構 iMemComp的優點是在每個“處理器”中設置了一些可配置的憶阻器,用來實現可重構計算。所謂可重構計算,是指不改變電路結構的情況下,通過重置操作(RESET)設置憶阻器的阻值,使得相同的電路實現不同的狀態邏輯計算。 拷貝操作將交叉桿中的N位數據拷貝到交叉桿的另一個位置,是實現交叉桿中數據遷移,支持狀態邏輯重構,進而構建高層體系結構的一個重要操作。 在圖4中,如果存儲K的憶阻器預先被置位,那么并行與邏輯實現的效果等價于并行復制邏輯,即D被拷貝到存儲K的憶阻器中。這樣的并行復制邏輯被稱為拷貝邏輯[33]。從上述過程可以看出,只需要2個時間步,就可以實現憶阻器交叉桿中2個N位數據之間的拷貝操作。 比較操作是一種較為重要的邏輯操作,其中判斷2個N位數值是否相等的等值比較是比較操作的基礎,被廣泛應用于微處理器、通信系統和控制系統中。比如,在微處理器中,等值比較器用來判斷流水線中前后2條指令是否數據相關,從而決定流水線是否需要暫停;在通信系統的路由芯片中,等值比較器用于檢測到達的數據包攜帶的目的地址和路由器地址是否相等,從而決定接收或是轉發該數據包;控制系統中,等值比較器用于檢測控制變量(時間、溫度等)是否達到預設值,從而決定是否觸發相應控制動作。 一種基于并行異或(XOR)狀態邏輯實現的等值比較結構如圖6[35,36]所示。采用該結構,輸入的二維像素值首先被轉化為一維,并被編碼到N位輸入憶阻器(Entry Data)。輸入憶阻器和交叉桿上的模式憶阻器(Database 1)執行并行異或操作,得到每一位的異或比較結果,形成N位的輸出值(Output Data)。N位輸出值再通過數字比較器(Digital Comparator)進行轉化,最終結果由一個模擬憶阻器的阻值表示。該方法的優點是利用了憶阻器交叉桿執行狀態邏輯的并行性。但是,在綜合N位輸出值得出比較結果時,采用了數值比較器,結果又采用模擬憶阻器表示,導致外圍電路龐大,不易集成。 Figure 6 Graphic pixel comparison schematic based on parallel XOR logic gate圖6 基于并行異或邏輯實現的圖形像素比較操作結構 國防科技大學憶阻器研究團隊提出了通用等值比較邏輯[33]。對2個N位數據D(d0d1…dN-1)和K(k0k1…kN-1)進行等值比較,分解為表達式: ∨(dN-1∧kN-1)]∧ (1) 實現表達式(1)的N位等值比較電路由1個憶阻器交叉桿陣列、N+5個CMOS控制開關、1個計算脈沖產生器、1個控制脈沖產生器、N+1個接地電阻5部分組成,如圖7[33]所示,其中,N為等值比較電路能比較的數據位數(或者說字長)。 Figure 7 Universal N-bit equivalent comparison logic circuit圖7 通用N位等值比較邏輯電路 等值比較過程被分解為2次比較過程,每次比較過程都由“清零—取反—或非—讀取”4個操作組成,分別完成式(1)式中2個或非邏輯表達式的計算。如果其中任何1次子比較過程完成后,結果憶阻器的阻值為高阻態(邏輯0),那么可以判定D和K不相等;如果2次比較過程之后,結果憶阻器的阻值都為低阻態(邏輯1),那么可以判定D和K相等。 (1)清零。清零操作所要達到的效果是使得存儲中間結果T(t0t1…tN-1)的憶阻器T0T1…TN-1和結果憶阻器MRES被置為高阻態(邏輯0)。 (2)取反。將數據K(k0k1…kN-1)按位求反結果(k0k1…kN-1)命名為K。此時,K被保存到中間結果憶阻器T0T1…TN-1中,得到中間計算結果T(t0t1…tN-1)。 (3)或非。或非操作完成了式(1)的第1個子表達式的運算,運算結果保存在憶阻器MRES中。 (4)讀取。如果VOUT的輸出接近0,那么結果憶阻器MRES處于最大阻值狀態(ROFF),于是式(1)的第1個或非表達式的計算結果為0,所以式(1)的值必為0,故D和K不相等,比較過程結束;如果VOUT的輸出接近讀脈沖VREAD,那么結果憶阻器MRES接近最小阻值狀態(RON),于是式(1)的第1個子表達式的計算結果為1,此時式(1)的值尚無法確定,需要進行第2次比較過程,比較過程類似。 第1次比較過程中的每一步,圖7中計算脈沖產生器的輸出線W1~W4、控制脈沖產生器的縱向控制脈沖輸出線WC1~WC4和橫向控制脈沖輸出線WL0~WLN上應產生的脈沖如表1[33]所示,其中,計算脈沖包括以下4種脈沖:幅度為VCLEAR的清零脈沖、幅度為VCOND的條件脈沖、幅度為VSET的置位脈沖和幅度為VREAD的讀脈沖;而控制脈沖為VSOPEN。 采用通用等值比較邏輯的實現方法進行2個多位數據之間的比較,最少只需4個時間步得出2個數據不相等的比較結果,最多需要8個時間步得出2個數據相等的比較結果。該方法的優點是,比較過程全部采用狀態邏輯實現,易于交叉桿集成,而且在最壞情況下,比較次數不會隨著比較數據的字長的增大而增加。缺點是比較時間步不是常量。 專用等值比較邏輯是對通用等值比較邏輯的一種改進[33]。通過觀察可以發現,采用狀態邏輯計算式(1)中的2個或非邏輯表達式時,除了輸入不同,計算步驟是相同的。專用等值比較邏輯的電路由2套完全相同的電路組成,每一套都和通用等值比較邏輯的電路(如圖7所示)完全一致。待比較數據D(d0d1…dN-1)和K(k0k1…kN-1)以及它們的按位互補值D(d0d1…dN-1)和K(k0k1…kN-1),被分別存儲在圖8a和圖8b中,因此等值比較的比較過程中不再需要進行清零和求反操作。 專用等值比較邏輯在保留通用等值比較邏輯優點的基礎上,采用空間換時間的方式,增加了邏輯電路,但縮短了實現等值比較所需的時間步。采 Figure 8 Dedicated equivalent comparison logic circuit圖8 專用等值比較邏輯電路 用專用等值比較邏輯實現方法,進行2個多位數據之間的比較,最少只需3個時間步就可以得出2個數據不相等的比較結果,最多只需4個時間步就可以得出2個數據相等的等值比較結果。相比通用的等值比較邏輯實現,最好情況和最壞情況下比較的效率都有大幅改進。 為了充分利用狀態邏輯計算和存儲融合的優勢,以及基于憶阻器交叉桿的存儲器具有的高密度、存儲非易失的優點,必須設計適當的數據存儲結構。本節介紹“數據HOME自治”的概念,以及基于“數據HOME自治結構”的憶阻存儲器結構[33,37 - 39]。 數據HOME自治定義:數據可在其存放位置進行不受外界干擾的自我管理,實現預定的操作和服務的數據處理機制[33]。 Table 1 Voltage pulse sequence of the first comparison process in the Universal N-bit equivalent comparison logic 這里,“數據HOME”指存放數據的宿主。計算機中,“數據HOME”即是存儲器芯片。“自治”指存儲系統能夠不受外界干擾,自我管理實現預定的操作和服務。 圖9[33]從靜態角度闡述了“數據HOME自治”原理。傳統計算結構下,運算與存儲分離,與數據存儲相關的上層軟件(文件系統、數據庫等)只能通過處理器配合存儲器完成各種數據操作,如圖9a所示。而如果可以實現運算和存儲的融合,以前依賴軟件在處理器上運行才能完成的部分功能被固化到存儲器中,如圖9b所示。存儲器依靠自身的運算能力完成特定的數據操作,比如數據查詢、訪問控制、糾檢錯和加解密等。 Figure 9 Static interpretation of the “Data Home Autonomy” principle圖9 “數據Home自治”原理靜態解釋 圖10[33]從動態角度對比了2種結構下數據處理的過程。馮·諾依曼體系結構下,數據存儲和數據處理在空間上分離,導致了存儲墻問題,如圖10a所示。而采用運算存儲融合結構,對數據的部分處理在存儲器中完成,如圖10b所示。 Figure 10 Dynamic interpretation of the “Data Home Autonomy” principle圖10 “數據HOME自治”原理動態解釋 “數據HOME自治”使得:(1)通過減少數據的讀出寫入,降低了數據被非法訪問的風險;(2)由于部分數據處理在存儲器中完成,極大緩解了存儲墻問題的壓力;(3)存儲器中容易以更高的并行度實現更細粒度的數據處理,比如在位級(bit)或字級(word)完成一些數據操作(例如數據比較等),提高了數據處理的效率。 數據HOME自治結構定義:把采用數據HOME自治原理實現的存儲結構稱為“數據HOME自治結構”,或者稱為“數據HOME自治體”[33]。 “數據HOME自治”的原理用于指導實現“數據HOME自治結構”時,要求:(1)底層器件必須具備融合計算和存儲的能力,或者說邏輯區域和存儲區域的輪換能力。這就要求數據區和存儲區工藝兼容,并且結構等價。(2)可以實現計算存儲的融合,在數據所在位置進行計算。 傳統CMOS工藝中,處理器和存儲器兩者目標不同,導致制作工藝和封裝工藝都不同,所以傳統CMOS器件不滿足這2個要求,而憶阻器則完全不同。對于基于憶阻器交叉桿的存儲結構而言,數據區即是邏輯區,邏輯區即是數據區,兩者都基于交叉桿結構,功能和特性上完全等價。狀態邏輯則能實現計算存儲的融合。 一種可能的基于憶阻器的“數據HOME自治”結構如圖11[33,37,38]所示。從圖11中可以看出,該結構由數據區、邏輯區和配置電路3個部分組成。其中,數據區用于存儲數據;邏輯區進行邏輯運算,用于對區域內的數據進行處理;配置電路配合邏輯區完成運算并控制數據區和邏輯區的輪換。 Figure 11 Memristor-based “DATA HOME Autonomy” structure 圖11 基于憶阻器的“數據 Home 自治”結構 基于憶阻器的“數據HOME自治”結構所具備的這種融合計算和存儲的能力,使得它只需接收特定的操作命令,就可啟動自治結構內部的數據處理過程,并視情況輸出處理結果。處理過程中無需CPU干預,計算在數據所在位置進行,除內部的數據傳輸之外,基本不存在存儲層次間的數據傳輸過程(輸出處理結果除外),從而大大節省了數據開銷。所以,基于憶阻器的“數據HOME自治”結構有望極大提高特定計算的效率,有效緩解傳統計算架構中的存儲墻問題。 根據“數據HOME自治”原理和基于憶阻器的“數據HOME自治”結構,圖12展示了一種憶阻存儲器結構[33,37 - 39]。憶阻存儲器可由多個Bank構成,而每個Bank又由多個憶阻Tile和多個功能部件構成。圖12中的憶阻存儲器由4個憶阻Bank 構成,其中Bank 0中包含4個憶阻Tile和多種功能部件。 Figure 12 Memristive memory architecture圖12 憶阻存儲器結構 憶阻Tile是指憶阻存儲器中用于數據存儲和邏輯運算的憶阻器交叉桿區域,是憶阻存儲器中數據的駐地,也是對數據進行狀態邏輯操作的基本單位。一種可能的憶阻Tile結構如圖13[33]所示。 Figure 13 Memristive Tile structure圖13 憶阻Tile結構 操作控制模塊負責控制計算脈沖產生器和控制脈沖產生器。在憶阻存儲器上進行的操作不管多么復雜,最終都是通過Tile上的狀態邏輯操作實現的。操作控制模塊能夠產生公共基本操作所需的計算脈沖序列和控制脈沖序列的功能模塊,可以根據不同需求對憶阻器Tile進行配置和重構。 圖12中的憶阻存儲器結構和圖13中的憶阻Tile結構設計基本涵蓋了近期關于支持狀態邏輯計算的存儲結構設計[17,30,40-49],這些狀態邏輯電路設計一般都包含憶阻器交叉桿結構設計、外圍電路以及脈沖序列產生方法3部分。該設計的優勢是以“數據HOME”結構為理論指導,設計了功能模塊完整的、具有自主運算能力的存儲結構。缺點是受制于器件制備能力,并沒有制作出實際的憶阻存儲器。 體系結構研究最終是為了面向應用,提高應用的執行效率。然而,并不是所有應用都可通過采用基于憶阻器的“數據HOME自治”結構帶來性能加速。一般來說,實施“數據HOME自治”對應用的數據存儲特性和處理特性都有要求。 “數據HOME自治”結構要求應用所處理的數據必須是結構化的。憶阻存儲結構是基于交叉桿實現的。交叉桿結構非常規整,適合存儲結構規整、類型統一的結構化數據,而不適合存儲非結構化數據。 “數據HOME自治”結構要求應用所進行的數據處理任務必須是簡單的。狀態邏輯是一種用時間換空間的操作,如果對數據的操作過于復雜,轉化成狀態邏輯操作序列可能過長,從而導致實現效率低下。而某些操作的復雜度可能超出了狀態邏輯可以接受的范圍,必須由CPU來完成。如果應用對數據的操作包含大量簡單同質化操作,則適合采用狀態邏輯實現。 應當按照這2個要求去尋找適合“數據HOME自治”結構實現的應用。然而即使找到了適合的應用,面向應用進行自上而下全流程體系結構設計的工作并不多見。國防科技大學憶阻器團隊開展了面向關系數據庫存儲體系結構[33]、存儲加密體系結構技術[37]、圖像處理體系結構[38,50]、自治容錯體系結構技術[39]4個方向的體系結構級研究。下面以基于憶阻器的關系數據庫存儲體系設計為例,闡述相關設計思路。 關系數據庫作為目前最重要的數據處理模型和工具,在當前乃至未來相當長的一段時間內仍將廣泛使用。關系數據庫的存儲特性和操作特性非常適合采用“數據HOME自治”結構實現,并且憶阻存儲器將有效提高關系數據庫的性能[33]。 在設計存儲結構時,他們采用了將二位數據表映射到物理存儲(交叉桿)中的實現方式,如圖14[33]所示。這種數據存儲設計的優點是直觀,并且支持記錄的隨機尋址。 Figure 14 A data table and its possible mapping to the memristor crossbar圖14 數據表及其在憶阻器交叉桿上可能的映射方式 所有數據庫的數據操作歸類為單元組一元操作、全關系一元操作和全關系二元操作。其中,單元組一元操作包括掃描操作、選擇操作和投影操作;全關系一元操作包括去重操作、排序操作和分組操作;全關系二元操作包括并/交/差操作、乘積操作和連接操作。他們通過分析這些操作的底層實現機理,將這些操作完全通過比較和拷貝2種操作實現,并設計了在憶阻存儲器中高效實現這些操作的方法。 值得一提的是,設計憶阻存儲器中關系數據庫查詢操作的實現方法,基于如下嚴格的假設: (1)假設憶阻存儲器上可以實現元組拷貝操作和比較操作; (2)假設關系數據已存儲在憶阻存儲器Tile中; (3)只關心查詢操作的實現過程,不考慮對查詢結果的處理; (4)待查詢的關系和結果關系的所有元組都可容納在一個基本Tile或者擴展Tile內; (5)進行操作的記錄之間都是按位對齊的,并且進行的比較操作都是對元組之間的關鍵字進行比較。 Table 2 The worst case complexity analysis of the query operation in the memristive memory 為了對基于憶阻存儲器的關系查詢操作進行分析和評價,設計了憶阻存儲器的性能模型。該模型對憶阻存儲器中進行關系數據庫單元組一元操作、全關系一元操作和全關系二元操作等查詢操作的時間開銷進行分析。若用N和M分別代表關系R和關系S中的元組數目,那么這些操作在最壞情況下的計算復雜度如表2所示。通過HSPICE對這些單元組一元操作、全關系一元操作和全關系二元操作進行模擬測評,并和基于磁盤的關系查詢操作進行對比發現,面向關系數據庫的存儲體系結構以及憶阻存儲器可以有效地加速關系數據庫的基本查詢操作[33]。 隨著CMOS器件逼近物理尺寸極限,業界一直在尋求新型使能器件或者技術,以延續摩爾定律。其中,基于憶阻器的狀態邏輯就是一種極有發展前景的使能技術。狀態邏輯可以實現真正意義上計算和存儲的融合,有望開創全新的計算架構。 為了研究基于憶阻器的計算存儲融合體系結構,本文按照從原理到結構再到應用的順序展開論述。首先闡述了惠普實驗室提出的蘊含狀態邏輯的實現原理,針對其存在的缺點,詳細介紹了2種狀態邏輯改進方法。接著探討將狀態邏輯從單比特位操作擴展為多比特位并行操作的方法,闡述拷貝操作和比較操作的實現方法。然后介紹了數據HOME自治原理,概括基于憶阻器的數據存儲結構的設計原理和實現結構。最后以關系數據庫存儲體系結構設計為例,探討了面向應用的計算存儲融合體系結構技術。 然而,當前基于憶阻器狀態邏輯的面向應用的體系結構還處于理論設計階段。原因是多方面的:(1)因為對于憶阻器的器件級機理的研究一直在深入,制備憶阻器材料的選擇尚無定論,研究人員還在尋求均一性更好、切換效應更明顯、器件狀態偏移更小的憶阻器;(2)憶阻器交叉桿內在的寫串擾、寄生電阻(電容)、潛通路等問題,嚴重影響著交叉桿規模的擴展;(3)和CMOS計算相比,狀態邏輯計算采用時間換空間的方法獲取優勢,但對于復雜邏輯操作,需要迭代執行的時間步驟,以及由此帶來的外圍電路的開銷,很可能得不償失;(4)設計狀態邏輯時,缺少自動化設計工具支持。這些因素限制了憶阻器從實驗室走向實用。 以上提到的4個方面研究應該并重,在可見的將來,基于憶阻器的狀態邏輯計算應該提高執行穩定性和效率,充分利用交叉桿的并行性,開發更高效的原子操作,如多位數據的大小比較等,并找準應用領域,設計面向應用的高層體系結構,成為特定應用的高效加速部件。同時,應和CMOS電路結合設計,發揮各自的優點。2.2 狀態邏輯優化研究
2.3 狀態邏輯分類
3 基于憶阻器交叉桿的狀態邏輯設計
3.1 基本邏輯并行實現
3.2 拷貝操作
3.3 比較操作
4 基于憶阻器的數據存儲結構
4.1 數據HOME自治原理

4.2 基于憶阻器的數據HOME自治結構
4.3 憶阻存儲器結構設計
5 面向應用研究
5.1 “數據HOME自治”結構對應用的要求
5.2 關系數據庫存儲體系結構技術
6 結束語
猜你喜歡
小獼猴智力畫刊(2023年4期)2023-04-23 08:49:58
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中學生數理化·高一版(2018年1期)2018-02-10 05:20:03
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
七彩語文·寫字與書法(2016年7期)2016-07-28 21:40:22
七彩語文·寫字與書法(2016年6期)2016-07-15 19:36:34
人間(2015年21期)2015-03-11 15:23:21
現代企業(2015年9期)2015-02-28 18:56:50
