面向HPC互連網(wǎng)絡(luò)的低延遲前向糾錯編碼研究與實現(xiàn) *
2020-11-30 07:36:32曹繼軍賴明澈徐煒遐
計算機(jī)工程與科學(xué) 2020年11期
王 超,曹繼軍,羅 章,賴明澈,徐煒遐
(國防科技大學(xué)計算機(jī)學(xué)院,湖南 長沙 410073)
1 引言
面向HPC的高性能互連網(wǎng)絡(luò)的特征是高帶寬、低延遲和高可靠等。數(shù)據(jù)在網(wǎng)絡(luò)物理信道中傳輸往往不能保證完全無誤,而且隨著傳輸速率的不斷提升,數(shù)據(jù)傳輸通道產(chǎn)生錯誤的概率也會增大。要保證數(shù)據(jù)傳輸可靠主要有3種方式:自動反饋重傳(Automatic Repeat-Request)、前向糾錯(Forward Error Correction)、混合重傳(Hybird Automatic Repeat Request)。當(dāng)前,主流高性能互連網(wǎng)絡(luò)端口速率已達(dá)到100~400 Gbps,其單通道速率已達(dá)到25~50 Gbps[1,2]。以這種速率傳輸數(shù)據(jù),使用較多的是混合重傳方式,即發(fā)生少量錯誤時,可以由前向糾錯碼糾正,超出前向糾錯碼糾錯能力時,進(jìn)行反饋重傳,這就需要采用合適的前向糾錯編碼。前向糾錯原理就是在數(shù)據(jù)發(fā)送之前編碼端根據(jù)一定的編碼規(guī)則增加一定的冗余,使原來不具有相關(guān)性的數(shù)據(jù)產(chǎn)生相關(guān)性,在譯碼端根據(jù)譯碼規(guī)則,利用冗余所產(chǎn)生的數(shù)據(jù)相關(guān)性來糾正信道中發(fā)生的錯誤,恢復(fù)發(fā)送的碼序列。
糾錯編碼有很悠久的歷史,自1950年提出漢明碼發(fā)展到現(xiàn)在有很多子類,還包括BCH碼、RS碼、TURBO碼和LDPC碼等[3],但它們各有優(yōu)缺點,目前比較前沿的是TURBO碼和LDPC碼,但TURBO碼的延遲過大,LDPC碼由于良好的性能需要比較長的碼長且實現(xiàn)復(fù)雜,因此這2種糾錯碼不符合互連網(wǎng)絡(luò)高效性的要求。由于RS編碼是迄今為止發(fā)現(xiàn)的一類很好的線性糾錯碼,其糾錯能力很強(qiáng),特別是在較短和中等碼長下,性能接近于理論極限,且構(gòu)造方便,編碼和譯碼相對規(guī)則簡單,因此被廣泛應(yīng)用于光傳輸系統(tǒng)、數(shù)據(jù)存儲、數(shù)字電視、衛(wèi)星通信、深空探測和互連網(wǎng)絡(luò)等多種領(lǐng)域。
當(dāng)前IEEE 802.3以太網(wǎng)規(guī)范中100 Gbps技術(shù)標(biāo)準(zhǔn)采用RS(528,514)和RS(544,514)2種碼型的編碼子層[4],200/400 Gbps技術(shù)標(biāo)準(zhǔn)采用RS(544,514)碼型的編碼子層。RS-FEC編解碼在提高糾錯能力的同時,存在譯碼延遲大等問題,就這2種RS編碼而言,RS(528,514)延遲比RS(544,514)低,但糾錯能力相對較差。對于延遲較為敏感的高性能計算應(yīng)用而言,在保證數(shù)據(jù)傳輸可靠性要求的前提下,延遲要求越低越好,這2種RS碼延遲較大,難以滿足延遲敏感型計算應(yīng)用的通信需求。因此,研究低延遲的RS-FEC編碼對高速互連網(wǎng)絡(luò)發(fā)展具有重要意義。
2 RS編解碼延遲分析
RS碼是1960年由Reed和Solomon提出的[4],RS碼是BCH碼的一種分支,GF(q)上(q≠2,通常q=2m),碼長n=q-1的本原BCH碼稱為RS碼。GF(2m)域中,RS碼型一般表示為RS(n,k),其中m表示符號長度,例如m=8表示符號由8位二進(jìn)制數(shù)組成;n=2m-1表示碼塊長度;k表示碼塊的信息長度;K=n-k表示碼塊的校驗元長度;t=(n-k)/2表示能夠糾正的錯誤數(shù)目。
GF(2m)域中,n=2m-1的RS碼型通常稱為系統(tǒng)碼或母碼,可以通過減小n或k變?yōu)榭s短碼或打孔碼,但會失去循環(huán)碼的特性,不再是循環(huán)碼。例如,當(dāng)前IEEE 802.3以太網(wǎng)規(guī)范使用的RS(528,514)和RS(544,514)均為縮短碼。其中RS(528,514)中以10位二進(jìn)制數(shù)為1個符號,碼長為528個符號,信息碼塊為514個符號,校驗碼塊為14個符號,最多糾正7個錯誤。
2.1 RS編碼原理
RS碼的編碼原理是根據(jù)一定的編碼規(guī)則增加一定的冗余,使原來不具有相關(guān)性的數(shù)據(jù)產(chǎn)生相關(guān)性,主要有基于乘法、除法和校驗多項式3種編碼器。其中基于除法的編碼流程分為以下3步:
(1)將信息多項式m(x)預(yù)乘xn-k,即右移n-k位,得到nx-km(x)。
(2)將nx-km(x)除以生成多項式g(x)[5,6],得余式r(x),其中g(shù)(x)確定了唯一的RS(n,k)碼。
(3)由nx-km(x)+r(x) =c(x),即得到編碼后的碼字多項式。
圖1為基于除法的編碼器結(jié)構(gòu)示意圖[7]。

Figure 1 Structure of encoder based on division圖1 基于除法的編碼器結(jié)構(gòu)示意圖
2.2 RS譯碼原理
譯碼原理是利用冗余所產(chǎn)生的數(shù)據(jù)相關(guān)性來糾正信道中發(fā)生的錯誤,恢復(fù)發(fā)送的碼序列。通用的譯碼流程[8]分為以下5步:
(1)由接收多項式R(x)求出伴隨式Sj,j=1,2,…,2t。
(2)根據(jù)伴隨式Sj求解關(guān)鍵方程,得出錯誤多項式σ(x)和錯誤值多項式ω(x)。
(3)用錢搜索算法[9]解出錯誤多項式σ(x)的根,得到錯誤位置。
(4)用福尼公式[9]計算錯誤值,得到錯誤圖樣E(x)。
(5)計算M(x)=R(x)-E(x),完成糾錯。
圖2為RS譯碼結(jié)構(gòu)示意圖。
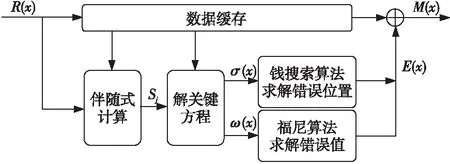
Figure 2 Structure of decoder圖2 譯碼結(jié)構(gòu)示意圖
2.3 RS延遲分析
RS編解碼延遲包括數(shù)據(jù)發(fā)送端的編碼延遲和數(shù)據(jù)接收端的解碼延遲,編碼延遲主要是編碼邏輯電路的固定延遲,由于數(shù)據(jù)編碼不需要緩存參與,相對較小,因此RS-FEC的處理延遲主要來源于譯碼過程。根據(jù)譯碼流程,譯碼過程大致可分為3個過程:(1)伴隨式計算;(2)關(guān)鍵方程求解;(3)Chien搜索算法、Forney算法求解和糾錯輸出。在不考慮多路并行的情況下,伴隨式計算需要的時間約為k/δ,其中k為信息數(shù)據(jù)長度,δ為每周期傳輸?shù)臄?shù)據(jù)長度;關(guān)鍵方程的求解時間約為2t,其中t為校驗元長度;Chien搜索算法、Forney算法求解和糾錯輸出的求解時間約為k/δ,因此總的譯碼延遲約為2k/δ+2t,即碼長和校驗元長度越長,延遲越大。因此,減小碼長或校驗元長度都可以減小FEC處理延遲。
3 新型低延遲FEC-RS(271,257)
根據(jù)第2節(jié)分析,減小碼長和校驗元長度可以減小FEC延遲,因此設(shè)計新RS碼型可以從這2方面著手。當(dāng)前以太網(wǎng)協(xié)議中,RS(528,514)和RS(544,514)比較成熟,所以本文以這2種RS碼作為出發(fā)點。考慮RS(271,257)編碼,其信息元長度是RS(528,514)和RS(544,514)的一半,碼長是RS(544,514)的一半,校驗元長度和RS(528,514)一樣,比RS(544,514)減少了約一半。
從RS碼參數(shù)上分析,這3種RS碼的性能對比如表1所示。
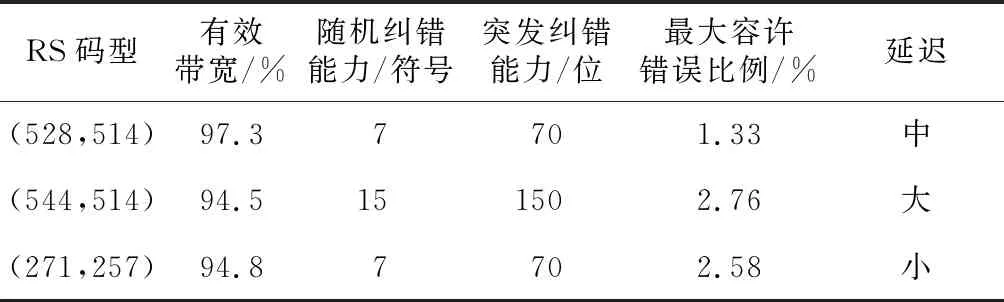
Table 1 Performance comparison of the three RS codes
從表1看,RS(528,514)帶寬利用率最高,糾錯能力最低,延遲大小適中;RS(544,514)糾錯能力最高,延遲最大,帶寬損耗最大;RS(271,257)帶寬損耗和糾錯能力與RS(544,514)相差不大,但延遲最小。經(jīng)Matlab軟件模擬分析,其糾錯性能對比如圖3所示。
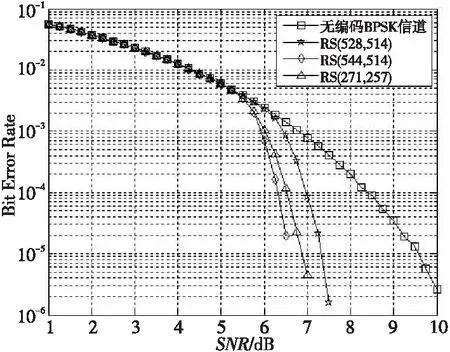
Figure 3 Comparison of error correction performance圖3 糾錯性能對比圖
如圖3所示,RS(271,257)的糾錯能力強(qiáng)于RS(528,514)的,略低于RS(544,514)的,與理論數(shù)據(jù)分析結(jié)果相符。
4 基于RS(271,257)的編碼子層設(shè)計
按照分層設(shè)計理念,面向HPC的高速互連網(wǎng)絡(luò)的底層通常可分為事務(wù)層、鏈路層和物理層。而物理層又可分為物理編碼子層PCS(Physical Coding Sublayer)、物理介質(zhì)附加子層PMA(Physical Medium Attachment)和物理介質(zhì)相關(guān)子層PMD(Physical Medium Dependent)。PCS主要負(fù)責(zé)實現(xiàn)編解碼、多通道綁定、數(shù)據(jù)同步等功能。編解碼是PCS的主要功能,也是PCS的重要特征。在高速互連網(wǎng)絡(luò)物理層單通道傳輸速率規(guī)格為QDR(Quad Data Rate)(10 Gbps)時,其PCS采用8 b/10 b編碼;物理通道為FDR(Fourteen Data Rate)(14 Gbps)規(guī)格時,其PCS采用64/66編碼;物理通道為EDR(Enhanced Data Rate)(25 Gbps)和HDR(High Data Rate)(50 Gbps)時,單純的64/66編碼已經(jīng)難以保證數(shù)據(jù)傳輸?shù)目煽啃裕仨氁刖哂星跋蚣m錯能力的FEC編碼才能提高數(shù)據(jù)傳輸質(zhì)量,以彌補高速率物理通道誤碼率升高帶來的數(shù)據(jù)傳輸可靠性下降。針對當(dāng)前HDR通道規(guī)格,本文基于RS(271,257)實現(xiàn)了面向HPC互連網(wǎng)絡(luò)的低延遲編碼子層。
4.1 編碼子層總體結(jié)構(gòu)設(shè)計
如圖4所示,編碼子層的總體分為數(shù)據(jù)發(fā)送模塊(PCS_TX)和數(shù)據(jù)接收模塊(PCS_RX)。

Figure 4 Flow chart of coding and decoding process 圖4 編譯碼處理流程圖
PCS數(shù)據(jù)發(fā)送模塊從數(shù)據(jù)鏈路層接收數(shù)據(jù),先后經(jīng)過64/66編碼和速率匹配、264/257編碼、加擾、插入對齊標(biāo)記、FEC編碼、符號分發(fā)處理后,將數(shù)據(jù)發(fā)送給物理介質(zhì)。
PCS接收模塊從物理介質(zhì)接收數(shù)據(jù),先后經(jīng)過通道鎖定對齊和重定序、FEC解碼、刪除對齊標(biāo)記、解擾、257/264解碼、66/64解碼和速率匹配處理后,將數(shù)據(jù)發(fā)送給數(shù)據(jù)鏈路層。
4.2 模塊接口設(shè)計
編碼子層模塊向外部主要提供3種接口,分別是用戶數(shù)據(jù)發(fā)送和接收接口、高速SERDES數(shù)據(jù)發(fā)送和接收接口、配置與狀態(tài)寄存器訪問接口。
(1)用戶數(shù)據(jù)發(fā)送與接收接口。在數(shù)據(jù)發(fā)送端,用戶數(shù)據(jù)發(fā)送與接收接口接收上層數(shù)據(jù)鏈路層的數(shù)據(jù),對其進(jìn)行編碼處理后發(fā)送給底層的高速SERDES;在數(shù)據(jù)接收端,用戶數(shù)據(jù)發(fā)送與接收接口接收底層SERDES的數(shù)據(jù),對其進(jìn)行數(shù)據(jù)塊邊界鎖定、同步、解碼后發(fā)送給上層的數(shù)據(jù)鏈路層。為了匹配底層4通道SERDES速率,用戶數(shù)據(jù)發(fā)送和接收接口數(shù)據(jù)寬度為256 b,工作頻率為800 MHz。
(2)SERDES數(shù)據(jù)發(fā)送與接收接口。在網(wǎng)絡(luò)端口的不同工作模式下,SERDES存在2種信號調(diào)制模式,分別是NRZ和PAM4。在NRZ調(diào)制模式下,編碼子層支持的SERDES數(shù)據(jù)發(fā)送和接收單通道并行接口數(shù)據(jù)位寬是32,其最大可支持的單通道速率為25 Gbps。在PAM4調(diào)制模式下,編碼子層支持的SERDES數(shù)據(jù)發(fā)送和接收單通道并行接口數(shù)據(jù)位寬是64,其最大可支持的單通道速率為53 Gbps。單個編碼子層模塊并行向底層4個SERDES發(fā)送數(shù)據(jù),并從這4個SERDES接收數(shù)據(jù)。
(3)配置與狀態(tài)寄存器訪問接口。通過該接口可以對編碼子層模塊的配置寄存器和狀態(tài)寄存器進(jìn)行讀寫訪問。可讀寫訪問的配置包括:旁路示錯控制、旁路糾錯控制、對齊標(biāo)記AM(Align Marker)插入周期控制等;只讀訪問的狀態(tài)包括:鏈路狀態(tài)、通道鎖定狀態(tài)、糾錯計數(shù)、不可糾錯計數(shù)、通道符號錯誤計數(shù)、通道映射關(guān)系等。
4.3 時鐘域的劃分
編碼子層模塊的時鐘通常可劃分為用戶時鐘域、參考時鐘域和SERDES恢復(fù)時鐘域。
用戶數(shù)據(jù)發(fā)送與接收接口工作在用戶時鐘域。編碼子層模塊的大部分邏輯(包括編碼和解碼邏輯等)都工作在參考時鐘域。除此之外,SERDES的發(fā)送端也使用參考時鐘。SERDES恢復(fù)時鐘域:一種方式是,為SERDES每個接收和發(fā)送通道(Lane)各提供一個時鐘。在各個通道的時鐘之間,以及一個通道內(nèi)部的接收和發(fā)送時鐘之間,均不存在任何頻率和相位的關(guān)系(異步時鐘)。另一種方式是,SERDES的接收端為每個通道提供異步時鐘,但SERDES的發(fā)送端使用統(tǒng)一的參考時鐘,這帶來的好處是允許編碼子層模塊發(fā)送邏輯和SERDES發(fā)送邏輯使用同一個時鐘,從而省去發(fā)送端的跨時鐘域處理,進(jìn)而降低延遲。
本文中編碼子層模塊的SERDES數(shù)據(jù)發(fā)送接口使用參考時鐘,而SERDES數(shù)據(jù)接收接口的每個接收通道對應(yīng)一個恢復(fù)時鐘。同時,為了降低編碼子層處理延遲,本文將用戶時鐘域和參考時鐘域合并為同一時鐘,從而進(jìn)一步省去用戶時鐘域和參考時鐘域之間的跨時鐘域處理。唯一需要進(jìn)行跨時鐘處理的邏輯是SERDES各個通道接收端恢復(fù)時鐘域和參考時鐘域之間的跨時鐘處理。
4.4 數(shù)據(jù)發(fā)送處理設(shè)計
數(shù)據(jù)發(fā)送端的處理流程為:
步驟164/66編碼和速率匹配:編碼層將256 b的報文FLIT進(jìn)行64/66編碼產(chǎn)生264 b數(shù)據(jù)塊。
步驟2264/257編碼:編碼層將264 b數(shù)據(jù)塊壓縮編碼為257 b的數(shù)據(jù)塊。
步驟3加擾:編碼層對數(shù)據(jù)進(jìn)行加擾,加擾的多項式為X+X39+X58。其中X代表當(dāng)前加擾的數(shù)據(jù)位,X39和X58分別代表當(dāng)前數(shù)據(jù)的前39 b和58 b,“+”為異或運算符。
步驟4插入對齊標(biāo)記:編碼層周期性地向數(shù)據(jù)中插入特定符號串作為FEC塊的對齊標(biāo)記,插入周期通常為4 096個FEC塊,每個FEC塊包含2 570 b用戶數(shù)據(jù)。
步驟5FEC編碼:編碼層對每個FEC塊2 570 b用戶數(shù)據(jù)產(chǎn)生140 b的校驗和,并將校驗和插入FEC塊尾部。
步驟6符號分發(fā):編碼層將數(shù)據(jù)以10 b符號為單位順序輪轉(zhuǎn)發(fā)送到4個物理介質(zhì)的適配層接口。
在插入對齊標(biāo)記處理過程中,AM插入周期會受到相關(guān)配置寄存器的控制,如果AM插入周期控制位域設(shè)置為“0”,表示AM插入周期為4 096個FEC塊,如果該位域設(shè)置為“1”,表示AM插入周期為300個FEC塊。該配置位域的默認(rèn)值為“0”,只有當(dāng)需要模擬加速時,才將該值設(shè)置為“1”,此時能將編碼子層的初始化過程提速約14倍。
FEC編碼過程如圖1所示,其中g(shù)0~gn-k-1是生成多項式的系數(shù),信息多項式的系數(shù)被順序送入編碼電路執(zhí)行除以g(x)的除法運算,同時被送至輸出端,經(jīng)過k個時鐘周期后在移位寄存器b0~bn-k-1中保留的是余式r(x)的系數(shù),這樣前面n-k個時鐘周期輸出的是信息元,后k個時鐘周期輸出的是校驗元。
符號分發(fā)是將上一批編碼產(chǎn)生的校驗數(shù)據(jù)與本批數(shù)據(jù)的第1個周期數(shù)據(jù)同時傳輸,在進(jìn)行信道傳輸之前,需對數(shù)據(jù)進(jìn)行分配,為4個信道分配相同的數(shù)據(jù)量,符號分發(fā)規(guī)則如表2所示。
表2中第1個周期傳輸?shù)氖巧弦慌鷶?shù)據(jù)的校驗符號和本批數(shù)據(jù)的前25個符號,第7個周期中包含了1個全0符號,以平衡信道數(shù)據(jù)量。

Table 2 Symbol distribution rule
4.5 數(shù)據(jù)接收處理設(shè)計
數(shù)據(jù)接收端的處理流程為:
步驟1通道鎖定對齊和重定序:編碼層從4個物理介質(zhì)的適配層接口接收數(shù)據(jù),識別數(shù)據(jù)中各自包含的對齊標(biāo)記,依據(jù)對齊標(biāo)記重新排列4路數(shù)據(jù),對齊數(shù)據(jù)并上傳至FEC解碼模塊。
步驟2FEC解碼:編碼層對每個2 710 b FEC塊解碼。如果配置使能了旁路糾錯功能(Bypass Correction=1),則直接取出FEC塊的2 570 b用戶數(shù)據(jù)并上傳至下一模塊;否則,根據(jù)FEC塊的140 b校驗和對數(shù)據(jù)檢查2 570 b用戶數(shù)據(jù)的正確性,如果錯誤則糾錯。
步驟3刪除對齊標(biāo)記:編碼層刪除數(shù)據(jù)中周期性出現(xiàn)的FEC塊對齊標(biāo)記。
步驟4解擾:編碼層對數(shù)據(jù)進(jìn)行解擾,解擾的多項式為X+X39+X58。
步驟5257/264解碼:編碼層將257 b的數(shù)據(jù)解壓縮編碼為264 b的數(shù)據(jù)塊。
步驟666/64解碼和速率匹配:編碼層將264 b的數(shù)據(jù)塊進(jìn)行66/64解碼產(chǎn)生256 b數(shù)據(jù)塊并交給鏈路層。
FEC解碼器采用BM算法[10]求解關(guān)鍵方程,Chien搜索算法求錯誤位置,F(xiàn)orney算法求錯誤值。當(dāng)校驗和驗算發(fā)現(xiàn)無差錯發(fā)生時,經(jīng)旁路選擇器直接選擇前面的信息元數(shù)據(jù)進(jìn)行輸出;當(dāng)發(fā)現(xiàn)有錯誤發(fā)生時,由校驗核利用BM算法計算關(guān)鍵方程,再經(jīng)Chien算法和Forney算法計算偏移量和誤碼量,并進(jìn)行數(shù)據(jù)糾錯,當(dāng)錯誤個數(shù)在糾錯能力內(nèi)時,選擇糾錯后的信息元數(shù)據(jù)輸出,當(dāng)錯誤個數(shù)超出糾錯能力時,糾錯失敗,需要進(jìn)行反饋重傳。

Figure 5 Model of decoding delay analysis圖5 譯碼延遲分析模型
根據(jù)譯碼原理和工程實現(xiàn),RS(271,257)和RS(528,514)的解碼延遲分析如圖5所示。可見,在RS(271,257)解碼處理流程中,校驗核驗算需要10時鐘周期,關(guān)鍵方程求解需要15時鐘周期,Chien搜索算法和Forney算法求解需要2時鐘周期,糾錯輸出需要10時鐘周期,考慮到最長通路,整體延遲約為39時鐘周期,與RS(528,514)相比,校驗核驗算和糾錯輸出各減少了10時鐘周期,共減少了20時鐘周期,延遲性能有較大提升。
4.6 其它關(guān)鍵功能設(shè)計
除了提供通道數(shù)據(jù)塊鎖定、多通道綁定、加解擾、編解碼等基礎(chǔ)性編碼子層功能外,為了增強(qiáng)RAS(Reliability、Availability、Serviceability)特性,本文設(shè)計的編碼子層還提供如下功能:
(1)通道自動極性翻轉(zhuǎn)和重定序:高速網(wǎng)絡(luò)物理通道采用SERDES技術(shù)傳輸,其串口為P/N差分信號。通常2個SERDES對接時,其P和N信號應(yīng)該對應(yīng)相接。如果P和N信號相反相接,則稱為通道極性翻轉(zhuǎn)。編碼子層在數(shù)據(jù)接收處理的通道鎖定對齊步驟中,通過同時檢測對齊標(biāo)記及其反碼,判據(jù)通道極性是否翻轉(zhuǎn)。如果發(fā)生極性翻轉(zhuǎn),則將數(shù)據(jù)的反碼輸出給后續(xù)邏輯處理。這種自動翻轉(zhuǎn)處理機(jī)制無需配置SERDES支持而實現(xiàn)通道極性反接,為PCB布線設(shè)計和調(diào)試帶來了便利。自動極性翻轉(zhuǎn)針對的是單通道間的P/N差分信號對接。而通道自動重定序針對的是2個網(wǎng)絡(luò)端口(本文中每個端口綁定了4個物理通道,且分別編號為0~3)之間的通道亂序相接,其實現(xiàn)機(jī)理如下所示:由于單個端口各個通道在發(fā)送數(shù)據(jù)中插入的對齊標(biāo)記是不同的,所以編碼子層接收方通過對齊標(biāo)記識別出各個通道,然后對各個通道的數(shù)據(jù)重新排序組合后再上傳給上層邏輯。通道自動重定序也是一種降低PCB布線設(shè)計難度的技術(shù)。
(2)通道容錯:綜合考慮邏輯實現(xiàn)的復(fù)雜性和容錯性目標(biāo),編碼子層模塊實現(xiàn)了對x1,x2,x4通道綁定模式的支持,而且在部分通道出現(xiàn)故障的情況下,鏈路2端編碼子層狀態(tài)機(jī)通過自動協(xié)商,實現(xiàn)通道綁定模式的降級(故障通道數(shù)目分別為1,2,3時,通道綁定模式分別為x2,x2,x1),從而避開故障通道發(fā)送和接收數(shù)據(jù),保證網(wǎng)絡(luò)端口的可用性和可靠性。
(3)旁路糾錯和示錯:實際網(wǎng)絡(luò)物理介質(zhì)應(yīng)用場景多種多樣,并不是所有應(yīng)用場景的物理介質(zhì)數(shù)據(jù)傳輸都存在誤碼,所以編碼子層的解碼模塊實現(xiàn)了糾錯旁路(Bypass Correction)和示錯旁路(Bypass Indication)功能。根據(jù)鏈路質(zhì)量靈活配置旁路示錯和旁路糾錯功能,可以降低編碼子層處理延遲。根據(jù)圖5所示的解碼延遲分析模型,只旁路糾錯就可以減少10時鐘周期處理延遲,而既旁路示錯又旁路糾錯可以減少20時鐘周期處理延遲。
5 資源消耗與延遲性能評估
為了驗證本文提出的基于RS(271,257)的低延遲編碼子層結(jié)構(gòu)及其關(guān)鍵技術(shù),本節(jié)使用Verilog硬件描述語言實現(xiàn)了編碼子層RTL模塊。同時,為了評估RS(271,257)相比以太網(wǎng)標(biāo)準(zhǔn)的RS(528,514)的性能優(yōu)化,也使用Verilog語言實現(xiàn)了基于RS(528,514)的編碼子層。為了便于表述,將上述2種編碼子層模塊實現(xiàn)分別表示為RS271-PCS和RS528-PCS。
5.1 資源消耗評估
為了評估RS271-PCS和RS528-PCS 2種編碼子層實現(xiàn)實際使用的邏輯資源情況,對這2種邏輯實現(xiàn)的RTL代碼在FPGA設(shè)計平臺上進(jìn)行了綜合。綜合工具是Xilinx公司的Vivado v2018.2(64-bit),綜合目標(biāo)器件選用了Virtex UltraScale系列xcvu440-flga2892-2-e。綜合策略采用默認(rèn)策略(即Vivado Synthesis Defaults)。在FPGA中,主要的邏輯資源包括:查找表LUT和查找表存儲器LUTRAM等。資源消耗情況如表3所示,可見與RS528-PCS相比,RS271-PCS的LUT資源消耗降低了約6.32%,LUTRAM資源消耗降低了約0.13%。
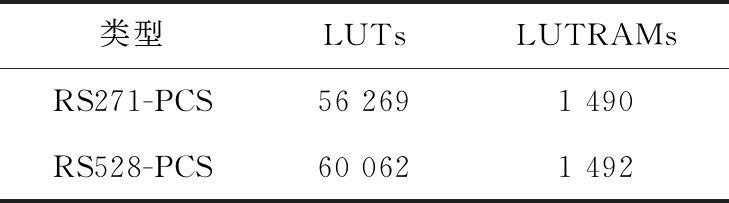
Table 3 Resource consumption
5.2 延遲性能評估
為了評估RS271-PCS和RS528-PCS 2種編碼子層實現(xiàn)的處理延遲,本文分別以這2種邏輯實現(xiàn)的RTL實現(xiàn)作為DUT(Device Under Test),采用System Verilog語言構(gòu)造了統(tǒng)一的性能測試環(huán)境,并使用Synopsys公司的VCS工具進(jìn)行模擬。依據(jù)當(dāng)前的工藝水平,設(shè)置DUT的參考時鐘工作在800 MHz。為了簡化測試環(huán)境,將DUT的SERDES數(shù)據(jù)發(fā)送接口與數(shù)據(jù)接收接口直接相接。由于旁路模式會影響編碼子層處理延遲,所以本文的測試覆蓋了3種旁路模式。延遲統(tǒng)計測量的是數(shù)據(jù)從用戶數(shù)據(jù)發(fā)送接口進(jìn)入DUT,到從DUT接收接口出來的通過時間。
延遲的模擬測試結(jié)果如表4所示,可見:(1)與RS528-PCS相比,RS271-PCS在2種旁路配置(糾錯&旁路示錯、旁路糾錯&旁路示錯)模式下的處理延遲分別降低了17.74%和22.73%;(2)與RS528-PCS相比,RS271-PCS在非旁路模式(糾錯&示錯)下的處理延遲降低了25 ns,大大降低了編碼子層處理延遲。

Table 4 Delayed performance simulation results
除了對編碼子層的延遲性能進(jìn)行了評估,我們還利用該測試環(huán)境構(gòu)造了各種測試場景,對編碼子層的各項功能,例如通道自動極性翻轉(zhuǎn)、通道自動重定序、通道容錯、通道SKEW容限等進(jìn)行了驗證,驗證結(jié)果表明了結(jié)構(gòu)設(shè)計的可行性和功能實現(xiàn)的正確性。
6 結(jié)束語
目前,物理介質(zhì)的傳輸速率已經(jīng)達(dá)到25~50 Gbps,在該速率范圍下,為了保證數(shù)據(jù)傳輸?shù)恼_性,IEEE 802.3cd標(biāo)準(zhǔn)的編碼子層使用RS(528,514)和RS(544,514) 前向糾錯編碼(FEC)以糾正數(shù)據(jù)傳輸中的差錯。
本文根據(jù)下一代HPC互連網(wǎng)絡(luò)低延遲需求,基于當(dāng)前成熟的前向糾錯編碼,分析RS編碼參數(shù)與延遲之間的關(guān)系,提出一種面向HPC互連網(wǎng)絡(luò)的低延遲RS(271,257)的FEC編碼,并對基于該編碼的網(wǎng)絡(luò)編碼子層進(jìn)行了設(shè)計和實現(xiàn),通過模擬驗證,該互連網(wǎng)絡(luò)編碼子層處理延遲最高為75 ns,相較于目前成熟的RS編碼有較大提升,更適合于下一代HPC互連網(wǎng)絡(luò)的低延遲需求,且其糾錯能力也有較大程度的保留。下一步將研究多種編碼的融合設(shè)計與實現(xiàn),以滿足不同融合網(wǎng)絡(luò)的設(shè)計需求。
