基于LABVIEW圖像識別技術在文字識別領域的研究
2020-12-08 06:42:45高新怡張坤坤楊靜怡陳冠宇蔡華蕊
科學導報·學術 2020年89期
關鍵詞:方法
高新怡 張坤坤 楊靜怡 陳冠宇 蔡華蕊
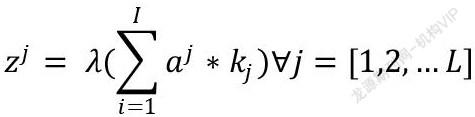
【摘 要】文章主要研究了外界獲取的文字圖像整個處理過程所使用到的方法和算法,并對完成文字識別操作的各種方法進行了比較。通過雙三次插值法完成圖像的采集、平均值二值化完成圖像的預處理、卷積神經網絡和遞歸神經網絡處理并識別文字。并且闡述了各個環節用LABVIEW實現步驟。圖像識別是幾年來的一個熱門技術,對于試聽能力下降的老人,如果能利用這類技術極好的便利生活,即實現了高科技助老。
【關鍵詞】LABVIEW;圖像采集;文字識別;神經網絡
1 圖像獲取
1.1圖像采集
圖像采集 是指通過攝像頭將光學信號轉化為電信號,傳送至圖像采集卡進行數字化,形成可使計算機識別、處理的數字圖像數據,將其保存下來的過程。通常情況,圖像的采樣有3種方法:最鄰近插值法、雙線性插值法、雙三次插值法。
采集后的圖像有兩個衡量指標:灰度等級以及采集分辨率。對衡量指標的優化,稱為對圖像的預處理。
1.2圖像預處理
1.2.1 二值化
圖像二值化 是指將采集到的灰度圖像的灰度值置為0或者255,使整個圖像呈現為黑白圖像,這樣有利于簡化圖像,在對圖像做進一步處理時,圖像的集合性質僅與0像素值或255像素值的點的有關,不會涉及到像素的多級值,使得數據的處理更加簡單、壓縮量更小。
簡單方法 是指在對彩色圖像灰度化以后,掃描圖像的每一個像素值,小于127的像素值設為0(黑色),大于或者等于127的像素值設為255(白色)。該方法的優點在于處理量小、反應速度快,缺點在于閾值127的選擇沒有依據,僅為像素值0-255的中值,沒有考慮到像素值的分布情況,處理后圖像的效果欠佳。
平均值二值化方法 是指先計算出像素點的平均值K,再對灰度化后的圖像的每一個像素點進行掃描,小于或者等于K像素值的像素點設為0(黑色),大于K像素值的像素點設為255(白色)。該方法相比于簡單方法,在閾值選取上更加的有邏輯,選擇像素值的平均值。但仍然可能導致部分對象像素或者背景像素丟失,導致二值化后的結果不能反映源圖像的真實信息。
直方圖方法 該方法的閾值選擇為尋找兩個最高的峰值,閾值取值在兩個峰之間的峰谷最低處。該方法的精準度更高,結果更為人們所接受。
1.2.2 反色
反色 是指將得到的彩色圖像的R、G、B值取反,這里所涉及的反轉操作即為用255減去原來圖像的R、G、B值得到新圖的R、G、B值。對圖片反色處理后可以增加圖像的對比度,凸顯出圖片的一些細節信息。
1.3濾波處理
均值濾波 通俗來說,是一種“低通濾波器”,去除高頻信號,即消除尖銳噪聲,使圖像平滑,但無法去除椒鹽噪聲。
中值濾波 是取某個像素點的周圍像素點的中值作為該點的像素值,相比于均值濾波,可以較好的去除椒鹽噪聲。
最大值/最小值濾波 是取某像素點的周圍像素點的最大值/最小值作為該點的像素值,此方法能夠很好的處理椒鹽噪聲。
高斯濾波 取某像素點與周圍像素點的距離作為權重卷積計算中心位置的像素。高斯濾波是一種低通濾波,對圖像的“平滑化”效果顯著。
1.4 用LABVIEW預處理信號
LABVIEW 中的運動視覺模塊具有相對完整的圖像處理功能,調用其中的IMAQ USB函數可自動識別USB攝像頭并讀取數據,圖像采集完成之后,調用IMAQ Extract進行光標設置所需查找的像素。待找到最合適的像素值之后,程序中先運行一個條件結構,其次運行一個順序結構,再設置其image控件,調整palette參數可實現對所獲圖像的二值化,再調用matlab中的白化函數,完成對所獲圖像的白化處理。
2 圖像識別
2.1 算法選取
2.1.1 最佳統計分類器
最佳統計分類器算法 通過模式分類器計算出模式相對于類的平均損失,再通過貝葉斯分類器將平均損失降至最低。在此,標準字庫中的每個字符對應于算法中的一個類,每個文字圖像對應于算法中的一個模式。此算法的運算量相對較小,但結果不夠精確。
2.1.2 串匹配
串匹配算法 是將獲取的文字圖像的邊緣信息編碼成串,且與標準字庫文字邊緣信息進行比對,計算出其與標準字庫文字邊緣信息的匹配度。此算法在精確的接近于無限大時,可將所獲文字與標準字庫精準匹配。但該算法的匹配是逐個字符進行匹配的,計算量大,相應速度較慢。
2.1.3 神經網絡
神經網絡 是將圖片文字作為輸入,標準字庫文字作為輸出,利用反向傳播算法、梯度下降法對網絡各參量進行優化,使得誤差函數最小。神經網絡可通過卷積神經網絡算法,對輸入進行強制稀疏化,減小計算量,準確度提高。
相比三種算法,神經網絡的計算量小,準確度更高。
2.2 神經網絡
2.2.1 卷積神經網絡
卷積神經網絡由輸入層、卷積層、池化層、全連接層以及輸出層組成。輸入層可對圖像進行前文所提到的預處理操作。卷積層通過一個用戶自定義的核與圖像的特征描述矩陣作遍歷完某個方向的卷積運算,將所得到的局部信息存儲到一個新的矩陣中,其中通過不同的核得到的特征矩陣可進行信息共享[1].設第層卷積層的輸入具有個通道,且該層具有個核表示激活函數,該層的結果可表示如下:
池化層的作用是對卷積層所提取到的特征進行降維,使激活值的變換更加陡峭以實現更好的學習。在通過卷積層得到的矩陣中選擇的窗口以的步幅滑動,并選擇每個窗口中的最大值記錄到一個新的矩陣中,該最大池化值對應于核所需求的最佳匹配模板。
最后通過全連接層作用,與傳統MLNN網絡類似,對所提取整理得到的信息特征進行非線性組合,在輸出層得到對圖片中文字識別的結果。
整個網絡的訓練將文字圖片作為輸入,其對應于文字庫的標準輸出作為標簽,采用反向傳播算法進行各層中參數的計算。其中全連接層的BP計算與傳統前饋神經網絡相同,卷積層采用與前饋傳播類似的交叉相關方法進行計算,池化層則在將訓練中的誤差極大值分配到合適的位置,而在反向傳播中不會進行參數的更新。利用傳統的SGD方法將各誤差函數的最小化,可得到各層中參數的最優值。
2.2.2 遞歸神經網絡
為增強神經網絡所處理結果的可讀性,此處增加一個RNN網絡進行自然語言的進一步處理。RNN反向傳播算法[4]和常規神經網絡類似,通過梯度下降法基于時間進行反向傳播,得到合適的模型參數。
2.3 基于LABVIEW的神經網絡實現
神經網絡在LABVIEW中是通過反饋的形式實現的,利用移位寄存器將前一次循環的輸出傳遞給下一個循環的輸入。在使用的先進控制算法中,內模控制在系統的控制領域具有極強的優越性。
3 結論
本文介紹了基于圖像識別技術完成文字識別的方法,闡述了所獲取的文字圖像的預處理方法,介紹了用于圖像文字識別過程中所涉及到的算法。其中插值能增強圖像的某些特征來對所獲圖像進行預處理,濾波去除不必要的噪聲,訓練好的神經網絡可對處理好的圖像進行貼標簽或分類。
目前,文字識別到技術已經相對成熟,各種圖像計算的科學算法如濾波、白化、卷積神經網絡等已被不僅限于圖像識別的各領域廣泛應用,而濾波可用于各種圖片的平滑處理,插值能增強各種信號,使信號的特征更清晰,這些算法在識別領域中可達到較好的效果。
參考文獻:
[1]熊秀,石秀華,許暉,杜向黨.用LABVIEW實現神經網絡控制.1000-8829.2005.
[2]張乃堯,閻平凡.神經網絡與模糊控制[M].北京:清華大學出版社,1998.
天津市大學生創新創業訓練計劃項目202110069073
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
