基于Word的中文詞頻分析系統設計與實現
2020-12-09 05:24:35楊鵬張利強賀斯慧
企業科技與發展 2020年10期
楊鵬 張利強 賀斯慧


【摘 要】隨著互聯網的飛速發展,各類網絡開發平臺飛速成長,供用戶在網絡上暢所欲言,交流學習。但是,各種垃圾信息在網絡上頻繁發布,違背了網絡平臺開發的初衷,污染了網絡環境。為杜絕此類垃圾信息,各大平臺都采取各種措施優化網絡環境,但是效果不佳,究其原因在于文字的任意組合排列都會產生不同的信息,而在攔截垃圾信息時必須進行模板化配置攔截,這就導致垃圾信息是可變的而攔截信息卻要人為操作。為解決此類問題,可以將垃圾信息細化成單獨的個體,也就是對信息進行分詞。
【關鍵詞】word分詞;詞頻;中文分詞
【中圖分類號】TP311.52 【文獻標識碼】A 【文章編號】1674-0688(2020)10-0070-03
0 引言
中文分詞處理需要對現有的中文信息至少從字、詞、句等3個層面進行處理,甚至必須從語義、詞性等方面處理才能分析出其中意義。在中文里面,詞是最小的語言單位,如果不處理好中文分詞的問題,那么處理語句問題也就無從談起,所以中文分詞是中文處理技術的基礎。相對于其他語言,中文分詞是比較復雜的。英語的單詞之間有著空格相隔,檢索方便,并且采用窮舉的方式表達其意,因此不存在分詞的說法。中文語句之間是沒有分割符的,想要處理中文,就需要專門的技術支撐。隨著自然語言的興起發展,涌現眾多算法支撐中文分詞。根據特點,我們可以分為以下幾類:匹配算法、理解算法、統計算法、語義算法。每種方法各有優劣,目前沒有單一的算法能達到令人滿意的結果,只有優勢互補才能得到相對好的結果。
本文結合各類算法并利用現有的網絡環境提供了多種基于詞典的分詞算法,選用Java語言利用Word分詞去除詞句相近的多重歧義。能夠準確地識別時間、日期及數字等數量詞,結合中國國情能夠識別出人名、地名、組織結構名等未登錄詞。提供配置化改變詞庫行為及豐富分詞的功能;用戶自己上傳詞庫,自動監聽詞庫改變;能夠在現在流行的分布式環境下提供支持,提供統計詞頻、拼音、未登錄詞、量詞等功能。結合市面上各種各大分布式框架進行Lucene、Solr、ElasticSearch、Luke集成實時處理。
1 分詞算法
分詞算法大體可以總結為四大類,分別是基于規則的分詞、基于統計的分詞、基于語義的分詞、基于理解的分詞。
1.1 基于規則的分詞方法
基于規則的分詞方法是一種機械分詞方法,需要依托于字典的詞庫模型分詞,按照定義的策略將要分解的字符串與詞庫模型進行逐條匹配。找到則匹配成功。這種方式和數據庫的搜索類似,因此該方法受一定的環境限制,倘若詞庫過于龐大,在匹配時就會消耗大量的資源和時間。這種方法需要保證文本的掃描順序、詞典及匹配規則。文本的掃描索引類似鏈表查詢節點,有正向、逆向、雙向3種選擇。原則上可以分為正向最大匹配法和逆向最大匹配法及雙向結合最佳匹配法。
1.2 基于統計的分詞方法
基于統計的分詞的主要思路:詞是能夠窮舉的穩定組合,因此如果相鄰的字出現在同一場景下的次數過多就可能組成一個詞。基于這樣的規則,我們通過字出現的概率和頻率統計詞的可信度。對文本中字之間出現位置頻度進行統計,得出它們之間的相作用信息。該信息體現了文字之間的緊密度。當緊密度大于閾值時,可以將這個字組合認為是一個詞。該方法所應用的主要的統計模型是N-gram模型,也就是本系統主要使用的模型。市面上還有其他成熟模型,例如條件隨機模型、最大熵模型、隱馬爾可夫模型等。
1.3 基于理解的分詞方法
利用計算機的運算,按照策略模擬大腦運算并分析句子的含義,從而達到識別效果。這是一種先進的分詞方式,它結合了句法、語義、分詞等多種分詞方式進行處理。主要包括分詞系統、歧義識別系統、總控系統。在總控系統的協調下,分詞系統可以對分詞的相關詞、句子等信息進行判斷,模擬人對文本的理解過程,這種方法需要大量的語言知識庫。
2 系統設計
本系統從應用上劃分為兩大塊;一是作為開放平臺供人們使用統計,用于日常中文分析結合網絡環境動態識別語言多重含義,分解短語統計詞性;二是作為開發平臺銜接市面上各大信息分析框架如Lucence、Solr、ElasticSearch、Luke、Redis等各大分布式緩存框架,提供分詞處理驅動。
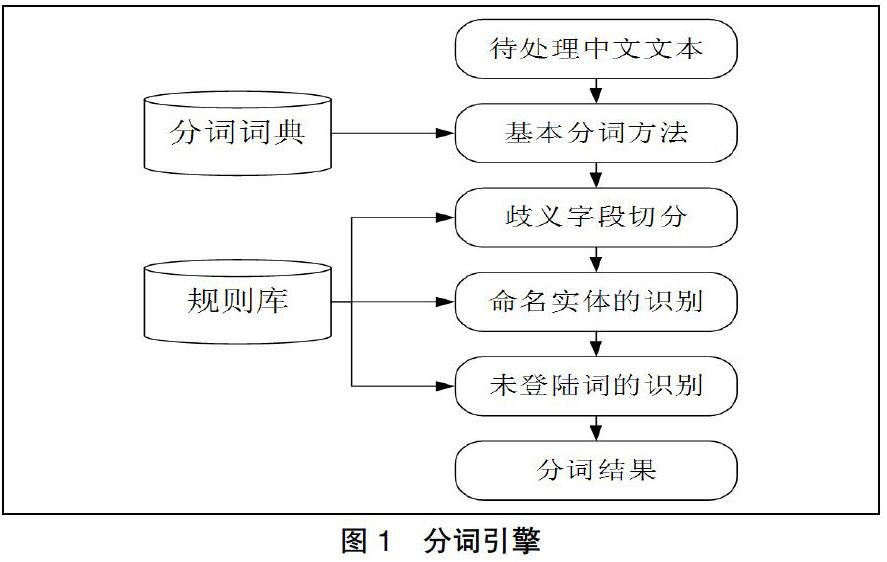
2.1 分詞引擎
分詞引擎,分詞實現支撐主要由分詞詞典和規則庫組成。利用責任鏈模式,流程如下:輸入待處理中文文本→基本分詞→歧義字段切分→命名實體的識別→未登陸詞的識別→分詞過濾→分詞結果。上述組成分詞引擎,作為開放平臺和開發平臺的功能支撐(如圖1所示)。
2.2 平臺架構
開放平臺主要采用流行的Web應用,通過前端應用傳遞分詞結果,由后端進行處理,調用分詞引擎將分詞信息返回給調用者,調用者通過分析框架和引擎進行分詞統計分析。開發平臺采用依賴包和請求配置等進行接入,不會破壞系統的原來架構和代碼,作為一個插拔式的、拿來即用的應用。
2.3 開發語言
開發語言選用面向對象的語言JAVA作為基礎引擎的功能開發語言,現在市面上常用應用分布在Web端和App端,而這兩端的后臺支撐80%左右都是JAVA語言,并且JAVA語言在數據分析存儲方面也有著巨大的優勢,比如常搭配分布式使用的ES(ElasticSearch)、Hadoop、Spark等高性能框架。我們采用JAVA語言開發分詞引擎可以很好地接入這些框架。
2.4 分詞組件
Word分詞器自帶多種詞典分詞算法,文本相似算法覆蓋面廣泛,利用N-gram模型識別短語歧義,底層也是采用JAVA語言編寫,因此可以更加方便地接入各大平臺,并且為分詞引擎提供很好的環境支持。
3 系統主要模塊設計與實現
3.1 word分詞
用戶通過Web表單提交待分詞的中文文本,前端通過Axios.create(config)方法創建Axios實體攔截用戶請求,調用axiosInstance.interceptor.response.use(config)方法轉發請求,系統后端在接到請求后初始化繼承自SpringSecurity的OncePerRequestFilter的filter對象,并調用其doFilterInternal()方法獲得用戶提交的數據與請求。獲取文本后,調用SplitFactory.getInstance(wordConfig.xml)讀取word分詞依賴,并生成analyzer實例,analyzer調用tokenStream(“text”,splitWordStr)得到分詞切片器對象tokenStream,然后對分詞切片器進行停用詞、詞庫、自建字典、優先級設置,設置完成后通過split獲得分詞結果,同時調用數據訪問類將結果存入數據庫中,供后期詞頻統計使用。
3.2 詞頻字典
數據字典是后端應用開發漫長過程中總結出來的一套通用的程序設計方法,它的作用是存儲除了需求業務主體之外的屬性信息,從而統一維護管理。例如,用戶存在性別屬性,性別又有男、女的取值范圍,此時該屬性的取值范圍或者說取值枚舉就需要用統一數據集進行維護,這就是數據字典的作用。在詞頻分析系統中,為了更快速地對詞頻進行分析,借用數據字典的思想,將所有字詞作為數據元,在數據庫中存儲字詞出現的次數及與其他詞語相關出現的次數,將這些結果作為詞的屬性,使用枚舉類型統一管理配置。
3.3 詞頻分析
詞頻WordFrequency表示的是某一個詞語在文本中出現的頻率。假定在文本字符串集S{s1,s2,s3,…,sn}中包含n個字符串,包含特征詞的Wi的字符串數為m,m除以n的結果就是關鍵詞Wi的詞頻,即
WFi值越大,表示詞語在文本中出現的概率高,則該詞語的參考價值高,反之則表示該詞語參考價值低。當WFi極低時,表明該詞對文本內容沒有貢獻,刪除該詞對分詞結果沒有影響,所以為了降低系統的復雜度,系統通過最小風險估計法,設置一個最低閾值,當WFi低于該值時,自動刪除該詞。
詞頻分析的實現過程核心如下:
調用new WordInfomation()方法初始化用于保存關鍵詞、出現次數、相關度的WordInformation對象,并將當前關鍵詞通過setInfo(keyString.getString())注入wordInformation中,并通過while循環進行遍歷查詢比較,統計該詞在字符串中出現的次數及與之相關的詞語。While(keyStringList.hasNext()){ if(keyString)在文本中出現,那么調用setInfoNumberCount(wordInformation.getInfoNumber()+1);累加出現記錄次數。完成遍歷后,將出現次數除以字符串總數,得出詞頻概率,并通wordDaoImplement對象的update(wordFreq)方法將其存入數據庫中。
3.4 結果展示
為了更直觀、高效地將分詞與詞頻結果展示給用戶,后臺完成分詞統計后,將結果封裝到json對象中,并通過response對象將json轉發給前臺頁面,前臺頁面中使用Vue進行數據解析,首先調用initRender()對頁面中需要使用的form、laydateInstance、formInstance等layUI組件進行初始化,完成初始化后通過$.each(res.data,function(i,obj))方法完成數據的綁定,然后通過render方法將數據進行渲染刷新,將結果展現給用戶(如圖2所示)。
4 結語
目前,分詞引擎主要利用自然語言中的技術,尚不能完美地處理語法分析的問題。在語法詞義等方面的自動分析研究還需要進一步挖掘。在自然語法挖掘方面,神經網絡分詞具有顯著的優勢。但是,目前人們的狀態轉義和規則推理尚不能完全表達出人類大腦思維的機制;對復雜、模糊的信息處理,仍然處于無能為力的地步;分詞庫的建設和詞典選擇還具備大量的人為因素。對此,本文提出了一種基于Word的中文詞頻分析系統,采用Javaweb框架技術,將傳統分詞進行平臺化,為垃圾信息處理提供前置服務和參考。
參 考 文 獻
[1]丁潔,趙景惠.基于N-gram模型的中文分詞算法的研究[J].福建電腦,2017(5):110,116.
[2]楊貴軍,徐雪,鳳麗洲,等.基于最大匹配算法的似然導向中文分詞方法[J].統計與信息論壇,2019,34(3):19-24.
[3]于舒曼,馬秀峰.基于詞頻分析和共詞聚類的圖書館創客空間研究熱點分析[J].大學圖書情報學刊,2019,37(2):99-103.
