基于敏感信息鄰近抵抗的匿名方法
2020-12-16 02:43:40呂永軍程小輝
計算機工程 2020年12期
桂 瓊,呂永軍,程小輝
(1.桂林理工大學 信息科學與工程學院,廣西 桂林 541004; 2.武漢理工大學 信息工程學院,武漢 430070)
0 概述
在大數據背景下,海量數據的共享與應用極大地推動了社會的發展,但同時也帶來了隱私保護問題。在這種情況下,數據匿名技術可以有效降低攻擊者獲取個人敏感信息的概率,同時保證數據的可用性。匿名化以其安全性和有效性成為保護數據隱私的一個有效方法,近年來在社會中受到廣泛關注。
匿名化操作方式一般是刪除記錄中標識符屬性,隨后發布數據,但是鏈接攻擊會通過發布數據中準標識符屬性進行唯一識別元組導致隱私泄露。研究人員提出諸多匿名模型,如k-匿名模型[1]、l-多樣性[2]和t-近鄰[3]等,在對元組敏感屬性賦約束時,提出(α,k)-匿名模型[4]、(k,e)-匿名模型[5]和(,m)-匿名模型[6]等,其中(,m)-匿名模型給出相似性攻擊的概念。文獻[7]證明如何最優化數據匿名問題為NP-hard。在已發布數據確保隱私保護的同時,支持有效的數據分析有多種不同匿名方法被提出[8-9]。
在信息損失和時間效率優化方面,文獻[10]提出一種貪心聚類匿名方法,權衡總體信息損失和匿名時間。依據準標識符對敏感屬性分類重要程度,文獻[11]提出一種基于權重屬性熵的分類匿名方法,根據不同敏感屬性的權重屬性熵大小對數據集進行有利劃分。文獻[12]提出面向缺失數據的方法,強調保留原始數據特性,在面向包含關系和事務屬性的數據時,又提出(k,l)-多樣化模型[13],在保障數據可用性的同時實現更高的效率。文獻[14]提出數據中敏感屬性分配敏感度級別方法。文獻[15]提出基于屬性值語義邊緣劃分方法。文獻[16]提出面向多敏感屬性的匿名方法。
考慮同一等價類語義相近的敏感屬性,攻擊者通過相似性攻擊提高了個人隱私泄露概率。(ε,m)-匿名模型可以有效抵抗相似性攻擊,但未對分類敏感屬性分類問題提出解決方案。文獻[17]提出一種抵制相似性攻擊的(p,k,d)-匿名模型,要求每個等價類至少包含p個d-相異的敏感值阻止相似性攻擊,有效保護了個人隱私,但會造成不必要的信息損失。本文對分類敏感屬性進行研究,構建一種敏感信息鄰近抵抗的(r,k)-匿名模型,并給出基于敏感屬性鄰近抵抗的匿名方法GDPPR。
1 基本概念
令T為原始數據表,A={A1,A2,…,An}分別對應表中元組的n個屬性。其中,標識屬性表示唯一識別個人身份的屬性,如“Name”屬性,在發布的原始數據中被移除。準標識符屬性表示通過組合可以唯一標識個人身份的屬性,如“Age”“Gender”和“ZipCode”等屬性。設定“Disease”為敏感屬性,即涉及隱私信息的屬性。發布的原始數據表如表1所示。
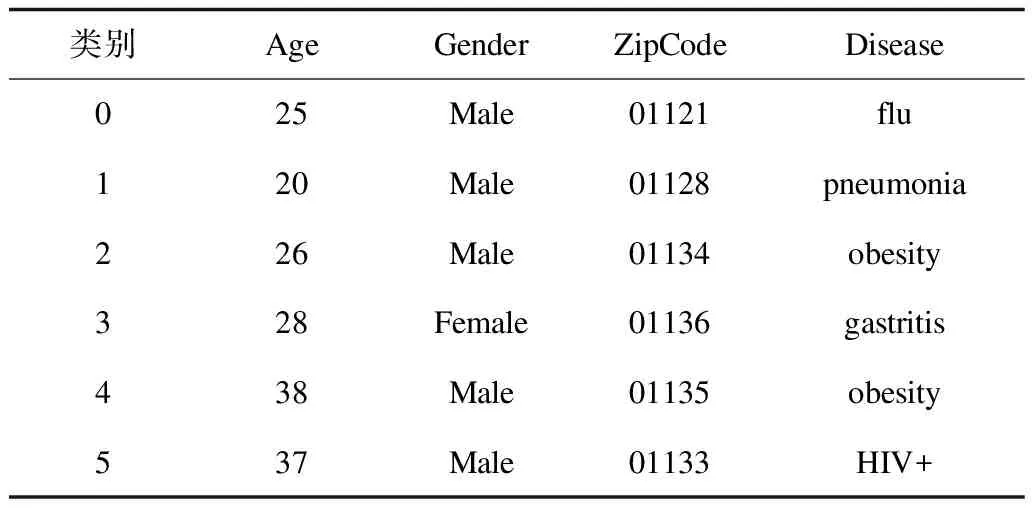
表1 原始數據表Table 1 Raw data table
使用區間或者模糊的值取代原數據中具體的屬性值的過程稱為數據泛化,為保留數據語義,需要對元組屬性建立泛化層次結構,如圖1所示。
圖1 泛化層次結構
不同元組屬性有不同的泛化層次,為減少信息損失,需要尋找泛化層次中替代相應取值的最低公共子節點。
在數據表T中,每個等價類滿足至少有k個元組準標識符屬性不可區分,那么該數據表T滿足k-匿名模型。表2為滿足3-匿名模型的匿名數據。

表2 滿足3-匿名模型的數據Table 2 Data satisfying the 3-anonymity model
定義1(隱私泄露風險) 在數據表T中,同一等價類相鄰語義下敏感屬性集合取值頻率,稱為泄露風險。結合分類敏感屬性特性,改進泄露風險R[18],定義等價類中的泄露風險R(ci):
(1)
在同一等價類中,cRSA表示用戶可容忍發布的最低層次下語義關聯敏感屬性值,cSA表示敏感屬性值。如表2的等價類1中,敏感屬性flu、pneumonia屬于呼吸系統類疾病,被攻擊者推斷出,造成隱私泄露。數據被劃分為p個等價類時,定義數據表T的泄露風險為:
R(T)=max(R(ci)),i=1,2,…,p
(2)
本文基于屬性相似度衡量信息損失,屬性間相似度越高,泛化造成的信息損失就越少。
根據原始數據表T,得到匿名表T*產生的信息損失為:

(3)
其中,IL(ci)表示T*中等價類通過泛化產生的信息損失,p表示等價類數量。根據等價類中各元組的準標識符不可區分,產生的信息損失相同,信息損失如式(4)所示:
IL(ci)=|ci|IL(t)
(4)
IL(t)表示元組信息損失,如式(5)所示:

(5)
其中,ωi表示元組中不同的準標識符所占權重,IL(Ai)表示某一準標識符的信息損失,信息損失如式(6)所示:
(6)
其中,f(Ai)表示準標識符節點集合泛化結構層次路徑長度,root表示泛化層次根節點路徑長度。數值屬性的泛化層次結構通過差異程度表示,分類屬性的泛化層次結構通過集合表示。
在數據表T中,元組抑制時產生的信息損失最高。T*產生的信息損失與數據抑制產生的信息損失的比值稱為損失率,如式(7)所示:
(7)

定義2(距離定義) 在數據表T中,元組相似度距離通過準標識符與敏感屬性結合來表示。在準標識符中,元組與簇中心計算公式如式(8)所示:
(8)
其中,dt(ni)、dt(cj)分別表示數值屬性和分類屬性的相似度距離,n、c分別表示元組中數值和分類屬性的數量,ω表示屬性權重,取值取決于在聚類過程中元組準標識符對屬性選取的重視程度,且需要滿足0≤ω≤1。
定義3(敏感屬性相異度) 在語義角度分析下,通過敏感屬性的相似度構造層次結構,得出元組的敏感屬性相異度公式如式(9)所示:
(9)
其中,h(a,b)表示敏感屬性值所屬泛化分類層次最小公共節點路徑長度,roots表示敏感屬性語義層次根節點路徑長度。
本文采用模糊聚類技術,根據隸屬度矩陣劃分簇,結合敏感屬性相異度得出距離矩陣,矩陣公式如式(10)所示:
(10)
其中,權重α、β分別表示元組準標識符和敏感屬性權重參數,體現數據擁有者對元組屬性的重視程度,且滿足α+β=1。
2 敏感屬性鄰近抵抗的匿名模型
在匿名模型中通常假定敏感屬性值之間相互獨立,在相似性攻擊下則無法保障個人匿名需求,本文考慮敏感屬性相異度,在k-匿名模型基礎上加以改進。
定義4((r,k)-匿名模型) 設原始數據表為T,匿名數據表為T*。當匿名表T*滿足k-匿名時,等價類中至少有k個除敏感屬性外不可區分的元組,同時滿足敏感屬性的鄰近屬性取值頻率不超過閾值r(0≤r≤1),即:
其中,C={c1,c2,…,cn}為等價類集合,在同一等價類中,cSA表示敏感屬性,cRSA表示具有語義關聯的敏感屬性。
在表2中,由于k-匿名未約束敏感屬性,當攻擊者通過背景知識推斷出患者ANDY在第1個等價類中,將推斷其患有呼吸系統疾病。本文設計(r,k)-匿名模型對原始數據表匿名化,如表3所示,由于每個等價類中敏感屬性語義層次結構父節點不同,攻擊者進而無法分析ANDY患有哪類疾病,從而降低隱私泄露風險。

表3 滿足(0.5,3)-匿名模型的數據Table 3 Data satisfying the (0.5,3)-anonymity model
3 GDPPR算法
3.1 算法思想
GDPPR算法的核心思想在于敏感屬性基于語義關聯定義層次結構,按照元組屬于每個簇的概率完成簇的劃分。根據不同屬性泛化層次結構進行泛化。
算法1GDPPR算法
輸入數據集T,匿名參數k,選擇聚類數p,模糊指標m,聚類中心閾值f,隱私泄露閾值r
輸出滿足(r,k)-多樣性的匿名數據表T*
1.Random initialization membership matrix Dn×p;
2.Traversing data records tiin T,i=1,2,…,n;
3.for j=1 to p do
4.Calculate Cluster Center cj;
5.end for
6.for i=1 to n do
7.for j=1 to p do
8.Calculating membership dij=αdtij+βdtij(s);
9.end for
10.end for
11.counter e=0;
12.while Number of iterations e > E,E:maximum number of iterations do
13.if Maximum difference between adjacent cluster centers< f then
14.Stop the iteration;
15.else
16.Recalculate the cluster center set C;
17.Update the membership matrix D;
18.e=e+1;
19.end if
20.end while
21.Dividing clusters according to the determined membership matrix;
22.for i=1 to n do
23.if The Privacy disclosure threshold < r then
24.Find the maximum membership probability of the tuple tibelonging to the cluster in the membership matrix cj;
25.Let tuple tibelong to the cluster;
26.end if
27.end for
28.for j=1 to p do
29.Generalize the divided clusters by defining a generalization strategy to obtain equivalence classes C;
30.T*=T*+C;
31.end for
32.Get cluster result T*.
對GDPPR算法描述如下:
1)步驟8計算元組與簇中心距離,形成距離矩陣D。
2)步驟13通過判斷迭代前后最大簇中心距離是否小于閾值f,不滿足則需重新計算簇中心,更新距離矩陣,直到滿足條件為止。
3)步驟29在泛化過程中結合元組的敏感屬性值對準標識符進行層次泛化,形成滿足(r,k)-匿名模型的等價類,得出匿名表T*。
3.2 算法分析
3.2.1 正確性分析
GDPPR算法最終會得出滿足(r,k)-匿名模型的匿名表。當簇中心距離變化小于某一閾值時, 對數據集進行簇的劃分,結合敏感信息值語義關聯,保證劃分后每個等價類敏感屬性高度相異,形成的等價類中相鄰語義敏感屬性取值頻率不超過隱私泄露閾值r。
3.2.2 時間復雜度分析
在數據集T中,設數據記錄數量為n,準標識符為m,算法中劃分p個等價類。首先遍歷數據集,時間復雜度為O(n)。初始化距離矩陣并計算簇中心,復雜度為O(p)。循環執行步驟3~步驟10,不斷更新簇中心和距離矩陣,當簇中心變化閾值小于f或迭代次數超過指定次數E時循環停止,時間復雜度不高于O(enp),e表示迭代運行次數。步驟24通過距離矩陣劃分簇,時間復雜度為O(np)。最后在步驟29依次泛化簇中元組屬性,時間復雜度為O(mp)。在整體執行過程中,GDPPR算法總的時間復雜度為O(enp)。
3.2.3 隱私泄露風險分析
針對隱私泄露,對敏感屬性給出約束條件,滿足每個等價類中相鄰語義敏感屬性取值頻率不超過閾值r。根據數據擁有者對屬性的重視程度,結合式(9),當權重值β較高時,可達到較高的隱私抵抗效果。
4 實驗結果與分析
本節驗證GDPPR算法性能,并與Mondrian算法[19]進行對比,實驗從數據效用、隱私泄露風險和執行時間[20]進行對比分析。Mondrian算法采用貪婪算法查找等價類,基于工作負載查詢泛化元組屬性,泛化策略使用多維重新編碼方法。實驗選取UCI機器學習庫中的Adult數據集和Census-Income數據集,實驗環境為Intel?CoreTMi5-4210M CPU @2.60 GHz,4 GB RAM,操作系統為Microsoft Windows10。算法GDPPR和Mondrian均使用java代碼實現。
4.1 Adult數據集
Adult數據集描述了1996年美國人口統計數據的一部分,包含15個屬性。刪除含有缺失值的記錄,得到包含有45 222個數據記錄的數據表。實驗中主要提取其中9個具有代表性的數據屬性進行驗證,即gender、age、race、marital-status、educations、native-country、workclass、occupation和salary-class。設定occupation為敏感屬性,其余8個為準標識符,在準標識符中,age為數值屬性,其余7個為分類屬性,分類屬性的泛化層次結構分別由2個~4個層次結構組成。
本文將Adult數據集中準標識符屬性權重均設為1。選取不同匿名參數k下數據集的信息損失、執行時間在準標識符組中(QI)的變化,以及不同QI值下信息損失、隱私泄露風險和執行時間隨匿名參數k值的變化情況。設定閾值參數r=0.25,根據式(9)設定重視參數α=0.5,β=0.5。具體實驗數據如表4和表5所示。
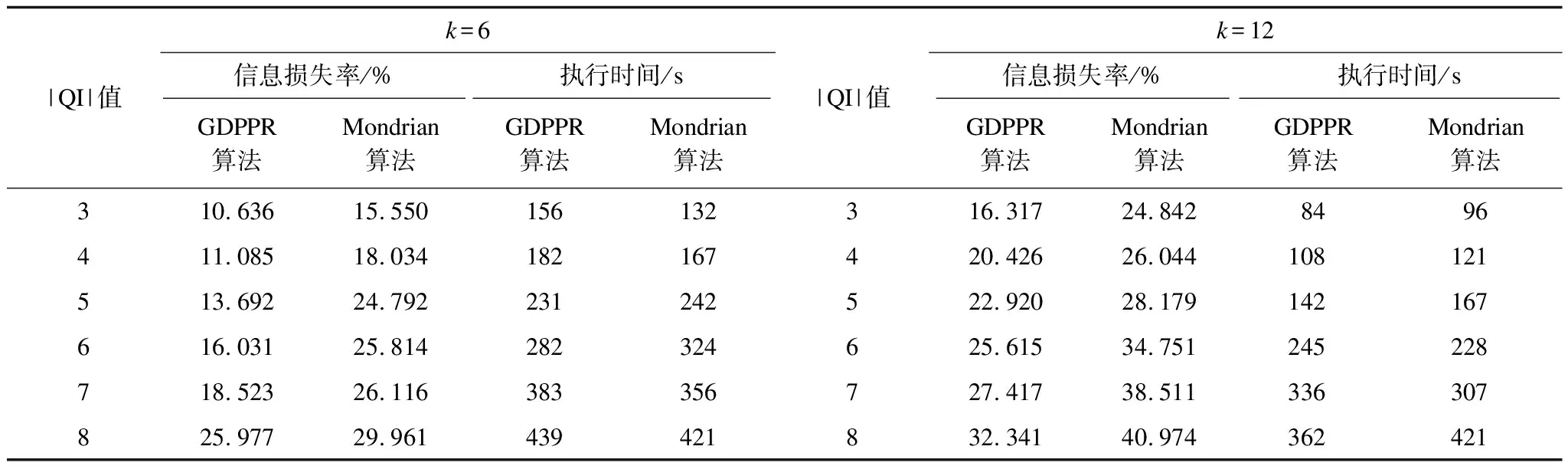
表4 Adult數據集|QI|值變化的運行結果Table 4 Operation results of |QI| value change of Adult dataset

表5 Adult數據集k值變化的運行結果Table 5 Operation results of k value change of Adult dataset
4.1.1 可用性分析
圖2給出當k=6和k=12時,|QI|值的變化在GDPPR算法和Mondrian算法中對Adult數據集的信息損失影響,信息損失均使用損失率RIL表示。
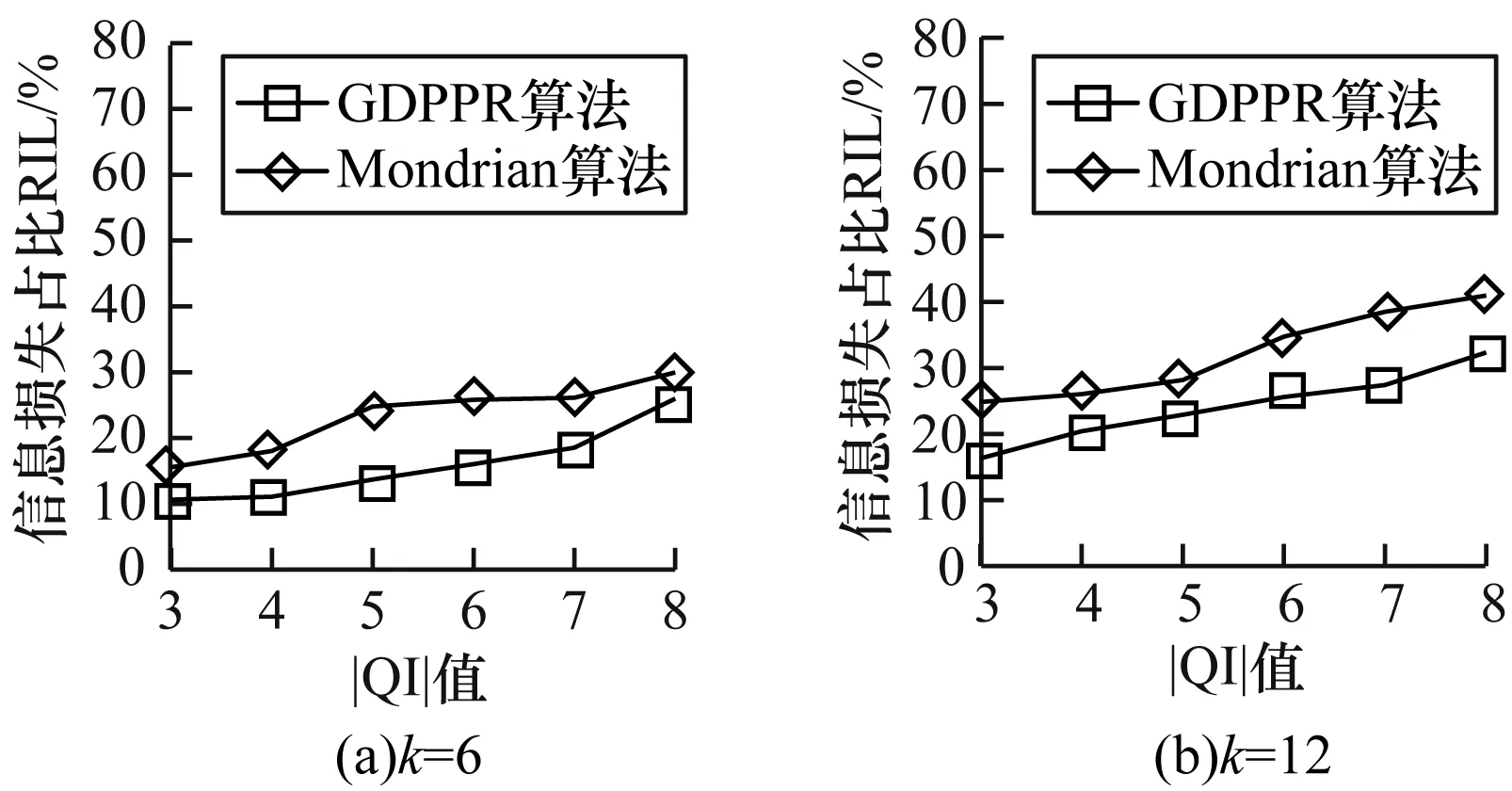
圖2 Adult數據集|QI|值變化信息損失的對比結果
從圖2可以看出,GDPPR算法泛化產生的信息損失要比Mondrian算法小。隨著QI維度的增加,信息損失逐步增加。在同等環境下,GDPPR算法可以減少約7%的信息損失。
圖3給出當|QI|=4和|QI|=8時,k值的變化對Adult數據集的信息損失影響。
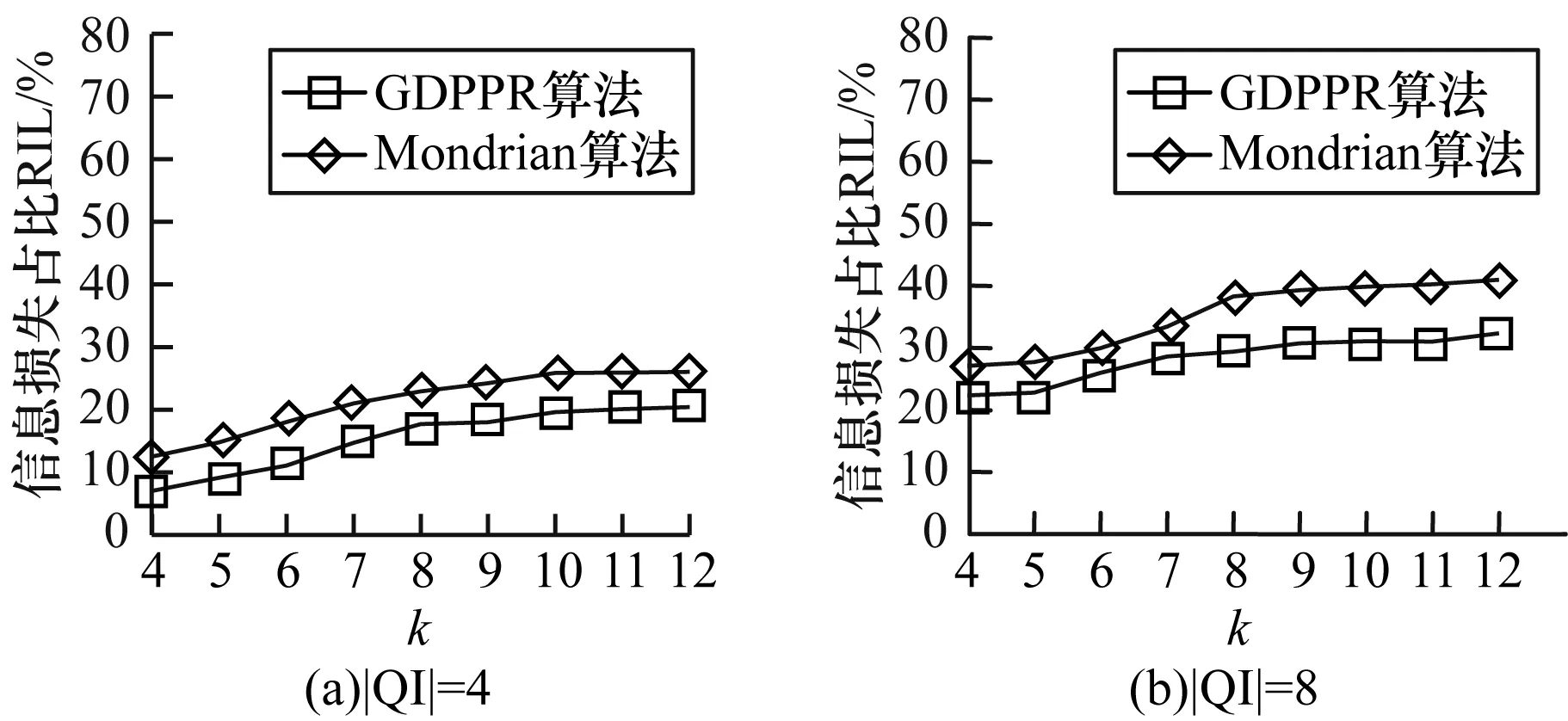
圖3 Adult數據集k值變化信息損失的對比結果
從圖3可以看出,在k值不斷增大時,造成的信息損失在不斷增大,由于k值的增大會導致等價類中元組數量增加,進而信息損失增加。但GDPPR算法信息損失在整體上少于Mondrian算法。在同等運行環境下,GDPPR算法減少約6%的信息損失。
4.1.2 泄露風險分析
隱私泄露風險主要取決于k的取值,圖4給出|QI|=4和|QI|=8時,k值的變化在GDPPR算法和Mondrian算法中對Adult數據集的隱私泄露風險影響。
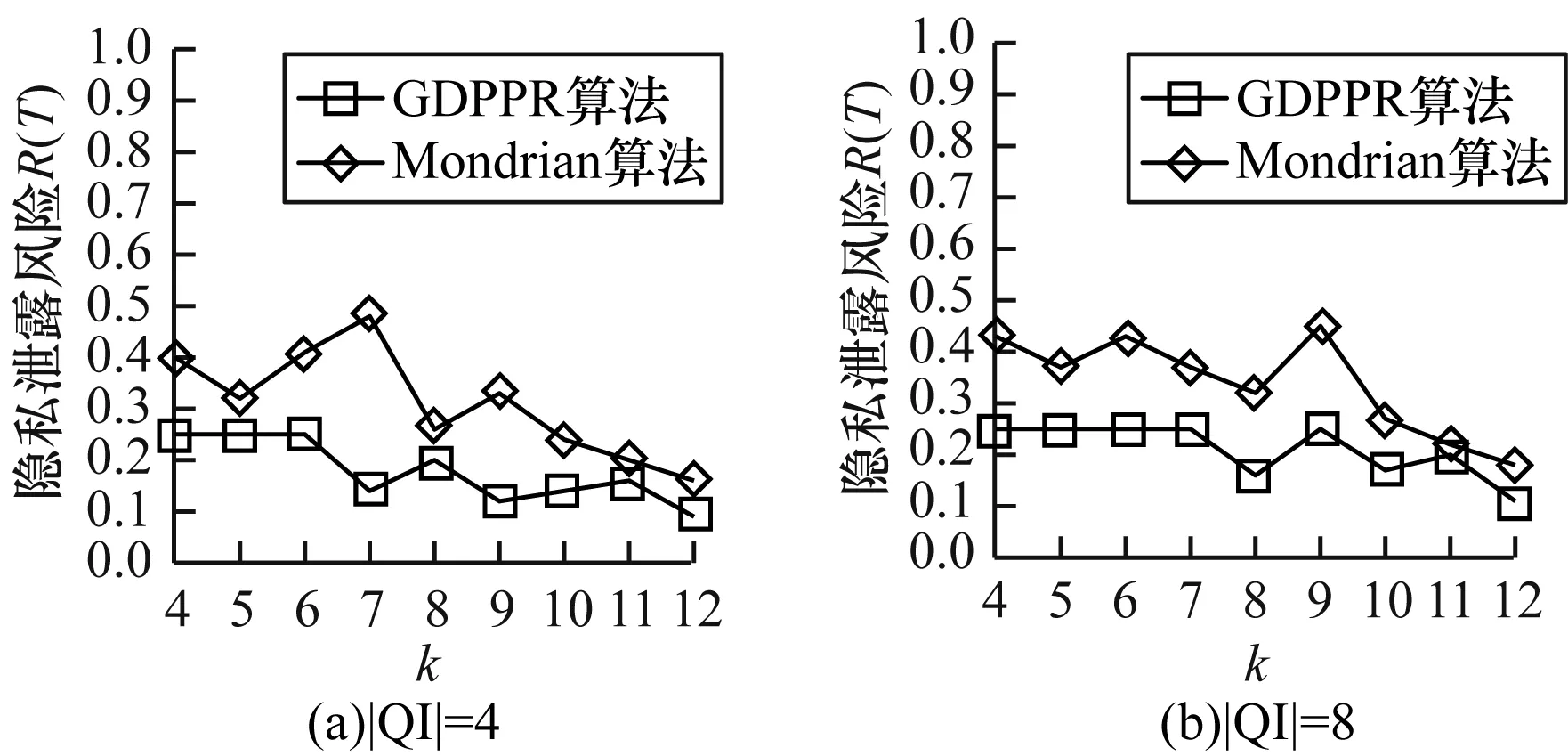
圖4 Adult數據集k值變化下隱私泄露風險的對比結果
從圖4可以看出,GDPPR算法須滿足每個等價類中的敏感屬性隱私泄露閾值不得超過0.25,Mondrian算法則無此約束,隨著k值的增加,GDPPR算法和Mondrian算法中隱私泄露風險分布無明顯規律,但整體上逐步降低。Mondrian算法的隱私泄露風險值偏高,不足以抵抗相似性攻擊。
4.1.3 執行時間分析
圖5給出當k=6和k=12時,|QI|值的變化對GDPPR算法和Mondrian算法執行時間的影響。
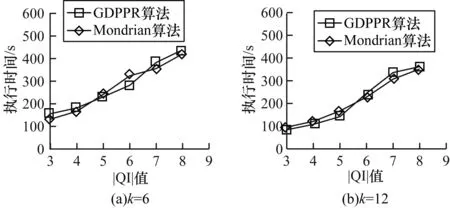
圖5 Adult數據集|QI|值變化下執行時間的對比結果
從圖5可以看出,GDPPR和Mondrian算法計算開銷區別差異不大,隨著QI維度的增加,執行時間隨之增加。這是由于QI的增加導致元組之間的距離計算開銷增加,進而使得實驗整體執行時間增加。
圖6給出當|QI|=4和|QI|=8時,k值的變化對GDPPR算法和Mondrian算法執行時間的影響。
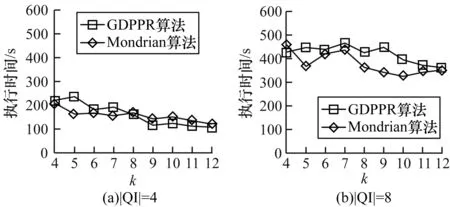
圖6 Adult數據集k值變化下執行時間的對比結果
從圖6可以看出,GDPPR和Mondrian算法執行時間整體減小,k值增加會導致匿名表中的每個等價類元組數量增加,構造等價類的時間開銷將會增大。但整個數據集元組固定,進而出現等價類個數減少,算法整體的運行時間變化幅度不大。
4.2 Census-Income數據集
Census-Income數據集包含1970年、1980年和1990年來自洛杉磯和長灘地區的未加權PUMS人口普查數據,包含有42個屬性、199 523條記錄,為降低計算開銷,本文隨機截取20%數據記錄并刪除含有缺失值的記錄,得出包含38 024個數據記錄的數據表。主要提取8個具有代表性的數據屬性,即age、sex、race、marital-status、education、country of birth self、class of worker、major occupation code。設定major occupation code為敏感屬性,其余為準標識符,在準標識符中,age為數值屬性,其余為分類屬性,泛化層次有2個~4個。
本文將Census-Income數據集中準標識符屬性權重均設為1。分別選取不同參數k下Census-Income數據集的信息損失、執行時間在準標識符組中|QI|值的變化,以及不同|QI|值下的據信息損失、隱私泄露風險和執行時間隨匿名參數k值的變化情況,實驗中設定閾值參數r=0.40。設定重視參數α=0.5,β=0.5。具體實驗數據如表6和表7所示。
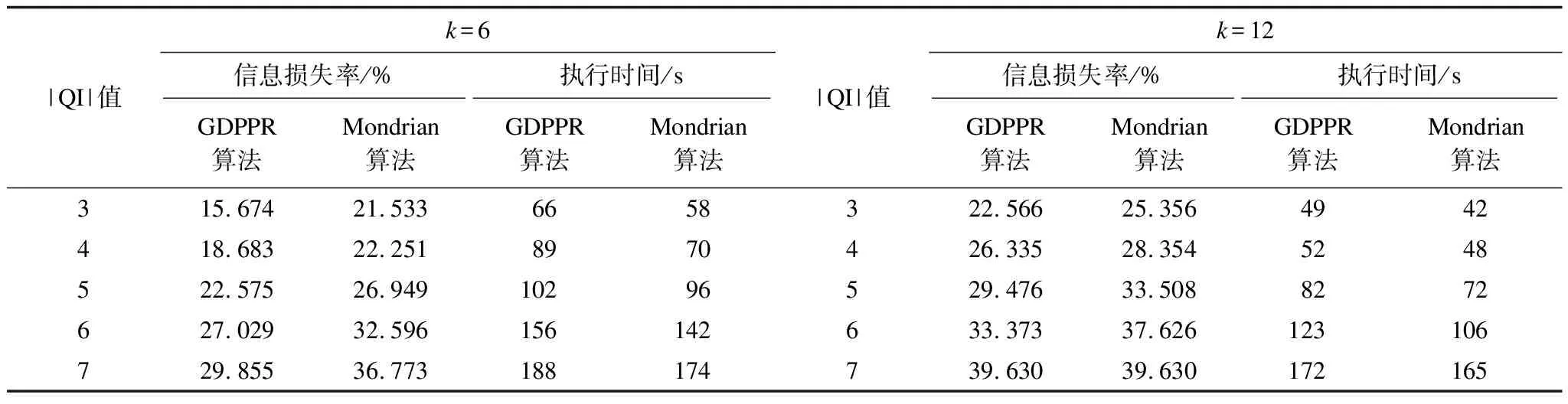
表6 Census-Income數據集|QI|值變化的運行結果Table 6 Operation results of |QI| value change of Census-Income dataset

表7 Census-Income數據集k變化的運行結果Table 7 Operation results of k value change of Census-Income dataset
4.2.1 數據可用性分析
圖7給出當k=6和k=12時,|QI|值變化在GDPPR算法和Mondrian算法中對Census-Income數據集的信息損失影響,信息損失通過損失率RIL表示。

圖7 Census-Income數據集|QI|變化信息損失的對比結果
從圖7可以看出,GDPPR算法在Census-Income數據集下泛化產生的信息損失要比Mondrian算法少。隨著QI維度的增加,信息損失也在增加。在同等環境下,GDPPR算法可以實現減少約5%的信息損失。
圖8給出了當|QI|=3和|QI|=6時,k值的變化對Census-Income數據集的信息損失影響。

圖8 Census-Income數據集k值變化信息損失的對比結果
從圖8可以看出,當k值不斷增大時,造成的信息損失不斷增大,但GDPPR算法略小于Mondrian算法。當k值增大時,導致等價類中元組數量在增加,信息損失也在增加。在同等運行環境下,GDPPR算法可以減少約6%的信息損失。
4.2.2 泄露風險分析
隱私泄露風險主要取決于k的取值。圖9給出當|QI|=3和|QI|=6時,k值的變化在GDPPR算法和Mondrian算法中對Census-Income數據集的隱私泄露風險影響。
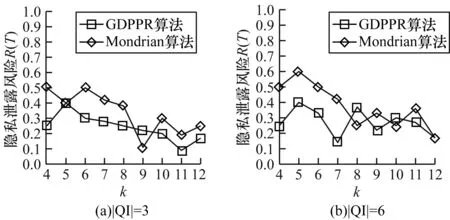
圖9 Census-Income數據集k值變化下隱私泄露風險對比結果
從圖9可以看出,隨著k值的增加,GDPPR算法和Mondrian算法中隱私泄露風險整體上逐步降低。但由于Mondrian算法未考慮敏感屬性語義關聯,相比GDPPR算法,Mondrian算法的隱私泄露風險值偏高。
4.2.3 執行時間分析
圖10給當在k=6和k=12時,|QI|的變化對GDPPR算法和Mondrian算法執行時間的影響。

圖10 Census-Income數據集|QI|值變化下執行時間的對比結果
從圖10可以看出,GDPPR和Mondrian算法執行時間差異不大,隨著QI維度的不斷增加,執行時間也隨之增加。這是由于QI增加導致元組距離計算開銷增加,進而使得執行時間增加。
圖11給出當|QI|=3和|QI|=6時,k值的變化對GDPPR算法和Mondrian算法執行時間的影響。
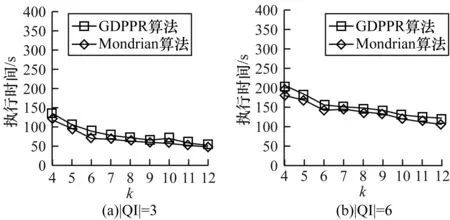
圖11 Census-Income數據集k值變化下執行時間對比
從圖11可以看出,隨著k值的變化,GDPPR算法和Mondrian算法的執行時間逐步減少,但總的執行時間變化幅度較小,且相差也較小。
5 結束語
本文針對相似性攻擊造成隱私泄露的問題,設計一種基于敏感信息鄰近抵抗的(r,k)-匿名模型,并提出一種滿足該模型的匿名方法GDPPR。該方法根據敏感屬性的語義關聯,保證所發布的數據滿足(r,k)-匿名模型。通過多組實驗的比較分析驗證了該算法有效性,泛化后的匿名表降低了相似攻擊造成的隱私泄露幾率,減少了信息損失。下一步將考慮元組屬性間函數依賴在匿名化后對信息損失的影響,以及匿名模型k值選取的優化問題,進一步提高執行效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
