知識圖譜的資產關聯模型構建和運用分析
2020-12-21 08:48:54任敬斌
中國新技術新產品 2020年20期
張 磊 任敬斌 魏 麗
(國網甘肅信通公司,甘肅 蘭州 730050)
0 引言
在市場體制快速改革的大背景下,參與跨行業、跨區域經營活動的企業數目有快速增長趨勢,電網行業精確掌握企業生產實況的難度相應增加,很可能使授信工作推進階段面對諸多阻礙。為了解除以上問題,合理地應用大數據技術,利用官方及相關數據建設模型于關聯圖譜。與常規圖譜相比,關聯圖譜能真切地勾畫出不同主體間形成的關聯網絡,特別是為帶電網數據主體勾畫出完整的“自畫像”,在三維空間還原實際狀況。
1 研究方法
1.1 知識圖譜
從本質上分析,知識圖譜為一類結構化、語義化的知識庫,其以符號為載體闡述客觀存在事物的定義、特性及其相關性。實體、相關性及與之相關的屬性為只是圖譜的基本構成單元,基于關系鏈條不同實體間形成一張知識網絡。
1.2 Spark平臺
在Hadoop 以后較為流行的新大數據處理平臺——Spark平臺,也可以將其看成是一個快捷的測算引擎,當下應用較為廣泛。Spark 吸納了Hadoop 的優勢,在設計方面進行完善,和Hadoop 相比,其效率提升了100 倍左右,因此,在有Map Reduce 迭代需求的情景內適用性更強,數據挖掘、機器學習是典型代表。
2 采集數據
首先,剖析建設知識圖譜的模式與目標對象,會涉及頂層定義、頂層事件內容,兩者在社交、物權、運營等方面存在一定的相關性。其次,把持有的信息轉型為對應的實體,存儲于圖數據庫內并建設圖節點;提獲不同本體間的相關性并細化其所屬類別,然后整體存于圖數據庫內,這是關聯邊建設的重要基礎。這樣一個知識圖譜的大體輪廓隨之形成,但是該圖譜需要在他類數據的協助下拓展內容[1]。
3 構建數據處理系統的架構
3.1 數據源
在該系統內,數據源發揮了邏輯核心功能,結合數據需求差異性,本系統涵蓋授權、爬蟲及自有數據。
3.2 存儲層
因該系統內有很多類型有別的數據源,持有高價值、權威性強的結構化數據,為了滿足系統后續階段提供的拓展需求與考評數據異構屬性,該系統擬定整合NoSQL 與SQL 數據庫的形式存儲數據,NoSQL 內未設置有嚴格要求的表結構,簡化了數據集表結構整改流程[2]。
3.3 計算層
計算層主要針對存儲在計算機系統中的非結構化數據完成抽取信息、挖掘數據等任務。構建系統過程中需要綜合應用數據挖掘、圖計算和機器學習等諸多技術。
3.4 模型層
這是系統將自身核心價值充分體現出來的層級依托,促進多個用于闡述企業相關信息的模型產出過程,進而達到整體呈現企業數據“自畫像”的目的。
4 建設資產關聯模型
4.1 捕獲與集成數據
內、外部都是獲得數據的重要渠道,前者包括上級企業傳送的數據、電子檔案影像、視頻及視頻資料等;外部數據多是微博、網站等上發布的動態結構或非結構化數據、將來集中式購置的數據等。在ETL 工具的幫襯下,每日或定時收集平臺有關數據源。
4.2 處理平臺數據
以Hadoop 的處置集群為基礎建設數據平臺,存儲、測算被采集數據信息是平臺的核心功能。Hadoop 聚集了多種功能性構件;HDFS 作為分布式文件系統,以分布式形成存儲大數據文件;在大批量數據測算過程中,YARN 發揮管理與調控資源的作用;Hbase 是持有拓展功能的NoSQL 數據庫,結構及非結構化數據均可存儲于其內;針對存留于HBase 內的數據,可采用Hve 查找、解讀數據;Spark 作為快速通用型測算引擎,通用性、適用性均處于較高層次上(如圖1 所示)[3]。
4.3 分析大數據
平臺數據處理層整合、加工、測算大批量數據后,產出面向主題的數據集與多樣化分析模型。對多源異構數據信息予以整合處理后,可以建設有闡述企業有關信息的數據模型,常見的有關系圖譜、物理方位、訴訟懲罰等,進而整體呈現出活躍在資本市場環境內的企業數據“自畫像”。
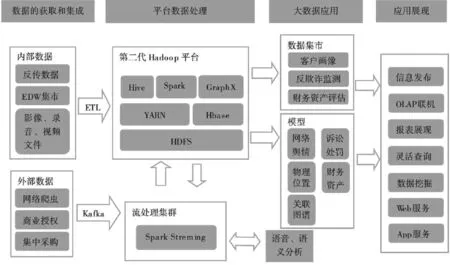
圖1 資產關聯模型圖示
5 應用情景
5.1 辨識關聯企業
很多企業間建設的關聯關系具有極為顯著的隱匿性特征,從表象上難以觀察到,合理應用大數據分析系統能促進企業關系網復原過程。利用數據挖掘技術分析企業對內部、外部真實的擔保狀況、與訴訟相關的信息,結合不同企業之間發生的大型、不均等交易活動以及大事紀等諸多信息,歷經互為印證過程判別企業間存在的關聯性。當確定大數據分析系統全面掌握了不同電力公司間塑造的關聯性行為后,就能夠關聯知識圖譜內建設出不同主體之間的聯系網絡,同時將數值分別賦予各類關聯聯系,例如,賦予互為擔保關系賦一個較大數值;小額度賬戶資金往來關聯關系,通常賦予低值;而針對間接關聯關系,通常分流程測算出關聯關系值,最后測算出2 個不同主體間的相關性程度,并智能化做出標識,逾越預設閾值時將會智能傳送出預警信號,披露企業之間存在的關聯關系。
5.2 審批與管理
在辦理授信審批業務過程中,對現場實地考評、結構化數據集審批人員的主觀判斷表現出高度依賴性,以無多維度、多樣性數據為支撐,很難準確地辨識出客戶群體的償債能力。在知識圖譜關聯的協助下,能夠減輕企業之間信息不對稱的問題,協助企業能在短時間內快速了解客戶的真實運營狀況、經濟效益、資金需求量。可以在資產關系模型的支撐下建設實時監測機制,通過挖掘信貸企業電表、水表、工資表等諸多信息,辨識出反常動向,依照現金流與上下游交易數據拓展對反常動向成因分析的深度性,特殊情況可通過自覺退離、調控抵押物等形式降低風險等級。
5.3 處置不良資產
例如,在處置人員案頭分析過程中,需要通過多種渠道采集和債務人相關的基本信息,常規方法是于數個系統內逐一搜查。可以從企業內部系統探查信息,而訴訟與實施信息可以從法院系統內捕獲,行中數據庫是查找信息的主要渠道。以上信息來源渠道繁多,并且需要符合某些條件后方可捕獲一些信息源,耗用大量的人力與時間資源。而大數據系統能深度挖掘數個數據庫,并建設其間的關聯性,這樣相關人員就能在一個界面上快捷、精確的查詢到以上所有數據源,明顯降低了工作人員的作業量。
6 結語
知識圖譜將多個類別的信息銜接為一而產出的關系網絡,其提供站在實體“關系”視角去解讀問題的能力,在闡述客觀環境中不同實體之間相關性的基礎上,還能為用戶群體提供更多有實用價值的檢索結果。該文在大數據技術的支配下,以數據建設關聯圖譜為支撐建設了資產關聯模型,該模型對信息運維管理、完善網絡過程均有一定促進作用,值得推廣。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代陜西(2021年17期)2021-11-06 03:21:36
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年2期)2011-01-23 06:39:12
