
居民對國產科幻電影的消費輿情分析及票房預測
2020-12-23 09:33:16周杰梁佳雯何加豪
中國集體經濟 2020年34期
周杰 梁佳雯 何加豪


摘要:2019年年初,以《流浪地球》為代表的一股科幻潮流席卷中國。截止2019年3月1日,其票房已達44.50億。為了研究居民對國產科幻電影的消費情緒,文章選取了電影產地、時長、上映日期、上映首日評分、上映首日評論人次和主演六種影響因素,運用決策樹(Decision Tree)和隨機森林(Random Forest)算法對國產科幻電影的影響因素進行了深度挖掘。最終以《流浪地球》為例,進行實證分析,從而證明了模型的有效性。
關鍵詞:科幻電影;隨機森林;消費輿情;AHP加權平均法
一、文獻綜述
最早的電影票房影響因素研究可追溯到20世紀中期,為經驗性研究。主要有蓋洛普對觀影觀眾進行經驗性測定,尋找觀眾感興趣內容。后期,學者開始建立模型,對電影票房影響因素進行量化研究。如王錚,徐敏基于Logit模型對電影票房影響因素進行研究,得出續集、評分、票價、檔期、明星和導演均對票房產生積極影響。在國內學者王麗娟的研究中,電影票房預測可分為“觀眾研究”、“預測模型”、”更高效的預測模型”三個階段。然而即便到了預測模型更高效的第三階段,研究者們仍主要以單一因子進行票房預測,并且采取的數據樣本較少。西方電影票房的預測通過分析樣本中影響電影票房因素的數據來實現,但其基本以好萊塢電影為樣本,以預測美國或北美的票房為目標,很少關注其他國家的情況。
本文以國產科幻電影為研究對象,研究國內居民對國產科幻電影的消費需求,同時在最后給出了相應的票房預測實證分析。
二、研究方法
本研究在前人的基礎上,采用了機器學習與大數據分析相結合的方法,將變量深度量化,以獲得對國產科幻電影影響顯著的因素并預測其票房。
(一)數據獲取
在數據獲取上,使用python的scrapy爬蟲框架、selenium包和fiddle軟件分別爬取網頁和手機app中的相關資料,并結合分布式網絡爬蟲技術,高效快捷的從貓眼電影、微博等平臺中爬取海量有效資源。
(二)方法選取
1. 決策樹CART(Classification And Regression Trees)算法
決策樹算法是一類常用的機器學習算法,是基于樹形結構來進行決策的。設有數據集D,X、Y分別為輸入和輸出變量,其中Y是連續變量(回歸模型)。包含m個樣本的數據集D可以表示為:
找到最優的切分點(j,s)之后,切分點就能將集合切分成總損失最小的兩部分。對于切分出來的區域在重復遞歸這樣的劃分過程,直到滿足條件為止。
2. 隨機森林回歸算法
隨機森林算法是一種重要的基于Bagging的集成學習方法。隨機森林可以解釋若干自變量(X1,X2,…XK)對因變量Y的作用。如果因變量Y有n 個觀測值,有k個自變量與之有關;在構建分類回歸樹的時候,隨機森林會隨機的在原數據中重新選擇n個觀測值,其中有的觀測值被選了多次。同時,隨機森林隨機地從k個自變量選擇部分變量進行分類樹節點的確定。這樣,每次構建的分類樹都可能不一樣。一般情況下,隨機森林會隨機的生成幾百個至幾千個分類樹,然后選擇重復度最高的樹作為最終的結果。
三、影響因素的指標性選擇
對于影響因素的選擇,本文采用逐步回歸法,將變量逐個引入模型,每引入一個變量都進行F檢驗和該解釋變量的t檢驗,當后面引入的變量使得原先的變量不顯著時,刪除該變量,以此確保每次引入的變量都是最優的。在研究前人的結論后得出,相關因素可能有電影時長、電影評分、評分人次、電影是產自中國、美國、日本、還是俄羅斯、上映時間是在春節期間(S1)、黃金周(S2)、還是暑假(S3)。經過逐步回歸后,我們篩選出顯著性水平較高的相關影響因素。
四、科幻電影票房預測
(一)科幻電影影響因素量化
1. 對上映日期的量化
根據電影上映的檔期不同將其分為三個檔期:賀歲檔、黃金周(五一、十一黃金周)、暑期檔。分別用S1,S2,S3三個虛擬變量來量化電影上映的檔期。
S1=1,賀歲檔上映0,其他;S2=1,黃金周上映0,其他;
S3=1,暑期檔上映0,其他
2. 對時長、上映首日評分、上映首日評論人次的量化
以分鐘為單位,從貓眼電影平臺上爬取近五年國產電影的上映首日的評分,并將評分化成十分制。從貓眼電影平臺上爬取近五年國產電影上映首日的評論人次,并將該數字轉化為以萬為單位。
3. 對主演的量化:AHP加權平均法
層次分析法簡稱AHP,在20世紀70年代中期由美國運籌學家托馬斯·塞蒂正式提出。本論文在對主演進行量化時,搜集了該演員近兩年來出演電影的票房并加以平均,以此作為衡量該演員的指標。在分析中,若演員個數大于5,則選擇能力值前5的演員;若小于等于5,則包含全部演員。定義演員陣容的影響如下:
演員陣容=∑演員綜合票房×權重
構造成對比較矩陣,根據演員能力值的大小確定,按能力值從大到小,影響程度設為9,7,5,…。假設演員為兩名時,權重分別為0.6和0.4。建立的權重結果如表1所示。
(二)建立決策樹與隨機森林模型
1. 建立決策樹模型
(1)特征選擇。特征選擇的目的是使得分類后的數據集比較純,這里就需要引入數據純度函數。此處我們選取基尼系數作為衡量數據集純度的指標,其公式為:
在模型初步建立時,我們選取“時長”、“類型”、“評分”、“評論人次”、“上映時間段”、“主演”作為特征,計算數據集的基尼系數增益值。
(2)隨機森林回歸模型。在機器學習中,隨機森林是一個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數而定。本文基于前文提到的特征,建立出電影票房預測模型。
2. 參數分類
調參的目標就是為了達到整體模型的偏差和方差最優化。進一步,這些參數又可分為兩類:過程影響類、子模型影響類。在子模型不變的前提下,某些參數可以通過改變訓練的過程,從而影響模型的性能,諸如:“子模型數(n_estimators)”、“學習率(learning_rate)”等。另外,我們還可以通過改變子模型性能來影響整體模型的性能,諸如:“最大樹深度(max_depth)”、“分裂條件(criterion)”等。
3. 參數調整
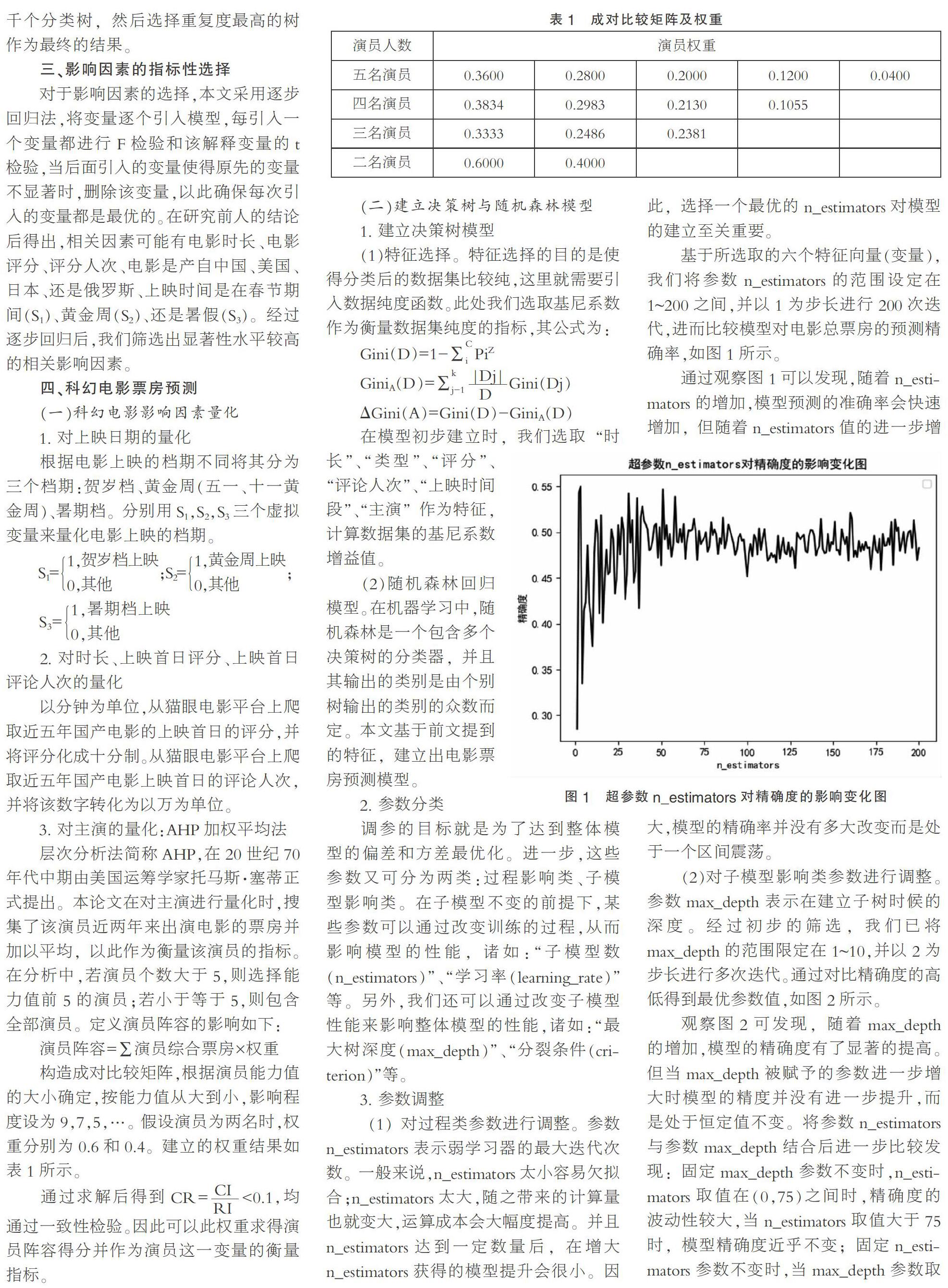
(1)對過程類參數進行調整。參數n_estimators表示弱學習器的最大迭代次數。一般來說,n_estimators太小容易欠擬合;n_estimators太大,隨之帶來的計算量也就變大,運算成本會大幅度提高。并且n_estimators達到一定數量后,在增大n_estimators獲得的模型提升會很小。因此,選擇一個最優的n_estimators對模型的建立至關重要。
基于所選取的六個特征向量(變量),我們將參數n_estimators的范圍設定在1~200之間,并以1為步長進行200次迭代,進而比較模型對電影總票房的預測精確率,如圖1所示。
通過觀察圖1可以發現,隨著n_estimators的增加,模型預測的準確率會快速增加,但隨著n_estimators值的進一步增大,模型的精確率并沒有多大改變而是處于一個區間震蕩。
(2)對子模型影響類參數進行調整。參數max_depth表示在建立子樹時候的深度。經過初步的篩選,我們已將max_depth的范圍限定在1~10,并以2為步長進行多次迭代。通過對比精確度的高低得到最優參數值,如圖2所示。
觀察圖2可發現,隨著max_depth的增加,模型的精確度有了顯著的提高。但當max_depth被賦予的參數進一步增大時模型的精度并沒有進一步提升,而是處于恒定值不變。將參數n_estimators與參數max_depth結合后進一步比較發現:固定max_depth參數不變時,n_estimators取值在(0,75)之間時,精確度的波動性較大,當n_estimators取值大于75時,模型精確度近乎不變;固定n_estimators參數不變時,當max_depth參數取值從1過度到3時,模型的精確度有了顯著提升,但當max_depth取值在(3,10)之間時,模型精確度并沒有太大提升。出于降低計算量考慮,通過圖2可將這兩個參數值分別設置為n_estimators=175、max_depth=7。
4. 參數可行性檢驗
調參的最終目的是使模型精度的方差最優化,即得到一組方差最小的參數組合。由于方差的比較會受到數據量級的影響,因此,此處我們選取精確度的變異系數作為參數優劣的指標。
通過觀察圖3容易發現,變異系數會隨著n_estimators的增大而減小,最終趨向于某一個值;變異系數同樣會隨著max_depth的增大而減小,并且同樣趨向于某一個值。因而,前文所選取的參數值滿足參數調優的要求,并且在現有變量條件下可以認為是最優參數值。
從近五年國產影片的可用數據中隨機篩選25條數據作為測試集對建立的模型進行預測。觀察圖4發現,電影票房的預測值與真實值之間擬合較好,并且計算機反饋出的模型精確率達到86.1%左右,已經處于一個很高的水平。進一步證明了所建模型具有很高的可用性。
五、實證分析
為了檢驗模型的可行性,本文對用最新上映的國產科幻電影《流浪地球》為例,從票房的預測面進行實證分析。
(一)數據的獲取與量化
利用python網絡爬蟲分別從貓眼電影、微博、藝恩網上爬取所需要的數據并進行量化,量化結果如下。
1.片長
從貓眼電影平臺上獲取該電影片長為128分鐘。
2.上映日期
該電影上映的日期為2019年2月5日,屬于春節賀歲檔類型。
3.首日評分
貓眼平臺反饋的評分信息為9.3。
4.首日評論數
以貓眼電影提供的數據為準。
5.演員
該電影的主演分別是吳京、屈楚蕭、李光潔、吳孟達、趙今麥。
(二)模型建立與預測
利用本文建立的隨機森林模型,調整參數max_depth=7,n_estimators=175至最優,得到《流浪地球》電影票房的預測值為43.11億。參照貓眼電影給出的估計值47.52億作為真實值進行比較。誤差在7%左右,處于可以接受的范圍內。
(三)預測結果分析
通過上述結果可知《流浪地球》是一部新年賀歲檔,且依據上映首日的相關數據,可以推測這是一部極具吸引力的影片,具有很大的市場。因此,影院可以加大對《流浪地球》的排片場次,加大宣傳力度。
參考文獻:
[1]蘇·奧默爾,蘇紋.測定愿望:蓋洛普和好萊塢的觀眾研究[J].世界電影1992(04):81-119.
[2]王錚,許敏.電影票房的影響因素分析——基于Logit模型的研究[J].經濟問題探索,2013(11):96-102.
[3]Li Zhuang, Feng Jing, Xiao-Yan Zhu. Movie Review Mining and Summarization[C]//Proceedings of the ACM 15th Conference on Information and Knowledge Management.ACM,2006.
[4]方匡南,吳見彬,朱建平,et al.隨機森林方法研究綜述[J].統計與信息論壇,2011,26(03):32-38.
[5]周元嬌.篩選逐步回歸方法的改進研究[D].揚州:揚州大學,2011.
*本文為江蘇省大學生創新創業訓練計劃國家級立項——“基于NPL的A股市場輿情監控及其量化投資策略研究”(項目編號:SZDG2019039)成果之一。
(作者單位:南京郵電大學)
