基于U-Net定位優化的交通標志識別網絡
2020-12-24 07:52:18馬社祥
重慶理工大學學報(自然科學) 2020年11期
劉 勝,馬社祥,孟 鑫,李 嘯
(天津理工大學 a.電氣電子工程學院;b海運學院;c.計算機科學與工程學院,天津 300384)
交通標志識別技術是許多運輸相關應用的重要組成部分,如自動駕駛、高級輔助駕駛系統。交通標志識別主要包含2個子任務,即交通標志檢測、交通標志分類。檢測任務負責定位交通標志在圖像中的具體位置,并預測相應的邊界框。分類任務負責區分交通標志的詳細類別[1]。
交通標志檢測不同于一般的目標檢測任務,它的挑戰主要來源于交通標志數據的內在特點。相比于一般的目標,交通標志通常更小,背景更復雜且容易被環境因素影響。因此,交通標志檢測相對更困難。Liang M等[2]提取目標感興趣區域,采用支持向量機對目標分類。Wu Y等[3]利用滑動窗“由粗到細”的檢測交通標志,實現了較高的檢測精度。盡管這些傳統的檢測方法已經實現了很高的檢測精度,但無法達到實時檢測的要求。近些年,由于計算設備性能的提升,深度神經網絡廣泛應用于交通標志檢測中,其中深度卷積神經網絡(deep convalutional neural network,DCNN)表現尤為突出。Zhu Z等[4]提出的多任務網絡能實現對交通標志的像素級預測。Yang T等[5]引入AN(attention network)到Faster R-CNN中提取感興趣區域,利用 FRPN(fine region proposal network)生成目標區域進行檢測。DCNN的應用極大地提升了目標檢測速度,但檢測精度仍需改進。在現實應用中,如自動駕駛需同時具備檢測精度和檢測速度,因為錯誤檢測或延遲檢測將增加系統故障風險,更嚴重的可能導致交通事故。因此,怎樣同時實現高精度和高速檢測仍值得研究。
交通標志分類任務比檢測任務簡單。大多交通標志分類方法都評估于德國交通標志識別基準(German traffic sign recognition benchmarks,GTSRB)。一些最先進的方法已經達到極好的分類準確率。例如,采用多列深度神經網絡[6]實現交通標志分類,達到了與人類視覺分類相當的表現。Jin J等[7]提出用 hinge loss作為卷積網絡的損失函數,實現了先進的分類表現。這些方法在單一的分類數據集中表現優異,但與檢測網絡相結合時,由于預測邊界框偏差導致分類結果準確率下降。為了解決該問題,Li J等[8]提出利用傳統圖像處理方法來優化目標定位問題,即結合交通標志的顏色和形狀信息來優化候選交通標志的邊界框,從而實現對交通標志分類效果的提升。為進一步提升分類精確度,筆者提出采用U-Net實現候選交通標志的語義分割,然后對分割后的圖像進一步處理實現交通標志的定位優化,從而提升了分類網絡的分類準確率。
1 交通標志識別網絡
交通標志識別網絡包含3個子網絡:檢測網絡、定位優化網絡和分類網絡。首先,分別訓練3個子網絡,當驗證集損失不再降低則停止訓練。然后將輸入圖像經過檢測網絡處理后生成候選交通標志,再利用訓練好的U-Net網絡對候選交通標志語義分割以實現交通標志邊界框的優化。最終將優化后的候選交通標志輸入STN網絡分類。具體流程如圖1所示。
1.1 檢測網絡
圖2展示了端到端檢測網絡結構。首先,將圖像輸入到主干網絡(backbone network)提取多尺度特征,輸出不同尺度的特征圖。然后,通過特征融合網絡融合不同尺度的特征圖以生成3個輸出張量。最后,3個張量經過預測模塊處理后得到相應的邊界框、類別和目標分數。預測模塊采用與YOLOv3[9]相同的計算方法,本文中不過多贅述。
根據主干網絡的設計因素對檢測性能的影響,設計了一種新型的端到端網絡結構,主要包括主干網絡和特征融合網絡,分別用于特征提取和特征融合。
1.1.1 主干網絡
主干網絡是深度檢測網絡的一個重要組成部分,通常用來提取圖像的多尺度特征。CAI Z等[10-12]研究了下采樣率和網絡深度對檢測網絡性能的影響。這些影響對小尺寸目標是顯著的,即采樣率更大且深度更淺的網絡對小尺寸目標檢測起積極作用。根據這些因素對檢測效果的影響,設計一個基于Darknet-53的主干網絡,網絡結構如圖2所示。該網絡的卷積層由52層減少至48層,詳細配置參數如表1所示。主干網絡的輸出端尺度由原(13×13)(26×26)(52×52)改進為(26×26)(52×52)(104×104)。考慮到網絡頂層會預測更多的目標幾何特征,對尺度為(13×13)的特征圖連續上采樣,產生尺度為(26×26)(52×52)(104×104)的特征圖,然后在特征融合網絡中將生成的特征圖與之前對應尺度的特征圖融合。由于網絡底層能產生更好的語義信息,因此,對尺度為(208×208)的特征圖池化下采樣,以便與其他尺度特征融合。
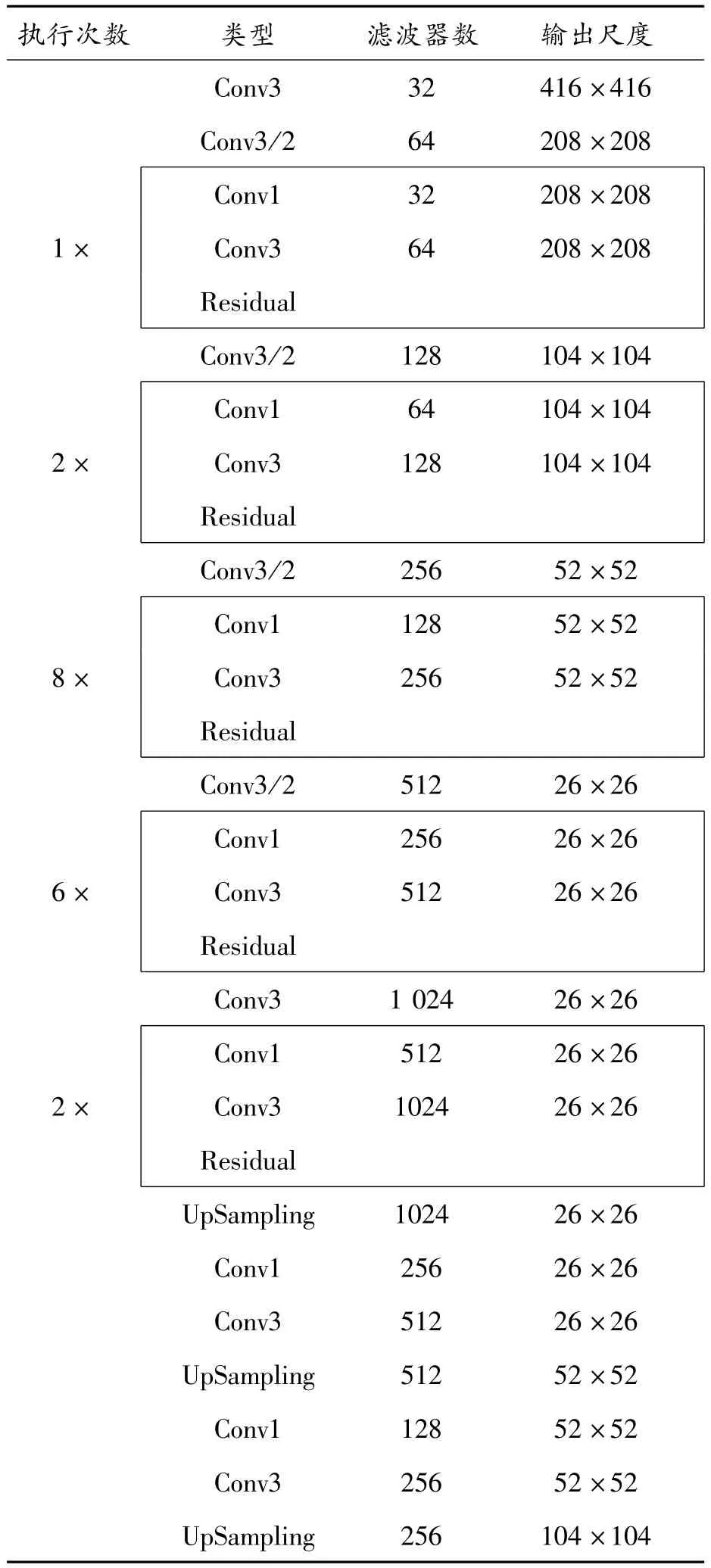
表1 主干網絡參數配置
1.1.2 特征融合網絡
為了解決目標檢測中的尺度變化問題,圖像金字塔[13]和特征金字塔網絡(feature pyramid network,FPN)[14]相繼被提出。但圖像金字塔需要輸入多尺度圖像,FPN會因提取多尺度特征而增加計算成本。為應對以上問題,設計了一種特征融合網絡,如圖2所示。該網絡融合4個不同尺度的特征圖以生成3個輸出端(Output1、Output2和Output3),對應的尺度分別為(26×26)(52×52)(104×104)。在特征融合過程中,尺度相同的特征圖通過級聯(Concatenate)的方式融合,尺度不同的特征圖通過最大值池化(Maxpoo-ling)或上采樣(UpSampling)將特征圖大小調整為與輸出特征圖大小相同,然后采用級聯融合。
1.2 定位優化網絡
由于檢測后的交通標志存在邊界框的回歸偏差,若將其直接分類會造成較大的分類誤差。因此,在檢測網絡和分類網絡之間應用定位優化網絡來優化候選交通標志的邊界框,并達到提高分類精度的目的。
1.2.1 定位優化方法
具體定位優化流程如圖3所示:①提取檢測網絡預測的候選交通標志。②分別擴大候選交通標志的寬和高1.33倍。③利用分割網絡實現圖像的語義分割。④提取分割后的交通標志輪廓,并裁剪出新的候選交通標志。⑤將新的候選交通標志輸入STN網絡分類。
選用 U-Net[15]作為分割網絡,并應用 Res-Net50作為 U-Net的主干網絡。U-Net是基于FCN[16]的語義分割網絡,通過擴大和修改網絡框架使其能夠使用很少的訓練數據就達到很好的分割效果。由于實驗中訓練分割網絡的數據較少,所以選用U-Net實現候選交通標志分割。
1.2.2 存在的問題及解決方法
交通標志數據中存在多個交通標志相鄰的情況,在檢測后會使邊界框偏差更大。擴大邊界框后會產生一張圖像中包含2個交通標志的情況,如圖4(左)所示。為解決該問題,在標注數據時每幅圖像僅標注一個完整的交通標志作為分割目標。這種做法很大程度地減少了不完整交通標志帶來的分割錯誤問題。
雖然問題得到改善,但是還存在一些錯誤分割情況,如圖5所示。對于這類問題,首先利用輪廓檢測提取圖像中的2部分,然后計算各部分面積,選取面積最大的為分割目標,最終實現交通標志的精確分割。
1.3 分類網絡
分類網絡的任務是將重新定位的候選交通標志分成詳細類別。選用空間變換網絡(spatial transformer network,STN)[17]作為分類網絡。該網絡無需標定關鍵點,并且能夠根據分類或者其他任務自適應地將數據進行空間變換和對齊(包括平移、縮放、旋轉以及其他幾何變換等)。STN在交通標志分類任務中表現優異,因此,選用該網絡實現識別網絡的分類功能。
2 數據集
在訓練檢測網絡、定位優化網絡和分類網絡的過程中,分別用到了交通標志檢測數據集、交通標志分割數據集和交通標志分類數據集。
2.1 交通標志檢測數據集
1)TT100K
TT100K(Tsinghua-Tencent 100 K)是中國現實交通標志數據集基準,該數據集提供了100 000張圖像,共包含了30 000個交通標志實例。每張圖像的分辨率為2 048×2 048,且囊括了多種不同場景下的目標,如不同光照、不同天氣等狀況。每個交通標志分別標注了類別、邊界框和像素掩碼。實驗選用6 105張帶有標注信息的圖像為訓練數據,3 071張帶有標注信息的圖像為測試數據,并將數據標注為3類,分別為Prohi-bitory、Mandatory和Danger。
2)GTSDB
GTSDB(German traffic sign detection benchmarks)是德國交通標志數據集基準。該數據集包含900張帶有標注信息的圖像,每張圖像的分辨率為800×1 360。選用600張為訓練數據,300張為測試數據。該數據集是目前應用最廣泛的數據集之一,因此用來評估提出的檢測網絡。根據交通標志特點,數據集被標記為4類,分別為Prohibitory、Mandatory、Danger和 Other。
2.2 交通標志分割數據集
為了更好地完成候選交通標志的語義分割任務,制作了一個小型交通標志分割數據集。該數據集包含500張圖像,每張圖像僅標注一個交通標志作為前景,其他像素全部標注為背景。收集GTSDB訓練集中被檢測出的交通標志作為訓練數據,并將預測邊界框的尺寸擴大原尺寸的1/3,以保證圖像中有完整的交通標志。選用labelme作為標注工具,首先標注交通標志的輪廓,然后將其轉化為像素掩碼,最后利用像素掩碼完成網絡訓練。
2.3 交通標志分類數據集
對于交通標志分類網絡的訓練,采用GTSRB(German traffic sign recognition benchmarks)作為訓練和測試數據集。該數據集包含超過50 000張圖像,共43個類別,是目前應用最廣泛的交通標志分類數據集之一。選用其中37 901張作為訓練集,12 630張作為測試集。
3 評估指標
在實驗中,采用平均精度均值(mean average precision,mAP)作為評估檢測網絡檢測性能的指標。根據精確率/召回率曲線計算平均精度(average precision,AP)。精度率和召回率定義如式(1)所示,其中TP、FP、FN分別表示正確識別的正樣本、錯誤識別的正樣本和錯誤識別的負樣本。AP的計算方法定義如式(2)所示,其中p(k)是召回率為k時的測量精度;k是召回率變化點;Δr(k)是召回率的變化量;n是召回率變化點的總數;i是類別的索引值。mAP通過計算所有類別AP的均值所得,其中m是類別數。
通過計算預測邊界框(Bp)和真實邊界框(Bgt)之間的交并比(intersection over union,IOU)驗證預測的準確性。IOU定義為
曲線下面積(area under curve,AUC)可以通過積分計算精確率/召回率曲線下的面積求得。AUC用于衡量本文方法和傳統交通標志檢測方法的檢測準確性。為了評估交通標志識別網絡的整體性能,采用分類準確率作為衡量指標之一。分類準確率的定義為
4 實驗結果分析
實驗平臺配備雙 TITAN Xp GPU,Intel(R)Core(TM)i7-7800X CPU,32GB RAM,Ubuntu 16.04操作系統,實驗中采用Python實現網絡模型的編譯。
4.1 檢測結果分析
4.1.1 實施細節
在實驗中,采用Keras構建提出的檢測網絡、YOLOv3和 RetinaNet(ResNet50),采用 TensorFlow構建 Faster R-CNN(ResNet50)。對 TT100K和GTSDB數據集上的輸入圖像尺寸分別調整為416×416和416×672。為了獲得更好的訓練結果,在訓練期間應用遷移學習。對于TT100K數據集,加載在Imagenet上預訓練的Darknet-53前35層卷積層權重。首先,凍結前35層卷積層,經過50次迭代后解除凍結。然后,所有層在經過30次迭代后結束訓練。對于GTSDB數據集,通過加載在TT100K上訓練好的權重來實現遷移學習。
表2展示了相關超參數配置。
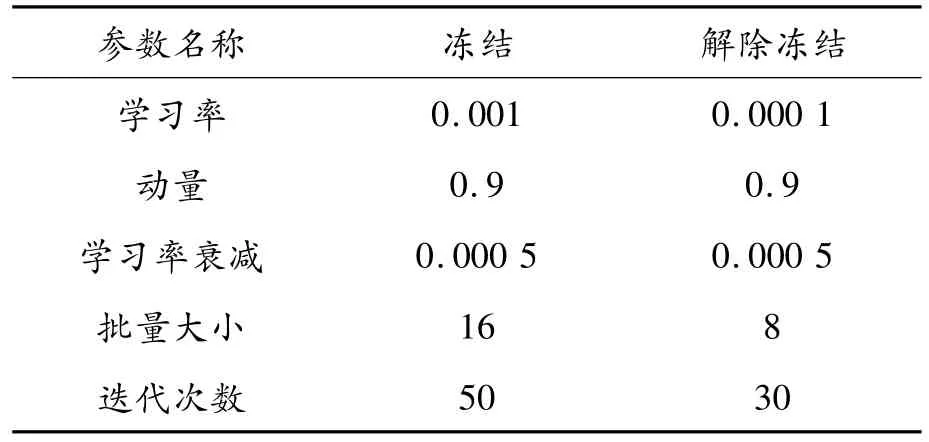
表2 超參數配置
4.1.2 檢測表現
為了分析檢測網絡的性能,分別在TT100K和GTSDB兩個數據集上進行測試分析。在TT100K數據集上對比不同深度網絡的檢測表現。在GTSDB數據集上分別與深度網絡和傳統檢測方法對比。由于TT100K數據集中的目標比GTSDB數據集的更小,所以應用TT100K訓練和測試更能展現網絡對小尺寸目標的檢測能力。下面從檢測準確率和運行時間2個方面分析說明。
1)準確率分析
表3展示了在TT100K數據集下的實驗結果。在3個類別中,提出的檢測網絡的AP分別達到86.60%、88.24%和87.88%。因此,提出的網絡模型對小型交通標志的檢測能力更強。
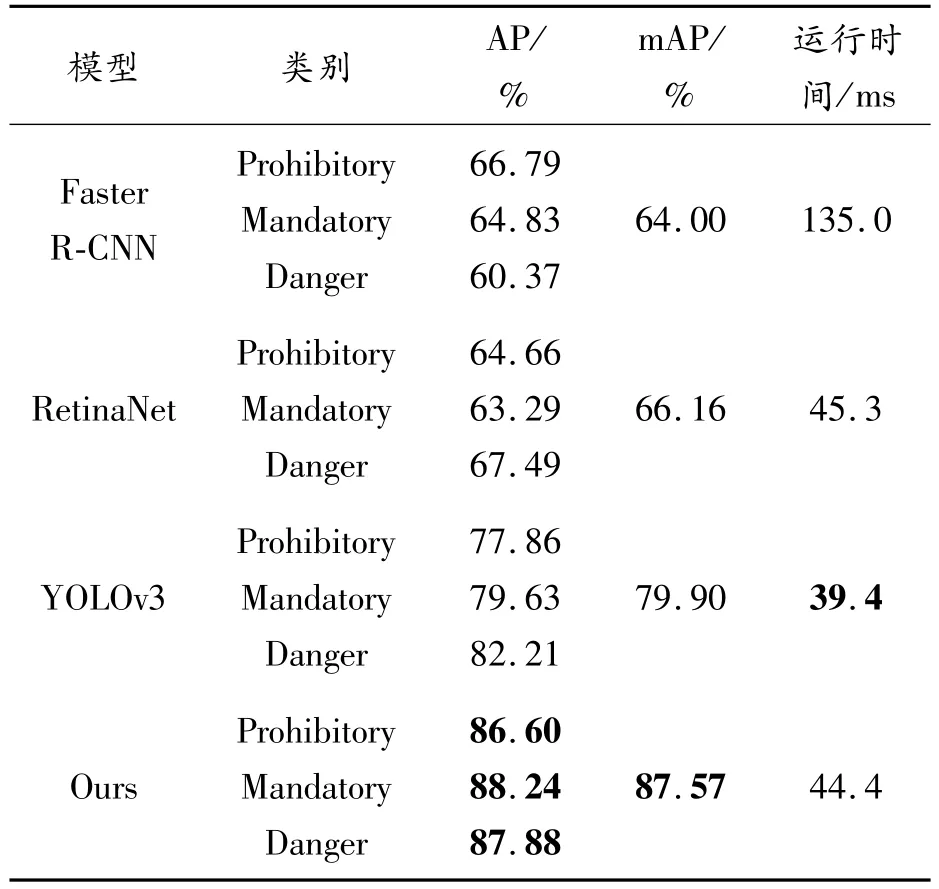
表3 TT100K下檢測精度和檢測速度
表4展示了在GTSDB數據集下的實驗結果。與其他幾個深度網絡的檢測AP對比,除YOLOv3和Ours外的其他網絡實驗數據來源于文獻[18]。提出的檢測網絡能夠檢測4類交通標志,且每類的檢測表現都優于其他網絡。與YOLOv3相比,提出的網絡在每個類別都實現了性能提升,尤其對Other類提升最大。除了與深度網絡相比,表5中還展示了與傳統方法的對比數據。采用AUC作為準確性評價指標。提出的網絡在檢測準確性方面實現了與ROI+HOG+SVM[19]方法相當的性能,但運行時間約為它的1/3。總體來看,提出網絡的表現更佳。
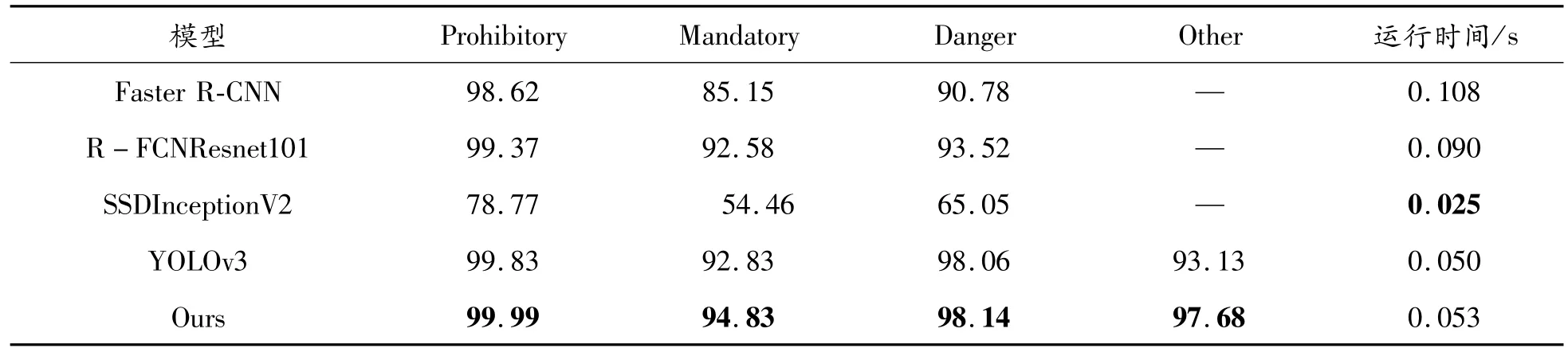
表4 GTSDB下檢測精度和檢測速度

表5 GTSDB下與傳統方法檢測精度和檢測速度
2)運行時間分析
運行時間是交通標志檢測系統中的重要指標。對于TT100K數據集,表3中對比了不同深度網絡的運行時間,其中YOLOv3的檢測速度最快,每張圖像的執行時間為39.4 ms。提出的檢測網絡的運行時間僅次于YOLOv3,而且檢測精度遠高于其他3個檢測網絡,實現了87.57%的mAP,每個圖像的平均執行時間為44.4 ms。
對于GTSDB數據集,表4和表5分別與深度網絡和傳統方法的運行時間進行比較。提出網絡的運行時間遠優于傳統方法,且檢測精確度實現了與傳統方法相當的性能。
4.2 定位優化結果分析
前文提及利用傳統圖像處理方法實現定位優化[8]。在實驗中復現該方法,并與提出的定位優化方法進行對比分析。主要從3個方面對比討論:特殊實例優化、分類準確率優化和識別網絡整體優化。
1)特殊實例優化分析
針對具有代表性的交通標志對比分析,如目標清晰、目標模糊、特殊目標以及多交通標志等。圖6展示了原始圖像、傳統方法優化結果和提出方法優化結果。從圖6中可以看出:對于一些特殊目標和模糊目標,傳統方法不能很好地重新定位,而被提出的方法實現了精確的目標定位。由此可見,提出的方法對特殊實例有更好的優化效果。
2)分類準確率優化分析
分析分類準確率的目的是驗證定位優化網絡對STN網絡分類效果的影響。表6中給出了未使用定位優化方法、傳統方法和本文中提出的優化方法的分類優化效果。表中的分數閾值為分類器的分數閾值,分類得分大于該值則預測類別,反之不預測。從表6中可以看出:提出的方法對分類準確率有很大提升,且在各個分數閾值下的優化效果都優于傳統方法。
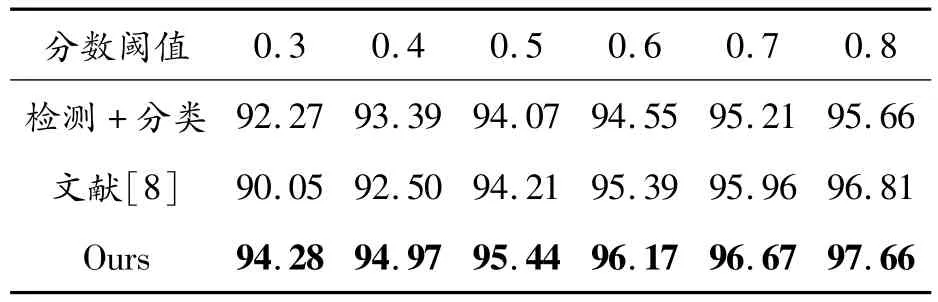
表6 不同分數閾值下分類準確率
3)識別網絡整體優化分析
表7為識別網絡的mAP結果。可以看出:傳統方法對原始網絡的作用是消極的,使mAP大幅下降。而提出的方法對各個閾值下的性能都有提升,尤其對于分數閾值為0.7和0.8下的mAP提升效果最大。總體來看,提出的網絡展現了優異的性能。

表7 不同分數閾值下mAP
5 結論
1)提出了一種基于YOLOv3的交通標志檢測網絡。該網絡實現了快速精準的交通標志檢測。
2)通過引入定位優化網絡重新生成候選交通標志,提升了分類網絡的準確性。通過在TT100K和GTSDB數據集上的訓練和測試驗證了所提方法的有效性。
3)基于YOLOv3的檢測網絡可以應用于其他小型目標檢測中,尤其對于同時需要高速和高精度檢測的任務。定位優化方法能有效提升識別網絡的整體性能,可以將其添加到各種需要檢測和分類網絡聯合應用的任務中,以此來提升網絡性能。對于定位優化方法中的分割網絡還有進一步提升的空間,也是未來重點研究內容。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
