基于卷積神經網絡的特征描述子學習
2020-12-26 22:32:11馬正見文志誠
企業科技與發展 2020年7期
關鍵詞:特征提取
馬正見 文志誠


【摘 要】隨著深度學習的發展,作為圖像任務基礎的特征描述子開始傾向于通過卷積神經網絡學習。目前的卷積神經網絡模型大多采用交叉熵損失項進行約束,通過大量的輸入數據訓練網絡。但由于缺乏細節上的約束,因此訓練的網絡模型特征提取能力并不優秀。針對以上問題,文章提出一種新的淺層神經網絡模型,并在此基礎上通過改進采樣策略以獲得更多的訓練樣本,使用復合的損失項對網絡訓練過程進行約束。實驗表明,提出的神經網絡模型能夠獲得更緊湊的特征描述子,特征提取的能力更強。
【關鍵詞】卷積神經網絡;特征提取;特征描述子;特征匹配
【中圖分類號】TP391.41 【文獻標識碼】A 【文章編號】1674-0688(2020)07-0041-03
特征匹配是計算機視覺的基礎任務,其中涉及的主要問題是對圖像局部區域進行特征描述,以獲得能更好表達圖像局部區域信息的特征描述子。
早期的研究工作傾向于手工設計的描述子,包含SIFT[1]、SURF[2]、ORB[3]等。這一類描述子依賴人類對圖像像素分布的認知,在早期的研究中占主導地位。
隨著大規模帶有標簽的圖像數據集的出現,神經網絡開始廣泛用于處理計算機視覺相關任務。其中,P Fischer等人在文獻[4]中證明從ImageNet[5]神經網絡最后一層學習到的特征描述子在性能上比傳統SIFT更優秀。S Zagoruyko等人在文獻[6]中對不同網絡模型進行測試,實驗證明基于學習方式獲得的描述子性能優于手工設計的描述子。
1 基于學習的卷積神經網絡
基于數據學習的方式從給定的數據集中訓練一個能準確區分匹配與非匹配輸入的神經網絡。對于兩個輸入xi與xj,分別將它們通過初始的卷積神經網絡后獲得相對應的特征描述子yi、yj,將它們之間的匹配程度通過一個距離進行衡量,距離在閾值范圍內則視為匹配,否則為非匹配。
輸入的圖像數據通過卷積神經網絡進行特征信息提取,其中最關鍵的是卷積和全連接處理。卷積就是對輸入進行局部特征提取,而全連接則是將提取到的局部特征進行組合描述,全連接層也可以視為一個特殊的卷積。
像素點在前一層圖像的特征提取范圍稱為感受野。當像素點所處的層數越深,感受野越大,能獲取的特征信息也越多。卷積過程如公式(1)。
xn+1=sign(f(w,xn)+b)(1)
其中,xn代表當前卷積層的輸入,w與b是卷積層需要學習的權重和偏置,f為線性變換函數,sign為激勵函數,xn+1為當前卷積層的輸出。
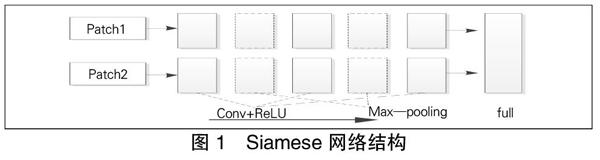
Siamese是一個學習階段常用的網絡模型,它由兩個共享參數的分支構成。在訓練時分別將兩個訓練圖像數據通過網絡的分支提取特征向量,最后一層以一個相似度函數對兩個向量進行相似性評估。整個網絡結構如圖1所示。
圖1由左到右分別為輸入的圖像patch、3個卷積層及2個池化層和1個相似度函數度量層,其中2個分支的卷積層與池化層的參數保持一致。另一種Siamese網絡模型卷積與池化層中的參數由兩個分支各自進行學習。文獻[6]對網絡結構進行了改進,引入中心環繞雙流結構,將輸入的64x64的圖像數據分為中心裁剪的32x32和下采樣的32x32兩個輸入,分別用兩個Siamese網絡模型進行計算,減少了輸入數據的維度,加速了網絡模型的學習速度。
為了加速學習到的特征描述子的匹配,X Han等人提出對MatchNet[7]網絡將特征向量學習過程與特征向量匹配過程進行拆分,拆分后學習到的特征向量可以進行多次匹配。同時,他們還在特征向量學習網絡的最后加入了一個瓶頸層,實現了參數降維的效果。
2 基于卷積神經網絡的描述子學習
2.1 三元組樣本采樣策略
由上文可知,在訓練過程中需要不斷地使用訓練樣本來更新參數。基于之前研究者的經驗,只有具有區分度的訓練樣本,才能促進參數的更新,而不具備區分度的樣本,不僅對網絡的訓練毫無意義,還造成大量計算損失。
雖然類似于文獻[8]提出的一系列采樣策略能獲得一些優質樣本,但都需要大量的原始數據作為支撐。為了解決這個問題,本文提出一種新的采樣策略,在這種策略下,即使在原始數據較少的情況下也能采集到足夠多的訓練樣本。
記批次內樣本為X={x1,y1,…,xm,ym,…,xn,yn},其中上標相同的兩個樣本為一對匹配的3D點。通過網絡后的描述子為Y={x1,y1,…,xm,ym,…,xn,yn}。對應的點為正例樣本,同批次中計算出距離最遠的點為負例樣本。兩點間距離計算:
其中,q為描述子的維度。為了獲得距離最大的硬性負樣本,對樣本點間距離計算結果以距離矩陣D表示。這里同類間的點不進行計算以免出現距離為零。距離矩陣D可表示:
式中的2為距離公式d中計算出的通項,后者為距離計算余項的向量表示。距離矩陣D對角線上的項為匹配點的距離,其余項為非匹配點距離。對任意一個錨點,可以從距離矩陣中獲取它的匹配點及距離最小的非匹配點,這3個點組合即形成三元組樣本數據。
這里本文引入兩個額外的計算,即分別計算Y中x、y類別中點之間的相對距離,距離矩陣記為DX、DY。距離項越小,則說明兩個描述子的位分布越相似,反之差異大。若兩個描述子與錨點的距離都很近并且它兩的位分布差異大,那么這兩個描述子對應的點都可以作為非匹配點進行采樣。因為位布差異大,所影響的參數位置不一樣,所以都能很好地促進網絡參數學習。
2.2 損失函數選擇
描述子的相似性損失約束的是描述子提取特征信息的能力。具體體現為減小樣本中匹配的點之間的距離,增加非匹配點間的距離。神經網絡將調整參數滿足這種結果。相似性約束項以公式可以表示如下:
描述子的匹配如圖2所示。樣本中的點視為同類的類內點和非同類的類間點,那么描述子的匹配就可以看做類間點的擇優問題。之前的研究傾向于研究類間的關系,忽視了類內點蘊含的信息。本文將加深對類間點距離信息進行利用。
以圖2中匹配對(x2,y2)為例。計算x2與其他類內點間的距離,比如與x1點間的距離為d1。y2為匹配點,則它與x2的類間距離小,描述子的位分布相似,與x1計算的距離也應當近似于d1。同理,作為x1類間匹配點的y1點到y2的距離也應當非常接近d1。本文將這種類內、類間關系進行如下約束:
這里的兩個類間距離的值可以直接從“2.1”中計算的DX、DY獲得。若兩個錨點間的距離較大,那它們匹配點之間的距離也應該較大,類間約束項就是約束神經網絡參數向這一目標進行更新。由于距離過大的類之間的作用并不明顯,再進行約束反而會使結果變差,因此這里用U限定參與計算的類內點的范圍。
描述子的緊湊性約束目的是使神經網絡產生的描述子位分布均勻,這里設計的約束項:
其中,B為描述子的維度,S為每批次訓練樣本的數目。通過最小化描述子緊湊性損失項使描述子在維度較低的情況下攜帶更多的特征信息。
由于各個損失函數對訓練過程的影響不同,因此需要對它們添加一個影響因子,于是完整的損失函數可以表示如下:
2.3 訓練的卷積神經網絡模型
由于輸入的訓練圖像尺寸相對較小,因此選擇的卷積神經網絡層數較淺,其結構包括1個輸入層、6個卷積層和1個全連接層,在池化層的選擇上摒棄了傳統的最大、平均值池化方式,選擇的是能更好保留信息的跨步卷積。同時,為了加速網絡學習速率,在每次卷積后進行歸一化處理。優化器選擇的是Adam[9]優化器。
3 實驗與分析
用于實驗的數據集有Brown數據集和Oxford數據集。用數據集中帶標簽的數據訓練網絡模型到收斂,再在數據集上對訓練好的模型進行測試以檢測描述子的各項能力。
3.1 描述子性能驗證
用Brown數據集檢驗描述子的特征提取能力,它包含3個子數據集。用1個子集進行網絡模型訓練,然后在其他子集上測試。各類模型在召回率為95%的數據集上進行訓練測試,測試結果見表1。
從表1的結果可以看到,基于學習方式獲得的描述子性能遠遠優于基于手工設計的描述子。每個輸入的樣本都對卷積神經網絡的參數進行調整,當進行多次的優化后網絡參數達到一個穩定的值不再變動。通過不斷地優化,使得網絡擁有更強的圖像細微特征提取、組合能力。
3.2 關鍵點匹配實驗
衡量一個描述子性能最重要的一個部分就是描述子進行匹配的準確率。這里使用Oxford基準數據集。用特征點檢測器提取特征點周圍像素作為神經網絡的輸入,實驗結果如圖3所示。
基于學習方式獲得的特征描述子總體的性能比手工設計的描述子要好得多。尤其是SIFT還作為最優秀的手工設計方法之一,在同樣的實驗環境下總體的表現相較于基于學習方式的描述子略差一些。本文的算法總體上的結果都有很好的表現,充分說明了使用的約束項加強了卷積神經網絡的特征提取能力。
3.3 描述子的緊湊性
通常,優秀的描述子都應該具備緊湊性質,占用更少的空間并包含更多的信息。滿足這樣條件的描述子應當在每個位分布上居于一個平衡的位置,在某個信息位上不能總是出現固定的值,這樣相同的值使描述子的區分性能有所降低。
這里通過隨機選取的測試點對描述子的緊湊性進行實驗。實驗結果如圖4所示。
由圖4可以看到,隨機挑選出來的測試點生成的描述子位的平均分布大體上靠近零,意味生成的描述子的各個位在零上下分布較為均勻,這樣的描述子能攜帶的信息量大。形成這樣均勻的位分布的主要原因是損失函數中對描述子緊湊性的約束,致使卷積神經網絡學習到更優質的描述子。
4 總結與展望
本文提出一種新的采樣策略獲取更多數目的訓練樣本,同時引入多個損失項以約束卷積神經網絡參數更新方向,提升了生成描述子的性能。實驗表明,通過本文方法獲得的描述子在匹配性能及緊湊性上比傳統手工設計更好。但和大多數網絡結構一樣,未解決圖像模糊帶來的問題,這也將是下一步我們要解決的一個重要問題。
參 考 文 獻
[1]Lowe D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Com-puter Vision,2004,60(2):91-110.
[2]Bay H,Tuytelaars T,Gool L V.SURF:Speeded up robust features[C].Proc of the 9th European Conferenceon Computer Vision,2006:404-417.
[3]Rublee E,Rabaud V,Konolige K,et al.ORB:An efficient alternative to SIFT or SURF[C].Proceedings of IEEE International Conference on Computer Vision,2012:2564-2571.
[4]Fischer P,Dosovitskiy A,Brox T.Descriptor mat-
ching with convolutional neural networks:a comparison to sift[J].arXiv preprint arXiv,2014:? (1405):5769.
[5]Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C].Advances in neural information processing systems,2012:1097-1105.
[6]Zagoruyko S,Komodakis N.Learning to compare image patches via convolutional neuralnetworks[C].Proceedings of the IEEE conference on computer vision and pattern recognition,2015:4353-4361.
[7]Han X,Leung T,Jia Y,et al.Matchnet:Unifying feature and metric learning for patch-based matching[C].Proceedings of the IEEE Conference on Co-mputer Vision and Pattern Recognition,2015:3279-3286.
[8]Mishchuk A,Mishkin D,Radenovic F,et al.Wo-rking hard to know your neighbor's margins:Local descriptor learning loss[C].Advances in Neural Information Processing Systems,2017:4826-4837.
[9]Kingma D P,Ba J.Adam:A method for stochasticoptimization[J].arXiv preprint arXiv,2014(1412):6980.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
