任務(wù)驅(qū)動(dòng)法在醫(yī)學(xué)數(shù)據(jù)挖掘中的應(yīng)用
——以帕金森綜合征的預(yù)測(cè)為例
2021-01-11 09:29:16肖偉昌聶小英
科教導(dǎo)刊·電子版 2020年33期
關(guān)鍵詞:數(shù)據(jù)挖掘模型
余 維 肖偉昌 聶小英 彭 微
(湖北科技學(xué)院 湖北·咸寧 437100)
0 引言
目前,很多高校結(jié)合自己的優(yōu)勢(shì)進(jìn)行轉(zhuǎn)型發(fā)展,其中不乏向應(yīng)用型進(jìn)行轉(zhuǎn)型,更加注重培養(yǎng)應(yīng)用型人才。針對(duì)理工多學(xué)科交叉專(zhuān)業(yè),比如醫(yī)學(xué)信息工程專(zhuān)業(yè)的專(zhuān)業(yè)課教學(xué),傳統(tǒng)的理論教學(xué)面臨重大的挑戰(zhàn)。傳統(tǒng)的理論教學(xué)往往是學(xué)生被動(dòng)填鴨式的接受知識(shí),雖然能讓學(xué)生學(xué)到很多理論知識(shí),但是在解決實(shí)際問(wèn)題時(shí)十分茫然,不能做到舉一反三。因此有必要以任務(wù)驅(qū)動(dòng)為導(dǎo)向,在結(jié)合案例教學(xué)的基礎(chǔ)上增加學(xué)生的主動(dòng)性,將教師與學(xué)生的角色互換,充分發(fā)揮學(xué)生的主觀能動(dòng)性,讓學(xué)生享受學(xué)習(xí)的過(guò)程,在提高學(xué)習(xí)成效的同時(shí)提高理論與實(shí)踐應(yīng)用的能力。
目前,人口老年化一直呈現(xiàn)出上升趨勢(shì),而帕金森綜合征是一種常見(jiàn)的神經(jīng)系統(tǒng)退行性疾病,常見(jiàn)于老年人。發(fā)病平均年齡約為60歲,帕金森病在40歲以下的年輕人中很少見(jiàn)。大多數(shù)帕金森病患者是散發(fā)性的,只有不到10%的人有家族病史。
本文從加州大學(xué)歐文分校(UCI)的機(jī)器學(xué)習(xí)庫(kù)①中的帕金森綜合征數(shù)據(jù)集入手,對(duì)其數(shù)據(jù)進(jìn)行分析并構(gòu)建一個(gè)帕金森綜合征預(yù)測(cè)模型,以供決策者提高診斷效率及準(zhǔn)確率。根據(jù)所要解決的問(wèn)題,按照數(shù)據(jù)挖掘的流程,本文所得到預(yù)測(cè)帕金森綜合征的分類(lèi)模型是通過(guò)數(shù)據(jù)獲取、數(shù)據(jù)預(yù)處理、挖掘建模、模型評(píng)估等幾個(gè)階段完成的。通過(guò)對(duì)理論與實(shí)踐操作,學(xué)生能對(duì)數(shù)據(jù)挖掘過(guò)程中的每個(gè)階段有更深刻的認(rèn)識(shí)。
1 數(shù)據(jù)挖掘過(guò)程
1.1 數(shù)據(jù)獲取
本文選取的公開(kāi)數(shù)據(jù)集來(lái)自伊斯坦布爾大學(xué)醫(yī)學(xué)院神經(jīng)內(nèi)科188例帕金森綜合征患者(男性107例,女性81例),年齡從33歲到87歲不等(65.1±10.9)歲。對(duì)照組為64例健康人(男23例,女41例),年齡41-82歲(61.1±8.9)歲。在數(shù)據(jù)收集過(guò)程中,麥克風(fēng)設(shè)置為44.1kHz,并根據(jù)醫(yī)生的檢查,從每個(gè)受試者中收集元音/a/的持續(xù)發(fā)音,并進(jìn)行三次重復(fù)(見(jiàn)表1)。

表1:帕金森病分類(lèi)數(shù)據(jù)集
1.2 數(shù)據(jù)預(yù)處理
對(duì)于龐大的數(shù)據(jù)量,原始數(shù)據(jù)集中的數(shù)據(jù)或多或少是存在質(zhì)量下降的現(xiàn)象,直接利用該數(shù)據(jù)進(jìn)行數(shù)據(jù)挖掘,不僅會(huì)增加挖掘工作的難度,還會(huì)影響挖掘效果的準(zhǔn)確性。為了減輕影響數(shù)據(jù)挖掘的多種因素,提高用來(lái)挖掘的數(shù)據(jù)質(zhì)量,通常獲取數(shù)據(jù)后需對(duì)數(shù)據(jù)集進(jìn)行預(yù)處理,以使混亂無(wú)序的數(shù)據(jù)變?yōu)槿菀追治鎏幚淼臄?shù)據(jù)。對(duì)獲取的數(shù)據(jù)進(jìn)行預(yù)處理步驟通常包括數(shù)據(jù)清洗、數(shù)據(jù)集成、數(shù)據(jù)變換、數(shù)據(jù)精簡(jiǎn)等。
1.3 算法建模
要解決的問(wèn)題是通過(guò)對(duì)帕金森綜合征數(shù)據(jù)集進(jìn)行數(shù)據(jù)挖掘,分類(lèi)得到能有效判斷罹患帕金森綜合征的預(yù)測(cè)模型。基于python的第三方工具庫(kù)中,sklearn作為機(jī)器學(xué)習(xí)領(lǐng)域知名的模塊之一,包含了很多重要的數(shù)據(jù)挖掘算法。鑒于此,考慮選用兩種常用分類(lèi)算法(如KNN算法和決策樹(shù)算法)對(duì)帕金森綜合征數(shù)據(jù)集進(jìn)行分析預(yù)測(cè),并在python語(yǔ)言編程環(huán)境下結(jié)合sklearn庫(kù)進(jìn)行建模②。
1.3.1 決策樹(shù)算法建模
將采集到的188例帕金森綜合征患者數(shù)據(jù)分成兩部分:一部分作為訓(xùn)練集,用來(lái)構(gòu)建模型;另一部分作為測(cè)試集,用來(lái)評(píng)估模型的準(zhǔn)確性。利用sklearn庫(kù)中的train_test_split生成訓(xùn)練集和測(cè)試集,利用sklearn庫(kù)中的Decision Tree Classifier生成決策樹(shù),得到?jīng)Q策樹(shù)模型的核心代碼如下:

1.3.2 KNN算法建模
與上述決策樹(shù)算法建模操作相似,將188例帕金森綜合征患者數(shù)據(jù)集分成訓(xùn)練集和測(cè)試集,利用sklearn庫(kù)中的train_test_split生成訓(xùn)練集和測(cè)試集,利用sklearn的KNeighbors-Classifier方法對(duì)KNN算法進(jìn)行建模,得到KNN算法模型的核心代碼如下:

1.4 模型評(píng)估
利用1.3節(jié)對(duì)188例帕金森綜合征患者數(shù)據(jù)集分離出的訓(xùn)練集生成出對(duì)應(yīng)的決策樹(shù)算法模型和KNN算法模型后,用相應(yīng)的測(cè)試集對(duì)生成的兩種模型進(jìn)行精確度評(píng)估。通過(guò)驗(yàn)證,得到兩種不同模型的預(yù)測(cè)精度。
1.4.1 決策樹(shù)算法模型評(píng)估
利用predict對(duì)測(cè)試數(shù)據(jù)集x_test進(jìn)行預(yù)測(cè),y_predict為預(yù)測(cè)結(jié)果,借助y_test,利用sklearn庫(kù)中的metrics.confusion_matrix生成混淆矩陣結(jié)果并對(duì)y_predict進(jìn)行分析,核心代碼如下:

結(jié)果見(jiàn)表2決策樹(shù)算法模型混淆矩陣表。通過(guò)表2所示的混淆矩陣,計(jì)算出模型的準(zhǔn)確率和錯(cuò)誤率見(jiàn)表4。

表2:決策樹(shù)算法模型混淆矩陣表
1.4.2 KNN算法模型評(píng)估
與1.4.1節(jié)類(lèi)似,通過(guò)測(cè)試集對(duì)模型進(jìn)行預(yù)測(cè),并對(duì)預(yù)測(cè)結(jié)果進(jìn)行分析,核心代碼如下:
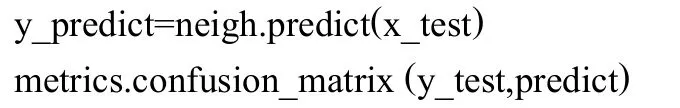
結(jié)果見(jiàn)表3 KNN算法模型混淆矩陣表。通過(guò)表3所示的混淆矩陣,計(jì)算出模型的準(zhǔn)確率和錯(cuò)誤率見(jiàn)表4。
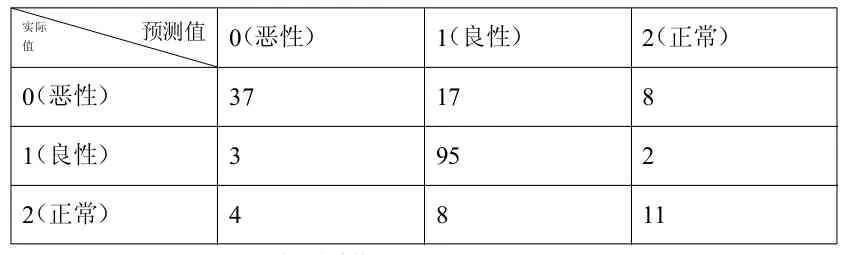
表3:KNN算法模型混淆矩陣表
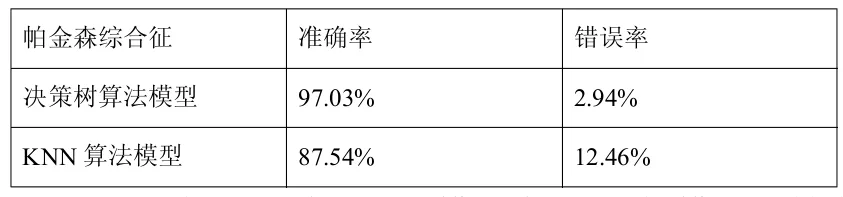
表4:算法模型準(zhǔn)確率和錯(cuò)誤率
由表4能看出,兩種不同的模型中,決策樹(shù)模型對(duì)帕金森綜合征的預(yù)測(cè)更加準(zhǔn)確。
2 小結(jié)
通過(guò)對(duì)公開(kāi)的帕金森綜合征數(shù)據(jù)集入手,對(duì)目標(biāo)任務(wù)進(jìn)行分析,構(gòu)建一個(gè)帕金森綜合征預(yù)測(cè)模型。針對(duì)該分類(lèi)問(wèn)題,本文利用python編程環(huán)境和相關(guān)工具庫(kù)完成了帕金森綜合征數(shù)據(jù)挖掘,包括數(shù)據(jù)獲取、數(shù)據(jù)預(yù)處理、算法建模與模型評(píng)估等四個(gè)階段。利用機(jī)器學(xué)習(xí)領(lǐng)域著名的 sklearn庫(kù)實(shí)現(xiàn)了決策樹(shù)算法模型和KNN算法模型,并對(duì)188例帕金森綜合征數(shù)據(jù)集分離出的測(cè)試集進(jìn)行模型評(píng)估。通過(guò)對(duì)比決策樹(shù)模型和KNN模型的精確度,能夠得出決策樹(shù)算法在帕金森綜合征數(shù)據(jù)挖掘上的應(yīng)用優(yōu)于KNN算法的結(jié)果。與單純理論教學(xué)相比,課堂學(xué)習(xí)中,將實(shí)踐與理論結(jié)合,使學(xué)生在學(xué)習(xí)理論的同時(shí)加強(qiáng)編程的練習(xí),能有效提高學(xué)生理解并掌握所學(xué)的數(shù)據(jù)挖掘方法在臨床工作中的應(yīng)用。
注釋
① http://archive.ics.uci.edu/ml/index.php
② https://scikit-learn.org/stable/
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國(guó)中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
