
基于邊緣檢測和Blob分析的車牌識別技術研究
2021-01-13 12:17:14李百明
裝備制造技術 2020年10期
李百明
(閩南理工學院,工業機器人測控與模具快速制造福建省高校重點實驗室,福建石獅362700)
隨著科技的進步和人們生活水平的提高,對汽車的需求量逐年上漲,導致城市交通問題日益嚴峻。智能交通系統(Intelligent Traffic System,簡稱ITS)的出現帶來了高效可行的解決方案[1]。ITS將計算機、圖像處理、通信、自動控制及模式識別等技術綜合運用于現代交通管理體系中,實現交通管理的自動化與車輛行駛的智能化,解決了交通管理中存在的一系列問題[2-3]。車牌識別技術是ITS不可或缺的核心技術,30年間受到大量學者和企業的廣泛研究,誕生的識別方法層出不窮。目前,國外的車牌識別系統已經非常成熟,比如英國PIPS公司的號牌識別系統堪稱世界最先進的識別系統[4];美國SCT公司研發的車牌識別系統,在車速高達350 km/h的情況下仍可以捕捉到車牌牌照[5-6];以色列Hi-Tech公司的See Car系統,幾乎可以識別所有國家的車牌。但國外的車牌識別系統無法識別中國的車牌,因為中國的車牌除了數字和字母外還有漢字字符。國內對車牌識別系統的研究始于20世紀90年代,業界口碑較好的車牌識別系統有廈門宸天車牌識別公司的SupPlate、深圳科安信實業有限公司的KC系列等產品,并已在高速公路收費站和大型停車場等場所得到了成功的應用。然而,現有的車牌識別系統在交通監控、卡口治安系統上對違章或違法犯罪車輛快速進行車牌鎖定的時效性和準確性上仍有很大的差距[7]。因此,建立一個成熟完善的車牌識別系統迫在眉睫。
車牌識別技術的核心是車牌的定位和字符識別,其中車牌能否精準定位直接決定了系統識別成功率的高低。目前,常用的車牌定位方法有基于顏色識別定位法、基于邊緣檢測定位法和基于Blob分析定位法。顏色識別法依據車牌的背景色進行目標區域定位,利用顏色模型通過車牌的顏色來尋找車牌所在位置[8、9]。顏色識別法的優點是對車牌的大小、位置及圖像背景的限制較少;缺點是當車身顏色與車牌顏色相近時,差錯率較高。邊緣檢測法根據車輛、車牌及字符之間存在著明顯的灰度變化這一特點,只保留高頻的車牌區域、車輛邊緣和字符,去除圖像中大量無關信息,僅保留最基本的輪廓結構,再利用車牌的形狀特征實現目標區域定位。邊緣檢測的優點是能成功定位大多數車牌;缺點是當車牌圖像中有大量矩形邊緣時,難以準確的定位車牌所在區域。Blob分析法根據車牌區域與周圍背景灰度值存在較大差異這一特點,運用二值化、形態學和特征篩選等手段實現車牌區域的定位。Blob分析的優點是靈活性好[10]、能保留車牌的完整圖像信息;缺點是受背景光的影響較大、適應性差。
針對上述問題,本文提出了一種改進型定位方法——基于邊緣檢測和Blob分析定位法,并設計了一套完整的車牌自動識別系統。該系統具有適應性強、定位快速和識別準確率高等特點。本文的創新點如下:(1)在HSV顏色空間采用邊緣檢測算法對車牌在圖像中的區域進行粗定位。(2)利用Blob分析法對粗定位的區域做進一步篩選,實現車牌的準確定位。
1 車牌識別系統設計
本文設計的車牌識別系統由車牌采集、通道轉換、車牌定位、字符分割、字符識別和車牌顯示六個模塊組成,系統的原理如圖1所示。
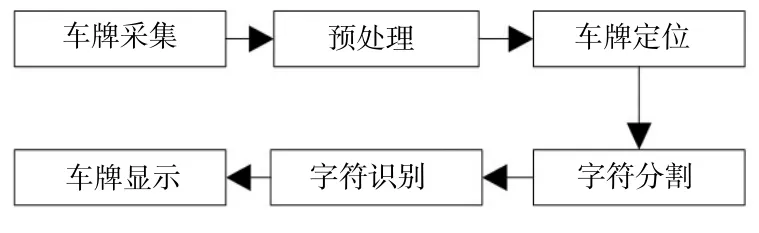
圖1 車牌識別系統原理圖
車牌采集模塊負責加載事先拍攝好的車牌圖像,或從攝像機中實時獲取車牌圖像;通道轉換模塊負責顏色空間的轉換;車牌定位模塊負責提取出車牌所在區域,定位時先用邊緣檢測法進行粗定位,再由Blob分析進行精定位;字符分割模塊負責將車牌中的字符分割開來;字符識別模塊完成車牌的識別功能;車牌顯示模塊負責顯示提取出的車牌信息。
1.1 通道轉換
圖像的顏色有多種表示方式,最常用的是RGB顏色模型。車牌采集模塊采集到的圖像便是RGB三通道圖像。R、G、B分別表示紅、綠、藍三種基本的顏色。彩色圖像在處理前,一般需要進行降維處理,常用的降維方法有圖像灰度化處理和圖像通道拆分。在實際的車牌識別系統中,無論是將車牌圖像直接轉成灰度圖像還是拆分成R、G、B三個單通道的灰度圖像,車牌的特征都不太明顯,不利于車牌的準確定位。
除了RGB顏色模型外,圖像的顏色還可以用HSV顏色模型來描述。其中,H為色調,表示顏色的純度;S為飽和度,表示顏色由濃漸漸變淡的特征;V為亮度,表示光場的強度。HSV顏色空間能較好的反映人對色彩的感知和鑒別能力。將RGB顏色模型轉成 HSV顏色模型可用公式(1)~(3)來表示[11]。
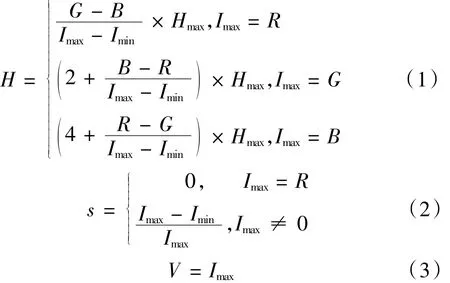
圖2為對原彩色圖像拆分后得到的R、G、B三個單通道灰度圖像。圖3為由R、G、B轉換的H、S、V圖像。從圖2和圖3可知,在RGB空間車牌區域特征并不明顯,將其轉換為HSV通道后,S通道的車牌區域特征特別明顯,為下一步的車牌定位做好了準備。

圖3 車牌圖像HSV通道
1.2 車牌定位
1.2.1 邊緣檢測粗定位
常用的邊緣檢測算法有Robert算法、Sobel算法、Prewitt算法和Canny算法。其中,由于Canny算法具有對信號干擾適應性強、邊緣檢測準確完整、連續性好等優點[12],所以本文采用Canny算法對車牌區域進行粗定位。
Canny算法邊緣檢測的步驟[6]如下:
(1)濾波
用高斯濾波器和車牌圖像進行卷積,達到平滑降噪的目的,具體實現如公式(4)所示。
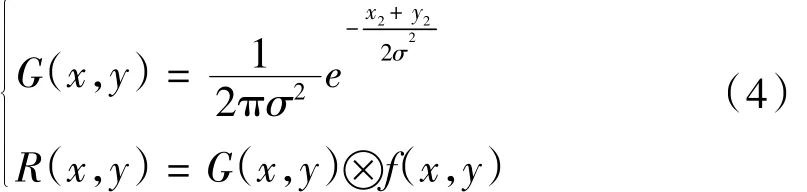
式中:G(x,y)表示二維高斯卷積核;σ表示高斯分布參數;f(x,y)表示處理前的圖像;R(x,y)表示處理后的圖像。
(2)計算梯度的幅值和方向
用一階偏導的有限差分計算圖像沿X與Y方向的偏導數Gx、Gy,則梯度的幅值和方向如公式(5)所示。
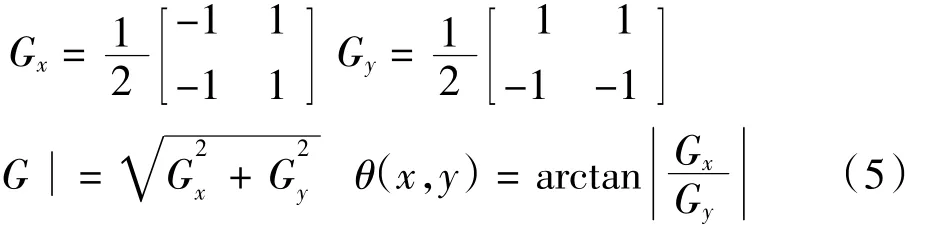
(3)對梯度幅度值進行非極大值抑制
非極大值抑制就是尋找像素點的局部最大值。非極大值抑制的原理是先沿幅角方向檢測模值,其最大值處即為邊緣點,再沿8個方向進行遍歷,并比較像素點偏導值與鄰像素的模值,得到的最大值點為邊緣點,然后將其灰度值清0。重復上述操作,即可得到初步的邊緣位置。
(4)用雙閾值算法檢測,并對邊緣進行鏈接
用兩個閾值 A,B(令 A<B)作用于步驟(3)獲取的圖像,閾值A檢測出的圖像邊緣相對完整,但噪聲多;閾值B檢測出的圖像濾掉了大部分噪點,但邊緣信息不完整;最后用A檢測的圖像對B檢測出的圖像進行補充,便可得到鏈接邊緣。
圖4是用Canny邊緣檢測算法提取的車牌區域。從圖4可知,利用Canny算子準確的找到了車牌區域的邊界,且邊界信息完整,但也產生了很多假邊緣,需要進一步處理。

圖4 邊緣檢測結果
1.2.2 Blob分析精定位
Blob又稱團塊,是指像素相連通的區域。Blob分析就是對連通閾的形狀、數量、方向等特征進行統計和處理,進而達到檢測目的。
(1)二值化
二值化的目的是將邊緣檢測后的圖像對象轉換為區域對象,同時縮減車牌區域以外的區域,減少干擾,保留關鍵信息。車牌圖像二值化的難點是閾值的選取。常用的閾值確定方法有固定閾值法和自適應閾值法。本文采用自適應閾值法中的大津法(OTSU)來實現車牌圖像的二值化[13],OTSU的原理如下。
設當前的閾值為T,背景點占整幅圖像的比例為ω背,背景點的灰度均值為,前景點占圖像的比例為ω前,前景點的灰度均值為,則整幅圖像的灰度均值u為:
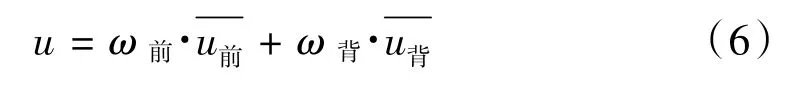
設前景與背景的類間方差為g(T),則
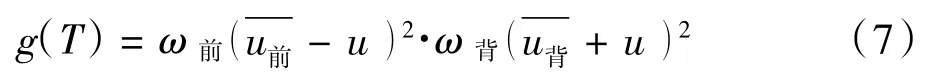
將(6)式帶入(7)式,得類間方差的等價公式為:
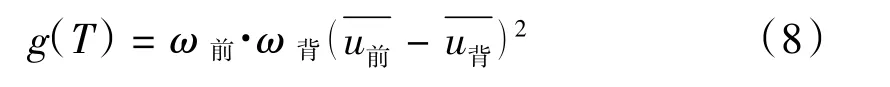
最后只需遍歷每個灰度值,找到這個灰度值所對應的類間方差,當某個灰度值使g(T)最大時,該灰度值即為最佳分割閾值。對粗定位后的圖像進行OTSU閾值分割后的結果如圖5所示。

圖5 OTSU二值化圖
(2)形態學處理
經二值化處理后,車牌字符之間可能變成多個分離的區域,在車牌的定位中,需要將這些部分變成一個整體。因此,先對二值化后的區域進行膨脹處理,使分開的相鄰字符區域連成一個整體,并對區域中的細小孔洞進行填充。但經膨脹處理后,車牌所在區域變大了,為了獲得車牌的實際大小,還需在進行一次腐蝕處理。圖6為先膨脹后腐蝕后的結果。

圖6 先膨脹后腐蝕結果
(3)特征篩選
我國的車牌都是矩形的,且長寬比為3∶1,可根據這一特征對圖像的候選區域進行篩選。對于實際拍攝的圖片,車牌可能發生傾斜和變形,故將車牌的長寬比設為2~6。另外在圖像中車牌區域還有一定的面積,且外形似矩形,因此本文同時選擇了面積、長寬比和矩形度三個方面的特征對候選區域做最終的篩選。圖7為經過篩選后得到的車牌位置,圖8為轉正后的車牌。

圖7 定位后的車牌

圖8 轉正后的車牌
1.3 字符分割
字符分割是指將車牌中的7個字符分割成相互獨立的連通域,每個連通域代表一個待識別的字符。中國的車牌是由字符、數字加漢字組成的。通過分析不難發現所有的數字和字母都是一個完整的連通域,而漢字在提取時卻有些復雜。由于漢字存在上下結構、左右結構,很容易誤將一個漢字拆成多個字符,進而影響識別結果的準確性。為解決這個問題,本文先將轉正后的車牌圖像轉成灰度圖像,然后將灰度圖像變成白底黑字模式,為后續字符識別做好準備;接下來對灰度圖像進行二值化,并聯合特征篩選實現車牌字符的篩選。經二值化處理后,漢字可能被拆成兩個獨立的連通域,因此需要對特征篩選后的區域進行膨脹處理,使分開的區域連在一起。膨脹后車牌的字符會發生變形,影響識別結果,故還需做每個字符的最小外接矩形,最后用這些外接矩形和原圖像求交集,便可得到7個完整獨立的區域。圖9為字符分割的詳細流程,圖10為分割后的效果。
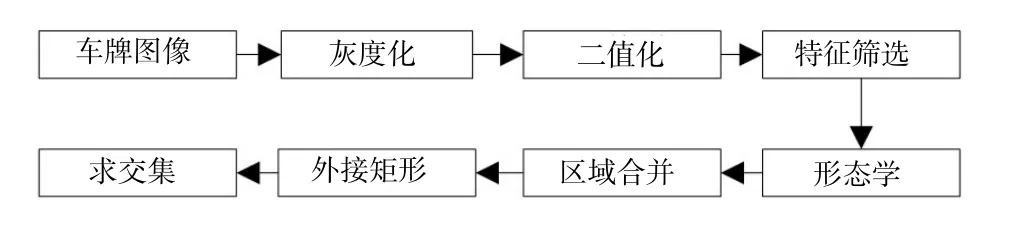
圖9 字符分割流程圖

圖10 字符分割結果
1.4 字符識別
目前,車牌字符識別的常見方法有基于規則推理、基于模板匹配和基于人工智能等方式[14]。本文采用基于MLP(Multilayer Perceptron,多層感知)分類器進行字符識別。MLP也叫人工神經網絡(Artificial Neural Network,ANN),是一種模仿生物神經元傳輸的機制,主要由輸入層、輸出層和多個中間隱藏層構成。最簡單的MLP只有一個中間隱藏層[15]。MLP的三層結構如圖11所示。圖12為MLP分類器字符識別的基本流程。
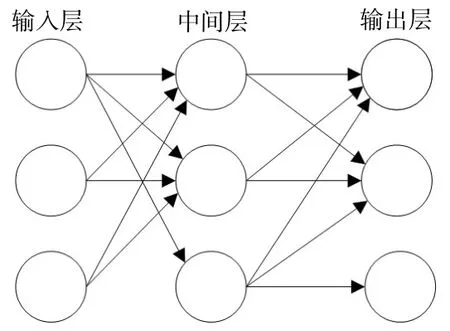
圖11 多層感知器
圖12 MLP分類器車牌字符識別流程圖
2 檢測實驗及結果分析
車牌識別系統的算法部分采用德國Mvtec公司開發的Halcon機器視覺軟件平臺進行設計,該平臺具有強大的幾何與圖像計算能力,被廣泛應用于工業自動檢測領域。但Halcon軟件無法直接生成應用程序,故系統的GUI界面部分在VS2015平臺上采用C#編程語言設計。
本文從網絡上搜集了20幅白天拍攝的車輛照片對該系統進行測試。經過統計20張車牌中有19張車牌可以實現精準定位,1張車牌定位區域偏大,但并未對車牌的正確識別產生影響;有18張車牌被準確識別,2張識別失敗。本系統對白天車牌的精準定位準確率為95%、字符識別準確率為90%,平均識別每幅車牌的時間為0.485 s。部分識別結果如圖13所示。其中圖13(a)為正面拍攝時的識別結果,圖13(b)為側拍拍攝時的識別結果。

圖13 部分車牌識別結果
經過分析,兩幅車牌識別失敗的主要原因是:(1)拍攝的車牌圖片分辨率低,字符模糊且車牌字符有不同程度的缺損;(2)訓練的樣本數量太少,不能正確識別不完整的字符。
3 結束語
(1)針對傳統車牌定位方法的不足,本文提出了一種在HSV顏色空間下基于邊緣檢測和Blob分析的定位方法。實驗結果表明,白天時該方法定位可靠、準確率接近100%。
(2)在確定了車牌定位方法的基礎上設計了一套完整的車牌識別系統,實驗表明該系統的識別準確率為90%,平均識別時間約為0.5 s,具備良好的使用性能。
(3)設計了系統的GUI界面,增強了系統的實用性能。該系統可以廣泛應用于商場、超市、小區及城市道路交通監控等場合。
(4)本系統目前僅對白天的車輛進行了實驗測試,未來的研究工作主要有:1)對夜間的車輛進行識別調試,增加系統的通用性;2)大幅增加訓練樣本,提高識別準確率;3)加入遠程數據庫,識別套牌車輛,違章和違法車輛并及時報警。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
