基于色彩的車牌識別研究
2021-01-18 03:38:10唐愉順張生果牛潞崔澤宇
現(xiàn)代計(jì)算機(jī) 2020年32期
唐愉順,張生果,2,牛潞,崔澤宇
(1.甘肅省民族語言智能處理重點(diǎn)實(shí)驗(yàn)室,西北民族大學(xué),蘭州 730030;2.西北民族大學(xué)電氣工程系,蘭州730030)
0 引言
伴隨著我國車輛數(shù)目的快速增長,截至2020上半年,我國汽車保有量已超過3億,通過人工對汽車進(jìn)行管理顯然工作量太大,效率太低。如何對汽車進(jìn)行高效的管理是一個很大的問題,現(xiàn)如今圖像處理和識別等技術(shù)已經(jīng)日益成熟,利用圖像處理有效提取車牌關(guān)鍵信息進(jìn)而自動識別的技術(shù)提升了車輛管理的效率,在汽車的停車管理、交通違章、布控巡查等方面都有著廣泛的應(yīng)用[1]。對車牌自動化且實(shí)時識別的關(guān)鍵環(huán)節(jié)便是車牌定位、字符切割、字符識別以及后續(xù)處理。常見的車牌識別技術(shù)主要是依據(jù)灰度圖像處理的圖像識別技術(shù),判別車牌圖像的有效信息區(qū)域,進(jìn)而對字符進(jìn)行識別。但在實(shí)際車牌識別過程中,此類方法往往因?yàn)樯倭寇嚺七吘壧卣鳠o法被捕捉而產(chǎn)生的識別率不高和識別速度不快等缺點(diǎn)造成車牌有效信息提取不完整或提取失敗等問題。本文提出的基于色彩的車牌識別方法針對目前國內(nèi)常見的家用小轎車車牌的藍(lán)色背景、7個白色字符、矩形邊框等特點(diǎn)在MATLAB平臺設(shè)計(jì)出智能車牌識別系統(tǒng)。能夠?qū)嚺菩畔⑦M(jìn)行有效、精準(zhǔn)且實(shí)時的識別,系統(tǒng)工作的流程圖如圖1所示。
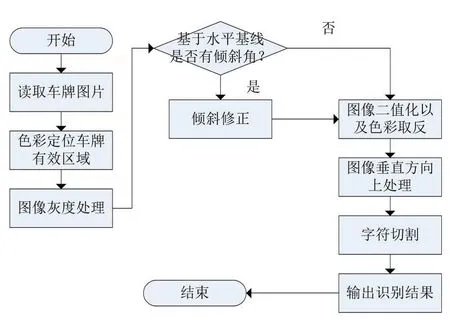
圖1 系統(tǒng)工作流程圖
該系統(tǒng)主要依賴于對彩色圖像的RGB比例定位來判定車牌的有效位置,緊接著在圖像處理階段利用了Radon算法進(jìn)行傾斜角度計(jì)算,并對傾斜圖片進(jìn)行修正。利用Radon算法對圖片進(jìn)行傾斜角的判定以及傾斜修正的優(yōu)點(diǎn)是:①時間和空間復(fù)雜度都不算高在車牌的實(shí)時識別過程中有著良好的響應(yīng)表現(xiàn)。②能夠在車牌有效信息區(qū)域存在缺失和受污染的情況下穩(wěn)定有效地對圖片傾斜角進(jìn)行判定并校正。通過修正后的圖片有利于后期的圖片分割及圖像識別。
1 研究方法
1.1 車牌的定位
本環(huán)節(jié)是車牌識別的關(guān)鍵步驟,本文提出的是一種基于對色彩特征的提取分析定位算法,其成功率直接關(guān)系到整張車牌圖片識別的成功率。因?yàn)檐嚺谱R別的第一步就是找到、定位并且提取車牌的有效區(qū)域信息,即藍(lán)底白字的矩形車牌邊框區(qū)域。基于色彩對圖像進(jìn)行分析,找到圖片中符合目標(biāo)藍(lán)底白字的矩形邊框區(qū)域,不需要對整張圖像的邊緣進(jìn)行檢測。其原理是:當(dāng)識別目標(biāo)帶有明顯的某一類顏色時,在圖片中表現(xiàn)為某一類顏色的像素,可以通過R、G、B三顏色通道定位出一個大概的范圍,無需進(jìn)行大量復(fù)雜的邊緣特征計(jì)算,省時省力。具體操作步驟為:首先在分割開的區(qū)域中統(tǒng)計(jì)每一行的藍(lán)色像素點(diǎn),通過找到最多藍(lán)色像素點(diǎn)積累所在行確定為車牌矩形邊框的邊界上限,即Y方向上的最大值。接著同樣的方法確定每一列中最多藍(lán)色像素點(diǎn)積累所在列為車牌邊框的邊界上限,即X方向最大值,即可確定車牌邊框位置,隨后統(tǒng)計(jì)白色像素點(diǎn)即字符所在行列數(shù)的位置數(shù)目由邊框向中間依次掃描,多次統(tǒng)計(jì)綜合判斷并成功定位車牌所在位置。如圖2所示。

圖2 車牌定位展示圖
1.2 車牌圖像灰度處理
對成功定位好的車牌圖像進(jìn)行灰度處理是提取車牌有效信息的重要步驟。對于已經(jīng)成功定位提取的車牌圖像只包含有字符和背景信息,然而此時的背景信息對后續(xù)的處理是無用的[2],因此通過灰度處理后彩色圖片失去色彩值同時保留下了關(guān)鍵的字符信息,方便后續(xù)進(jìn)行信息的提取。灰度處理后圖像如圖3所示。

圖3 圖像灰度處理
1.3 傾斜判定以及修正
在車牌的識別過程中,字符的分割是關(guān)鍵環(huán)節(jié),由于圖片的拍攝角度和基于色彩的有效區(qū)域提取操作后車牌圖像或多或少都會存在一定范圍的傾斜,如果不加以校正處理將直接影響到后續(xù)的字符分割和識別過程。所以將車牌圖像修正為水平顯得尤為重要。本文主要以Radon變換(拉東變換),來對車牌圖像進(jìn)行傾斜角度計(jì)算以及傾斜修正。Radon變換可以在數(shù)字圖像矩陣在某一指定角度射線方向上做投影變換。這就是說可以沿著任意角度theta來做Radon變換[3]。本文選擇在X方向(圖像最下邊界)和Y方向(圖像最左邊界)兩個方向投影,統(tǒng)計(jì)黑點(diǎn)數(shù),以獲取在X和Y方向上突出的特性。最終利用算法計(jì)算出傾斜角度,并對圖像進(jìn)行修正處理,如圖4所示。

圖4 傾斜修正
1.4 圖像的2值化以及擦除干擾信息
為了進(jìn)一步方便對后續(xù)的字符識別,為了方便字符分割,需要對圖像進(jìn)行二值化處理。通過二值化處理后圖像變得簡單,數(shù)據(jù)量減少,并且能夠突出字符主要特征。但是將圖像二值化后無論用什么方法都會無可避免的產(chǎn)生一些干擾噪點(diǎn),如圖5所示為二值化后的車牌圖像。

圖5 二值化后車牌圖像
為了提升后續(xù)7個字符分割的成功率,需要對二值化后的圖像做進(jìn)一步處理,盡可能保留有效信息而擦除干擾值。本文對二值化的圖像像素值取反使得有效信息和干擾信息最大限度分離如圖6所示為圖像取反結(jié)果,緊接著為了去除車牌邊框定位了字符的高度,截取掉了高于和低于字符在Y方向上的部分圖片。

圖6 顏色取反后車牌圖像
這個時候圖像中仍然保留有大量的無關(guān)干擾特征例如:固定車牌的鉚釘(在圖像中顯示為圓形斑禿),矩形車牌邊界外的區(qū)域(在圖像中顯示為大量黑色區(qū)域)。想要成功進(jìn)行后續(xù)字符分割和字符識別操作必須對這些干擾因素加以剔除。本文所采用的方法是:將圖像在X方向上進(jìn)行投影,得到圖像在垂直方向上的像素分布信息,統(tǒng)計(jì)出黑白像素值,當(dāng)像素值出現(xiàn)大量跳變時在其范圍內(nèi)界定一個上下界,截去上下界之外的圖像,如圖7所示為在垂直方向上截取后的圖像。

圖7 垂直方向上處理結(jié)果
1.5 字符分割
本文所采用的字符分割主要還是傳統(tǒng)意義上的字符分割算法,針對上述處理好的圖像結(jié)果,將圖像進(jìn)行水平、豎直兩個方向的投影進(jìn)而分割每一個字符。此方法對分割閾值的依賴性比較大,閾值的選取恰當(dāng)關(guān)系到字符分割的成功率。由于在車牌圖像中每一個字符的尺寸都大體相同,所以只要選擇恰當(dāng)?shù)拈撝稻涂梢猿晒M(jìn)行字符分割。具體操作是將圖像先進(jìn)行X方向上的投影得到圖像在垂直方向上的像素點(diǎn)分布信息,有像素點(diǎn)的區(qū)域即是字符區(qū)域,將有像素點(diǎn)的區(qū)域切割開來,同理將圖像在Y方向上進(jìn)行投影,得到水平方向上的像素點(diǎn)信息,同樣有像素點(diǎn)的區(qū)域?yàn)樽址麉^(qū)域,將其切割。如圖8所示為操作結(jié)果。
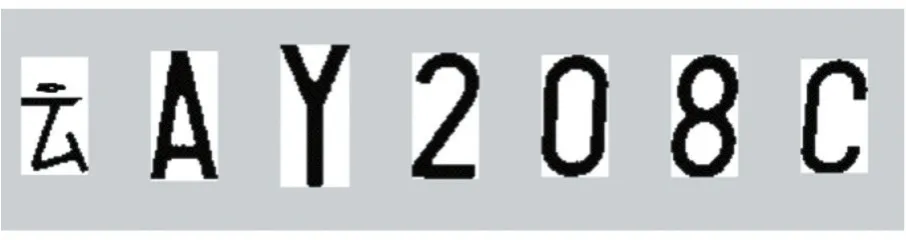
圖8 字符分割結(jié)果
1.6 模式匹配識別
本文采用模式匹配算法來對切割好的字符進(jìn)行識別,模式的核心思想是將字符圖片從左上角開始從左向右進(jìn)行像素掃描與圖片庫里的圖片進(jìn)行相似度計(jì)算,匹配出最相近的結(jié)果。其中相似度計(jì)算的方法采用的是MAD算法,由于前期干擾信息的擦除處理和字符分割的成功,模式匹配所要識別的圖片中不含或者含有極少量噪聲,對識別結(jié)果不會產(chǎn)生什么影響。MAD算法的具體操作是將目標(biāo)圖片掃描后與圖片庫里的圖片對應(yīng)位置像素值相減,其結(jié)果累加后取平均值。數(shù)值越小代表兩張圖片越接近也就越相似,即為匹配對象。如圖9所示為輸出結(jié)果,其結(jié)果準(zhǔn)確無誤為云AY208C。
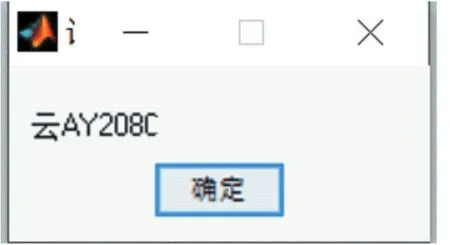
圖9 識別結(jié)果
2 實(shí)驗(yàn)結(jié)果
目前模式匹配圖片庫中錄入了10個省份的漢字簡稱、26個英文字母和10個數(shù)字。通過對10個省份總共100張車牌圖像進(jìn)行識別實(shí)驗(yàn),結(jié)果表明:對于傾斜角度較小的車牌色彩定位成功率為97%,而部分傾斜角度過大的車牌圖片識別率也高達(dá)80%。字符識別中由于部分?jǐn)?shù)字和字母在形態(tài)上過于相似對于這一類字符的識別,成功率只有70%左右。除部分?jǐn)?shù)字和字母外其余識別成功率高達(dá)95%,表1列出部分容易混淆難以識別出的字符:
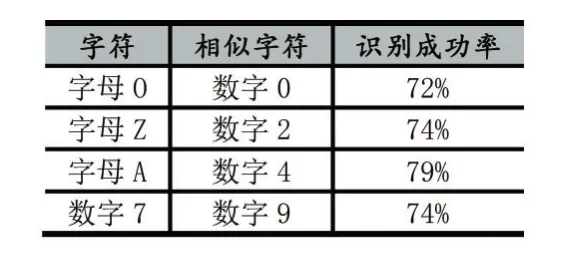
表1 容易混淆難以識別的字符
3 結(jié)語
車牌的識別過程中車牌有效區(qū)域的定位和提取是識別的第一步也是最關(guān)鍵的一步,本文所設(shè)計(jì)車牌識別系統(tǒng)針對國內(nèi)常見的家用小轎車藍(lán)底白字特征的車牌基于色彩進(jìn)行定位,在進(jìn)行字符分割和模式匹配前,將車牌圖像灰度、二值化處理,最大化限度突出了車牌特征并擦除干擾信息。這樣做可以提高字符分割和最后識別的成功率。實(shí)驗(yàn)結(jié)果表明此方法對于傾斜角度不大的藍(lán)底白字小轎車車牌識別成功率較高,識別速度快,算法時間空間復(fù)雜度都比較低。但是本文提出的車牌識別方法是基于色彩的識別方法,此方法雖然對于藍(lán)底白字的小轎車車牌識別有極高的準(zhǔn)確率可是也有致命的缺點(diǎn):無法識別汽車為藍(lán)色背景的小轎車車牌,并且對于識別的車牌圖片像素要求不能太低,不然會無法提取特征信息導(dǎo)致識別失敗。同時在模式識別過程中依然存在著部分字符由于形態(tài)上過于相似導(dǎo)致識別結(jié)果混淆經(jīng)常難以區(qū)分的問題。針對色彩定位問題可以增強(qiáng)對圖片色彩的敏感度以達(dá)到區(qū)分不同藍(lán)色背景和車牌有效區(qū)域的目的,字符識別想要提高識別成功率有效區(qū)分容易混淆的字符可以采用神經(jīng)網(wǎng)絡(luò)的算法提前將各個省份的漢字簡稱、26個英文字母和10個數(shù)字訓(xùn)練好提高識別效率。
猜你喜歡
計(jì)算機(jī)應(yīng)用(2022年2期)2022-03-01 12:33:42
計(jì)算機(jī)應(yīng)用(2021年4期)2021-04-20 14:06:36
計(jì)算機(jī)應(yīng)用(2021年1期)2021-01-21 03:22:38
中華手工(2017年2期)2017-06-06 23:00:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
小天使·一年級語數(shù)英綜合(2015年2期)2015-01-14 06:35:05
中外會展(2014年4期)2014-11-27 07:46:46
民生周刊(2012年10期)2012-10-14 09:06:46
