基于耦合模擬退火S3VM的信用預(yù)測
2021-01-20 08:31:22王國偉
計算機工程與設(shè)計 2021年1期
李 琳,王國偉,張 杰,周 棟
(1.武漢理工大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,湖北 武漢 430070;2.湖南科技大學(xué) 計算機科學(xué)與工程學(xué)院,湖南 湘潭 411201)
0 引 言
在線P2P(Peer-to-Peer)貸款[1],又稱為點對點貸款,為民間小額借貸,方便了小微企業(yè)的借貸。在實際生產(chǎn)生活中,許多小微企業(yè)經(jīng)常需要小額短期資金進(jìn)行周轉(zhuǎn),但銀行借貸的過程復(fù)雜,無法滿足小微企業(yè)的需求[2,3]。
借貸行業(yè)的實際情況給模型訓(xùn)練帶來了困難,導(dǎo)致信用預(yù)測結(jié)果的準(zhǔn)確度偏低。首先對于訓(xùn)練數(shù)據(jù)樣本的形成,僅當(dāng)金融機構(gòu)完成了某次借貸申請流程后,才會形成標(biāo)記數(shù)據(jù)。大多小微企業(yè)無信用記錄,僅有少量小微型企業(yè)的信用被相關(guān)的金融機構(gòu)評估。人工標(biāo)記數(shù)據(jù)的成本過高導(dǎo)致訓(xùn)練樣本嚴(yán)重不足。可以看到用借貸歷史記錄作為訓(xùn)練數(shù)據(jù)集,不但標(biāo)記數(shù)據(jù)量少,且其正負(fù)樣本比例不均衡,傳統(tǒng)的監(jiān)督機器學(xué)習(xí)方法的預(yù)測效果會因此受到影響。
半監(jiān)督學(xué)習(xí)充分利用未標(biāo)記數(shù)據(jù)中的信息,提高模型在預(yù)測時的表現(xiàn)。簡單而言,半監(jiān)督學(xué)習(xí)可將一些不含標(biāo)簽的數(shù)據(jù)通過一定的機制添加到訓(xùn)練數(shù)據(jù)中,用以緩解上述問題。
基于半監(jiān)督支持向量機的信用評估是一種有效的預(yù)測方法[4]。由于超參數(shù)通常由經(jīng)驗選取,當(dāng)對不同數(shù)據(jù)集進(jìn)行預(yù)測時,由于數(shù)據(jù)集間的差異,無法保證模型的穩(wěn)定性。因此,本文提出基于耦合模擬退火的S3VM(CSAS3VM),采用耦合局部最優(yōu)的方法來優(yōu)化模擬退火過程,尋找半監(jiān)督支持向量機的最優(yōu)參數(shù)。實驗結(jié)果表明,本文提出的CSAS3VM,具有更高的精度和較高的F-1值,且在正負(fù)樣本比例不均衡時也表現(xiàn)穩(wěn)定,是一種有效的信用預(yù)測方法。
1 相關(guān)工作
1.1 信用評估
對于信用評估,主流機器學(xué)習(xí)方法已有較好的表現(xiàn)。Malini等[5]提出了基于KNN和離群值檢測的信用卡欺詐識別模型;Save等[6]提出了一種使用決策樹(decision tree)檢測信用卡交易處理中欺詐行為的系統(tǒng)。支持向量機同樣被廣泛應(yīng)用于信用評估。Yu等[7]試圖提出一種基于深度置信網(wǎng)絡(luò)的重采樣SVM集成學(xué)習(xí)范式,并將其用于信用評估;肖斌卿等[8]使用最小二乘SVM,建立了用于小微企業(yè)的信用評估模型;Hsu等[9]的研究結(jié)果表明將SVM與人工蜂群方法相結(jié)合,能夠提高信用評估的結(jié)果。
除傳統(tǒng)的機器學(xué)習(xí)方法外,神經(jīng)網(wǎng)絡(luò)也同樣受到關(guān)注。Oresk等[10]提出了一種神經(jīng)網(wǎng)絡(luò)混合遺傳算法(HGA-NN),用于提高信用評估的分類準(zhǔn)確性和可擴展性。Fu等[11]提出了一個基于CNN的信用欺詐檢測框架,從標(biāo)記數(shù)據(jù)中學(xué)習(xí)欺詐行為的內(nèi)在模式。
監(jiān)督學(xué)習(xí)方法中SVM在信用評估上表現(xiàn)突出,本文在半監(jiān)督SVM中引入耦合模擬退火機制優(yōu)化參數(shù)選擇,提升信用預(yù)測質(zhì)量。
1.2 半監(jiān)督學(xué)習(xí)
在21世紀(jì)初,半監(jiān)督學(xué)習(xí)得到廣泛關(guān)注,主要有生成式、基于圖的半監(jiān)督、協(xié)同訓(xùn)練和半監(jiān)督支持向量機等[12-14]。本文主要關(guān)注半監(jiān)督支持向量機,其基本思想是:將未標(biāo)記的信用數(shù)據(jù)加入到模型中,試圖找到劃分超平面能對數(shù)據(jù)進(jìn)行分類且穿過的區(qū)域為數(shù)據(jù)稀疏區(qū)域。Chen等[14]對Lap-TSVM進(jìn)行改進(jìn),提出了Lap-STSVM,將原始約束轉(zhuǎn)換為無約束最小問題;Rethishkumar等[15]利用分支定界法優(yōu)化的確定性退火半監(jiān)督支持向量機(DAS3VM)對節(jié)點進(jìn)行分類;Huang等[16]將基于流形正則化的極限學(xué)習(xí)機擴展到半監(jiān)督和無監(jiān)督任務(wù)中;Dai等[17]提出了一個基于對抗生成網(wǎng)絡(luò)的半監(jiān)督學(xué)習(xí)框架,該框架使用生成的數(shù)據(jù)來提高任務(wù)性能;Wang等[18]提出了一種基于主動學(xué)習(xí)結(jié)合TSVM的新型半監(jiān)督學(xué)習(xí)算法,并在目標(biāo)函數(shù)中添加流形正則項;Yang等[19]提出了一種基于圖嵌入的半監(jiān)督學(xué)習(xí)框架,并與基于高斯調(diào)和函數(shù)的半監(jiān)督方法進(jìn)行了對比。
在信用預(yù)測和金融風(fēng)控領(lǐng)域,考慮半監(jiān)督學(xué)習(xí)方法來解決標(biāo)記數(shù)據(jù)不足問題的研究偏少,Li等[20]的研究結(jié)果表明半監(jiān)督支持向量機在信用預(yù)測上比邏輯回歸表現(xiàn)好;Lebichot等[21]提出了基于圖的半監(jiān)督信用卡欺詐檢測系統(tǒng)。
1.3 演化算法與半監(jiān)督學(xué)習(xí)
演化算法的靈感源于自然界生物的進(jìn)化,其在參數(shù)優(yōu)化、模式識別和機器學(xué)習(xí)等眾多領(lǐng)域有較為廣泛的應(yīng)用。Chen等[22]的MPSVM是一種用于半監(jiān)督分類的支持向量機,并采用粒子群算法來優(yōu)化模型參數(shù)的選擇;Albinati等[23]提出基于蟻群算法的半監(jiān)督分類算法;Lazarova等[24]使用遺傳算法與S3VM結(jié)合,提出GS3VM來優(yōu)化非凸問題,在Diabetes和Coil20數(shù)據(jù)集上表現(xiàn)出較好的結(jié)果;Lazarova等[25]提出了一種半監(jiān)督多視圖遺傳算法,應(yīng)用于回歸函數(shù)學(xué)習(xí)中。根據(jù)上述文獻(xiàn),將演化算法與半監(jiān)督相結(jié)合的方法能有效提高傳統(tǒng)半監(jiān)督方法的準(zhǔn)確性并且現(xiàn)有的研究工作對所采用的傳統(tǒng)演化算法做了進(jìn)一步優(yōu)化和改進(jìn)。總體上,實驗中除了與傳統(tǒng)的半監(jiān)督方法對比之外,還對比了所要改進(jìn)的演化方法。
本文考慮到基于確定性退火的S3VM(DAS3VM)采用人工選擇參數(shù)[15],模型容易過擬合或欠學(xué)習(xí),而基于模擬退火的S3VM信用預(yù)測方法[26]受初始溫度影響,低溫時容易陷入局部最優(yōu)。針對該問題,本文提出了耦合模擬退火的S3VM方法,通過共享多個模擬退火過程的信息,優(yōu)化模型參數(shù)的選擇。本文利用耦合模擬退火優(yōu)化半監(jiān)督的參數(shù)學(xué)習(xí),今后的研究將考慮其它演化算法在實際問題中的可行性。
2 耦合模擬退火半監(jiān)督SVM方法
本文研究演化算法與二分類的S3VM結(jié)合,尋找模型的優(yōu)化參數(shù),以此來提高分類預(yù)測效果。
2.1 確定性退火半監(jiān)督SVM(DAS3VM)
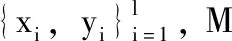
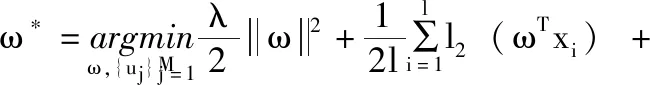
(1)
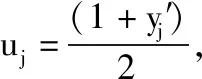
確定性退火半監(jiān)督支持向量機(DAS3VM)[15]通過構(gòu)造一個關(guān)于溫度T的自由能函數(shù),將傳統(tǒng)的S3VM的最優(yōu)化過程轉(zhuǎn)換為一系列溫度依賴的物理系統(tǒng)。其中pj∈[0,1], 是x′j在正類上的概率。將變量uj放大到概率變量pj, 并根據(jù)pj建立關(guān)于溫度T的函數(shù),如式(2)所示
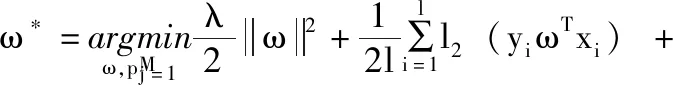
(2)
式(2)中,r為正樣本在所有樣本的占比,T控制了一系列目標(biāo)函數(shù)。從式(2)的優(yōu)化中得到最優(yōu)解的過程轉(zhuǎn)換為溫度T的降溫過程,從高溫狀態(tài)逐漸降低,理想值為0。記錄函數(shù)最值,由此獲得最優(yōu)解。溫度轉(zhuǎn)移的過程為Tk=ρTk-1,Tk模擬退火的過程中,第k次的溫度,ρ為過程中的系數(shù)。初始狀態(tài)下,溫度降低較快,隨著降溫過程的進(jìn)行,退火速度逐步減慢。
2.2 耦合模擬退火半監(jiān)督SVM(CSAS3VM)
2.2.1 耦合模擬退火
SVM超參數(shù)選取,對算法最終表現(xiàn)有較大影響[27]。確定性退火S3VM是根據(jù)經(jīng)驗或?qū)嶒灉y試來選擇。本文提出的耦合模擬退火S3VM,將耦合模擬退火用于到S3VM的超參數(shù)選取。耦合模擬退火(coupled simulated annealing,CSA),模擬物理過程中的退火,在初始狀態(tài)下求解全局最優(yōu)解[28]。耦合模擬退火(CSA)與單個退火求解和并行多個退火求解問題的差異在于其將多個退火過程中的狀態(tài)信息共享,通過耦合的方式定義接受概率,面對新狀態(tài)的到來,所有耦合信息共同決定溫度狀態(tài)是否轉(zhuǎn)移。
對于新狀態(tài)的接受概率A(s→st), 數(shù)學(xué)上有多種定義。本文在尋求最優(yōu)解的過程中,采用的是Metropolis規(guī)則的變形,如式(3)所示
(3)
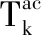
(4)
利用Boltzmann求解系統(tǒng)在第i個狀態(tài)的概率值,假設(shè) (i=1,2), 即系統(tǒng)僅有兩個可選狀態(tài),如式(5)所示
(5)
式(5)中kB為Boltzmann常數(shù),Ei為i狀態(tài)下,當(dāng)前系統(tǒng)的能量值,T為i狀態(tài)下的溫度。Z為當(dāng)前系統(tǒng)所有狀態(tài)的能量和,如式(6)所示
(6)
考慮式(4)和式(5),在狀態(tài)st和溫度T已給定的情況下,狀態(tài)st被接受的概率值由式(5)近似表示。為了實現(xiàn)耦合模擬退火,先初始化一個多狀態(tài)系統(tǒng),s為狀態(tài)的集合,si為當(dāng)前的第i個狀態(tài),sti為第i個當(dāng)前狀態(tài)將要轉(zhuǎn)移的新狀態(tài)。設(shè)s∈{s1,s2,…,sm}, 式(4)轉(zhuǎn)換為式(7)
(7)
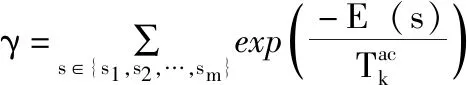
此時,當(dāng)前狀態(tài)s∈{s1,s2,…,sm} 對應(yīng)新狀態(tài)st∈{st1,st2,…,stm} 的接受概率為A(s→st)∈{A(s1→st1),A(s2→st2),…,A(sm→stm)}。 狀態(tài)集合s內(nèi)各個狀態(tài)接受對應(yīng)的轉(zhuǎn)移狀態(tài)st的概率,除了考慮自身外,還要考慮其它狀態(tài)的耦合。特殊情況下,當(dāng)狀態(tài)總數(shù)m=1時,方法將退化為傳統(tǒng)的模擬退火求解問題。
定義Θ={s1,s2,…,sm}, Θ?Ω, Ω為所有合法狀態(tài)的集合,CSA中的狀態(tài)si轉(zhuǎn)移到新狀態(tài)sti的概率如式(8)所示
0≤AΘ(γ,si→sti)≤1
(8)
當(dāng)前狀態(tài)si∈Θ, 新狀態(tài)sti∈Ω,γ為耦合項,如式(9)所示
γ=f[E(s1),E(s2),…,E(sm)]
(9)
如圖1所示,可以看到CSA與SA的主要不同點在于接受概率的定義。它使得當(dāng)前狀態(tài)集合下所有SA的狀態(tài)信息共享,并對耦合項和接受概率進(jìn)行組合,尋找全局最優(yōu)解。

圖1 模擬退火與耦合模擬退火的區(qū)別
2.2.2 CSAS3VM方法描述
耦合模擬退火半監(jiān)督支持向量(CSAS3VM)將耦合模擬退火應(yīng)用于尋找半監(jiān)督支持向量機的最優(yōu)參數(shù)。設(shè)定初始值,由此生成當(dāng)前狀態(tài)。通過擾動函數(shù),產(chǎn)生新狀態(tài)。關(guān)于擾動函數(shù)的定義請參見文獻(xiàn)[26],擾動因子ε的分布為
(10)
將式(10)帶入擾動函數(shù),由此新狀態(tài)st的表達(dá)式如式(11)所示
(11)
具體實現(xiàn)如算法1所描述,源代碼見https://github.com/WUT-IDEA/SAS3VM(含傳統(tǒng)模擬退火方法和耦合模擬退火方法)。
算法1:CSAS3VM
輸出:全局最優(yōu)解ω

(2)對集合Θ的每個狀態(tài)si都通過擾動函數(shù)產(chǎn)生新的狀態(tài)sti=si+εi, ?si∈Θ。εi是通過式(10)隨機得到的變量。將轉(zhuǎn)移狀態(tài)sti和當(dāng)前解ωi作為輸入,代入算法2中,計算轉(zhuǎn)移狀態(tài)的能量E(sti), ?sti∈Θ, ?i=1,2,…,m。
(3)對每個i=1,2,…,m, 如果E(sti)≤E(si), 接受新狀態(tài)sti; 否則,以AΘ(γ,si→sti) 的概率,接受轉(zhuǎn)移狀態(tài)sti。 當(dāng)AΘ>δ時,接受轉(zhuǎn)移狀態(tài)sti,δ∈[0,1]。 更新每個SA對應(yīng)的當(dāng)前最優(yōu)解ω*, 計算耦合項γ, 返回步驟(2),循環(huán)N次。
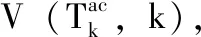
(5)如果達(dá)到預(yù)先設(shè)定好的停止條件,則算法結(jié)束,找到能量E(si),i=1,2,…,m的最小能量,輸出該能量所在狀態(tài)的最優(yōu)解ω*; 否則,從步驟(2)開始,繼續(xù)循環(huán)。
CSAS3VM的時間復(fù)雜度為O(nNE),N為CSA方法內(nèi)循環(huán)次數(shù)需要的次數(shù),n為CSA方法外循環(huán)次數(shù)需要的次數(shù),E為計算系統(tǒng)能量E(s) 的時間復(fù)雜度(算法2中給出計算)。
本文提出的CSAS3VM的接受概率如式(7)所示,使得接受新狀態(tài)的概率AΘ(γ,si→sti) 與轉(zhuǎn)移狀態(tài)的能量E(sti) 成反比。耦合項由當(dāng)前所有狀態(tài)共享。
傳統(tǒng)的確定性退火半監(jiān)督支持向量機中的超參數(shù)λ和λ′, 常見的做法是通過經(jīng)驗判定。就不同的數(shù)據(jù)集,超參數(shù)初始化不同,會影響預(yù)測結(jié)果。針對該情況,本文在尋找實際問題中最優(yōu)參數(shù)組合時,選定初始值后,第k次的超參數(shù)的擾動函數(shù)如式(12)所示
λk=λk-1+εk-1λk∈Ω
(12)
εk-1為滿足式(10)的隨機變量。
接下來討論使用確定性退火(DA)計算系統(tǒng)能量E(s) 的過程,見算法2。
算法2:E(s)計算
輸入:狀態(tài)s, 當(dāng)前最優(yōu)解ω;
輸出:當(dāng)前狀態(tài)能量E(s), 最優(yōu)解ω。
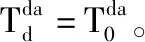
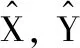
(3)使用拉格朗日方程,將式(2)重構(gòu)為式(15),求pj的偏導(dǎo),帶入到式(2)的約束后,得到用于求解拉格朗日乘子v的非線性方程,通過使用組合的牛頓-拉夫遜迭代法和二分法進(jìn)行求解。計算v, 更新pj。
(4)循環(huán)執(zhí)行步驟(2)和步驟(3),對ω和p進(jìn)行優(yōu)化,檢查是否滿足停止迭代的條件。本文采用pj的當(dāng)前值p與上一次循環(huán)的值q的平均KL距離。
(5)對Tda進(jìn)行降溫,將改變后的ω作為傳統(tǒng)監(jiān)督SVM的初始值,重復(fù)步驟(2)~步驟(4),當(dāng)溫度為最低或者達(dá)到最大循環(huán)次數(shù)時,停止。
(6)更新ω, 使用測試集,完成當(dāng)前狀態(tài)s的能量E(s) 的計算。
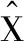
(13)
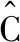

(14)
步驟(3)中構(gòu)造的式(2)的關(guān)于拉格朗日方程如式(15) 所示
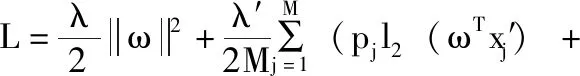
(15)
式(15)中,v為拉格朗日pj乘子,對pj求偏導(dǎo)得到式(16)
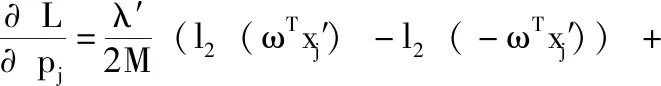
(16)
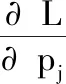
pj代入到傳統(tǒng)監(jiān)督SVM的約束條件得到式(17)
(17)
式(17)為關(guān)于v的非線性方程,通過算法2的步驟(3),帶入式(17)可以得到pj。
本文中的KL距離定義如式(18)所示
(18)
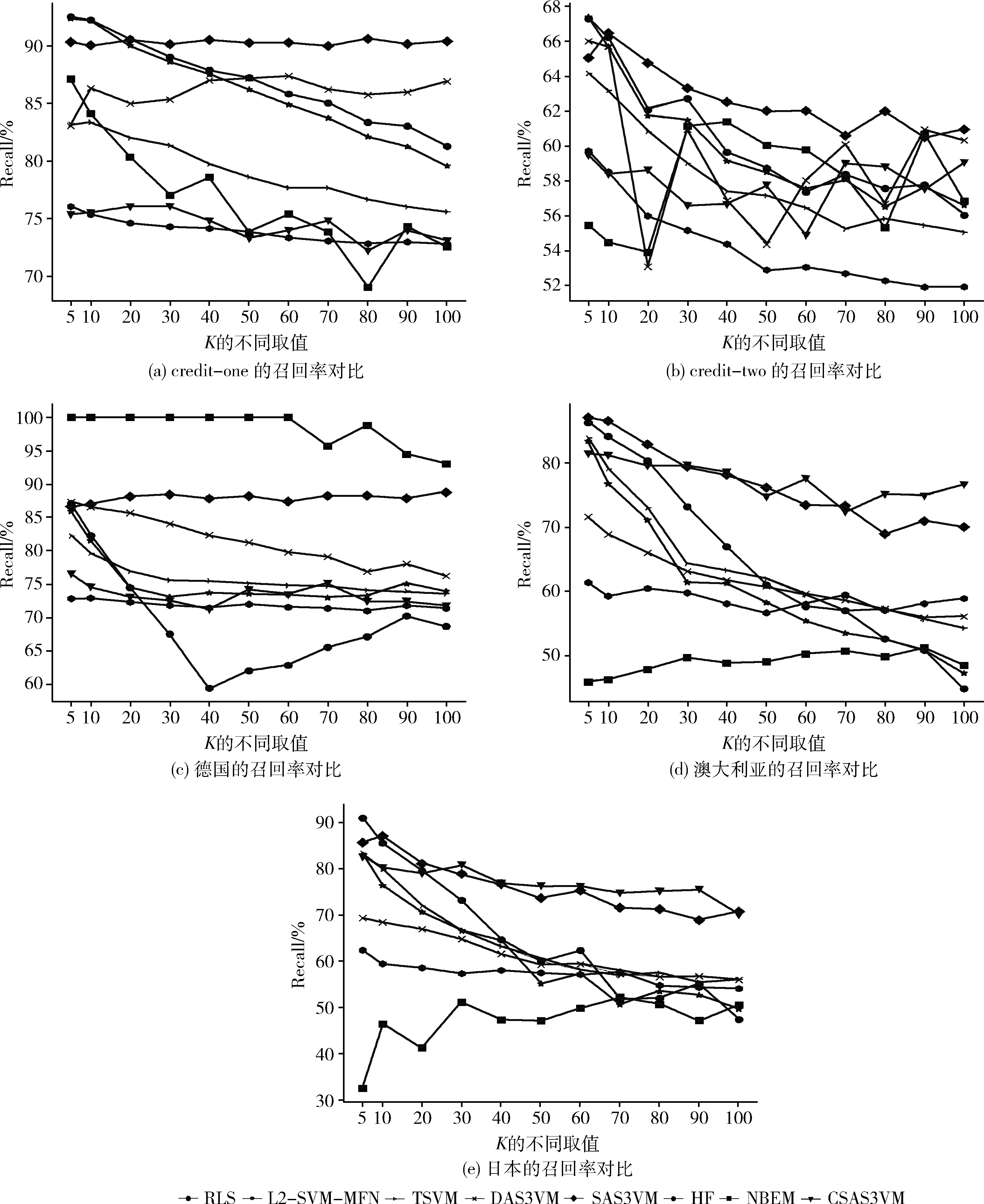
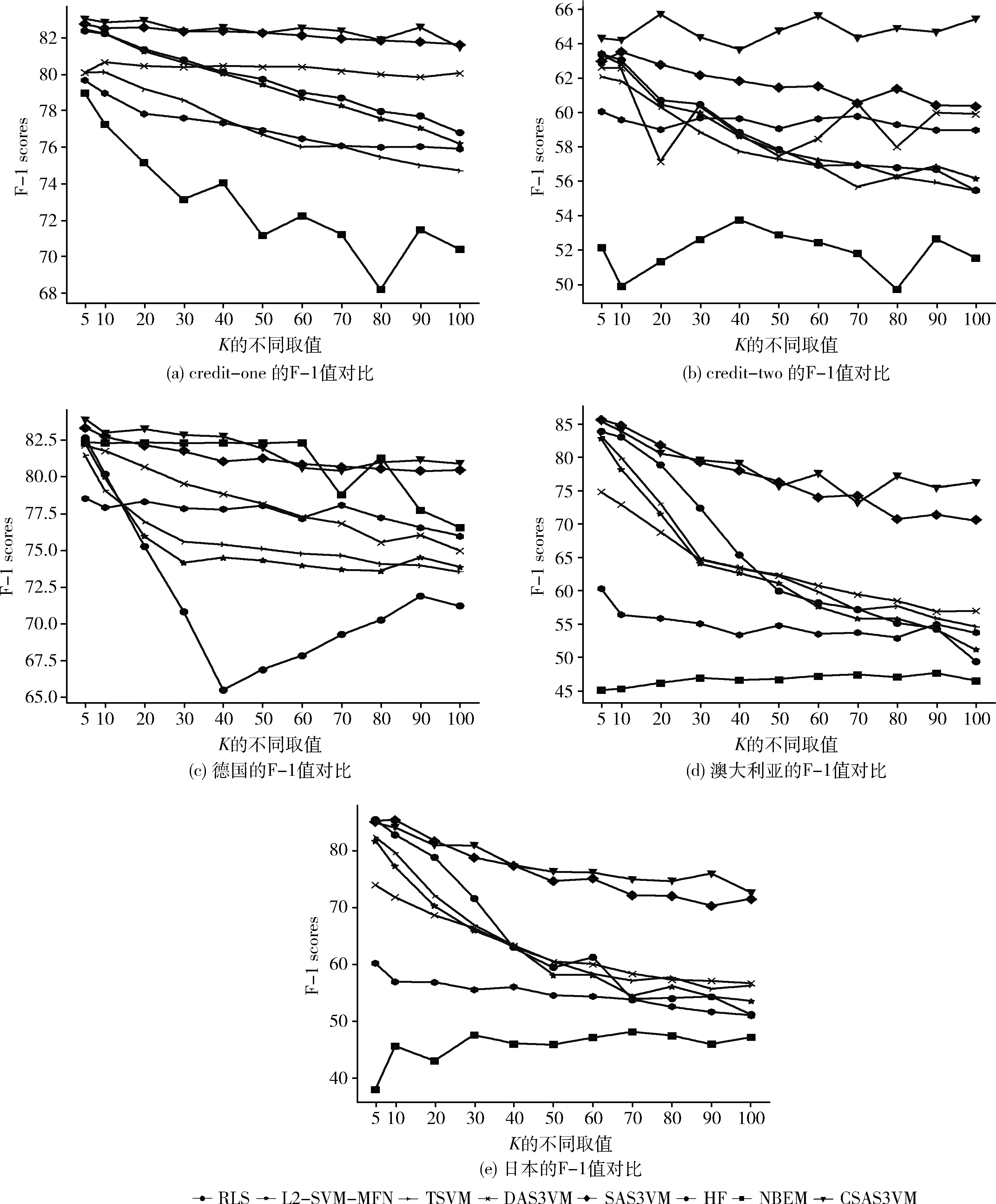
當(dāng)滿足KL(p,q) 本文使用的兩類數(shù)據(jù)集分別是UCI(https://archive.ics.uci.edu/ml/datasets.html)公開的個人信用數(shù)據(jù)(德國、澳大利亞、日本)和通過網(wǎng)絡(luò)爬取的中國企業(yè)信用數(shù)據(jù)(credit-one、credit-two)。 表1為UCI上的3組個人信用數(shù)據(jù)集的相關(guān)信息。p+n項為數(shù)據(jù)集的樣本數(shù),p為正類樣本,n負(fù)類樣本,feature為每個樣本的特征數(shù)量。 表1 個人信用數(shù)據(jù)集 由于UCI的信用數(shù)據(jù)集來自于90年代且數(shù)據(jù)量偏小,本文通過爬蟲從阿里巴巴(https://s.1688.com)和企業(yè)信用信息公示系統(tǒng)(http://www.gsxt.gov.cn)中爬取企業(yè)信用相關(guān)數(shù)據(jù)。由于數(shù)據(jù)存在缺失,還需要對數(shù)據(jù)進(jìn)行篩選。 篩選后,形成兩個企業(yè)數(shù)據(jù)集credit-one和credit-two。相關(guān)字段的意義與表1相同,見表2。credit-one數(shù)據(jù)集屬于正負(fù)樣本不均衡,而credit-two數(shù)據(jù)集相對均衡,本文根據(jù)這兩種數(shù)據(jù)的實驗結(jié)果討論不同信用預(yù)測方法的性能。 表2 企業(yè)信用數(shù)據(jù)集 本文所有需要用到核函數(shù)的算法,選取的核函數(shù)為線性核。提出的CSAS3VM方法與以下7種方法進(jìn)行了對比實驗:基于傳統(tǒng)監(jiān)督學(xué)習(xí)的方法(1)和方法(2)與基于半監(jiān)督學(xué)習(xí)的方法(3)~方法(7)。 (1)RLS[29]:邏輯回歸,監(jiān)督學(xué)習(xí)方法。 (2)L2-SVM-MFN[30]:傳統(tǒng)支持向量機,監(jiān)督學(xué)習(xí)方法。 (3)TSVM[18]:半監(jiān)督支持向量機,半監(jiān)督學(xué)習(xí)方法。 (4)HF[19]:基于高斯調(diào)和函數(shù)的半監(jiān)督算法,半監(jiān)督學(xué)習(xí)方法。 (5)NBEM[31]:樸素貝葉斯最大期望算法,半監(jiān)督學(xué)習(xí)方法。 本文提出的CSAS3VM是在確定性退火和模擬退火S3VM上的改進(jìn)。 (6)DAS3VM[15]:用確定性退火尋找最優(yōu)解的半監(jiān)督支持向量機,半監(jiān)督學(xué)習(xí)方法。 (7)SAS3VM[26]:用模擬退火尋找最優(yōu)解的半監(jiān)督支持向量機,半監(jiān)督學(xué)習(xí)方法。 (8)CSAS3VM:本文提出的耦合模擬退火半監(jiān)督支持向量機(使用 L2-SVM-MFN 在標(biāo)記數(shù)據(jù)上訓(xùn)練出一個初始分類器),半監(jiān)督學(xué)習(xí)方法。 為避免實驗中出現(xiàn)過擬合現(xiàn)象,本文采用反K折交叉驗證的方式,該方式為半監(jiān)督學(xué)習(xí)中常用的驗證方式,使結(jié)果更加真實準(zhǔn)確。反K折交叉驗證的過程類似于K折交叉驗證,不同點在于訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)劃分的方式。反K折交叉驗證在訓(xùn)練過程中一次選擇1折進(jìn)行訓(xùn)練,其余K-1折數(shù)據(jù)為測試數(shù)據(jù),最后取K次實驗的平均結(jié)果。實驗中,設(shè)置K=5,10,20,30,40,50,60,70,80,90,100。 本文的評價指標(biāo)包含:分類的精度(Precision)、召回率(Recall)和F-1值(F-1 scores)。F-1值對精度和召回率進(jìn)行了權(quán)衡。精度(Precision)表示分類器預(yù)測為正的樣本中,預(yù)測準(zhǔn)確的比例。召回率(Recall)表示測試集中正樣本被預(yù)測出的比例。在信用評估中,信用為負(fù)的個人或者企業(yè)若被誤分,將獲得貸款,這將帶來非常大的經(jīng)濟損失。所以本文除了考慮評價指標(biāo)F-1值,還關(guān)注各種方法在精度指標(biāo)上的表現(xiàn)。 圖2(a)、圖2(b)用折線表示8種方法在企業(yè)信用數(shù)據(jù)集上精度對比的實驗結(jié)果,圖2(c)~圖2(e)則是在個人信用數(shù)據(jù)上的對比結(jié)果。橫坐標(biāo)表示反K折交叉驗證中K的不同取值,K越大,則表示標(biāo)記數(shù)據(jù)越少,越能體現(xiàn)半監(jiān)督學(xué)習(xí)類方法的優(yōu)勢。 圖2 精度對比實驗 在credit-one和credit-two企業(yè)信用數(shù)據(jù)集上(圖2(a)、圖2(b)),本文所提出的CSAS3VM方法精度明顯最高。以credit-one的數(shù)據(jù)為例,當(dāng)K=5時,半監(jiān)督方法中DAS3VM的精度為77.3,HF為83.6,本文提出的CSAS3VM為92.4;當(dāng)K=100時,標(biāo)記數(shù)據(jù)只有1折數(shù)據(jù),SAS3VM的精度為74.1,HF為79.3,本文提出的CSAS3VM為92.8。在credit-one數(shù)據(jù)集上,取不同K值時,各方法的精度見表3。 表3 credit-one數(shù)據(jù)集上的Precision值/% 從企業(yè)信用數(shù)據(jù)的實驗結(jié)果總體來看,半監(jiān)督學(xué)習(xí)類方法優(yōu)于監(jiān)督類學(xué)習(xí)方法RLS和L2-SVM-MFN。CSAS3VM方法將較少的負(fù)類樣本預(yù)測為正類樣本,具有最高的精度。當(dāng)數(shù)據(jù)正負(fù)樣本不均衡時,CSAS3VM方法在精度指標(biāo)上表現(xiàn)穩(wěn)定,而其它方法的精度在credit-one上明顯低于credit-two。 圖3(a)、圖3(b)為在不同K值下,8種方法在企業(yè)信用數(shù)據(jù)集上召回率的對比結(jié)果,圖3(c)~圖3(e)為個人信用數(shù)據(jù)集上的對比結(jié)果。 圖3 召回率對比實驗 在credit-one、credit-two數(shù)據(jù)集和德國數(shù)據(jù)集上,CSAS3VM的召回率表現(xiàn)并不理想,這是由于CSAS3VM不只是關(guān)注預(yù)測正例的效果。而NBEM方法在德國數(shù)據(jù)集上部分K值的召回率達(dá)到了100%,這是因為數(shù)據(jù)集正負(fù)樣本不均衡,其中德國數(shù)據(jù)集的正例樣本占比為70%,算法偏向于將樣本預(yù)測為正例,忽略了在信用評估領(lǐng)域若負(fù)例被預(yù)測為正例會造成較大的損失。在澳大利亞和日本的個人數(shù)據(jù)集上,CSAS3VM方法在大部分K值上召回率為最高。 在信用評估中,應(yīng)更加關(guān)注精度(預(yù)測信用為好的樣本中,實際信用好的樣本所占比例)。因此,僅通過召回率來評價模型并不合理,綜合了召回率和精度的F-1值能更好評價算法的表現(xiàn)。 圖4(a)、圖4(b)用折線表示8種方法在企業(yè)信用數(shù)據(jù)集上F-1值的對比實驗結(jié)果,圖4(c)~圖4(e)則是在個人信用數(shù)據(jù)上的對比實驗結(jié)果。 圖4 F-1值對比實驗 在credit-one和credit-two企業(yè)信用數(shù)據(jù)集上,本文提出的CSAS3VM方法的F-1值最高,其次是SAS3VM方法。 在credit-one數(shù)據(jù)集上,由于其不均衡,其它非退火類方法隨著K值的變大,性能下降明顯。在credit-two數(shù)據(jù)集上,CSAS3VM方法明顯優(yōu)于其它7種方法,當(dāng)K=100時,CSAS3VM方法的F-1值為65.4,比次之的SAS3VM(60.3)提高了8.5%,比監(jiān)督方法中表現(xiàn)最好的L2-SVM-MFN(56.1)提高了16.6%。 以credit-one數(shù)據(jù)為例,當(dāng)K=5時,本文提出的CSAS3VM的F-1值為83.0,次之的L2-SVM-MFN監(jiān)督方法為82.4;兩者差距不大,是因為有1/5的訓(xùn)練數(shù)據(jù)參與訓(xùn)練。當(dāng)K=100時,標(biāo)記數(shù)據(jù)只有1/100份時,CSAS3VM的F-1值為81.4,而L2-SVM-MFN監(jiān)督方法為76.8。可以看到隨著K值的增大,訓(xùn)練數(shù)據(jù)越來越少,本文提出的CSAS3VM方法表現(xiàn)穩(wěn)定且最優(yōu)。NBEM方法表現(xiàn)最差,波動較大。 在個人信用數(shù)據(jù)集上,本文提出的CSAS3VM方法在F-1值上表現(xiàn)穩(wěn)定,特別是在K取值較大的情況下,其次是SAS3VM。以澳大利亞個人信用數(shù)據(jù)集為例,當(dāng)K取值小于等于20時,SAS3VM的F-1值稍微高于CSAS3VM方法,最多為1.6%;但是當(dāng)K取值大于20之后,CSAS3VM方法明顯優(yōu)于SAS3VM,最高提升了7.9%。總體而言,和其它方法相比,耦合模擬退火方法在參數(shù)尋優(yōu)方面表現(xiàn)突出。 NBEM方法表現(xiàn)最差,雖然在德國個人信用數(shù)據(jù)集上有82左右的F-1值,其原因是NBEM方法簡單,算法傾向于預(yù)測多數(shù)類,即將數(shù)據(jù)預(yù)測為正類。由此得到了接近100%的召回率和70%左右的精度;而在澳大利亞和日本數(shù)據(jù)集上的F-1值不足50。 (1)本文提出的CSAS3VM方法在兩種共5組數(shù)據(jù)集上的總體表現(xiàn)最好,精度最高,F(xiàn)-1值較高。在正負(fù)樣本比例不均衡時,也表現(xiàn)穩(wěn)定。可以看到耦合模擬并行地進(jìn)行模擬退火過程,通過接收概率函數(shù)耦合,提高了最優(yōu)參數(shù)搜索的性能,彌補了傳統(tǒng)模擬退火方法對初始參數(shù)選取魯棒性差的缺點。 (2)引入模擬退火機制的S3VM,比如本文提出的CSAS3VM和已有的SAS3VM,綜合來看均比其它方法表現(xiàn)好。較差解在滿足條件的情況下,模擬退火將接受該解,避免算法一直處于局部最優(yōu)。 (3)半監(jiān)督的HF和NBEM方法總體上看表現(xiàn)最差,大多數(shù)情況下也不如RLS和L2-SVM-MFN兩種監(jiān)督學(xué)習(xí)方法。與大多數(shù)的研究結(jié)果一致,SVM分類預(yù)測能力強。 (4)監(jiān)督學(xué)習(xí)方法RLS和L2-SVM-MFN隨著K的增加,訓(xùn)練數(shù)據(jù)減少,精度減少,F(xiàn)-1值減少,預(yù)測性能呈現(xiàn)明顯的下降趨勢。可以看到監(jiān)督學(xué)習(xí)方法在訓(xùn)練數(shù)據(jù)小于測試數(shù)據(jù)的情況下,性能不理想。 本文在傳統(tǒng)半監(jiān)督支持向量機的基礎(chǔ)上,提出了CSAS3VM,并在5組數(shù)據(jù)集上進(jìn)行了對比實驗。綜合精度、召回率和F-1值3項評價指標(biāo),本文提出的CSAS3VM相對于SAS3VM和其它方法,具有更高的精度和較高的F-1值。因此,可以認(rèn)為CSAS3VM是一種有效的信用預(yù)測方法,在正負(fù)樣本不均衡的情況下,表現(xiàn)穩(wěn)定。 CSAS3VM在準(zhǔn)確度和效率上都存在改進(jìn)空間。耦合模擬退火雖然并行處理多個退火過程,但單個退火過程仍采用單次比較的方式。今后考慮在每一個當(dāng)前狀態(tài),采用多次搜索策略,搜索當(dāng)前狀態(tài)范圍內(nèi)的最優(yōu)解。其次,耦合模擬退火在多個模擬退火之間進(jìn)行信息共享,這一特性讓其適應(yīng)于分布式環(huán)境,今后同樣可以考慮在分布式環(huán)境下,實現(xiàn)CSAS3VM。3 實 驗
3.1 數(shù)據(jù)集


3.2 對比方法
3.3 評價指標(biāo)
3.4 精度對比實驗
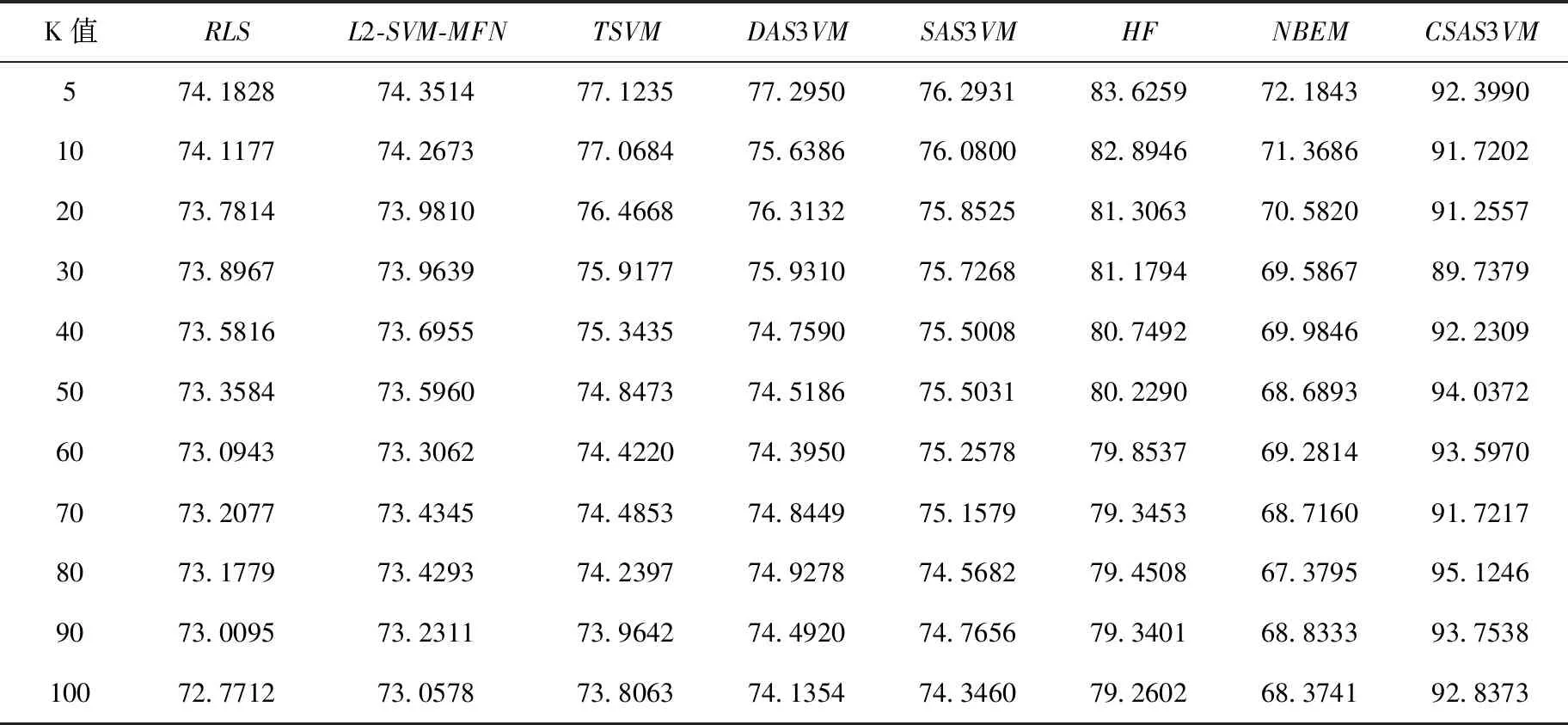
3.5 召回率對比實驗
3.6 F-1值對比實驗
3.7 實驗結(jié)果分析
4 結(jié)束語
猜你喜歡
人大建設(shè)(2020年4期)2020-09-21 03:39:12
兒童故事畫報(2019年5期)2019-05-26 14:26:14
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
浙江人大(2014年5期)2014-03-20 16:20:28
浙江人大(2014年4期)2014-03-20 16:20:16
