大規模空間矢量數據分布式存儲與計算優化①
2021-01-21 06:50:22白曉飛張小桐
計算機系統應用 2020年12期
張 嘉,白曉飛,陶 超,張小桐
1(中國國土勘測規劃院,北京 100035)
2(廣東南方數碼科技股份有限公司,廣州 510665)
Foundation item:National Key Research and Development Program of China (2018YFD1100103-05);Program of Ministry of Natural Resources of the People’s Republic of China (1902-033-14)
1 引言
國土數據類型多樣、結構復雜、變化頻繁,具有很強的空間化、圖形化特征.近年來,隨著空間信息技術與資源環境管理工作普遍、深度交融,地表基質、地表覆蓋、地下空間、業務信息等各類國土空間數據日趨復雜,涉及“山水林田湖草”及地質、礦產等數百類自然資源要素,在地理空間上彼此映射、關聯,且數據規模迅速增長.以全國土地調查矢量數據為例,年度更新數據超過2TB,累計要素數已達41 億.自然資源政務審批和業務管理,需要高效分析上述海量數據間的位置和語義關系以輔助決策,這一過程往往需要進行大量復雜空間運算.面向大規模空間數據分析,傳統關系型數據庫的空間數據存儲與計算框架愈發難以滿足實際需要.
隨著大數據技術快速發展,以云計算為代表的分布式計算技術以其高性能和高可靠性,特別是彈性擴展的數據存儲與處理能力,為大規模空間數據高效存儲與計算提供了可靠路徑[1-3].其中,Apache Hadoop 項目作為普遍流行的開源分布式大數據應用框架,實現了MapReduce 分布式數據計算模型和HBase 分布式數據庫等核心應用,支持基于集群的海量數據分布式存儲和運算,在超大規模數據管理中得到廣泛運用[4].近年來,為解決矢量數據空間分析的基本難題,基于Hadoop 應用生態構建了SpatialHadoop、Hadoop-GIS、Spatial-Spark、GeoSpark 等擴展框架,為矢量數據存儲、索引和計算提供了基礎支持[5].
數據組織作為處理和操作的基石,其結構和性能深刻影響統計、分析與服務效率,成為海量時空數據管理、應用的關鍵問題之一.針對Hadoop 空間數據存儲與計算,相關學者在數據組織、索引構建等方面進行了研究.王凱等提出了基于Hadoop 的地理信息大數據處理模型,設計了矢量數據的格式轉換方法[6];范建永等利用HBase 進行矢量空間數據管理,基于Map-Reduce 構建了并行空間索引[7];李振舉等提出了一種四叉樹-Hilbert 結合的索引設計方法[8];朱進等提出了一種基于內存數據庫Redis 的輕量級矢量地理組織方法[9].但當前研究主要集中在分布式數據存儲的負載均衡,未對索引、分區和計算進行一體化考慮.
本文基于HBase 數據存儲與訪問的特性,使用四叉樹多級格網編碼算法進行矢量要素編碼,構建分布式空間數據索引;針對HBase 缺乏對矢量數據模型有效支持的問題,提出了一種通過行鍵編碼鏈接索引、分區與計算的數據組織模型和分布式處理機制,并設計了分布式計算的優化流程,為大規模空間數據存儲與處理提供了一種解決方案.
2 空間數據組織與優化
2.1 四叉樹格網索引
本文使用四叉樹多級格網算法對矢量數據進行編碼構建索引.該算法基于平面直角坐標系劃分象限編碼,基本思想是將全域空間范圍劃分為4 個相等的區域并遞歸執行,直到剖分層次達到指定深度[10,11].其處理流程可簡單描述為:第一,確定矢量要素集合的矩形空間范圍作為基準格網并逐級剖分;第二,對剖分后的各級格網進行編碼;第三,計算每個矢量要素的最小外接矩形;第四,根據最小外接矩形空間上映射的格網,使用格網編碼對其遞歸賦值;第五,存儲每個矢量要素的編碼集合.可見,通過計算矢量要素外接矩形所在的格網編碼,可快速獲取該要素在相應格網層級的空間位置,如圖1所示.格網的劃分層級與要素的編碼長度正相關,過多層級會導致要素的編碼復雜性增大,并產生數據冗余.因此,格網編碼的深度應根據數據特點進行設計,遵循的基本原則是確保大部分要素擁有一個編碼,允許少部分的要素擁有多個編碼.
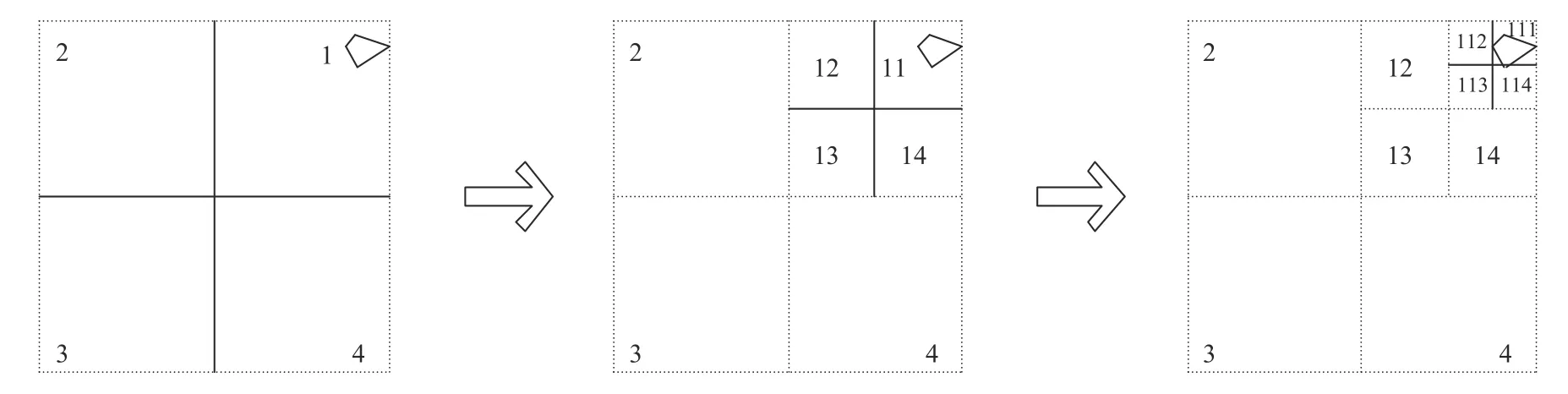
圖1 四叉樹編碼示意圖
2.2 HBase 預分區設計
將數據均衡分布到集群計算節點,是充分利用分布式計算資源的必要條件.HBase 以region 作為數據擴展和負載均衡的基本操作單元,分配到不同的計算服務器.HBase 表中的數據按照行鍵(RowKey) 排序,每個region 通過記錄起止行鍵管理表中的某些行數據[12].表首次創建時,默認只分配一個region,此時所有的讀寫操作都集中于這個region 所在的服務器,從而產生“熱點”(hot spotting)問題,導致該服務器負載急劇上升、性能下降;同時,region 中導入的數據量達到一定閾值會觸發分裂(region-split),即找到一個中間行鍵(MidKey)將其拆分為兩個region,當輸入大規模數據時,分裂次數快速增加將大量占用磁盤I/O 資源,降低集群性能.針對上述問題,本文根據矢量數據的格網索引機制設計預分區策略,分區格網采用四叉樹剖分,當預設4n(n≥1,n為剖分層級)個分區時,以第n級格網編碼作為預分區號,如圖2.預分區號作為行鍵編碼的前綴,數據入庫時可自動根據該編碼將要素均衡地向多個region 劃分.
使用MapReduce 框架進行并行計算時,分區數量決定了Map 函數的數量,即每個分區將啟動一個Map 函數進行計算,為保證計算和負載均衡,需合理預設分區數量,并考慮將相鄰空間要素聚集.分區個數過小,會造成單個分區的數據量過大,不利于負載均衡;分區個數過多,會導致單個分區內數據量不足,不利于集中處理.實踐中,應根據計算資源和數據量采用適當的分區數,原則上是充分利用集群的分布式特性,進行大范圍空間計算時,盡可能減少節點間數據傳輸,并使局部范圍計算在單個節點完成,以節約I/O 資源.一般而言,可以以集群中region server 數量的倍數作為參考值.
2.3 空間數據分布式存儲設計
2.3.1 行鍵編碼方法
HBase 作為面向列存儲的數據庫,通過行鍵檢索數據的效率較高,每秒鐘可獲取1000~2000 條記錄,而檢索非Key 列時效率相對偏低.因此,建立空間數據格網編碼與行鍵編碼的關聯,使行鍵編碼集成空間信息,是提高空間檢索效率的關鍵環節.本文提出以預分區號、要素格網編碼和隨機碼組合構建行鍵編碼的方法,該編碼集成了集群和要素空間信息,便于分布式處理.
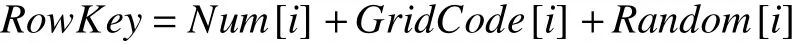
GridCode為格網編碼,使用2.1 節中通過格網編碼算法生成的定長字符碼;Random為隨機碼,根據實際應用中數據集的大小確定,用于保證行鍵編碼的唯一性;預分區號(Num)根據2.2 節確定的方法獲取,并根據格網剖分后空間相鄰矢量要素編碼通常前綴相同的特點進行優化:僅有一個編碼的要素,直接以其編碼值的后兩位作為預分區號;有多個編碼的要素,采用多個編碼共同前綴的后兩位作為預分區號.這種方法實現了索引、分區、計算的一體化設計(如圖3),使地理空間臨近的數據相對聚集,整體數據較均衡分布到各數據節點,有助于提升空間分析的計算效率,同時便于索引的動態更新維護.
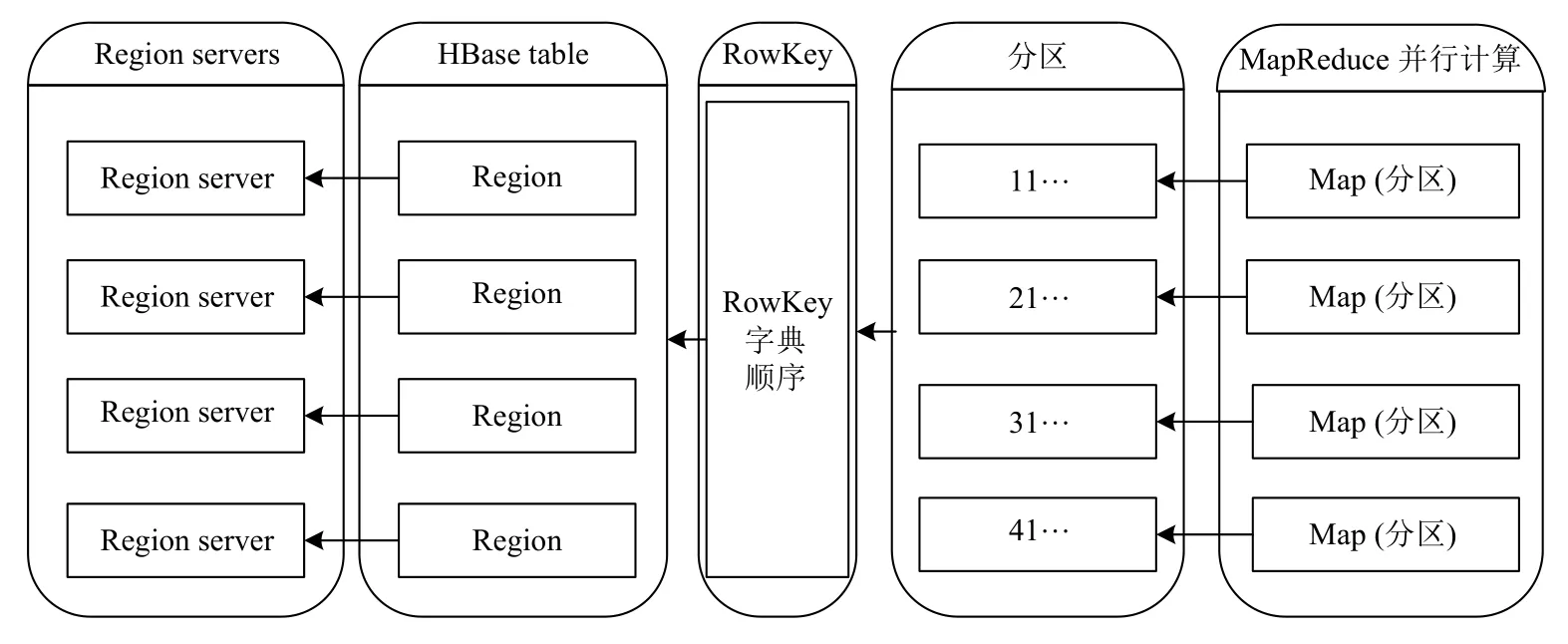
圖3 行鍵編碼與數據存儲計算
2.3.2 矢量數據表存儲
基于上述行鍵編碼方法,空間矢量數據在HBase中的表存儲設計如表1.其中,num[i]+gridCode[i]+random[i]構成行鍵(“+”表示連接,行鍵字符串中不含該符號)唯一標識表中的一條記錄.矢量要素存儲表設計了一個Column Family(列族)矢量信息,該列族下按照要素字段定義Qualifier(列限定符),列限定符與原矢量數據屬性名稱保持一致,存儲圖斑編號、地類、權屬等信息,其中SHAPE 存放JSON 格式的坐標數據.至此,實現了土地空間矢量數據從關系型數據組織向分布式數據存儲的轉換.
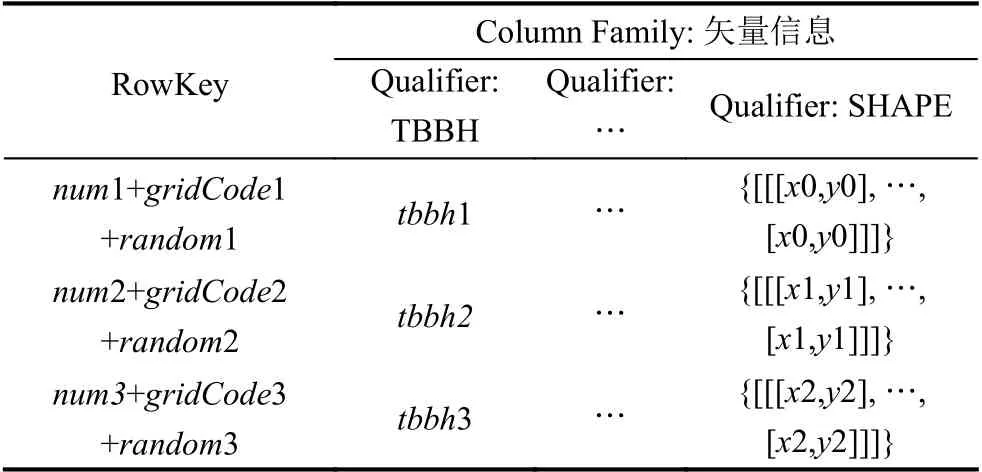
表1 空間數據存儲表結構設計
3 空間數據分布式計算
3.1 預處理與計算優化
(1)重復計算規避.基于格網的空間數據存儲本質上是一種以空間換時間的設計模式.矢量要素空間大小不同,格網編碼算法生成的編碼值個數也隨之不盡相同,導致存入HBase 表中的同一要素可能存在多個記錄,不利于MapReduce 并行計算[13].為降低重復數據對計算性能的影響,本文將同一要素的多個記錄存儲在同一分區,通過矢量要素標識信息,在Map 函數計算階段構建緩存記錄參與計算的要素,進行去重操作,避免了數據重復計算和傳輸.
(2)空間數據關聯映射.針對參與空間計算的多元矢量數據集,按照格網編碼方法進行統一編碼,矢量要素采用本文提出的行鍵編碼算法構建數據對象間的編碼映射.計算時對無編碼映射關系的空間數據進行過濾,可有效降低計算數據的規模.同時,通過要素編碼可快速查找關聯要素,避免全表要素掃描,從而大幅減少程序遍歷次數,提升了分布式計算的性能.
3.2 分布式計算流程
分布式計算一定程度上可以有效改善傳統模式下處理大規模空間數據計算能力不足的問題.以空間疊加操作為例,典型的業務場景為:針對存儲于分布式數據庫中的地類圖斑矢量要素,使用外部存儲的、對應縣級行政區劃內的監測圖斑與之進行空間疊加,將疊加得到的裁切后矢量數據輸出,計算要素面積,并統計某類屬性下的土地面積匯總數.以此為例,基于上述數據組織策略,本文設計了分布式計算方法,主要思路為:基于MapReduce 計算框架,結合Esri GIS Tools for Hadoop 工具,實現空間數據Map 函數計算,Reduce 函數執行結果匯總并輸出.具體處理流程為:(1)將待疊加矢量要素轉換為JSON 文件,讀入HDFS 存儲,對其進行格網編碼;(2)建立與被疊加地類圖斑矢量要素的編碼映射,獲取關聯的要素集合;(3)將關聯集合加載到分布式緩存中;(4)Map 函數逐條讀取地類圖斑矢量數據,根據要素編碼獲取分布式緩存中集合中的對應要素,并執行空間疊加操作;(5)輸出裁切后的數據,并將過程數據傳送Reduce 函數處理;(6)Reduce 函數完成計算結果的匯總及輸出.總體流程如圖4.
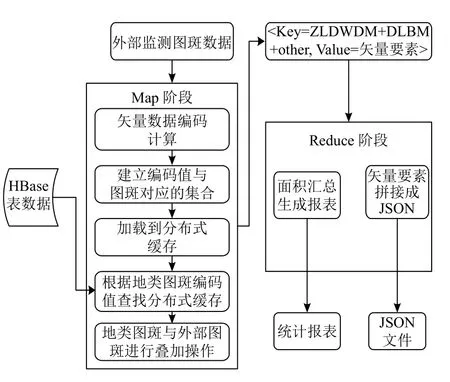
圖4 空間數據裁切操作流程
4 測試與分析
針對本文提出的格網編碼索引、預分區及行鍵優化設計的空間數據組織策略和計算流程,使用真實數據,采用空間疊加與統計場景進行測試,驗證方案的有效性.
4.1 測試環境
基于Hadoop 2.7.3 搭建一個主節點,4 個數據節點的集群環境(圖5),在該集群部署HBase 1.3.1.數據節點服務器配置為:CPU Intel(R) Xeon(R) CPU E5-2609 v4 @ 1.70 GHz;內存:128 GB;操作系統:CentOS7.3;網絡帶寬為1000 Mb/s.
4.2 測試過程與結果分析
4.2.1 測試數據
180個縣級行政區劃單位的地類圖斑(DLTB)和監測圖斑(JCTB),兩類數據都是空間矢量要素.為便于對比,將其分為8 個測試組,每組所含要素和數據量如表2所示.
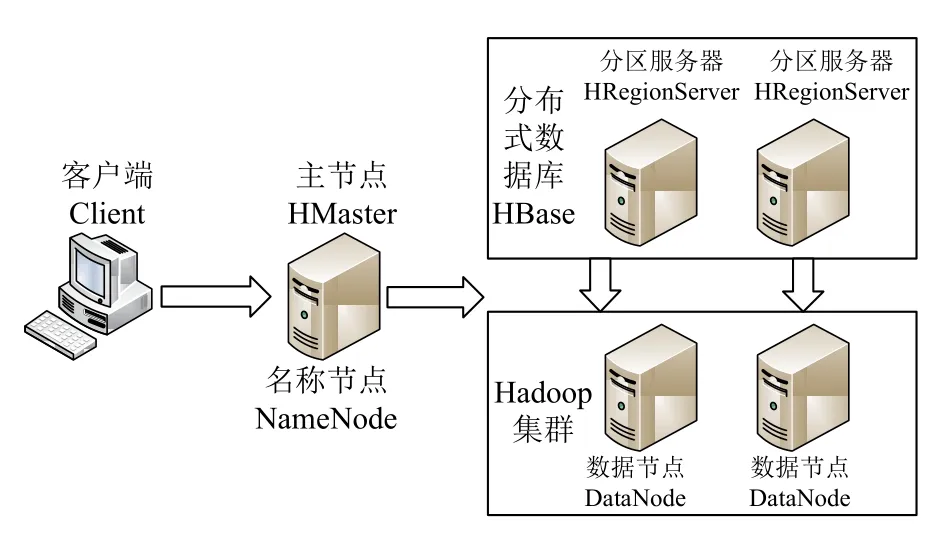
圖5 測試環境
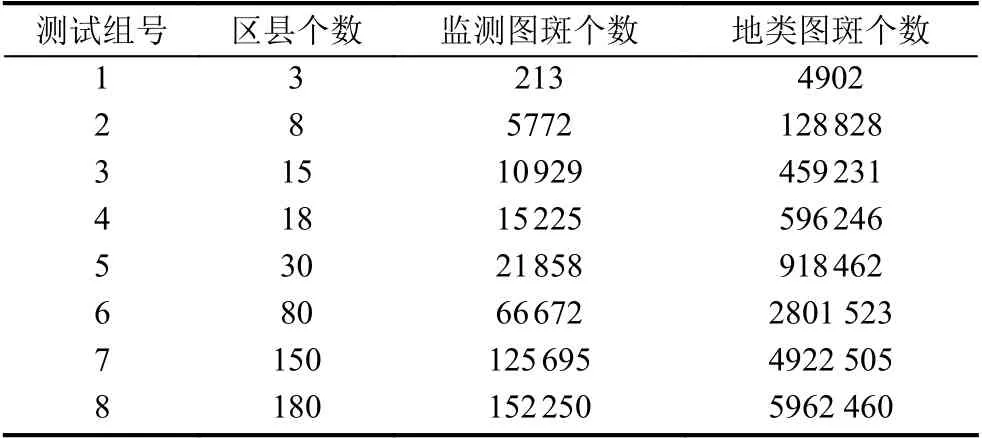
表2 數據分組及要素數
4.2.2 測試內容與流程
自然資源管理中,地類圖斑刻畫了土地利用的現狀情況,按照規定的時點更新.遙感監測是維護土地現狀信息準確性和現勢性的重要手段,通過對比、判讀不同時相的遙感影像,能夠識別發生變化的國土特征信息,這些變化信息經矢量化形成監測圖斑.業務實踐中,一種典型的應用場景是獲取監測圖斑空間范圍內變更前的土地利用類型和面積等數據,以輔助數據更新、變化分析和行政監管.本文將監測圖斑與地類圖斑進行空間疊加,獲取監測圖斑的地類面積、權屬等信息,測試研究提出的分布式存儲與計算方案下空間數據分析和匯總統計的效率,主要流程如下:(1)將地類圖斑數據作為疊加底圖,創建格網索引,存儲在HBase 分布式數據庫;(2)以監測圖斑作為外部疊加數據,采用GIS Tools for Hadoop 插件工具集將其轉換為以縣級行政區為單位的JSON 文件,存儲于HDFS 分布式文件系統;(3)基于MapReduce 框架對監測圖斑和地類圖斑進行疊加,提取地類信息并計算面積,匯總形成監測圖斑地類面積匯總表,并輸出疊加后的圖形數據,驗證其正確性.
4.2.3 結果分析
按照測試流程對8 個測試組按照執行數據操作,記錄數據上傳、數據轉換、空間疊加、統計輸出幾項主要處理環節的耗時情況,如表3.

表3 測試耗時結果記錄(單位:s)
對表3數據進行分析,結果表明:
(1)數據處理耗時與數據量正相關,但隨著數據量的增加,計算效率呈現階段特征.在地類圖斑數由5000 向50 萬量級增長過程中,處理要素的平均耗時顯著下降,由平均0.29 秒/要素降為0.01 秒/要素,說明單位時間系統處理要素的能力在迅速提升,充分體現了分布式環境處理大規模數據的優勢;當要素數據超過50 萬后,單位時間處理要素的數量變化曲線基本平滑,這是由于服務器數量固定導致計算資源受限,可以預測增加計算節點,能夠進一步提高性能.
(2)空間疊加環節在總體分析流程中的耗時居支配地位,且遠高于其他環節,占比區間為94.45% 至98.02%,這說明空間數據并行計算是數據分析的核心,也是計算優化的重點.
根據上述分析結果,進一步測試本文提出的索引、預分區及行鍵編碼一體化設計的空間數據組織策略(記作GRID),與常規采用隨機散列構建行鍵編碼方法(記作RHASH)的空間分析效率對比.為降低計算資源對數據處理效率的影響,測試數據選擇18 個縣級行政單元的地類圖斑和監測圖斑矢量要素(共90 萬個要素),分為5 個測試組,記錄空間疊加的處理時間,如表4所示.
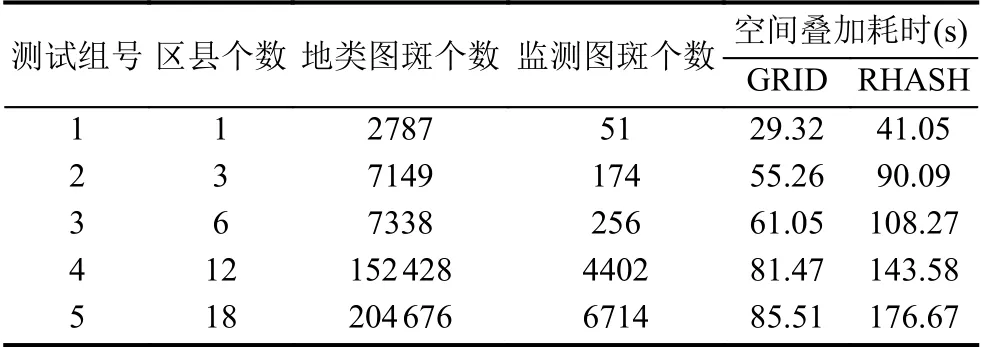
表4 空間疊加測試記錄
可見,GRID 優化方法空間疊加的耗時在各測試組均顯著低于RHASH 方法,且隨著數據規模的增加,其效率優勢進一步顯現,測試要素數據量區間最大側的執行效率提升了1 倍.這主要是由于未優化方案不能根據疊加數據從HBase 表中快速過濾與其相關的信息,需進行全表掃描,并判斷每條數據與疊加數據的空間關系.本文提出的優化策略彌補了這一不足,大幅降低了MapReduce 處理的數據量,從而有效提升了計算性能.
總體來看,分布式存儲與計算環境下,空間數據處理效率較關系型數據庫大幅增加.在硬件資源要求并不苛刻的條件下,近600 萬地類圖斑矢量要素的全流程疊加操作耗時僅20 分鐘,而關系型數據庫下的同量級相似數據處理需投入大量作業人員使用不同客戶端執行操作,時間單位往往以工作日計.因此,在海量國土空間矢量數據管理與分析中,將分布式存儲、計算技術與空間數據特性充分優化結合,能夠大幅提升工作效率.
5 結語
本文對空間矢量數據的分布式存儲與計算技術進行了探索,研究了基于四叉樹格網構建空間索引的方法,結合矢量數據的特性,將其與HBase 預分區策略和分布式存儲設計有效融合.同時,基于Hadoop 處理模型,設計了與之銜接的分布式計算流程,形成了一種分布式場景下矢量數據組織與計算的優化方法.后續工作中,擬擴大集群和數據規模,全面調試并進一步提升其實用性.
