
基于改進faster R-CNN 算法的小目標(biāo)車輛檢測
2021-01-24 14:27:08姚國愉李雪純張佳樂
科技創(chuàng)新與應(yīng)用 2021年4期
張 昭,姚國愉,李雪純,張佳樂
(西安郵電大學(xué) 通信與信息工程學(xué)院,陜西 西安 710121)
1 概述
車輛目標(biāo)檢測[1-2]在智能交通、智能駕駛、交通安全等方面發(fā)揮著重要作用,其任務(wù)是通過圖像處理技術(shù)識別出車輛目標(biāo)在圖像中的具體坐標(biāo)位置。如今,車輛目標(biāo)檢測算法雖然對正常的目標(biāo)車輛大小的檢測效果達到了一定標(biāo)準(zhǔn),但對遠距離小目標(biāo)的檢測性能均未達到應(yīng)有的效果,并且對遠距離小目標(biāo)的檢測在交通疏導(dǎo)和交通安全上都起著至關(guān)重要的作用,可以達到緩解交通壓力和降低交通事故的作用。在交通場景復(fù)雜性的背景下,遠距離小目標(biāo)車輛檢測存在一定難度。
為了應(yīng)對這些挑戰(zhàn),目標(biāo)檢測技術(shù)在不斷的發(fā)展,目標(biāo)檢測算法在最初的開發(fā)階段是基于手工特征的,但局限在提取特征能力比較弱,于是,由于深度學(xué)習(xí)的效果明顯,便成為了目標(biāo)檢測的主流方法。最初,AlexNet[3]由Krizhevsky 等人提出,隨后,在卷積神經(jīng)網(wǎng)絡(luò)框架的不斷改進和創(chuàng)新下,VGG[4]以及ResNet[5]網(wǎng)絡(luò)等優(yōu)秀網(wǎng)絡(luò)框架先后被提出,為深度學(xué)習(xí)方法在圖像檢測識別的應(yīng)用奠定了堅實的基礎(chǔ)。
車輛目標(biāo)檢測深度學(xué)習(xí)算法被分為兩類:分別是基于two stage 方法和基于one stage 方法。基于two stage的車輛檢測方法分為兩步進行,第一步使用某種圖像分割算法提出候選區(qū)域,第二步再將這些候選區(qū)域進一步進行分類以及位置校準(zhǔn)得到最終的檢測結(jié)果。2014年,Girshick 等人提出了 R-CNN 算法[6],到 2015年提出的空間金字塔池化結(jié)構(gòu)(Spatial Pyramid Pooling,SPP)[7],再到Girshick 等人提出的 Fast R-CNN 算法[8],最后到Ren 等人提出的Faster R-CNN 算法[9],這是基于two stage 的最優(yōu)秀的經(jīng)典算法,但由于網(wǎng)絡(luò)深度過深,對小目標(biāo)的特征提取較差。隨后,基于one stage 方法的車輛檢測方法出現(xiàn),雖然網(wǎng)絡(luò)框架更簡易,但其用檢測精度換取了檢測速度的提升,同樣由于網(wǎng)絡(luò)深度較高,對底層的空間特征表達較差,所以對小目標(biāo)車輛檢測性較差。
faster R-CNN 雖然是基于two stage 的目標(biāo)檢測方法,但它的特征網(wǎng)絡(luò)主要都是共享的,并且網(wǎng)絡(luò)是端到端,檢測速度可以應(yīng)用到實際,所以我們選擇了基于two stage 的優(yōu)秀經(jīng)典算法faster R-CNN 作本文框架的基礎(chǔ),提出反卷積反向特征融合faster R-CNN 算法,首先對faster R-CNN 算法的特征提取網(wǎng)絡(luò)進行改進,選用在網(wǎng)絡(luò)深度和網(wǎng)絡(luò)性能均表現(xiàn)良好的ResNet-101 網(wǎng)絡(luò)替換原VGG 網(wǎng)絡(luò),提取出表達性能更豐富的特征,且結(jié)合FPN 網(wǎng)絡(luò)特點提出反卷積反向特征融合結(jié)構(gòu),將特征提取網(wǎng)絡(luò)的各層次的提取結(jié)果進行自上向下和自左向右的特征融合,提高了遠距離小目標(biāo)這種對分辨率要求較高的低層特征信息的特征提取和表達能力,提高網(wǎng)絡(luò)對不同場景下檢測的精確度,特別是對小目標(biāo)的精確度;最后,將網(wǎng)絡(luò)中的ReLU 激活函數(shù)改進為Mish 激活函數(shù),用整個區(qū)域的光滑曲線解決ReLU 函數(shù)會丟失一部分信息的問題,以整體提高網(wǎng)絡(luò)對車輛目標(biāo)的精確度、穩(wěn)定性和魯棒性。
2 反卷積反向特征融合faster R-CNN 算法
2.1 算法整體框架
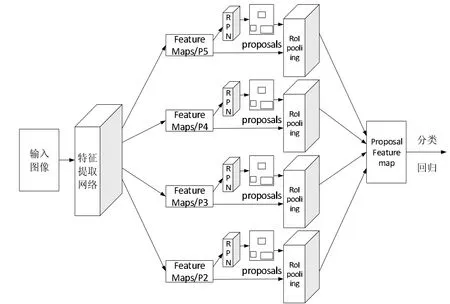
圖1 本文算法整體框架
本文為了提高遠距離小目標(biāo)的檢測效果,在faster R-CNN 算法的基礎(chǔ)上,對特征提取網(wǎng)絡(luò)進行改進,并將網(wǎng)絡(luò)中的ReLU 激活函數(shù)改進為Mish 激活函數(shù),構(gòu)成了如圖1 所示的本文算法整體框架。本文算法分為四個階段:(1)輸入圖片經(jīng)過特征提取網(wǎng)絡(luò)得到四個多尺度融合后的feature maps;(2)分別經(jīng)過RPN 網(wǎng)絡(luò)生成不同大小和比例的候選區(qū)域;(3)分別經(jīng)過RoI pooling 層對候選區(qū)域和經(jīng)過特征提取網(wǎng)絡(luò)的共享特征圖進行處理,并融合后輸出大小統(tǒng)一的特征圖(proposal feature map);(4)對proposal feature map 經(jīng)過softmax 分類得到具體類別,經(jīng)過邊框回歸修正物體的精確位置。
2.2 特征提取網(wǎng)絡(luò)
對faster R-CNN 算法的特征提取網(wǎng)絡(luò)進行改進,選用ResNet-101 網(wǎng)絡(luò)和提出的反卷積反向特征融合結(jié)構(gòu)相結(jié)合,提高了遠距離小目標(biāo)這種對分辨率要求較高的信息的特征提取和表達能力。
2.2.1 ResNet-101 網(wǎng)絡(luò)
選用在網(wǎng)絡(luò)深度和網(wǎng)絡(luò)性能均表現(xiàn)良好的ResNet網(wǎng)絡(luò)替換原先的VGG 網(wǎng)絡(luò),使用了殘差模塊,不僅減輕了深層網(wǎng)絡(luò)的訓(xùn)練難度,而且有效的改善了網(wǎng)絡(luò)的梯度消失或梯度爆炸問題。本文選用的是ResNet-101 網(wǎng)絡(luò)結(jié)構(gòu),分為5 個卷積塊,第一個卷積塊是由一個7*7 大小、通道數(shù)為64、步長為2 的卷積核構(gòu)成,第二個卷積塊中由一個3*3、步長為2 的最大池化層,和3 個如圖1 所示的殘差塊級聯(lián),輸出通道數(shù)為256,第三個卷積塊由四個殘差塊級聯(lián),輸出通道數(shù)為512,第四個卷積塊由23 個卷積塊級聯(lián),輸出通道數(shù)為1024,第五個卷積塊由3 個卷積塊級聯(lián),輸出通道數(shù)為2048,最后加上一個全連接層,共101 層網(wǎng)絡(luò)(101 層中不包含激活函數(shù)層和池化層)。
2.2.2 反卷積反向連接融合結(jié)構(gòu)
針對提高遠距離小目標(biāo)車輛這種小分辨率的信息的特征提取和特征表達,并且本文網(wǎng)絡(luò)層次較深,直接對深層次提取到的特征進行處理,會因為特征中淺層特征圖語義信息較少,而影響網(wǎng)絡(luò)檢測的精確度。并且參考到FPN 的特點,即對網(wǎng)絡(luò)中淺層和深層特征圖包含信息的再利用,因為淺層特征圖語義信息較少,但包含空間位置信息較為豐富。使用淺層特征能夠使分析出小目標(biāo)車輛的位置信息更加準(zhǔn)確,而深層特征圖中提取到的特征語義信息相對豐富,在識別分類上能夠有更佳的表現(xiàn)。所以,在FPN 的基礎(chǔ)上,修改上采樣為反卷積,提出反卷積反向連接融合結(jié)構(gòu)。通過反向連接和橫向連接將深層特征圖的語義信息有效地與淺層特征相結(jié)合,使得融合后的特征圖具有準(zhǔn)確預(yù)測遠距離小目標(biāo)的能力。本文特征提取網(wǎng)絡(luò)中的反卷積反向特征融合結(jié)構(gòu)如圖2 所示:
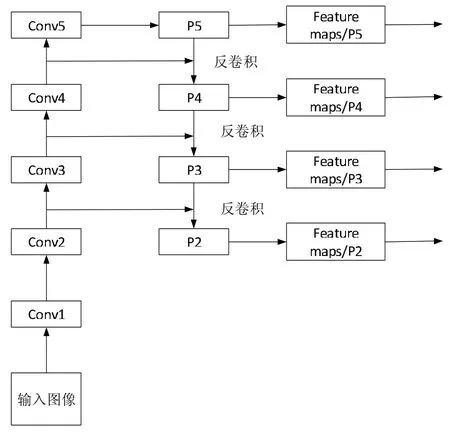
圖2 反卷積反向特征融合結(jié)構(gòu)
輸入圖像經(jīng)過自下向上的路徑進行卷積塊的處理,得到五個層次的特征映射,由于深一層的卷積塊輸出的特征映射尺寸比淺一層的小一倍,所以基于FPN 中自頂向下的中的下一層輸入應(yīng)經(jīng)過上一層的2 倍上采樣得到與左側(cè)路徑平級的特征映射尺寸,然后再進行融合;但由于上采樣僅僅是對低分辨率特征圖的一個簡單的擴充,對特征的逆向的表達性能與左側(cè)提取到的特征聯(lián)系性較差,會丟失一些信息,所以提出用反卷積替換上采樣,因為反卷積是卷積的一個逆過程,對信息的丟失會大大減少;最后,經(jīng)融合后的特征層P2、P3、P4、P5 分別經(jīng)過RPN 層和 RoI pooling 層,在 proposal feature map 上進行合并。
反卷積將特征圖不僅達到放大一倍的效果,還使經(jīng)過融合的特征保持與融合前的特征的緊密聯(lián)系,提高整個特征提取網(wǎng)絡(luò)多尺度的特征表達。由于經(jīng)過反卷積后的特征圖大小為原來的2 倍,所以padding 的計算公式如式1 所示:

其中 p 為 padding,o 為反卷積后的特征圖大小,k 為卷積核大小,s 為步長。
2.3 Mish 激活函數(shù)
針對ReLU 激活函數(shù)的硬零邊界和過于簡易的非線性處理的問題,選用Mish 激活函數(shù)來替代,兩種函數(shù)的數(shù)學(xué)公式如式2 和式3 所示:
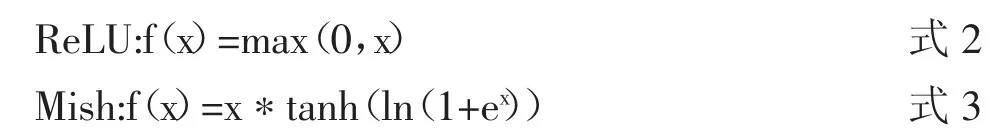
Mish 激活函數(shù)在負值區(qū)域有輕微的允許,并在整個區(qū)域的梯度都是光滑的,不會像ReLU 激活函數(shù)那樣,丟失掉一部分信息,并且Mish 激活函數(shù)在深層次網(wǎng)絡(luò)中準(zhǔn)確性和穩(wěn)定性更好,且提高了網(wǎng)絡(luò)的泛化能力。
3 實驗結(jié)果與分析
3.1 實驗環(huán)境與參數(shù)設(shè)置
實驗環(huán)境:操作系統(tǒng)為Windows 10,CPU 為英特爾Core i5-7300HQ @ 2.50GHz 四核,GPU 為 NVIDIA GeFo rce GTX 1050,顯存4 GB,深度學(xué)習(xí)框架為Tensorflow 框架。在訓(xùn)練階段,初始learning_rate 設(shè)為0.001,momentum設(shè)為 0.9,weight_decay 設(shè)為 0.0005,batch_size 設(shè)為 32,max_iters 設(shè)為 10000。
3.2 實驗數(shù)據(jù)集
由于大型公開數(shù)據(jù)集(如VOC 數(shù)據(jù)集等)中目標(biāo)檢測的種類過多,包含車輛圖片較少,對網(wǎng)絡(luò)訓(xùn)練效果較差,所以,需要通過制作更加豐富的數(shù)據(jù)集來訓(xùn)練目標(biāo)檢測網(wǎng)絡(luò)的參數(shù),并提高網(wǎng)絡(luò)對車輛目標(biāo)檢測的專業(yè)性。本文制作小目標(biāo)車輛圖像庫的步驟如下:
(1)搜集來自西安市多處天橋上拍攝的車輛圖片和大型公開數(shù)據(jù)集UA-DETRAC(主要拍攝于北京和天津的道路過街天橋,并已進行了手動標(biāo)注)的部分圖片,共4196張圖片,包含白天、夜晚、稀疏、密集等綜合場景以達到豐富圖像庫場景的目的,并且緊密貼合交通道路實際情況,小目標(biāo)車輛圖像庫部分示例如圖 3 中(a)、(b)、(c)、(d)所示。
(2)將所有圖片均通過labelImg 標(biāo)注工具進行手工標(biāo)注,標(biāo)注效果圖部分示例如圖4 所示,包含不同尺寸的目標(biāo),生成標(biāo)注文件。
(3)將圖像庫按8:1:1 比例分為訓(xùn)練集、驗證集和測試集,建立了VOC 格式的數(shù)據(jù)集,以備進行小目標(biāo)車輛檢測實驗。
3.3 評價指標(biāo)
在道路交通背景下,車輛目標(biāo)檢測結(jié)果的精確位置起著至關(guān)重要的作用,并且本文目標(biāo)檢測是二分類的問題,所以,本文使用AP(Average Precision)來衡量網(wǎng)絡(luò)對于車輛目標(biāo)檢測的性能。AP 值是由查準(zhǔn)率Precision 和召回率Recall 在不同閾值下構(gòu)成的P(R)曲線下的面積經(jīng)過插值求解計算得到的,數(shù)學(xué)公式如式4 所示:

圖3 小目標(biāo)車輛圖像庫部分示例

圖4 標(biāo)注效果圖部分實例
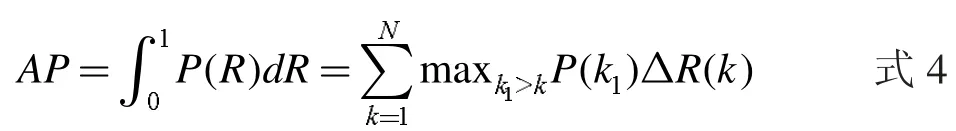
maxk1≥kP(k1)表示對于某個召回率 R,所有召回率不小于R 中的查準(zhǔn)率最大值,ΔR(k)表示召回率的變化值。
查準(zhǔn)率和召回率的計算公式如式5 和式6 所示,TP為測試集中正確識別車輛的檢測框個數(shù),F(xiàn)P 為測試集中錯誤識別車輛的檢測框個數(shù),F(xiàn)N 為測試集中未識別出車輛的標(biāo)注框個數(shù),且TP 與FN 之和為所有標(biāo)注框的個數(shù)。

3.4 實驗結(jié)果及分析
利用上述實驗數(shù)據(jù)集分別對已經(jīng)經(jīng)過ImageNet 圖像庫預(yù)訓(xùn)練的faster R-CNN、YOLOv3 和本文提出的改進算法模型進行訓(xùn)練和測試。faster R-CNN 是在two-stage 目標(biāo)檢測方法中具有代表性的經(jīng)典算法,在精度和檢測速度均達到了實際應(yīng)用的標(biāo)準(zhǔn),YOLOv3 是在one stage 目標(biāo)檢測算法中的具有代表性經(jīng)典算法,所以,本文對在faster R-CNN 基礎(chǔ)上提出的反卷積反向特征融合faster R-CNN、faster R-CNN 和 YOLOv3 在測試集上進行對比實驗,對比三種算法在綜合場景下對不同大小目標(biāo)車輛的檢測精度;本文借鑒了MS COCO 數(shù)據(jù)集,對大目標(biāo)、中等目標(biāo)、小目標(biāo)的范圍進行了定義,如表1 所示:
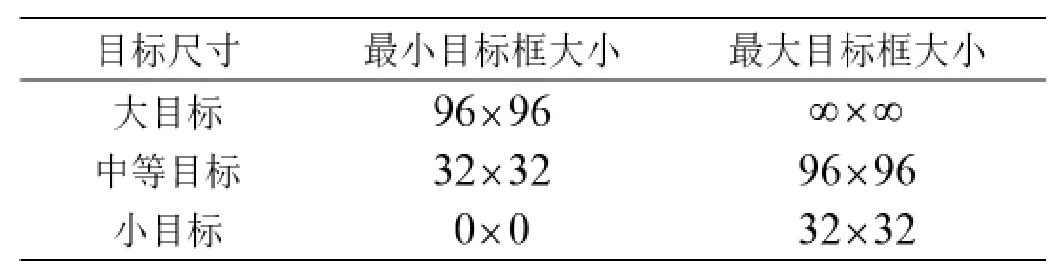
表1 目標(biāo)大小區(qū)分定義
圖5 所示為faster R-CNN、YOLOv3 和本文算法的車輛檢測效果對比。

圖5 三種算法的車輛檢測效果
圖5(a)所示為faster R-CNN 檢測效果圖,可看出雖然在精確度上已經(jīng)達到了一定的標(biāo)準(zhǔn),但會對小目標(biāo)車輛出現(xiàn)漏檢的情況,并且明顯能觀察出越小的目標(biāo)車輛檢測效果越差;圖5(b)所示為YOLOv3 檢測效果圖,YOLOv3算法中結(jié)合了多尺度融合預(yù)測,可以觀察到小目標(biāo)車輛檢測效果有所提升,并具有一定的檢測精度,但相對于faster R-CNN,對大分辨率目標(biāo)的精確位置檢測稍差;圖5(c)所示為本文提出的反卷積反向特征融合faster RCNN 算法的檢測效果,可看出不僅能保證大分辨率目標(biāo)的檢測精度,并且經(jīng)過特征提取網(wǎng)絡(luò)和激活函數(shù)層的改進,提高了小分辨率目標(biāo)的特征提取效果。
三種算法在測試集上的檢測結(jié)果如表2 所示。
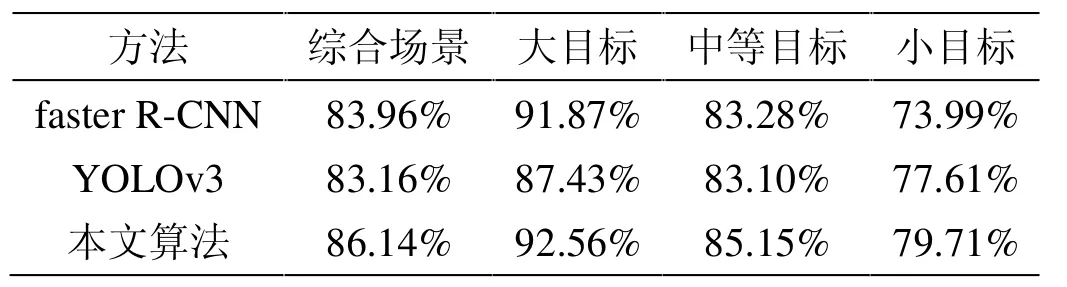
表2 三種算法在測試集上的檢測結(jié)果
由表2 可以對比出,本文算法在綜合場景下的AP值均高于 faster R-CNN 和 YOLOv3,且 faster R-CNN 的AP 值高于YOLOv3;在目標(biāo)尺寸方面,雖然faster RCNN 對大目標(biāo)和中等目標(biāo)的檢測精度優(yōu)于YOLOv3,但YOLOv3 對小目標(biāo)的檢測精度優(yōu)于faster R-CNN,然而,本文算法在三個尺寸目標(biāo)的檢測精度都高于另外兩種算法;本文算法針對小目標(biāo)車輛檢測比faster R-CNN、YOLOv3 分別提高了5.72%、2.10%;綜合場景下本文算法的 AP 值比 faster R-CNN、YOLOv3 分別提高了2.18%、2.98%。
4 結(jié)論
本文提出了反卷積反向特征融合faster R-CNN 算法,與faster R-CNN 和YOLOv3 算法相比,選用ResNet-101 網(wǎng)絡(luò)和提出的反卷積反向特征融合結(jié)構(gòu)相結(jié)合,來改進faster R-CNN 算法的特征提取網(wǎng)絡(luò),提高了遠距離小目標(biāo)這種對分辨率要求較高的低層信息的特征提取和表達能力;其次,利用Mish 激活函數(shù)替換網(wǎng)絡(luò)中的ReLU激活函數(shù),提高整體網(wǎng)絡(luò)的精確度、穩(wěn)定性和魯棒性;通過實驗驗證,本文算法在綜合場景下的檢測精度均有不同程度的提高,尤其是對小目標(biāo)的車輛檢測效果提升更突出。在未來的工作中,應(yīng)該提高小目標(biāo)車輛檢測網(wǎng)絡(luò)在光照和遮擋等情況下的泛化能力。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學(xué)工程學(xué)報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
