面向OPAC的非個(gè)性化圖書推薦算法
2021-02-04 07:50:27鄒鼎杰方世敏
現(xiàn)代情報(bào) 2021年2期
關(guān)鍵詞:高校圖書館
鄒鼎杰 方世敏
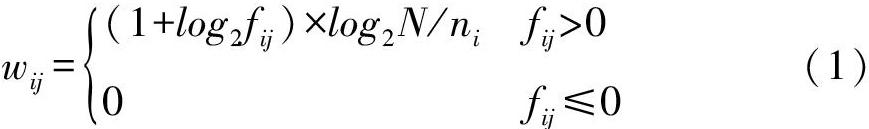
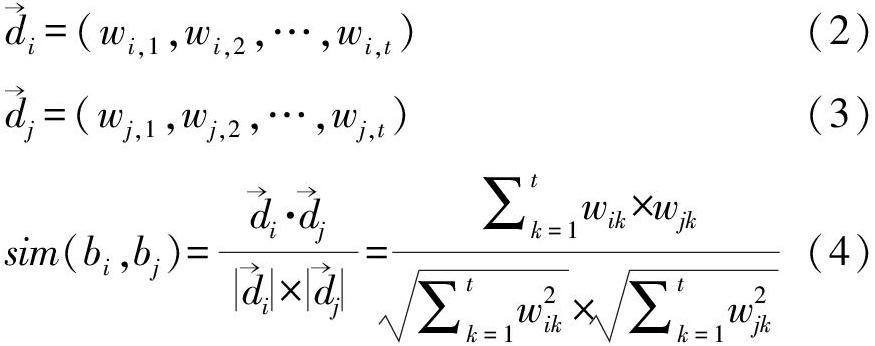
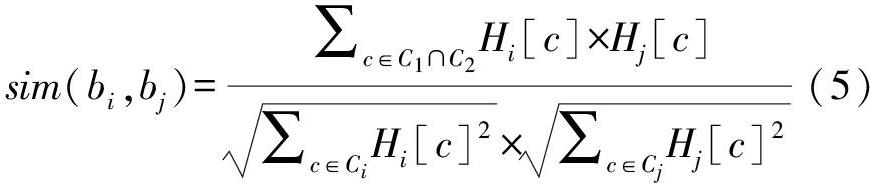
摘?要:[目的/意義]OPAC書目檢索系統(tǒng)用戶處于非登錄狀態(tài),系統(tǒng)無(wú)法獲取用戶個(gè)人信息,個(gè)性化推薦算法難以發(fā)揮作用,有必要探索非個(gè)性化推薦算法。[方法/過(guò)程]首先提出基于圖書語(yǔ)義相似度的圖書推薦算法,通過(guò)構(gòu)建向量空間模型計(jì)算圖書語(yǔ)義相似度,向讀者推薦與當(dāng)前瀏覽圖書相似的圖書;然后提出基于共借關(guān)系的圖書推薦算法,向讀者推薦借閱了當(dāng)前瀏覽圖書的讀者還借閱過(guò)的其他圖書;最后討論了兩種算法的融合策略。[結(jié)果/結(jié)論]選取10本圖書作為推薦窗口,在復(fù)旦大學(xué)圖書館真實(shí)借閱數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),推薦成功率為20%。每5名讀者中有1名讀者能在推薦列表中發(fā)現(xiàn)自己后續(xù)會(huì)借閱的圖書。
關(guān)鍵詞:OPAC;圖書推薦;非個(gè)性化推薦;高校圖書館;復(fù)旦大學(xué)
DOI:10.3969/j.issn.1008-0821.2021.02.013
〔中圖分類號(hào)〕G251?〔文獻(xiàn)標(biāo)識(shí)碼〕A?〔文章編號(hào)〕1008-0821(2021)02-0125-07
Abstract:[Purpose/Significance]Non-personalized Book Recommendation Algorithm is necessary for OPAC book retrieval system,because users are always in the state of logging out.It is impossible to access user information,without which personalized recommendation algorithm cannot work efficiently.[Method/Process]Firstly,book recommendation algorithm based on semantic similarity was designed with vector space model recommending books similar to book browsing.Secondly,algorithm based on relation of same readers was introduced,which recommended books borrowed by readers who also borrowed the book that the user was browsing.Lastly,methods to merge two algorithm were discussed.[Results/Conclusion]With ten recommending books,the result of experiment on Fudan University library's book borrowed datasets showed that success rate of algorithm was 20%,such that one in five readers could find at least one books that he would borrow in recommending book list.
Key words:OPAC;book algorithm;non-personalized book recommendation;university library
高等學(xué)校圖書館是學(xué)校的文獻(xiàn)信息資源中心,主要任務(wù)是建設(shè)全校的文獻(xiàn)信息資源體系和建立健全全校的文獻(xiàn)信息服務(wù)體系[1]。據(jù)教育部高等學(xué)校圖書情報(bào)工作指導(dǎo)委員會(huì)統(tǒng)計(jì)[2],我國(guó)高校圖書館館均紙質(zhì)文獻(xiàn)資源購(gòu)置費(fèi)為每年200余萬(wàn)元,中山大學(xué)圖書館等高校每年采購(gòu)紙質(zhì)圖書的經(jīng)費(fèi)高達(dá)1億元。根據(jù)各高校圖書館官網(wǎng)介紹,中山大學(xué)圖書館紙質(zhì)館藏總量達(dá)685.14萬(wàn)冊(cè),復(fù)旦大學(xué)圖書館收藏紙本、報(bào)紙合訂本資源約546.4萬(wàn)冊(cè),浙江大學(xué)圖書館實(shí)體館藏總量達(dá)655.8萬(wàn)冊(cè)。面對(duì)海量的館藏圖書,如何讓讀者發(fā)現(xiàn)并利用這些圖書,讓“每本書有其讀者”是圖書館在建設(shè)學(xué)校文獻(xiàn)信息服務(wù)體系的時(shí)候需要考慮的關(guān)鍵問(wèn)題。
OPAC(Online Public Access Catalogue,聯(lián)機(jī)公共檢索目錄)是圖書與讀者之間的橋梁。對(duì)于采取閉架借閱制度的書庫(kù),OPAC系統(tǒng)是圖書與讀者之間的唯一橋梁。OPAC系統(tǒng)的主要職能是書目檢索,讀者在明確自己所需圖書主題或者知道所需圖書標(biāo)題、作者、出版社等檢索點(diǎn)時(shí),通過(guò)輸入檢索表達(dá)式查閱圖書。檢索只能滿足讀者顯性的、意識(shí)到的、能夠用檢索式表達(dá)的圖書需求,無(wú)法滿足讀者隱性的、潛在的、尚未用檢索式表達(dá)的圖書需求。大量所需圖書因?yàn)闊o(wú)法出現(xiàn)在檢索結(jié)果中不被讀者知曉,無(wú)法發(fā)揮應(yīng)用作用。圖書推薦可以根據(jù)讀者的檢索、瀏覽等行為數(shù)據(jù)以及圖書館的圖書借閱數(shù)據(jù)“猜測(cè)”讀者可能需要的圖書,彌補(bǔ)檢索帶來(lái)的不足。
1?相關(guān)研究評(píng)述
根據(jù)推薦書目是針對(duì)1位讀者還是多位讀者,圖書推薦分為個(gè)性化圖書推薦和非個(gè)性化圖書推薦。個(gè)性化圖書推薦根據(jù)讀者借閱歷史等個(gè)人信息生成書單,不同讀者收到的推薦書單并不相同,能夠做到“千人千面”。非個(gè)性化推薦通常面向特定用戶群體提供一份相同的書單。
非個(gè)性化圖書推薦由來(lái)已久。《論語(yǔ)》中就有孔子向弟子推薦《詩(shī)經(jīng)》的記載[3]。梁?jiǎn)⒊帯段鲗W(xué)書目表》,向公眾推薦300余種圖書,影響廣泛。這種依托領(lǐng)域?qū)<一蛘邎D書館館員生成的閱讀書單至今仍然是重要的圖書推薦手段,一般稱作書目推薦[4]。除了依靠人工推薦圖書,依托計(jì)算機(jī)技術(shù)生成書單也逐漸受到關(guān)注。黎邦群[5]受到信息檢索中查詢推薦的啟發(fā),提出了基于檢索行為的非個(gè)性化圖書推薦算法,認(rèn)為通過(guò)用戶的檢索歷史記錄可以提供更有效的圖書推薦,是非個(gè)性化圖書推薦算法的一次不錯(cuò)嘗試。明均仁等[6]提出一種推薦書目自動(dòng)生成方法,通過(guò)收集豆瓣讀書、京東圖書、卓越亞馬遜等網(wǎng)站的書評(píng)數(shù)據(jù),經(jīng)過(guò)數(shù)據(jù)預(yù)處理、資源整合、書單生成、人工篩選等步驟自動(dòng)生成書單,使推薦書目更加高效且擁有群體智慧。劉麗帆等[7]從形式、效用、內(nèi)容等維度提出了一種高校圖書熱門TOP圖書的評(píng)價(jià)模型,用于向讀者提供一份熱門TOP書單。在非圖書領(lǐng)域,崔春生等[8]提出了一種基于Vague值的非個(gè)性化產(chǎn)品推薦策略,Chakraborty A等[9]針對(duì)紐約時(shí)報(bào)、CNN等新聞網(wǎng)站用戶處于非登錄狀態(tài)問(wèn)題,圍繞時(shí)效性、新穎性和多樣性3個(gè)目標(biāo)提出了新聞的非個(gè)性化推薦方法。相對(duì)于個(gè)性化推薦,依托計(jì)算機(jī)技術(shù)生成書單的非個(gè)性化推薦理論研究比較稀缺,缺乏對(duì)圖書館中的借閱數(shù)據(jù)和圖書的著錄數(shù)據(jù)的挖掘和利用。實(shí)踐層面,圖書館OPAC系統(tǒng)的非個(gè)性化推薦卻比較普遍。李民等[10]通過(guò)訪問(wèn)國(guó)內(nèi)116所“211工程”院校的圖書館網(wǎng)站,發(fā)現(xiàn)100%的圖書館都提供非個(gè)性化推薦服務(wù),主要有新書通告、熱門檢索、熱門借閱、借閱排行等,這些推薦通常以一個(gè)簡(jiǎn)單頁(yè)面將全部信息呈現(xiàn)給所有用戶,不夠靈活、缺乏智能。郭婧婧等[11]發(fā)現(xiàn)城市圖書館推薦系統(tǒng)的非個(gè)性化推薦主要有兩類:一類是基于統(tǒng)計(jì)分析的推薦方法,如借閱排行、熱門檢索、熱門借閱;另一類是基于手工的推薦方法,比如新生推薦、特色館藏推薦等;但均存在智能化程度不高的問(wèn)題,與李民等[10]的調(diào)查結(jié)果相一致。
實(shí)際上,個(gè)性化圖書推薦的智能化程度更高,也是當(dāng)前研究熱點(diǎn)。只是個(gè)性化推薦算法要求用戶處于“登錄”狀態(tài)以獲取用戶的借閱歷史、性別、年級(jí)等個(gè)人信息,而OPAC系統(tǒng)用戶通常處于“游客”狀態(tài),個(gè)人信息難以被系統(tǒng)獲取,個(gè)性化推薦算法難以發(fā)揮作用。個(gè)性化推薦算法雖然無(wú)法直接用于非個(gè)性化推薦,但是其中的思想可以指導(dǎo)非個(gè)性化算法的設(shè)計(jì)。本文通過(guò)對(duì)個(gè)性化推薦算法的改進(jìn),提出了用戶非登錄狀態(tài)下的非個(gè)性化推薦算法。
2?算法設(shè)計(jì)
圖書推薦算法的目的是從大量圖書中過(guò)濾掉用戶不需要的圖書,篩選出用戶需要的圖書。如果不引入額外信息、根據(jù)等可能假設(shè),用戶對(duì)每本圖書的需要程度是相同的,在海量圖書中發(fā)現(xiàn)用戶所需圖書的概率是1/N,其中N為圖書總數(shù)量,通常在幾十萬(wàn)至幾百萬(wàn)不等,這是一個(gè)很小的概率。推薦算法通過(guò)引入額外信息消除不確定性,增加用戶所需圖書被推薦的概率。引入的額外信息包括以下3種:①圖書的內(nèi)容特征,包括標(biāo)題、作者、出版社、主題詞、分類號(hào)等,這些特征是讀者選取圖書的依據(jù);②圖書借閱歷史,即所有讀者在過(guò)去借閱圖書的歷史記錄。借閱歷史是協(xié)同過(guò)濾圖書推薦算法依賴的信息,該算法認(rèn)為擁有相似借閱偏好的讀者在未來(lái)也將借閱相似圖書,以此作為圖書推薦依據(jù);③待推薦讀者的個(gè)人信息,既包括讀者的年級(jí)、專業(yè)等屬性信息,也包括讀者借閱圖書的歷史記錄。在非個(gè)性化推薦算法中,系統(tǒng)無(wú)法獲取第3種信息,但依然能獲取第1和第2兩種信息。利用第1種信息發(fā)現(xiàn)讀者所需圖書的算法通常稱作基于內(nèi)容的推薦算法,本文將其稱作基于語(yǔ)義相似度的推薦算法,該算法向讀者推薦與當(dāng)前瀏覽圖書語(yǔ)義上最相近的k本圖書。利用第2種信息的推薦算法通常稱作協(xié)同過(guò)濾算法,本文將其稱作基于共借關(guān)系的推薦算法,該算法向讀者推薦借閱了當(dāng)前瀏覽圖書的讀者都還借閱了其他k本圖書。
2.1?基于語(yǔ)義相似度的非個(gè)性化推薦
語(yǔ)義是指文字載體承載的意義,意義是人們對(duì)世界的認(rèn)識(shí)。意義通常在表達(dá)時(shí)賦予,在閱讀時(shí)理解。算法可以在特定維度上“理解”文字載體上的意義,典型的做法有自上而下地構(gòu)建本體和自下而上地提取特征兩種。前者對(duì)領(lǐng)域?qū)<业囊蕾嚦潭容^大,后者從海量數(shù)據(jù)中提取的統(tǒng)計(jì)特征。本文采用后一種思路,利用向量模型計(jì)算圖書的語(yǔ)義相似度。
計(jì)算語(yǔ)義相似度之前有兩個(gè)關(guān)鍵步驟:特征詞的選取和特征詞權(quán)重的確定。OPAC系統(tǒng)中的圖書是紙質(zhì)圖書。紙質(zhì)圖書的特點(diǎn)是只有標(biāo)題、作者、出版社等屬性數(shù)據(jù)是電子化的,能夠作為特征詞的來(lái)源。紙質(zhì)圖書的內(nèi)容一般不會(huì)電子化,難以成為特征詞來(lái)源。相對(duì)于電子書、網(wǎng)頁(yè)等載體,紙質(zhì)圖書的特征詞來(lái)源稀缺。因此,紙質(zhì)圖書的特征詞提取應(yīng)當(dāng)使用細(xì)粒度的分詞技術(shù)以提升圖書召回率。選用TF-IDF作為特征詞權(quán)重,特征詞i在圖書j中的權(quán)重計(jì)算方法如式(1)所示,其中N是圖書館的館藏圖書種數(shù),ni是包含有特征詞i的圖書種數(shù),log2N/ni是反比文檔頻率(Inverse Document Frequency,IDF)的標(biāo)準(zhǔn)計(jì)算公式;fij是特征詞i在圖書j中的詞頻(Term Frequency,TF),為了與IDF值具有可比性,對(duì)頻率fij做了取以2為底的對(duì)數(shù)處理,并通過(guò)加1避免出現(xiàn)值為0的情況。沒(méi)有在圖書j中出現(xiàn)過(guò)的特征詞權(quán)值為0。
假設(shè)總共從館藏圖書中提取出t個(gè)特征詞,利用t維向量表示圖書的語(yǔ)義特征。圖書bi和bj的向量空間分別如式(2)和式(3)所示。利用向量間的余弦?jiàn)A角表示圖書之間的語(yǔ)義相似度,計(jì)算方法如式(4)所示。
圖書館藏有圖書規(guī)模較大,圖書的特征詞數(shù)量t是一個(gè)較大數(shù)值。以復(fù)旦大學(xué)圖書館5年間的借閱數(shù)據(jù)集為例,總共從數(shù)據(jù)集中提取40余萬(wàn)個(gè)特征詞;但由于紙質(zhì)圖書特征詞來(lái)源的稀疏性,一本圖書的特征詞通常不超過(guò)10個(gè)。如果直接使用向量存儲(chǔ)特征詞,空間利用率為1/40 000,利用率極低。該借閱數(shù)據(jù)集僅包含了該校圖書館不到1/10的圖書,如果要表示該館所有圖書,特征向量會(huì)更長(zhǎng),空間利用率會(huì)更低。改用哈希表分別存儲(chǔ)每本書的特征值權(quán)值將極大地節(jié)省存儲(chǔ)空間。為每本圖書創(chuàng)建一個(gè)哈希表,表的鍵是圖書包含的特征詞,表的值是對(duì)應(yīng)特征詞的權(quán)值,沒(méi)有在圖書中出現(xiàn)過(guò)的特征詞的權(quán)值為零,無(wú)需存儲(chǔ)。圖書bi與bj之間語(yǔ)義相似度計(jì)算方法如式(5)所示,式中C是圖書b的特征詞集合,H是圖書b的特征詞哈希表,H[c]是特征詞c對(duì)應(yīng)的特征權(quán)值。
為了給一本圖書尋找與其最鄰近的k本圖書,需要計(jì)算這本圖書與其余所有圖書的語(yǔ)義距離,然后根據(jù)距離排序,找出排名前k的圖書。算法為每本圖書尋找與其最鄰近的k本圖書。如果圖書館有N本圖書,需要進(jìn)行C2N次距離計(jì)算,計(jì)算時(shí)間復(fù)雜度為O(N2)。高校圖書館藏有圖書規(guī)模較大,難以接受該計(jì)算復(fù)雜度。以擁有100萬(wàn)藏書的圖書館為例,需要進(jìn)行1 000億次距離計(jì)算。即便每次距離計(jì)算耗時(shí)為1微秒,所需耗時(shí)將達(dá)11天。大多數(shù)高校圖書館藏書都在100萬(wàn)以上。好消息是圖書館中絕大多數(shù)圖書之間的語(yǔ)義相似度是0,即圖書bi的特征詞集合Ci與圖書bj的特征詞集合Cj的交集為空,Ci∩Cj=。利用索引技術(shù)找出與圖書b距離非0的所有圖書集合Cb,在Cb中尋找與圖書bi最鄰近的k本書。由于Cb的規(guī)模遠(yuǎn)小于整個(gè)圖書館的圖書數(shù)量,因此可以極大地降低計(jì)算復(fù)雜度,使基于語(yǔ)義相似度的非個(gè)性化推薦算法變得可行。使用哈希表MAP表示該索引,其中的鍵是特征詞c,對(duì)應(yīng)的哈希值MAP[c]是包含有該特征詞的所有圖書集合B。圖1是在哈希表中查找與圖書b距離非零圖書集合Cb的算法。關(guān)鍵步驟為(1)~(3),不斷根據(jù)特征詞查找包含有該詞的圖書并添加到集合Cb。圖書b自身也會(huì)被查詢并添加到集合Cb中,因此需要在步驟(4)將b從Cb中移除。
搜索到與待推薦圖書b距離非零的圖書集合Cb后,根據(jù)式(5)計(jì)算圖書b與Cb中每一本圖書的距離,排序后取相似度最高的前k本圖書,即為向用戶推薦的圖書。基于語(yǔ)義相似度的非個(gè)性化推薦算法可以視作一種查詢擴(kuò)展技術(shù),即通過(guò)讀者對(duì)圖書的點(diǎn)擊信息幫助讀者重構(gòu)查詢式,并將查詢排名前k的圖書展現(xiàn)給讀者。該思想與文獻(xiàn)[5]有相似之處。
2.2?基于共借關(guān)系的非個(gè)性化推薦
共借關(guān)系是指圖書bi與bj共同被若干名讀者借閱的關(guān)系,這兩本書或許在語(yǔ)義上有較高的相似度,也有可能在語(yǔ)義上體現(xiàn)不出相似度,是由于其他因素被共同借閱。基于共借關(guān)系的推薦算法被認(rèn)為比基于語(yǔ)義的推薦算法更能幫助讀者發(fā)現(xiàn)新穎圖書。協(xié)同過(guò)濾算法利用圖書之間的共借關(guān)系向讀者推薦圖書,這種推薦算法無(wú)法直接應(yīng)用于非個(gè)性化推薦,需要做相應(yīng)改進(jìn)。
在協(xié)同過(guò)濾算法中,計(jì)算兩本圖書鄰近關(guān)系的方法主要有余弦相似度和皮爾遜相似度,這兩種相似度計(jì)算方法無(wú)法直接適用于共借讀者人數(shù)較少的情況。由于兩種計(jì)算方法原理類似,以余弦相似度為例說(shuō)明。余弦相似度的計(jì)算方法如式(6)所示,Ri是圖書bi的讀者集合,Rj是圖書bj的讀者集合,daysrb是用戶r借閱圖書b的天數(shù)。如果兩本圖書只有1名讀者借閱,這兩本圖書的余弦相似度為1,即最大值;如果兩本圖書本有兩名讀者借閱,僅當(dāng)這兩名讀者的借閱天數(shù)相等時(shí),余弦相似度才等于1,否則余弦相似度將小于1。也就是說(shuō),兩本圖書共被借閱的人數(shù)為1時(shí),它們之間的相似度最大;隨著這兩本圖書共借人數(shù)的增加,這兩本圖書的相似度會(huì)逐漸下降。該算法不符合常識(shí)。實(shí)際上,余弦相似度和皮爾遜相似度僅在圖書的共借人數(shù)較多且相等時(shí)有比較價(jià)值。決定圖書之間共借相似度的首要因素是共借讀者人數(shù)n。因此將圖書共借關(guān)系強(qiáng)度定義為式(7),即共借人數(shù)與余弦相似度之和。共借人數(shù)是整數(shù),余弦相似度的值域區(qū)間為(0,1]。從數(shù)值上比較圖書之間共借關(guān)系強(qiáng)度時(shí),共借讀者人數(shù)是首要因素,余弦相似度是次因素。
基于共借關(guān)系的推薦算法與基于語(yǔ)義相似度的推薦算法面臨類似問(wèn)題——需要計(jì)算每本圖書之間的距離,由此帶來(lái)的時(shí)間復(fù)雜度已經(jīng)在上一節(jié)中論述,在此不再贅述。類似地,圖書館中擁有共借關(guān)系的圖書并不多,因此可以直接提取擁有共借關(guān)系的圖書而忽略沒(méi)有共借關(guān)系的圖書。高校圖書館的讀者借閱記錄通常保存在數(shù)據(jù)庫(kù)中,可以利用數(shù)據(jù)庫(kù)的連接查詢技術(shù)快速獲取擁有共借關(guān)系的圖書。在查詢到與圖書b具有共借關(guān)系的圖書集合以后,根據(jù)式(7)計(jì)算圖書之間的共借關(guān)系距離,排序后取前k本圖書推薦給讀者。
2.3?融合語(yǔ)義相似度和共借關(guān)系的非個(gè)性化推薦
基于語(yǔ)義相似度的推薦算法與基于共借關(guān)系的推薦算法有各自的優(yōu)勢(shì),也有各自的劣勢(shì)。基于語(yǔ)義相似度的推薦算法通常向用戶推薦主題相近的圖書,這些圖書或者在標(biāo)題上具有某種相似度,或者來(lái)自同一作者,或者來(lái)自同一出版社,或者兼而有之。對(duì)于正在進(jìn)行主題閱讀的讀者,語(yǔ)義推薦算法能夠給他們帶來(lái)較大幫助,因?yàn)橥扑]算法能夠滿足他們發(fā)現(xiàn)同一主題下大量圖書的需求。語(yǔ)義推薦算法的弊端也很明顯,這些主題相近的圖書通常在相鄰排架甚至同一排架,即便沒(méi)有推薦系統(tǒng),讀者也可以在排架上方便地找到這些圖書。基于共借關(guān)系的推薦算法是在向讀者回答“讀過(guò)這本書的人還讀過(guò)哪些書?”,推薦的圖書在語(yǔ)義上可能相關(guān),也可能無(wú)關(guān)。基于共借關(guān)系的算法更能夠給讀者帶來(lái)新穎性,能夠幫助讀者發(fā)現(xiàn)意想不到的圖書,通常認(rèn)為基于共借關(guān)系的推薦算法優(yōu)于基于語(yǔ)義相似度的推薦算法。但是基于共借關(guān)系的算法存在一個(gè)弊端——冷啟動(dòng)問(wèn)題,對(duì)于借閱率較低的圖書,算法甚至無(wú)法找到足夠數(shù)量的推薦圖書;對(duì)于從未被借閱過(guò)的圖書,算法無(wú)法根據(jù)共借關(guān)系作出推薦。兩種算法的融合能發(fā)揮各自優(yōu)勢(shì),帶來(lái)更好的推薦效果。本文提出了平等融合和補(bǔ)充融合兩種策略,前者在把兩種推薦算法視作同等地位,后者以基于共借關(guān)系的推薦算法為主,基于語(yǔ)義相似度的推薦算法作為補(bǔ)充,解決冷啟動(dòng)問(wèn)題。
平等融合算法認(rèn)為通過(guò)語(yǔ)義關(guān)系和共借關(guān)系獲得的圖書具有同等重要的推薦價(jià)值,首選同時(shí)被兩種算法推薦的圖書,然后根據(jù)排名先后選取只被一種算法推薦的圖書。同時(shí)被兩種算法推薦的圖書根據(jù)在各自推薦列表中的排名求和后重新排名。通過(guò)例子說(shuō)明選取和排序的規(guī)則。假設(shè)推薦5本圖書,兩種算法給出的推薦圖書分別是a、b、c、d、e和g、c、e、b、f。同等融合算法首選同時(shí)出現(xiàn)在兩個(gè)列表的圖書b、c、e,這3本圖書在兩個(gè)列表的排名之和分別是6、5、8,因此排序應(yīng)當(dāng)是c、b、e。然后從余下圖書中選取排名靠前的a和g構(gòu)成5本推薦圖書。
補(bǔ)充融合算法認(rèn)為共借關(guān)系推薦的圖書最重要,語(yǔ)義算法推薦的圖書在共借算法無(wú)法發(fā)現(xiàn)足夠圖書時(shí)作為補(bǔ)充。假設(shè)推薦窗口為k本,如果共借算法能夠發(fā)現(xiàn)k本以上圖書,則使用該算法發(fā)現(xiàn)的前k本圖書;如果共借算法只發(fā)現(xiàn)j(j 3?實(shí)驗(yàn)結(jié)果及其分析 評(píng)估推薦算法的常用方法有離線評(píng)估、用戶調(diào)查和在線評(píng)估,本研究根據(jù)實(shí)際情況選擇了復(fù)旦大學(xué)圖書館的真實(shí)外借數(shù)據(jù)集進(jìn)行離線評(píng)估。 3.1?數(shù)據(jù)集 測(cè)試數(shù)據(jù)為復(fù)旦大學(xué)圖書館在2013—2017年間的所有圖書借閱記錄,該數(shù)據(jù)集由2019年首屆“慧源共享”上海高校開(kāi)放數(shù)據(jù)創(chuàng)新研究大賽主辦方提供,包含有該高校5萬(wàn)余名讀者在2013—2017年間對(duì)大約40萬(wàn)種圖書的160余萬(wàn)條借閱記錄。由于高等院校的教學(xué)活動(dòng)以學(xué)年為單位進(jìn)行,為了更接近高校圖書館圖書推薦的真實(shí)情況,將數(shù)據(jù)集分為2013—2014年、2014—2015年、2015—2016年和2016—2017年4個(gè)學(xué)年,以前3個(gè)學(xué)年的借閱數(shù)據(jù)作為基于共借關(guān)系的非個(gè)性化推薦算法的訓(xùn)練集,以2016—2017學(xué)年的借閱數(shù)據(jù)作為測(cè)試集。基于語(yǔ)義的推薦算法以所有圖書作為訓(xùn)練集,以2016—2017學(xué)年的借閱數(shù)據(jù)作為測(cè)試集。 3.2?評(píng)估方法 選取最終效用作為評(píng)估標(biāo)準(zhǔn),即推薦窗口的圖書是否包含用戶后續(xù)借閱圖書。以2016—2017學(xué)年借閱兩本以上圖書的讀者作為測(cè)試標(biāo)準(zhǔn),假設(shè)讀者借閱的第1本圖書在OPAC系統(tǒng)中檢索過(guò),且讀者瀏覽了這本書的詳細(xì)頁(yè)面。在這本書的詳細(xì)頁(yè)面中,算法將推薦10本與第1本圖書相關(guān)的圖書,如果推薦窗口中有用戶后續(xù)借閱的圖書,則認(rèn)為是一次成功的推薦;如果窗口中任何一本圖書都沒(méi)有被讀者借閱過(guò),則認(rèn)為是一次失敗的推薦。舉例說(shuō)明,讀者r在2016—2017學(xué)年間按照時(shí)間先后順序借閱3本圖書b1、b2、b3,假設(shè)讀者r借閱圖書b1時(shí)在OPAC系統(tǒng)上檢索并瀏覽了該書的詳情頁(yè)面,算法將在頁(yè)面底部根據(jù)圖書b1推薦10本圖書,如果r后續(xù)借閱的圖書b2或b3出現(xiàn)在這10本圖書之中,則認(rèn)為算法是一次成功的推薦;如果后續(xù)任何一本圖書均沒(méi)有出現(xiàn)在推薦范圍內(nèi),則認(rèn)為是一次失敗的推薦。以推薦成功率作為評(píng)估效果的指標(biāo),計(jì)算方法是成功推薦次數(shù)除以總推薦次數(shù)。
3.3?實(shí)驗(yàn)結(jié)果
3.3.1?算法的成功率
4種推薦算法的成功率如圖2所示。基于共借關(guān)系的推薦效果略好于基于語(yǔ)義相似度的推薦效果。融合以后的推薦效果要好于單一推薦算法的效果,但提升的程度并不十分明顯。把語(yǔ)義推薦結(jié)果和共借推薦結(jié)果視作同等重要的平等融合的效果最好,以共借關(guān)系為主,語(yǔ)義關(guān)系為輔的補(bǔ)充融合算法雖然也能起到一定改進(jìn)作用,但效果不如前者。從實(shí)用的角度,每5名讀者中有1名讀者能夠在推薦列表中發(fā)現(xiàn)他這一學(xué)年會(huì)借閱的圖書,是一個(gè)可以讓讀者接受的推薦效果。
3.3.2?推薦窗口大小對(duì)成功率的影響
推薦窗口大小是指最多允許向讀者推薦的圖書數(shù)量。圖3中,橫坐標(biāo)為推薦窗口大小,縱坐標(biāo)是推薦成功率。圖中可以看出,推薦窗口大小與推薦成功率表現(xiàn)為成類似對(duì)數(shù)函數(shù)的曲線關(guān)系,在推薦窗口較小時(shí),推薦成功率隨窗口的增大而迅速增大;在窗口較大時(shí),推薦成功率的增幅趨于平緩。這說(shuō)明盲目增大窗口并不是總能帶來(lái)更好的效果,過(guò)大的推薦窗口反而會(huì)帶來(lái)糟糕的用戶體驗(yàn)。
3.3.3?推薦算法對(duì)不同受眾的影響
高等院校圖書館的讀者主要有本科生、碩士生、博士生和教職員工,他們的借閱習(xí)慣存在一定差異,因此體驗(yàn)到的最終效果也存在一定差異。整體來(lái)看,推薦算法在本科生中的效果最好,在教職員工中的效果最差,這與訓(xùn)練樣本中本科生遠(yuǎn)多于教職員工有關(guān),數(shù)據(jù)驅(qū)動(dòng)的算法更有利于大多數(shù)群體。對(duì)于本科生人群,基于共借關(guān)系的推薦算法成功率遠(yuǎn)高于基于語(yǔ)義推薦算法的成功率,說(shuō)明本科生讀者的共借關(guān)系比較密切。本科生的主要任務(wù)是學(xué)習(xí)公共課和專業(yè)課,所學(xué)內(nèi)容比較相近,因此共借關(guān)系比較密切。隨著學(xué)歷層次的增加,基于語(yǔ)義推薦算法的成功率逐漸增加,而基于共借關(guān)系的推薦算法成功率逐漸下降。原因是學(xué)歷越高的讀者,他們之間的需求差異越大,共借關(guān)系偏弱。而他們研究的書目普遍處于同一主題,因此基于語(yǔ)義推薦的算法更有效。通過(guò)上述分析,可以清晰地看到同一個(gè)算法面向不同受眾的弊端,在個(gè)性化推薦算法中,這些弊端將得到較好地解決。
4?結(jié)?語(yǔ)
針對(duì)OPAC系統(tǒng)用戶普遍處于非登錄狀態(tài),個(gè)性化推薦算法難以發(fā)揮效用的問(wèn)題,本文分別從語(yǔ)義相似度和共借關(guān)系兩個(gè)角度提出了兩種圖書非個(gè)性化推薦算法。通過(guò)構(gòu)建詞向量模型計(jì)算圖書之間的語(yǔ)義相似度,提出基于語(yǔ)義相似度的算法,推薦成功率為15.5%;基于共借關(guān)系的推薦成功率為17.2%。兩種算法有各自的優(yōu)勢(shì)也有各自的缺點(diǎn),提出了兩種算法融合策略:一種是基于平等關(guān)系的融合策略,該策略把兩種算法推薦的結(jié)果視作同等重要,推薦成功率為22.1%;另一種是以共借關(guān)系為主體以語(yǔ)義關(guān)系為補(bǔ)充的融合算法,推薦成功率為19.1%。另外,本文還討論了在大規(guī)模圖書和讀者條件下算法的實(shí)現(xiàn)問(wèn)題,通過(guò)引入哈希表有效節(jié)省了向量空間模型帶來(lái)的存儲(chǔ)開(kāi)銷,通過(guò)引入索引技術(shù)解決了距離計(jì)算量的問(wèn)題。
需要說(shuō)明的是,成功率并非評(píng)估推薦算法的標(biāo)準(zhǔn),多樣性、驚喜度等在推薦算法中同樣重要。在實(shí)踐中,推薦算法的選擇還應(yīng)當(dāng)與圖書館的服務(wù)宗旨和服務(wù)理念相一致。因此,本文提出的4種推薦算法沒(méi)有絕對(duì)的優(yōu)劣之分,只有在不同場(chǎng)景下合適還是不合適的區(qū)別。
參考文獻(xiàn)
[1]中華人民共和國(guó)教育部.普通高等學(xué)校圖書館規(guī)程[EB/OL].http://www.scal.edu.cn/gczn/sygc,2020-02-20.
[2]教育部高等學(xué)校圖書情報(bào)工作指導(dǎo)委員會(huì)秘書處.2018年高校圖書館發(fā)展報(bào)告[EB/OL].http://www.scal.edu.cn/sites/default/files/attachment/tjpg/2018年中國(guó)高校圖書館發(fā)展報(bào)告.pdf,2020-02-20.
[3]王心裁.文化沖突交融中的導(dǎo)讀目錄[J].圖書情報(bào)知識(shí),1998,(4):2-6.
[4]蔣小峰.近十年來(lái)我國(guó)圖書館推薦書目服務(wù)研究綜述[J].圖書館理論與實(shí)踐,2017,(9):6-11,20.
[5]黎邦群.基于檢索行為的非個(gè)性化圖書推薦[J].圖書館雜志,2013,32(8):36-41.
[6]明均仁,周知,陳雪.閱讀推廣推薦書目的自動(dòng)生成研究[J].圖書館論壇,2017,37(10):94-99,113.
[7]劉麗帆,朱紫陽(yáng).基于“全評(píng)價(jià)”理論的高校圖書館熱門TOP圖書推薦模型研究[J].圖書情報(bào)工作,2018,62(7):47-53.
[8]崔春生,蘇白云.基于Vague值的非個(gè)性化產(chǎn)品推薦研究[J].計(jì)算機(jī)工程與應(yīng)用,2012,48(13):63-66.
[9]Chakraborty A,Ghosh S,Ganguly N.Optimizing the Recency-Relevance-Diversity Trade-offs in Non-personalized News Recommendations[J].Information Retrieval Journal,2019,22(5):447-475.
[10]李民,王穎純,劉燕權(quán).“211工程”高校圖書館館藏資源推薦系統(tǒng)調(diào)查探析[J].圖書情報(bào)工作,2016,60(9):55-60.
[11]郭婧婧,王穎純,劉燕權(quán).城市圖書館館藏資源推薦系統(tǒng)調(diào)查分析[J].圖書館學(xué)研究,2019,(4):76-82,101.
(責(zé)任編輯:郭沫含)
猜你喜歡
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 16:13:56
出版廣角(2016年15期)2016-10-18 00:19:57
科技視界(2016年21期)2016-10-17 19:32:37
科技視界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:39:10
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科學(xué)與財(cái)富(2016年28期)2016-10-14 23:43:29
科學(xué)與財(cái)富(2016年28期)2016-10-14 00:28:44
科技視界(2016年20期)2016-09-29 13:17:57
