多尺度多核高斯過程隱變量模型
2021-02-05 03:03:38周培春吳蘭岸
計(jì)算機(jī)工程 2021年2期
周培春,吳蘭岸
(1.玉林師范學(xué)院計(jì)算機(jī)科學(xué)與工程學(xué)院,廣西玉林 537000;2.南寧師范大學(xué)計(jì)算機(jī)與信息工程學(xué)院,南寧 530299)
0 概述
在機(jī)器學(xué)習(xí)和模式識(shí)別任務(wù)中,圖像數(shù)據(jù)作為一種特殊的數(shù)據(jù)形式廣泛應(yīng)用于人臉識(shí)別[1]、表情識(shí)別[2]、年齡估計(jì)[3]等場(chǎng)景中,而此類數(shù)據(jù)通常具有較高的維度導(dǎo)致機(jī)器學(xué)習(xí)模型計(jì)算復(fù)雜度高且容易產(chǎn)生過擬合等維數(shù)災(zāi)難問題。為應(yīng)對(duì)上述挑戰(zhàn),主成分分析[4]、高斯過程隱變量模型(Gaussian Process Latent Variable Model,GPLVM)[5]、線性判別分析[6]、自編碼器[7]和字典學(xué)習(xí)[8]等數(shù)據(jù)降維和特征學(xué)習(xí)方法陸續(xù)被提出并取得了較好的成果,其中GPLVM作為一種貝葉斯非參數(shù)降維模型,具有非線性學(xué)習(xí)、不確定性量化和非參數(shù)柔性建模等特性[5],近年來在圖像識(shí)別領(lǐng)域得到廣泛應(yīng)用[9-11]。然而原始GPLVM作為一種無監(jiān)督的降維模型,利用高斯過程構(gòu)建由隱變量空間到觀測(cè)變量空間的映射,進(jìn)而通過求解最大化似然函數(shù)的方式獲得最佳隱變量并實(shí)現(xiàn)數(shù)據(jù)降維。
圖像數(shù)據(jù)信息通常分為像素值信息、特征空間信息和語義標(biāo)記信息3類。像素值信息指圖像中各像素值的大小所包含的信息,通常可以被PCA、字典學(xué)習(xí)、GPLVM等降維方法直接利用,從而實(shí)現(xiàn)數(shù)據(jù)降維。特征空間信息指圖像像素及其局部區(qū)域之間所具有的相關(guān)性信息[12-13]。圖像語義標(biāo)記信息指人們通過自身認(rèn)知和圖像所包含的內(nèi)容為圖像標(biāo)注的信息[14-15],如圖像注釋、類別標(biāo)記等。然而,原始GPLVM在建模過程中僅假設(shè)觀測(cè)變量的特征之間相互獨(dú)立,因此通常無法有效利用圖像數(shù)據(jù)自身包含的特征空間結(jié)構(gòu)信息和語義標(biāo)記信息。為此,本文對(duì)原始GPLVM進(jìn)行改進(jìn),提出一種多尺度多核高斯過程隱變量模型(Multi-Scale Multi-Kernel Gaussian Process Latent Variable Model,MSMK-GPLVM)。
1 相關(guān)工作
1.1 高斯過程隱變量模型
GPLVM是一種無監(jiān)督的概率、非線性、隱變量模型。在GPLVM定義中,假設(shè)已觀測(cè)到N個(gè)樣本Χ=[x1,x2,…,xN]T∈?N×D,其中xn∈?D表示第n個(gè)樣本對(duì)應(yīng)的輸入,本文目標(biāo)是求解每個(gè)觀測(cè)變量xn對(duì)應(yīng)的隱變量zn∈?Q,Q?D,因此GPLVM可以通過求解觀測(cè)變量對(duì)應(yīng)隱變量的方式實(shí)現(xiàn)數(shù)據(jù)降維。具體地,GPLVM假設(shè)每個(gè)樣本xn的生成過程如下:

其中:xnd為第n個(gè)樣本的第d個(gè)特征;εnd為噪聲項(xiàng)且服從高斯分布p(εn)=N(εn|0,σ2);函數(shù)f(d·)具有高斯過程先驗(yàn),因此fd~N(0,K),fd表示函數(shù)f(d·)在隱變量集合Z=[z1,z2,…,zN]上對(duì)應(yīng)N個(gè)輸出組成的向量;K表示核函數(shù)k(·,·)在隱變量集合Z上對(duì)應(yīng)的核矩陣Kij=k(zi,z)j。通過將中間變量fd進(jìn)行積分可以得到如下邊際似然函數(shù):
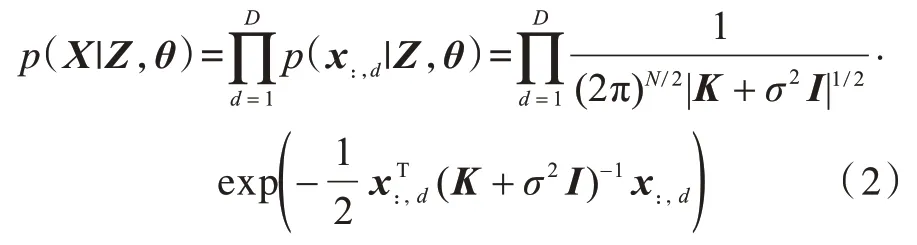
其中:θ表示GPLVM的核函數(shù)及噪聲分布中包含的超參數(shù);σ2表示噪聲方差;x:,d表示矩陣Χ的第d列元素組成的向量;I表示單位矩陣;|K+σ2I|表示矩陣(K+σ2I)的行列式。在模型優(yōu)化過程中,GPLVM通過最大化上述似然函數(shù)的方式對(duì)隱變量Z和超參數(shù)θ進(jìn)行求解,最終實(shí)現(xiàn)數(shù)據(jù)降維。
盡管GPLVM具有較強(qiáng)的非線性學(xué)習(xí)和不確定性量化等能力,但其卻無法有效利用數(shù)據(jù)的語義標(biāo)記信息,從而導(dǎo)致在圖像分類、人臉識(shí)別等任務(wù)中的性能無法滿足用戶需求,其原因主要為GPLVM在模型構(gòu)建過程中沒有對(duì)數(shù)據(jù)標(biāo)記的生成過程進(jìn)行有效的建模和表示,因此無法直接將其應(yīng)用于監(jiān)督學(xué)習(xí)任務(wù)中。
1.2 監(jiān)督型高斯過程隱變量模型
為實(shí)現(xiàn)GPLVM的監(jiān)督學(xué)習(xí)并充分利用數(shù)據(jù)中包含的語義標(biāo)記信息,近年來已有一些監(jiān)督型GPLVM被提出,其中主要包括判別高斯過程隱變量模型(D-GPLVM)[14]、監(jiān)督高斯過程隱變量模型(S-GPLVM)[15]和監(jiān)督隱線性高斯過程隱變量模型(SLLGPLVM)[15]。為對(duì)監(jiān)督型GPLVM進(jìn)行詳細(xì)說明,假設(shè)除了觀測(cè)變量Χ,本文還獲取了每個(gè)樣本對(duì)應(yīng)的類別標(biāo)記y∈?N,其中第n個(gè)元素yn∈{1,2,…,C}表示第n個(gè)樣本所屬類別,C表示類別總數(shù)。
為利用數(shù)據(jù)標(biāo)記信息,D-GPLVM構(gòu)建一種基于廣義判別分析(Generalized Discriminant Analysis,GDA)的隱變量先驗(yàn)分布,具體如下:
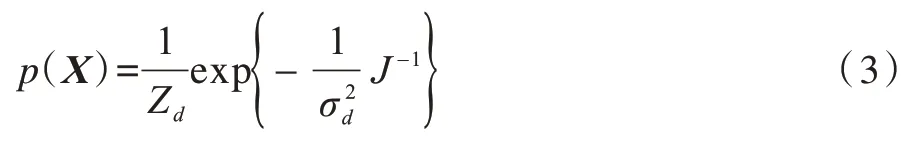
其中:Zd為歸一化常量;表示先驗(yàn)的全局伸縮因子;J為依賴于Χ的函數(shù),Sω和Sb分別為在隱變量Χ上依據(jù)標(biāo)記y計(jì)算出的類內(nèi)和類間散度矩陣。將式(3)中的先驗(yàn)分布加入GPLVM中可以獲得隱變量Χ后驗(yàn)分布,并通過最大化此后驗(yàn)分布或等價(jià)地最小化式(4)獲得最佳的隱變量和超參數(shù)。

其中,L表示GPLVM的負(fù)對(duì)數(shù)邊際似然,LS表示加入監(jiān)督信息后的對(duì)數(shù)后驗(yàn)分布。值得注意的是在式(4)中為便于描述,本文省略了對(duì)核函數(shù)超參數(shù)先驗(yàn)的假設(shè),因此在式(4)中缺少文獻(xiàn)[15]中所述的超參數(shù)正則化項(xiàng)。可以看出,D-GPLVM為GDA與GPLVM結(jié)合而成的模型,GDA先驗(yàn)為GPLVM提供了數(shù)據(jù)標(biāo)記中包含的語義判別信息。同時(shí)可以看出,當(dāng)σd→0時(shí),D-GPLVM退化為GDA;反之,當(dāng)σd→+∞時(shí),D-GPLVM退化為GPLVM。
與D-GPLVM不同,S-GPLVM通過分別構(gòu)建由隱變量到觀測(cè)變量的類別標(biāo)記映射方式實(shí)現(xiàn)了監(jiān)督型GPLVM。將樣本標(biāo)記yn轉(zhuǎn)化為由1和-1組成的向量的形式,從而獲得樣本的標(biāo)記矩陣Y=[y1,y2,…,yN]T∈?N×C。若第n個(gè)樣本屬于第c類,則其對(duì)應(yīng)的標(biāo)記向量yn中第c個(gè)元素的值為1,其他元素的值為-1。S-GPLVM假設(shè)Χ和Y均是由隱變量Z通過服從高斯過程的函數(shù)生成,且Χ和Y在Z條件下相互獨(dú)立,進(jìn)而可以獲得隱變量Z的后驗(yàn)分布為:
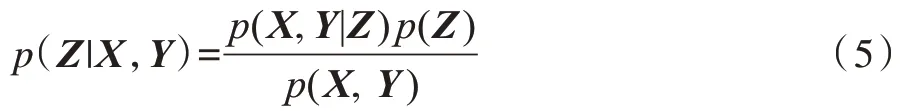
最終得到如下目標(biāo)函數(shù):
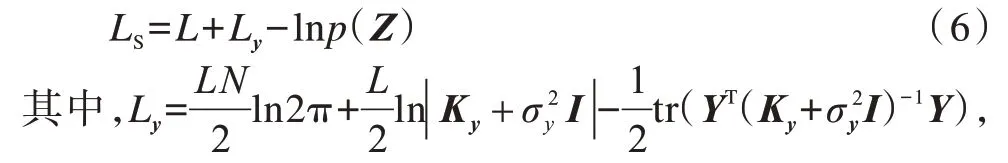
Ky表示與Y生成相關(guān)的核矩陣,表示噪聲方差。可以看出,S-GPLVM通過使Χ和Y共享隱變量Z的方式實(shí)現(xiàn)了語義標(biāo)記信息和輸入信息的聯(lián)合建模。這使得隱變量Z具有更優(yōu)的判別能力,有效提升了GPLVM在分類和回歸任務(wù)中的性能。
SLLGPLVM通過直接構(gòu)建由觀測(cè)變量Χ到隱變量Z的投影方式實(shí)現(xiàn)了GPLVM的監(jiān)督學(xué)習(xí)。與原始GPLVM類似,其假設(shè)隱變量可以通過一個(gè)服從高斯過程的函數(shù)投影并加入噪聲得到觀測(cè)變量。然而SLLGPLVM假設(shè)GPLVM生成標(biāo)記Y而不是原始GPLVM中的Χ,同時(shí)其假設(shè)隱變量可以通過一個(gè)線性投影函數(shù)由輸入變量Χ得到,從而構(gòu)建由Χ到Z和由Z到Y(jié)的映射關(guān)系,使得GPLVM可以顯式地嵌入標(biāo)記信息。整個(gè)生成過程具體如下:
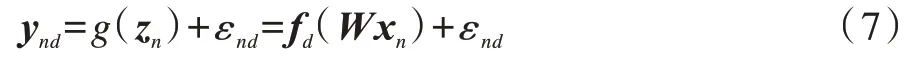
其中,g(·)表示線性投影函數(shù),可以看出SLLGPLVM將隱變量學(xué)習(xí)問題轉(zhuǎn)化為參數(shù)矩陣W的學(xué)習(xí)問題,因此其具有更少的參數(shù)量,同時(shí)能夠有效解決D-GPLVM中先驗(yàn)信息與真實(shí)數(shù)據(jù)信息不相符的問題,以及S-GPLVM中需要存儲(chǔ)和操作兩個(gè)核矩陣K和Ky所導(dǎo)致的高復(fù)雜度問題。
1.3 現(xiàn)有模型存在的問題
雖然現(xiàn)有監(jiān)督型GPLVM已在某些特定任務(wù)中有效提升了GPLVM隱變量的判別性能,但是這些模型仍然存在一定問題從而限制了其應(yīng)用范圍,如D-GPLVM和S-GPLVM在對(duì)新樣本進(jìn)行預(yù)測(cè)時(shí)需要通過優(yōu)化求解方式計(jì)算出對(duì)應(yīng)新樣本的隱變量,因此預(yù)測(cè)的時(shí)間復(fù)雜度過高,限制了其在快速預(yù)測(cè)任務(wù)中的應(yīng)用。盡管這兩個(gè)模型均可以通過添加反向約束[16]的方式實(shí)現(xiàn)非優(yōu)化式的預(yù)測(cè),但該反向約束同時(shí)也限制了模型的表示能力。SLLGPLVM利用構(gòu)建由輸入變量到隱變量的線性投影方式實(shí)現(xiàn)新樣本的快速預(yù)測(cè),然而此類簡(jiǎn)單的線性映射通常無法滿足真實(shí)應(yīng)用場(chǎng)景中復(fù)雜非線性任務(wù)的需求。另外,現(xiàn)有監(jiān)督型GPLVM采用相對(duì)簡(jiǎn)單的方式對(duì)標(biāo)記信息進(jìn)行建模,一般情況下無法挖掘出真正的復(fù)雜語義信息,從而造成標(biāo)記信息流失。
除了上述問題外,現(xiàn)有GPLVM模型在處理圖像數(shù)據(jù)時(shí)無法有效利用數(shù)據(jù)的空間結(jié)構(gòu)信息。如圖1所示,兩個(gè)相鄰的像素值a1和a2通常具有一定的相關(guān)性和相似性。同理,兩個(gè)局部區(qū)域之間通常也存在較強(qiáng)的相關(guān)性,如圖1中b1和b2所示。由于現(xiàn)有GPLVM并沒有對(duì)觀測(cè)變量特征之間的相關(guān)性進(jìn)行任何的假設(shè)和建模,無法進(jìn)一步提升模型性能,因此本文主要研究在處理圖像數(shù)據(jù)時(shí)如何能夠兼顧語義標(biāo)記信息和空間結(jié)構(gòu)信息來構(gòu)建GPLVM,從而有效提升其在人臉識(shí)別、圖像分類等應(yīng)用中的綜合性能。
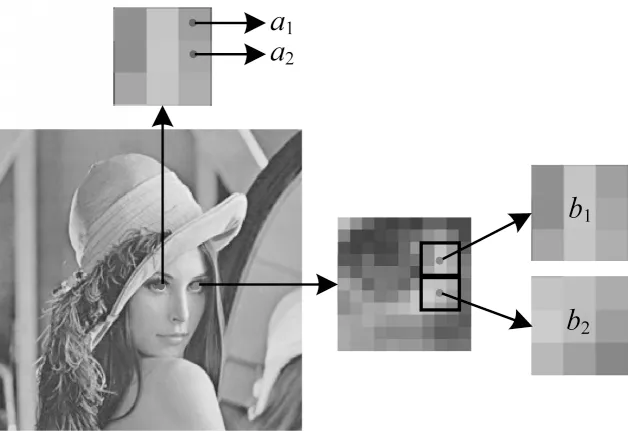
圖1 圖像相鄰像素及區(qū)域之間的相關(guān)性Fig.1 Correlations between adjacent pixels and regions of the image
2 MSMK-GPLVM構(gòu)建與優(yōu)化
2.1 模型構(gòu)建
為便于描述,本文后續(xù)內(nèi)容將使用上文中的變量定義。在模型構(gòu)建過程中,主要從圖像空間結(jié)構(gòu)信息和語義標(biāo)記信息兩方面對(duì)GPLVM的擴(kuò)展方式進(jìn)行分析與研究。

通過將每個(gè)樣本(不同尺度的圖像)對(duì)應(yīng)的隱變量進(jìn)行非線性變換再相加的方式,得到第n個(gè)樣本對(duì)應(yīng)的隱變量:
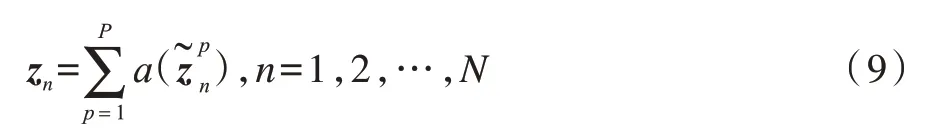
其中a(·)表示神經(jīng)網(wǎng)絡(luò)中的激活函數(shù)。由上述構(gòu)建過程可知,本文提出的多尺度特征融合方法與神經(jīng)網(wǎng)絡(luò)中的空間金字塔池化方法[17]非常相似,然而兩者也有明顯區(qū)別:1)空間金字塔池化主要是為了解決卷積神經(jīng)網(wǎng)絡(luò)無法處理任意尺度的圖像而設(shè)計(jì)的方法,其進(jìn)行池化時(shí)的核大小是根據(jù)圖像大小自動(dòng)確定,而本文多尺度特征融合方法主要是將其應(yīng)用于圖像多尺度特征提取,其處理的原始圖像大小相同;2)本文模型在特征融合時(shí)使用一個(gè)非線性變換函數(shù),因此其具有更強(qiáng)的非線性學(xué)習(xí)能力,而空間金字塔池化通過將多尺度特征合并為一個(gè)大向量的方式實(shí)現(xiàn)多尺度特征融合,其非線性學(xué)習(xí)能力主要體現(xiàn)在后續(xù)的全連接層中。當(dāng)a(·)為線性函數(shù)時(shí),本文多尺度特征融合方法可以退化為包含線性投影層的空間金字塔池化方法。
在圖像語義標(biāo)記信息利用方面,本文使用一個(gè)多核高斯過程模型[17-19]來構(gòu)建由隱變量到樣本標(biāo)記的映射。具體地,定義由隱變量到樣本標(biāo)記的生成過程,具體如下:

其中,εnc為服從高斯分布的噪聲,f(c·)為服從多核高斯過程先驗(yàn)分布的函數(shù)為M個(gè)核函數(shù)組合的權(quán)重。可以看出,fc服從的高斯過程先驗(yàn)是一個(gè)多核高斯過程,其中的協(xié)方差矩陣由多個(gè)核矩陣加權(quán)而成。因此,可以認(rèn)為本文模型是一種多核高斯過程模型。從上述樣本標(biāo)記生成過程可知,MSMKGPLVM通過構(gòu)建多核高斯過程模型的方式顯著地提升了由隱變量到標(biāo)記映射函數(shù)的表示能力,并且可以高效地建模數(shù)據(jù)標(biāo)記信息。同時(shí),MSMKGPLVM與多尺度圖像特征提取相結(jié)合能夠有效地對(duì)隱變量和數(shù)據(jù)生成過程進(jìn)行模擬,提升模型判別和特征學(xué)習(xí)能力。MSMK-GPLVM結(jié)構(gòu)如圖2所示。
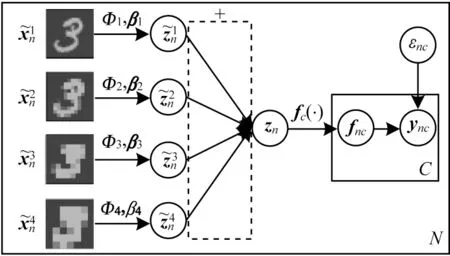
圖2 MSMK-GPLVM結(jié)構(gòu)Fig.2 Structure of MSMK-GPLVM
2.2 模型優(yōu)化
在模型求解過程中,由MSMK-GPLVM生成過程可知噪聲εnc服從高斯分布,因此似然函數(shù)可寫為以下形式:

由于核矩陣Ks關(guān)于隱變量Z的導(dǎo)數(shù)取決于核函數(shù)的形式,因此通常多數(shù)核函數(shù)(如徑向基核函數(shù)等)可以直接得出其關(guān)于隱變量的導(dǎo)數(shù),而對(duì)數(shù)似然函數(shù)關(guān)于核矩陣導(dǎo)數(shù)的計(jì)算過程具體如下:

基于上述求導(dǎo)過程,利用基于梯度的優(yōu)化方法對(duì)MSMK-GPLVM中的變量進(jìn)行優(yōu)化求解。MSMKGPLVM優(yōu)化算法具體如下:
算法1MSMK-GPLVM優(yōu)化算法

2.3 新樣本預(yù)測(cè)
在新樣本預(yù)測(cè)中,本文目標(biāo)是預(yù)測(cè)給定新樣本x*所屬的類別標(biāo)記。與原始GPLVM、D-GPLVM和S-GPLVM相比,MSMK-GPLVM的顯著優(yōu)勢(shì)是可以直接對(duì)新樣本進(jìn)行分類,而GPLVM、D-GPLVM和S-GPLVM在預(yù)測(cè)出對(duì)應(yīng)的隱變量z*后,通常需要使用KNN算法對(duì)樣本進(jìn)行分類。在MSMK-GPLVM預(yù)測(cè)過程中,首先依據(jù)式(8)和式(9)計(jì)算出新樣本對(duì)應(yīng)的隱變量z*,然后根據(jù)高斯過程模型的預(yù)測(cè)方法得出對(duì)應(yīng)目標(biāo)值服從高斯分布,其均值和方差計(jì)算如下:
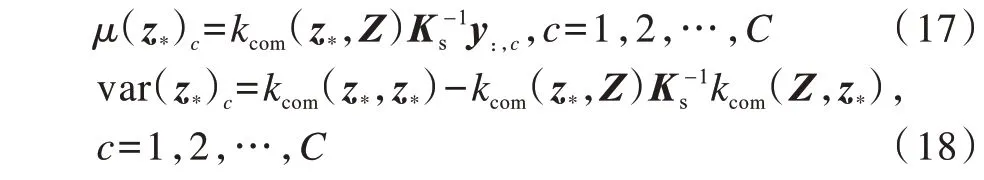
其中,kcom(z*,Z)為z*和Z中每個(gè)樣本取核函數(shù)(多核組合函數(shù))的值組成的行向量,kcom(z*,Z)T=kcom(Z,z*),kcom(z*,z*)表示z*與z*取核函數(shù)后的值。可以看出,高斯過程模型可以對(duì)預(yù)測(cè)的不確定性(方差)進(jìn)行建模,有效擴(kuò)展了其在醫(yī)療診斷、自動(dòng)駕駛等需要對(duì)不確定性進(jìn)行量化任務(wù)中的應(yīng)用。在完成上述計(jì)算后,可以利用μ(z*)={μ(z*)1,μ(z*)2,…,μ(z*)C}獲得最終的類別標(biāo)記:
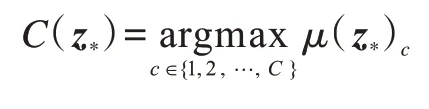
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集與對(duì)比方法
在實(shí)驗(yàn)過程中,為充分驗(yàn)證MSMK-GPLVM的有效性,分別在多個(gè)數(shù)據(jù)集上與現(xiàn)有隱變量模型進(jìn)行對(duì)比。實(shí)驗(yàn)數(shù)據(jù)集信息如表1所示。
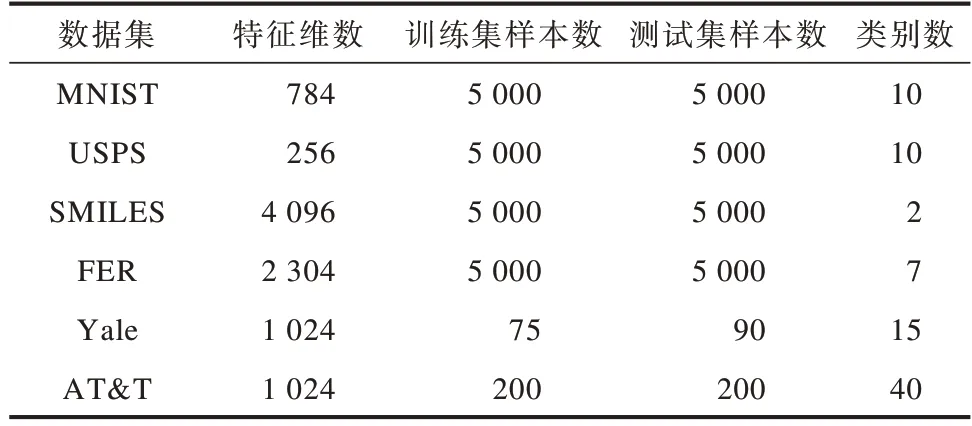
表1 實(shí)驗(yàn)數(shù)據(jù)集Table 1 Experimental dataset
MNIST[20]和USPS[21]均為手寫字體數(shù)據(jù)集,分別包含像素值大小為28×28和16×16的手寫數(shù)字圖片。SMILES[22]數(shù)據(jù)集是一個(gè)包含笑臉和非笑臉兩類圖像的表情識(shí)別數(shù)據(jù)集,是由LFW中提取圖像組成的數(shù)據(jù)集,包含像素值大小為64×64的圖像。FER是Kaggle人臉表情識(shí)別競(jìng)賽數(shù)據(jù)集,包含生氣、厭惡、恐懼、高興、悲哀、驚訝、平和7種表情且像素值大小為48×48的圖像。Yale和AT&T是兩個(gè)人臉識(shí)別數(shù)據(jù)集,其中,Yale數(shù)據(jù)集包含15個(gè)人的165張人臉圖像(每人11張),AT&T包含40個(gè)人的400張人臉圖像(每人10張),所有圖像均使用人工對(duì)齊和裁剪方式規(guī)整化至像素值大小為32×32的灰度圖像。對(duì)于MNIST、USPS、SMILES、FER數(shù)據(jù)集,本文分別使用5 000個(gè)樣本作為訓(xùn)練集和測(cè)試集。對(duì)于Yale數(shù)據(jù)集,使用每個(gè)人的5張人臉圖像作為訓(xùn)練集(總數(shù)為75),其余6張圖像作為測(cè)試集(總數(shù)為90)。對(duì)于AT&T數(shù)據(jù),使用每人5張人臉圖像作為訓(xùn)練集(總數(shù)為200),其余5張圖像作為測(cè)試集(總數(shù)為200)。在訓(xùn)練過程中,在訓(xùn)練集上使用五折交叉驗(yàn)證方法選擇模型超參數(shù),主要是對(duì)MSMKGPLVM中核函數(shù)數(shù)量進(jìn)行選擇。最終在整個(gè)訓(xùn)練集上基于最佳超參數(shù)對(duì)模型進(jìn)行訓(xùn)練,并將訓(xùn)練好的模型在測(cè)試集上進(jìn)行分類性能測(cè)試,重復(fù)5次上述過程以獲得各模型的平均分類準(zhǔn)確率。
本文對(duì)比模型為原始GPLVM、D-GPLVM、S-GPLVM、SLLGPLVM、PCA[23]和LDA[24]。值得注意的是由于GPLVM、PCA和LDA不包含需要交叉驗(yàn)證的超參數(shù),因此本文直接將其在訓(xùn)練集和測(cè)試集上進(jìn)行訓(xùn)練和測(cè)試。同時(shí),因?yàn)镚PLVM、D-GPLVM、S-GPLVM、PCA和LDA不能對(duì)樣本類別進(jìn)行直接預(yù)測(cè),所以本文使用KNN算法(K=5)對(duì)學(xué)習(xí)到的隱變量進(jìn)行分類。
3.2 數(shù)據(jù)降維與可視化
為驗(yàn)證MSMK-GPLVM在數(shù)據(jù)降維和可視化方面的性能,本文將所有模型應(yīng)用于MNIST數(shù)據(jù)降維實(shí)驗(yàn)中并將學(xué)習(xí)到的二維隱變量進(jìn)行可視化,如圖3所示。可以看出,原始GPLVM和PCA由于無法使用樣本的語義標(biāo)記信息,因此其學(xué)到的隱變量可區(qū)分性較差,而 LDA、S-GPLVM、D-GPLVM、SLLGPLVM和MSMK-GPLVM可以有效使用樣本的語義標(biāo)記信息,因此可以學(xué)習(xí)到的樣本可分性較好。同時(shí),MSMK-GPLVM兼顧了圖像數(shù)據(jù)的多尺度空間結(jié)構(gòu)信息,因此獲得了最優(yōu)的結(jié)果,并且當(dāng)隱變量維度從2增加到3時(shí),其分類性能得到進(jìn)一步提升。
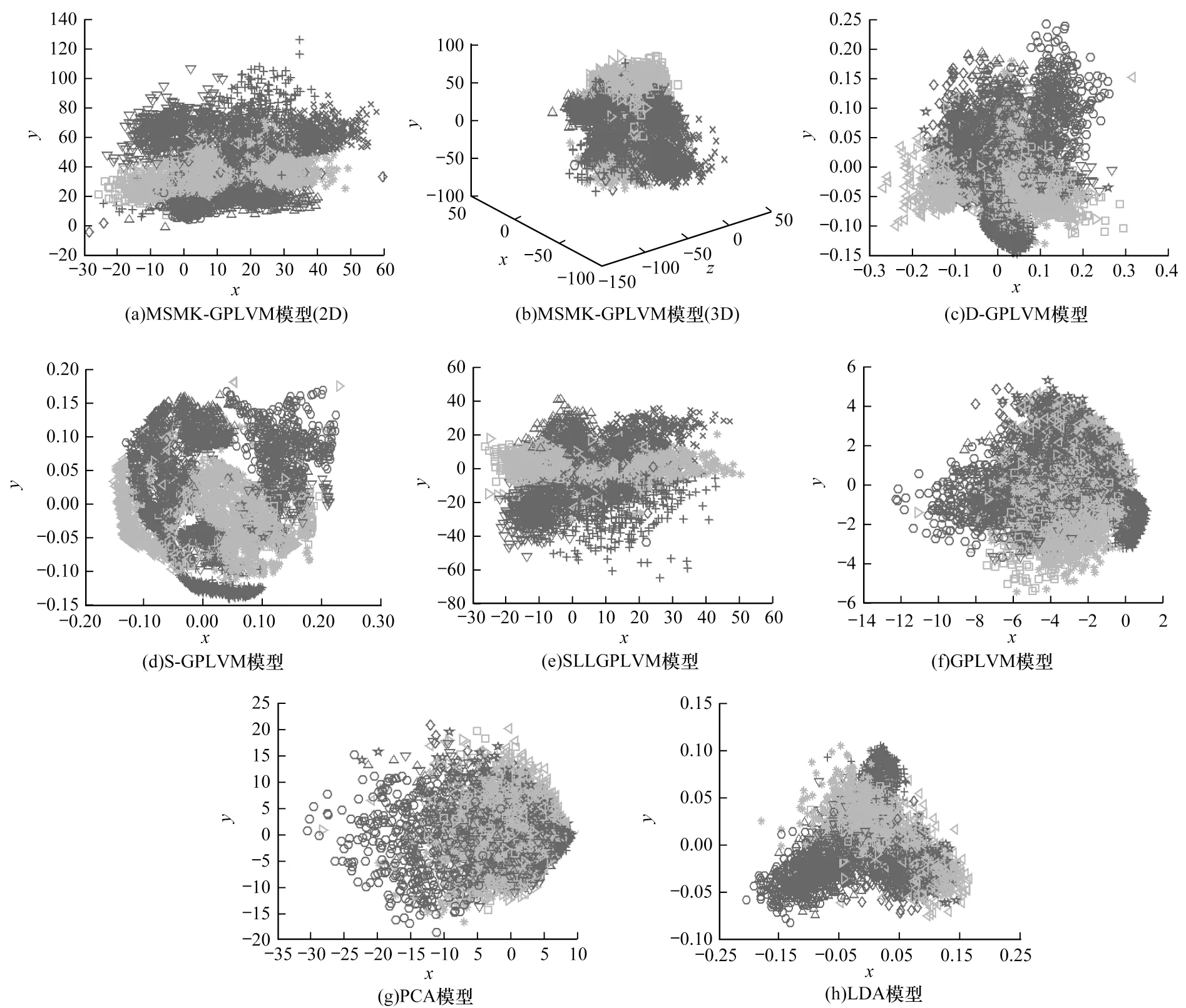
圖3 MNIST數(shù)據(jù)降維和可視化Fig.3 Data dimension reduction and visualization of MNIST
3.3 數(shù)據(jù)分類
在數(shù)據(jù)分類實(shí)驗(yàn)中將隱變量維度為2、4、6、8、10的情況下所有隱變量模型應(yīng)用于分類任務(wù),測(cè)試其數(shù)據(jù)分類準(zhǔn)確率,實(shí)驗(yàn)結(jié)果如圖4所示。值得注意的是,由于LDA隱變量維度不能大于或等于原始數(shù)據(jù)的類別數(shù),因此在使用LDA對(duì)SMILES數(shù)據(jù)進(jìn)行學(xué)習(xí)時(shí)本文僅設(shè)置隱變量維度為1,分類準(zhǔn)確率為0.819。與此類似,在使用LDA對(duì)FER數(shù)據(jù)集進(jìn)行學(xué)習(xí)時(shí),僅設(shè)置其隱變量的維度為2、4和6。可以看出,在MNIST、USPS、SMILES、Yale和AT&T數(shù)據(jù)集上模型分類性能均較高,其主要原因?yàn)檫@5種數(shù)據(jù)集包含較少的噪聲、同一類的數(shù)據(jù)差異較小。然而,在FER數(shù)據(jù)集上所有模型的分類準(zhǔn)確率均較低,其主要原因?yàn)槿四槇D像表情識(shí)別可能會(huì)受到姿態(tài)、光照、個(gè)體差異等多種因素的影響。所有模型的分類準(zhǔn)確率均隨著隱變量維度的增加而提升,最終趨于穩(wěn)定,從而證明較高的隱變量維度可以在數(shù)據(jù)降維過程中獲得更多的判別信息。此外,在所有模型中,GPLVM和PCA由于僅使用了樣本的輸入信息,而無法使用樣本的語義標(biāo)記信息,因此其分類準(zhǔn)確率較低。在所有實(shí)驗(yàn)數(shù)據(jù)集上,MSMK-GPLVM獲得了最優(yōu)的分類準(zhǔn)確率,充分說明了其采用兼顧樣本語義標(biāo)記信息和多尺度空間結(jié)構(gòu)信息的方式能夠有效提升GPLVM的分類性能。
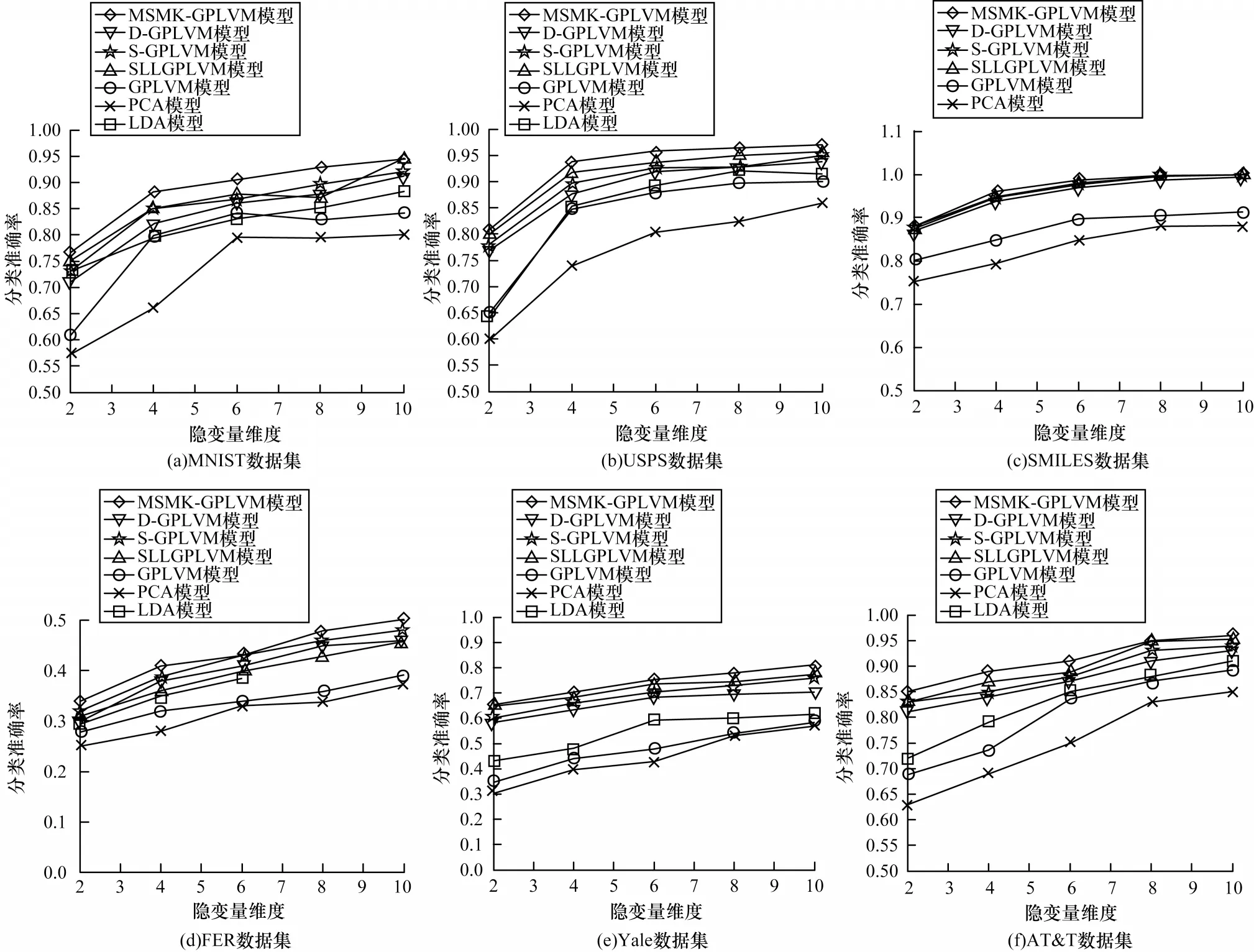
圖4 MSMK-GPLVM與其他隱變量模型的分類準(zhǔn)確率對(duì)比Fig.4 Comparison of classification accuracy of MSMK-GPLVM and other latent variable models
3.4 不同訓(xùn)練樣本數(shù)下模型分類性能比較
本文在包含不同數(shù)量訓(xùn)練樣本數(shù)的訓(xùn)練集上對(duì)MSMK-GPLVM、D-GPLVM、S-GPLVM、SLLGPLVM、GPLVM、PCA和LDA模型的分類準(zhǔn)確率進(jìn)行比較,實(shí)驗(yàn)結(jié)果如表2和表3所示,其中,Tr表示每個(gè)人用于訓(xùn)練的圖像數(shù),Te表示每個(gè)人用于測(cè)試的圖像數(shù)。例如,Tr2/Te9表示在Yale數(shù)據(jù)集中每個(gè)人有2張圖像作為訓(xùn)練集,9張圖像作為測(cè)試集。
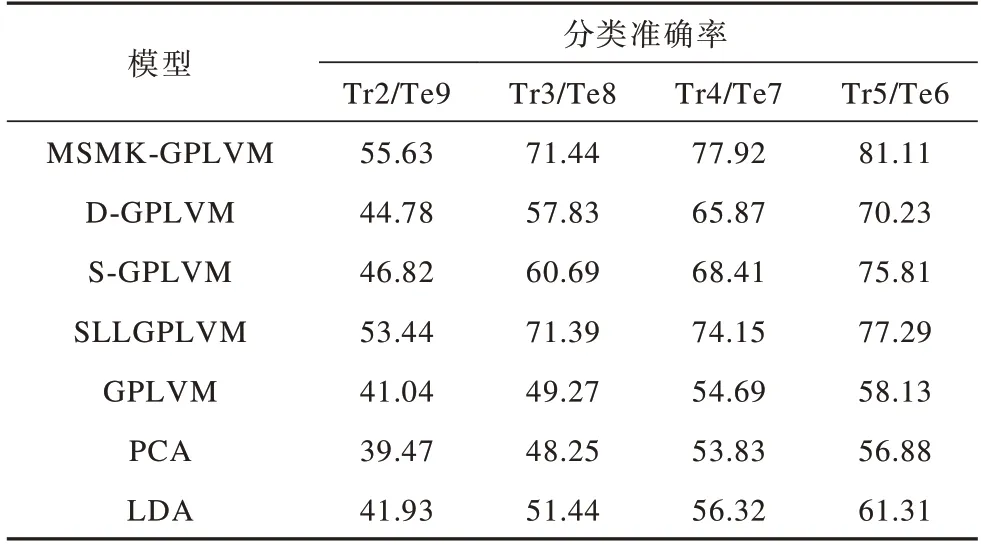
表2 7種模型在Yale數(shù)據(jù)集上的分類準(zhǔn)確率比較Table 2 Comparison of classification accurary of seven models on Yale dataset %
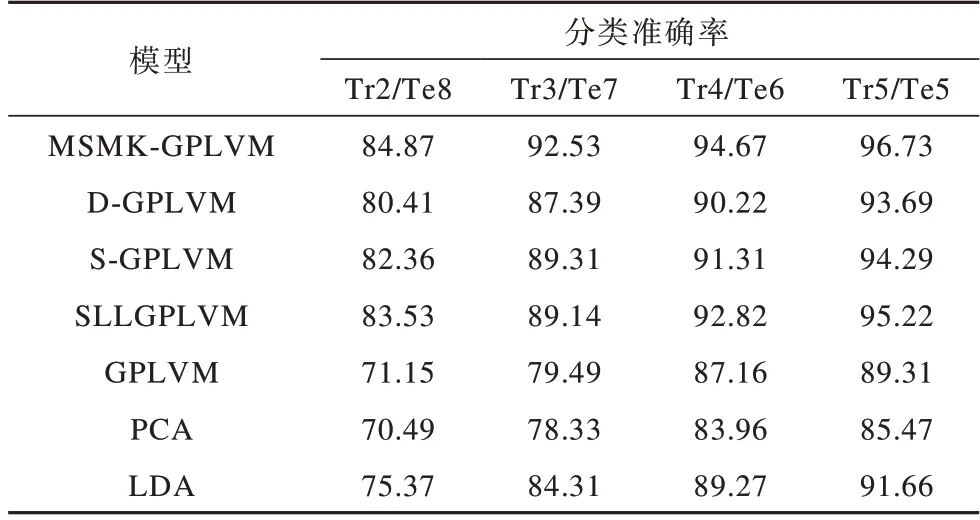
表3 7種模型在AT&T數(shù)據(jù)集上的分類準(zhǔn)確率比較Table 3 Comparison of classification accuary of seven models on AT&T dataset %
由表2、表3可以看出,由于AT&T數(shù)據(jù)集包含更多的訓(xùn)練圖像(該數(shù)據(jù)集包含人數(shù)多于Yale),因此模型在AT&T數(shù)據(jù)集上的分類準(zhǔn)確率高于其在Yale數(shù)據(jù)集上。同時(shí),PCA和GPLVM均為無監(jiān)督模型,分類準(zhǔn)確率均低于其他監(jiān)督型模型,而在所有情況下MSMKGPLVM的分類準(zhǔn)確率均高于其他模型,說明其在不同樣本數(shù)下均有較優(yōu)的性能,適用于不同規(guī)模的高維數(shù)據(jù)學(xué)習(xí)任務(wù)。
4 結(jié)束語
本文針對(duì)GPLVM無法有效利用圖像特征空間結(jié)構(gòu)信息和語義標(biāo)記信息的問題,提出一種多尺度多核GPLVM(MSMK-GPLVM)。實(shí)驗(yàn)結(jié)果表明,MSMK-GPLVM能夠?qū)D像空間結(jié)構(gòu)信息和語義標(biāo)記信息進(jìn)行有效利用,進(jìn)一步提升其在圖像識(shí)別任務(wù)和數(shù)據(jù)可視化任務(wù)中的整體性能。但由于MSMK-GPLVM在多尺度投影的構(gòu)建過程中引入了較多的冗余特征,因此后續(xù)將針對(duì)冗余特征的選擇及隱變量維度和核函數(shù)的確定做進(jìn)一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會(huì)展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
