基于改進D-S證據理論數據融合的路段單元交通狀態判別方法
2021-02-11 15:00:14王玉婷蔡曉禹
交通運輸研究 2021年6期
關鍵詞:融合
王玉婷,李 靜,蔡曉禹
(1.山地城市交通系統與安全重慶市重點實驗室,重慶 400074;2.重慶交通大學交通運輸學院,重慶 400074)
0 引言
高德地圖2021 年1 季度發布的《中國主要城市交通分析報告》顯示,我國361 個城市中,有59%的城市在通勤高峰時處于緩行狀態,有1.66%的城市處于擁堵狀態。由此可見,交通擁堵給城市交通運行帶來了較大的挑戰,亟需有效的應對措施。目前,準確的交通狀態判別是智能交通領域的熱點研究方向之一,也是實施有效管控措施、緩解擁堵問題的重要基礎[1]。
國內外學者對數據融合、道路交通狀態判別等已進行大量研究。按照獲取方式劃分,交通領域的數據可分為兩類[2],一類是由傳統的固定式檢測器(如感應線圈、地磁等)獲取的數據;另一類是移動型交通數據,如GPS 浮動車數據、手機信令數據、車聯網數據等。單一來源數據面臨信息不完整、不可靠等問題,需靠多源數據融合來彌補其不足。面向多源數據的融合算法中,基于多傳感器數據的融合算法涉及分布式融合技術、卡爾曼濾波技術、有序加權平均法、模糊積分法、神經網絡法等[3]。應用在交通領域,研究人員提出了基于交通流理論非線性函數的數據融合算法[4]、考慮虛假數據和交通狀態的數據融合算法[5]、基于置信張量的數據融合算法[6]、D-S 證據理論融合算法等。在D-S證據理論方面,Wang等研究了基于證據理論的空域擁塞預測技術[7];胡林等對傳統D-S 證據理論進行了改進,解決了證據的可信度問題,并將改進后的D-S 證據理論應用于車輛導航的地圖匹配中,確定了車輛位置信息和方向信息判斷規則[8]。已有的交通狀態判別方法主要分為三類,分別為:宏觀基本圖法[9]、歷史數據驅動的交通狀態識別算法[10-12]、基于實時檢測數據的交通狀態識別方法。
綜上,道路交通狀態判別相關研究已積累了豐富成果,但尚存不足:(1)利用不同類型車輛數據進行判別時,通常采用統一的交通狀態劃分標準,未考慮不同類型車輛運行的差異性;(2)基于浮動車數據的交通狀態判別研究大多只使用出租車或公交車一種浮動車數據,數據源較單一、狀態判別結果較難全面反映實際情況。而DS 證據理論能將具有差異性的數據通過不精確推理進行融合,得到更客觀、更符合實際的結果。鑒于此,本文考慮不同類型車輛運行的差異性,利用出租車、公交車、私家車3 種浮動車數據作為數據源,針對不同車種浮動車數據的差異及樣本的不均衡性,引入D-S 證據理論并對其進行改進,來融合不同車種的浮動車數據,充分挖掘其中蘊含的交通信息,實現路段交通狀態的準確判別。
1 不同車種浮動車數據特征分析
1.1 速度分布
不同類型車輛在車型尺寸、動力性能、服務對象等方面存在差異,因此其在交通流中的運行速度也各不相同。本文以重慶市江北區五紅路路段單元為研究對象,采集了各類型浮動車在“暢通-擁堵-暢通”這一連續的狀態變化過程中的速度數據,采樣時間為2018 年11 月27 日14:00—19:00,數據樣本情況如表1所示。通過數據預處理,得到以5min為時間間隔的各類型車輛速度平均值隨時間變化的趨勢圖,如圖1所示。
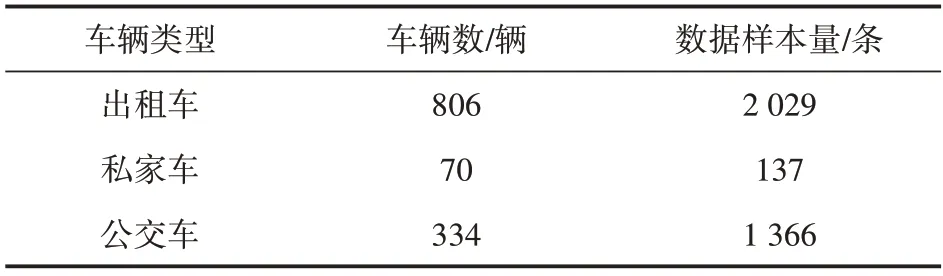
表1 各類型浮動車采樣情況
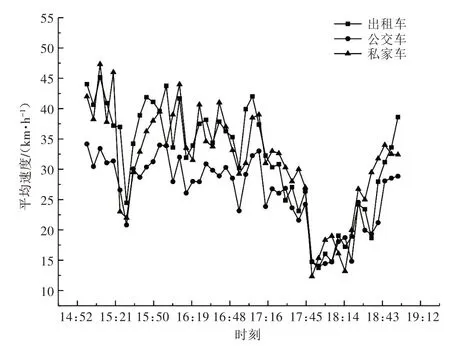
圖1 不同類型車輛平均運行速度
圖1 中,15:00—17:00 為非擁堵時段(15:30速度下降是因為發生了交通事故),17:00—19:00為擁堵時段。由圖1 可看出,不同類型車輛在平均運行速度上存在明顯差異,公交車的平均運行速度在擁堵前明顯小于私家車和出租車,擁堵時3種車輛的運行速度幾乎相同。
本文結合現有交通狀態分級類別數[13]和交通流變化情況,將交通狀態劃分為暢通、較暢通、緩行、擁堵4 個等級。通過重慶市五紅路路段單元的視頻錄像,分別對不同類型的浮動車提取各交通狀態下的車輛瞬時速度,并求其標準差,得到各類型浮動車速度標準差隨交通狀態的變化趨勢,如圖2 所示。

圖2 不同交通狀態下不同類型車輛速度標準差對比
從圖2 可看出:(1)在相同交通狀態下,不同類型車輛速度離散程度存在明顯差異,其中公交車的速度離散程度明顯小于出租車和私家車;(2)同一類型車輛在不同交通狀態下速度離散程度不同,整體均呈現出隨著交通擁堵的加劇,離散度逐漸減小的趨勢。
1.2 交通狀態劃分標準
采用模糊C-均值聚類(Fuzzy C-Means,FCM)算法確定交通狀態劃分標準,以其輸出的聚類中心值作為各交通狀態中的特征值,本文用速度表征交通狀態特征值。由于1.1 節中提及的路段單元車速數據涵蓋了從暢通到擁堵的4種交通狀態,且各狀態持續時間幾乎相同,因此,由該路段單元數據獲取的各交通狀態的特征值能較好地反映實際交通運行狀況。分別提取不同類型浮動車的速度數據進行模糊聚類,得到各交通狀態特征值(見表2)。

表2 交通狀態特征值對比
從表2 可看出,出租車與私家車的交通狀態特征值差異不顯著,兩者與公交車在暢通與較暢通狀態下特征值存在顯著差異。
1.3 樣本特征
受車輛出行隨機性和浮動車覆蓋率的影響,相同采樣間隔下不同類型浮動車數據獲取的樣本量不同,而浮動車數據樣本量與交通狀態判別結果可信度之間存在相關關系。一般情況下,樣本量越大,交通狀態的判別結果準確性越高。
數據越聚集,用于反映數據總體趨勢所需的樣本量就可以越小;數據越離散,所需的樣本量則越大。從圖2 可看出,所有類型車輛在暢通下的速度離散度均最大,因此,在進行該狀態判別時所需的樣本量也應最大。
本文提取暢通狀態下各類型浮動車的瞬時速度信息,分析各類型浮動車數據樣本量與交通狀態判別結果可信度間的關系。實驗方法采用隨機抽樣,步驟如下:
第1 步:選取暢通狀態下某一種浮動車車輛的所有瞬時速度作為抽樣的總體。
第2 步:從總體中每次隨機抽取n條數據樣本(n=1,2,…,m),每條樣本抽取次數k=100。
第3 步:針對每一次抽取的樣本量方案,計算瞬時速度平均值v。
第4 步:計算v與對應數據聚類中心的歐式距離,歐氏距離最小者對應的交通狀態即為判別出的路段單元交通狀態。
第5 步:將不同樣本量方案的交通狀態判別結果與標準狀態(暢通)進行對比,計算可信度。
第6 步:利用SPSS 軟件擬合出數據樣本量與交通狀態判別結果間的函數關系式。
第7 步:重復第1 步~第6 步,獲得3 種浮動車交通狀態判別結果可信度為100%時所需的最小數據樣本量,以及當樣本量小于最小樣本量時,交通狀態判別結果的可信度大小。
根據以上步驟,計算出3 類車輛數據樣本量與交通狀態判別結果可信度間的關系如下:

式(1)~式(3)中:Pt為出租車數據交通狀態判別結果的可信度;Pc為私家車數據交通狀態判別結果的可信度;Pb為公交車數據交通狀態判別結果的可信度;n為浮動車數據樣本量(條)。
從以上關系式可看出:①出租車、私家車、公交車用于交通狀態判別的最小數據樣本量各不相同,當交通狀態判別結果可信度為100%時,所需的最小數據樣本量分別為18 條、25 條、16條;②不同浮動車數據樣本量與交通狀態判別結果可信度之間的關系式也各不相同。
以上結果表明,不同類型的浮動車數據在運行速度分布、交通狀態劃分標準方面存在差異,因此有必要針對不同類型的數據分別確定交通狀態劃分標準,避免因標準不同而導致的交通狀態判別誤差。而針對不同浮動車數據樣本的差異性特征,在進行數據融合時應考慮樣本量導致的各浮動車交通狀態判別結果可信度。
D-S 證據理論能將具有差異性的數據通過不精確推理進行融合,得到更客觀、更符合實際的結果。因此,本文將采用D-S 證據理論進行各浮動車數據的融合,從而實現交通狀態判別。
2 D-S證據理論基本原理
假設現有一個問題需要判別,問題所有可能答案所構成的非空論域用Θ表示,Θ為識別框架,Θ={θ1,θ2,…,θj,…,θN},其中θj為識別框架的一個元素或一個事件,j=1,2,…,N,N為元素個數。在Θ中,基本信任分配函數m滿足從2Θ→[0,1]的映射關系,設A表示Θ中的任一子集,記作A?Θ,基本信任分配函數滿足如下條件[14]:

式(4)中:m(A)為事件A的基本信任分配函數,其反映了證據對事件A的信任程度;m(?)=0 表明證據對于空集的信度為0;=1 表示證據賦予所有子集的信任度之和為1[15]。
由于數據源之間相互獨立且不同的數據源檢測誤差不同,因此得到的基本信任分配函數存在差異。為提高目標檢測準確度,D-S 合成規則具備對多個獨立數據源所提供的信息進行融合的能力,該合成規則如下:

式(5)~式(6)中:m(A)含義同式(4);K表示所有證據間的沖突程度。K越大,表示證據間沖突越高;當K→1-時,為高沖突;當K<1 不成立時,證據無法合成。
3 基于改進D-S 證據理論的交通狀態判別
針對D-S 證據理論處理高沖突證據時會存在結果與常理相悖的問題,國內外學者進行了深入分析,指出造成這種不足的原因有:①證據源本身問題,證據源的基本信任分配函數本身不合理,導致融合結果錯誤;②合成規則問題,傳統D-S 證據理論的合成規則將數據源間沖突信息丟棄,導致融合結果不合理。本文考慮數據源在融合過程中自身數據的可靠性以及對數據源間沖突信息的合理分配,對D-S 證據理論從修正證據源和優化合成規則兩方面進行改進,并基于改進的D-S證據理論構建路段單元交通狀態判別模型。
3.1 改進的D-S證據理論
車輛出行的隨機性以及檢測誤差等的影響會導致在同一判別時段,不同浮動車數據源采集的樣本條數并不相等,可能出現某一種浮動車樣本極少甚至沒有的情況。如果樣本少的數據源正好出現檢測誤差,那么經由該數據源只會得出錯誤的交通狀態判別結果,會與其他數據源判別出的結果產生沖突。從樣本與交通狀態判別結果可靠度關系的研究中可看出,當數據樣本較少時,該數據判別出的交通狀態結果可靠性也較低。因此,在路段單元交通狀態判別改進模型中,可利用各數據源交通狀態判別結果可靠度對該數據源的基本信任分配函數進行修正,再利用優化后的合成規則進行數據融合,解決樣本過少的問題。本文對D-S證據理論的改進方法如下。
(1)修正基本信任分配函數
n個數據源的基本信任分配函數分別為m1,m2,…,mn,數據在融合過程中的可靠度分別為α1,α2,…,αn,則基本信任分配函數修正規則如下[14]:

式(7)中:(Aj)為修正后的數據源i對焦元Aj的基本信任分配函數;m′i(Θ)為數據源i對目標結果的不確定程度。
(2)衡量修正后函數差異性
采用綜合相似度衡量修正后基本信任分配函數的差異,綜合相似度r的計算公式[16]為:
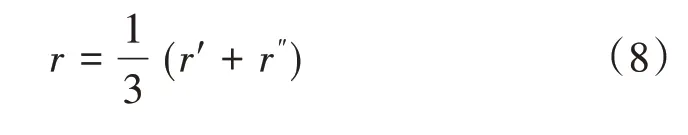
式(8)中:r′為證據間的細粒度相似度,通過模糊理論中的貼近度獲得,計算公式如式(9)[17]所示;r″為粗粒度相似度,由粗距離和Pignistic 概率轉換函數獲得,計算公式如式(10)所示[18-19]。

根據各證據綜合相似度,構造研究對象的綜合相似度矩陣R:

式(13)中:rij為修正基本信任分配函數后的證據i和證據j間的綜合相似度。
(3)確定沖突及不確定性分配權重
證據的支持度計算公式[19]如下:

式(14)中:Supi為證據i的支持度。
證據的可信度反映了在綜合考慮所有證據的支持度后,證據在融合過程中的可信程度,其計算公式如下[19]:

式(15)中:Crdi為證據i的可信度。
不確定信息的值如果大于決策中所有目標焦元的信任值,會使得決策無法進行。因此,本文將不確定信息和沖突信息一同分配到各目標焦元中。為確定權重值,本文利用Pignistic 概率轉化函數和各證據的可信度,得出所有證據對各目標焦元的綜合決策概率w(Sk)。綜合決策概率之和為1。用該概率作為沖突及不確定信息的分配權重,其計算公式如下:

(4)優化合成規則
優化后的合成規則將取消歸一化的過程,融合結果由3 部分信息組成:證據間的一致信息、沖突信息K、不確定信息C。優化后的D-S 組合規則M(S)如下:

式(17)~式(19)中各參數含義同前。
3.2 交通狀態判別模型
設S={S1,S2,S3,S4}為路段單元交通狀態類型集合,其中S1,S2,S3,S4分別表示擁堵、緩行、較暢通、暢通狀態,則模型的識別框架Θ={S1,S2,S3,S4}。出租車、公交車、私家車3 種浮動車數據源分別為模型中的證據1、證據2、證據3。
路段單元交通狀態判別模型涉及的具體步驟如下:
(1)計算各種浮動車在判別時段內的瞬時速度平均值,并統計數據樣本條數。

式(20)中:p為數據源類型,p=t,b,c分別表示出租車、公交車、私家車;np為p的采樣條數;vp,i為i時刻采集的p類型浮動車的瞬時速度(km/h);為p類型浮動車的瞬時速度平均值(km/h)。
(2)根據各類型浮動車的交通狀態劃分標準及瞬時速度平均值,各證據的基本信任分配函數mp(Sj)計算公式如下[20]:
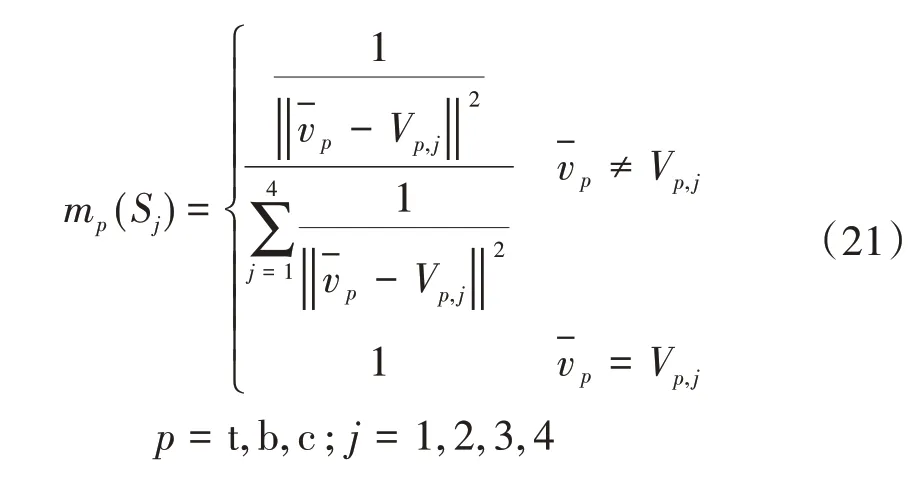
式(21)中:Vp,j為p類型浮動車在交通狀態為j時的速度聚類中心值。
(3)利用1.3 節中獲得的各浮動車判別結果準確率可信度作為融合過程中的數據可靠度,利用3.1 節提出的改進方法進行數據融合,得到融合后的交通狀態判別結果。
4 實證分析
4.1 數據準備
選擇重慶市江北區五紅路某一路段單元作為交通狀態判別效果實驗路段單元,數據采集時間為2018年11月28日14:00—19:00。交通狀態劃分標準由另一與判別路段道路屬性相似的路段單元得出,數據采集時間為2018 年11 月27 日15:00—19:00。數據樣本量如表3 所示。路段實際交通狀態根據拍攝的視頻進行人工認定。

表3 各類型浮動車采樣情況
4.2 D-S證據理論改進前后判別效果對比
選取2018 年11 月28 日14:00—19:00 三類浮動車速度分布差異較明顯時的數據對模型進行測試,該時段采集的各浮動車基本信息為:出租車、公交車、私家車浮動車瞬時速度數據樣本量分別為17 條、11 條、4 條,瞬時速度平均值分別為41km/h,30.55km/h,35km/h。該時段的實際交通狀態為暢通。
基于傳統和改進D-S 證據理論的交通狀態判別研究結果分別如表4所示。

表4 多源數據高沖突情況下判別算例結果
由表4 可知:根據出租車數據,交通狀態為暢通的可能性最大;根據私家車數據,交通狀態為較暢通的可能性最大;根據公交車數據,交通狀態為暢通的可能性最大。3 種類型浮動車數據的判別結果存在高度沖突(K=0.804,在左側靠近1)。傳統的D-S 證據理論方法得出交通狀態為較暢通,判別錯誤;本文提出的改進的D-S 證據理論由于在融合時考慮了各浮動車數據樣本量大小對融合結果的影響,并且對證據間的沖突信息進行了合理分配,得出了正確的判別結果。這表明本文提出的算法能解決傳統D-S 證據理論在融合高度沖突信息時存在的缺陷。
4.3 多算法判別效果對比
從路段單元2 的實驗數據中隨機選取67 條樣本進行模型效果評估,選取的樣本組包含了高沖突和低沖突數據,將基于改進D-S 證據理論的判別結果、基于D-S 證據理論的判別結果、基于單一數據源(出租車、公交車、私家車)的判別結果進行統計和對比分析,如表5所示。
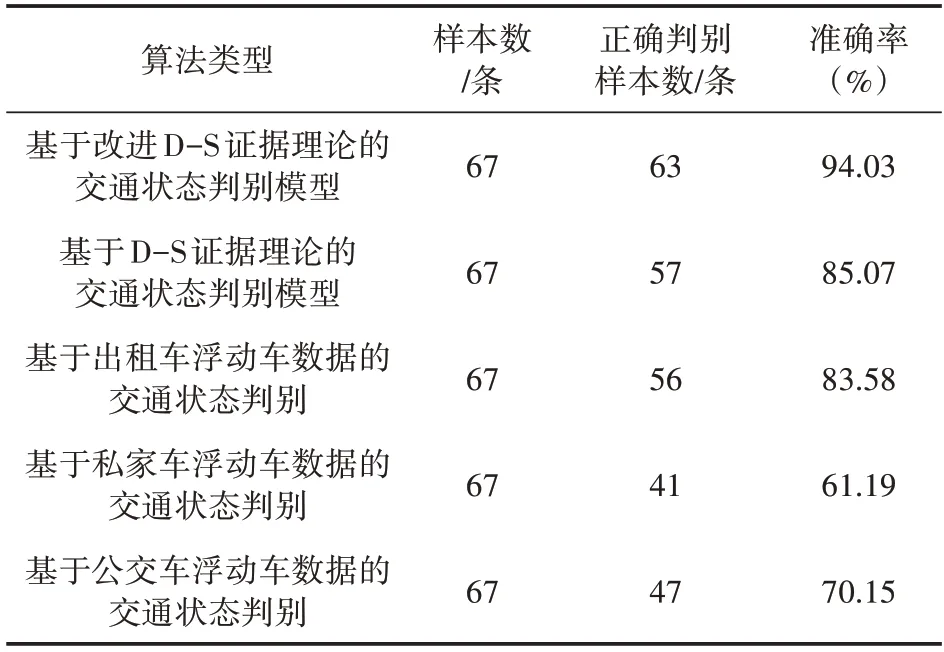
表5 各算法交通狀態判別準確率
從表5 可看出:基于D-S 證據理論的判別方法準確率相比基于單一數據源的判別方法準確率有所提升,證明了將D-S 證據理論引入交通狀態判別能有效融合不同類型的浮動車數據,提升判別準確率;基于改進D-S 證據理論的模型克服了傳統D-S 證據理論在交通狀態判別時的缺陷,判別準確率有了進一步提升。
5 結語
本文基于出租車、公交車、私家車3 種不同類型浮動車數據,構建了基于改進D-S 證據理論數據融合的路段單元交通狀態判別模型,該模型可解決不同類型浮動車數據間交通狀態判別結果高度沖突的問題。實例驗證結果表明:
(1)通過引入D-S 證據理論對不同類型浮動車數據進行融合判別,能得到比任一單一浮動車數據源更高的判別準確率,說明D-S 證據理論能有效融合具有差異性的不同類型車輛浮動車數據,提升交通狀態判別效果。
(2)本文提出的基于改進D-S 證據理論的交通狀態判別模型避免了某一數據源樣本量過小時,檢測結果中的錯誤數據給最終融合結果帶來的影響,能在一定程度上融合高度沖突的數據源信息,其判別效果相比基于傳統D-S 證據理論的判別模型有進一步提升。
本文只對路段單元整體交通狀態判別進行了研究,但部分特殊路段單元(包含公交專用道、定向車道等的路段)中不同車道的交通狀態還可能存在不均衡性,后續可對這類路段單元各車道的交通狀態判別進行研究,為交通管控提供車道級的高精度數據支持。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
