參數(shù)優(yōu)化GBDT算法的密封繼電器材質識別
2021-02-15 03:58:14呂冰澤王國濤汪國強
黑龍江大學自然科學學報 2021年6期
呂冰澤, 王國濤,2, 汪國強, 李 碩
(1.黑龍江大學 電子工程學院, 哈爾濱 150080;2.哈爾濱工業(yè)大學 電器與電子可靠性研究所, 哈爾濱 150001)
0 引 言
密封繼電器作為一種常用的航天元器件,在航天設備中起著重要的作用。因此,密封繼電器的可靠性會直接影響到航天設備的可靠性[1]。在諸多問題中對密封繼電器可靠性影響最大的就是內部多余物問題。繼電器在制作中容易將不易發(fā)現(xiàn)的鋁粒、焊錫和熱熔膠等多余物微粒混入密封腔體內部,當設備處于失重或者超重的環(huán)境下,會對腔體內部的多余物微粒產生激勵,使其產生無規(guī)則運動,微粒可能移動至組件連接處或觸點間[2]。當金屬多余物處于電路觸點時易產生電弧破壞內部結構,而非金屬多余物卡在組件連接處會使得繼電器無法正常運行導致系統(tǒng)失效[3]。
美國是最早關注多余物問題和研究微粒碰撞檢測法的國家,國內對于多余物的材質識別的研究主要集中于哈爾濱工業(yè)大學[4]。文獻[2]首次提出基于時域和頻域特征,實現(xiàn)了對金屬和非金屬多余物材質特征識別。文獻[5]提出基于學習矢量量化網絡(Learning vector quantization, LVQ)和特征級數(shù)據(jù)融合的多余物材質識別方法,對繼電器中錫粒、銅絲、橡膠和導線皮多余物進行了材質識別,但是其研究的材質識別分類器參數(shù)依靠經驗確定,材質識別模型復雜且泛化能力較差,最終并未應用于實際。文獻[6]提出了基于改進型梅爾頻率倒譜系數(shù)(Mel frequency cepstral coefficients, MFCC)的多余物材質特征識別方法,建立了多余物材質概率統(tǒng)計模型,選用多余物材質敏感頻域特征,實現(xiàn)了對導線皮、芯片、鋁和錫粒的有效識別。依據(jù)Mel濾波器設計原理和多余物信號的頻譜特征,設計了一種基于敏感頻域的Mel濾波器,提出適用于多余物信號的改進型MFCC特征提取方法,提升了多余物信號的有用信息,但是該方法缺乏實現(xiàn)設備,并沒有與多余物檢測設備結合起來,仍然未應用于實際。
綜上所述,由于目前在對多余物信號進行研究時一般使用傳統(tǒng)信號分析方法或者采用如KNN和支持向量機等經典的機器學習算法[7-8],盡管可以對多余物材質進行識別分類,但準確率還有待提高。所以,本文提出一種采用參數(shù)優(yōu)化的梯度GBDT算法對密封繼電器中的多余物進行金屬和非金屬微粒材質分類。并且在原有特征的基礎上,采用小波變換的方法提取了多余物信號能量特征。為了提高金屬和非金屬材質識別精度,加快模型訓練過程中參數(shù)優(yōu)化的效率,引入了Python中的分布式異步超參數(shù)優(yōu)化模塊Hyperopt,使用樹形評估器Parzen對基于默認參數(shù)的GBDT算法進行參數(shù)調優(yōu)。實驗表明,基于貝葉斯優(yōu)化的GBDT分類算法可以有效提高密封繼電器多余物材質識別的準確率。
1 多余物特征提取
1.1 傳統(tǒng)特征提取
受實驗環(huán)境等因素的影響,在進行顆粒碰撞噪聲檢測(Particle impact noise detection,PIND)實驗時,會采集到一部分噪聲信號隨機分布在多余物信號中,需要先去除數(shù)據(jù)中的噪聲[9]。常見的多余物信號特征一般從頻域和時域兩個部分進行提取,在頻域上目前采用短時傅里葉算法來進行多余物特征提取。主要將信號通過窗函數(shù)處理使其由不平穩(wěn)信號加以平穩(wěn),再經過傅里葉變換得到局部的頻譜特征值。在時域上,可以直觀地表現(xiàn)出信號的根本特征,本文選取了脈沖面積、脈沖左右對稱度、脈沖上下對稱度、脈沖持續(xù)時間、脈沖上升占比、能量密度、脈沖占比、波峰系數(shù)、面積占比、頻譜質心、均方頻率、方差、過零點率和均方根差14個特征。
1.2 小波變換特征提取
1.2.1 小波變換
由于短時傅里葉變換需要對窗函數(shù)進行設置,但是在實際應用中需要對窗函數(shù)的長度只能設置常見值或者進行多次嘗試,當長度較短時,會導致截取的局部頻率不夠精準;當長度過長時,會出現(xiàn)范圍過廣不能對實時變化情況作出描述的情況,所以需要一種新的方法能精確地將信號的頻譜特征加以表達。小波變換的選擇就是能對這個問題進行解決,小波變換通過對原始信號進行層級分解,在不同的層級根據(jù)所分解的信號進行適當?shù)拇昂瘮?shù)調整,這樣能夠對信號的頻譜信息更好地進行表達[10]。本文在原信號的基礎上,采用小波變換對新的特征加以提取。
在小波分析中,可以任意選擇小波基函數(shù)。本文對采集信號低頻部分連續(xù)進行3層分解,得到關于原始信號小波變換的能量特征,小波變換是一種具有低時間分辨率和高頻譜分辨率的快速算法[11]。
1.2.2 能量特征提取
小波變換主要通過小波函數(shù)來分析非平穩(wěn)信號,在材質識別中,提取金屬和非金屬微粒所包含的隱藏特征。因此,通過數(shù)值分析,計算出小波變換系數(shù)的能量值。
一維信號X(t)的小波分解[10]為:
X(t)=Gj+∑Zj
(1)
式中:G為低頻分量的近似信號;Z為高頻分量的細節(jié)信號。
一維信號X(t)與尺度函數(shù)V通過卷積運算可得到低頻的近似系數(shù)cGj(t)。一維信號X(t)與小波函數(shù)通過卷積運算可得到高頻的細節(jié)系數(shù)cGDj(l)。其近似系數(shù)和細節(jié)系數(shù)為:
(2)
小波能量系數(shù)為:
(3)
式中l(wèi)= 1,2,…,N/2j-1,N是信號長度。
選擇第3層近似系數(shù)的能量和各層細節(jié)系數(shù)的能量作為信號特征,然后構建小波能量系數(shù)特征向量模型為:
[EGj,EZ1,EZ2,···,EZj]
(4)
選擇小波系數(shù)中的雙正交(Biorthogona)小波,分別對金屬和非金屬微粒進行小波3層分解,使用式(2)分別得到1個小波近似系數(shù)和3個細節(jié)系數(shù),使用式(3)提取近似系數(shù)的能量和各層系數(shù)的能量,作為多余物微粒特征。
2 算法原理
2.1 GBDT算法
梯度增強決策樹(GBDT)是在增強算法(Boosting)的基礎上,采用梯度增強算法通過依次迭代生成決策樹,高效地解決二分類問題的方法。梯度提升的訓練目的是為了減少與上一次訓練之間的殘差,通過不斷地在梯度方向上訓練新的模型,通過逐漸降低殘差逼近目標函數(shù),最后達到誤差最小化[11-12]。在GBDT的訓練中,假設上一輪的迭代得到了強學習器是fm-1(X),損失函數(shù)是L(fm-1(X)),本輪的目標是通過訓練學習找到一個弱學習器hm(X),讓損失函數(shù)L(y,fm(X))=L(fm-1(X))+hm(X))最小,在這里一般定義 GBDT分類的損失函數(shù)為:
L(y,fm(Xi))=-(yilogρi+(1-yi)log(1-ρi))
(5)
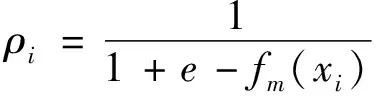
GBDT算法流程主要分為以下步驟:
步驟1:對弱學習器
(6)
進行初始化,并確定初始化函數(shù)式(7),利用損失函數(shù)式(5)計算出最佳初始值。
(7)
步驟2:對于輸入樣本m=1,2,…,M,建立出M棵決策樹,建立過程如下:
(a)對每個決策樣本i=1,2,…,M,計算其負梯度,利用式(8)確定每一輪的殘差值。
(8)
(b)將(a)中得到的殘差作為訓練數(shù)據(jù),再次對其訓練學習,得到新的決策樹fm(X),其對應的葉子節(jié)點區(qū)域為Rjm,j=1,2,…,J,其中J為決策樹m的葉子節(jié)點個數(shù)。
(c)通過函數(shù)(9)對葉子節(jié)點j=1,2,…,J計算最佳相似度,即擬合值。
(9)
該步驟會對葉子節(jié)點的殘差值進行變換,γjm表示第j個葉子節(jié)點殘差轉換值,yi表示第j個葉子節(jié)點上樣本xi的類別概率觀測值,fm-1(xi)表示第j個葉子節(jié)點的樣本xi在上一棵樹上的預測值,γ是常數(shù)(第j個節(jié)點的殘差轉換后的值)。對于每個節(jié)點都有一個最優(yōu)殘差轉換值γjm是第j個葉子節(jié)點的觀測值yi與fm-1(xi)之間的最小誤差[13]。通過損失函數(shù)對γ微分即可找到每個節(jié)點的最優(yōu)殘差轉換值。
(10)
(d)對前一輪訓練得到的強學習器進行更新,得到函數(shù)為:
(11)

步驟3:通過不斷的迭代學習,得到強學習器為:
(12)
在迭代過程中,如果損失誤差小于設定的閾值,未達到給定的迭代次數(shù),則返回式(12)繼續(xù)學習。然后算出分類的概率值與設定值對比,并將結果標記為相應的所屬類別。GBDT算法訓練過程如圖1所示,其中T表示輸入數(shù)據(jù)集,F(xiàn)(X)表示輸出梯度提升模型。
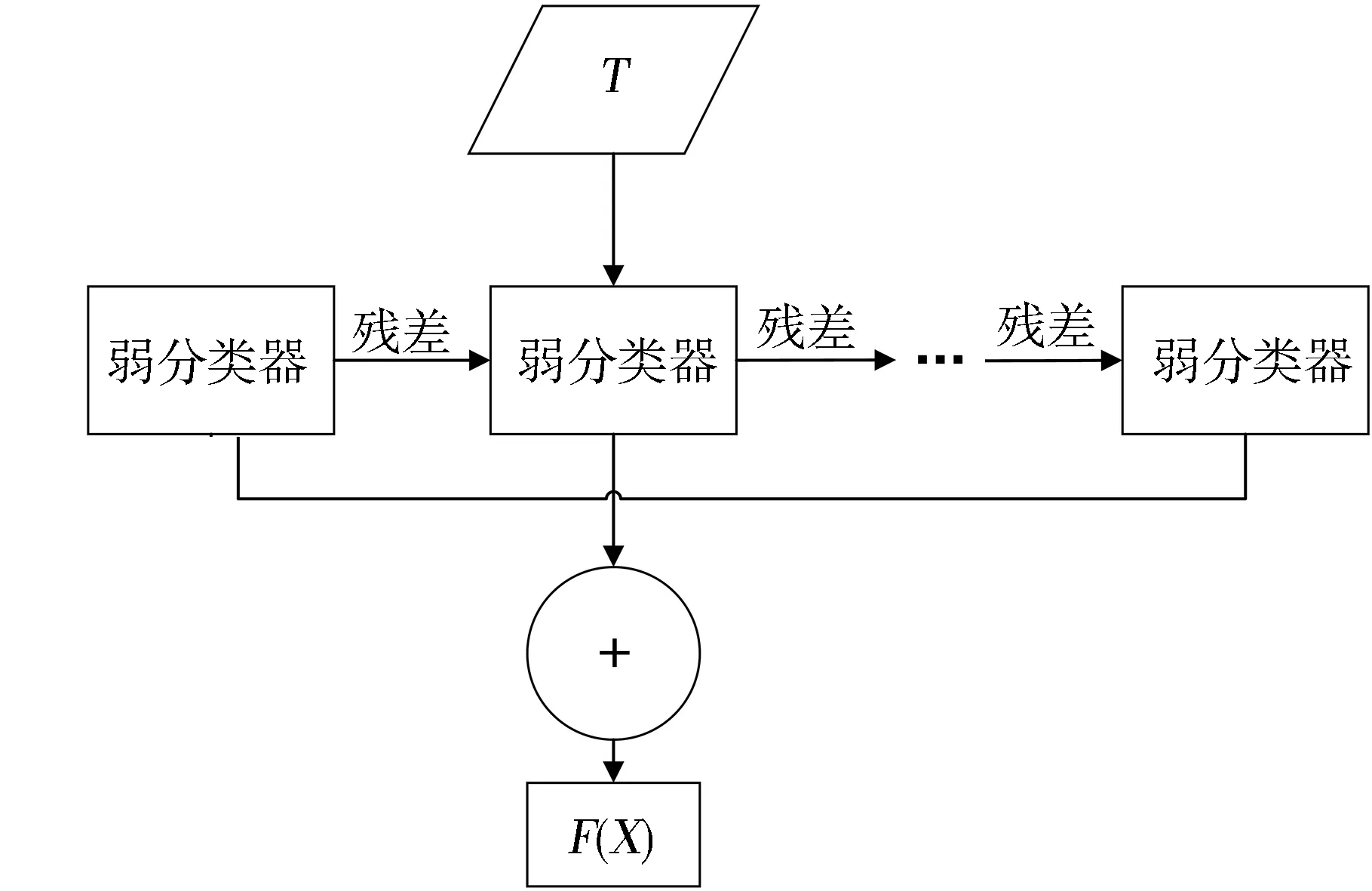
圖1 GBDT算法訓練過程
2.2 Hyperopt參數(shù)調優(yōu)
超參數(shù)優(yōu)化對機器學習算法的必要性已在許多文獻的實驗研究中都得到了證明。大多數(shù)的機器學習算法,如深度神經網絡和梯度提升模型等都需要借助優(yōu)化算法將模型性能調整至最佳。通常情況下有兩種類型的參數(shù)調試方法,網格搜索(Grid search)和隨機搜索(Random search)。網格搜索速度慢但是適用于需要隨整個參數(shù)空間進行搜索的情況;隨機搜索速度很快,但是容易遺漏一些重要信息。網格搜索調參方法在搜索空間方面效果更好,但速度較慢,而隨機搜索很快,但可能會錯過搜索區(qū)域中的重要信息。而Hyperopt使用貝葉斯優(yōu)化的形式進行參數(shù)調整,可以自適應的為給定模型獲得最佳參數(shù),在大范圍內優(yōu)化具有數(shù)百個參數(shù)的模型[14]。綜合考慮下,本文使用Python中的Hyperopt工具執(zhí)行貝葉斯優(yōu)化,從而對所建立的模型進行調參。
使用Hyperopt主要采用四個步驟:
步驟1:確定目標函數(shù)。對于所要評估的模型首先需要將其最小化,由于Hyperopt將目標函數(shù)進行“黑箱”處理,所以只是對輸入和輸出值進行處理,使得輸出為最小化的實值,找到損失最小的輸入。
步驟2:對目標模型中的超參數(shù)劃分不同參數(shù)值的空間范圍。對于貝葉斯優(yōu)化中的每個超參數(shù)來說,空間閾值的概率密度是呈離散分布的。由于不同訓練集之間的最佳模型空間范圍很難確定,因此在參數(shù)優(yōu)化時,采用多個閾值點來設定每個參數(shù)之間的邊界值。
步驟3:構造代理模型并選擇樹結構估計算法(Tree-structured parzen estimator, TPE)評估超參數(shù)值。
步驟4:將評估后的損失函數(shù)和最優(yōu)參數(shù)進行輸出。
由于GBDT算法采用Boosting框架構成,其弱分類器為CART回歸樹組合而成,所以此時首先對其弱分類器進行參數(shù)調優(yōu),對回歸樹進行修剪,在決策樹的訓練學習過程中,有些節(jié)點分類是意義不大的,而這些節(jié)點的存在不僅增加復雜度,而且減少了分類器的正確率。決策樹模型有很多超參數(shù),但不是所有參數(shù)都需要調試,主要需要調試樹的最大深度、最大葉子節(jié)點數(shù)和內部節(jié)點再劃分所需最小樣本數(shù)這幾個超參數(shù)。
3 材質識別模型構建
基于GBDT算法和Hyperopt模塊的原理介紹構建多余物材質分類模型,實現(xiàn)對多余物微粒金屬和非金屬的材質識別。由于GBDT算法以回歸樹作為基本分類器,因此,弱分類器一般選擇具有偏差較大的回歸樹模型。在迭代訓練生成決策樹時,通過不斷降低偏差來提高弱學習器集成的強學習器的模型精度。同時,預測模型的因變量是連續(xù)的數(shù)值型變量,因此,選擇平方損失函數(shù)作為模型的損失函數(shù)。
輸入:T={(x11,…,x17,y1),…,(x11,…,x17,y1)},損失函數(shù)為:
(13)
初始化弱分類器:
對式(13)中的平方損失函數(shù)直接求導,令導數(shù)等于零,得到:
(14)
式中:c的取值為所有訓練樣本標簽值的均值。對于m=1,2,…,M,對樣本i=1,2,…,n,根據(jù)式(8)計算損失函數(shù)的負梯度值,利用數(shù)據(jù)集(xi,rmi)擬合下一輪基礎模型。得到第m棵決策樹的葉子節(jié)點,并計算各葉子節(jié)點的最佳擬合值。
(15)
式(15)表示cmj的取值為第m棵樹的第j個結點中殘差的均值。
更新式(16),得:
(16)
得到新一輪函數(shù)值,結合前(m-1)輪的基礎模型,加入學習率防止模型過擬合,得到梯度提升模型函數(shù)為:
FM(x)=FM-1(x)+vfm(x)
(17)
式中v為學習率。
為了提高識別準確率,采用默認參數(shù)建立基于GBDT多余物金屬非金屬分類模型后,使用Hyperopt對其進行參數(shù)優(yōu)化提高模型整體效率[15]。為克服數(shù)據(jù)集自身造成的缺陷,還將采用k折交叉檢驗的方法。通過將整體數(shù)據(jù)集分為k份,在對模型進行訓練時,將其中K-1份進行訓練,然后將剩下的一份數(shù)據(jù)集作為數(shù)據(jù)集進行測試,對上述操作重分k次,每次采用不同份的數(shù)據(jù)集進行實驗,最終將k次檢驗的結果求均值輸出作為最終結果。
4 實驗分析
4.1 多余物材質數(shù)據(jù)集
選擇來自某型號密封繼電器采集到的一組數(shù)據(jù)集來評估該材質識別模型的有效性,采集到的主要數(shù)據(jù)集信息如表1所示,其中包括了樣本總數(shù),金屬微粒數(shù)量和非金屬微粒數(shù)量,以及數(shù)據(jù)集選擇的特征總數(shù)。

表1 數(shù)據(jù)集的主要信息
為了識別試驗效果,對處理后的數(shù)據(jù)集采用參數(shù)優(yōu)化的GBDT算法進行分類驗證。在進行實驗時,70%的數(shù)據(jù)用于訓練GBDT模型;30%的數(shù)據(jù)用來預測分類模型,評估模型的識別效果。
通常情況下,信號的特征信息越豐富,對于模型識別精度提高就越明顯。在原有脈沖面積、脈沖左右對稱度、脈沖上下對稱度、脈沖持續(xù)時間、脈沖上升占比、能量密度、脈沖占比、波峰系數(shù)、面積占比、頻譜質心、均方頻率、方差、過零點率和均方根差14個特征的基礎上,對原始信號進行小波變換得到信號頻帶分析,將計算得到的每個頻帶能量作為新特征。與本文原有特征相結合組成新的樣本數(shù)據(jù)集進行了分析,提取出的部分特征如表2所示。
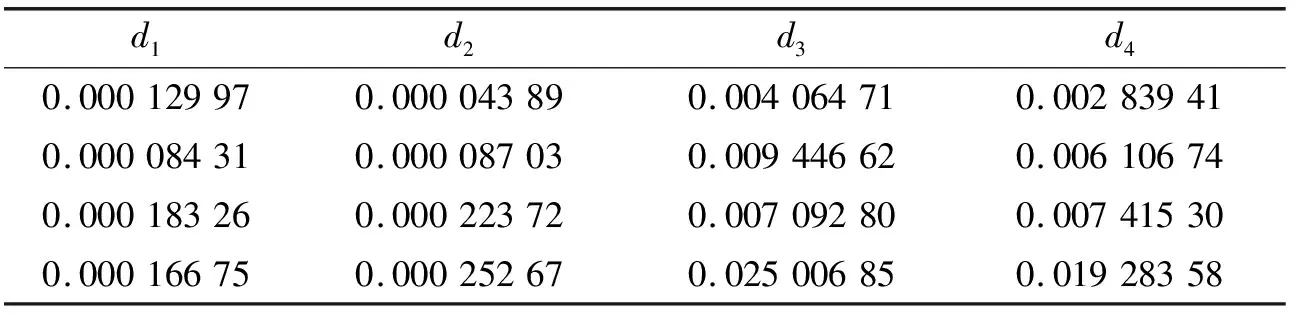
表2 小波變換部分特征集
4.2 評價指標
對于機器學習分類算法,存在樣本過擬合問題。為了更好地對模型性能加以反映,在保證了準確率不變的基礎上使用混淆矩陣評估模型調參的效果,如表3所示。

表3 二分類混淆矩陣
在對該模型進行評估時,經過各個評價指標對比,最后選擇查準率(Precison)、召回率(Recall)和F1-score三個值作為評價指標。
“查準率”是用來表示預測集中被預測正確的個數(shù),定義為:
(18)
召回率主要是查找有多少樣本能被找回公式為:
(19)
F1-score是綜合評價查準率和查全率的評價指標,為查準率和查全率的調和平均數(shù)[14]。計算方法為:
(20)
式中,β=1時,F(xiàn)1-score值一般情況下β=1。F1-score值能很好地反映二分類的分類效果。
4.3 實驗驗證
為了驗證加入小波變換能量特征后的整體特征集的識別效果,使用原有特征組合進行機器學習模型識別,結果如表4所示。

表4 原特征集測試結果
此時,模型的精確度為0.90,使用加入小波變換后的特征集采用同樣的模型進行金屬和非金屬識別,得到的測試結果如表5所示。

表5 新特征集測試結果
加入新特征后模型精確度為0.914,準確率提高1.4%。此外,由表4和表5中的判別指標對比可以發(fā)現(xiàn),對非金屬的檢測效果有所提升,證明加入小波變換的能量特征可以提高多余物材質分類精度。
本實驗采用GBDT算法進行密封繼電器中金屬和非金屬多余物材質識別,由于GBDT算法是基于Boosting框架下的集成算法,由弱分類器回歸樹(CART)組成,主要選擇貝葉斯優(yōu)化法對弱分類器中的最大深度(max_depth)和最大特征數(shù)(max_features)進行單棵樹的優(yōu)化。在Boosting框架下,n_estimators表示整個模型弱分類個數(shù),在實際參數(shù)優(yōu)化過程中,一般與learning_rate,即每個弱分類器的權重縮減系數(shù)共同進行調優(yōu)。
在訓練集上將learning_rate設置為0.5,并采用5重交叉驗證對參數(shù)n_estimators進行尋優(yōu),結果為800。再用同樣的方法對max_depth和max_features進行超參數(shù)的選擇,參數(shù)值均為5。
在進行參數(shù)選擇后,基于前面的模型構建,利用數(shù)據(jù)集分別在優(yōu)化前后的GBDT模型上進行測試。此外,為了分析GBDT模型的分類效果,分別以KNN分類模型和SVM支持向量機模型測試結果進行對比。采用默認參數(shù)進行測試得到準確率為0.902,采用Hyperopt對其進行參數(shù)優(yōu)化,得到整體模型參數(shù)優(yōu)化數(shù)值,如表6所示。
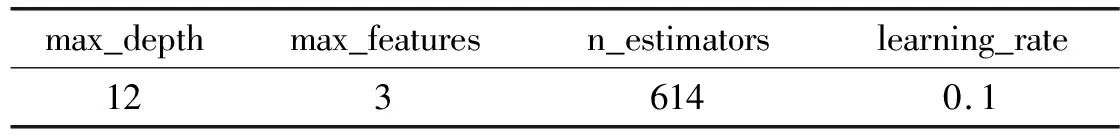
表6 模型參數(shù)優(yōu)化
參數(shù)優(yōu)化后與優(yōu)化前模型對比測試結果如表7所示。
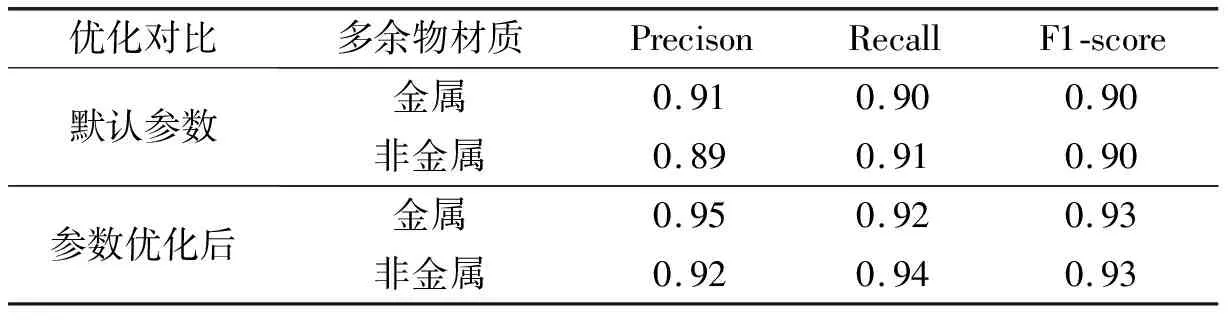
表7 默認參數(shù)測試結果
經過參數(shù)優(yōu)化后,模型整體準確率可以達到93.2%,比默認參數(shù)模型準確率提升了3.1%,此外,其他評估指標也有一定的提高。將優(yōu)化后的模型與目前常用的KNN分類模型和SVM支持向量機模型進行對比,分類準確率對比如表8所示。

表8 不同模型的分類準確率
由預測結果可以看出,參數(shù)優(yōu)化后的GBDT算法的分類準確率更高,準確率為0.932。分類結果優(yōu)于KNN、支持向量機模型和基于默認參數(shù)的GBDT分類模型。因此,參數(shù)優(yōu)化后的GBDT模型為分類結果最佳的選擇。由表9可以看出,與默認參數(shù)的GBDT算法相比,使用參數(shù)優(yōu)化的GBDT算法對金屬和非金屬微粒識別時,各項指標都有提升,這相比傳統(tǒng)的檢測方法的精確度也有一定程度的提升,尤其對非金屬識別的準確度提升較高。雖然使用SVM支持向量機算法的二分類各項指標也能很好地反映金屬微粒和非金屬微粒分類效果,但由于泛化性較低,因此,使用參數(shù)優(yōu)化的GBDT算法能夠有效地提升金屬微粒和非金屬微粒的準確度。
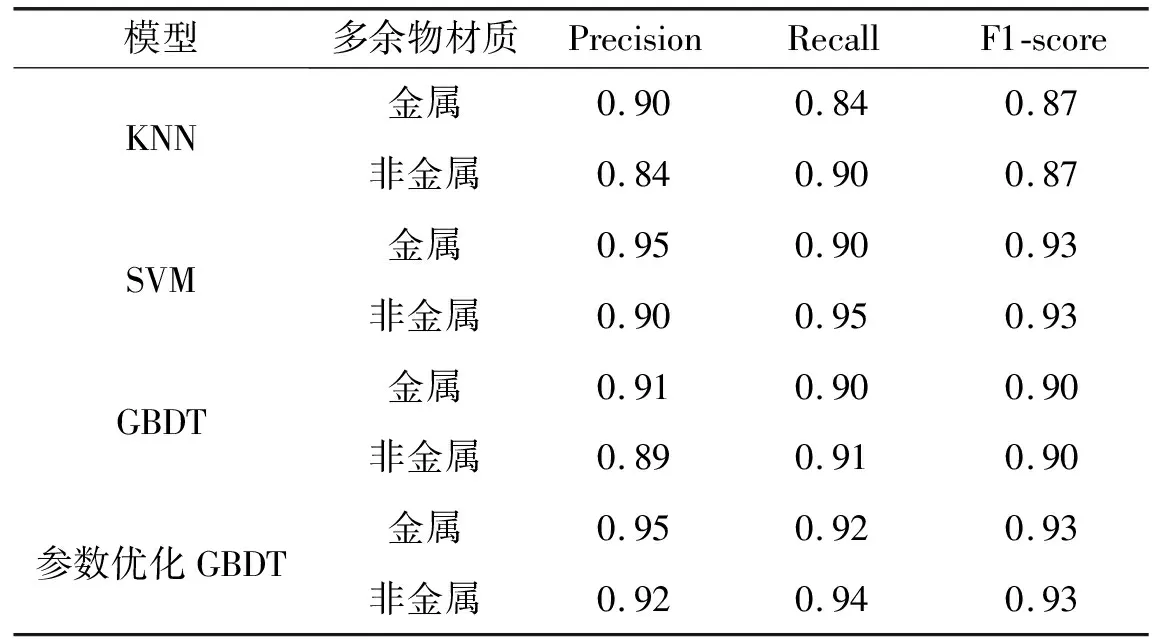
表9 評估指標值
5 結 論
采用貝葉斯參數(shù)優(yōu)化的GBDT算法對航天密封繼電器內部的金屬和非金屬微粒進行材質識別。在原有特征的基礎上,利用小波變換提取了能量系數(shù)作為特征值。實驗驗證,加入新特征后模型識別準確率提升了1.4%。根據(jù)GBDT算法流程建立了材質識別的分類器模型,并使用Hyperopt模塊的TPE評估器對多余物微粒識別模型進行超參數(shù)調優(yōu)。實驗結果表明,調參后的GBDT算法具有更好的分類效果,分類準確率提升到93%,提升了3.1%。同時,3個評價指標相對于KNN分類模型和SVM支持向量機模型也有一定的提升,其中精確度、召回率和F1-score值均提升超過了3%。此方案可以提高密封繼電器金屬和非金屬微粒的識別準確率。通過對多余物的材質信息更準確的識別,還可以改善多余物的生產環(huán)節(jié),進一步推動相關材質的改進,提高整個航天系統(tǒng)的可靠性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
