基于隨機森林的單粒玉米種子水分近紅外快速定量檢測
2021-02-18 05:28:54吳靜珠李江波劉翠玲孫曉榮
中國糧油學報 2021年12期
(張 樂 吳靜珠 李江波 劉翠玲 孫曉榮 余 樂
(北京工商大學食品安全大數據技術北京市重點實驗室1,北京 100048)
(北京農業智能裝備技術研究中心2,北京 100097)
玉米是目前我國種植面積最廣、產量第一的農作物,不僅是“飼料之王”,還是重要的工業原料[1]。近年來隨著美國先鋒公司“單粒播”玉米種子的推出[2],以及歐美等發達國家的玉米機械化單粒精量播種技術的引入,我國傳統玉米播種模式發生了深刻的改變[3]。單粒精量播種技術較傳統播種模式更有利于機械化操作,省工、省種、高產,但是對每顆種子都提出了更高的檢測需求,其中單粒播種的玉米種子含水量不能高于14%,否則會導致種子呼吸增大、消耗養分、活力下降[4]。根據GB 4404.1—2008[5],水分是我國農作物種子質量四大必檢項目之一。因此單粒玉米種子水分的快速、高通量、無損檢測對于單粒精量播種具有重要的現實意義。
GB/T 3543.6—1995《農作物種子檢驗規程水分測定》中規定了種子水分測量方法有低恒溫烘干法、高溫烘干法、高水分預先烘干法[6],這些方法測試精度高但普遍存在試樣破壞性、耗時長、無法單顆測定等問題。近年來,近紅外光譜(Near Infrared Spectrometry,NIR)技術以其快速、無損、綠色分析特點在種子質量檢測領域展開了大量深入研究[7-9]。GB/T 24900—2010[10]用于玉米種子批水分的測定,表明近紅外光譜技術在玉米種子批水分檢測領域具有實際應用可行性,但是目前鮮有針對單粒種子水分近紅外檢測的方法或標準等。
隨機森林(Random forest, RF)具有許多其他傳統的機器學習方法無法比擬的優點,不需要顧慮一般回歸分析面臨的多元共線性的問題,便于非線性數據處理[11]。邵琦等[12]基于隨機森林算法,在有效波段和紋理信息特征組合下,能充分利用高光譜圖像的光譜和紋理信息,準確地鑒別玉米品種,為玉米品種的自動識別提供了一種新方法。王麗愛等[13]利用隨機森林回歸算法構建每個生育期的小麥葉片SPAD(Soil and plant analyzer development)值遙感反演模型,并以基于支持向量回歸和反向傳播神經網絡算法構建的模型作為比較模型,以R2(coefficient of determination,R2)和均方根誤差為指標,結果表明,RF-SPAD模型在3個生育期都表現出最強的學習能力和預測能力。李盛芳等[14]使用隨機森林對不同種類的水果(蘋果、梨)糖分進行預測。實驗表明,對于同一種類的水果,RF和PLS(Partial least squares)的建模和預測結果均較好。但對于不同種類的水果,RF明顯增加了模型的預測能力。
近紅外光譜結合隨機森林算法在農作物、瓜果定性鑒別以及定量預測組分濃度都具有較好的應用效果。但是近紅外光譜技術結合隨機森林算法鮮有應用于檢測單粒玉米的水分,因此本研究重點探索將近紅外光譜與隨機森林算法相結合建立性能優秀的單粒玉米種子水分快速、無損檢測定量檢測模型,以期為玉米精量播種技術的推廣和發展探索可行的檢測手段。
1 材料與方法
1.1 實驗材料
本實驗玉米樣本購于種子市場,共計購買55組樣本,品種包括中地77、沈玉29、中地168、強碩68、奔誠15和春育8。從每組樣本中分別選取2個玉米籽粒,共計110份玉米樣本。首先采用單籽粒采樣附件掃描近紅外光譜后, 再使用HB43-S鹵素水分測定儀測定每組樣本水分。
表1為110份玉米樣本的含水量統計信息。按照3∶1的比例隨機進行劃分訓練集和測試集,其中訓練集樣本82份,測試集樣本28份。

表1 樣本集統計信息
1.2 光譜采集
本實驗采用VERTEX 70傅立葉變換紅外光譜儀,及直徑為 2. 5 cm 的單籽粒采樣附件采集單粒玉米種子光譜。為減少裝樣引起的干擾,放樣本時統一將樣本胚面朝下,樣本尖端朝向一致。儀器參數設定如下:波數范圍為4 000 ~ 12 500 cm-1,分辨率為8 cm-1,掃描次數為64次。樣本近紅外光譜如圖1所示[15]。由于不同顆粒的玉米種子表面平整度不一且種子形態、種皮性質均存在明顯差異,導致光譜采集過程中光反射、散射影響程度不同,從圖1中也可以看出,樣本集近紅外光譜在整個譜區范圍內離散度較大。但是所有樣品的光譜趨勢基本一致,玉米近紅外光譜在波數為8 400、7 000、5 000 cm-1附近有3個明顯的特征峰。水分子由兩個氫原子和一個氧原子結合而成的結構使得水分子具有多個原子鍵振動能級,水的近紅外吸收譜分布較寬。其中波數為7 000 cm-1處的特征峰主要為氫氧鍵伸縮振動的一級倍頻,8 400 cm-1處的特征峰為氫氧鍵伸縮振動的一級倍頻和合頻,5 000 cm-1處的特征峰也為氫氧鍵伸縮振動的合頻[16],這些特征峰均明顯地反映了玉米種子中的水分子對不同波長的近紅外光的吸收程度。
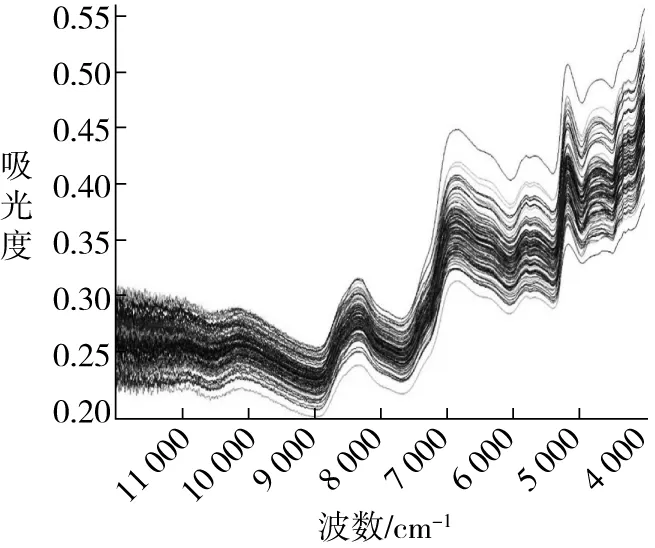
圖1 樣本集近紅外原始光譜
1.3 數據處理方法
1.3.1 光譜預處理
由于復雜樣品光譜信號往往會受到雜散光、噪聲、基線漂移等因素的干擾[17],樣品粒徑是影響光譜測量的一個重要參數,隨著樣品粒徑的增加,所測光譜的重現性變差,光譜的變動性隨粒徑的增加呈指數形式增加。每顆玉米籽粒形狀、直徑都不相同,所測光譜差異性變大,造成測量誤差無法消除[18],從而影響最終的定量分析結果。因此為了降低由種子形態等引起的光譜噪聲干擾,采用合適的光譜預處理方法提升光譜質量是必要的。選用Savitzky-Golay卷積求導法 (SG7_2)、均值中心化(mean centering, MC)、歸一化(Normalization,NOR) 、標準正態變量變換(Standard normal variate transformation,SNV)、多元散射校正(Multiplicative scatter correction,MSC)方法分別進行數據預處理。
1.3.2 光譜降維
在實際應用中,近紅外光譜數據量通常較大,具有一定冗余性,因此對近紅外光譜降維就變得尤為重要,本研究采用主成分分析和去噪自編碼器兩種光譜降維消噪算法在預測模型上的效果。
主成分分析(Principal Component Analysis,PCA)是一種常用的數據分析方法,通過線性變換將原始數據變換為一組各維度線性無關的表示,可用于提取數據的主要特征分量,這些主要特征分量就稱之為主成分,常用于高維數據的降維[19]。然而,PCA作為一種線性算法,不能有效地降低非線性數據集的維數。PCA的線性特征組合會丟失原始數據中的大量有用信息[20]。
去噪自編碼器(denoising auto encoder,DAE)是由輸入層、隱藏層和輸出層三層結構組成的神經網絡。在自動編碼器(Auto Encoder,AE)的基礎上,通過向輸入中注入噪聲,然后利用含噪聲的樣本去重構不含噪聲的輸入,這種訓練策略也使得DAE能夠學習到更能反映輸入數據的本質特征。DAE在訓練過程中,采取無監督學習機制和有監督微調的方式,它使用了反向傳播算法,通過逐層訓練,使輸出值與輸入值相等。DAE的意義在于學習的最中間的隱層,這一層是輸入向量的良好表示,可以用于原始數據的降維,起到特征學習的作用。
1.3.3 隨機森林回歸
隨機森林是一種基于分類樹的算法,它使用觀測數據的子集和變量的子集來建立一個決策樹,再建立多個這樣的決策樹并集成,提高了模型更穩定的預測能力。隨機森林的決策樹選擇的是CART算法,即利用基尼指數最小化準則進行特征選擇,CART既可以處理分類,也可以用于回歸。最優特征選擇原則是采用和方差度量,度量目標是對于劃分特征A,對應劃分點s兩邊的數據集D1和D2,求出使D1和D2各自集合的均方差最小,同時D1和D2的均方差之和最小。表達式為:
(1)
式中:c1為D1的樣本輸出均值;c2為D2的樣本輸出均值。
隨機森林模型中的生成決策樹數目(ntree)和選擇分裂屬性個數(mtry)直接影響結果的準確性,通常對ntree和mtry的選擇采用嘗試方法,從而獲得比較適合的值[21]。
RF算法的優點體現在:學習過程較快;對于大規模數據集,是一種高效的處理算法,且對數據集中的噪聲有較強的魯棒性;不需要另外預留部分數據做交叉驗證;相對于偏最小二乘法、多元線型回歸法等方法,隨機森林回歸方法對非線性數據的解析能力較強[14]。
2 結果與討論
2.1 基于不同預處理方法的全波段光譜的建模對比
采用 Matlab 2018b 軟件進行數據處理及建模。由于采集單粒玉米種子光譜時,引入了顆粒形態等噪聲的非線性干擾,因此本研究選用隨機森林回歸方法建立預測模型,利用Matlab軟件中的RandomForest 工具箱,根據經驗及多次實驗,確定模型中ntree、mtry這2個參數分別取100和4。結果見表2。

表2 基于不同光譜預處理的RF模型預測效果比較
由表2可以看出,經過不同預處理后的光譜建模結果有所差異。卷積求導并不適用于單粒玉米種子光譜數據預處理,單粒種子光譜本身含有的噪聲較大,求導更加劇了噪聲的引入,因此大大降低了模型的準確性;多元散射校正可以有效消除近紅外漫反射光譜中由于樣品的鏡面反射及不均勻造成的噪聲[23],消除光譜的基線漂移現象及光譜的不重復性,多元散射校正方法是現階段多波長標定建模常用的一種數據處理方法, 經過散射測試后得到的光譜數據可以有效地消除散射的影響, 增強了與成分含量相關的光譜吸收信息[24],因此基于多元散射校正相對其他預處理方法而言,建立的單粒種子水分模型性能較好,其訓練集的相關系數為0.986 2,訓練集均方根誤差(Root Mean Square Error of Correction Set,RMSEC)為0.141 4;測試集的相關系數為0.968 9,測試均方根誤差(Root Mean Square Error of Prediction,RMSEP)為0.445 7。
2.2 基于光譜特征的RF建模分析
由近紅外全波段 RF建模結果可知,全波段光譜對單粒玉米種子水分具有較好的預測效果,但由于其光譜數據量龐大,含有較多的冗余信息和共線性變量,影響模型的預測能力和高效性。因此將經過MSC預處理后的110份樣本近紅外光譜,每份樣本光譜包含的2 074個波段,分別作為PCA、DAE光譜降維消噪算法的輸入變量,去掉自變量之間具有強線性相關的冗余變量。最后,基于重新組合的特征變量分別建立隨機森林回歸模型,并對模型進行檢驗分析,結果見表3。

表3 基于不同變量篩選方法的RF模型預測效果比較
研究結果表明,在光譜降維消噪方法分析中,DAE-RF模型效果比PCA-RF更好,DAE-RF測試集的R較全波段RF模型提升了1.39%, RMSEP較全波段RF模型降低了5.63%, 對比PCA-RF測試集的效果反而不如全波段RF模型。這是因為PCA 是輸入空間向最大變化方向的簡單線性變換,而自動編碼器可以對相對復雜的非線性關系進行建模。并且PCA將變量降維到四維,僅占原特征變量數的0.19%,可能遺漏了原始數據中的大量有用信息,而最佳光譜降維消噪方法DAE重新組合了100個光譜特征,占原特征變量數的4.82%。由DAE的算法原理與特點可知,這種方法在降維的基礎上,既能保留原始輸入數據的信息,又能確保獲得一種有用的特征表示[24]。因此在處理引入了非線性干擾的單粒玉米種子水分近紅外數據時,去噪自編碼器效果更好。
3 結論
本研究首先采用多種光譜預處理方法消除單粒種子采集光譜時由于顆粒形態等引起的噪聲干擾,然后比較建立了基于RF模型的單粒玉米種子水分近紅外檢測模型。隨后利用2種光譜降維消噪方法PCA、DAE選出與玉米種子水分相關的波段,并建模比較預測效果。實驗結果表明,相對其他預處理方法而言,多元散射校正處理后建立的單粒種子水分模型性能較好,其訓練集的R為0.986 2,RMSEC為0.141 4;測試集的R為0.968 9,RMSEP為0.445 7。進一步對比光譜降維消噪方法,基于DAE的模型效果更好,其訓練集的R為0.988 5,RMSEC為0.175 31;測試集的R為0.982 4,RMSEP為 0.420 6。本研究將近紅外光譜技術、光譜預處理、光譜降維消噪和RF算法相結合,可以有效降低單粒玉米種子近紅外光譜采集時引入的非線性干擾,有助于提升單粒玉米種子水分近紅外快速無損檢測實際應用可行性,有望為玉米精量播種技術的推廣和發展提供可行的檢測手段。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
