基于卷積神經網絡和支持向量機的水稻種子圖像分類識別
2021-02-18 03:25:20楊紅云孫愛珍王映龍肖小梅羅建軍
中國糧油學報 2021年12期
(楊紅云 黃 瓊 孫愛珍 王映龍 肖小梅 羅建軍
(江西農業大學軟件學院1,南昌 330045)
(江西農業大學計算機與信息工程學院2,南昌 330045)
水稻是我國種植面積最大的農作物,加強水稻生產技術可以有效促進農業發展和提高國民經濟,而水稻種子的純度是影響水稻生產重要因素。水稻種子純度差會造成水稻的發芽率、成苗率、抗病性和豐產性等多項指標下降,因此采用稻種品種的單粒鑒別是有效保證種子純度質量、糧食安全和農業生產安全的重要手段。經典的農作物品種鑒定方法有人工目測法、化學鑒定及熒光掃描等,以上方法因隨意性大、效率低、鑒定成本高和易對環境產生污染難以在實際生活中得到普遍推廣,因此迫切需要探索一種高效環保的識別方法來選育出優質的稻種品種以提高水稻生產質量。
機器視覺具有成本低,客觀性強等優點,利用機器視覺對水稻種子進行識別可彌補傳統識別方法的不足,目前已普遍應用在農作物種子識別方面。很多研究者[1-4]通過獲取光譜信息和圖像信息結合SVM、RF模型來識別農作物種子品種,識別率普遍較高,但高光譜儀的成本高,不利于實際推廣,而通過獲取圖像數據特征可降低成本。如部分研究者[5,6]通過利用BPNN對水稻種子的顏色形狀特征進行分類,識別準確率較高。 Mebatsion等[7]利用最小二乘法對5類麥種的形狀和顏色特征進行分類,準確率為99.6%。吳尚智等[8]利用粗糙集和BP神經網絡相結合的方法對麥種進行分類,識別準確率可達到95.24%。這些方法都是通過獲取圖像的顏色或形狀等數據后采用分類器進行分類,獲取方法成本較低,但特征選擇具有經驗主觀性且算法繁瑣,不能實現直接端對端的稻種圖像識別,不具便捷性。近年來,卷積神經網絡憑借強大的特征提取功能在圖像領域取得了成效,與傳統的圖像外觀特征相比,學習的深度特征是對輸入圖像的語義描述,因而可對外觀特征起到替代或補充作用。端對端的深度學習不需要前期繁瑣的人工特征設計和提取,在實踐中更容易實現。如祝詩平[9]采用卷積神經網絡的4種經典模型對麥種進行識別,得出這4類模型明顯優于SVM和BP的傳統模型。
本研究利用卷積神經網絡泛化能力強且速度快的優點直接從水稻種子圖像獲取顯著信息,省略對圖像數據的預處理操作,更加便捷。將泛化能力強且計算量小SVM替換Softmax分類器對提取的圖像特征進行分類能夠減少識別時間且提高識別正確率。將CNN_SVM與SVM、KNN、HOG_KNN/SVM、LBP_KNN/SVM、SIFT_KNN/SVM和CNN_KNN/Softmax10種模型進行對比分析,其中,CNN能高效準確地提取水稻種子圖像的有效信息,結合SVM后能高效識別8類水稻種子。利用CNN_SVM模型對不同年份的水稻種子數據庫和加入噪聲的數據庫進行識別后依然有較高的識別正確率,表明本文模型識別不同年份水稻種子的高效性和能適應識別環境的變化,具有良好的泛化性。
1 材料與方法
1.1 數據采集
8種水稻種子:楚粳7號、鄂豐絲苗、馬壩油粘、玉楊糯、玉針香、兵兩優401、五鄉優398、泰優398。在人工選樣過程中,去除破碎干癟的雜質,選取每類顆粒飽滿的水稻種子各200粒進行研究。在自然光照的環境下,以黑色卡紙為背景隨機擺放水稻種子,為增加數據獲取的多樣性,選用佳能EOS 60D型數碼相機垂直對單粒水稻種子圖像(圖1)和多粒水稻種子圖像(圖2)進行拍攝。
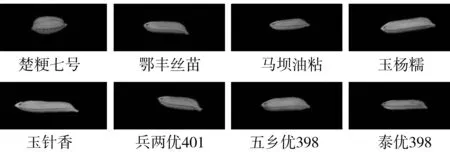
圖1 單粒水稻種子圖像
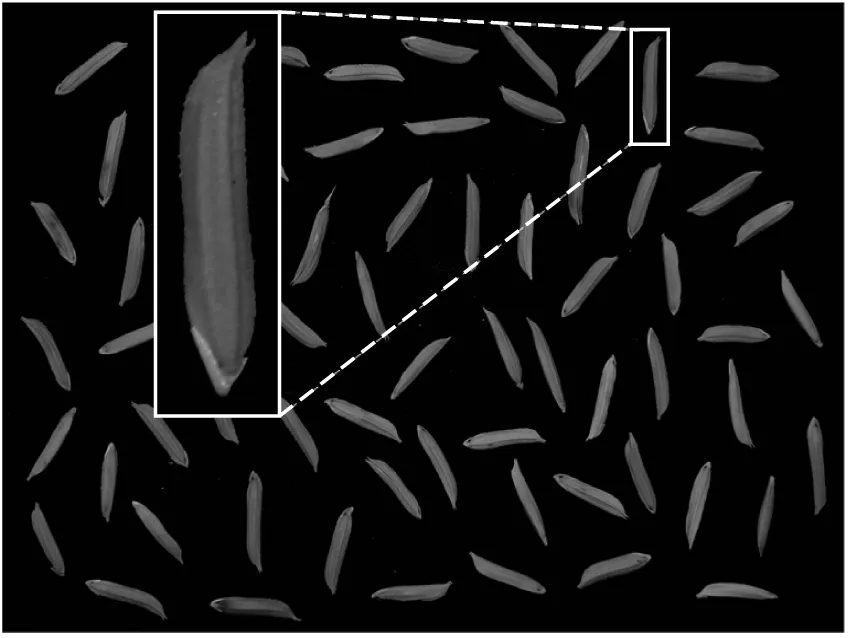
圖2 多粒水稻種子圖像
1.2 圖像預處理
為保證種子的純度,采用單粒鑒別對水稻種子圖像進行分類識別,因此需要將單粒水稻種子圖像從多粒圖像中切割出來,切割方法為首先對水稻種子圖像進行灰度化和高斯模糊等操作去除圖像噪聲,再采用Canny算子提取水稻種子的邊緣,通過輪廓檢測算法提取出每粒水稻種子的輪廓,采用最小外界矩陣法得到水稻種子最小外接矩陣的長寬以及四個頂點坐標,最后通過獲取的各項參數將單粒水稻種子圖片進行旋轉操作,為了保證水稻種子的完整性,將最小外接矩陣向外擴展20個像素點切割出單粒水稻種子圖片。
針對樣本小帶來的泛化能力不足問題,采用隨機翻轉、旋轉(30°、-30°,60°、-60°、90°)和調節亮度來對圖像樣本進行擴增,將數據集擴展到原來的5倍,每類水稻種子樣本圖像為1 000張。
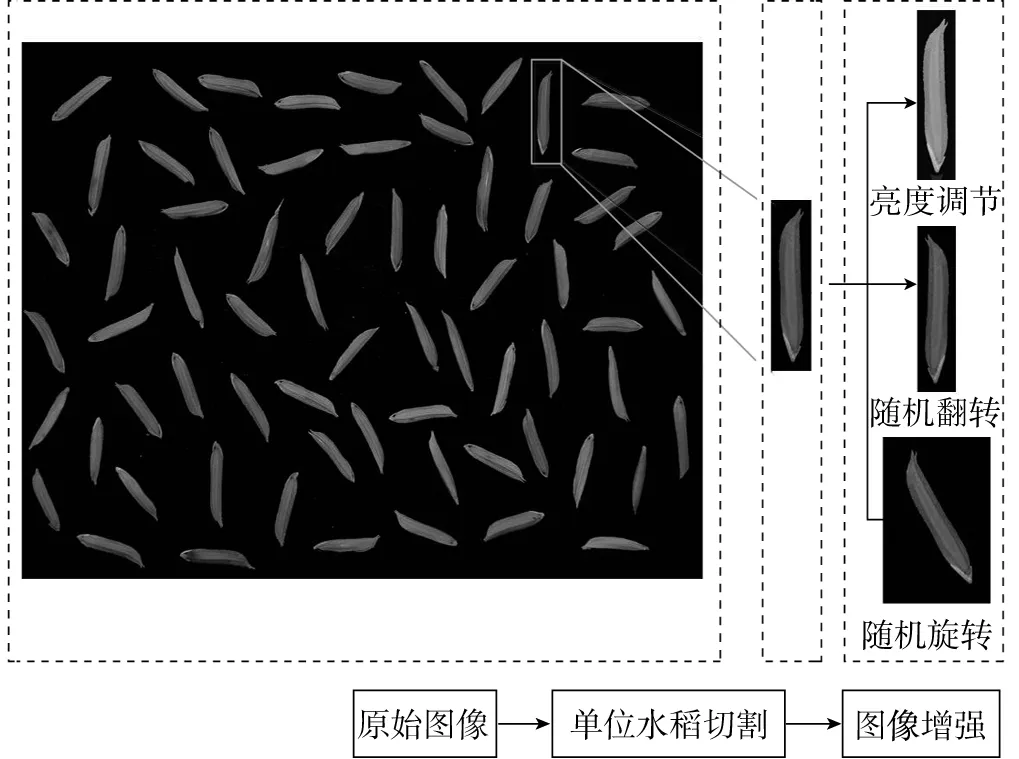
圖3 圖像預處理
1.3 卷積神經網絡
卷積神經網絡[9-12]于1998年由紐約大學的Yann LeCun提出,它是通過多層感知機(MLP)演變而來。一般情況下,CNN的架構是由輸入層、卷積層、池化層、全連接層和輸出層組成,如圖4所示。其中卷積層是實現卷積神經網絡特征提取功能的核心,相當于特征提取器,池化層能夠壓縮數據和參數的量,提取出圖像中的重要特征,進而壓縮圖片。全連接層的輸入是將卷積層和池化層提取的特征進行加權,將特征空間將特征空間通過線性變換映射到樣本標記空間。

圖4 CNN基本架構圖
1.4 支持向量機
支持向量機[13-15](Support Vector Machine,SVM)是通過核函數將樣本集向量映射到一個高維特征空間,在該空間中隨機產生一個超平面并不斷移動對樣本集進行分類,直至不同類別的樣本點正好位于該超平面的兩側,滿足樣本集分類的超平面可能有多個,從中尋找到能使超平面兩側距離最大化則為最優決策超平面,能對分類問題提供良好的泛化能力。
假設訓練樣本集D={(X1,Y1),(X2,Y2),……,(xm,ym)},在樣本空間中,將樣本分開的超平面可由公式(1)表示:
wTx+b=0
(1)
式中:w為法向量,決定超平面的方向;b為位移項決定超平面原點距離;x表示空間中的任意點。
通過等比例地縮放w和b的值,可以使得兩類到超平面的距離最大,得到SVM的基本型如公式(2)所示。
s.t.yi(wTxi+b)≥1,i=1,2,……,m
(2)
1.5 CNN_SVM模型
基于CNN_SVM模型的水稻種子識別算法步驟為:通過最小外矩陣從水稻種子圖像中切割出單粒種子的圖片,進行隨機翻轉、旋轉和亮度調節從而擴增樣本集,其中80%為訓練樣本,20%為測試樣本;選擇能快速準確提取特征的卷積神經網絡網絡來提取水稻種子的圖像特征,將SVM分類器代替Softmax分類器組成CNN_SVM模型對圖像特征進行分類,其架構圖如圖5所示;將CNN_SVM模型與HOG、LBP、SIFT與KNN、SVM結合的模型,CNN_Softmax以及CNN_KNN進行分類正確率和識別時間的對比分析;采用CNN_SVM模型在3個數據集上進行實驗對比:原始數據集(OR-Dataset)、不同年份水稻種子形成的數據集(DYR-Dataset)以及加入噪聲點后形成的數據集(NR-Dataset))。
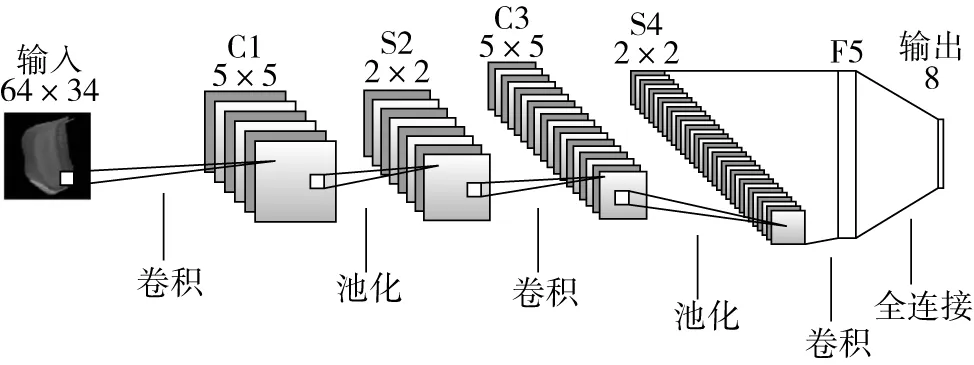
圖5 CNN_SVM模型
2 結果與分析
圖像處理和分析實驗的軟件環境是基于Tensorflow為后端運行的Keras深度學習框架,以Python為編程語言,再PyCharm搭建模型。硬件配置是處理器為Intel(R) Core(TM) i5-6200U CPU,運行內存為8 G。
2.1 卷積神經網絡特征提取可視化
利用卷積神經網絡自動獲取水稻種子圖像的顏色、紋理以及形狀特征,并且將其特征提取過程可視化,如圖6所示。其中圖6a為64*64水稻種子圖像,圖6b為第一層卷積提取的前15張水稻種子特征圖像以及將該層各個特征圖像按1∶1疊加的綜合特征圖,圖6c為第二層卷積提取的前15張水稻種子特征圖像以及將該層各個特征圖像按1∶1疊加的綜合特征圖。

圖6 CNN特征圖
從圖6可以看出,通過卷積神經網絡提取的特征是具有辨別性的特征,它能使水稻種子圖像中的無關背景被忽略,進而把關鍵信息給提取出來。從第一層卷積神經網絡提取的特征圖像可以看出,該層學習的特征基本上是一些邊緣等底層特征;從第二層卷積神經網絡提取的特征圖像可以看出,該層可以提取一些更加完整和區別性的復雜特征,例如紋理特征。可以得到,隨著卷積層的增加,提取的特征詳細度與之成正比,但是過多的卷積層會造成數據的冗余,本文選取了大小適中的兩個卷積層作為此次實驗的研究基礎。
2.2 各模型的識別正確率
本實驗采用圖像識別正確率和平均識別一張圖片的時間對各算法進行評估,圖像識別正確率見式(3)。
(3)
式中:a為圖像識別正確率;n為識別正確的圖像數量;N為進行識別的總的圖像數量。
為了驗證CNN_SVM模型的高效性,選取SVM、KNN、HOG_SVM、HOG_KNN、LBP_SVM、LBP_KNN、SIFT_SVM、SIFT_KNN、CNN_KNN和CNN_Softmax10種模型與之對比,如表1所示。
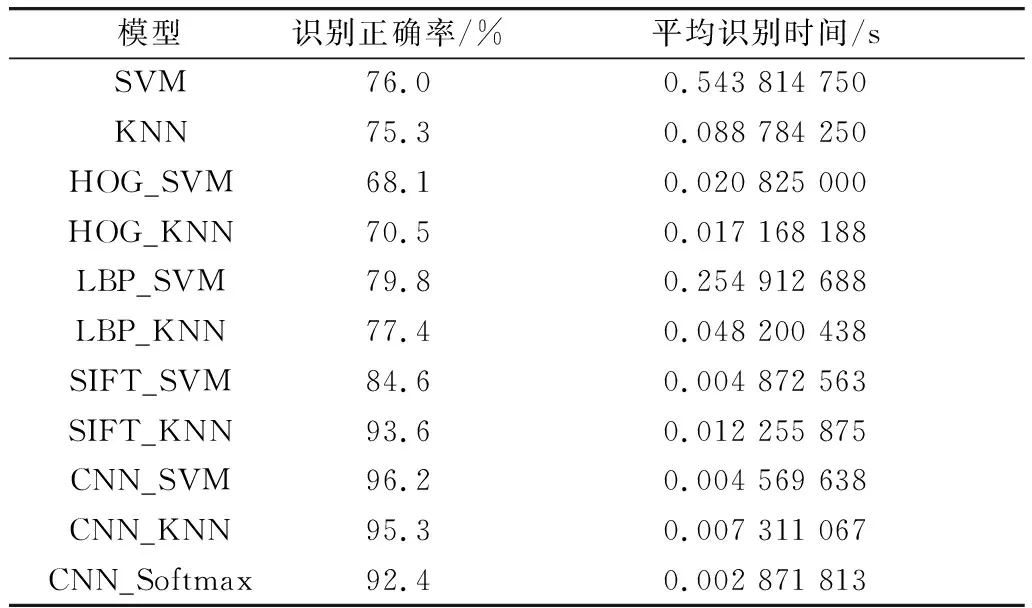
表1 各模型的識別正確率和平均識別時間
從表1可以看出,未經過任何特征提取的SVM、KNN原模型在在運行時間上較長,且識別正確率不高;通過提取HOG特征與SVM和KNN模型相結合能在運行時間上有一定的縮短,但是識別正確率卻降低了;相較于SVM和KNN原模型,通過提取LBP特征能在識別正確率和識別時間上面有所提高,其中,LBP_SVM相較于SVM模型識別正確率提高了3.8%,LBP_KNN相較于KNN模型識別正確率提高了2.1%; 通過提取SIFT描述子與KNN、SVM模型相結合,可以看出運行效率有一定的提高,SIFT_SVM相較于SVM模型識別正確率提高了8.6%,SIFT_KNN相較于KNN模型識別正確率提高了18.3%;通過CNN提取圖像特征與SVM和KNN相結合后的模型能較大提高識別正確率和縮短運行時間:CNN_SVM模型相較于SVM模型識別正確率提高了20.2%,相較于CNN_Softmax模型識別正確率提高了3.8%,CNN_KNN模型相較于KNN模型識別正確率提高了20%,相較于CNN_Softmax提高了2.9%。通過比較11種模型,可以看出CNN_SVM有更高的識別正確率,在運行效率方面明顯優于其他10種模型。
2.3 NR數據集和DYR數據集的識別正確率
因外表氧化原因,不同年份的水稻種子在色彩方面會有一定的誤差。年份較近的水稻種子色彩飽和度高,顏色更鮮艷;年份較遠的水稻會因為氧化問題變得發灰發白,從而色彩飽和度會更低。本實驗通過調整水稻種子的色彩飽和度模擬了5種不同年份的水稻種子,如圖7所示,圖7a~圖7e表示水稻種子隨著年份的增長顏色會逐漸變淺,最后為淺灰色。采用CNN_SVM模型對不同年份的水稻種子圖像進行分類識別,識別正確率為96.1%(如表2所示),說明該模型對不同年份的種子依然具有高識別率。

圖7 不同年份的水稻種子圖像
為了提高模型的泛化能力,通過對水稻種子圖片隨機加入不同比例的椒鹽噪聲點,圖8a為水稻種子原始圖像,圖8b從左到右依次為加入比例為0.01、0.05、0.1噪聲點的圖像,可以看出,加入噪聲的后的圖片部分圖像信息會被遮蓋,會對圖像特征有一定干擾。
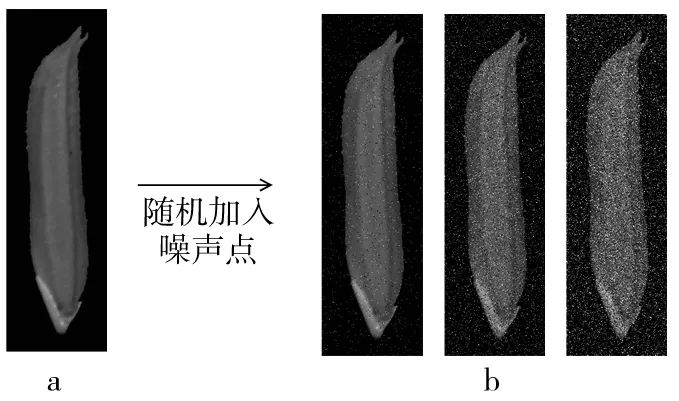
圖8 加入噪聲的水稻種子圖像
采用CNN_SVM模型對增加噪聲后的水稻種子圖像進行分類識別,從表2可以看出相較于未增加噪聲數據集來說,增加噪聲后的數據集識別正確率只是稍微下降,識別正確率為95.8%,說明該模型在噪聲干擾下還是能準確識別水稻種子圖像,泛化能力較強。

表2 加入噪聲和不同年份水稻種子的識別正確率
3 討論
圖像特征的提取是圖像分類識別的關鍵步驟。通過計算和統計圖像局部區域的梯度方向直方圖來提取水稻種子圖像的HOG特征[16-19]能夠描述出水稻種子的表象和形狀,但是生成HOG特征的過程冗長,速度慢,實時性差且不具有旋轉不變性;通過LBP算法[20,21]來提取水稻種子圖像局部紋理具有旋轉不變形和灰度不變性的優點,但在光照變化不均勻的情況下,圖像像素大小關系被破壞會導致LBP算子的變化;基于SIFT特征[22,23]提取可以在不同尺度空間上獲取水稻種子圖像的關鍵點及其方向,具有旋轉不變形以及對亮度變化保持不變,且識別速度較快,但對于一些邊緣光滑的水稻種子圖像,該算法檢測的關鍵點過少,無法準確提取水稻種子圖像的全部特征。而卷積神經網絡是一種監督學習下的機器模型,在圖像特征提取方面能夠自動進行圖像的特征提取,能夠全面提取水稻種子的局部特征和全局特征,具有縮放不變性、旋轉不變性、亮度變化不變性和強魯棒性,在處理環境信息復雜,噪聲干擾的環境下自適應性能好,對于被噪聲遮擋的損缺和畸變水稻種子圖像依然能較好地提取其關鍵信息。
KNN[24,25]是一種簡單且易于實現的分類算法,是通過計算樣本件的距離來決定兩個樣本的相似程度,在進行圖像分類時需要考慮到每個樣本,因此計算量大,不適合處理樣本維度過高的數據集并且不會自主去學習圖像的特征權重。而SVM只需要去找一個能將圖像樣本劃分開來的函數,因此計算量不大,能自主獲取圖像的特征權重且對于通過卷積卷積神經網絡提取的高維度圖像特征能處理得較好。
相較于一些需要獲取水稻種子的高光譜、形狀、顏色等各種圖像特征進行分類的模型來說,CNN_SVM具有一定的便捷性,可直接將一幅圖像輸入模型中,在輸出端給出識別結果。其優勢在于避免了傳統識別算法中復雜的特征提取、數據重建過程和數據預處理,能自行抽取圖像特征包括顏色、紋理、形狀及圖像的拓撲結構。對于經過旋轉、翻轉和亮度調節后的圖像增強數據,該模型的識別位移、旋轉不變性和亮度不變性讓其在對水稻種子圖像分類時具有良好的魯棒性和運算效果。不同年份水稻種子的樣本會因氧化產生顏色誤差,CNN_SVM模型對其依然具有高識別率。在處理增加噪聲后的數據集上,特別是對于一些因噪聲造成圖像信息損缺的水稻種子圖像,CNN_SVM模型具有良好別的泛化能力,能夠高效正確識別水稻種子圖像。
實驗的研究對象是8類水稻種子,分別是楚粳7號、鄂豐絲苗、馬壩油粘、玉楊糯、玉針香、兵兩優401、五鄉優398、泰優398。由于玉楊糯和五鄉優398在顏色、形狀以及紋理等特征方面高度相似,人工較難察覺兩者區別。CNN_SVM對這兩類品種識別時也易將兩者混淆識別,錯誤率相對其他品種來說略高,但相對人工識別的準確率更高,說明該模型能為高度相似品種間的水稻種子識別打下良好基礎。在后期將對該模型進行優化,提高其在高度相似水稻種子間的識別準確率,形成一個能夠識別多種相似水稻種子的在線實時識別系統。
4 結論
針對8種水稻種子圖像識別問題,將CNN_SVM模型與其他10種混合模型進行比較,結果表明,相較于其他方法,本研究的方法無論是在識別正確率還是識別時間上面都具有較強的優勢,識別正確率為96.2%,平均識別一張圖像的時間為4.57 ms,與SVM、CNN原模型對比,顯著提高了識別正確率和縮短了識別時間。
采用CNN_SVM模型對OR數據集、DYR數據集以及NR數據集進行分類識別,識別準確率分別為96.2%、96.1%、95.8%。結果表明,CNN_SVM模型能夠高效識別不同年份的水稻種子,且對加入對特征提取具有強干擾作用的噪聲后,該模型的識別正確率依然較高,表明該模型具有較強的泛化能力,在強烈噪聲的干擾下可保持較高的分類準確率,可根據所分析數據的變化不斷優化模型,能對后續識別多種水稻種子圖像提供基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
