基于深度學習的步態(tài)識別算法及其應(yīng)用研究
2021-02-19 05:28:04趙煦華胡海根
現(xiàn)代信息科技 2021年13期
關(guān)鍵詞:深度學習
趙煦華 胡海根


摘 ?要:文章對步態(tài)識別的應(yīng)用進行研究,基于深度學習技術(shù)研究開發(fā)了移動端步態(tài)識別系統(tǒng)。手機客戶端主要完成步態(tài)數(shù)據(jù)的采集、上傳以及結(jié)果顯示,服務(wù)器端負責對步態(tài)數(shù)據(jù)進行輪廓提取、步態(tài)匹配與識別等功能。其中步態(tài)輪廓提取采用DeepLabV3+語義分割模型,實現(xiàn)像素級別的輪廓分割;步態(tài)識別采用GaitSet模型,實現(xiàn)人體步態(tài)匹配。系統(tǒng)分別經(jīng)CASIA-B數(shù)據(jù)集和真實場景進行測試,顯示系統(tǒng)能夠獲得較好的性能,準確率達到77.5%。
關(guān)鍵詞:步態(tài)識別;深度學習;輪廓提取;語義分割;手機攝像頭
中圖分類號:TP183 文獻標識碼:A文章編號:2096-4706(2021)13-0063-06
Research on Gait Recognition Algorithm Based on Deep Learning and
Its Application
ZHAO Xuhua1, HU Haigen2
(1. College of Information, Zhejiang Guangsha Vocational and Technical University of Construction, Dongyang ?322100, China;
2. College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou ?310024, China)
Abstract: This paper studies the application of gait recognition, and develops a mobile terminal gait recognition system based on deep learning technology. The mobile client mainly completes the gait data collection, uploading and result displaying, while the server side is responsible for contour extraction, gait matching and recognition of gait data. The gait contour extraction adopts DeepLabV3+ semantic segmentation model to realize pixel level contour segmentation; Gaitset model is used for gait recognition to realize human gait matching. The system has been tested by CASIA-B data set and real scenarios respectively. It shows that the system can obtain good performance, and the accuracy rate can reach 77.5%.
Keywords: gait recognition; deep learning; contour extraction; semantic segmentation; phone camera
0 ?引 ?言
步態(tài)識別是一種新興的生物特征識別技術(shù),旨在通過人們走路的姿態(tài)進行身份識別。與虹膜、指紋等其他的生物識別技術(shù)相比,步態(tài)識別具有非接觸、遠距離和不易偽裝等優(yōu)點,在智能視頻監(jiān)控領(lǐng)域,是遠距離情況下最具潛力的生物特征,比面相識別更具優(yōu)勢[1],因而引起了國內(nèi)外廣大研究者們的濃厚興趣。作為一種可以遠距離識別的獨特生物識別功能,步態(tài)將在預(yù)防犯罪、法醫(yī)鑒定和社會保障方面具有廣泛的應(yīng)用前景。而深度學習作為一種新型的機器學習方法,能夠?qū)Τ橄蟮奶卣餍畔⑦M行多層次的提取和學習,在圖像分類、目標檢測與跟蹤、自然語言處理等領(lǐng)域取得了突破性進展。在深度學習的大框架下,步態(tài)識別亦取得了重要進展,步態(tài)信息的表現(xiàn)形式與處理方式呈現(xiàn)出多元化的特點,一些步態(tài)識別方法相繼涌現(xiàn)出來,主要通過步態(tài)采集、步態(tài)分割、特征提取、特征比對等四個階段[2]來完成對個人的識別。目前有兩種基于視覺特征的主流方法:一是將步態(tài)視為靜態(tài)圖像進行處理,最為典型代表是基于步態(tài)能量圖(GEI)的識別方法[3],例如,馮世靈等人[4]提出了結(jié)合非局部與分塊特征的跨視角步態(tài)識別,通過隨機生成正負GEI樣本對,提取各自的非局部特征和樣本間的相對非局部特征,又將特征圖水平切分為靜態(tài)、弱動態(tài)和強動態(tài)三塊,分別訓(xùn)練,而胡靖雯等人[5]將GEI輸入多層CNN,利用四元損失對網(wǎng)絡(luò)進行訓(xùn)練;二是將步態(tài)視為動態(tài)的視頻序列進行處理,由于整合了前后幀的上下文信息,識別效果較為顯著,最為典型的步態(tài)識別算法以GaitSet[6]等為代表,例如,GaitSet在CASIA-B步態(tài)數(shù)據(jù)集上實現(xiàn)了平均95.0%的一次命中準確度,在OU-MVLP步態(tài)數(shù)據(jù)集上達到了87.1%的準確度。早在2012年,賁晛燁等人就從人體測量學數(shù)據(jù)、空間時間數(shù)據(jù)、運動學數(shù)據(jù)、動力學數(shù)據(jù)和視頻流數(shù)據(jù)的特有方法角度總結(jié)步態(tài)識別的各種方法,較為深入全面地闡述了步態(tài)識別傳統(tǒng)方法的研究現(xiàn)狀[7]。除了視覺特征之外,在可穿戴設(shè)備日益盛行的今天,可穿戴傳感器作為人體信息采集的重要工具,促使可穿戴設(shè)備也日益作為步態(tài)識別信息的采集工具。例如,汪濤等人[8]將注意力機制融入CNN,實現(xiàn)對步態(tài)特征的加強;張馨心等人[9]對傳感器系統(tǒng)進行特征值篩選,并用粒子群優(yōu)化BP神經(jīng)網(wǎng)絡(luò)進行識別。此外,還有不少學者[10-14]把目光聚焦于WiFi信號無線傳感技術(shù),現(xiàn)在這項技術(shù)在步態(tài)識別上已經(jīng)得到了較好的應(yīng)用。
隨著智能手機和移動通信網(wǎng)絡(luò)特別是5G技術(shù)的高速發(fā)展,使移動端與服務(wù)器端之間大容量、低時延的圖像視頻數(shù)據(jù)實時傳輸成為可能,以手機作為步態(tài)視覺信息的采集與顯示工具,通過在后端服務(wù)器端進行步態(tài)識別處理成為一種可行的應(yīng)用解決方案。本文基于步態(tài)識別領(lǐng)域最新的研究進展,提出了基于深度學習的輪廓提取與步態(tài)識別整合方案,亦即先通過DeepLabV3+[15]算法在真實環(huán)境下提取人體步態(tài)輪廓,再利用GaitSet步態(tài)識別算法進行有效識別的應(yīng)用解決方案。本文的主要工作及創(chuàng)新在于:(1)在服務(wù)器端,通過使用Socket通信實現(xiàn)了從客戶端接收圖片/視頻并返回識別結(jié)果給客戶端的功能;(2)在手機客戶端,基于Android Studio的APP編程,實現(xiàn)了連續(xù)拍照,將照片發(fā)送給客戶端并接收返回結(jié)果的功能;(3)通過DeepLabV3+語義分割模型進行像素級的輪廓提取,實現(xiàn)了將普通照片轉(zhuǎn)化為步態(tài)輪廓圖的功能;(4)基于GaitSet算法對步態(tài)輪廓圖進行特征提取,通過與數(shù)據(jù)庫信息進行比對,實現(xiàn)了身份識別的功能。經(jīng)實驗測試,通過手機所拍攝的一段人的步態(tài)視頻,即可辨別其身份,操作簡單便捷。
1 ?相關(guān)工作
1.1 ?DeepLabV3+
DeepLabV3+是結(jié)合空間金字塔池化(Spatial Pyramid Pooling,SPP)模塊和encode-decode結(jié)構(gòu)的優(yōu)點提出的新的語義分割結(jié)構(gòu)。其特點在于:基于DeepLabV3[15]提出了新的encode-decode的語義分割結(jié)構(gòu)和一個簡單但有效的decode模塊;并通過設(shè)置空洞卷積調(diào)整encode模塊輸出的特征圖大小以調(diào)節(jié)精度和運行時間之間的平衡,實現(xiàn)了多尺度信息的融合;為語義分割任務(wù)調(diào)整了Xception模塊,同時對于ASPP和decode模塊運用深度分離卷積結(jié)構(gòu),使得整個網(wǎng)絡(luò)更強更快,提高了語義分割的健壯性和運行速率,在Pascal VOC上達到了89.0%的mIoU,而在Cityscape上也取得了82.1%的好成績。
1.2 ?GaitSet
GaitSet步態(tài)算法[6]主要思想來自人類對步態(tài)的視覺感知上,作者發(fā)現(xiàn),步態(tài)中的silhouette從視覺上看前后關(guān)系很容易辨認。受此啟發(fā),作者不再刻意建模步態(tài)silhouette的時序關(guān)系,而將步態(tài)silhouette當作沒有時序關(guān)系的圖像集,讓深度神經(jīng)網(wǎng)絡(luò)自身優(yōu)化去提取并利用這種關(guān)系。該算法在具體實現(xiàn)上具有如下特點:CNN用于獨立地從每個輪廓中提取幀級特征,并池化為集級特征;Set Pooling操作用于將幀級特征聚合成獨立序列級特征;使用水平金字塔映射(HPM)的結(jié)構(gòu)將這個序列級特征,就是包含了時間和空間的特征壓縮成一維特征便于最后全連接做分類。而Set Pooling采用了注意力機制,首先由三種統(tǒng)計函數(shù)收集全局信息,然后將其與原始特征圖一起送入1×1卷積層計算注意力以精煉特征信息,再通過在所設(shè)置的幀級特征映射的集合上使用MAX來提取最終的序列級特征z,再將其應(yīng)用于序列維度,殘余結(jié)構(gòu)可以加速并穩(wěn)定收斂。
2 ?系統(tǒng)方法
2.1 ?總體設(shè)計
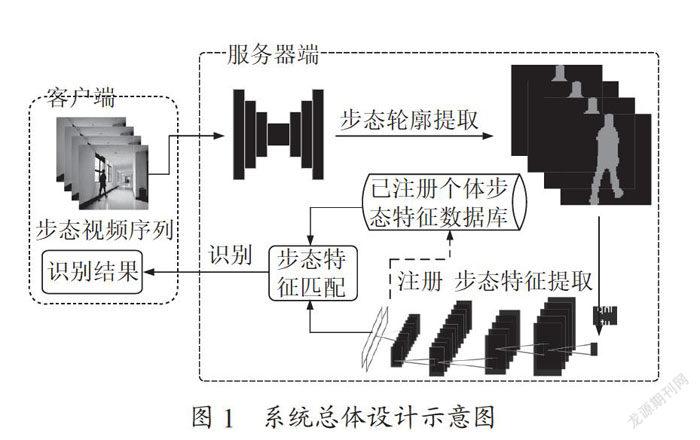
系統(tǒng)采用C/S架構(gòu),總體流程分為步態(tài)注冊和步態(tài)識別兩階段,總體設(shè)計示意圖如圖1所示。
注冊階段:首先在客戶端通過現(xiàn)場錄制上傳或本地上傳的方式,將步態(tài)序列發(fā)送至服務(wù)器端,用DeepLabV3+語義分割模型加工產(chǎn)生步態(tài)輪廓序列,再通過GaitSet進行步態(tài)特征提取,最終將步態(tài)特征與個人身份信息一同存入數(shù)據(jù)庫。
識別階段:采用同樣的方式將步態(tài)序列發(fā)送至服務(wù)器端并獲得步態(tài)特征,將該特征與數(shù)據(jù)庫中已注冊的信息進行相似度比對,以識別身份,最終將結(jié)果返回客戶端。
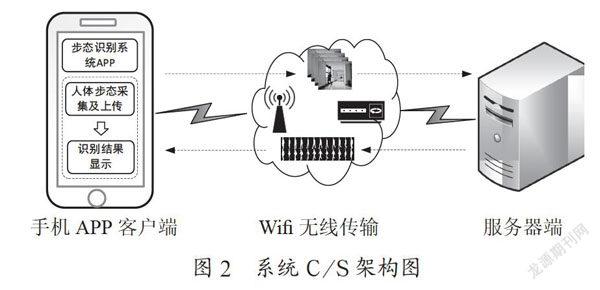
2.2 ?C/S架構(gòu)
整個步態(tài)識別系統(tǒng)采用C/S架構(gòu),分為手機APP客戶端和服務(wù)器端,而手機APP則是基于Android手機開發(fā)的。根據(jù)系統(tǒng)的需求分析,要實現(xiàn)安卓手機通過WiFi對服務(wù)器進行指令的發(fā)送與接收,需要將指令通過指定IP地址和8080端口發(fā)送給服務(wù)器,安卓手機作為客戶端連入該WiFi網(wǎng)絡(luò)服務(wù)器,通過手機端采集的步態(tài)視頻序列數(shù)據(jù)在服務(wù)器處理后將數(shù)據(jù)發(fā)送給手機。其中,由手機客戶端輸入IP地址、端口號和要發(fā)送的數(shù)據(jù)信息,以及采集到的步態(tài)視頻。Socket通訊將數(shù)據(jù)發(fā)送至同一個網(wǎng)絡(luò)下的服務(wù)器,服務(wù)器接收到這些步態(tài)視頻數(shù)據(jù)后,對其進行輪廓提取、格式轉(zhuǎn)換以及步態(tài)識別,系統(tǒng)C/S架構(gòu)如圖2所示。
2.2.1 ?服務(wù)器端
服務(wù)器采用高性能的工作站,依托NVDIA GPU的性能,能加快整個步態(tài)識別的速度。服務(wù)器上搭建了DeepLabV3+和GaitSet等深度學習網(wǎng)絡(luò)平臺,前者用于人體輪廓提取,后者用于步態(tài)識別。平臺上配置了numpy、PIL、OpenCV等常用的python模塊,使其能夠完成步態(tài)輪廓提取和步態(tài)識別功能。
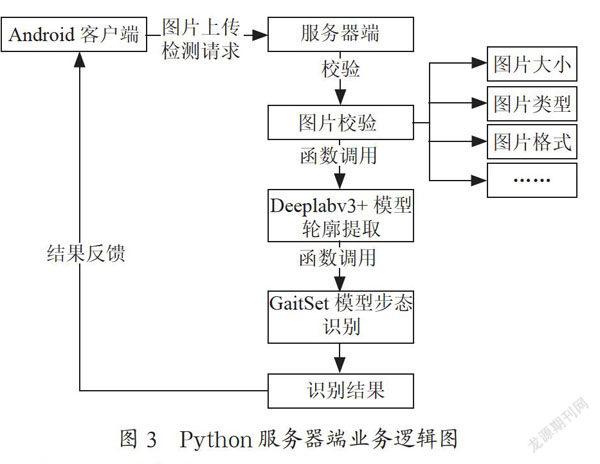
服務(wù)器端響應(yīng)Android手機客戶端請求過程為:(1)首先對請求上傳的視頻幀圖片進行必要的校驗,包括圖片的大小、類型、格式等;(2)再以函數(shù)調(diào)用系統(tǒng)命令的方式,調(diào)用deeplabv3模型并對視頻幀圖片進行輪廓提取;(3)提取到的輪廓序列圖片經(jīng)訓(xùn)練好的GaitSet步態(tài)模型識別處理,得到識別結(jié)果;(4)最后將識別結(jié)果封裝成相應(yīng)數(shù)據(jù)格式,通過Socket通訊請求返回給Android手機客戶端,完成服務(wù)器端的響應(yīng)過程,其業(yè)務(wù)邏輯如圖3所示。
2.2.2 ?手機客戶端
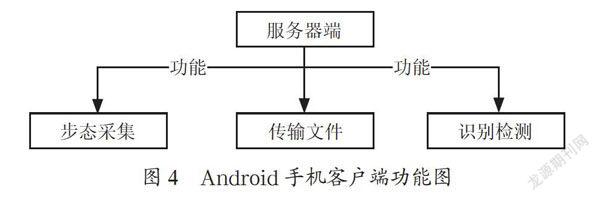
Android手機客戶端采用Android Studio開發(fā)平臺搭建,主要目的在于為用戶提供友好的可視化操作界面。客戶端主要完成步態(tài)視頻采集、傳輸圖片、識別檢測等功能。具體操作流程為:(1)通過手機拍攝一段步態(tài)視頻,或者通過手機連拍功能拍攝一段步態(tài)圖像序列;(2)設(shè)定上傳圖片的數(shù)量,再通過Socket傳輸序列幀圖像,收到服務(wù)器確認后表示傳輸結(jié)束;(3)服務(wù)器將接收到的圖片經(jīng)輪廓提取并進行識別匹配后,將識別結(jié)果返回給客戶端,并顯示在彈窗上,Android手機客戶端的功能如圖4所示。
2.3 ?DeepLabV3+步態(tài)輪廓提取
步態(tài)輪廓常采用幀間差分法[16]、光流法[17]、背景差分法[18]。幀間差分法實現(xiàn)簡單,但是當前后兩幀變化很小時,檢測目標會不完整;光流法計算復(fù)雜,對光線非常敏感;背景差分法需要事先建立良好的背景模型,在應(yīng)用的過程中也需要實時更新背景。考慮到語義分割模型在經(jīng)過充分訓(xùn)練后能夠?qū)ξ矬w進行像素級別的分割,能取得較好的分割效果,本文將DeepLabV3+運用于步態(tài)輪廓的分割。對于單幀信息,首先選一個低層級的feature用的卷積進行通道壓縮(原本為256通道,或者512通道),目的是減少低層級的比重。我們認為編碼器得到的feature具有更豐富的信息,所以編碼器的feature應(yīng)該配置更高的比重,以便于有效訓(xùn)練。而對于解碼器部分,直接將編碼器的輸出上采樣4倍,使其分辨率和低層級的feature保持一致。例如,若采用ResNet Conv2輸出的feature,則進行上采樣,再將兩種feature連接后,進行一次的卷積操作(細化作用),最后再次采樣就得到了像素級的預(yù)測。
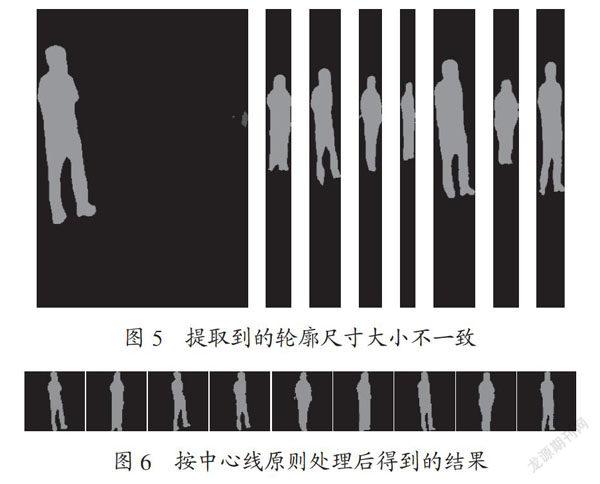
值得注意的是,在進行步態(tài)輪廓采集過程中,由于鏡頭與人的距離是一個動態(tài)過程,輪廓會因距離鏡頭的遠近而大小不一如圖5 所示,將會嚴重影響到后續(xù)步態(tài)識別的精度。因此,本文采用OpenCV-Python的方法,通過中心線原則把步態(tài)輪廓統(tǒng)一裁剪成的大小,如圖6所示。
2.4 ?步態(tài)特征提取
GaitSet[6]有別于template-based和sequence-based當前主流的步態(tài)識別方法,template-based方法會導(dǎo)致時序信息得不到利用,sequence-based方法則會由于引入了時序約束從而丟失了靈活性。而GaitSet[6]是一種將步態(tài)序列視為一組無序集合來處理的方法,將步態(tài)特征視為一組步態(tài)輪廓圖,即使這些輪廓是亂序的,也只要通過觀察它們的外觀就能將它們重新排列成正確的順序。因而它能有效且高效地提取空間和時間特征,從而獲得了優(yōu)秀的性能。GaitSet的實用性也很強,其寬松的輸入限制可以使其獲得更廣泛的應(yīng)用場景,模型可以直接計算步態(tài)特征而非計算步態(tài)間的相似度。因此,本文采用GaitSet模型來實現(xiàn)步態(tài)的識別。
對于模型訓(xùn)練,GaitSet的輸出是具有d個維度的特征。不同樣本對應(yīng)的特征將被用于計算損失,訓(xùn)練網(wǎng)絡(luò)采用Batch All(BA+)Triplet Loss函數(shù)。從訓(xùn)練集中拿出一個大小為p×k的batch,其中p表示人數(shù),k表示每個人拿k個樣本,這樣總共會有pk(pk-k)(k-1)種組合,計算loss時就依照此組合數(shù)統(tǒng)計全部可能。人和除人之外的東西分開,那么人就是所謂正樣本,除人之外的東西就是負樣本。
3 ?方法驗證
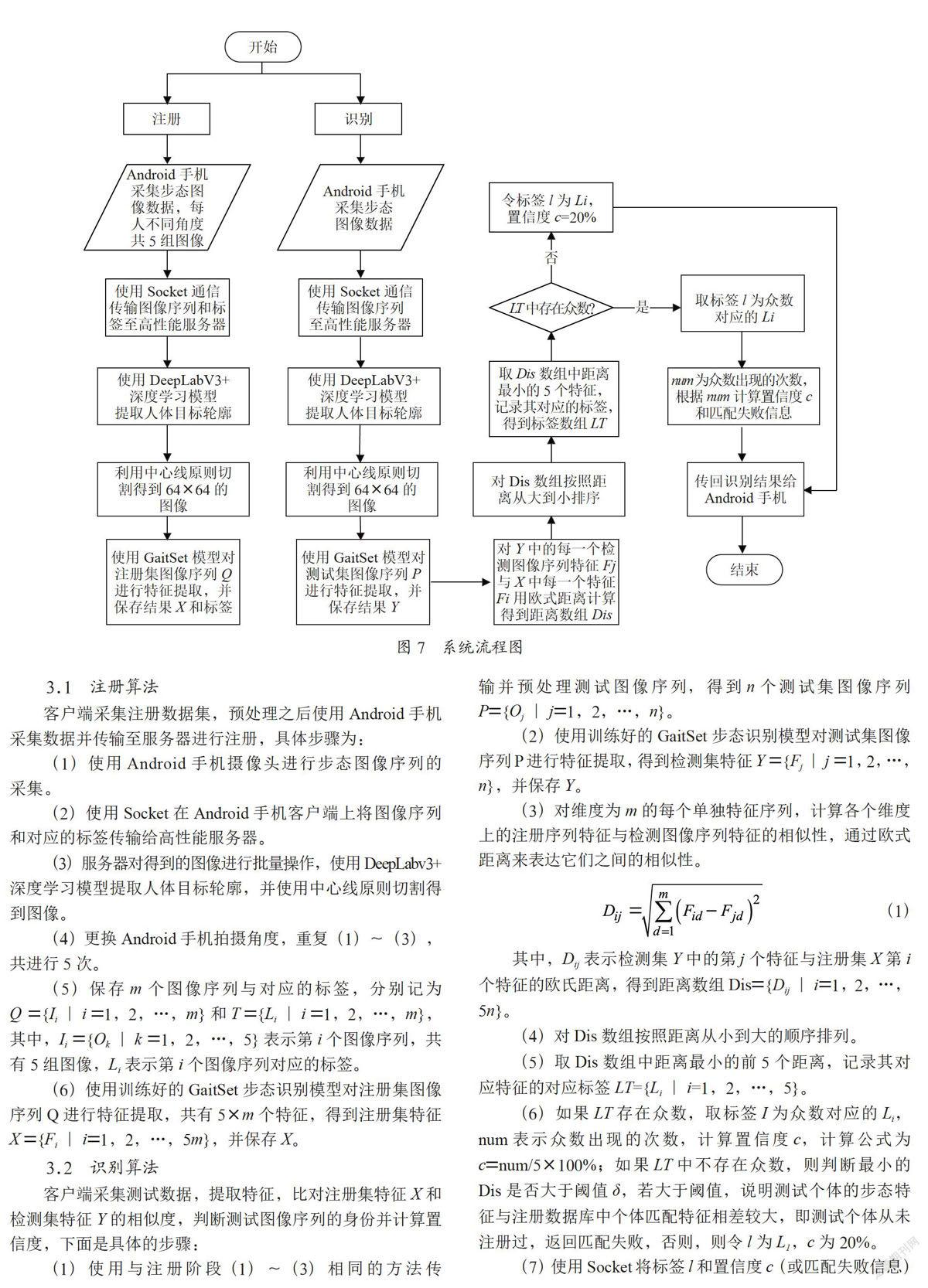
步態(tài)識別分為注冊和識別兩個階段:(1)注冊階段,即Android手機端從不同角度采集不同人的步態(tài)數(shù)據(jù),并進行輪廓分割等預(yù)處理操作,再使用步態(tài)識別模型提取每個人的特征向量,將這些得到的特征向量存儲在數(shù)據(jù)庫中;(2)識別階段,輸入任意視頻序列圖片,對這些圖片進行預(yù)處理后,輸入網(wǎng)絡(luò),得到一個特征向量,將該特征向量與數(shù)據(jù)庫中個體的特征向量進行比對,計算歐式距離,距離最小的歐式距離所對應(yīng)的個體ID即為輸入圖片對應(yīng)的ID,系統(tǒng)流程如圖7所示。
3.1 ?注冊算法
客戶端采集注冊數(shù)據(jù)集,預(yù)處理之后使用Android手機采集數(shù)據(jù)并傳輸至服務(wù)器進行注冊,具體步驟為:
(1)使用Android手機攝像頭進行步態(tài)圖像序列的采集。
(2)使用Socket在Android手機客戶端上將圖像序列和對應(yīng)的標簽傳輸給高性能服務(wù)器。
(3)服務(wù)器對得到的圖像進行批量操作,使用DeepLabv3+ 深度學習模型提取人體目標輪廓,并使用中心線原則切割得到圖像。
(4)更換Android手機拍攝角度,重復(fù)(1)~(3),共進行5次。
(5)保存m個圖像序列與對應(yīng)的標簽,分別記為Q ={Ii∣i =1,2,…,m}和T ={Li∣i =1,2,…,m},其中,Ii ={Ok∣k =1,2,…,5}表示第i個圖像序列,共有5組圖像,Li表示第i個圖像序列對應(yīng)的標簽。
(6)使用訓(xùn)練好的GaitSet步態(tài)識別模型對注冊集圖像序列Q進行特征提取,共有5×m個特征,得到注冊集特征X ={Fi∣i=1,2,…,5m},并保存X。
3.2 ?識別算法
客戶端采集測試數(shù)據(jù),提取特征,比對注冊集特征X和檢測集特征Y的相似度,判斷測試圖像序列的身份并計算置信度,下面是具體的步驟:
(1)使用與注冊階段(1)~(3)相同的方法傳輸并預(yù)處理測試圖像序列,得到n個測試集圖像序列P={Oj∣j=1,2,…,n}。
(2)使用訓(xùn)練好的GaitSet步態(tài)識別模型對測試集圖像序列P進行特征提取,得到檢測集特征Y ={Fj∣j =1,2,…,n},并保存Y。
(3)對維度為m的每個單獨特征序列,計算各個維度上的注冊序列特征與檢測圖像序列特征的相似性,通過歐式距離來表達它們之間的相似性。
(1)
其中,Dij表示檢測集Y中的第j個特征與注冊集X第i個特征的歐氏距離,得到距離數(shù)組Dis={Dij∣i=1,2,…,5n}。
(4)對Dis數(shù)組按照距離從小到大的順序排列。
(5)取Dis數(shù)組中距離最小的前5個距離,記錄其對應(yīng)特征的對應(yīng)標簽LT={Li∣i=1,2,…,5}。
(6)如果LT存在眾數(shù),取標簽I為眾數(shù)對應(yīng)的Li,num表示眾數(shù)出現(xiàn)的次數(shù),計算置信度c,計算公式為c=num/5×100%;如果LT中不存在眾數(shù),則判斷最小的Dis是否大于閾值δ,若大于閾值,說明測試個體的步態(tài)特征與注冊數(shù)據(jù)庫中個體匹配特征相差較大,即測試個體從未注冊過,返回匹配失敗,否則,則令l為L1,c為20%。
(7)使用Socket將標簽l和置信度c(或匹配失敗信息)傳回手機,完成識別。
(8)重復(fù)(3)~(7),直至遍歷完Y。
4 ?實驗結(jié)果與分析
4.1 ?數(shù)據(jù)集
本文使用CASIA-B數(shù)據(jù)集,該數(shù)據(jù)集由中國科學院提供,涵蓋11個視角(0°,18°,36°,…,180°),124個人,分為普通、攜帶包裹、穿外套或夾克三種情況,主要用于訓(xùn)練步態(tài)識別模型。
4.2 ?輪廓提取
為了充分展現(xiàn)語義分割的效果,實驗者被置于比較復(fù)雜的環(huán)境中,如圖8所示。
11張圖片組成的視頻幀序列中,實驗者從遠到近地以自然步態(tài)行走,背景較為復(fù)雜,有門、窗、消防栓、天花板、光影等干擾因素存在,照片通過DeepLabV3+提取到的步態(tài)特征輪廓都十分清晰,效果比較理想。
4.3 ?步態(tài)識別
GaitSet模型訓(xùn)練階段設(shè)置為:優(yōu)化器使用Adam,學習率為1e-4,總迭代次數(shù)為80K,batchsize為(8,8)。表1記錄了步態(tài)識別系統(tǒng)在不同角度下,行走狀態(tài)為正常(NM)、攜帶包裹(BG)和穿外套或夾克衫(CL)時的識別準確率,可以看出,本文的模型在步態(tài)身份識別上是比較精準的。
在實際環(huán)境下,服務(wù)器端采用E5-494 2620 2.0 GHz 6核處理器、32 GB RAM和1080Ti GPU的工作站,而客戶端則采用華為Honor 20 Pro手機,通過手機拍攝一段4~5秒的步態(tài)視頻序列作為一個固定角度的步態(tài)樣本。基于訓(xùn)練得到的GaitSet模型,對上述提取到的輪廓進行步態(tài)特征識別與匹配。在實際測試中,考慮到采集步態(tài)數(shù)據(jù)的限制,我們分別對8個人進行采樣測試,準確率能夠達到77.5%。輪廓提取所花的時間較大,約3秒鐘,而識別時間則為0.8秒。為測試數(shù)據(jù)匹配容量與識別速度的關(guān)系,我們把數(shù)據(jù)集(不需要提取輪廓)中的數(shù)據(jù)匹配容量增加至1 000人,則識別速度約為4.3秒,總體上識別速度尚可。
5 ?結(jié) ?論
步態(tài)識別是一種新興的生物特征識別技術(shù),具有非接觸、遠距離和不易偽裝等優(yōu)點,近年來日益受到國內(nèi)外研究者的廣泛關(guān)注。本文基于現(xiàn)實的應(yīng)用需求,基于深度學習技術(shù)研究開發(fā)了面向Android智能手機的步態(tài)識別系統(tǒng)。系統(tǒng)采用C/S架構(gòu),手機客戶端主要完成步態(tài)數(shù)據(jù)的采集、上傳以及識別結(jié)果的顯示等功能,而服務(wù)器端則主要負責對客戶端采集的步態(tài)數(shù)據(jù)進行輪廓提取、步態(tài)匹配與識別等功能。為達到此目的,步態(tài)輪廓提取采用了DeepLabV3+語義分割模型,能實現(xiàn)像素級別的輪廓分割;而步態(tài)識別則采用了當前最先進的GainSet模型,能夠達到較高的識別率。系統(tǒng)方案充分利用了Android手機的便捷性和服務(wù)器的強大算力,同時彌補了固定設(shè)備進行識別時的靈活性欠缺等不足,只要有網(wǎng)絡(luò),便可隨時隨地通過Android手機客戶端迅速獲取對象身份,非常簡潔實用。
最后,系統(tǒng)分別經(jīng)CASIA-B數(shù)據(jù)集和真實場景進行測試,結(jié)果顯示系統(tǒng)能夠獲得較好的性能,在真實場景下,系統(tǒng)的準確率能夠達到77.5%。下一步將考慮向預(yù)處理中加多線程服務(wù)器,以縮短服務(wù)器反應(yīng)時間,改善用戶體驗感。
參考文獻:
[1] CONNOR P,ROSS A. Biometric recognition by gait:A survey of modalities and features [J].Computer Vision and Image Understanding,2018,167:1-27.
[2] 朱應(yīng)釗,李嫚.步態(tài)識別現(xiàn)狀及發(fā)展趨勢 [J].電信科學,2020,36(8):130-138.
[3] JU H,BIR B. Individual recognition using gait energy image [J].IEEE transactions on pattern analysis and machine intelligence,2006,28(2):316-322.
[4] 馮世靈,王修暉.結(jié)合非局部與分塊特征的跨視角步態(tài)識別 [J].模式識別與人工智能,2019,32(9):821-827.
[5] 胡靖雯,李曉坤,陳虹旭,等.基于深度學習的步態(tài)識別方法 [J].計算機應(yīng)用,2020,40(S1):69-73.
[6] CHAO H,HE Y,ZHANG J,et al. GaitSet:Regarding gait as a set for cross-view gait recognition [C]//Proceedings of the 33th AAAI Conference on Artificial Intelligence,2019:8126-8133.
[7] 賁晛燁,徐森,王科俊.行人步態(tài)的特征表達及識別綜述 [J].模式識別與人工智能,2012,25(1):71-81.
[8] 汪濤,汪泓章,夏懿,等.基于卷積神經(jīng)網(wǎng)絡(luò)與注意力模型的人體步態(tài)識別 [J].傳感技術(shù)學報,2019,32(7):1027-1033.
[9] 張馨心,姚愛琴,孫運強,等.基于深度學習的步態(tài)識別算法優(yōu)化研究 [J].自動化儀表,2020,35(4):70-74.
[10] 周志一,宋冰,段鵬松,等.基于WiFi信號的輕量級步態(tài)識別模型LWID [J].計算機科學,2020,47(11):25-31.
[11] SHI C,LIU J,LIU H,et al. Smart user authentication through actuation of daily activities leveraging WiFi-enabled IoT [C]//Proceedings of the 18th ACM international symposium on Mobile Ad Hoc Networking and Computing. Chennai,India:Association for Computing Machinery,2017:1–10.
[12] WANG W,LIU A X L,SHAHZAD M. Gait recognition using WiFi signals [C]//Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing. Heidelberg Germany:Association for Computing Machinery,2016:363–373.
[13] ZENG Y,PATHAK P H,MOHAPATRA P. WiWho:wifi-based person identification in smart spaces [C]//Proceedings of the 15th International Conference on Information Processing in Sensor Networks. Vienna Austria:IEEE Press,2016:1-12.
[14] ZHANG J,WEI B,HU W,et al. Wifi-id:human identifica-tion using wifi signal [C]//Proceedings of the International Conference on Distributed Computing in Sensor Systems. Washington,DC,USA:2016 International Conference on Distributed Computing in Sensor Systems (DCOSS),2016:75-82.
[15] CHEN L C,ZHU Y,PAPANDREOU G,et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]//Proceedings of the European conference on computer vision (ECCV). Munich,Germany:Computer Vision – ECCV 2018,2018:833-851.
[16] CHEN L C,PAPANDREOU G,SCHROFF F,et al. Re-thinking atrous convolution for semantic image segmenta-tion [J/OL].arXiv.org,2017,3(2017-06-17).https://arxiv.org/abs/1706.05587v1.
[17] LIPTON A J,F(xiàn)UJIYOSHI H,PATIL R S. Moving target classification and tracking from real-time video [C]//Proceeding of Fourth IEEE Workshop on Applications of Computer Vision. Princeton,NJ,USA:IEEE,1998:8-14.
[18] 商磊,張宇,李平.基于密集光流的步態(tài)識別 [J].大連理工大學學報,2016,56(2):214-220.
作者簡介:趙煦華(1973.12—),男,漢族,浙江東陽人,中級工程師,碩士研究生,研究方向:嵌入式系統(tǒng)、大數(shù)據(jù)、人工智能、機器學習。
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
