
基于Kudu 的電力輔助設備實時監控業務解決方案
2021-02-22 02:38:32陶繼群
科技創新與應用 2021年8期
曹 成,陶繼群,鄭 湃
(江蘇中科院智能科學技術應用研究院,江蘇 常州213164)
1 概述
江蘇中科院智能科學技術應用研究院基于Hadoop架構的分布式大數據平臺已經搭建完成,以T+1 形式處理數據,目前已成功運行各類數據應用和業務需求。但這種離線處理數據的方式已無法滿足目前的電力輔助設備的實時數據監控需要,基于分布式文件存儲系統(HDFS)、分布式的高性能并行計算平臺(MapReduce)和Hive 的Hadoop 架構無法實時加載數據和提供數據查詢分析;雖然可以在該架構中添加HBase 存儲系統,HBase存儲系統雖然可以實現數據的快速插入和實時更新,但其并不適用于大批量的數據掃描工作[1]。目前,我院大數據平臺急需能夠實現大批量數據實時讀寫和實時分析的解決方案。
Kudu 存儲系統是Cloudera 公司開發的可以實現多種一致性協議的列式存儲引擎,兼顧了數據更新實時性和分析速度,能夠與Hadoop 大數據平臺中的Hive、HDFS等組件形成互補。Kudu 存儲系統在滿足電力輔助設備實時監控業務實時查詢需求的同時,還能夠滿足監控業務的實時分析,同時還提供了Kudu-API、Impala-JDBC 等連接方法[2],向電力輔助設備的分析系統和展示系統提供快速的查詢和分析類的數據共享能力,滿足大數據平臺的實時類業務處理能力需求。
2 電力輔助設備實時監控業務應用難點分析和相關解決方案
2.1 電力輔助設備實時監控業務應用難點分析
電力輔助設備的實時監控業務主要包括輸變電系統中的紅外熱成像、避雷器、驅鳥器、通風裝置、端子箱等6大類輔助設備的數據實時采集入庫和實時查詢、實時分析和遠程控制等。目前大數據平臺已對接電力輔助設備500 余臺,各類終端20000 余個,通過該監控業務可以有效監控變電站各類設備工作情況和實時報警等。
目前,江蘇中科院智能科學技術應用研究院基于Hadoop 架構的分布式大數據平臺主要完成各類工業離線數據的計算和分析工作,每日凌晨定時匯總前一天數據至歷史數據表單中,按業務要求完成離線計算任務,再將結果同步到結果表單中,供前臺系統調用。然而這種處理方式并不適用于電力輔助設備的實時監控業務。主要有以下原因: 該監控業務對底層數據庫的響應時間要求極高,涉及的電流值、電壓值波動記錄存儲通常為秒級或者毫秒級,輕微的電流值和電壓值波動很可能造成電力設備供電異常或故障。然而HDFS 存儲數據效率無法滿足這一需求,也無法支撐數據的動態更新和插入等數據庫DLL 操作[3];在分析計算實時數據時,Hive 的大批量數據關聯查詢和計算效率偏低,計算時間偏長,達不到實時數據的計算需要;外網部署的客戶分析系統和展示系統獲取數據需要大數據平臺通過數據API 接口提供,但Hadoop 平臺提供的HadoopAPI 接口和Hive API 接口快速響應的能力差,無法滿足實時性需求[4]。基于以上分析,大數據平臺實時數據處理和讀取的能力缺陷導致其成為電力輔助設備實時監控業務的制約。為了滿足實時應用的需要,平臺急需可以實現大批量實時讀寫、實時分析解決方案。
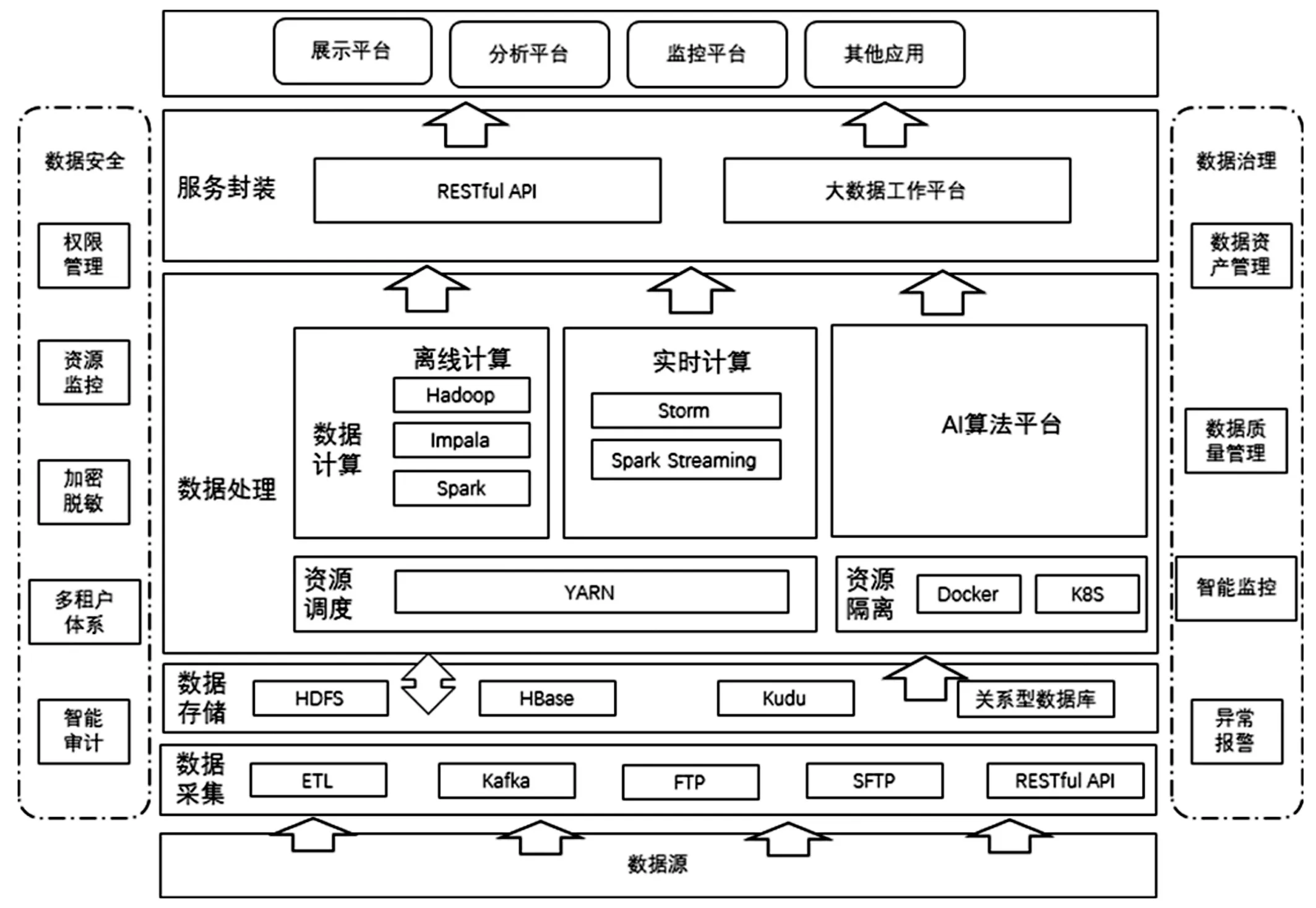
圖1 大數據平臺總體架構圖
2.2 相關解決方案
為處理電力輔助設備的實時監控業務,前期嘗試采用的解決方式有Strom 和Spark Streaming 兩種,但兩種方案最終均被證明無法滿足業務需求。
方案1:Strom
Storm 是毫秒級的流處理實時計算體系,Storm 的流處理過程是將實時應用的計算任務寫好topology(拓撲)結構然后等待數據進來分析,相似于Hadoop 的MapReduce 任務。其優點是全內存計算[5],所以Storm 的速度相比Hadoop 非常快(瓶頸是計算機內存和CPU),缺點就是不夠靈活,數據吞吐量低,不能在中間執行SQL 交互式查詢、復雜的轉換等[6]。對于電力輔助設備的實時監控業務中的OLTP 場景并不適用。
方案2:Spark Streaming
Spark Streaming 是可以實現高吞吐量的、具備容錯機制的實時流數據的處理,Spark Streaming 的處理機制是接收實時的輸入數據流,并根據一定的時間間隔(秒級)拆分成一批批的數據,然后通過SparkEngine 處理批數據,最終得到處理后的結果[7]。但Spark Streaming 只是準實時的,事務機制不夠完善,也不支持動態調整[8]。對于電力輔助設備的實時監控業務來說,準實時的存儲和分析數據并不能滿足實時需求。
3 Kudu 解決方案
3.1 Kudu 存儲系統
Kudu 的定位是在更新更加及時的基礎上實現更快的數據分析,HBASE 不適用于基于SQL 的數據分析方向,大批量數據獲取時的性能較差;HDFS 適合離線分析,不支持單條紀錄級別的update 操作,隨機讀寫性能差[9],正因為HDFS 與HBASE 有以上缺點,Kudu 較好的解決了HDFS 與HBASE 的這些缺點,它不及HDFS 批處理快,也不及HBase 隨機讀寫能力強,但是反過來它比HBase 批處理快(適用于OLAP 的分析場景),而且比HDFS 隨機讀寫能力強(適用于實時寫入或者更新的場景),在更新更加及時的基礎上實現更快的數據分析。通過在Hadoop 大數據平臺中加入Kudu 存儲系統,江蘇中科院智能科學技術應用研究院大數據平臺實現了對實時業務處理的能力。且Kudu 存儲系統可以和已有的Hive、Kafka、Impala 等組件無縫對接,從而服務上層中的數據應用和ETL 流程[10]。引入Kudu 后的大數據平臺總體架構如圖1 所示。
通過引入Kudu 存儲系統,江蘇中科院智能科學技術應用研究院大數據平臺在保留現有離線業務的前提下,可以實現平臺對實時業務的處理能力。同時支持Python、JAVA 等語言開發人員直接調用Kudu API 數據接口,極大的拓展了大數據平臺的使用范圍[11];同時Kudu 存儲系統還具備眾多優點,如下:
我院使用的Kudu 存儲系統為開源版本,無版權費用支出,降低了項目開發成本。
數據開發工程師只需要向大數據平臺提交一份SQL腳本就可以同時處理和HDFS 和Kudu 存儲系統中的數據,不需要同時在兩個系統中都存儲數據,節省硬盤空間,方便快捷[12]。
Kudu 存儲系統可以和現有平臺中的租戶共用,不需要重新申請創建新的租戶,其主持多用租戶操作環境,有效避免了不同賬號的多源管理問題[13]。
Kudu 存儲系統開發門檻低,數據開發工程師無需掌握Kudu 底層原理,只需掌握SQL 語言和大數據平臺運維原理就可以快速上手,大大節約了學習成本。
3.2 Kudu 實時數據查詢
電力輔助設備的實時監控業務對數據的實時性要求極高,從數據采集到數據入庫分析再到數據讀取整個數據流程不能超過2 秒,終端設備的電流值和電壓值入庫后需要再次和其他業務表單進行多表聯合查詢,并將結果及時反饋到分析系統和展示系統中。少量數據可以通過傳統型數據庫或HBase 進行處理。該方案無法滿足電力輔助設備監控業務的大批量數據查詢的實時響應要求。
使用Kudu 存儲系統+Impala 交互式SQL 解析引擎可以有效滿足電力輔助設備的實時監控業務實時查詢的業務需求。Impala 是Cloudera 公司開發的一種高效率的SQL 查詢工具,采用內存計算模型,對于分布式Shuffle,最大限度的利用服務器的內存和CPU 資源。同時,Impala也有預處理和分析技術,表數據插入之后可以用COMPUTESTATS 指令來讓Impala 對行列數據深度分析,具有實時,批處理,多并發等優點,其也允許開發人員使用Impala 的SQL 語法對Kudu 存儲系統中的tablets 插入、查詢、更新和刪除數據[14]。
對于電力輔助設備的實時監控業務中的電流值和電壓值查詢業務,涉及跨數據庫多表關聯查詢、消除取值重復行查詢、大小比較查詢和分組聚集函數查詢、嵌套查詢等;其中分組聚集函數查詢和跨數據庫多表關聯查詢兩種業務最為典型,測試結果見表1,表2。
從表1、表2 測試結果可以看出,基于Kudu 和Impala 結合使用的解決方案完全能夠支撐電力輔助設備的實時監控業務需要,跨數據庫大批量的數據查詢和分組聚集函數查詢響應時間都達秒級,分析系統和展示系統展示的數據查詢結果和實時數據相差也為秒級,滿足精度要求極高的電流監控和電壓監控等需求。
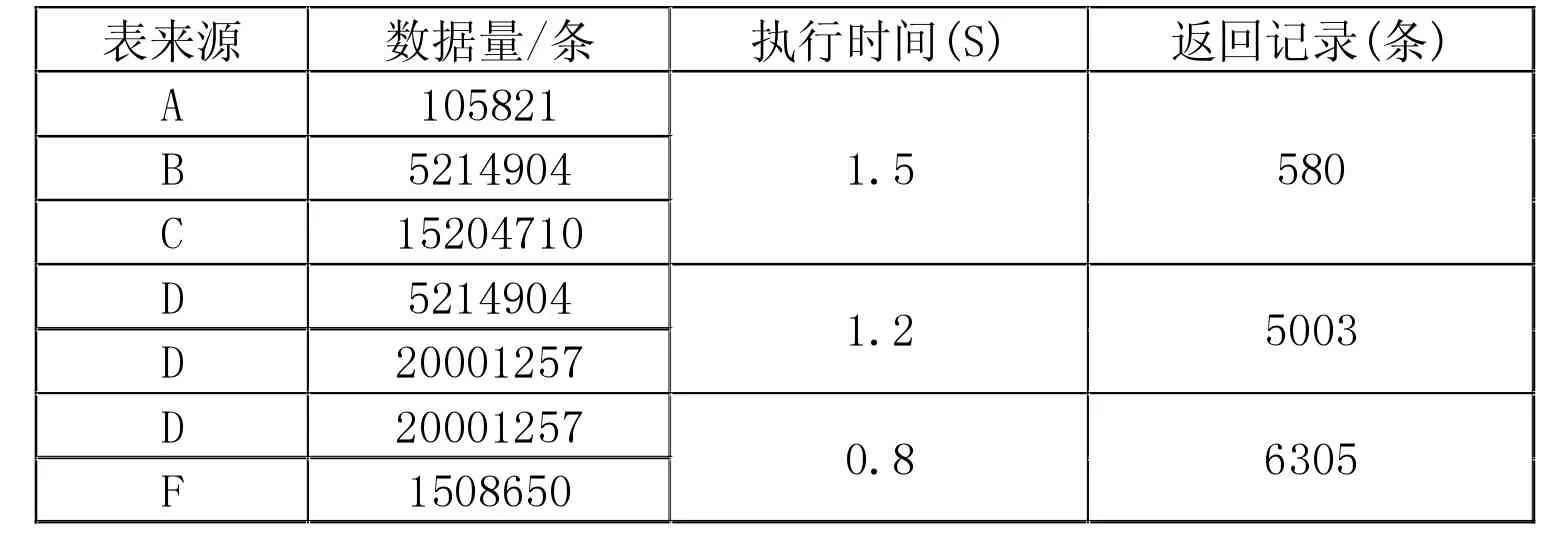
表1 Kudu 存儲系統跨數據庫多表關聯查詢
3.3 Kudu 實時數據入庫和增量更新
電力輔助設備的實時監控業務數據采集周期設置為實時采集,每秒采集各類終端設備20000 余個,電流值、電壓值、溫濕度、風速、聲波值等各類數值500 多項,約1.5 萬余條數據。Hadoop 大數據平臺通過結合Kafka 流式處理平臺與分布式文件存儲系統對接采集實時數據。Kafka 通過O(1)的磁盤數據結構提供消息的持久化,這種結構對于即使數以TB 的消息存儲能夠保持長時間的穩定性能[15]。
Kudu 數據存儲系統可以和Kafka 實時消息系統進行對接,從而實現電力輔助設備實時監控業務數據的加裝。Kudu 作為列式存儲引擎,滿足數據逐條采集,因此Kudu 適用于Kafka 的實時寫入要求,數據入庫效率極高,大數據平臺每秒可入庫約10 萬余條。基于Kudu 的流式數據實時入庫測試結果見表3。由此可見,使用Kudu 結合Kafka,電力輔助設備的實時監控業務數據每秒2 萬余條數據采集至Kudu 存儲系統中的時間完全可以達到秒級,滿足監控業務的實時性要求。

表2 Kudu 存儲系統分組聚集函數查詢

表3 基于Kudu 的流式數據入庫測試結果
Hadoop 大數據平臺的離線數據倉庫Hive,在數據的提取、裝載和轉化等方面具有優勢,但Hive 的執行效率偏低、調優困難、粒度較粗、每次執行Hive 都會自動生成Mapreduce 作業,通常情況下不夠智能化,每次都會產生大量的I/O 開銷、平臺內存被長期占用,因此Hive 無法支持批量數據的增量更新和修改。Kudu 存儲系統可以用以下方式實現數據增量更新:每張Kudu 表都會被分成若干個tablet,每個tablet 包括MetaData 元信息及若干個RowSet。執行數據寫入操作時,系統都會在Tablet 中的所有RowSet 中進行查找,驗證等待寫入數據相同主鍵的記錄是否沖突。如果master 校驗通過,則返回表的分區、tablet 與其對應的tserver 給client;如果校驗失敗則報錯給client,再次經過一致性算法校驗通過后,tserver 會將寫入請求預寫到WAL 日志,用來server 服務器宕機后的恢復操作。插入的數據寄存在Tablet 的MemRowSet 中,一旦MemRowSet 的大小達到1G 或120s 后,MemRowSet會flush 成一個或DiskRowSet,用來將數據持久化存儲,同時再次生成MemRowSet 繼續接收新的數據請求,如此循環[16]。Kudu 寫入數據的工作機制如圖2 所示。
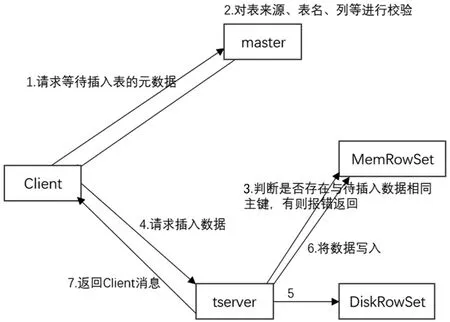
圖2 Kudu 寫入數據的工作機制
3.4 Kudu API 接口服務
電力輔助設備的實時監控業務不僅需要在分析系統和展示系統中實時展示和應用,同時需要為企業提供數據API 服務,盡管Hadoop 大數據平臺通過提供抽象操作和并行編程接口,以Java API 的方式實現了接口的封裝,但由于MapReduce 機制原因,企業在調取該類數據API 接口時需要等待很長一段時間才能返回結果[17],企業用戶對于這種問題的敏感度極高,無法容忍該響應時間過長的問題。
企業用戶通過調用平臺的API 數據接口和自身系統接口數據或數據庫數據進行對接,通過一定的分析運算后加載在企業自用系統中,該類需求就需要盡量縮減企業調用大數據平臺API 接口并返回有效值的響應時間。Kudu 存儲系統提供的Kudu API 接口服務正好可以滿足這類要求響應時間短,操作簡潔、修改方便的需求,Kudu官方推薦使用Java API 或Python API 來完成Kudu 存儲系統中的數據讀寫操作,且Kudu 每張表單均有主鍵可作為索引進一步縮短了響應時間,Kudu API 在進行調用時運算均在數據磁盤上進行,此種方式處理簡單的聯機事務(OLTP)時是可行的;單在聯機分析處理(OLAP)方面,采用Impala-JDBC 的連接方式處理Kudu 存儲系統數據更為高效,Impala 自身并沒有存儲系統,在進行數據運算時,Impala 會將Kudu 存儲系統和HDFS 存儲系統中的數據放入內存中進行計算;基于大數據平臺512G的運算內存,將數據放入內存中計算的效率遠高于在數據磁盤上運算效率[18]。
為提升企業用戶調用大數據平臺數據的效率和充分利用大數據平臺內存資源,針對OLAP(聯機分析處理)和OLTP(聯機事務處理)兩種不同的業務場景均選擇使用Impala-JDBC 的連接方式與企業系統進行數據交互,其性能測試結果見表4。
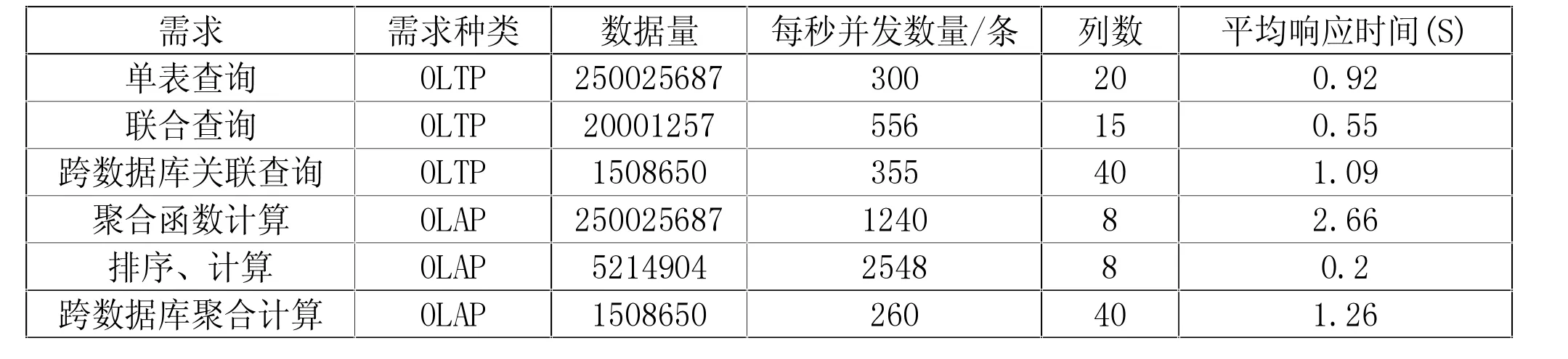
表4 基于Impala-JDBC 的OLAP 和OLTP 接口性能測試結果
從測試結果可以看出,基于Impala-JDBC 的OLAP和OLTP 接口性能可以滿足大數據平臺對企業提供電力輔助設備的實時監控業務的OLAP(聯機分析處理)和OLTP(聯機事務處理)兩種不同的業務場景的需求,達到了快速響應、提升企業用戶使用體驗的要求。
4 結束語
綜上所述,Kudu 存儲系統解決了Hadoop 大數據平臺對實時數據的處理短板,Kudu 存儲系統部署以來,高效、穩定的完成了實時數據入庫、數據的增量更新、實時查詢、對外提供高效的API 數據接口服務等工作,在電力輔助設備實時監控業務中發揮了極為重要的作用。后續在保障數據安全的前提下將不斷調優Kudu 存儲系統性能,進一步提升Kudu 存儲系統在電力輔助設備實時監控業務中的能力,為后期進行的深度數據挖掘做足準備。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年11期)2018-08-04 03:26:08
山東工業技術(2016年15期)2016-12-01 05:31:22
工業設計(2016年12期)2016-04-16 02:52:00
設備管理與維修(2015年12期)2015-04-09 06:57:00
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
消費者報道(2014年7期)2014-07-31 11:23:57
