基于迭代深度網(wǎng)絡(luò)的紅外圖像增強算法
2021-02-23 03:06:04陳世紅陳榮軍
激光與紅外 2021年1期
陳世紅,陳榮軍
(1.廣東生態(tài)工程職業(yè)學(xué)院信息工程系,廣東 廣州 510520;2.廣東技術(shù)師范大學(xué)計算機科學(xué)學(xué)院,廣東 廣州 510665)
1 引 言
為了提高紅外圖像的視覺效果,使其更符合人眼或計算機處理的要求,國內(nèi)外學(xué)者從軟硬件方向展開了科研攻關(guān)。在硬件領(lǐng)域,隨著大面陣、小間距的集成電路技術(shù)的發(fā)展,紅外圖像的分辨率也逐漸提升[1-3]。以昆明211所為代表的國產(chǎn)科研機構(gòu)已經(jīng)研制成功高分辨的探測器陣列[4]。由于制造工藝和材料性能的限制,單純依靠增加紅外焦平面陣列密度來提升成像質(zhì)量是非常困難的。同時,降低像元尺寸也會導(dǎo)致的探測靈敏度下降,信號噪聲增大。因此,在紅外探測器硬件性能提升有限的情況下,采用軟件技術(shù)提升圖像質(zhì)量是目前最經(jīng)濟可靠的方式。
紅外圖像增強是指從給定的低質(zhì)量圖像中恢復(fù)高清晰的圖像的過程。現(xiàn)有的紅外增強算法大致可以分為基于模型驅(qū)動的信號處理方法與基于數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)方法[4]。模型驅(qū)動主要是利用數(shù)學(xué)模型方法重建出高質(zhì)量的紅外圖像,其關(guān)鍵技術(shù)是如何構(gòu)造基于先驗正則的目標(biāo)函數(shù)[5-6],雖然在一定程度上改善了圖像的質(zhì)量,但實際采集的紅外圖像的受到各種干擾因素的影響。往往并不服從某種單一的假設(shè)先驗。文獻(xiàn)[7]假定紅外圖像中存在大量自相似區(qū)域,提出了基于低秩和鄰域嵌入的單幀紅外圖像增強算法,確保了重建圖像均勻區(qū)域的一致性,又保留了圖像的細(xì)節(jié)信息和邊緣輪廓的完整性,但該算法只適用于具有明顯邊界的面目標(biāo)場景,對于需要探測點目標(biāo)的對空紅外圖像的效果不理想。
相比之下,基于數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)方法不受成像模型的影響,這種方法在很大程度上主要針對大數(shù)據(jù)樣本學(xué)習(xí)潛在的隱藏特征,而不是對具體模型進行了優(yōu)化[8]。2015年,Dong等人首次將卷積神經(jīng)網(wǎng)絡(luò)(CNN)應(yīng)用于圖像增強重建,提出了SRCNN增強模型[9],通過將使用CNN模型來擬合低質(zhì)量圖像和高質(zhì)量圖像的映射關(guān)系,并使用大量的高/低圖像對訓(xùn)練模型,其結(jié)果優(yōu)于鄰域嵌入[7]和稀疏編碼。然而,SRCNN的三層結(jié)構(gòu)并不能滿足更高重建精度的要求,主要是由于低層卷積只能得到圖像的淺層紋理信息。為了獲得更準(zhǔn)確的深度特征并提升重建效果,有必要使用更深的卷積網(wǎng)絡(luò),Kim等人在VGG網(wǎng)絡(luò)和ResNet網(wǎng)絡(luò)的基礎(chǔ)上,設(shè)計了20層權(quán)值網(wǎng)絡(luò)的VDSR模型[9],解決了網(wǎng)絡(luò)深度增加引起的梯度爆炸問題。所有這些重建方法中的低質(zhì)量圖像都是先雙三次插值,再輸入網(wǎng)絡(luò)進行增強。文獻(xiàn)[10]提出了一種基于生成性對抗網(wǎng)絡(luò)(GAN)的圖像增強模型,通過引入感知損失函數(shù)提升重構(gòu)圖像細(xì)節(jié)。針對非盲影像去模糊問題,文獻(xiàn)[11]設(shè)計出多層感知網(wǎng)絡(luò)來去除重建偽影;文獻(xiàn)[12]采用DCNN進行非盲影像去模糊,并利用遷移學(xué)習(xí)理論,提升了深度網(wǎng)絡(luò)的學(xué)習(xí)效率。近年來,基于深度學(xué)習(xí)的紅外圖像增強算法取得了很好的增強性能,但大多數(shù)算法是將圖像增強問題當(dāng)作去噪問題來處理,通過將多層感知網(wǎng)絡(luò)級聯(lián)起來,并沒有探索圖像的固有特征,同時也忽略了觀測模型。
針對現(xiàn)有基于深度網(wǎng)絡(luò)的紅外增強應(yīng)用忽略了觀測模型,以及可解釋性較弱的問題,提出了一種改進紅外圖像深度增強模型,該模型將圖像增強任務(wù)嵌入到一個深度網(wǎng)絡(luò)中,通過增強網(wǎng)絡(luò)模塊和反投影模塊交錯優(yōu)化,實現(xiàn)紅外數(shù)據(jù)一致性約束。實驗結(jié)果也表明,該模型重建出的高質(zhì)量圖像在點目標(biāo)等弱小區(qū)域也能獲得清晰的效果。
2 基于迭代優(yōu)化的紅外增強模型
紅外圖像增強模型的數(shù)學(xué)本質(zhì)是一個NP難的數(shù)學(xué)優(yōu)化問題,其模型如下所示:
E=f(θ,x,y)+J(x)
(1)
其中,E表示目標(biāo)函數(shù);x,y分別表示需要重構(gòu)恢復(fù)的信號及其相應(yīng)的觀測信號;保真項f描述了x與y之間的約束關(guān)系,正則項J表征了先驗知識。大多數(shù)情況下式(1)的求解采用變量分離技術(shù),并將其分解為兩個子問題交替優(yōu)化。若新增一個輔助變量z,式(1)可以改寫為:
E=f(θ,x,y)+J(z),s.t.z=x
(2)
為了求解式(2),最常用的方法就是將z=x轉(zhuǎn)換成誤差項,增加到目標(biāo)函數(shù)中。也就是說,在實際應(yīng)用中式(2)可以進一步改寫:
(3)
根據(jù)交替方向乘子法思想,該模型可以通過交替求解兩個子問題來實現(xiàn)優(yōu)化:
(4)
(5)
可以看出,式(4)具有閉式解,一般表示為x(t+1)=W-1b,其中W通常是與退化矩陣A相關(guān)。然而,實際應(yīng)用中W的逆矩陣無法直接計算,只能采用經(jīng)典共軛梯度算法[13]求解x(t+1),其解如下所示:
x(t+1)=xt-δ(AT(Ax(t)-y)+η(x(t)-v(t)))
(6)

3 紅外增強網(wǎng)絡(luò)結(jié)構(gòu)
3.1 系統(tǒng)架構(gòu)


圖1 圖像增強模型框架
3.2 增強網(wǎng)絡(luò)模塊
現(xiàn)有的圖像增強優(yōu)化問題被分解為兩個單獨的子問題:一個用于處理數(shù)據(jù)保真項,另一個用于正則化項,通過交替求解獲得最優(yōu)的圖像質(zhì)量。具體地說,與正則化相關(guān)的子問題是一個純?nèi)ピ雴栴},因此也可以采用其他無法表示為正則化項的更復(fù)雜的去噪方法,例如BM3D[14],Low-Rank和Sparse-learning方法[15]。本文選用的圖像增強模塊是一種基于深度卷積網(wǎng)絡(luò)的學(xué)習(xí)模塊,旨在降低圖像的退化干擾,并盡可能地保留圖像的細(xì)節(jié)信息,尤其是保留弱小點目標(biāo)。
受DCNN在影像去噪應(yīng)用的啟發(fā),本文采用的增強網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示,該網(wǎng)絡(luò)結(jié)構(gòu)類似于U-net網(wǎng)絡(luò),可以分為特征提取與圖像重建模塊,其中特征提取部分采用多個3×3卷積,每個卷積后跟一個RELU和一個步長為2的用于下采樣的2×2最大池化操作,有助于增加神經(jīng)元的感受野大小,并降低提取到的特征圖的分辨率。本文設(shè)計了多個卷積層以提取不同層次下的深度特征,灰色箭頭所表示的特征編碼層如圖3(a)所示。每個特征編碼層包含4個3×3核的卷積層和ReLU非線性激活函數(shù),每次卷積過程將生成64通道特征映射。本文設(shè)計的結(jié)構(gòu)在前四個編碼層后面添加了一個以2為采樣因子的下采樣層,沿垂直/水平方向降低特征映射的空間分辨率。圖像重建模塊與特征提取模塊是相對應(yīng)的結(jié)構(gòu),重建模塊是由卷積層,上采樣層構(gòu)成,其中卷積層對應(yīng)著特征解碼,如圖3(b)所示。特征重建階段每個解碼塊由五個卷積層組成,第一層采用利用1×1卷積和ReLU控制卷積核的數(shù)量達(dá)到通道數(shù)大小的放縮,同時實現(xiàn)跨通道的交互和信息整合,將特征提到從128降到64。剩下的卷積層采用3×3核的卷積層和ReLU非線性激活函數(shù)重構(gòu)出64個通道的特征圖,并采用縮放因子2的反卷積獲取最終重構(gòu)特征。由于卷積層、池化層、上采樣層實現(xiàn)端到端的圖像增強,不可避免存在空間信息的丟失,導(dǎo)致重建圖像的細(xì)節(jié)不完整。因此,直接通過逐層特征提取與特征重構(gòu),最終重構(gòu)得到的紅外圖像丟失了大量的空間信息,不能完全恢復(fù)出精細(xì)的圖像細(xì)節(jié)。為了保留特征空間的細(xì)節(jié)信息,受U-net網(wǎng)絡(luò)啟發(fā),本文將特征編碼階段生成的深度特征與特征解碼階段對應(yīng)的同大小的上采樣特征進行融合,以獲得表征能力更強,細(xì)節(jié)更豐富的特征。為了操作方便,本文采用的特征融合是基于級聯(lián)實現(xiàn)。本文設(shè)計的增強網(wǎng)絡(luò)模塊主要恢復(fù)圖像中丟失的細(xì)節(jié),即高頻信息,具有更加魯棒的重建性能。

圖2 網(wǎng)絡(luò)增強模塊

圖3 編解碼模塊
3.3 網(wǎng)絡(luò)訓(xùn)練
使用變量分離技術(shù),強大DCNN去噪器可以為模型優(yōu)化帶來圖像先驗。值得注意的是,文獻(xiàn)[11]提出的DCNN網(wǎng)絡(luò)不必預(yù)先訓(xùn)練,而本文提出的網(wǎng)絡(luò)結(jié)構(gòu)是需要通過端到端訓(xùn)練。為了減少參數(shù)個數(shù)且避免過擬合,本文強制每次迭代運行的增強模塊共享相同的參數(shù),并采用最小均方誤差和感知損失函數(shù)共同優(yōu)化網(wǎng)絡(luò),其總損失函數(shù)表示為:
L=LMSE+λLp
(7)
其中,LMSE,Lp分別表示像素級歐氏距離與感知損失;λ是權(quán)值參數(shù)。感知損失更符合自然圖像分布規(guī)律,使重建結(jié)果具有非常逼真的細(xì)節(jié)效果。感知損失函數(shù)可以表示為:
(8)
其中,wi,hi分別表示特征映射圖的尺寸;Ci表示第i個卷積層;R(Y)=Y-X表示高頻殘差,理想情況下R(Y)≈N;式(8)可以采用隨機梯度下降算法優(yōu)化求解。
4 實驗結(jié)果與分析
為了驗證本文提出的深度網(wǎng)絡(luò)圖像重構(gòu)算法的有效性,本章設(shè)計了紅外圖像去模糊與紅外圖像去噪任務(wù),并為不同的任務(wù)訓(xùn)練了對應(yīng)的模型。
4.1 實驗數(shù)據(jù)集及參數(shù)設(shè)置
為了訓(xùn)練增強網(wǎng)絡(luò)模塊,實驗構(gòu)造了一個具有1000張圖像的訓(xùn)練樣本庫,所有的圖像都有制冷型紅外熱像儀采集,其默認(rèn)為高清晰圖像,其中圖像大小是640×480。同時,我們也構(gòu)造了一個50張不同場景的非制冷熱像儀采集的低質(zhì)量圖像作為測試庫。
本文提出的增強網(wǎng)絡(luò)采用Python3.5進行開發(fā),以TensorFlow作為深度學(xué)習(xí)框架實現(xiàn),所有實驗均在均在相同硬件平臺上進行。采用ADAM優(yōu)化器來訓(xùn)練網(wǎng)絡(luò),其參數(shù)設(shè)置為β1= 0.9,β2=0.999和ε= 10-8,并采用Xavier初始化方法對所提的網(wǎng)絡(luò)的卷積層進行初始設(shè)置,使得每一層輸出的方差盡量相等。另外,與退化矩陣A相關(guān)的線性層則由退化模型A進行初始化,參數(shù)δ與η則分別經(jīng)驗設(shè)置為0.1和0.9。實驗結(jié)果表明,圖1所示的處理流程僅僅需要6次迭代就可以得到滿意的增強效果。圖像質(zhì)量評價主要采用峰值信噪比(PSNR)和結(jié)構(gòu)相似性度量(SSIM)對各算法進行定量描述。
4.2 定性定量分析
由于圖像增強問題可以表示為y=Ax+n。對于A的不同設(shè)置,可以表示不同的圖像增強問題。本文提出的算法能夠應(yīng)用于紅外圖像去噪、去模糊等任務(wù)中。為了便于定性定量的分析,本章將對不同任務(wù)進行針對性分析。
4.2.1 圖像去噪
對于圖像去噪任務(wù),退化矩陣A=I,因此圖像增強問題就裝換成y=x+n。本文所提出的去噪網(wǎng)絡(luò)嵌入變量分析優(yōu)化模型,通過逐漸迭代增強紅外圖像的清晰度。
為了客觀公正的分析本文提出的模型在去噪任務(wù)上的性能,實驗選用幾種常用的對比算法進行比較,即BM3D方法[14]、EPLL方法[15]、TNRD方法[16]、DnCNNs方法[17]和MemNet方法[18]。BM3D是一種經(jīng)典的去噪算法,該算法利用圖像中的自相似性構(gòu)建相似性矩陣,并在變換域上實現(xiàn)軟閾值去噪。EPLL是一種采用最大似然估計算法對高斯混合模型進行訓(xùn)練的去噪模型。TNRD是一種非線性反應(yīng)擴散模型,該模型通過展開固定數(shù)量的梯度下降推斷步驟來學(xué)習(xí)出無噪圖像;DnCNNs是利用前饋去噪卷積神經(jīng)網(wǎng)絡(luò)來實現(xiàn)去噪;MemNet是一種基于限制的長期記憶網(wǎng)絡(luò)的圖像增強算法。表1展示了所有對比算法的平均PSNR和SSIM結(jié)果。對于低噪聲水平,MemNet方法與DnCNNs方法的增強效果類似,但指標(biāo)上都不如本文提出的算法;對于高噪聲水平,MemNet方法,DnCNNs方法與本文方法在噪聲方差50下的SSIM分別是0.783,0.625與0.798,因此本文所提模型能夠重構(gòu)出更多的圖像細(xì)節(jié)信息,去噪性能優(yōu)于MemNet方法。非均勻噪聲是紅外圖像中不同位置的噪聲服從不同分布,實驗采用文獻(xiàn)[19]的非均勻噪聲仿真方法。表2展示了非均勻噪聲下的圖像增強的定量指標(biāo)。本文的模型是在迭代優(yōu)化中引入了深度網(wǎng)絡(luò),提升了去噪的性能。
為了進一步驗證該方法的有效性,實驗選用了多幅圖像做定性比較,如圖4與圖5所示。可以看出,基于模型的方法(即BM3D和EPLL)恢復(fù)的圖像邊緣和紋理被過度平滑。基于深度學(xué)習(xí)的方法:TNRD、DnCNNs、MemNet和本文方法,的重構(gòu)圖像具有更加清晰的細(xì)節(jié)信息,尤其是圖4(a)中樹叢,一些紋理信息很明顯,而BM3D方法則過度平滑。雖然BM3D在樹干區(qū)域的效果很清晰,但對于很難找到自相似塊的空天背景的區(qū)域,重建效果較差,且存在較多劃痕。MemNet采用不同的記憶單元實現(xiàn)密集連接,由于卷積核為1×1的卷積層,負(fù)責(zé)將所有記憶單元的存儲信息分別輸出,大大耗費運算資源,且上采樣恢復(fù)過程會引入偽影噪聲。從重構(gòu)結(jié)果也可以看出,圖4(b)中水渠大壩處存在一些條紋,這就是在上采樣過程增加的偽影。DnCNNs是采用單個殘差單元來預(yù)測殘差圖像,并采用批量歸一化加快訓(xùn)練效率。由于DnCNNs要求端到端的訓(xùn)練,實現(xiàn)輸入輸出大小保持一致,需要在卷積過程中補0填充,這使得重建結(jié)果存在邊界偽影;圖4(c)是把公路上的車輛都去除,而本文算法不僅增強了弱小目標(biāo),還盡可能還原了細(xì)節(jié)信息;圖4(d)與4(e)在同質(zhì)區(qū)域仍然存在一些噪聲。圖5是非制冷紅外采集圖像的一個小區(qū)域的重建結(jié)果對比,其中BM3D、EPLL方法則過度平滑,深度學(xué)習(xí)算法的結(jié)果優(yōu)于傳統(tǒng)算法。本文的算法在去除噪聲的同時,也能保持好細(xì)節(jié)信息。因此,與TNRD、DnCNN-S和MemNet方法相比,本文提出的方法在恢復(fù)圖像細(xì)節(jié)方面取得了更好的效果。

圖4 不同算法的去噪性能對比

圖5 非制冷紅外采集圖像的一個小區(qū)域的重建結(jié)果對比
4.2.2 紅外圖像去模糊
對于去模糊任務(wù),退化矩陣A是模糊卷積核。為了訓(xùn)練去模糊網(wǎng)絡(luò),首先將訓(xùn)練圖像與模糊核卷積,生成模糊圖像,然后從模糊圖像中提取128×128大小的訓(xùn)練圖像塊,并在模糊樣本中加入隨機方差的高斯噪聲。清晰圖像與對應(yīng)模糊圖像的對比圖如圖6所示。訓(xùn)練樣本也通過翻轉(zhuǎn)和旋轉(zhuǎn)等操作對數(shù)據(jù)集進行擴充,總共生成300000個圖像塊樣本用于訓(xùn)練。為了便于定量分析,本文選用的模糊核分別是標(biāo)準(zhǔn)差為1.6的25×25高斯模糊核與文獻(xiàn)[20]給出的運動模糊核。本文選用的對比算法分別是EPLL[20]、IDDBM3D[21],NCSR[22]和MemNet,其中MemNet需要模糊圖像塊對和原始圖像塊組成的樣本對進行訓(xùn)練。為了進行公平的比較,所有的深度學(xué)習(xí)模型都采用相同的訓(xùn)練樣本與測試樣本。
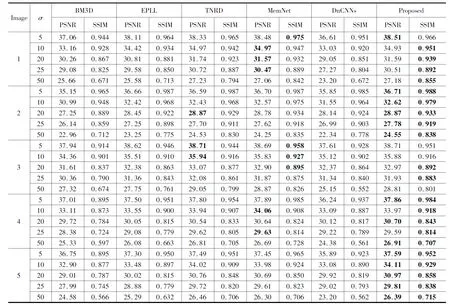
表1 部分測試圖像的PSNR與SSIM結(jié)果對比

表2 非均勻噪聲下的重構(gòu)質(zhì)量

圖6 模糊圖像對比
所有對比算法的去模糊結(jié)果如表3所示。可以看出,本文提出的方法與MemNet算法的去模糊性能優(yōu)于EPLL、IDDBM3D和NCSR[24],而本文所提方法的平均性能比MemNet方法高出0.58 dB。對于噪聲方差超過20的運動模糊核圖像,本文提出的模型比MemNet方法稍差,但后者需要更多的迭代(最多30次迭代)才能得到滿意的結(jié)果。圖7展示了所有對比方法的去模糊結(jié)果。與其他去模糊方法相比,本文所提出的方法不僅獲得了更銳利的邊緣,而且恢復(fù)了更多的細(xì)節(jié)信息。圖7(a)的原始模糊圖像邊緣模糊,細(xì)節(jié)不清楚,經(jīng)過EPLL、IDDBM3D和NCSR處理后,所有的結(jié)果都能獲得相對清晰的邊緣。EPLL是一種利用圖像塊似然概率先驗信息的對數(shù)期望實現(xiàn)圖像去模糊。從圖7(b)可以看出,該方法對高斯模糊的效果較好,但對運動模糊下的重建效果較差,主要歸咎于先驗信息對運動模糊的擬合精度較差。IDDBM3D是基于BM3D的改進算法,主要用于圖像去模糊。從處理結(jié)果可以看出,IDDBM3D對勻質(zhì)區(qū)域的處理效果較好,尤其是圖中的路面結(jié)果非常平滑。NCSR是基于中心稀疏的迭代型去模糊算法,該算法的去模糊效果優(yōu)于IDDBM3D與EPLL,細(xì)微的紋理和邊界保留的較完整,但其重構(gòu)結(jié)果不如基于深度學(xué)習(xí)的MemNet與本文提出的模型。由于非制冷紅外熱像儀采集的紅外圖像存在大量噪聲,且細(xì)節(jié)模糊,從圖7(e)可以看出本文提出的改進的深度神經(jīng)網(wǎng)絡(luò)能夠提升圖像恢復(fù)的質(zhì)量。尤其是對于空天背景的小目標(biāo)圖像,本文提出的算法考慮了保真項的約束,增強了原始圖像的弱小目標(biāo)的細(xì)節(jié)。表3的定量結(jié)果也表明了本文提出的去模糊算法的PSNR與SSIM分別高于MemNet 0.43 dB與0.1定性定量實驗結(jié)果表明,本文研究方法取得了優(yōu)于其他對比算法的復(fù)原效果。

表3 去模糊算法的平均PSNR與SSIM

圖7 去模糊對比
5 結(jié) 論
由于基于深度模型的圖像恢復(fù)算法忽略了觀測模型,導(dǎo)致了重構(gòu)的圖像存在虛假的紋理,尤其是對于紅外圖像中的弱小目標(biāo),大多數(shù)算法也并不能增強弱小目標(biāo)的細(xì)節(jié)。本文提出了一種改進的深度神經(jīng)網(wǎng)絡(luò)用于提升圖像恢復(fù)的質(zhì)量,該網(wǎng)絡(luò)將圖像增強模塊嵌入到基于迭代優(yōu)化模型中,通過圖像增強模塊和反投影模塊交錯而成,增強數(shù)據(jù)的一致性,保留紋理細(xì)節(jié)。實驗結(jié)果表明,本文提出的方法可以在圖像去噪和去模糊任務(wù)上獲得非常有競爭力的恢復(fù)結(jié)果。下一步,本文將著重對算法性能進行優(yōu)化,并將其移植到嵌入式智能平臺,實現(xiàn)工程化應(yīng)用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
