基于消息優先級隊列分布式交換網元調用系統的研究
2021-02-27 02:07:00胡佳
電腦與電信 2021年11期
關鍵詞:服務
胡佳
(中國聯合網絡通信有限公司廣東省分公司,廣東 廣州 510320)
1 引言
隨著移動互聯網和手機的不斷發展和普及,電信行業的數據業務量呈爆發式增長。針對如何處理如此大量的數據,在現有的解決方案中最普遍的就是搭建一個分布式的消息隊列進行數據存儲,數據存儲在消息隊列中等待被處理,這樣可以實現消息的不遺漏處理。
現有的按照普通消息隊列進行消費的處理方式存在明顯的缺點。數據業務可細分出緊急業務,正常業務,低優先級業務等,當大量的低優先級或者普通業務堆積時,在現有的普通的消息隊列中,需要按照時間順序來一個一個處理,緊急業務不能得到優先處理,導致緊急業務被貽誤,從而造成不必要的損失。
本研究的目的在于提供一種基于消息優先級隊列的分布式交換網元調用系統,解決現有技術存在的無法按照優先級處理訂單的問題。通過增添消息隊列topic個數并且賦予每個消息隊列topic優先級屬性,然后按照高優先級的消息隊列topic優先消費來將處理訂單的順序重新排列,達到高優先級的訂單優先處理的目的,而且保證了消息隊列還是分布式。同時,通過Json微服務調用工單拆分模塊,將優先級高的訂單分配到優先級高的消息隊列中。最后高優先級的訂單會優先執行工單激活模塊,從而使多主機多節點同時工作,起到負載均衡和自動切換的作用,實現高可用。
2 總體技術方案
通過Json微服務調用工單拆分接口內的方法,工單拆分模塊接收到Json調用后會接收到該訂單要辦理的業務的相關數據信息,在這個模塊中有三部分要操作,即工單校驗、工單拆分、工單入庫。接到上游系統發來的業務Json后,對輸入參數進行校驗,如果缺少參數,則返回;如果參數完整正確,則繼續。對工單進行拆分,遍歷工單的服務編碼,并結合參數編碼匹配對應的子服務,如果無,則直接將服務寫入服務列表;如果有,則生成新的子工單,并接入對應的平臺和服務。遍歷工單服務過程中,拆分新的服務編碼時,如果發現已有工單存在對應的平臺,則嘗試合并工單服務列表;如果已有工單服務中存在串行服務,則生成新的工單。遍歷完工單的服務編碼后,將業務號碼發送kafka中,kafka的topic為業務Json中指定的優先級topic。
工單調度模塊采用多線程處理,工單獲取Get線程,工單完工Finish線程,以及網元redis隊列:in隊列和out隊列。Get線程根據號碼處理相關的業務,號碼來源是kafka消息,按照優先級從高到低的順序依次消費kafka中的存放業務號碼的topic,并根據號碼取出數據庫中關聯的未處理工單。根據網元類型將工單分類打包,并放到待發送隊列in隊列。Finish線程獲取待完工隊列out中的單個工單,并根據當前工單的狀態做不同的處理。工單激活模塊會提取工單調度模塊中保存到in隊列中的工單數據進行工單翻譯和工單交互。工單翻譯為將工單的服務翻譯為具體的指令集,工單交互為將工單的具體指令集發送到網元。
工單激活模塊收到待發送工單列表集合后,會檢查工單的服務名和當前激活模塊服務名是否一致。對工單集合依次進行翻譯,遍歷工單列表和遍歷工單的服務列表,完成工單服務編碼對應的指令的映射、工單參數的變種和替換。遍歷工單的服務列表,對工單的每個服務編碼的多個指令進行交互,并根據交互的結構進行綜合判斷。如果交互成功,則進行下一個指令的交互;如果交互失敗,則轉換失敗原因和進行容錯判斷。所有工單的所有服務編碼對應的所有指令交互完成后,進行整個工單列表集合的返回。
2.1 消息優先級隊列的分布式交換網元調用
聯指云化系統是一種基于消息優先級隊列分布式交換網元調用技術的系統(如圖1所示),主要用到三份模塊化的代碼,即工單拆分、工單調度、工單激活這三個模塊,和一個數據緩存集群、一個消息隊列集群、數據持久化集群。本系統根據工具對業務的契合度和工具的優缺點,決定選用spring-cloud來模塊化代碼,redis工具來作為數據緩存集群,kafka作為分布式消息隊列集群。通過Json微服務調用聯指云化系統,數據經過該系統的處理后就會按照高優先級到低優先級的順序發送指令去外圍網元系統集合。
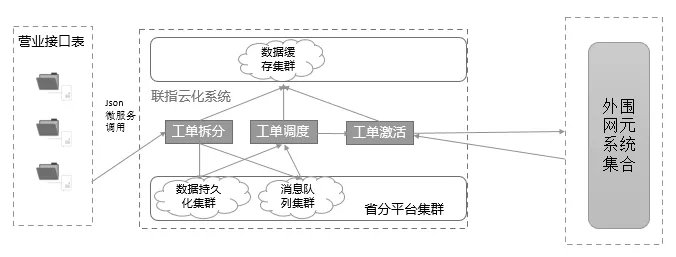
圖1 基于消息優先級隊列的分布式交換網元調用的流程示意圖
2.2 消息優先級隊列的分布式交換網元調用中工單拆分
運行的spring-cloud程序接收營業接口表的Json微服務調用。如圖2,工單拆分模塊首先會對Json數據的完整性進行校驗,如參數的個數是否符合,如果參數為空,就直接返回,以及在日志中記錄該條數據的報錯和流水號,以便后期的報錯定位。如果參數不為空則代表接收到的數據是完整的,那么程序會繼續往下走。工單拆分的第二步是對接收到的工單數據進行服務編碼匹配,工單數據有兩種類型,一種是服務編碼所代表的服務還能被細分成多個服務的,含有這種服務編碼的數據會在這一步操作中被工單拆分模塊拆分成多條數據。而另外一種數據則是服務編碼僅僅代表一個服務,無法再細分下去了,那么這條數據就會跳過這一步服務代碼拆分操作,直接進入下一步操作。在工單拆分的第三步操作中,處理完的數據分為兩種類型的數據:一類是數據字段中網元字段相同的數據;另一類是網元字段不相同的數據。如果網元字段相同,那么代表這些數據將會發送去同一個目的地,同一個外圍網元,所以將這類數據進行合并然后保存在數據庫中;如果網元字段不相同,則代表發往不同外圍網元,不進行數據合并直接保存到數據庫中。在這一步進行工單合并的用意是減少同一網元的數據多次發送,降低與外圍網元系統集合交互的次數,避免因為網絡原因而導致的不必要損失。工單拆分的最后一步操作是按照Json中優先級字段,將數據寫入到kafka的不同topic中(topic01,topic02,topic03,topic0n),優先級依次遞減,到此工單拆分模塊執行結束。
2.3 消息優先級隊列的分布式交換網元調用中工單調度
當數據經過工單拆分模塊后會保存在兩個地方(如圖3所示)。
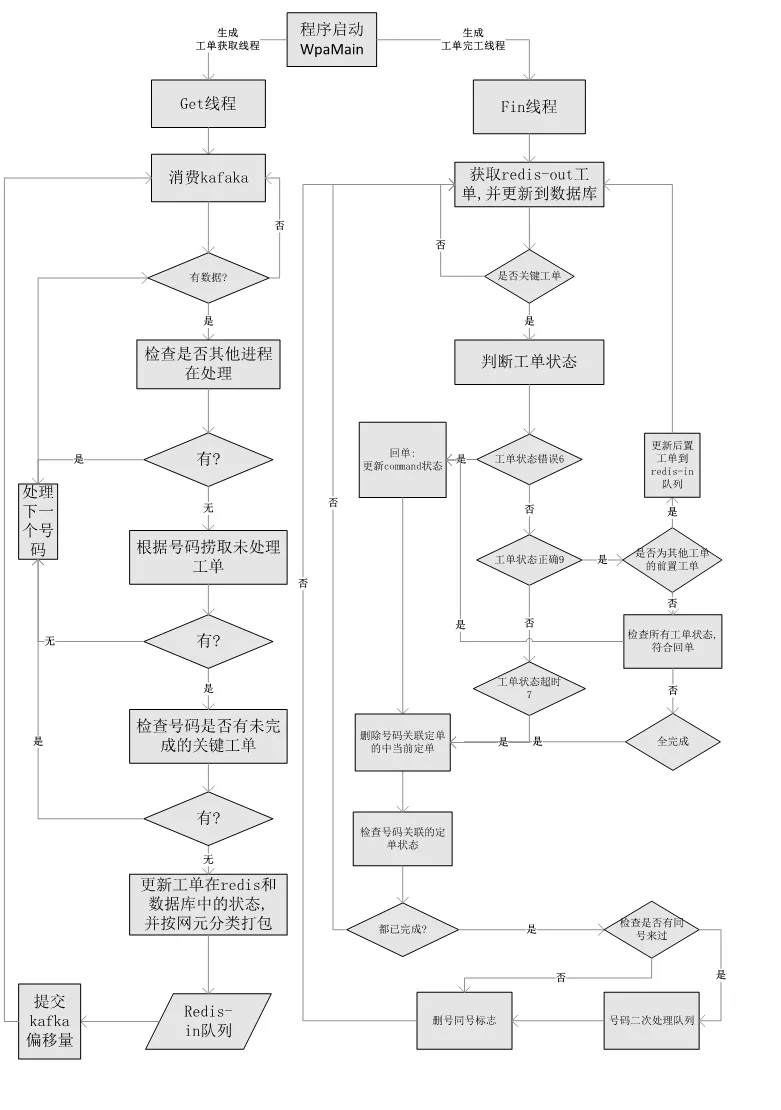
圖3 基于消息優先級隊列的分布式交換網元調用中工單調度的流程示意圖
在工單調度模塊有2個線程,分別為Get線程與Fin線程,而保存在kafka中的數據就會觸發工單調度的Get線程。Get線程的第一步操作是按照優先級進行kafka消費,采用算法讀取(topic01,topic02,topic03,topic0n),以此類推,Get線程沒有消費到數據時會一直消費kafka,當消費到了數據時就會進行下一步操作,檢查該條數據是否有其他進程在處理,如果有的話就跳過這條數據,處理下一條數據,如果沒有線程在處理這條數據的話就會根據這條數據中的號碼字段來撈取數據庫中未處理的工單,當在數據庫中撈取不到該號碼的相關工單就跳過這條數據,處理下一條數據,如果在數據庫中撈取到該號碼的相關工單就會進行下一步的判斷,檢查號碼是否有未完成的關鍵工單,如果有就跳過,處理下一條數據,如果沒有就代表這條工單已經全部完成,則更新工單在redis和數據庫中的狀態,并按網元分類打包,放到待發送隊列redis–in列表。
工單調度中的Fin線程會一直去獲取redis-out列表中的工單,第一步操作會判斷這條數據是否為關鍵工單,當不是關鍵工單的時候會跳過,繼續獲取下一條數據,當獲取到關鍵工單數據的時候會進行第二步操作,判斷工單狀態(錯誤,成功,超時等)。如果這條數據工單狀態為錯誤,就回單,也就是更新數據庫中的狀態為錯誤;如果這條數據工單狀態為正確,會進行下一步判斷,是否為其他工單的前置工單,是的話就更新后置工單到redis-in列表中然后回到Fin線程最開始,不是話就檢查所有工單狀態,符合回單就更新表狀態,不符合就刪除該號碼關聯定單中當前定單;如果這條數據的工單狀態為超時則直接刪除該號碼關聯定單中當前定單,經過第二步數據狀態判斷的操作后就會進行第三步操作,檢查該號碼關聯的訂單狀態,如果還有沒完成的關鍵訂單就繼續等待,如果關鍵訂單均完成后就會檢查是否有同一個號碼的其他訂單,有的話就進入號碼二次處理隊列,沒有的話就刪除同號標志。
2.4 消息優先級隊列的分布式交換網元調用中工單激活
如圖4所示,在工單拆分模塊中處理完的數據,也就是圖中接收到的Json請求并且通過了服務名校驗的數據,這些數據存到了redis-in 列表中,工單激活模塊會一直去redis-in 列表中獲取數據,當獲取到一條數據的時候就會進行第一步操作——工單翻譯,首先會處理數據中的特殊服務,如果在工單服務列表中匹配不到的話就跳過,如果匹配到了就判斷特殊服務類型并處理服務列表;其次是處理擴展參數,如果遍歷工單參數列表后發現變種參數的話就直接生成變種參數然后加入擴展參數列表,如果沒發現變種參數就直接加入擴展參數列表;再次就是獲取服務編碼的配置,替換服務對象;最后是指令代碼參數替換,擴展參數替換指令模板。工單翻譯運行到這里就完成了,每條工單被翻譯成能夠被網元理解的指令。
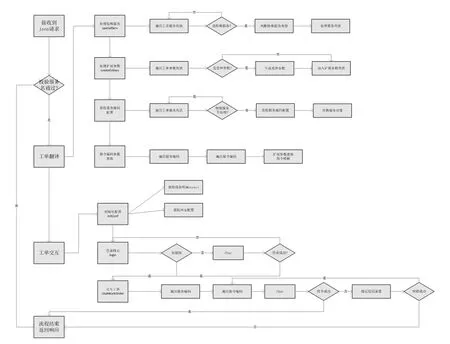
圖4 基于消息優先級隊列的分布式交換網元調用中工單激活的流程示意圖
當工單翻譯完了之后就會和對應的網元進行工單交互,首先會去初始化登錄的配置,獲取線程所屬socket和網元的配置,然后就能夠登錄到對應的網元,并根據交互的結構進行綜合判斷,如果交互成功,則進行下一個指令的交互。如果交互失敗,則轉換失敗原因和進行容錯判斷。所有工單的所有服務編碼對應的所有指令交互完成后,進行整個工單列表集合的返回。
2.5 運行效果
高峰期工單處理能力比未改造消息優先級隊列時:原來100萬/天,提升到>1000萬/天(10倍);高峰期工單處理時長:原來14 秒,縮短到<2 秒(7 倍);高峰期聯指處理能力:原來100 萬/天,提升到>1000 萬/天(10 倍);高峰期指令處理時長(含網元時間):原來17 秒,縮短到<3 秒(6 倍);工單并發處理數:原來10TPS,提升到>200TPS(20倍)。
3 結語
本系統通過Json微服務調用工單拆分模塊,將優先級高的訂單分配到優先級高的消息隊列中,然后工單調度系統按照高優先級隊列優先處理原則進行工單的調度,最后高優先級的訂單會優先執行工單激活模塊,這樣既保證了消息的隊列分布式處理,又能將訂單進行排序,以提高系統效率,強化系統能力,擴大系統使用范圍,同時具備云平臺的高效率、高可用、高擴展特點,簡化運維操作,釋放人力資源。高效率即是模塊微服務化,輕Json 格式調用,去除耗時的數據庫掃表操作,使用中間件緩存。高可用即是系統分布式部署,多主機多節點同時工作,起到負載均衡和自動切換的作用,實現高可用。
猜你喜歡
杭州金融研修學院學報(2022年5期)2022-06-15 11:41:48
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年11期)2019-08-13 00:49:08
今日農業(2019年13期)2019-08-12 07:59:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
銅仁學院學報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
