基于膚色分割和卷積神經(jīng)網(wǎng)絡(luò)的手語識別系統(tǒng)
2021-02-28 11:14:29劉濤馬靜徐軍鄭煜偉唐兆軍付琳周瑩瑩
電腦知識與技術(shù) 2021年35期
劉濤 馬靜 徐軍 鄭煜偉 唐兆軍 付琳 周瑩瑩


摘要:針對聽障人士手語交流的問題,設(shè)計了一種基于膚色分割和卷積神經(jīng)網(wǎng)絡(luò)的手語識別系統(tǒng)。首先,利用視覺傳感器采集不同的手勢圖像,然后基于YCrCb空間對手勢圖像進行膚色分割,構(gòu)建手勢圖像數(shù)據(jù)集,采用卷積神經(jīng)網(wǎng)絡(luò)對手勢圖像數(shù)據(jù)進行特征提取與分類,將訓練與測試得到的最優(yōu)模型導入樹莓派,使用訊飛語音包將識別結(jié)果轉(zhuǎn)化為語音,實現(xiàn)語音播報手語識別結(jié)果。
關(guān)鍵詞: 膚色分割; YCrCb; 卷積神經(jīng)網(wǎng)絡(luò); 手語識別
中圖分類號:TP183 ? ? 文獻標識碼:A
文章編號:1009-3044(2021)35-0014-04
Sign Language Recognition System Based on Skin Color Detection and Convolutional Neural Network
LIU Tao,MA Jing ,XU Jun,ZHENG Yu-wei,TANG Zhao-jun,F(xiàn)U Lin,ZHOU Ying-ying
(Harbin University of Science And Technology, School of Measurement and Control Technology and Communication Engineering, Harbin 150000, China)
Abstract:Aiming at the problem of sign language communication for the hearing impaired, a sign language recognition system based on skin color segmentation and convolutional neural network is proposed. First, the visual sensor is used to collect different gesture images, and then the gesture image is segmented based on the YCrCb space to construct the gesture Image data set, using convolutional neural network to extract and classify gesture image data, import the optimal model obtained from training and testing into the Raspberry Pi, use the iFLYTEK voice package to convert the recognition result into speech, and realize the speech broadcast sign language recognition result.
Key words: skin tone segmentation; YCrCb; convolutional neural network; sign language recognition
1 引言
手語作為聽障人士的“語言”表達形式,含有明確的信息。而正常人需要進行系統(tǒng)學習才能與聽障人士進行良好溝通,所以正確識別聽障人士的手語信息是非常重要的。隨著科學技術(shù)的不斷發(fā)展,手語識別技術(shù)已經(jīng)成為人機共融領(lǐng)域的熱門研究方向。
目前,眾多學者對手語識別進行了研究,如基于傳感手套的手語識別系統(tǒng)[1]、基于肌電傳感器的手語識別系統(tǒng)[2]、基于深度傳感器的手語識別系統(tǒng)[3]等。其中文獻[1-2]需要可穿戴設(shè)備的支持,文獻[3]需要對手部進行復雜建模。上述有關(guān)于手語識別的研究都有各自的適用要求,為了滿足實際手語識別所需的便攜性和易使用性,本文設(shè)計了一種基于膚色分割和卷積神經(jīng)網(wǎng)絡(luò)的手語識別系統(tǒng),通過YCrCb空間對手勢圖像進行膚色分割,然后使用卷積神經(jīng)網(wǎng)絡(luò)來代替?zhèn)鹘y(tǒng)的特征提取方法提取手部圖像特征和建立手語識別模型,完成手語圖像信息的識別與分類。
2 膚色分割與卷積神經(jīng)網(wǎng)絡(luò)
2.1 ?膚色分割
膚色分割是一種通過篩選圖像中符合膚色范圍像素實現(xiàn)膚色提取的方法,在手部跟蹤、人機交互等領(lǐng)域,具有巨大的潛力和應用前景。
2.1.1 顏色空間
顏色空間,也被稱為色彩模型。學者們使用不同維度空間坐標構(gòu)建了若干色彩模型,用一維、二維、三維或者四維空間坐標表示某種色彩[4]。目前情況,國際上常用的顏色空間有YCrCb、RGB、HSV等。各個顏色空間描述的顏色都有不同程度的差異。
我們常常把RGB空間圖像轉(zhuǎn)化為YCbCr顏色空間,然后再進行圖像處理。YCbCr顏色空間的Y是指灰階值,可以表示明亮度,Cb與Cr分別可以表示成藍色分量、紅色分量與亮度的差值。YCbCr顏色空間有將色度與亮度分開的特點,在YCbCr顏色空間中膚色的聚類特性較好,能夠較好地限制膚色分布區(qū)域[5]。本文通過YCbCr顏色空間對圖像進行膚色區(qū)域分割。
2.1.2 膚色檢測
通過轉(zhuǎn)換公式[6]將RGB顏色空間轉(zhuǎn)換進而得到Y(jié)CbCr顏色空間,轉(zhuǎn)換公式如下:
[Y=0.299R+0.587G+0.114BCr=R-YCb=B-Y] ? ? ? ? ? ? ? (1)
根據(jù)實驗表明,人體膚色在CbCr平面上的范圍為[77≤Cb≤127,133≤Cr≤173]。本研究利用公式(1)將圖像從RGB顏色空間轉(zhuǎn)化為YCbCr顏色空間,然后通過設(shè)定圖像在CbCr平面上的投影范圍,從而將含有膚色的部分從背景圖像中分離出來,如圖1所示。
在實際的膚色分割中,往往會受到類似膚色的顏色背景干擾,此時膚色分割往往分離出一些非膚色區(qū)域,而這些非膚色區(qū)域往往會影響最后模型訓練的效果。因此,本研究先對膚色提取后圖像進行開運算,即先腐蝕后膨脹,去除孤立的小點,毛刺,然后對各個聯(lián)通區(qū)域進行計算,獲取出最大聯(lián)通區(qū)域,并將其提取出來,這樣便能排除膚色分割后圖像中的非膚色區(qū)域帶來的干擾。
如圖2所示,當原圖像出現(xiàn)非膚色區(qū)域或者非手部圖像時,通過上述等操作能夠有效地排除非膚色區(qū)域或者非手部圖像所帶來的干擾。但是當非膚色區(qū)域或者非手語圖像的聯(lián)通區(qū)域面積大于手部圖像面積時,上述算法會將手部圖像剔除,所以在實際操作過程中避免出現(xiàn)上述情況便能取得很好的手部圖像提取效果。
2.2 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)是一類包含了卷積運算的神經(jīng)網(wǎng)絡(luò),是深度學習的代表算法之一[6]。本研究利用卷積神經(jīng)網(wǎng)絡(luò)實現(xiàn)手部圖像特征的提取和手語識別模型的構(gòu)建。
2.2.1 網(wǎng)絡(luò)結(jié)構(gòu)
經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。其分別參照LeNet-5,LeNet-5并由Lecun作為手寫數(shù)字識別設(shè)計的卷積網(wǎng)絡(luò)結(jié)構(gòu)。該結(jié)構(gòu)由2層卷積層、2層池化層、1層全連接層構(gòu)成[7]。
卷積層,又叫作特征提取層,一般采用3[×]3、5[×]5、7[×]7大小的卷積核,對輸入的圖像進行卷積操作。卷積層有著加強特征,降低噪聲的作用。輸入的原始圖像用[X]表示,[Qi]為卷積網(wǎng)絡(luò)第[i]層的特征圖像([Q0=X])。卷積的產(chǎn)生過程可以表示為:
[Qi=f(Qi-1*Ti+bi)] ? ? ? ? ? ? ? ? ? ? ? (2)
其中,[Wi]表示為第[i]層卷積核的權(quán)值矩陣,[*]表示為卷積運算,[bi]為偏置矩陣。
池化層是對數(shù)據(jù)進行降維,也就是所謂的下采樣。常見的池化方法有均勻池化和最大池化,此處采用最大池化的方法,把圖像數(shù)據(jù)劃分成若干個2[×]2的區(qū)域,然后在這四個之中取最大值,從而形成新的數(shù)據(jù)輸出。
而全連接層的作用相當于一個分類器。
2.2.2 AlexNet模型
本研究采用AlexNet模型來訓練手語識別模型,AlexNet模型架構(gòu)如圖5所示。AlexNet模型包括有5個卷積層和3個全連接層。其中有3個地方還做了最大池化處理。激活函數(shù)采用線性校正單元ReLU函數(shù),即[ReLUx=max (0,x)]。
同時,AlexNet還采用了局部響應歸一化的處理,進一步改善了卷積神經(jīng)網(wǎng)絡(luò)性能,具體公式如下:
[bix,y=aix,y/(k+αj=max (0,i-n/2)min (N-1,i+n/2)(aix,y)2)β] (3)
[aix,y]表示第[i]個卷積面上在位置[(x,y)]的值,[bix,y]表示局部響應歸一化的值,N是卷積面的總數(shù),n是相鄰面的個數(shù),[k,α,β]是可調(diào)參數(shù),可以通過選擇合適的參數(shù)來減少錯誤率[8]。
3 ?手語識別系統(tǒng)
3.1系統(tǒng)總體結(jié)構(gòu)
整個手語識別系統(tǒng)采用模塊化設(shè)計方法,總共可以分為數(shù)據(jù)采集模塊、模型訓練模塊、嵌入式硬件模塊、手語翻譯模塊。系統(tǒng)總體結(jié)構(gòu)如圖6所示。數(shù)據(jù)采集模塊目前有兩種途徑:一是利用高分辨率攝像頭進行手語圖片的采集和存儲,二是下載現(xiàn)有的American Sign Language(ASL)或者Chinese Sign Language(CSL)數(shù)據(jù)集;模型訓練模塊是通過卷積神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)進行訓練和測試,并選出最優(yōu)模型作為最終的手語識別模型;嵌入式硬件模塊主要以微型計算機樹莓派4B作為主控器,在其上連接觸摸屏、攝像頭來分別實現(xiàn)人機交互、實時手語識別;手語翻譯模塊是通過導入訊飛語音包到樹莓派上,再連接上揚聲器實現(xiàn)語音播報的功能。
用戶點擊數(shù)據(jù)采集功能時,將自己的手部對準攝像頭,按下對應的字母鍵,系統(tǒng)就會對圖像進行采集。采集成功之后系統(tǒng)將會生成圖片轉(zhuǎn)為NPZ格式。采集完成以后按Q鍵存儲數(shù)據(jù),下方會顯示采集數(shù)據(jù)的種類及數(shù)量。本系統(tǒng)的手語識別內(nèi)容包含A、B、C、D、E、F,可根據(jù)實際需求改動相應內(nèi)容。點擊手語翻譯后,將手部對準攝像頭即可進行實時手語翻譯。當用戶對系統(tǒng)不熟悉時,可以打開操作提示,按照系統(tǒng)的提示進行手語識別操作。
系統(tǒng)主界面和采集界面如圖7所示。
3.2 ?實驗流程
3.2.1 數(shù)據(jù)集構(gòu)建
目前,數(shù)據(jù)采集有兩種途徑:一是利用高分辨率攝像頭進行手語圖片的采集和存儲;二是下載現(xiàn)有的ASL或者CSL數(shù)據(jù)集。途徑一利用前文所述的膚色分割技術(shù),能夠?qū)⑹植繄D像從復雜背景中提取出來,降低環(huán)境帶來的干擾,而現(xiàn)有數(shù)據(jù)集無法實現(xiàn)這一點。實驗對現(xiàn)有的ASL Alphabet手語數(shù)據(jù)庫進行訓練,以期驗證利用TensorFlow搭建的AlexNet模型能夠?qū)崿F(xiàn)圖像識別與分類的功能。
本文實驗所選取ASL Alphabet手語數(shù)據(jù)庫作為基礎(chǔ)數(shù)據(jù)集。該數(shù)據(jù)集包含87000張200[×]200像素的圖像,其中每一種英文靜態(tài)手語數(shù)據(jù)為3000張。訓練選取了其中A、B、C、D、E、F六種手語的圖像,并按照7:3的比例隨機將18000張圖像分為了12600個訓練集和5400個測試集。
3.2.2 模型訓練設(shè)置
卷積神經(jīng)網(wǎng)絡(luò)的訓練采用的是誤差反向傳播算法進行訓練。
1)計算[softmax]損失函數(shù):
[HP,T=-1Cplog (T)]
其中T為樣本的實際輸出,
[T=[softmaxy1,softmaxy2,...,softmax(yi=n)]],P為樣本的期望輸出。交叉熵表現(xiàn)的是實際輸出與預測輸出的差距,交叉熵的值越小,預測輸出就越接近實際輸出。
2)按極小誤差的方法調(diào)整權(quán)值矩陣[W]以及偏置值[b]。更新過程中運用梯度下降法中的小批量梯度下降法:
[W2=W1-?E?W1] ? ? ? ? ? ? ? ? ? ?(5)
[b2=b1-?E?b1] ? ? ? ? ? ? ? ? ? ? ? (6)
其中,[η]為梯度下降的學習率,[W2]和[b2]為更新后的值。誤差反向傳播訓練就是為了更新網(wǎng)絡(luò)的權(quán)值,使得(4)中的交叉熵最小,即實際輸出與期望輸出最接近。
3.2.3 訓練結(jié)果及分析
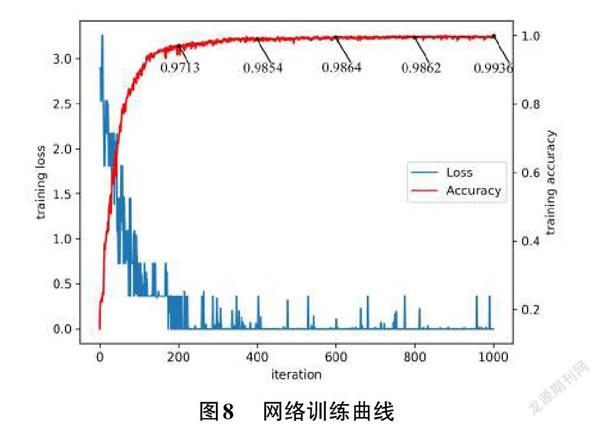
本文實驗使用AlexNet模型進行1000次迭代訓練。在訓練數(shù)據(jù)集進行訓練的過程中,使用測試數(shù)據(jù)集對神經(jīng)網(wǎng)絡(luò)模型進行同步測試,計算得出隨著訓練數(shù)據(jù)迭代次數(shù)的增加,其網(wǎng)絡(luò)準確率以及損失函數(shù)曲線如圖8所示。
由圖8可知,訓練過程中訓練數(shù)據(jù)迭代次數(shù)增加的同時,網(wǎng)絡(luò)模型的損失曲線呈不斷下降趨勢,這個現(xiàn)象證明了AlexNet模型的訓練過程是一個不斷收斂的過程。由公式(4)可知,隨著損失曲線的不斷下降,實際輸出與期望輸出之間的差距越來越小。同時,該模型在測試數(shù)據(jù)集上的準確率也在不斷提升,并且在數(shù)據(jù)迭代超過400次之后,準確率曲線與損失函數(shù)曲線逐漸趨于平穩(wěn),測試準確率停留在98%與99%之間,最終識別模型選用迭代次數(shù)為704次的迭代模型,704模型的準確率為99.53%。圖9為手語識別演示圖。
4 結(jié)論
本文設(shè)計了一個基于YCrCb空間和卷積神經(jīng)網(wǎng)絡(luò)的手語識別系統(tǒng)。首先,對靜態(tài)手語圖像進行預處理,分割手部圖像。同時該算法對復雜環(huán)境下的手語圖像進行分割,手部圖像提取的效果也比較好。接著利用卷積神經(jīng)網(wǎng)絡(luò)提取手部圖像特征,對圖像特征進行識別與分類。最后,將最優(yōu)模型導入樹莓派,并利用訊飛語音包把識別結(jié)果轉(zhuǎn)化為語音進行播報,實現(xiàn)手語的實時識別和語音播報。下一步將考慮如何優(yōu)化AlexNet模型的各項參數(shù),使提高模型識別的準確率,并使得網(wǎng)絡(luò)模型能夠快速地收斂。卷積神經(jīng)網(wǎng)絡(luò)被廣泛應用于自然語言處理、機器視覺等許多領(lǐng)域,仍然需要進行大力的研究。
參考文獻:
[1] Tubaiz N,Shanableh T,Assaleh K.Glove-based continuous Arabic sign language recognition in user-dependent mode[J].IEEE Transactions on Human-Machine Systems,2015,45(4):526-533.
[2] 李云,陳香,張旭,等.基于表面肌電信號對中國手語識別的探索與動作規(guī)范[J].航天醫(yī)學與醫(yī)學工程,2010,23(3):196-202.
[3] Fang B Y,Co J,Zhang M.DeepASL:enabling ubiquitous and non-intrusive word and sentence-level sign language translation[C]//Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems.Delft Netherlands.New York,NY,USA:ACM,2017.
[4] 吳要領(lǐng).基于YCrCb色彩空間的人臉檢測算法的設(shè)計與實現(xiàn)[D].成都:電子科技大學,2013.
[5] 陶堅堅.基于膚色分割和未確知聚類的彩色人臉檢測算法研究[D].邯鄲:河北工程大學,2012.
[6] 張書真.彩色圖像中復雜背景下的人臉檢測[D].長沙:國防科學技術(shù)大學,2006.
[7] Yann L,Yoshua B.Convolutional networks for images,speech,and time-series[J].The Handbook of Brain Theory and Neural Networks,1995:255-258.
[8] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017,60(6):84-90.
[9] 李強.基于卷積神經(jīng)網(wǎng)絡(luò)的靜態(tài)手語識別系統(tǒng)[D].長春:吉林大學,2020.
【通聯(lián)編輯:唐一東】
