基于寬度學(xué)習(xí)系統(tǒng)的電動汽車用戶臺區(qū)相屬辨識
2021-02-28 09:41:00李紅玲吳杰康蔡志宏王瑞東
黑龍江電力 2021年6期
李紅玲,吳杰康,蔡志宏,王瑞東
(廣東工業(yè)大學(xué) 自動化學(xué)院,廣州 510006)
0 引 言
隨著全球能源互聯(lián)網(wǎng)的不斷推進和“碳中和”倡議的持續(xù)發(fā)酵,電力行業(yè)面臨著新的機遇和挑戰(zhàn)。新的發(fā)展、新的訴求對電力營銷、調(diào)度、配網(wǎng)等環(huán)節(jié)的發(fā)展也提出了更高的要求。智能電網(wǎng)是近些年來電力工業(yè)最重大的變革與創(chuàng)新,也是智慧城市建設(shè)的重要組成部分之一[1]。同時,智能電網(wǎng)的快速發(fā)展也對配電側(cè)的精細化管理提出了更高的要求[2]。然而配電臺區(qū)普遍存在線損計算異常等問題,導(dǎo)致臺區(qū)運行、規(guī)劃等多個高級應(yīng)用難以推進,難以對整個臺區(qū)實現(xiàn)智能化管控,會對用戶的安全用電造成直接的影響[3]。終端用戶難以和臺區(qū)管控的配電變壓器準確配對是該問題的主要成因。因此,提出精準且高效的臺戶關(guān)系辨識方法,對實現(xiàn)智能配電網(wǎng)臺區(qū)管理運行的“信息化、自動化、精準化”具有重要意義,且臺區(qū)的運行和優(yōu)化管理,對供電企業(yè)的發(fā)展與管理起著重要的作用。
根據(jù)配網(wǎng)臺區(qū)發(fā)展進程,臺區(qū)用戶的相別辨識方法可以分為傳統(tǒng)方法、通信信息方法和大數(shù)據(jù)分析方法。傳統(tǒng)方法主要依靠人工記錄、整理,據(jù)火線走向進行相別辨識,部分區(qū)域配網(wǎng)線路錯綜復(fù)雜導(dǎo)致辨識過程費時費力且辨識結(jié)果準確率不高。通信信息方法通過在臺區(qū)用戶部署相應(yīng)電子儀器,對儀器中電力載波信號或脈沖電流信號進行分析比對,從而實現(xiàn)臺區(qū)用戶的相別辨識,具有較高的準確率。但儀器本身的運營維護費用較高,在一定程度上增加了電網(wǎng)運營成本。且鄰近臺區(qū)或者周邊環(huán)境對電信號的干擾,使臺區(qū)間信息易出現(xiàn)混疊、交叉等問題,導(dǎo)致臺區(qū)用戶相屬辨識的準確率有所下降。
大數(shù)據(jù)分析方法得益于智能裝置及大數(shù)據(jù)技術(shù)的發(fā)展,通過大數(shù)據(jù)技術(shù)分析數(shù)據(jù)的變化趨勢,配網(wǎng)的拓撲結(jié)構(gòu)與數(shù)據(jù)的變化趨勢息息相關(guān)。成本低廉的海量數(shù)據(jù)可為電力公司提供眾多核心信息用以分析資產(chǎn)管理優(yōu)化、分臺區(qū)管理和臺區(qū)用戶相別辨識等問題。利用大數(shù)據(jù)分析方法對配網(wǎng)實際場景的線變關(guān)系進行了分析、校驗。依據(jù)量測裝置所采集的電壓數(shù)據(jù),一方面通過對臺區(qū)用戶智能電表中電壓數(shù)據(jù)波動趨勢的相似性分析,利用灰色關(guān)聯(lián)分析來實現(xiàn)用戶歸屬臺區(qū)及相別的辨識[4],某些情況波動趨勢相似性存在重疊,難以辨別所屬相別;另一方面采用FastICA技術(shù)對電壓時序數(shù)據(jù)進行獨立成分分析(independent component analysis,ICA)及特征提取,對特征數(shù)據(jù)進行K-means聚類分析,從而實現(xiàn)臺戶辨識[5],但所需數(shù)據(jù)量過于龐大,辨識耗時較長。針對臺區(qū)線變不匹配問題,文獻[6]提出了一種考慮異常點的臺區(qū)用戶相別辨識方法,通過局部異常因子算法剔除非分析臺區(qū)的用戶數(shù)據(jù),并采用改進K-means算法對屬于分析臺區(qū)的用戶進行相別辨識,取得了不錯的效果。就鄰近臺區(qū)數(shù)據(jù)信號互相干擾的問題,文獻[7]提出了一種基于大數(shù)據(jù)的改進灰色關(guān)聯(lián)分析的智能臺區(qū)識別方法,通過關(guān)聯(lián)度來判斷電能表的臺屬性,排除鄰近臺區(qū)數(shù)據(jù)干擾,實測證明該方法能有效提高臺區(qū)識別的精準度,但是復(fù)雜情況下精準度有待提高。
目前臺區(qū)用戶相屬辨識大部分針對普通用戶,忽略了電動汽車的不斷融入對用戶相屬辨識的影響。針對上述問題及現(xiàn)有辨識方法所存在的缺陷,該文提出了一種基于寬度學(xué)習(xí)系統(tǒng)(broad learning system,BLS)的電動汽車用戶臺區(qū)相屬辨識方法。首先,建立電動汽車隨機參數(shù)的概率密度函數(shù),利用拉丁超立方抽樣技術(shù)(latin hypercube sampling,LHS)對電動汽車概率密度函數(shù)進行抽樣,形成考慮電動汽車充電的用戶電壓模型;接下來,搭建臺區(qū)相戶拓撲結(jié)構(gòu),利用皮爾遜相關(guān)系數(shù)來準確區(qū)分研究臺區(qū)用戶和非研究臺區(qū)用戶;最后,基于某研究臺區(qū)純電動汽車用戶數(shù)據(jù)和混合用戶數(shù)據(jù),通過寬度學(xué)習(xí)系統(tǒng)辨識研究臺區(qū)用戶的相屬,對比支持向量機(support vector machine,SVM)、線性判別(linear discriminant, LD)以及最鄰近分類(K-Nearest neighbor,KNN)算法等傳統(tǒng)辨識方法,證實了該文方法在臺區(qū)相戶識別方面具有更高的實用價值和準確性。
1 計及電動汽車充電的臺區(qū)相戶拓撲結(jié)構(gòu)
隨著物聯(lián)網(wǎng)產(chǎn)業(yè)的發(fā)展[8]和低碳環(huán)保理念的倡導(dǎo),電動汽車行業(yè)開拓了廣闊的市場,越來越多的家庭開始響應(yīng)政府號召,選擇用電動汽車作為代步工具。然而,電動汽車的充電行為會影響用戶電壓特征,進而影響臺區(qū)相戶辨識的準確性。考慮上述因素,根據(jù)建立的電動汽車負荷模型,更新用戶電壓,重建臺區(qū)相戶拓撲結(jié)構(gòu)。
1.1 電動汽車負荷模型
電動汽車負荷模型建模方法主要包括單一建模、物理學(xué)建模、統(tǒng)計學(xué)建模。融合多臺電動汽車的差異,考慮起始充電時間、日行程量等常規(guī)因素,采用統(tǒng)計學(xué)建模方法[9]對電動汽車負荷進行建模,進而更新用戶電壓數(shù)學(xué)模型。假定1天中電動汽車并/離網(wǎng)時刻、充電功率是相戶獨立的隨機變量,模型建立包括以下兩步:
1.1.1 建立離/并網(wǎng)時刻、日行程量的概率密度函數(shù)
并/離網(wǎng)時刻是指電動汽車在1天中起始接入/脫離電網(wǎng)的時刻。基于美國聯(lián)邦公路局的美國家用車輛調(diào)查結(jié)果(national household travel survey,NHTS)[10],近似認為離/并網(wǎng)時刻服從正態(tài)分布,日行程量服從對數(shù)正態(tài)分布[11],進行擬合處理后,分別得到如下的離/并網(wǎng)時刻、日行程量的概率密度函數(shù):
(1)
(2)
(3)
式中:f0、fi、fk分別是離網(wǎng)時刻、并網(wǎng)時刻、日行程量的概率分布函數(shù);μ0、μi、μk分別是離網(wǎng)時刻、并網(wǎng)時刻、日行程量的期望;δ0、δi、δk分別是離網(wǎng)時刻、并網(wǎng)時刻、日行程量的標準差。
1.1.2 拉丁超立方抽樣
LHS的主要原理[12]就是將取值范圍為[0,1]的概率密度函數(shù)進行分區(qū)段打亂抽樣,得到樣本數(shù)據(jù),分為以下兩步:
1)樣本抽取。定義Yk為任意第k個隨機變量,將Xk的累積概率分布函數(shù)定義為
Yk=ζk(Xk)
(4)
設(shè)樣本總數(shù)為n,以概率密度函數(shù)的取值范圍為[0,1]的縱軸為基準,進行N等份分區(qū)處理,第m個分區(qū)所對應(yīng)的Yk的樣本值定義為
(5)
結(jié)合式(4)和式(5),經(jīng)過反函數(shù)計算,得出任意一個隨機變量的第m個區(qū)段樣本值,表達式如下:
(6)
將k個隨機變量的N個樣本值xk,m組合成樣本矩陣Xk×N。
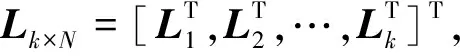
(7)
式中:pk,j表示相關(guān)性矩陣中第k行第j列的元素(k≠j)。
根據(jù)式(6)和原次序矩陣L,更新第m個區(qū)段抽樣樣本的對應(yīng)樣本值x′:
(8)
式中:lk,m為次序矩陣第k行第m列的元(k≠m)。
1.2 用戶電壓模型更新
用戶通常的用電對象是指家用電器、照明裝置等,由于小區(qū)的智能化、環(huán)保化發(fā)展,電動汽車成為每家用戶不可或缺的交通工具。考慮到電動汽車放電的復(fù)雜性和不確定性,僅考慮電動汽車的充電行為。用戶的原始電壓必然會受到電動汽車充電行為的影響。
根據(jù)上節(jié)的理論介紹,假定有680輛電動汽車,設(shè)定μ0=8.91,δ0=3.23,μi=17.46,δi=3.42,μk=2.97,δk=1.15。擬合得到電動汽車各隨機參數(shù)(離/并網(wǎng)時刻、日行程數(shù))的概率密度函數(shù),結(jié)果如圖1所示。根據(jù)拉丁超立方抽樣,抽取特定樣本數(shù)量的離/并網(wǎng)時刻,根據(jù)離/并網(wǎng)時刻從而知道電動汽車充電時間、充電功率存在時間段,即電動汽車有效充電時段會影響用戶的電壓,對臺區(qū)相戶辨識起到一定的影響作用。電動汽車產(chǎn)生的電壓差定義為
(9)
式中:P表示電動汽車的充電功率;R+jX表示線路阻抗。
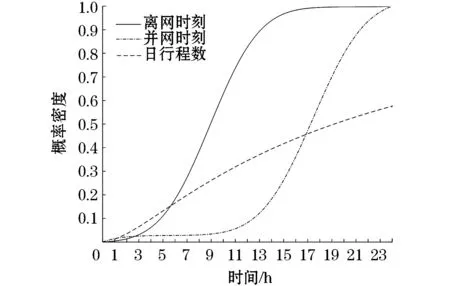
圖1 電動汽車各隨機參數(shù)的概率密度函數(shù)Fig.1 Probability density function of each random parameter of electric vehicle
將電壓差映射到用戶電壓上,表達式如下:
U′=U-ΔU
(10)
式中:U是初始不受電動汽車影響的用戶電壓。
1.3 臺區(qū)相戶拓撲結(jié)構(gòu)
低壓配電網(wǎng)終端由變壓器、配電箱和配有智能電表的用戶端組成。一般每一個表箱都由三相進線,由表箱分出A、B、C三相連接各個電動汽車用戶,一個表箱下可能存在單相用戶,也有三相用戶,該文臺區(qū)相戶關(guān)系辨識只涉及單相用戶。相與相之間電壓互不影響,每一相只受該相下所接用戶的用電情況影響,具體的臺區(qū)相戶拓撲結(jié)構(gòu)如圖2所示。

圖2 臺區(qū)相戶拓撲結(jié)構(gòu)Fig.2 The topological structure of the station area
臺區(qū)相戶等值電路如圖3所示,M3點為變壓器某相低壓側(cè)。通常低壓側(cè)的電壓與用戶用電功率、高壓側(cè)檔位和負荷功率有關(guān)。高壓側(cè)的檔位分別為±5%和0。由潮流計算可得M3點的電壓為
(11)
VM3=VM1-ΔV
(12)


圖3 臺區(qū)相戶等值電路圖Fig.3 Equivalent circuit diagram of station area
電力系統(tǒng)中的臺區(qū)是指一臺配電變壓器的供電范圍,具體包括臺區(qū)變壓器及其下所屬的所有用戶。其中,低壓臺區(qū)屬于用戶供電的最終環(huán)節(jié),電動汽車的充電行為會直接導(dǎo)致用戶電壓發(fā)生波動,從而會對臺區(qū)相戶辨識造成一定的干擾,易導(dǎo)致相戶辨識發(fā)生偏差現(xiàn)象。
2 基于寬度學(xué)習(xí)的電動汽車用戶臺戶辨識
2.1 用戶臺區(qū)相關(guān)性分析
由于某一臺區(qū)下的不同相的用戶群之間存在電壓特征區(qū)分程度不明顯的問題,并且傳統(tǒng)的人工收集數(shù)據(jù)方法容易混淆相屬用戶電壓,導(dǎo)致不屬于本相的用戶也被歸類為該相。引入皮爾遜相關(guān)系數(shù)[13],用來衡量用戶電壓與臺區(qū)相屬電壓的相似度。利用已獲得的電壓數(shù)據(jù),可以先應(yīng)用皮爾遜相關(guān)系數(shù)范圍判斷該用戶是否屬于該臺區(qū)下的用戶,否則標記為異常用戶。用戶臺區(qū)相關(guān)性分析能夠提高臺區(qū)相戶辨識的辨識度。
用皮爾遜相關(guān)系數(shù)的關(guān)聯(lián)強度來表示兩者之間的關(guān)聯(lián)程度,關(guān)聯(lián)系數(shù)的范圍大小分別表示用戶與臺區(qū)三相之間的關(guān)聯(lián)度。皮爾遜相關(guān)系數(shù)計算方式如下:
(13)
式中:E(·)表示求該向量的期望值;cov表示求兩個向量的協(xié)方差;ρ(V,Xi)取值范圍[-1,1],小于0時為負相關(guān),大于0時為正相關(guān),當且僅當V與Xi有嚴格線性關(guān)系時取±1。通過表1相關(guān)系數(shù)范圍判斷變量之間的相關(guān)強度。
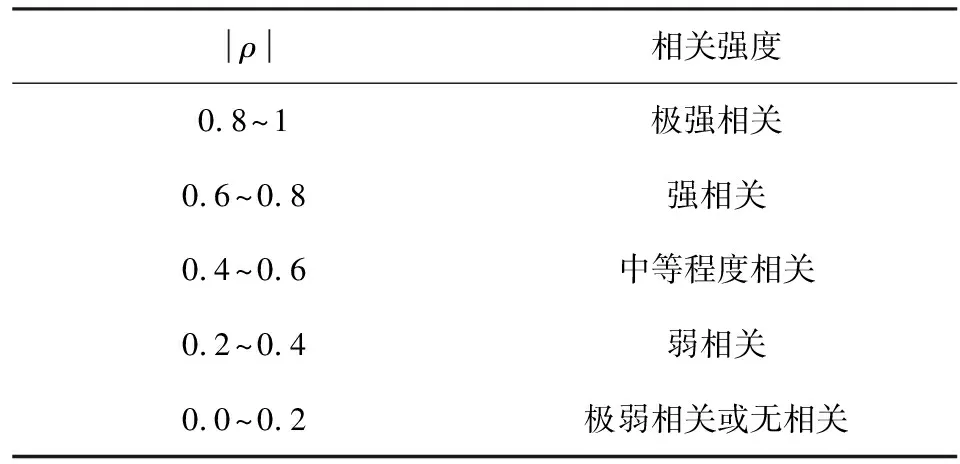
表1 Pearson相關(guān)系數(shù)相關(guān)強度Table 1 Pearson correlation coefficient correlation intensity
經(jīng)上述皮爾遜相關(guān)系數(shù)計算,得到A、B、C三相相關(guān)系數(shù)范圍分別為0.31~0.98、0.51~0.98、0.44~0.94。
2.2 寬度學(xué)習(xí)系統(tǒng)
寬度學(xué)習(xí)系統(tǒng)是近幾年陳俊龍教授及其學(xué)生提出的淺層增量式神經(jīng)網(wǎng)絡(luò)。BLS是基于Yoh-Han Pao教授提出的隨機向量函數(shù)鏈接神經(jīng)網(wǎng)絡(luò)(random vector functional link neural network,RVFLNN)基礎(chǔ)上提出的,融合了動態(tài)逐步更新算法(增量學(xué)習(xí))[14-15]。與傳統(tǒng)深度網(wǎng)絡(luò)不同之處在于提高精度的方式是增加網(wǎng)絡(luò)的“寬度”而不是增加網(wǎng)絡(luò)的“深度”。該文所采用的網(wǎng)絡(luò)結(jié)構(gòu)(如圖4所示)不含增量學(xué)習(xí)部分。
BLS的建模思路為:首先,輸入數(shù)據(jù)的映射特征作為網(wǎng)絡(luò)的特征節(jié)點;其次,特征節(jié)點經(jīng)過隨機權(quán)值和偏置增強為增強節(jié)點;最后,特征節(jié)點與增強節(jié)點作為最終輸入,輸入與輸出之間的權(quán)重通過嶺回歸的偽逆算法求解得出。

圖4 BLS的網(wǎng)絡(luò)結(jié)構(gòu)Fig.4 Network structure of BLS
如圖4所示,輸入層包括兩部分:特征節(jié)點和增強節(jié)點。假設(shè)有N個樣本,每個樣本維數(shù)為M,構(gòu)成輸入數(shù)據(jù)集XN×M=[X1,X2,…,XN]T,輸出矩陣Y∈RN×C。將含有k個神經(jīng)元的第i組特征節(jié)點定義為
Zi=ζ(Xεei+βei)i=1,2,…,n
(14)
式中:ζ(·)是激活函數(shù);ωei和βei分別表示隨機產(chǎn)生的權(quán)值和偏置。
為減少特征節(jié)點相互之間的可線性表示性,利用稀疏自編碼器進行稀疏表示和微調(diào)處理。n組特征節(jié)點組合表示為
Zn=[Z1,Z2,…,Zn]
(15)
將含有r個神經(jīng)元的第j組增強節(jié)點定義為
Hj=ξ(Xωhj+βhj)j=1,2,…,m
(16)
式中:ξ(·)是非線性激活函數(shù);ωhj和βhj分別表示隨機產(chǎn)生的權(quán)值和偏置。m組增強節(jié)點組合表示為
Hm=[H1,H2,…,Hm]
(17)
將特征節(jié)點Zn與增強節(jié)點Hm組合成最終輸入數(shù)據(jù),記為A=[Zn|Hm]。利用嶺回歸求解出輸入層與輸出層之間的權(quán)值ω,求解表達式如下:
ω=(ATA+λE)-1ATY
(18)
式中:λ是正則化系數(shù);E是單位陣;T表示轉(zhuǎn)置,記A的偽逆為A-1=(ATA+λE)-1AT。
2.3 基于BLS的電動汽車用戶臺戶關(guān)系辨識建模
該文利用Pearson相關(guān)系數(shù)剔除非研究臺區(qū)的用戶數(shù)據(jù),確保臺區(qū)之間數(shù)據(jù)不存在混淆的情況,對辨識不產(chǎn)生干擾。考慮電動汽車對用戶電壓的影響,更新用戶電壓,引入寬度學(xué)習(xí)系統(tǒng),新用戶電壓作為網(wǎng)絡(luò)的初始輸入,利用隨機權(quán)值和偏置進行特征提取,生成特征節(jié)點和增強節(jié)點,通過嶺回歸的偽逆求解出輸入-輸出的權(quán)重,在權(quán)重的作用下得到辨識結(jié)果輸出。該文所述辨識方法的流程圖如圖5所示,具體步驟如下:

圖5 辨識方法的流程圖Fig.5 Flow chart of the identification method described
1) 根據(jù)研究臺區(qū)已有的用戶數(shù)據(jù),首先,利用式(13)進行Pearson相關(guān)系數(shù)計算,剔除非研究臺區(qū)的用戶數(shù)據(jù);再進行歸一化處理,歸一化式如下:
(19)
2) BLS網(wǎng)絡(luò)訓(xùn)練。
①初始化單位窗口特征節(jié)點數(shù)N1、單位特征節(jié)點窗口數(shù)N2、增強節(jié)點數(shù)N3、迭代次數(shù)n以及增強節(jié)點的正則化參數(shù)s和縮放尺度c;
②劃分訓(xùn)練集X′a×b及對應(yīng)標簽Y′和測試集Xc×d及對應(yīng)標簽Y;

④隨機產(chǎn)生權(quán)值和偏置ωei、βei、ωhj、βhj;
⑤特征提取,根據(jù)式(14),得到特征節(jié)點Qn;
⑥對特征節(jié)點進行增廣和歸一化處理,引入非線性激活函數(shù)ξ,結(jié)合式(16)得到增強節(jié)點Pm;
⑦特征節(jié)點與增強節(jié)點的組合形成最終輸入數(shù)據(jù)A′=[Qn|Pm];
⑧達到迭代次數(shù),根據(jù)式(18),結(jié)合嶺回歸算法理論計算出輸入-輸出權(quán)重ω。
3) 輸入測試集數(shù)據(jù),數(shù)據(jù)進行增廣處理。
4) 特征提取,根據(jù)式(14)和式(16),形成特征節(jié)點Zn和增強節(jié)點Hm,整合成最終輸入數(shù)據(jù)A=[Zn|Hm]。
5) 利用網(wǎng)絡(luò)訓(xùn)練中的輸入-輸出權(quán)值,輸出辨識相屬Y=Aω。
3 實例仿真分析
該文研究的對象是某新興小區(qū)的某臺區(qū)下某臺配變A、B、C三相的相戶關(guān)系辨識。該配變下有A相用戶29戶,B相用戶25戶,C相用戶30戶,總共有84戶用戶,每家用戶都配有一輛電動汽車。
3.1 電動汽車對用戶電壓的影響
根據(jù)1.1節(jié)所述的電動汽車負荷模型,利用離并網(wǎng)時刻得到充電時間,假定電動汽車充電功率P=30 kW,輸電線路阻抗為0.36+0.18j Ω,結(jié)合式(9),同時考慮A、B、C三相電動汽車的充電行為的隨機性和延時性,得到由電動汽車產(chǎn)生的電壓差如圖6(a)所示,原始用戶電壓(無電動汽車)與電動汽車用戶電壓對比圖如圖6(b)所示。

圖6 用戶電壓受電動汽車的影響分析圖Fig.6 Analysis diagram of user voltage influenced by electric vehicles
由圖6(a)可知,由電動汽車產(chǎn)生的電壓差在0.1~3.5 V之間,A、B、C三相的電壓差的高峰值具有延時性,A相的高峰期大概在1天中的14點,B相延遲到21點左右,C相的高峰時刻大概在5點左右。從圖6(b)可以看出,不論是A、B、C三相的哪一相普通用戶,與電動汽車用戶之間的電壓差在4 V以內(nèi),對用戶電壓起到一個降低的作用,一定程度上削減了用戶電壓與配變電壓的關(guān)聯(lián)程度。
3.2 基于BLS的電動汽車用戶臺戶關(guān)系辨識
利用Pearson相關(guān)系數(shù)即式(13),對初始用戶數(shù)據(jù)進行篩選。再根據(jù)2.3節(jié)所述的基于BLS的電動汽車用戶臺戶關(guān)系辨識模型建立步驟,利用MATLAB編寫模型程序,設(shè)定增強節(jié)點的正則化參數(shù)c=2-30、增強節(jié)點的縮放尺度s=0.8、單位窗口特征節(jié)點數(shù)N1=41、單位特征節(jié)點的窗口數(shù)N2=35、增強節(jié)點數(shù)N3=1 100和迭代次數(shù)n=10。訓(xùn)練集采用60組電動汽車用戶,每相各20組,對應(yīng)的標簽為配變各相的電壓及相屬標號。剩下的用戶電壓作為測試集。
定義混合用戶包括有電動汽車用戶和無電動汽車用戶。為保證測試集數(shù)據(jù)的統(tǒng)一性,將測試集中無電動汽車用戶隨意替代每相中某些電動汽車用戶,從而構(gòu)成混合用戶。為突出所述辨識方法的準確性和優(yōu)越性,利用SVM、LD以及KNN 3種傳統(tǒng)分類方法[16-18],基于相同的訓(xùn)練集和測試集進行辨識,訓(xùn)練集的準確率均為100%,訓(xùn)練結(jié)果如圖7所示。

圖7 SVM/KNN/LD訓(xùn)練集的訓(xùn)練精度Fig.7 Training accuracy of SVM/KNN/LD training set
測試集數(shù)據(jù)包括純電動汽車用戶和混合用戶,為了使配變?nèi)嗟谋孀R對象一致,混合用戶中的非電動汽車用戶A、B、C三相等分。該文所述辨識方法和3種分類方式的辨識結(jié)果如表2所示。

表2 辨識準確率Table 2 Analysis of identification results 單位:%
由表2結(jié)果可知,純電動汽車用戶的辨識準確率均為100%,對于混合用戶的辨識準確率除了該文所述的BLS辨識方法均有所下降。雖然SVM和KNN針對混合用戶的辨識準確率均為91.7%,但是根據(jù)測試集辨識結(jié)果(表3):SVM和KNN均無法辨識A、B相的非電動汽車用戶,僅能準確辨識C相的非電動汽車用戶,并且誤判結(jié)果一致。兩者的訓(xùn)練時間相差不是很明顯。準確率為95.8%的LD只
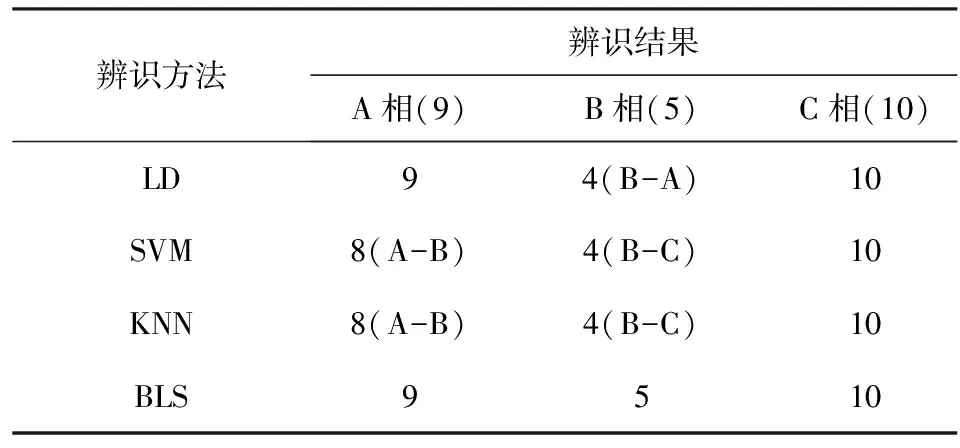
表3 測試集辨識結(jié)果Table 3 Test set identification results
是無法辨識B相的非電動汽車用戶。而對于BLS的辨別方法,無論是純電動汽車用戶還是混合用戶,其準確率都是100%,能夠有效、準確地辨識用戶相屬。
4 結(jié) 語
1) 該文所用的用戶數(shù)據(jù)來源于實際小區(qū)的用戶數(shù)據(jù),電動汽車電壓根據(jù)負荷模型進行仿真得來,具有一定的可靠性。
2) 隨著環(huán)保理念的不斷深入,家庭用戶用電動汽車替代傳統(tǒng)燃油汽車成為必然趨勢,該文研究對象選擇電動汽車用戶,符合未來配電網(wǎng)臺戶關(guān)系發(fā)展的趨勢。
3) 所提出的基于BLS的臺區(qū)相屬辨識方法不僅可以用于“相屬-電動汽車用戶”之間的辨識,還能用于“相屬-用戶”之間的辨識,普及性很高。
4) 所述辨識方法與SVM、KNN、LD這3種傳統(tǒng)的分類方法進行對比,該文所述方法在2種情況下均能有效、準確地辨識。
5) 該文僅考慮電動汽車接網(wǎng)充電情況,沒有考慮到電動汽車充電行為受電價影響,忽略了充電過程存在的放電行為。該模型的泛化能力有待進一步提高。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
