基于表情識別的情感計算系統
2021-03-01 12:52:28李志超
科學與財富 2021年27期
關鍵詞:深度學習

摘 要:從工程效果的角度上看,人臉識別技術已經發展成十分成熟的技術。但是,現實任務對于人臉識別的要求不僅僅止步于從機器視覺的角度上了解人臉的表層信息,對于。以人臉識別技術為基礎對研究客體進行情感計算是一種透過人臉表面挖掘客體情感的重要技術。本文致力于解決現代表情識別技術存在的由于數據源不適配導致的識別效果差等問題,并設計了基于深度學習的表情識別情感計算系統。
關鍵詞:表情識別;情感計算;深度學習
1 引言
大量的心理學與生理學理論認為,人體擁有豐富的表情是生物進化的結果。哺乳動物和人都有表情,它是生存的需要,是自然選擇的結果,是先天就存在的。在達爾文的進化論中曾有過記載,例如:一些恐懼的表情會讓我們的瞳孔放大,在野外生存時這種瞳孔放大可以讓人了解到更多的信息,從而做出使生存幾率變大的行為。但是,這也是一種比較寬泛的說法,真正將表情識別和情感分析聯系在一起的是著名的心理學家Ekman[1]。他提出,重要面部單元系統編碼是客觀的,也就是說人臉的各個肌肉單元不會完全地被主觀意識所控制,而是被情感客觀控制的。另外,他提出了基本表情模型,將表情模型分為六大模塊(生氣、傷心、開心、懷疑、害怕、驚喜)。本研究討論的表情識別主要是面向以上六種感情。
上個世紀60年代開始,表情識別的概念已經存在。到了現代,大量的人臉表情數據庫也為相關的研究而開源,但是與此同時,這些數據庫都存在著一定的問題。典型的問題是,客體所表現的表情會隨著其文化背景不同而造成差異,最終導致不同文化背景的客體與客體之間雖然擁有相似的表情,但其內心的心理活動狀態卻不盡相同,從而導致表情識別的準確率大打折扣。
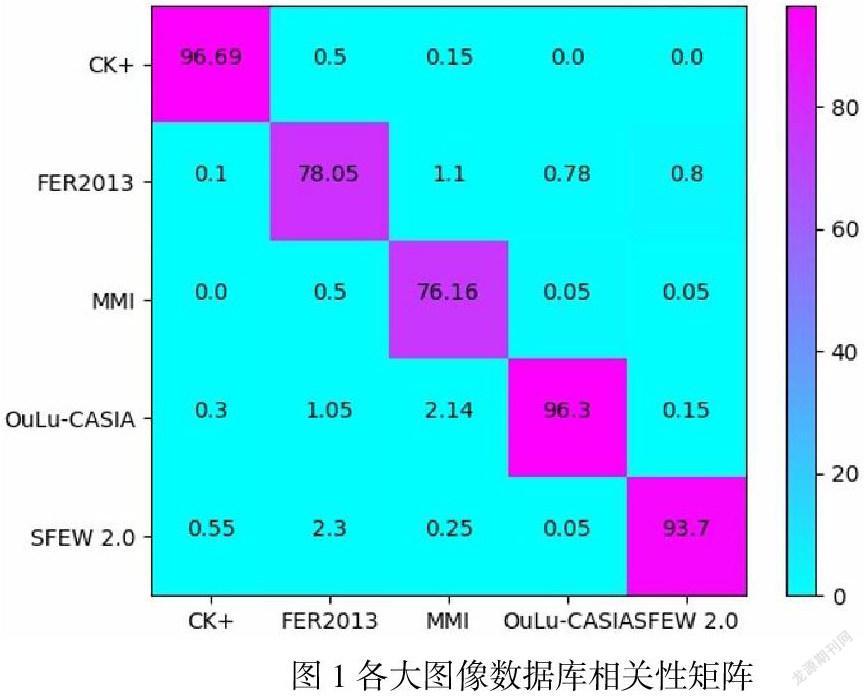
另外,現存的大量數據庫的數據源為實驗室數據源,即在實驗室環境下讓客體主觀表現出符合標簽的表情。這種實驗室數據與現實中人類心理活動導致的表情上的行為學特征數據有著極大的差異。在研究開始階段,本文使用hog算法將幾個主流的數據庫(CK+,FER2013,MMI,OuLu-CASIA,SFEW 2.0)的圖片進行特征提取,然后分析出他們的相關系數矩陣如圖1所示,可以明顯地發現,這些主流的數據庫的相互適應能力極差。
2 相關工作
在人工智能各項技術高度發展的今天,國內外已經有許多關于情感分析的研究。可以說,在人工智能的領域各個中,情感分析都占據著較大的比重。
在國內,華東理工大學信息科學與工程系的學者李冬冬使用雙相長短時記憶神經網絡(BLSTM)對客體的語音序列進行情感分析。[2]這種情感分析依賴語音識別,對語音識別的精度要求較高。在公眾場合下,由于聲音過于嘈雜導致的語音識別能力低下,從而使得這種方法不能被很好地用于實際場景中。華中科技大學的學者權學良利用腦電波等生理信號構建特征工程,并使用深度學習實現情感分析[3],但與上述所屬的問題相同,這種基于生理信號的情感算方法也不能很好的實現實時應用。江蘇科技大學分析機學院的學者張力為使用細粒度分層時空特性描述符對微表情進行了特征構建,并且使用了支持向量機(SVM)的分類方法實現微表情變化的捕獲[4],但是其值做到了表情是否發生變化的度量,并沒有實現對客體的情感分析。
在國外,同樣有大量的學者致力于情感分析。英國愛丁堡納皮爾大學的學者Amir Hussain使用信息融合的方法模仿人類處理和分析文本的方式,對文本實現了情感分析[5]。另外有學者Venkata Rami Reddy Chirra提出一種基于多塊神經網絡(DCNN)的表情識別,其模型具有相對較高的泛化能力[6]。
3 研究工作
本章主要在數據集構筑、深度學習模型訓練以及系統布置三個板塊介紹本研究的研究過程及結果,詳細過程如圖2所示:
3.1 構筑數據集
基于上述的幾個問題,本研究認為,建立一個國人專用的表情識別系統,就必須先要建立一個國人專用的表情識別數據集。
本團隊計劃在網絡中尋找部分較為經典的電視劇,并截取視頻中的角色面部表情,并將該角色對應的心理情感作為該圖片的標簽,數據量希望在8k到10k左右。其原因是經典的電視機有其劇情的輔助,是的本團隊更容易從人工角度識別角色的心理活動,此外,經典的電視劇演員表演功力足夠,在整個表演過程中其面部表情更接近于真實生活中的狀態。
為此,我們使用scrapy爬蟲框架在網絡上爬取了大量清晰的視頻,并使用openCV將視頻分割成幀,然后采用yolo v5模型自動提取其中的人臉。本次實驗共提取出16324張圖片。此后,我們邀請共80位在校大學生,通過支付酬勞的方式,將他們分為4組,每組完成對4081張圖片的表情標注。最后,本研究通過EM算法對他們的標注結果進行清洗,得到標簽正確的數據集。
至此,數據集構建完成。
3.2 深度學習模型訓練
卷積神經網絡(CNN)是一種深度人工神經網絡,與其他圖像分類算法相比,它可以用最少的預處理工作從輸入圖像中識別視覺模式。這意味著該網絡可以學習傳統算法中手工設計的過濾器[7]。CNN層內的重要單元是神經元。它們被連接在一起,以使一個層的神經元的輸出成為下一個層的神經元的輸入。為了計算成本函數的部分導數,采用了反向傳播算法。
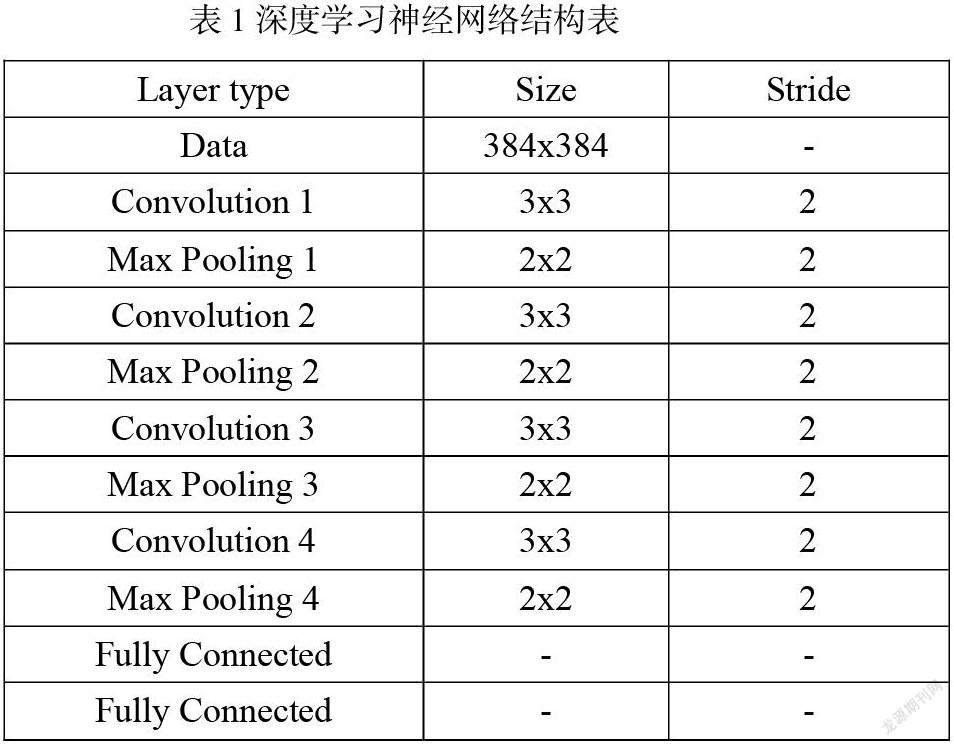
本研究使用卷積神經網路的網絡結構為:卷積層1、池化層1、卷積層2、池化層2、卷積層3、池化層3、全連接層1、全連接層2、輸出層,具體網絡結構如下表所示。
3.3 系統集成與布置
在完成3.2中所述的深度學習模型訓練后,本研究需要將完成訓練的模型嵌入系統中。從整體結構上看,首先是要在應用環境中獲取該環境下的攝像頭控制權,因此本研究采用openCV預留的接口完成對攝像頭控制權的獲取。此后,由攝像頭獲取到的視頻數據將會被傳送至后端服務器中,由后端服務器完成對視頻分割成幀的任務。獲取到被分割成幀的視頻圖片后,本項目再次采用yolo v5模型截取圖片中的人臉圖片,并將其尺寸修改為與深度學習神經網絡模型的輸入層相同的尺寸,最后將其喂入神經網絡模型,得到客體的表情識別標簽。
4 研究結論
從工程角度看,基于表情識別的情感計算系統能夠很好地解決在訓練過程中的樣本與現實應用樣本的不適配性問題。同時,由于其軟件結構簡單穩定,基于表情識別的情感計算系統能夠很好的運用在各個領域。例如,系統可以運用在教學過程中對學生心理狀態的監測,以達到教學過程中教師對學生心理狀況的把控。又例如,在審訊犯人的過程中,可以利用系統實時監測犯人的心理狀態,為警方偵破案情給予了極大的幫助。可以說,基于表情識別的情感計算系統是首款專門以非實驗室表情數據的表情識別系統,其識別準確度與利用實驗室數據的其他表情識別系統一定存在極大差異。
參考文獻:
[1]P. Ekman and W. V. Friesen, “Constants across cultures in the face and emotion,” Journal of Personality and Social Psychology, vol. 17, no 2, p. 124- 129, 1971.
[2]Li Dongdong,Liu Jinlin,Yang Zhuo,Sun Linyu,Wang Zhe. Speech emotion recognition using recurrent neural networks with directional self-attention[J]. Expert Systems With Applications,2021,173.
[3]權學良,曾志剛,蔣建華,張亞倩,呂寶糧,伍冬睿.基于生理信號的情感分析研究綜述[J/OL].自動化學報:1-17[2021-03-27].https://doi.org/10.16383/j.aas.c200783.
[4]張力為,王甦菁,段先華.細粒度分層時空特征描述符的微表情識別方法[J/OL].分析機工程與應用:1-9[2021-03-27].
[5]Hussain Amir,Cambria Erik,Poria Soujanya,Hawalah Ahmad,Herrera Francisco. Information fusion for affective computing and sentiment analysis[J]. Information Fusion, 2021, 71.
[6]Venkata Rami Reddy Chirra,Srinivasulu Reddy Uyyala,Venkata Krishna Kishore Kolli. Virtual facial expression recognition using deep CNN with ensemble learning[J]. Journal of Ambient Intelligence and Humanized Computing,2021.
[7]aionlinecourse.com/tutorial/machine-learning/convolution-neuralnetwork. Accessed 20 June 2019
本文得到上海立信會計金融學院大學生創新創業訓練計劃(202111047016)基金支持. 李志超(1999-),男,上海人,計算機科學與技術專業本科在讀。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
