基于SVM的網(wǎng)絡(luò)不良信息識(shí)別方法
2021-03-04 11:48:38陸向艷,陸生權(quán),劉峻
電腦知識(shí)與技術(shù) 2021年34期
陸向艷,陸生權(quán),劉峻
摘要:當(dāng)前用戶在互聯(lián)網(wǎng)中發(fā)布的一些文本信息中包含色情、暴力、政治敏感或惡意廣告等不良信息,對(duì)網(wǎng)絡(luò)生態(tài)環(huán)境造成破壞,特別對(duì)廣大青少年網(wǎng)民的健康成長(zhǎng)影響較大。本文提出一種基于SVM的不良信息識(shí)別方法,該方法包括文本標(biāo)記、文本分詞、Doc2Vec文本向量化、SVM不良信息分類器訓(xùn)練、SVM不良信息測(cè)試5個(gè)步驟。實(shí)驗(yàn)結(jié)果表明該方法能有效識(shí)別網(wǎng)絡(luò)不良信息,為網(wǎng)絡(luò)不良信息的甄別提供了一種方法參考。
關(guān)鍵詞:不良信息 ;SVM;識(shí)別;Doc2Vec;Jieba分詞
中圖分類號(hào):TP391? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2021)34-0097-02
1引言
當(dāng)前互聯(lián)網(wǎng)進(jìn)入了快速發(fā)展的階段,第44次《中國(guó)互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告》[1]顯示,截至2019年6月,我國(guó)網(wǎng)民數(shù)量達(dá)8.54億。互聯(lián)網(wǎng)信息發(fā)布呈指數(shù)級(jí)的快速增長(zhǎng),其中一些信息內(nèi)容涉及色情、暴力、政治敏感或?yàn)閻阂鈴V告,這些信息對(duì)網(wǎng)絡(luò)生態(tài)環(huán)境造成了不良影響,若不加甄別將對(duì)廣大青少年網(wǎng)民的健康成長(zhǎng)帶來(lái)不利影響。將網(wǎng)絡(luò)不良過(guò)濾后,再呈現(xiàn)給青少年具有重要意義。當(dāng)前互聯(lián)網(wǎng)不良信息識(shí)別主要有基于語(yǔ)義和基于機(jī)器學(xué)習(xí)兩種方法[2-5],基于后者本文提出一種基于SVM的不良信息識(shí)別方法,為不良信息識(shí)別,凈化網(wǎng)絡(luò)提供參考。
2? 基于SVM的網(wǎng)絡(luò)不良信息識(shí)別方法
2.1 識(shí)別模型
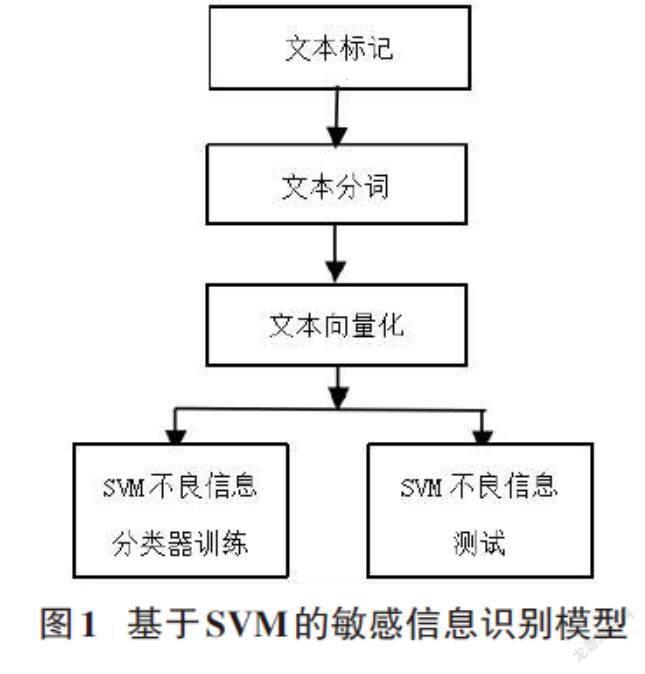
基于SVM的網(wǎng)絡(luò)不良信息識(shí)別方法包括文本標(biāo)記、文本分詞、Doc2Vec文本向量化、SVM不良信息分類器訓(xùn)練、SVM不良信息測(cè)試5個(gè)步驟,方法模型如圖1所示。
2.2文本標(biāo)記
用爬蟲收集網(wǎng)絡(luò)文本數(shù)據(jù)集,將數(shù)據(jù)集分成訓(xùn)練集和測(cè)試集兩部分,并進(jìn)行分類標(biāo)記,不包含色情、暴力、政治不良和廣告這四種敏感詞的文本數(shù)據(jù)集標(biāo)記為正面數(shù)據(jù),包含的則標(biāo)記為負(fù)面數(shù)據(jù),并按類別分開訓(xùn)練和測(cè)試。
2.3文本分詞
應(yīng)用Python中文分詞組件Jieba分詞的精確模式對(duì)所有文本數(shù)據(jù)集進(jìn)行分詞、去除停用詞處理。
2.4 Doc2Vec文本向量化
用Doc2Vec模型將文本分詞進(jìn)行向量化,設(shè)置詞向量長(zhǎng)度為200(對(duì)于SVM來(lái)說(shuō)就是有200個(gè)特征),形成文本數(shù)據(jù)的向量化表示,用于后續(xù)的SVM訓(xùn)練和測(cè)試。
2.5 SVM不良信息分類器訓(xùn)練
經(jīng)過(guò)Doc2Vec文本向量化后的訓(xùn)練數(shù)據(jù)集表示為{T1,T2,T3,T4}分別代表政治敏感、色情、廣告和暴力四個(gè)類別的數(shù)據(jù)集,第i個(gè)數(shù)據(jù)集:Ti={(ai1,bi1),(ai2,bi2),...,(aim,bim)},其中aij表示第i個(gè)數(shù)據(jù)集第j個(gè)文本的詞向量,bij表示第i個(gè)數(shù)據(jù)集第j個(gè)文本的是否為不良信息,是則取值為1,不是則取值為0。分別用SVM算法對(duì)數(shù)據(jù){T1,T2,T3,T4}進(jìn)行訓(xùn)練得到對(duì)應(yīng)的分類器。
2.6 SVM不良信息測(cè)試
SVM訓(xùn)練成功后.利用訓(xùn)練好的SVM分類器對(duì)向量化以后的測(cè)試數(shù)據(jù)集進(jìn)行不良信息分類測(cè)試,以確定測(cè)試文本是否為不良信息。
3 實(shí)驗(yàn)和結(jié)果分析
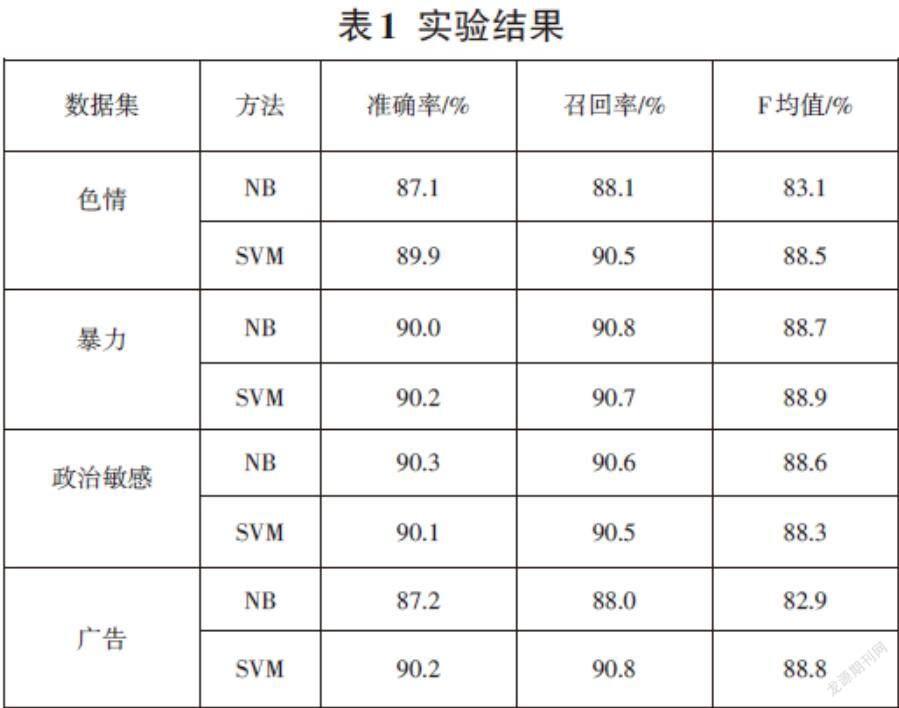
實(shí)驗(yàn)數(shù)據(jù)是用爬蟲進(jìn)行數(shù)據(jù)爬取,收集政治敏感、色情、廣告和暴力四個(gè)類別文本數(shù)據(jù)各800個(gè),600個(gè)文本用于訓(xùn)練,200個(gè)文本用于測(cè)試。將本文方法和基于樸素貝葉斯(NB)的不良信息識(shí)別方法進(jìn)行對(duì)比實(shí)驗(yàn),驗(yàn)證本文提出的基于SVM的網(wǎng)絡(luò)不良信息方法的有效性。采用正確率,召回率,F(xiàn)1值作為評(píng)價(jià)指標(biāo),計(jì)算公式為:
正確率=(TP+TN)/(P+N) ? ? (1)
召回率=TP/(TP+FN) ? ? (2)
F值=(TP+TN)/(P+N) ? ? (3)
其中,P為正面樣本數(shù),N為負(fù)面樣本數(shù),P+N為總樣本數(shù),TP為將正的預(yù)測(cè)為正的數(shù)目,TN表示將負(fù)的預(yù)測(cè)為負(fù)的數(shù)目,TP+FN為預(yù)測(cè)總信息數(shù)。實(shí)驗(yàn)結(jié)果如表1所示。
實(shí)驗(yàn)對(duì)于暴力和政治敏感數(shù)據(jù)集,SVM算法和樸素貝葉斯算法的準(zhǔn)確率和召回率基本相同,而對(duì)于色情和廣告數(shù)據(jù),SVM方法的準(zhǔn)確率和召回率都高于樸素貝葉斯方法,主要原因是樸素貝葉斯的屬性獨(dú)立性假設(shè)造成,因?yàn)樯楹蛷V告文本分詞比政治敏感及暴力文本具有更大的屬性相關(guān)性。
4 結(jié)論
網(wǎng)絡(luò)不良文本信息會(huì)對(duì)網(wǎng)絡(luò)生態(tài)環(huán)境造成破壞,尤其會(huì)對(duì)青少年兒童的健康成長(zhǎng)具有較大的影響。本文提出一種基于SVM的網(wǎng)絡(luò)不良信息識(shí)別方法。實(shí)驗(yàn)結(jié)果表明本文方法能有效識(shí)別不良文本信息。對(duì)凈化網(wǎng)絡(luò)環(huán)境,輔助青少年網(wǎng)民健康成長(zhǎng)具有重要意義。
參考文獻(xiàn):
[1] 于朝暉.CNNIC發(fā)布第44次《中國(guó)互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告》[J].網(wǎng)信軍民融合,2019(9):30-31.
[2] 湯烈,穆合義,候愛蓮,等.基于K最近鄰算法的網(wǎng)絡(luò)不良信息過(guò)濾系統(tǒng)研究[J].計(jì)算技術(shù)與自動(dòng)化,2019,38(4):172-175.
[3] 李兆翠,朱振方,李穎.基于改進(jìn)SVM的網(wǎng)頁(yè)過(guò)濾系統(tǒng)研究[J].軟件導(dǎo)刊,2016,15(2):159-161.
[4] 劉玉娥.基于數(shù)據(jù)挖掘技術(shù)的網(wǎng)絡(luò)信息過(guò)濾系統(tǒng)設(shè)計(jì)[J].現(xiàn)代電子技術(shù),2018,41(16):51-54.
[5] 劉凱.移動(dòng)網(wǎng)絡(luò)環(huán)境中不良信息智能過(guò)濾方法仿真[J].計(jì)算機(jī)仿真,2018,35(10):329-332.
[6] 王斌.基于樸素貝葉斯算法的垃圾郵件過(guò)濾系統(tǒng)的研究與實(shí)現(xiàn)[J].電子設(shè)計(jì)工程,2018,26(17):171-174.
[7] 孫玉杰.中文詞匯語(yǔ)義關(guān)系抽取及應(yīng)用研究[D].南京:南京師范大學(xué),2014.
[8] 聶證,曹燕.大數(shù)據(jù)時(shí)代面臨的信息安全機(jī)遇和挑戰(zhàn)[J].信息記錄材料,2018,19(2):47-48.
【通聯(lián)編輯:唐一東】
