基于全卷積網(wǎng)絡(luò)的閥門粘滯檢測方法
2021-03-13 09:13:20解劍波范海東李清毅劉夢杰趙春暉
浙江電力 2021年2期
解劍波,范海東,李清毅,劉夢杰,趙春暉
(1.浙江省能源集團(tuán)有限公司,杭州 310007;2.浙江大學(xué) 控制科學(xué)與工程學(xué)院,杭州 310027)
0 引言
現(xiàn)代社會的正常運(yùn)轉(zhuǎn)離不開電能,在我國的電力產(chǎn)業(yè)中,每年火電發(fā)電量約占總發(fā)電量的70%,火力發(fā)電仍然是電力產(chǎn)業(yè)的支柱,是我國經(jīng)濟(jì)發(fā)展的重要支撐。隨著計(jì)算機(jī)技術(shù)與自動控制技術(shù)的發(fā)展,火電廠中的自動化程度也在逐漸提高,每個(gè)工廠中都有數(shù)以百計(jì)的自動控制回路。每條自動控制回路在投入正式運(yùn)行前都經(jīng)過精心設(shè)計(jì),以保證回路的控制性能良好。然而在日常運(yùn)行過程中,回路中的設(shè)備難以避免地會出現(xiàn)老化等問題,這些問題可能會導(dǎo)致回路的控制性能下降,降低回路的生產(chǎn)效率,進(jìn)而影響到整個(gè)工廠的經(jīng)濟(jì)效益。
閥門是回路中最常見的執(zhí)行元件,自動控制回路中的控制器通過調(diào)節(jié)閥門開度的大小,對回路的過程變量進(jìn)行控制。正常的閥門在運(yùn)行時(shí)是線性的,閥門的實(shí)際開度能夠很好地跟隨控制信號變化,但是由于內(nèi)部元件磨損等問題,閥門在運(yùn)行一段時(shí)間后可能會出現(xiàn)非線性特性,如磁滯、死區(qū)、粘滯等,其中,粘滯是最常出現(xiàn)的問題[1]。閥門粘滯往往會導(dǎo)致回路出現(xiàn)振蕩,降低回路的控制性能,而依靠人工對工廠中的每個(gè)閥門進(jìn)行粘滯檢測會浪費(fèi)大量的人力物力。因此,如何利用控制回路中的數(shù)據(jù)進(jìn)行自動化閥門粘滯檢測成為控制回路性能監(jiān)控與診斷領(lǐng)域的一個(gè)重要問題。
在過去幾十年中,許多學(xué)者研究了閥門粘滯的檢測方法,主要可以分為以下4 類[2]:基于互相關(guān)函數(shù)的方法[3]、基于極限環(huán)模式識別的方法[4]、基于非線性檢測的方法[5]以及基于波形的方法[6]。Horch[3]提出了基于CCF(互相關(guān)函數(shù))的方法,如果OP(控制器輸出)與PV(過程變量)間的互相關(guān)函數(shù)為奇函數(shù),那么回路中的振蕩是由閥門粘滯引起的,否則,振蕩是由其他原因引起的。鄭麗麗等人[4]提出了一種改進(jìn)的基于模糊聚類的粘滯檢測方法,首先對OP-MV(操縱變量)圖使用模糊聚類算法獲得4 個(gè)聚類中心,然后對聚類中心所構(gòu)成四邊形進(jìn)行凹凸性識別,最后根據(jù)聚類中心的分布特征定義了一種新粘滯指標(biāo)。Choudhury 等人[5]先使用基于雙相干譜函數(shù)的方法[6]診斷回路中的振蕩是否由非線性原因所引起,當(dāng)是由非線性原因引起時(shí),使用橢圓對濾波后數(shù)據(jù)對應(yīng)的OP-PV 圖進(jìn)行擬合,若成功地?cái)M合出橢圓,則說明回路振蕩的根本原因?yàn)殚y門粘滯。He 等人[7]使用曲線擬合的方法進(jìn)行粘滯檢測,分別使用三角波和正弦波對OP 經(jīng)過第一個(gè)積分作用后的信號進(jìn)行擬合,并根據(jù)兩種擬合的誤差對比得到粘滯檢測結(jié)果。上述經(jīng)典的粘滯檢測算法雖然能夠取得不錯(cuò)的粘滯檢測結(jié)果,但通常適用范圍有限,如Horch 的方法只適用于使用PI 控制器的非積分過程。
在最近幾年中,神經(jīng)網(wǎng)絡(luò)被廣泛應(yīng)用于故障檢測與診斷領(lǐng)域[8-10,13-15],也有學(xué)者提出使用神經(jīng)網(wǎng)絡(luò)來解決閥門粘滯檢測問題。Dambros 等人[11]將回路的OP-PV 圖轉(zhuǎn)化為8×8 像素的圖片,并訓(xùn)練一個(gè)人工神經(jīng)網(wǎng)絡(luò)對該圖片進(jìn)行分類,最終可以得到回路的診斷結(jié)果為無振蕩、粘滯引起的振蕩或其他原因引起的振蕩。而Henry 等人[12]提出了一種基于CNN-PCA 的粘滯檢測方法,首先使用CNN(卷積網(wǎng)絡(luò))提取數(shù)據(jù)對應(yīng)的無閾值遞歸圖中的特征,然后使用PCA(主成分分析)模型對應(yīng)的特征統(tǒng)計(jì)量進(jìn)行閥門粘滯的檢測。以上方法在神經(jīng)網(wǎng)絡(luò)輸入數(shù)據(jù)構(gòu)造的過程中都難以避免地會損失部分過程數(shù)據(jù)本身包含的信息。
為了解決上述方法的不足,提出了一種基于FCN(全卷積網(wǎng)絡(luò))的閥門粘滯檢測方法。首先,回路中的原始運(yùn)行數(shù)據(jù)包含著豐富的過程動態(tài)信息。其次,相較于傳統(tǒng)的人工神經(jīng)網(wǎng)絡(luò),使用卷積神經(jīng)網(wǎng)絡(luò)能夠更好地處理多變量時(shí)間序列數(shù)據(jù)中的時(shí)序關(guān)系以及變量間的關(guān)系。因此,本文所提的方法直接使用回路運(yùn)行時(shí)的OP 與PV 數(shù)據(jù)來進(jìn)行閥門粘滯檢測,并使用全卷積網(wǎng)絡(luò)來解決這個(gè)分類問題。
1 閥門粘滯仿真數(shù)據(jù)生成
1.1 閥門粘滯模型
閥門粘滯現(xiàn)象指的是閥桿受到的靜摩擦力增加,導(dǎo)致閥桿在運(yùn)動時(shí)暫時(shí)卡住,隨著控制信號變化幅度增大,推動閥桿的作用力持續(xù)變大,當(dāng)作用力大于靜摩擦力時(shí),閥桿會突然跳躍。閥門粘滯的典型輸入、輸出特性曲線如圖1 所示。
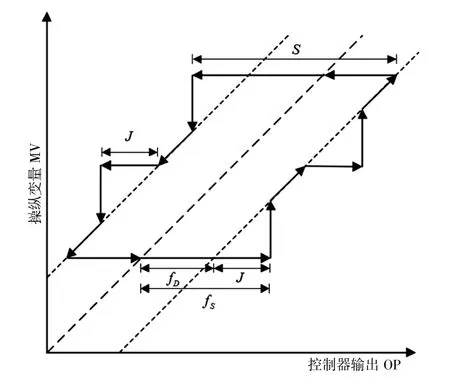
圖1 典型的粘滯閥輸入、輸出特性[18]
常用的閥門粘滯模型主要可以分為兩類:基于物理特性的和基于數(shù)據(jù)驅(qū)動的。Brasio 等人[16]總結(jié)了基于物理特性的閥門粘滯模型,但是這類方法需要了解閥門的真實(shí)物理特性來設(shè)置合適的模型參數(shù),并且進(jìn)行仿真時(shí)所需的計(jì)算量大,不方便進(jìn)行仿真。而基于數(shù)據(jù)驅(qū)動的模型則克服了上述缺點(diǎn),常用于進(jìn)行閥門粘滯的仿真。文獻(xiàn)[2]中對多種基于數(shù)據(jù)驅(qū)動的粘滯模型進(jìn)行比較,其中,Chen 等人[17]提出的雙參數(shù)閥門粘滯模型能夠更好地吻合閥門在粘滯時(shí)的運(yùn)動特性,本文在后續(xù)仿真時(shí)也采用這個(gè)模型。
1.2 仿真數(shù)據(jù)生成
訓(xùn)練一個(gè)深度神經(jīng)網(wǎng)絡(luò)需要大量的有標(biāo)簽數(shù)據(jù),然而在實(shí)際工業(yè)過程中,獲得高質(zhì)量的有標(biāo)簽數(shù)據(jù)成本極高,所以本文采用仿真模型來生成訓(xùn)練網(wǎng)絡(luò)時(shí)需要使用的數(shù)據(jù)。
控制回路性能下降的主要原因可以分為控制器參數(shù)不佳、外部擾動和閥門粘滯這三類[18]。因此,在進(jìn)行仿真數(shù)據(jù)生成時(shí),主要考慮生成控制性能良好以及處在上述三種性能退化情況下的仿真數(shù)據(jù)。在閥門粘滯的相關(guān)研究領(lǐng)域中,有著多種仿真數(shù)據(jù)生成方法[7,19-20],其中Choudhury 等人[6]中對上述4 種情況進(jìn)行過仿真數(shù)據(jù)生成,此外,Amiruddin 等人[21]使用類似的控制回路模型生成了大量的仿真數(shù)據(jù)用于后續(xù)訓(xùn)練人工神經(jīng)網(wǎng)絡(luò),并取得了良好的效果,本文使用類似的控制回路模型構(gòu)建方法來進(jìn)行仿真實(shí)驗(yàn)。不過需要注意的是,上述文獻(xiàn)中仿真時(shí)使用的是Choudhury的閥門粘滯模型[22],而本文采用的是Chen 的閥門粘滯模型,并對仿真時(shí)使用的模型參數(shù)進(jìn)行了修改。
所用仿真模型為一條單輸入單輸出閉環(huán)控制回路,回路模型由PI 控制器、閥門模型、被控對象、噪聲以及外部擾動組成,回路中被控對象的傳遞函數(shù)為
當(dāng)PI 控制器中K=I=0.15 時(shí),該仿真回路的控制性能良好[6],通過改變K 和I 的值來仿真回路控制性能不佳的情形。此時(shí),模型中控制器的參數(shù)設(shè)置如表1 所示。

表1 控制參數(shù)變化時(shí)參數(shù)設(shè)置
振蕩是過程工業(yè)中最常見的廠級范圍擾動[23],而由于回路間的低通濾波作用,振蕩在經(jīng)過多個(gè)回路傳遞后會趨向于正弦信號,因此,在回路中添加幅值和周期不同的正弦信號來代表回路受到外部擾動影響的情況,此時(shí)回路中的控制器參數(shù)為K=I=0.15,回路所受正弦擾動的具體參數(shù)設(shè)置如表2 所示。

表2 外部擾動情況下參數(shù)設(shè)置
對于回路中閥門出現(xiàn)粘滯問題的情況,回路控制器參數(shù)保持為良好狀態(tài),通過改變閥門粘滯模型中粘滯參數(shù)的大小來仿真回路受到不同程度粘滯影響時(shí)的數(shù)據(jù),仿真時(shí)具體的粘滯參數(shù)設(shè)置如表3 所示。

表3 閥門粘滯情況下參數(shù)設(shè)置
回路在實(shí)際運(yùn)行的過程中,難以避免地會受到噪聲的干擾,因此在上述參數(shù)已經(jīng)確定的情況下,回路會在不同的噪聲水平下多次進(jìn)行仿真以生成盡可能真實(shí)的數(shù)據(jù),噪聲方差的取值范圍如表4 所示。

表4 噪聲方差參數(shù)設(shè)置
圖2 展示了在閥門粘滯參數(shù)S=1.75,J=1,白噪聲方差V=0.03 情況下仿真生成的OP 及PV數(shù)據(jù),圖3 展示了對應(yīng)情況下的OP-PV 圖。
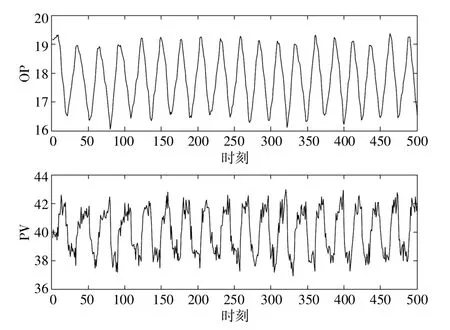
圖2 仿真生成的閥門粘滯情況下OP 及PV 數(shù)據(jù)
2 基于全卷積網(wǎng)絡(luò)的閥門粘滯檢測
2.1 網(wǎng)絡(luò)輸入
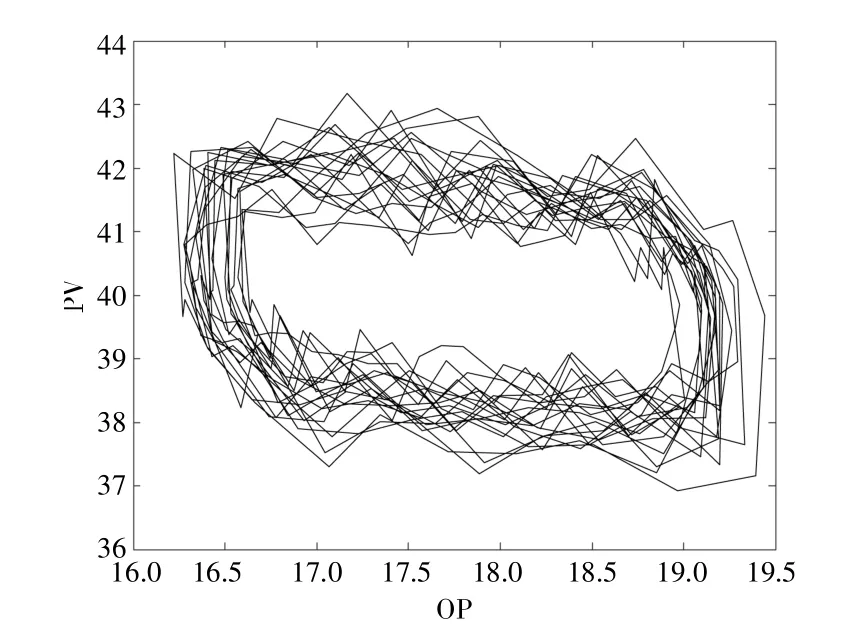
圖3 仿真生成的閥門粘滯情況下OP-PV 圖
對于使用非智能閥門的控制回路,回路運(yùn)行時(shí)的MV 數(shù)據(jù)無法直接獲得,為了增大閥門粘滯檢測算法的應(yīng)用范圍,使用OP 和PV 數(shù)據(jù)來檢測回路中的閥門粘滯現(xiàn)象。而且全卷積網(wǎng)絡(luò)作為一種可以進(jìn)行端到端訓(xùn)練的模型,不需要類似傳統(tǒng)方法人工提取特征,可以直接使用OP 和PV變量作為網(wǎng)絡(luò)的輸入并獲得分類結(jié)果。但是由于不同回路中OP 與PV 變量的取值范圍有很大差異,有的回路中PV 可以達(dá)到上千,而有的回路中PV 可能還不到十,因此本文采用最大最小歸一化對2 個(gè)變量進(jìn)行預(yù)處理后作為全卷積網(wǎng)絡(luò)的輸入。
此外,在對時(shí)序數(shù)據(jù)進(jìn)行分類時(shí),每個(gè)樣本中包含的時(shí)間序列長度也會對最終的分類結(jié)果產(chǎn)生影響。假如樣本中的時(shí)間序列長度過短,可能在一個(gè)樣本對應(yīng)的時(shí)間段內(nèi),回路中的閥門一直處于卡澀或者線性運(yùn)動階段,哪怕閥門是存在粘滯問題的,但是該樣本中的數(shù)據(jù)并沒有包含完整的粘滯閥門運(yùn)動周期,導(dǎo)致錯(cuò)誤的閥門粘滯檢測結(jié)果。而時(shí)間序列長度過長,則會增大運(yùn)算成本以及提高應(yīng)用時(shí)對于測試樣本的要求。因此本文設(shè)置每個(gè)樣本中包含的時(shí)間序列長度為500,即全卷積網(wǎng)絡(luò)的每個(gè)輸入樣本都為回路中OP 變量與PV 變量合并構(gòu)成的2×500 的矩陣。
2.2 全卷積網(wǎng)絡(luò)
閥門粘滯檢測的目的是通過分析回路運(yùn)行時(shí)的數(shù)據(jù),檢測出回路中的閥門是否出現(xiàn)粘滯現(xiàn)象。本文將閥門粘滯檢測問題看作是一個(gè)多變量時(shí)間序列分類任務(wù),通過對回路中的多變量數(shù)據(jù)進(jìn)行分析,將回路中閥門狀態(tài)分類為粘滯或者非粘滯。而使用深度學(xué)習(xí)的方法進(jìn)行多變量時(shí)間序列的分類已經(jīng)得到了廣泛的研究,F(xiàn)awaz 等人[24]將多種基于深度卷積網(wǎng)絡(luò)的時(shí)間序列分類算法的效果進(jìn)行了對比,其中,Wang 等人[25]提出的全卷積網(wǎng)絡(luò)在多變量時(shí)間序列分類任務(wù)中取得了最好的分類結(jié)果。由于全卷積網(wǎng)絡(luò)的優(yōu)秀性能,提出了適用于解決閥門粘滯檢測問題的全卷積網(wǎng)絡(luò)。
2.2.1 卷積層設(shè)置
多變量時(shí)間序列數(shù)據(jù)中的每個(gè)變量都是一個(gè)通道,可以直接采用一維卷積對多通道的數(shù)據(jù)進(jìn)行卷積操作。由于控制回路中廣泛存在時(shí)延,即OP 的變化會經(jīng)過一段時(shí)間才影響到PV,因此,具有大的感受野的卷積網(wǎng)絡(luò)能夠更好地捕捉OP與PV 變量間的相對關(guān)系,而增大卷積核的尺寸能夠直接增大卷積網(wǎng)絡(luò)的感受野。基于上述介紹,本文使用的全卷積網(wǎng)絡(luò)中共包含5 個(gè)一維卷積層,每個(gè)卷積層后都使用ReLU(線性整流函數(shù))作為激活函數(shù),卷積核的尺寸依次為7,5,3,3,3,卷積的步長都為1,且卷積網(wǎng)絡(luò)中不包含池化層與批標(biāo)準(zhǔn)化層。
2.2.2 分類網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置
在全卷積網(wǎng)絡(luò)中,卷積層的主要作用為提取數(shù)據(jù)中的特征,由于在上述網(wǎng)絡(luò)中經(jīng)過卷積層后的特征圖尺寸與卷積前相同,因此在最后一個(gè)卷積層后連接一個(gè)GAP(全局平均池化層)來減小特征圖的尺寸。相較于使用全連接層,使用全局平均池化層還能夠降低網(wǎng)絡(luò)中的參數(shù)量,起到正則化的作用,避免過擬合[26]。
對于全局平均池化層得到的特征,再依次連接一個(gè)包含2 個(gè)神經(jīng)元的全連接層以及softmax層以進(jìn)行分類任務(wù)。對于一個(gè)輸入的樣本。全卷積網(wǎng)絡(luò)的輸出可以表示為[y0,y1],且二者之和為一。
綜上所述,全卷積網(wǎng)絡(luò)結(jié)構(gòu)如圖4 所示。
2.3 模型訓(xùn)練
將閥門粘滯檢測任務(wù)視作一個(gè)分類任務(wù),因此可以使用樣本真實(shí)標(biāo)簽與網(wǎng)絡(luò)預(yù)測結(jié)果間的交叉熵作為網(wǎng)絡(luò)的損失函數(shù)。在網(wǎng)絡(luò)模型構(gòu)建完成后,將1.2 節(jié)中生成的仿真數(shù)據(jù)作為網(wǎng)絡(luò)的訓(xùn)練數(shù)據(jù),設(shè)置仿真生成的非粘滯數(shù)據(jù)的標(biāo)簽為[1,0],粘滯數(shù)據(jù)的標(biāo)簽為[0,1],使用學(xué)習(xí)率為0.000 5的Adam 優(yōu)化算法[27]對網(wǎng)絡(luò)進(jìn)行訓(xùn)練,并且在訓(xùn)練時(shí)引入權(quán)重衰減項(xiàng)以進(jìn)行正則化。
處于在線閥門粘滯檢測階段時(shí),只需要將待測試回路的數(shù)據(jù)按照2.1 節(jié)所述預(yù)處理后,輸入到訓(xùn)練完成的網(wǎng)絡(luò)中,就可以得到該回路的閥門粘滯檢測結(jié)果,若輸出y0大于y1,說明該回路中并沒有粘滯問題,否則,說明回路中的閥門出現(xiàn)了粘滯問題。

圖4 全卷積網(wǎng)絡(luò)結(jié)構(gòu)
3 實(shí)驗(yàn)分析
3.1 數(shù)據(jù)案例1
本案例數(shù)據(jù)來源于浙江省某發(fā)電廠的1B 汽泵1 號密封水CP 側(cè)控制回路。汽泵密封水的作用為防止高壓高溫水從泵內(nèi)泄漏以及防止低壓側(cè)漏入空氣。該控制回路采用PID 控制器,過程變量為密封水出口溫度,采集了該回路在閥門粘滯情況下運(yùn)行50 h 的OP 與PV 數(shù)據(jù),數(shù)據(jù)采樣的時(shí)間間隔為1 s,共計(jì)可得到180 000 個(gè)時(shí)刻的數(shù)據(jù)。由于構(gòu)建的閥門粘滯檢測網(wǎng)絡(luò)每次輸入的樣本包含500 個(gè)時(shí)刻的數(shù)據(jù),因此采用無重疊分段的方法對采集到的數(shù)據(jù)進(jìn)行劃分,最終可以得到360 個(gè)樣本。其中第一個(gè)樣本的OP 及PV 數(shù)據(jù)如圖5 所示,對應(yīng)的OP-PV 圖如圖6 所示。
將分段得到的每個(gè)樣本分別進(jìn)行預(yù)處理后輸入之前使用仿真數(shù)據(jù)訓(xùn)練完成得到的網(wǎng)絡(luò)中,可以得到這些樣本的閥門粘滯檢測結(jié)果,部分結(jié)果如表5 所示。
對于該案例中采集到的360 個(gè)樣本,本文提出的閥門粘滯檢測算法成功地分類了其中的305個(gè)樣本,準(zhǔn)確率為84.7%。
3.2 數(shù)據(jù)案例2
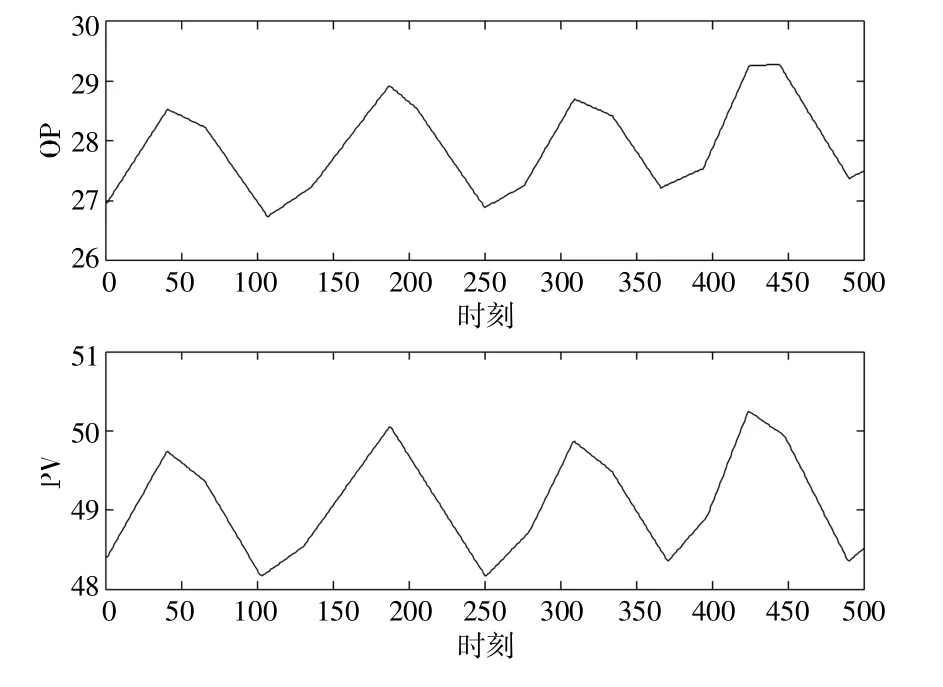
圖5 密封水控制回路的OP 及PV 數(shù)據(jù)
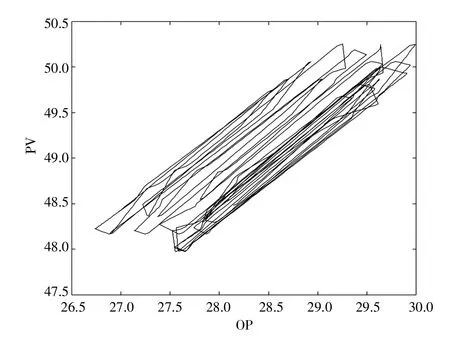
圖6 密封水控制回路的OP-PV 圖
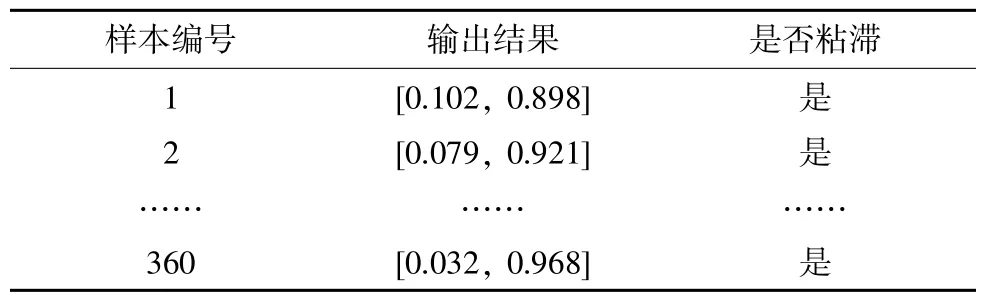
表5 閥門粘滯檢測結(jié)果展示
本案例數(shù)據(jù)來源于文獻(xiàn)[28]中提供的閥門粘滯公開數(shù)據(jù)集,為了方便與之前的方法進(jìn)行對比,從其中選取了78 條標(biāo)簽準(zhǔn)確的回路用作算法的測試集,這些回路數(shù)據(jù)來源于不同種類的工廠,如發(fā)電廠、化工廠等。這78 條回路中,有36條的標(biāo)簽為粘滯,剩余的42 條標(biāo)簽為非粘滯。在進(jìn)行測試時(shí),僅選擇每條回路中前500 個(gè)數(shù)據(jù)點(diǎn)作為該回路的代表樣本,用在該樣本上的結(jié)果代表整個(gè)回路的檢測結(jié)果。數(shù)據(jù)集中的CHEM29 回路的代表樣本的OP 和PV 變量如圖7 所示,圖8為對應(yīng)OP-PV 圖。
本文所提方法在36 條粘滯回路上檢測的準(zhǔn)確率為24/36(66.7%),在42 條非粘滯回路上檢測的準(zhǔn)確率為33/42(78.6%),總體檢測的準(zhǔn)確率為57/78(73.1%)。該方法與部分已發(fā)表方法在該公開數(shù)據(jù)集上的對比結(jié)果如表6 所示。
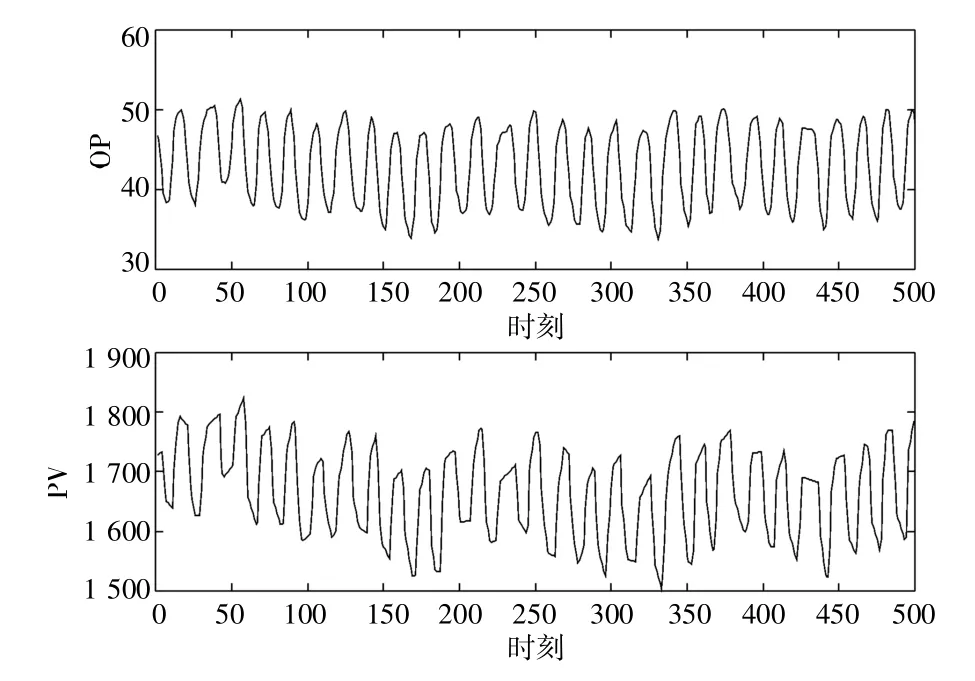
圖7 回路CHEM29 的OP 及PV 數(shù)據(jù)
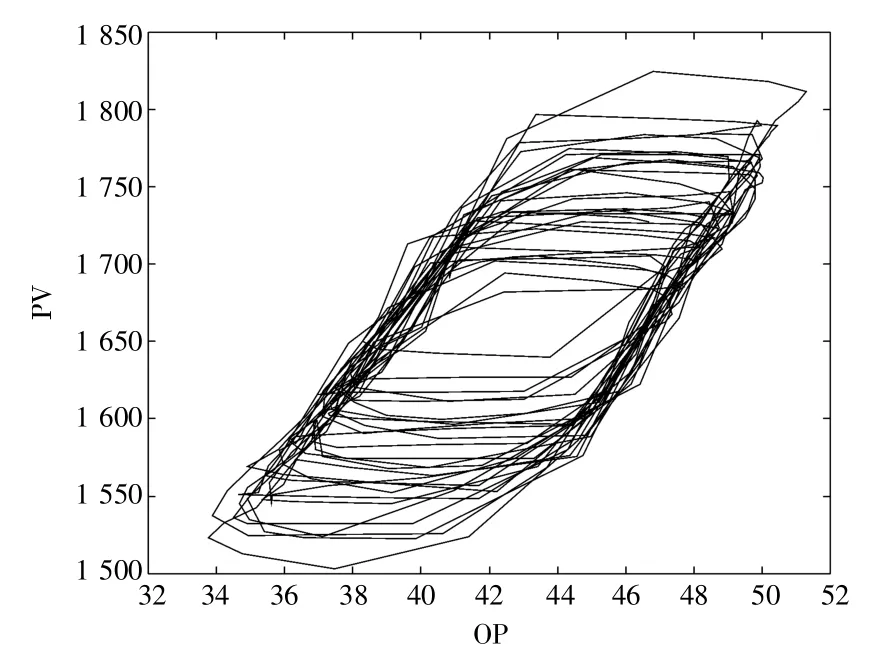
圖8 回路CHEM29 的OP-PV 圖

表6 閥門粘滯檢測結(jié)果
通過不同方法間的對比可以看到,本文所提的方法相較于文獻(xiàn)[16]和[29]中的算法在公開數(shù)據(jù)集上取得了更好的閥門粘滯檢測結(jié)果。
4 結(jié)語
本文針對控制回路中的閥門粘滯檢測問題提出了一種基于全卷積網(wǎng)絡(luò)的檢測方法。相比于其他的閥門粘滯檢測方法,該方法減少了對于人工提取特征的需求,只需使用回路原始的控制變量以及過程變量數(shù)據(jù)就可以實(shí)現(xiàn)閥門粘滯檢測,并且具有更加準(zhǔn)確的檢測結(jié)果。
訓(xùn)練集的質(zhì)量對于深度學(xué)習(xí)中網(wǎng)絡(luò)模型的精度有明顯影響,在后續(xù)工作中,可以考慮生成更加豐富的仿真數(shù)據(jù)作為訓(xùn)練集。除此之外,還可以考慮結(jié)合遷移學(xué)習(xí)方法,將使用仿真數(shù)據(jù)訓(xùn)練得到的網(wǎng)絡(luò)遷移到實(shí)際應(yīng)用的回路中。
猜你喜歡
流程工業(yè)(2022年3期)2022-06-23 09:41:08
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
煤氣與熱力(2021年3期)2021-06-09 06:16:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
