3D目標檢測技術發展綜述
2021-03-15 06:59:23梁小芳余華平
電腦知識與技術 2021年1期
關鍵詞:深度學習
梁小芳 余華平
摘要:目標檢測是計算機視覺領域的一個重要分支,由于2D目標檢測技術自身的發展限制和近年來硬件技術的發展與應用,3D目標檢測技術逐步取得了較不錯的成績,并為目標檢測技術打開了新的應用領域,如AR/VR、自動駕駛、文化遺產保護等。文中從2個方向,4個分支介紹近年來3D檢測技術領域的經典架構以及關鍵性知識,簡要分析了各架構特點,并對3D目標檢測技術的發展做出總結與展望。
關鍵詞:目標檢測;深度學習;激光雷達點云;圖像數據;神經網絡
中圖分類號:TP399文獻標識碼:A
文章編號:1009-3044(2021)01-0231-04
Abstract: Target detection is an important branch in the field of computer vision, Due to the limitations of the development of 2D target detection technology and the development and application of hardware technology in recent years,3D target detection technology has gradually achieved relatively good results and opened up new possibilities for target detection technology. The application areas of the company, such as AR/VR, autonomous driving, cultural heritage protection, etc. The article introduces the classic architecture and key knowledge in the field of 3D detection technology in recent years from 2 directions and 4 branches, briefly analyzes the characteristics of each architecture, and summarizes and prospects the development of 3D target detection technology.
Key words: target detection;deep learning;LIDAR point cloud; image data; neural network
1引言
在計算機視覺領域,目標檢測是近些年來引發各界關注的主要方向之一,其理論的進步和在各大領域的廣泛應用,很大程度上利用計算機視覺技術節約了對人力資源的消耗。目標檢測需要識別出物體的位置和相應類別信息,根據輸出結果的不同,分為2D目標檢測和3D目標檢測。與2D目標檢測相比,3D目標檢測包含物體的長度、寬度、高度以及旋轉角度等信息,因此,實際應用中,3D空間的目標檢測具有更深遠的意義,在AR/VR、遙感測繪、軍事勘察、無人駕駛、生物醫學檢測、文化遺產保護等領域,3D目標檢測技術能很好體現自身優勢,從而完成相關任務。
2基于點云的3D目標檢測
3D目標檢測問題本質上是三維點的劃分問題,而激光雷達點云是通過眾多無序數據點組成的集合進行表達的。與單視圖和多視圖對比發現,激光雷達點云中點的深度屬性能夠被直接測量,所以基于激光雷達點云的3D目標檢測方式顯得更為直觀和精準,同時由于一般深度相機的視野問題,激光雷達點云可以更好地應用于戶外環境下的大尺度場景。
關于點云數據的3D目標檢測研究,目前國際上大致分為兩個方向,一個方向是將圖像數據和點云數據進行融合,另一個方向則是僅以點云數據作為輸入。本章將從這兩個方向對近年來較優秀模型進行介紹。
2.1 激光雷達點云與圖像融合的3D目標檢測
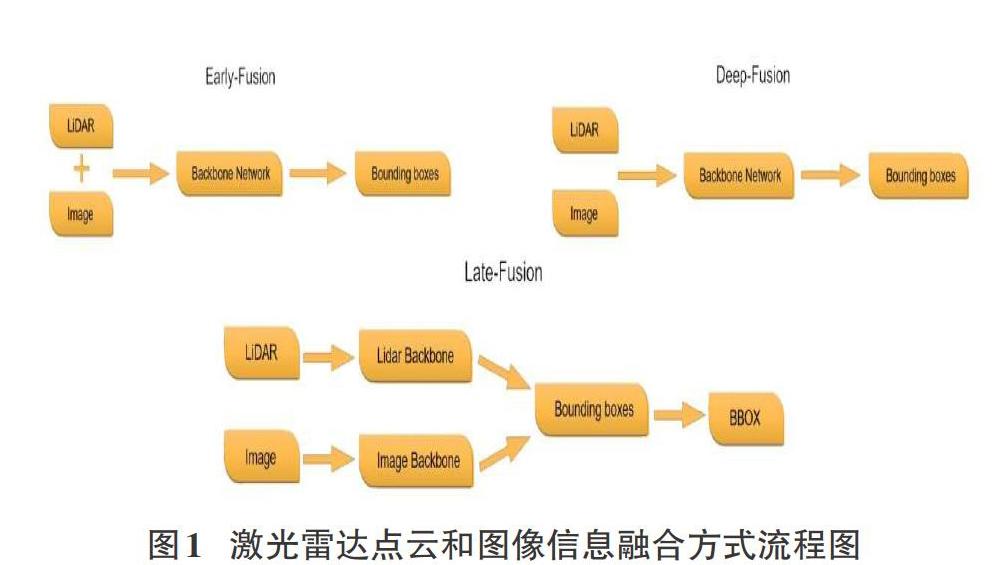
從信息論來看,多傳感器具有更多的互補信息,采用多模態的信息能夠很好地提高魯棒性和檢測準確率。在3D目標檢測中,將激光雷達點云和圖像信息進行融合的主要方法為前融合(Early-Fusion)、中間層融合(Deep-Fusion)和后融合(Late-Fusion)。它們的簡要流程如圖1所示。
Early-Fusion 指的是在對原始傳感器數據進行提取特征任務之前對特征進行融合。通常表現為將多個單獨的數據集處理成單一的特征向量,然后輸入到分類器中,再經過深度學習網絡實現邊框回歸。理論上,這種融合方法是多模態融合中效果最好的方法,因為此時對應的特征在現實中存在一定的索引關系和更少的特征抽象。但前融合技術通常不能很好地利用不同模態數據間的互補特性,并且前融合的原始數據經常含有非常多的冗余信息。所以,前融合方法經常和特征提取方法進行結合,從而達到剔除冗余信息的目的,如最大相關最小冗余算法(MRMR)、自動解碼器(Autoencoders)、主成分分析(PCA)等。
Deep Fusion需要在特征層中做一定的交互。激光雷達點云和圖像數據的分支都各自采用自己的特征提取器,并且各分支網絡在前饋層次中進行逐語義級別的融合,做到多尺度(multi-scale)信息的語義融合。其主要特點是可以靈活選擇進行融合的位置。因此也是最可能創造出新的融合方法的融合方式。
Late fusion是最簡單的融合方法,核心思想就是兩種模態的特征不在特征層或者最開始就融合,因為不同傳感器的數據本身存在比較大的差異,就激光雷達和圖像而言,最大的差異就在視圖的不同,圖像中物體尺度會隨距離變化而發生改變,但是點云數據不存在這個問題。此外,點云和圖像做特征層的融合最大的難點是像素和點云點之間索引精準性和領域差異。而該融合方式的誤差來自多個分類器,不同分類器的誤差通常互不干擾,從而不會使誤差發生累加現象。較普遍的后融合方式包括平均值融合(Averaged-Fusion)、貝葉斯規則融合(Bayesrule Based)、最大值融合(Max-Fusion),以及集成學習(Ensemble Learning)等。
通過上述內容不難發現,Early-Fusion、Deep-Fusion和 Late-Fusion分別是在輸入層、特征層和決策層上的融合。
目前3D目標檢測的多模態融合方法可以從MV3D(CVPR17)說起,它是將點云數據以特定的視角投影到二維平面,再將不一樣視覺角度的數據進行融合,從而完成認知任務。該方法進行鳥瞰視角投影時會丟失幾何結構信息,損失精度,并且實驗最終結果顯示MV3D只對汽車結果較好,對行人和自行車的檢測表現的都很差。
F-PointNet沒有對激光雷達點云和圖像這兩類信息分別處理(并行)進行融合,而是通過串行方式,先在2D目標檢測器中生成邊框,然后再投影到三維點云上對邊框做進一步的優化工作。該類方法提高了檢測效率,實現了逐維(2D-3D)定位,縮短了對點云的搜索時間,并且幾乎沒有任何維度的信息損失。但其突出劣勢表現為整個流程對2D的檢測效果比較依賴,且無法解決遮擋問題。
MMF(CVPR19)創新點主要是第一次將圖像特征投影到鳥瞰視圖(BEV圖)中做回歸,其次是解決了BEV視圖信息和圖像信息在點對點(point-wise)級別的融合問題。
以上三個架構是近年來通過激光雷達點云和圖像數據融合進行3D目標檢測方向的優秀作品,從中可以看出。多模態融合的3D目標檢測目前普遍存在以下難點:
1) 傳感器視角差異:攝像頭由于小孔成像原理,是從視錐出發獲取信息,而激光雷達是在真實的3D世界中獲取信息。
2) 數據表征不同:圖像數據是規則、稠密的,而點云數據則是無序、稀疏的。
3) 信息融合難度:圖像數據因距離存在尺度問題,2D檢測中,深度學習方法都是以CNN結構為基礎進行設計,而點云數據具備幾何結構和深度信息,無法采用傳統的CNN架構感知,且點云目標檢測領域中有MLP、CNN,GCN等多個簡單結構構成的網絡,在融合過程中將哪幾種網絡進行融合是需要進行研究的。
2.2激光雷達點云的3D目標檢測
相對于激光雷達點云與圖像融合方式而言,純點云數據做數據增強更容易,因為不需要考慮數據間的對應關系。
為了方便分析,相關學者將使用純激光雷達點云的3D檢測分為基于點素(Point-Based的)和基于體素(Voxel-Based)兩個分支。Point-Based方式采用原始的點云數據坐標作為特征載體,直接利用激光雷達點云進行處理。Voxel-Based方式將點云數據轉化成規則數據,利用卷積實現任務,換而言之,該方式將voxel中心作為CNN感知特征載體,但相對原始點云對圖像的坐標索引來說,voxel中心與原始圖像的索引存在偏差。
蘋果公司提出的VoxelNet架構將三維點云劃分為一定數量的voxel,經過點的隨機采樣及歸一化處理后,對每一個非空voxel都采用若干個VFE層進行局部特征提取,然后經過中間的3D卷積層進一步特征抽象處理,實現增大感受野并學習幾何空間特征,最后使用RPN對物體進行分類檢測與位置回歸。該方法提出了端到端、可訓練的深度網絡架構,可以直接處理稀疏的3D點云,避免了因人工設計的特征而引入的信息瓶頸問題。
SECOND方法是一個一階段的用于3D激光點云的目標檢測方法,主要特點為:
1)使用了3D稀疏卷積(SparseConvolution),大大提升了3D卷積的速度;
2)數據庫采樣的操作被應用到數據增強過程中;
3)分類損失使用了focal loss,方向損失使用smoothL1(sin(theat1-theta2))+softmax loss。
PointPillar是一種新穎的編碼器,它利用PointNet架構來學習在垂直列柱體組織中的點云的特征,完成3D物體檢測網絡的端到端訓練;通過將柱體上的所有計算都設置為稠密的2D卷積,從而實現62 Hz的檢測速率,比前期其他方法快2-4倍;
Part-A^2首次將稀疏卷積(SparseConvolution)應用到兩階段(Two-Stage)的3D點云目標檢測中,整個網絡分為局部感知(Part-Aware Stage)和局部聚集(Part-Aggregation Stage)這兩個模塊。Part-Aware Stage將整個空間柵格化,然后對每一個格子生成特征,使用全連接層和最大池化(MaxPooling)方法對柵格內的點云自動進行特征提取,得到每個柵格的特征,這個階段的輸出是4維的特征圖和區域提案。Part-Aggregation Stage對前一階段產生的voxel實現池化和分類。
PointRCNN是第一個從原始點云進行3D物體檢測的Two-Stage框架,也是首個基于點云的免錨提案生成策略的方案,實現了純粹使用點云數據完成3D目標檢測任務,并且很好地解決了遮擋問題和以及檢測過程中對2D檢測結果的依賴。該框架包括兩個部分:第一部分通過將前景點分割的方式,實現從原始點云空間產生3D提案;第二部分通過使用規范的坐標來調整提案,從而獲取最后的檢測結果。
STD是騰訊優圖和港科大的研究成果,它是一個Two-Stage方法,先通過語義信息對每一個點生成一個球形錨(anchor),再通過非極大值抑制(NMS)方法得到最終的分類提案,接下來是點池化層得到每一個提案的特征,采用的是VFE操作,這一階段區別于VoxelNet系列,VoxelNet系列的特征是以小size的anchor為單位,而STD則是以一個“提案”為單位進行提取的。第二階段是一個巨大的創新,是將交并比分支(IOU Branch)和邊框預測分支(Box Prediction Branch)進行結合。
香港中文大學團隊提出了一種新穎的高性能3D對象檢測框架,稱為PointVoxel-RCNN(PV-RCNN),用于從點云中進行精確的3D對象檢測。該方法也是一個Two-Stage方法,將3D體素卷積神經網絡和基于PointNet的集合進行抽象,通過深度集成來學習更多判別性點云功能。它利用了3D體素CNN的高效學習和替代提案以及基于PointNet的網絡靈活接收范圍等優勢。PV-RCNN不僅是一個Multi-Scale和voxel的特征信息融合,同時也是point和voxel的融合。point的方法具有可變、多尺度感受野的特征,而voxel的方法則具有高效性,PV-RCNN將這兩點得到了很好的體現。
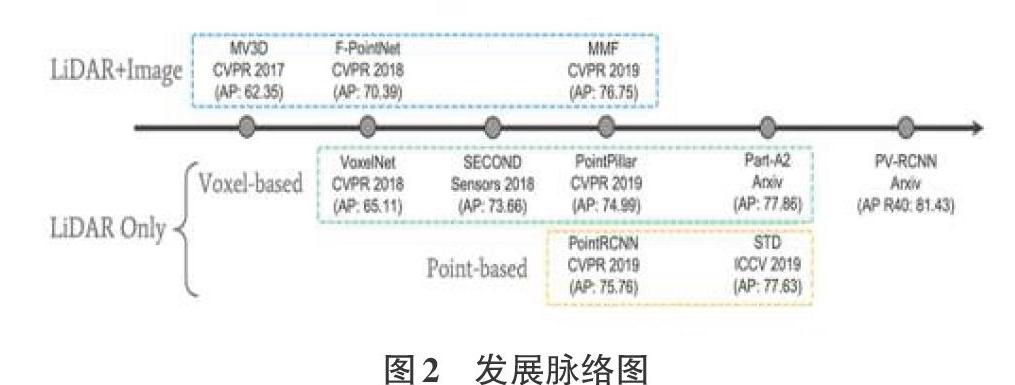
圖2展示的是近幾年來基于激光雷達點云數據進行3D目標檢測的主要發展脈絡。
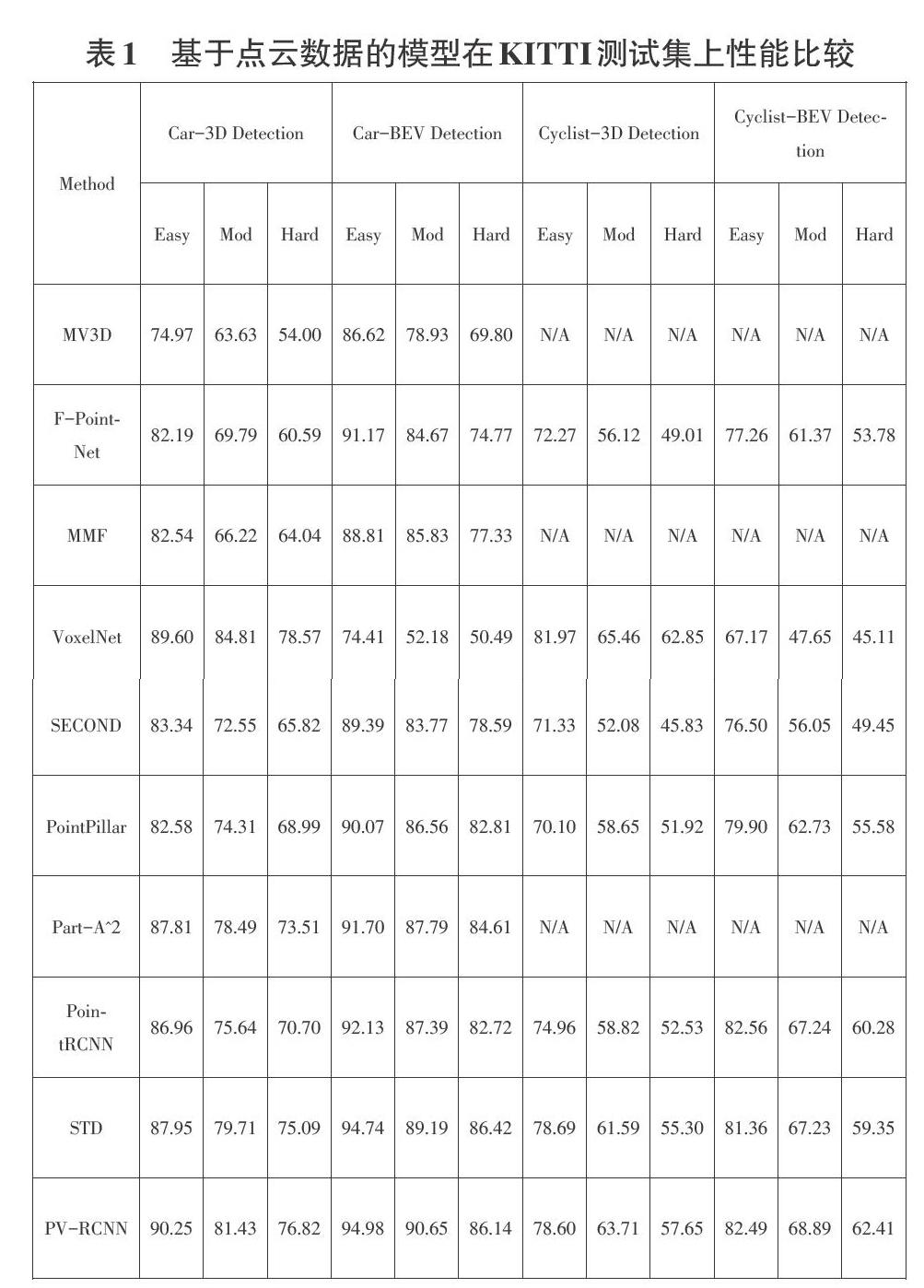
表1展示的是基于激光雷達點云數據進行3D目標檢測的幾大模型在KITTI測試集上的性能比較,這些結果是通過具有40個召回位置的平均精度評估結果。
3基于非激光雷達點云的3D目標檢測
3.1單目圖像下的3D目標檢測
2017年CVPR中,A.Mousavian團隊提出了一種利用單目圖像對目標物體進行朝向、大小和3D位置進行預測的方法。這種算法框架主要由2D目標檢測網絡、目標大小姿態估計網絡、目標3D中心點向量求解模塊這三個部分構成。它首次利用深度神經網絡獲得了相對穩定的3D對象屬性,并利用這些屬性和2D幾何約束,得到了3D的邊框,與此同時,這種方法不需要預處理階段,并為后人提供了MultiBin回歸這種新穎的用于估計物體方向的思路。
以王曉剛教授為主導的香港中文大學和商湯科技團隊提出的高性能3D目標檢測框架——GS3D,是一種基于可靠2D檢測結果和表面特征的三維車輛檢測算法,它的主要流程是:利用2D檢測器得到目標物體的方向和邊界框,然后得到具有指導意義的粗糙長方體3D邊界框,再利用3D邊框重投影到二維平面的信息來獲取目標物體的3D表面特征;最后將2D邊框提取的紋理信息和3D邊框提取的表面特征融合,獲得更加精細化的3D檢測框。GS3D為單目圖像下的3D目標檢測模型的精細化提供了指導性思路。
YOLO-6D是利用YOLO系列進行3D目標檢測的優秀算法,相比之前同類型算法,它的運行速度相對穩定,幾乎不受運行時間和目標數量影響,并且避免了因微調結果導致物體檢測超時問題,但它主要弊端是需要使用先驗3D模型知識。YOLO-6D通過預測目標物體3D邊框的1個中心點和8個頂點以及后續的PNP算法,實現了將6D姿態預測問題到9個坐標點預測的轉換。
3.2基于RGB-D圖像下的3D目標檢測
計算機圖形領域,含有與目標對象表面距離有關信息的圖像或圖像通道被稱為深度圖,傳感器與物體的實際距離就是由深度圖的像素值來表示。由于RGB圖像和深度圖像的配準關系,像素點間具備一一對應關系。
2014年,RGB大神對2D目標檢測架構——R-CNN進行改進,通過模塊對深度圖實現利用,第一階段基于RGB圖像和深度圖,檢測圖像中的輪廓,并生成包括每個像素的視差、高度、傾斜角2.5D的提案。第二階段利用DepthCNN和RGB CNN分別提取深度圖和2D圖像特征,最后使用SVM實現最終分類任務。
隨后,2015年陳曉智團隊將R-CNN推廣到RGB-D圖像,引入一種新的編碼方式來捕獲圖像中像素的地心姿態,該方式比單獨利用深度通道取得了更好的實驗效果。普林斯頓大學學者,提出的方法為Faster R-CNN的3D版本,側重于室內場景下的目標檢測。該團隊增加了多種尺度的檢測手段來檢測各種大小不一的目標。具體來說,是在不同的卷積層上進行3D滑窗,最后得到6個偏移量:來自坦普爾大學的學者則利用Fast R-CNN架構,重新回到2.5D方法來進行3D目標檢測。即從RGB-D上提取出合適的表達,而后建立模型以將2D結果轉換為3D空間。
雖然利用三維幾何特征實現3D目標檢測前景光明,但在實踐中,重建的三維形狀往往不完整,并且由于遮擋、反射等原因包含各種噪聲。
4結論
隨著硬件技術和理論技術的發展,3D目標檢測領域碩果累累,一定程度上改善了人類的生活習慣,促進了科技發展并推動了社會進步。盡管3D目標檢測發展勢頭迅猛,但也不難發現,該領域仍存在許多暫時難以突破的瓶頸,如單目圖像下的3D目標檢測中,由于透視投影存在,很難捕捉局部目標和尺度問題;基于深度圖的3D目標檢測因遮擋、光線等造成數據噪聲較多,極大影響三維重建過程;在基于激光雷達的3D目標檢測方向,采用激光雷達點云與圖像進行融合時,兩者間的數據配準以及對運算對顯存的極高要求暫時還未有突破性進展。
雖然在3D目標檢測技術的發展道路中存在許多艱辛,但其潛力仍不能小覷,未來3D目標檢測技術在識別精準度以及實時性方面或許會吸引更多的學者參與研究,當然各種因技術發展引發的道德倫理以及個人隱私和信息安全等問題也需要引起各界重視。
參考文獻:
[1] Chen X, Ma H, Wan J, et al. Multi-view 3d object detection network for autonomous driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1907-1915.
[2] Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 918-927.
[3] Liang M, Yang B, Wang S, et al. Deep continuous fusion for multi-sensor 3d object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 641-656.
[4] Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4490-4499.
[5] Yan Y, Mao Y, Li B. Second: Sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): 3337.
[6] Lang A H, Vora S, Caesar H, et al. Pointpillars: Fast encoders for object detection from point clouds[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12697-12705.
[7] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[8] Shi S, Wang Z, Shi J, et al. From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network[J]. arXiv preprint arXiv:1907.03670, 2019.
[9] Shi S, Wang X, Li H. Pointrcnn: 3d object proposal generation and detection from point cloud[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 770-779.
[10] Yang Z, Sun Y, Liu S, et al. Std: Sparse-to-dense 3d object detector for point cloud[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1951-1960.
[11] Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10529-10538.
【通聯編輯:梁書】
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
