Web用戶異常行為檢測的優化研究
2021-03-17 09:34:00王青松
遼寧大學學報(自然科學版) 2021年1期
王青松,李 菲
(遼寧大學 信息學院,遼寧 沈陽 110036)
0 引言
數據分析伴隨著大數據時代的發展,Web用戶的異常行為檢測技術[1-3]是當前研究熱點.近幾年,面對大規模用戶每天都會訪問Web網頁所產生的數據處理的需求,數據分析技術得以蓬勃發展.從大量數據中找到其背后隱藏的規律和模式,對異常數據的實時檢測具有重要的實際應用意義[4].統計數據預測采用分布式處理、并行處理和網格計算等方法,結合相關的數據特征挖掘和聚類,實現數據預測[5].
早期人們通常采用端口掃描、報文特征字段匹配等方法對異常行為進行深入分析以獲取特征,從而實現Web用戶異常行為的檢測[6].而人工智能技術的發展,機器學習技術更多地被用于從網絡數據中自動計算異常行為模式、提取其特征,從而自動產生檢測規則,大大降低了開發代價,而機器學習主要分為無監督學習和有監督學習.
傳統的無監督機器學習算法處理的是無標記或者數據趨勢模糊的情況下,這類算法不僅開銷大而且訓練出來的模型可讀性差,準確度較低,復雜度高且不適合時間序列數據,對Web用戶異常行為的檢測準確率較低,例如期望最大化算法(Exceptation Maximization)等.
基于有監督的機器學習算法通過利用帶標簽的訓練數據構建模型,來對未知數據進行預測,該類方法在模型可讀性、魯棒性等方面優于無監督學習的檢測方法,但易出現過擬合或欠擬合,泛化能力較差的問題.而且對訓練樣本中標記數據都要檢索一遍,關鍵特征提取率不高,增加了很多不必要的開銷.例如Teodoro[7]等人研究出基于異常的網絡入侵技術,提出基于知識、統計和機器學習的方法,但是他們的研究并沒有提出一套最先進的機器學習方法.Wu和Banzhaf[8]等人研究計算智能方法及其在入侵檢測中的應用,詳細地介紹了人工神經網絡、模糊系統、進化計算、人工免疫系統和群體智能等方法,只描述智能計算方法,不包括主流的機器學習和數據挖掘技術[9],例如決策樹算法(Decision Tree algorithm)、樸素貝葉斯算法(Naive Bayesian algorithm,NB)等.Bing[10]等人研究基于圖分析和支持向量機的企業網異常用戶檢測模型中所提取的特征雜亂,沒有對特征的重要性進行區分.
綜合現有的數據處理與數據挖掘的算法,將C4.5決策樹模型與過濾特征選擇Relief-F算法相結合,利用混淆矩陣的理念計算閾值并進行驗證,提出一種新的Web用戶異常行為檢測算法F_C4.5算法.通過消除冗余特征、減少特征集的大小降低模型建立的復雜度,對于用戶行為的分類效果更優,提高Web用戶異常行為檢測的效率和準確度.
1 相關知識介紹
1.1 特征選擇
在對訓練樣例數t維度為d的樣本點進行回歸時,可能存在d大于或者遠遠大于t的情況,在d中可能存在f個無用特征,若去除這些無用特征可能需要枚舉所有可能產生的情況,使用交叉驗證的方法對每一種情況計算其對應的錯誤率,根據得到的結果衡量應該消除的無用特征,這種方法對樣本數據的訓練和測試次數過多,浪費時間和空間資源.可以采用過濾特征選擇(Filter feature selection)的方法處理樣本數據,降低復雜度并且提高了算法的效率.
過濾特征選擇方法通過對數據的常用屬性(例如一致性、相關性、距離等)進行不同的度量來選擇特征[11].其中最著名的方法是Kira和Rendell在1992年提出的Relief(Relevant Features),以及由Kononenko于1994年提出的上述算法的改進版Relief-F[12],這兩種方法通過設計出一個“相關統計量”來度量某個特征對于學習任務的重要性.Relief-F算法[13-14]能處理多分類問題,解決了Relief算法在不完全、有噪聲、多類別標記的數據集上遇到的問題.
Relief-F算法的“相關統計量”是一個向量,其每個分量分別對應一個初始特征.而子集中的每個特征對應的的相關統計分量的和決定其重要性.算法過程中需要選取一個合適的閾值ε,選擇相關統計量分量比ε大的對應特征作為訓練數據進行后期的模型構建.
算法步驟如下:
1)假定數據集D中的樣本來自|y|個類別.對于示例xi若它屬于第k類(k∈{1,2,…,|y|}),則算法先在第k類的樣本中尋找xi的最近示例xi,nm并將其作為猜中近鄰,然后在其他類中找到一個xi的最近示例將其作為猜錯近鄰,記為xi,l,nm(l=1,2,…,|y|;l≠k).
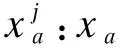
(1)
1.2 C4.5決策樹算法
決策樹算法相當于一個投影,是一種預測模型,通過分類給多個樣本賦予不同標簽,分類的過程用一棵樹來表示,分叉后的過程就是劃分特征的過程,將屬性值映射到樹的分叉路徑上.
C4.5算法是最著名和最廣泛使用的決策樹算法之一,精度水平高,獨立于要處理的數據量[15].在近幾年的一項比較決策樹和其他學習算法的研究表明,C4.5算法是一種追求更低誤報率和更高速率的結合型算法.該算法的生成規則易于理解,使用信息增益來進行決策樹的劃分屬性選擇,充分考慮了關鍵特征對分類的影響,對于離散型和連續型屬性變量都有較好的處理能力,產生的決策樹泛化能力強,預測未見數據示例的結果較準確.
算法步驟:
計算整個數據集的信息熵Info(D)和各個屬性的信息熵Infoa(D),其中Pi:當前樣本集合D中第i類樣本所占比例(i=1,2,…,m),Dv:第v個分支結點包含D中所有在屬性a上取值為av的樣本(假設離散屬性a有v個可能的取值{a1,a2,…,av}).
(2)
(3)
計算分裂信息H(V),通過信息增益Gain(D,a)來計算,一般信息增益越大,代表使用屬性a來進行劃分所獲得的“純度提升”越大.其中a:樣本集中的某一個特征,V:當前被計算熵特征取值為v的樣本集.
Gain(D,a)=Info(D)-Infoa(D)
(4)
(5)
計算信息增益率Gain_ratio(D,a),選擇信息增益率最高的特征來選擇最優劃分屬性,構建分支.其中:Ⅳ(a)為考慮分裂信息的度量,屬性a的取值數目越多(即V越大),則Ⅳ(a)的值越大.
(6)
(7)
(4)計算去除已經被使用的特征,按照步驟(1)和(2)、(3)重復計算未被選擇的特征,直到數據集不能或不用被再次劃分.
2 用戶異常檢測算法
2.1 用戶行為分類
Web用戶異常行為檢測過程包括對數據模型進行訓練和對用戶行為進行檢測.在訓練階段,系統首先定義并收集大量的正常行為數據,例如,應用程序一段時間對外的訪問量、主機CPU利用率、程序占用系統內存大小等[16].再利用過濾特征選擇Relief-F算法對這些數據進行預處理,然后根據Web用戶正常行為數據和Web用戶異常行為數據建立C4.5決策樹模型.在檢測階段,若未知行為數據實例在檢測模型中的測試距離與Web用戶正常行為數據具有更近的距離,則該數據為Web用戶正常行為數據,否則該數據為Web用戶異常行為數據.
2.2 訓練樣本處理
描述一個樣本可以通過很多特征,對于Web日志記錄的數據中,有些特征是對于檢測Web用戶異常行為的有價值的“相關特征”,有些則是幾乎無價值“無關特征”.對訓練樣本進行必要的預處理可以減輕計算過程的復雜度,有助于提高計算額準確性.C4.5決策樹算法雖然能做到處理連續屬性變量的訓練樣本數據集,但是需對訓練集反復進行排序及按一定規則順序掃描,導致算法效率低下[17],而對數據集進行過濾特征選擇處理后改善了由于特征變量過多決策數構造過程所造成復雜度過高的情況.在Web用戶異常行為檢測過程中,F_C4.5算法的實現過程分為如下兩個階段:
1)第一個階段評估原始特征集與類的相關性,從給定的特征集合中選擇出相關特征子集,處理劃分訓練樣本子集,刪除相關度較低的特征.在給定數據集的所有屬性中,通過過濾特征選擇Relief-F算法對數據集進行第一步預處理:定義兩個類別標簽,Web用戶正常行為類別標簽和Web用戶異常類別標簽.更新每個特征的權重W(A),公式如下:
(8)
基于從最近的數據構建好每個被檢測數據的估計值,使用混淆矩陣的思想選取閾值ε,混淆矩陣的各個參數設置如表1所示,使用Precision/Recall計算F1Score,找到閾值ε使得F1Score的值最高.

(9)
(10)
(11)
其中TP為正確預測正常樣本(true positives),TN為正確預測異常樣本(true negatives),TP和TN得到的都是正確結果.FP為錯誤預測正常樣本(false positives),模型預測為正常值實際樣本為異常值;FN為錯誤預測異常樣本(false negatives),實際樣本為正常值但模型預測為異常值.
2)第二個階段將兩個類別標簽中保留的相關特征傳遞給C4.5算法,通過Web用戶行為的訓練數據集進行遞歸分析構建決策樹模型,使用Web用戶行為測試數據集對構建好的決策樹模型進行檢測.
當有新的Web用戶異常行為發生時,使用F_C4.5算法進行檢測.Web用戶異常行為檢測算法總體實現過程描述如下:
算法:F_C4.5算法
輸入:訓練數據集D
樣本抽樣次數m
特征權重閾值δ
最近鄰樣本個數k
輸出:以root為結點的決策樹
1.置0所有特征權重,T為空集
2.fori=1 tomdo
(1)從D中隨機選擇一個樣本R;
(2)從R的同屬性樣本集中找到樣本R的最近鄰Hj(j=1,2,…,k),找到與R不同屬性集的最近鄰Mj(C),同為k個;
3.forA=1 toNAll feature updateW(A)
4.篩選出比閾值ε大的特征集
5.產生訓練集D*={(x1,y1),(x2,y2),…,(xm,ym)},
屬性集A={a1,a2,…,ad} then
6.計算函數TreeGenerate(D*,A)
7.得到root結點;
8.ifD*中所有樣本都屬于C類屬性then
9.C類葉節點更新為root;return
10.end if
11.ifD*中樣本在A上取值相同orA為空集then
12.root更新為葉節點,將對應類屬性更新為D*中有著最多樣本數的類;return
13.end if
14.從A中選擇Gain_ratio(D*,a)最大的ai作為最優劃分屬性
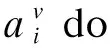
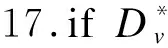
18.分支結點更新為葉結點,將對應類屬性更新為D*中樣本最多的類;return
19.else
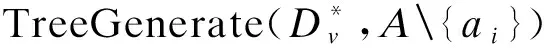
21. end if
22.end for
3 實驗與分析
3.1 實驗環境和任務
實驗在Windows10系統下,使用Python語言3.5版本,PyCharm工具運行代碼實現本文的Web用戶異常行為檢測.在UNSW-NB 15數據集[18]和KDD CUP1999數據集[19]上實現算法的性能評估任務.UNSW-NB 15數據集的原始網絡數據包是由澳大利亞網絡安全中心(ACCS)網絡范圍實驗室的IXIA Perfect Storm工具創建的,用于生成真實的現代正常活動和合成的現代攻擊行為的混合.TCPDump工具用于捕獲100 GB的原始流量(例如,Pcap文件).該數據集有九種類型的攻擊,即模糊攻擊、分析攻擊、后門攻擊、DoS攻擊、利用攻擊、通用攻擊、偵察攻擊、外殼代碼攻擊和蠕蟲攻擊.使用Argus、bros-ids工具,開發了12種算法來生成總共49個帶有類標簽的特性.KDD CUP1999數據集用于1999年舉行的KDD CUP競賽采用的數據集,雖然年代久遠,但KDD99數據集是網絡異常檢測領域的基準.
3.2 實驗內容
將UNSW-NB 15數據集中的一個分區配置為訓練集和測試集,兩個子集都包含Web用戶正常行為數據集和Web用戶異常行為數據集.訓練集為UNSW_NB15_training-set.csv,記錄數為175 341條;測試集為UNSW_NB15_test-set.csv,記錄數為82 332條.通過將網絡流的標識符與相應的條件標簽相結合可以跟蹤Web用戶異常行為示例,條件標簽描述前面提到的將記錄分為“異常”或“正常”的分類技術的結果.
為了評估Web用戶異常行為檢測算法的優劣,本文采用混淆矩陣思想進行評價.混淆矩陣是模式識別領域中一種常用的表達形式,它描繪樣本數據的真實屬性與識別結果類型之間的關系,是評價分類器性能的一種常用方法[20].采用2.2中表1混淆矩陣的定義,創建兩個指標:準確率OSR和誤報率FAR,使用這兩個指標來評估分類器.
(12)
(13)
3.3 算法分類性能對比實驗
將F_C4.5算法、C4.5算法、樸素貝葉斯算法(NB)和關聯規則挖掘分類算法(Association rule mining method,ARM)分別用于Web用戶異常行為檢測中,基于四種不同的模型在UNSW-NB 15數據集訓練得到的數據結果如表2所示,用戶行為特征分類結果如表3和圖1所示.
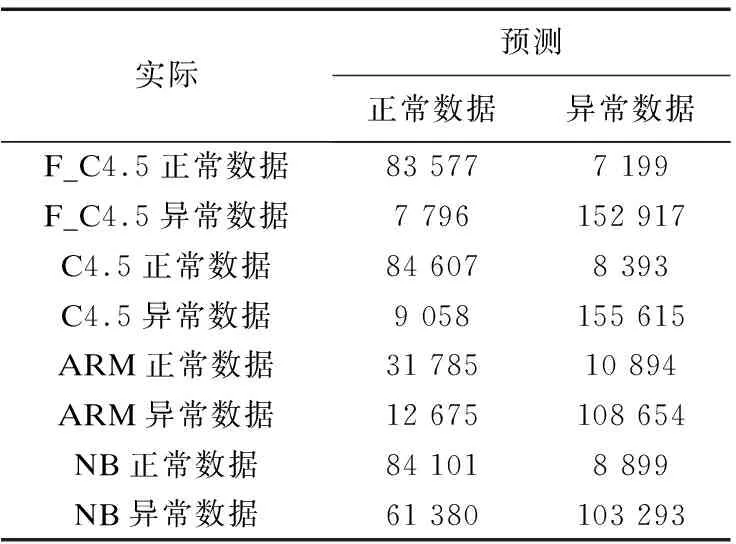
表2 混淆矩陣數據
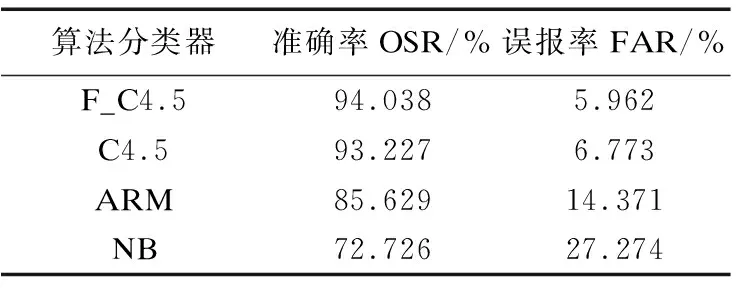
表3 算法分類器性能對比
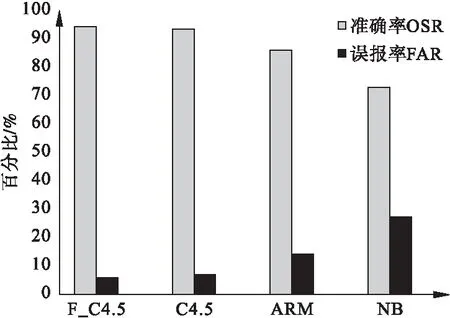
圖1 UNSW-NB 15數據集中評價指標的對比
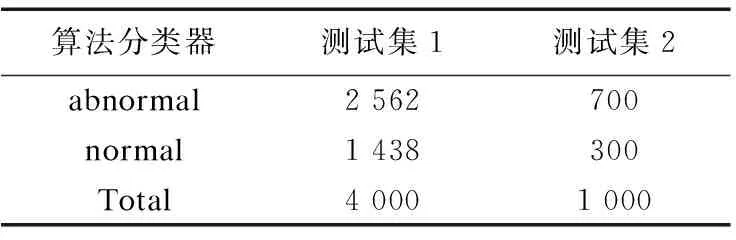
表4 測試數據集
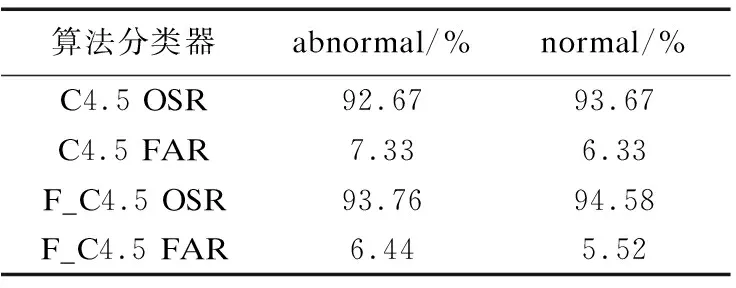
表5 算法預測性能對比
實驗結果對比可以看出,將決策樹算法用于Web用戶異常行為檢測中準確率提高并且誤報率得到了有效降低.與樸素貝葉斯算法(NB)和關聯規則挖掘分類算法(ARM)相比,決策樹C4.5算法的準確率達到93.227%,誤報率則是6.773%,較適用于Web用戶異常行為檢測.而本文的F_C4.5算法在C4.5決策樹算法基礎上先將數據集進行特征過濾,消除一部分無用數據后再進行決策樹模型構建,一方面充分利用了決策樹的優勢,用戶行為分類效果更優;另一方面數據集的精確度提高,構建決策樹的復雜度更低.如表3數據所示,準確率達到94.038%,誤報率降低到5.962%,從兩個評價指標來看,將F_C4.5算法用于Web用戶異常行為檢測達到了更好的效果.
3.4 預測新的Web用戶異常行為
為了進一步驗證本文算法的可靠性,使用KDD CUP1999入侵數據集中的測試數據集corrected.gz進行第二輪測試,實驗將測試集中的Web用戶異常特征分為U2R、DoS、PROBING、R2L,這四類在檢測中都歸為Web用戶異常行為檢測數據集.測試數據集如表4所示.
用測試集1和測試集2分別對構建好的C4.5模型和F_C4.5模型進行檢測.實驗結果顯示,F_C4.5算法的Web用戶異常行為檢測和Web用戶異常行為檢測的準確率都高于C4.5算法,誤報率低于C4.5算法,由表5的實驗數據進一步證明,F_C4.5算法的在Web用戶異常行為的檢測性能優于C4.5算法.
4 結束語
本文在Web用戶異常行為檢測過程中,綜合考慮了復雜度過高對特征提取的影響,將過濾特征選擇的思想和混淆矩陣的理念與C4.5決策樹算法結合提出一個新的算法F_C4.5算法.過濾特征選擇利用Relief-F算法,在選擇閾值上通過混淆矩陣的理念進行計算,得出優化特征子集的搜索范圍,從而降低決策樹構架過程中的復雜度.實驗表明在運行性能方面,F_C4.5算法有效降低原始特征集的維數,有效摒除了一部分無用數據,從而減少了訓練和測試時間的消耗,復雜度降低,對于Web用戶異常行為檢測來說該算法取得了很好的效果,具有更高的分類性能.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
