基于SVD 和ARIMA 的時空序列分解與預測
2021-03-18 08:03:12楊立寧李艷婷
計算機工程 2021年3期
關鍵詞:模型
楊立寧,李艷婷
(上海交通大學機械與動力工程學院,上海 200240)
0 概述
時空數據是指同時具有時間和空間維度的數據[1],傳感器、移動電話、射頻識別(RFID)和智能電網等智能設備的發展促進了實時時空數據流的采集。考慮一個時空隨機過程,時空建模的目標是基于時空數據構建時空模型以對給定時刻所有位置的行為進行預測[2]。若不考慮時間因素,可以采用單純的空間模型進行建模,如kriging 方法[3],但是其準確性較低,添加時間維度可以提高預測的準確性。隨著時空數據流采集難度的降低,時空序列建模逐漸成為學者們的研究熱點之一。
目前,關于時空序列預測主要分為基于物理模型、基于統計模型和基于機器學習的3 種方法。基于物理模型的方法首先對時空序列的機理進行研究,尋找其內在的系統動力學規律并構建系統動力學模型,然后對時空序列進行表達進而預測。其中,JONES 等人[4]提出隨機偏微分方程以描述連續型時空隨機過程。基于統計模型的方法主要分為描述型時空模型和動態時空模型兩類。前者利用統計學中的描述型統計量表達時空模型的性質,并對統計量進行建模以消除隨機誤差;后者考慮時間和空間的自相關性并利用過去和其他地區的數據對當前數據進行建模,然后實現迭代更新預測。近年來,隨著機器學習和深度學習的不斷發展,人工智能技術被廣泛應用于時空序列建模和預測任務。通過機器學習模型能夠提取時空序列中復雜的特征模式,也可以對高維時空序列進行降維和聚類從而使得分析更簡便。
本文提出一種分離時空數據中的時間模式和空間模式并分別建模的方法。對原始數據進行平穩性檢驗并中心化,利用奇異值分解(SVD)分解中心化的數據集,通過時間序列模型中經典的ARIMA 模型對時間模式建模并檢驗其有效性,然后利用ARIMA 模型預測時間序列,將預測結果與空間模式相結合并對真實時空序列進行重建,以得到各個地理觀測點的預測值。
1 相關工作
描述型時空模型較早以時空協方差為研究對象,通過對樣本協方差值進行曲面擬合獲得協方差函數,然后利用協方差函數分析時空模式的演變。時空kriging 方法[5-7]基于時空過程的協方差函數給出未知地區給定時刻的最優線性無偏估計。但是,由于時空協方差是一種描述型統計量,很難解釋時空模式的內在動態變化。描述型時空模型在數學上更通用,但是動態時空模型在科學上有更強的解釋性[8]。動態時空模型基于條件概率分布進行建模,其中最主要的動態時空模型為層次時空模型。層次時空模型可分為2 個主要類別:一類是經驗層次模型,其認為觀測到的時空過程是真實時空過程的演變以及真實過程通過某種函數作用產生觀測過程,其機制類似于隱馬爾可夫過程;另一類是貝葉斯層次模型,和經驗層次模型的主要區別在于,貝葉斯層次模型認為真實過程中的參數也是動態變化的,其在經驗層次模型的基礎上增加了底層的參數過程,因此,貝葉斯層次時空模型將時空序列過程分解為參數過程、真實過程和數據過程3 個層次并分別建模[8-10]。
無論經驗層次模型還是貝葉斯層次模型,真實過程都是最重要的,其對理解時空動態變化模式具有重要意義。因此,時空模型的一個研究重點在于真實過程的模型構建。統計時空模型的構建主要來源于時間模型和空間模型的結合。CLIFF 和ORD 較早將時間序列模型應用于空間分析中,提出空間自回歸模型(SAR)、空間移動平均模型(SMA)和空間回歸模型(SR)等[11]。MARTIN 和OEPPEN 將空間信息整合到傳統的ARIMA 模型[12]中,提出STARMA模型[12]。STARMA 定義了空間階次的概念并在真實應用中產生了良好效果[13-15]。但是,隨著時空數據的概念外延,STARMA 模型中關于歐式距離越小則空間階次越低的假設越來越難以滿足,使得其在一些未知空間相關性結構的數據集中表現較差。BESSA等人結合其他地區的歷史數據和待預測地區的數據,構建向量自回歸模型VAR[16]以對時空序列進行建模描述。但是,VAR 模型中的待估計參數空間較大,一方面需要消耗極大的計算資源,另一方面可能由于樣本量不足而引起過擬合問題。因此,基于Lasso 的VAR(Lasso-VAR)模型被廣泛應用[17],盡管Lasso-VAR 在一定程度上解決了模型過擬合問題,但是其優化模型變得更難求解,計算成本過高。
BAHADORI 等人[18]通過將時空數據作為張量進行處理,提出一種低秩張量學習框架以進行多元時空序列分析。BAROCIO 等人[19]通過動態模式分解的方式對時空數據進行降維并提取時空特征。LI[20]利用梯度提升回歸樹(Gradient Boosting Regression Tree,GBRT)算法對城市共享單車的時空數據進行建模并預測數量。在深度學習方法中,遞歸神經網絡(Recurrent Neutral Network,RNN)和深度神經網絡(Deep Neutral Network,DNN)被廣泛應用于時空序列模型構建任務。SHI[21]利用RNN 模型的一個變體,即長短時記憶(Long and Short Term Memory,LSTM)網絡對地區的降雨量進行預測。CHE 等人[22]將傳統的RNN 拓展到時空領域,提出時空遞歸神經網絡(Spatio-Temporal Recurrent Neural Network,ST-RNN),以對時空序列進行建模預測。類似地,在深度學習方面,ZHANG 等人[23]將深度殘差網絡拓展到時空領域,提出時空深度殘差模型(ST-ResNet)以對人流量進行預測。
2 算法描述
2.1 時空數據的奇異值分解
SVD 是一種矩陣分解技術,其在信號處理和統計學中有很多應用[24]。給定一個秩為l的時空數據矩陣YD×T,其中,D表示空間中觀測點的個數,T表示采樣時間點的個數。時空數據矩陣YD×T的奇異值分解如下:
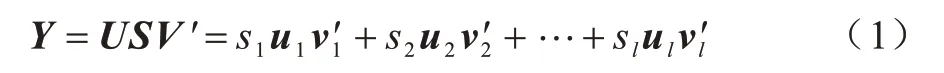
其中,U=(u1,u2,…,ul),V=(v1,v2,…,vl),S=diag{s1,s2,…,sl},且s1≥s2≥…≥sl?0。向量是左奇異矩陣的列向量,向量vi′(i=1,2,…,l)是右奇異矩陣的行向量,標量si稱為奇異值。
假設{cm:m=1,2,…,T}是矩陣YD×T的列向量,cm代表給定的m時刻D中所有空間單元的觀測值,YY′表達了D空間單元之間的相關性,這里假定YD×T已經去中心化為零均值矩陣。矩陣YD×T的ui事實上是相關矩陣YY′的特征向量,u1表示相關矩陣YY′對應特征值最大的特征向量,包含了空間相關性最多的信息量,或被稱為“空間模態”,表征了空間相關性的模式。ui的第j個分量uij表示第j地區對第i空間模態的“貢獻”。類似地,假定{r′n:n=1,2,…,D} 是矩陣YD×T的行向量,r′n代表n位置在整個時間段的觀測值向量,Y′Y表達了不同時刻之間的相關性,矩陣YD×T的vi′事實上是相關矩陣Y′Y的特征向量,r1表示相關矩陣Y′Y對應特征值最大的特征向量,包含了時間相關性最多的信息量,或被稱為“時間模態”,表征了時間相關性的模式。r′i的第j個分量r′ij表示第j時刻對第i時間模態的“貢獻”。時空矩陣YD×T分解后的S是奇異值矩陣,si表示模式i的重要程度,例如,若s1是最大的奇異值,則s1對應的模式1 具有表征空間模式的最重要的特征。
2.2 基于SVD 的時空序列模型
給定歷史時空數據矩陣YD×(t-1),對當前時刻t的各個地理觀測點進行預測的具體步驟如下:
步驟1通過SVD 對中心化后的時空矩陣進行分解。
假定歷史時空數據矩陣YD×(t-1)的秩為l,可利用式(1)得到如下分解:

SVD 有一個重要的性質,定義奇異值占比Er=,則當r<<l時,Er可達到85%以上的水平,剩余的可認為是噪聲。因此,通過選取前幾個奇異值與對應的左奇異向量和右奇異向量進行重建,可以對矩陣實現降噪,如下:

步驟2通過ARIMA[25]對時間模式進行建模預測。
由于分解之后得到的右奇異向量vi′可以看作時間序列,因此本文利用時間序列中應用最廣泛、效果最好的ARIMA 模型進行建模。ARIMA 的標準模型如下:

其中,?dvi,t代表t時刻第i個向量的d階差分,εt是t時刻均值為0 的隨機誤差,μ、φi(i=1,2,…,p)、θi(i=1,2,…,q)為待估計參數。利用AIC、BIC 信息準則和最大似然法進行模型選擇和估計,當得到估計好的模型后,利用該模型進行h步向前預測,如下:

步驟3利用SVD 進行重建得到h步向前預測結果。
當得到時間模式的估計值后,利用已經存儲的奇異值和對應的左奇異向量重建時空矩陣,得到最終預測結果:

2.3 模型優化
模型優化包括奇異值選擇和ARIMA 模型參數選擇過程。針對奇異值選擇,不同的奇異值個數重建的矩陣精度不同,通常情況下,利用前幾個較大奇異值即可基本重構原始時空矩陣,剩余奇異值可理解為由數據波動形成的噪音。本文通過遍歷的方式驗證了不同的奇異值個數對最后效果的影響,最終設定對前2 個奇異值對應的時間模式進行建模。針對時間模式ARIMA 模型的構建,首先需要對時間模式的平穩性進行檢驗,若不平穩,需要將其轉化為平穩模式并在后續模型中逆推回真實預測結果;當數據平穩性檢驗通過后,利用ARIMA 模型對平穩時間模式進行建模,并利用ACF 和PACF 圖[25]確定ARIMA 模型中的p、d和q參數取值;最后通過交叉驗證以及信息準則AIC、BIC[26]對模型有效性進行檢驗并選擇最優模型,在檢驗通過后,利用得到的ARIMA 模型完成預測。本文所提STSVD 算法描述如算法1 所示,算法流程如圖1 所示。
算法1ST-SVD 算法

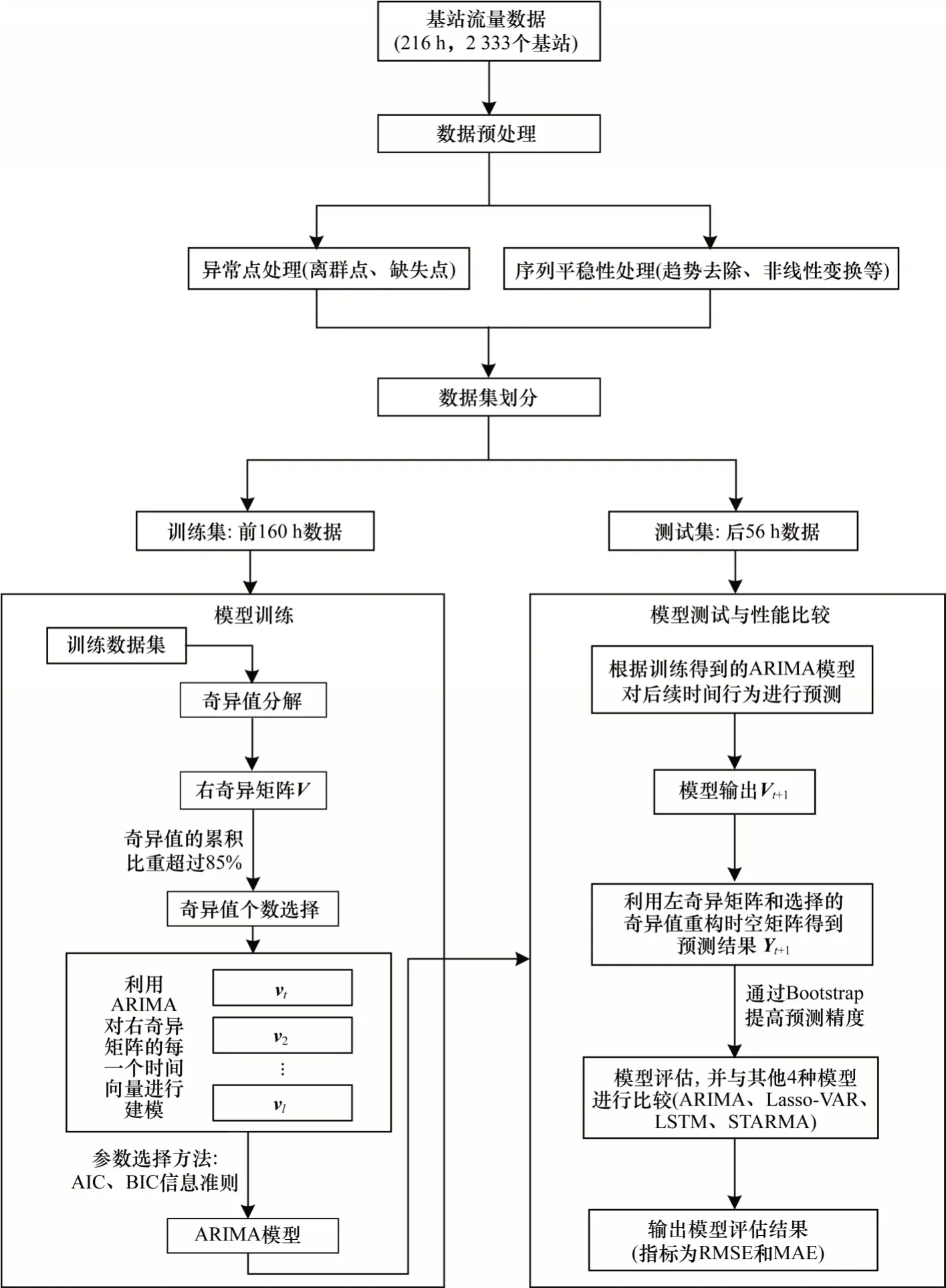
圖1 ST-SVD 算法流程Fig.1 Procedure of the ST-SVD algorithm
3 案例分析
3.1 數據集描述
本文利用中國某大型城市的2 333 個基站在216 h(共9 天)內的流量數據對所提ST-SVD 算法進行驗證,數據的采集頻率為1 次/h。圖2 所示為2 333 個基站的相對位置布局,經緯度已經過處理,表1 所示為其中5 個基站在13 h 內的流量數據示例。圖3 所示為3 個基站在216 h 內的流量變化情況,從圖3 可以看出,基站3 具有較明顯的9 個峰,表明基站流量的變化基本以一天為周期,雖然另外2 個基站中基站1 也存在較類似的峰值,但是兩者的整體變化有較大差異。本文將216 h 內的流量數據拆分成訓練集和測試集,訓練集包含前160 h 的數據,測試集包含剩余56 h 的數據。

圖2 2 333 個基站的布局Fig.2 Layout of 2 333 base stations
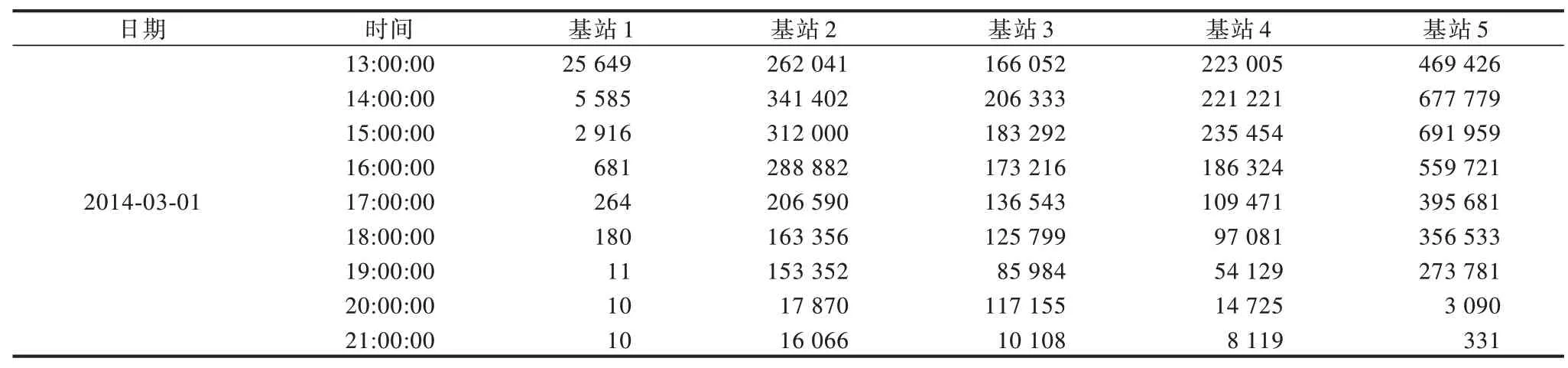
表1 5 個基站的部分歷史流量數據片段Table 1 Partial historical traffic data fragments of five base stationsKb
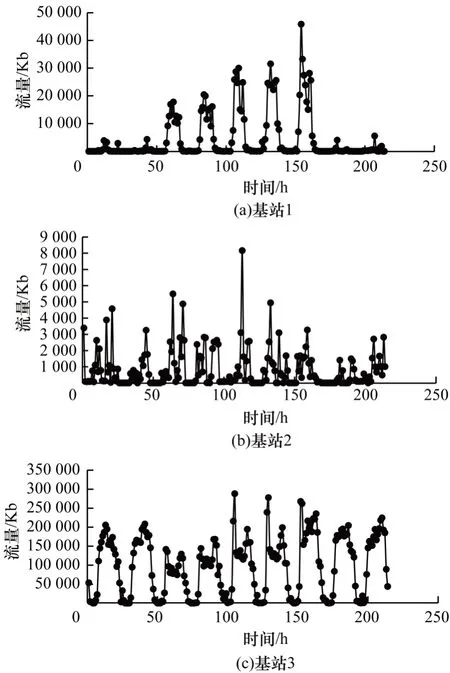
圖3 3 個基站在9 天內的流量情況Fig.3 Traffic situation of three base stations in nine days
3.2 ST-SVD 模型構建
ST-SVD 模型構建步驟如下:
步驟1通過奇異值分解對中心化后的時空矩陣進行分解。在本案例中,時空矩陣Y的大小是2 333×160,在進行數據預處理(異常值處理、平穩性處理)之后,通過對處理后的Y進行奇異值分解,得到左奇異矩陣、右奇異矩陣和奇異值。圖4 所示為截取的時空矩陣Y的右奇異矩陣,即時空序列的時間模式,此處截取了一天內每個小時之間的相關性情況,黃色區域表明相關性較強(彩色效果見《計算機工程》官網HTML 版),從圖4 可以看出,時間相關性具有較明顯的周期模式,并且可預測性較強。圖5所示為時空矩陣Y中不同地點的皮爾遜相關系數與距離之間的關系,從圖5 可以看出,針對該區域基站流量的時空數據,距離越近相關性越大的假設并不成立。

圖4 時間相關性矩陣Fig.4 Time correlation matrix
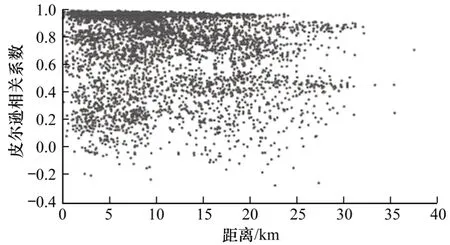
圖5 相關性與空間距離的散點圖Fig.5 Scatter plot of correlation and spatial distance
圖6 所示為排序后的奇異值,一般而言,前幾個奇異值即可涵蓋大部分信息。從圖6 可以看出,前2 個奇異值占據了奇異值之和的89%,因此,本文分別構建一個奇異值的重建算法ST-SVD(1)和兩個奇異值的重建算法ST-SVD(2)。

圖6 降序排列的奇異值Fig.6 Singular values of descending order
圖7、圖8 分別對應前2 個奇異值的左奇異矩陣(空間模式)和右奇異矩陣(時間模式)。從中可以看出,空間模式較為復雜,沒有明顯規律,但是時間模式顯示出明顯的周期性和可預測性。因此,本文利用ARIMA 模型分別對2 個時間序列進行建模并預測。

圖7 左奇異矩陣Fig.7 Left singular matrix

圖8 右奇異矩陣Fig.8 Right singular matrix
步驟2通過AIC 和BIC 信息準則(表2)選擇ARIMA 模型中的p、q、d參數并得到下述結果:

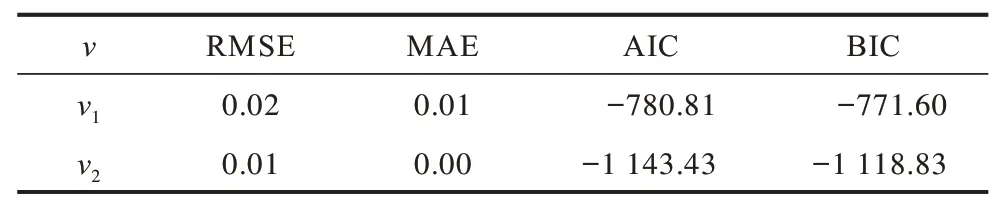
表2 模型擬合程度指標Table 2 Index of model fitting degree
RMSE 和MAE[27]的計算公式分別如下:
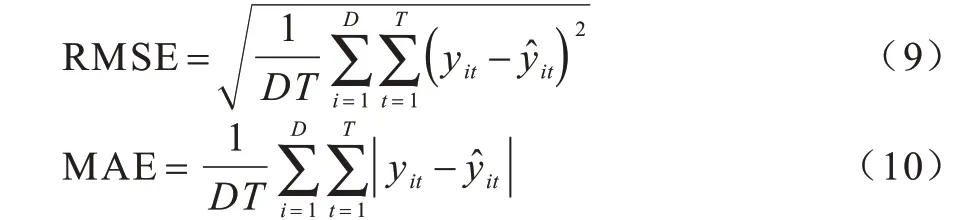
步驟3利用奇異值分解進行重建得到h步向前預測結果。在得到t時刻時間模式的預測值v1,t和v2,t后,即可利用式(1)結合左奇異矩陣和奇異值重建時空矩陣,得到t時刻空間各個位置的預測值。考慮到流量的周期性一般為一天,因此,本文利用ARIMA 模型分別向前1 步、向前6 步、向前12 步和向前24 步進行預測,并利用Bootstrap[28]從2 333 個基站中抽取不同的樣本量,從100 次實驗中取均值作為最終結果,以評估算法在整個周期內不同預測長度下的準確度和預測性能。
3.3 模型性能比較
本文將ST-SVD(1)、ST-SVD(2)與現有常用的ARIMA、Lasso-VAR、LSTM 和STARMA 4 種模型進行對比。其中,ARIMA 模型并不是時空序列模型,但是在不考慮空間觀測點的相關性時時空序列變成獨立的多個時間序列,可以分別利用ARIMA 進行建模預測。ARIMA 模型時間成本極高,但是可作為一種基線模型進行對比。Lasso-VAR 是帶有Lasso 正則化約束的VAR 模型,其認為時空模型是時間序列模型加空間維度,即增加一維,然后通過傳統的VAR模型并添加Lasso 正則化來降低過擬合風險。LSTM是遞歸神經網絡的變體,適用于時間序列,其與VAR類似,將時空數據集的空間維度疊加到時間序列中進行訓練預測。STARMA 模型是經典的時空分析模型,本文采用歐氏距離定義模型中的空間權重矩陣。實驗過程中使用的軟件、軟件依賴包信息以及模型關鍵參數如表3 所示。

表3 實驗過程中的軟件、軟件依賴包以及模型關鍵參數信息Table 3 The software,software dependency packages and key parameters information of the model during the experiment
利用10 個、20 個、50 個和100 個基站160 h 內的數據分別對上述6 種模型進行訓練,并給出向前1 步、6 步、12 步和24 步的預測結果,利用常見的預測精度指標——均方根誤差RMSE 和絕對值誤差MAE 對預測性能進行評估。由于本文案例中共有2 333 個基站,為了提高性能評估的準確性并降低方差,通過Bootstrap 在2 333 個基站中隨機選取上述10 個、20 個、50 個和100 個基站100 次,并對100 次的實驗結果取平均值以作為最終的性能評估結果。
表4 所示為上述6 種模型向前1 步的部分預測結果,加粗數字為最優預測結果,括號中的百分數表示預測百分比誤差,計算公式如式(11)所示表示預測值,y表示真實值。

從表4 可以看出:LSTM 模型的預測精度最差,原因是其數據量過少,模型欠擬合,這表明神經網絡模型需要足夠多的樣本來提高精度;STARMA 模型優于不添加空間信息的ARIMA 模型;ST-SVD 的2 種模型相較于其他4 種模型預測準確率更優。具體地,利用2 個奇異值的ST-SVD(2)模型的預測誤差約為0.13,ARIMA、Lasso-VAR、LSTM 和STARMA 的誤差分別約為0.22、0.21、0.92 和0.19。ST-SVD(1)和ST-SVD(2)明顯優于其他4 種對比模型且ST-SVD(2)優于STSVD(1)。

表4 6 種模型的1 步預測結果Table 4 One-step prediction results of six models
表5 所示為上述6 種模型在4 種不同基站個數以及4種不同預測步長情況下的RMSE,括號中為MAE。從表5可以看出,ST-SVD模型的性能明顯優于其余4種對比模型,而且ST-SVD(2)的重構結果稍優于ST-SVD(1)的重構結果。從圖9、圖10可以直觀地看出,2種ST-SVD模型的誤差低于其余4 種對比模型。
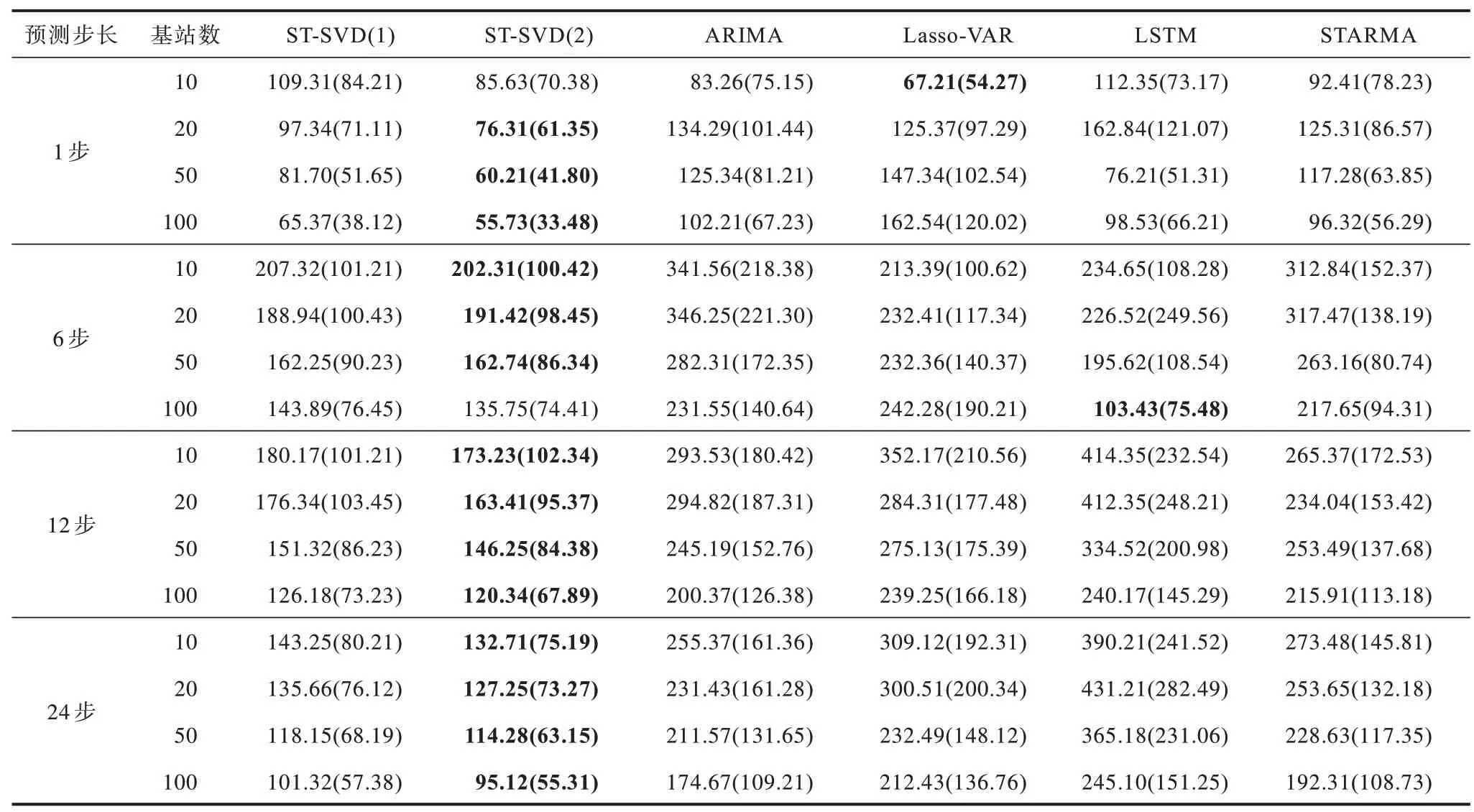
表5 6 種模型在不同基站個數與預測步長情況下的實驗結果Table 5 Experimental results of six models under different number of base stations and different prediction step size

圖9 6 種模型在不同基站個數與預測步長下的RMSEFig.9 RMSE of six models under different number of base stations and different prediction step size
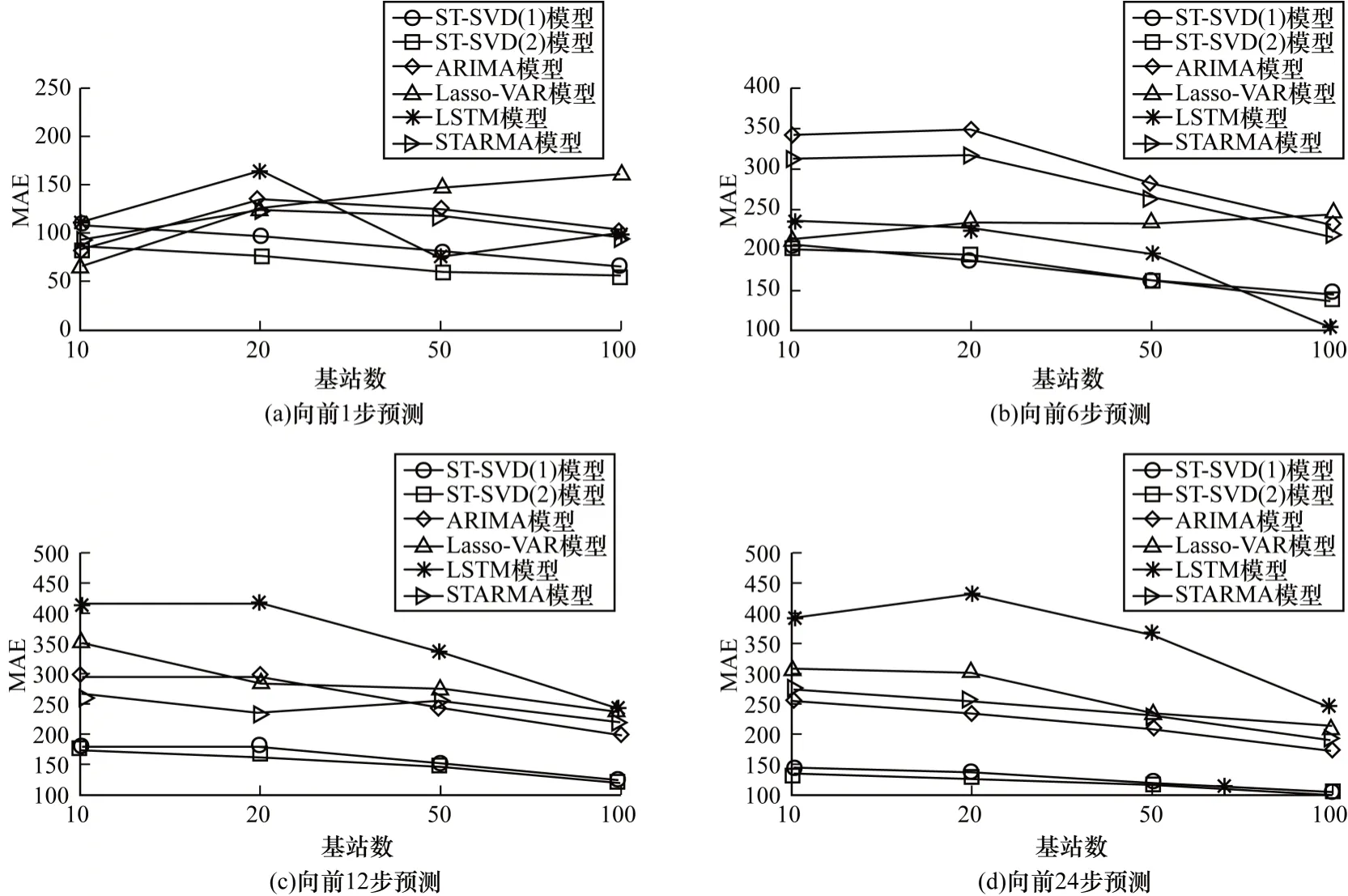
圖10 6 種模型在不同基站個數與預測步長情況下的MAEFig.10 MAE of six models under different number of base stations and different prediction step size
4 結束語
時空序列模型STARMA 通過構建空間權重矩陣來表征數據的空間相關模式,但是空間權重的構建大多依賴距離等主觀性因素,導致STARMA 難以適用于多數數據集。本文建立一種新的時空序列模型ST-SVD,其利用SVD 技術對時空數據集的時間模式和空間模式進行自動分解,通過ARIMA 模型擬合時間模式并建模預測,最終重建出時空預測結果。ST-SVD 模型不需要對數據集的空間結構進行假設,只需對時間序列實現建模,大幅降低了問題復雜度和模型訓練成本。實驗結果表明,ST-SVD 模型的預測效果優于LSTM、STARMA 等時空序列模型。但是,本文研究尚存在一定不足,一是ST-SVD 認為空間模式是時不變的,即空間作用和時間作用相互獨立,二是在奇異值分解后的時間序列建模中利用了較為傳統的ARIMA 模型,該模型是一種線性模型,無法捕捉到時間序列中的非線性模式。下一步將利用機器學習、深度學習等技術對時間模式進行建模,然后通過奇異值分解重建時空序列,以解決上述問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
