融合馬爾科夫決策過程與信息熵的對話策略
2021-03-18 08:04:12朱映波趙陽洋王振宇
計算機工程 2021年3期
朱映波,趙陽洋,王 佩,尹 凱,王振宇
(1.天翼愛音樂文化科技有限公司,廣州 510081;2.華南理工大學軟件學院,廣州 510006)
0 概述
隨著人工智能相關技術的飛速發展,人與智能設備之間的交互方式趨于智能化,逐漸從傳統的圖形化交互向人機對話交互轉變[1-3],即利用智能助理來幫助用戶完成多項任務或多項服務。任務型人機對話作為人機對話系統的重要分支之一,是人工智能領域中的一個熱門研究課題[4-5],同時被逐漸應用于工業界的各個方面,例如蘋果手機助手Siri[6]、亞馬遜Alex 和阿里智能客服小蜜等。
任務型對話系統又稱為目標驅動型對話系統,例如客服機器人、機票預訂系統等[1,7-9],它們為用戶提供特定領域的服務,旨在幫助用戶完成購物、訂機票等任務。這類人機對話系統能夠大幅降低人力成本,簡化人機交互過程,提高應用的智能程度,具有較高的研究和應用價值[10]。
任務型對話系統由自動語音識別(Automatic Speech Recognition,ASR)、自然語言理解(Natural Language Understanding,NLU)、對話管理(Dialogue Management,DM)、自然語言生成(Natural Language Generation,NLG)和語音合成(Text-To-Speech,TTS)5個模塊組成[4,11]。其中:ASR 模塊將用戶的語音輸入轉化為文本的形式;NLU 模塊的作用是理解用戶的對話文本,并提取出與任務相關的槽-值對信息;DM 模塊是對話系統的核心控制模塊,包括對話狀態跟蹤(Dialogue State Tracking,DST)和對話策略(Dialogue Policy,DP)兩個部分[11]:DST 接收來自NLU 模塊的語義信息,更新當前的對話狀態,DP 確定下一步系統的響應策略;NLG 模塊根據系統響應策略生成自然語言文本;TTS模塊將語言文本轉為語音反饋給用戶。
對話策略任務根據對話狀態跟蹤輸出的當前狀態分布,選擇系統響應的動作或策略[12-13],其性能的優劣決定了人機對話系統的成敗。因此,設計一個魯棒的對話策略模型是任務型系統成功應用的關鍵。然而,通過現有的深度學習的方法訓練一個高質量的對話策略需要大量的會話數據,且只能應用于已經有大型數據集的場景[14-15]。由于對話系統的潛在應用領域非常廣泛,因此在現實場景中存在較多的對話數據稀缺性問題[16]。
本文構建一個融合馬爾科夫決策過程和屬性信息熵的對話策略模型。將對話策略視為一個馬爾科夫決策過程,通過建立
1 相關工作
目前主流的對話策略模型可分為基于有限狀態自動機的對話策略、填槽或填表法和基于概率模型的對話策略。其中,基于概率的模型能通過回報函數的迭代計算、訓練狀態和動作之間的映射關系,得到可用的對話策略規則,這種方法由于避免了依賴人工制定規則帶來的局限性,并且能夠通過訓練提升模型的泛化能力,因此具有更好的效果。
1)基于有限狀態自動機的對話策略
任務型多輪對話系統通過與用戶進行多輪的對答,明確用戶的需求,得到完成任務需要的信息,這個與用戶進行多輪交互的過程類似于“初始狀態→動作→更新狀態→動作→更新狀態→…→終止狀態”的狀態與觸發動作進行交替的過程,與圖模型中的有限狀態自動機(Finite-State Machine,FSM)的定義非常吻合。有限狀態自動機用來描述對象在一個生命周期內的狀態序列以及狀態間進行轉移的動作事件,可以通過狀態轉移圖來進行描述,圖1 描述了在訂餐任務中有限狀態自動機的狀態轉移圖示例。
在圖1 中,節點表示系統執行的對話動作,節點之間的邊表示用戶執行的實際動作。在對話過程中,系統通過將用戶的輸入進行解析,得到相應的轉移方向,使得對話沿著狀態轉移圖的設定進行,對話中用戶與系統每交互一次,狀態就發生一次轉移,直到對話結束。基于FSM 的對話策略方法是典型的系統主導型方法,對話的節奏完全由系統決定,用戶需要按照系統指定的流程補充信息。這種方法通過預先人為地定義好對話流程,具有建模簡單且邏輯清晰的優勢,對簡單任務的信息獲取很友好。對于稍復雜的任務,如果對話過程中出現了系統沒有預先定義好的狀態,那么對話將會卡在其中的一個狀態中無法繼續進行。基于有限狀態自動機的對話策略需要對對話中的細節提前進行編寫和維護,缺少靈活性,因此在開發的過程中也很難對其進行擴展。

圖1 基于有限狀態自動機的對話策略狀態轉移圖Fig.1 State transition diagram of dialog policy based on finite state automata
2)基于填槽的對話策略
基于填槽的對話策略在一定程度上改進了基于FSM 的方法,它將對話建模成一個填槽的過程,其中,槽表示在對話過程中完成特定的任務所需要獲取的信息屬性。系統通過制定填槽的優先級,根據當前的槽位狀態來決定下一個系統動作。與基于FSM 的方法相比,填槽法不對獲取用戶信息的順序進行限制,用戶可以在對話過程中一次性補全一個或多個槽信息。經過系統的引導,用戶進行輸入,系統將用戶輸入轉化為一個或多個槽信息的填充,這種方法為用戶提供了相對靈活的輸入方式,支持用戶和系統混合主導的系統,適用于相對復雜的信息獲取場景。但這種填槽的對話策略方法由于槽位的限制,當槽的數量過多時,算法的復雜程度也會急劇增長,因此不適用于更復雜的場景。
3)基于強化學習的對話策略
基于有限狀態自動機和基于填槽的對話策略算法都需要人工制定規則,這種預先定義好所有場景的方法,不具備領域遷移的能力,當任務發生變化時,就需要重新制定規則。馬爾科夫決策過程(MDP)是一個解決序列決策的模型,文獻[17]將對話決策建模成一個馬爾科夫決策過程,通過模擬系統與用戶之間的交互過程,經過訓練優化模型參數,得到狀態和動作之間的映射關系(即對話策略)。在任務型對話系統中,通過將槽的取值狀態映射為對話的狀態,同時定義系統的動作、執行動作的回報函數和狀態與狀態間的轉移概率,這種方法相比于人工定義對話規則的方法擁有更高的覆蓋率。與需要大量標注數據的監督學習不同,強化學習可以通過構建智能體感知環境,然后由系統與用戶進行交互,根據回報函數獎勵好的行為、懲罰壞的行為,從而訓練出對話系統的最優策略。
對于槽數量較多的復雜場景,基于強化學習的模型也有較好的擴展方式。面對過多的狀態或動作空間,在傳統強化學習很難進行高效探索時,深度強化學習能夠大幅提升模型的收斂速度。同時,也出現了很多傳統強化學習模型的變種,如文獻[18-19]將卷積神經網絡(Convolutional Neural Networks,CNN)與傳統強化學習中的Q 學習[11]算法相結合,提出了深度Q 網絡(Deep Q-Network,DQN)模型。
目前關于策略學習的相關研究在任務型對話系統中的比重相對較小,遠少于自然語言理解和對話狀態跟蹤任務,仍然存在許多需要深入研究和解決的問題,如系統冷啟動、管道型對話系統模塊間誤差傳遞和復雜場景中狀態空間指數增加等,許多學者在對話策略學習的問題上進行了新的探索。
2 基于馬爾可夫決策過程與信息熵的對話策略
2.1 馬爾科夫決策過程模型構建
對話管理中的對話策略選擇問題可以抽象為一個馬爾科夫決策過程(MDP)[20-21]。馬爾科夫決策過程由五元組<S,A,P,R,γ>來定義,5 個元素分別表示狀態集合、動作集合、狀態間的轉移概率、及時回報和衰減因子。
1)狀態集合S
在音樂搜索任務中,對話狀態體現為6 個槽的取值情況,每個槽的狀態分為已填充和未填充兩種,將狀態跟蹤模塊輸出的對話狀態轉換為編號表示,則總共有26=64 種狀態,按照下標01 依次編碼,六位01 編碼依次表示“song,singer,album,lyricwriter,composer,label”槽的填充與否,狀態數量和對應的狀態編號如表1所示。例如,當前的對話狀態為<singer=周杰倫,song=稻香>,則所對應的狀態編碼應為S110000。那么,狀態集合S={S000000,S100000,…,S111111}。

表1 對話狀態的編號表示Table 1 Numbered representation of dialog state
終止狀態表示對話的結束,若達到了終止狀態,則表示系統應給出歌曲列表offer()結束對話。從經驗常識出發,本文制定如下規則來定義對話的終止狀態:
(1)當用戶給出歌曲的歌名song 信息和任一其他屬性信息,則該狀態為終止狀態,共5 種。
(2)當用戶給出歌曲的專輯名album 和作詞者lyricwriter 或作曲者composer,則該狀態為終止狀態,共2 種。
(3)6 個屬性中已知任意3 個或3 個以上,則該狀態為終止狀態,共20+15+6+1=42 種。
因此,定義42 種終止狀態,如表2 所示。

表2 對話終止狀態說明Table 2 Description of dialogue final states
2)動作集合A
系統動作分為詢問動作request()和提供歌曲列表動作offer(),詢問動作又可以根據詢問不同的槽分為詢問歌曲名request(song)、詢問歌手request(singer)、詢問專輯request(album)、詢問作詞者request(lyricwriter)、詢問作曲者request(composer)和詢問歌曲類型request(label)6 個動作。因此,動作集合A={offer(songs),request(attrs)},其中,attrs=[song,singer,album,lyricwriter,composer,label]。
3)狀態間的轉移概率P
定義狀態(s,s')之間的轉移概率為s'可能的取值個數,當前狀態s為非終止狀態。用戶在單輪的對話中,可能會給出不止一個槽的信息,因此,按照表3 定義對話狀態之間的轉移概率。

表3 對話狀態轉移概率示例Table 3 Example of dialogue state transition probability
4)及時回報R
定義當對話狀態達到設定的49 種終止狀態時,意味著用戶完成了當前的任務,轉移后的獎勵值設為100,其他每一輪對話狀態發生轉移的獎勵值均為-1,如表4 所示。

表4 對話狀態轉移獎勵矩陣示例Table 4 Example of dialogue state transition reward matrix
5)衰減因子γ
衰減因子代表了未來收益對當前狀態的重要程度,γ∈[0,1],本文設定衰減因子γ=0.8。
馬爾科夫獎勵過程中狀態值函數的貝爾曼方程表示為:

使用值迭代的方式對狀態值函數進行求解,得到收斂之后的狀態值函數矩陣v。
2.2 屬性信息熵計算
熵在信息論中表示信息量的大小,用來描述信源的不確定程度,不確定性越大,信息量越大,熵越大;反之,不確定性越小,信息量越小,熵越小。在基于多輪對話的音樂搜索任務中,每一輪對話后系統依據用戶提供的目標約束搜索曲庫,得到歌曲列表。不同屬性槽取值的不確定程度不同,因此帶有的信息量也不同。本文設計一種計算曲庫搜索結果歌曲列表中各個屬性信息熵的算法,根據屬性信息熵的大小來衡量哪一個屬性槽值的信息量最大,進而指導系統下一輪對話應引導用戶給出信息熵最大的屬性取值,以能夠用最少的對話輪次完成音樂搜索任務。屬性信息熵的計算公式如下:
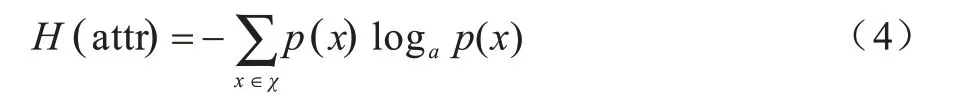
其中,χ表示屬性attr 可能的取值集合。
首先依據每一輪次用戶目標約束進行曲庫搜索,得到音樂列表,判斷搜索結果數量是否小于等于N,若小于等于N,則系統直接給出音樂結果offer(songs);若大于N,則系統計算結果列表中各個屬性槽的信息熵,選擇信息熵最大的屬性進行詢問。計算過程如式(5)所示:
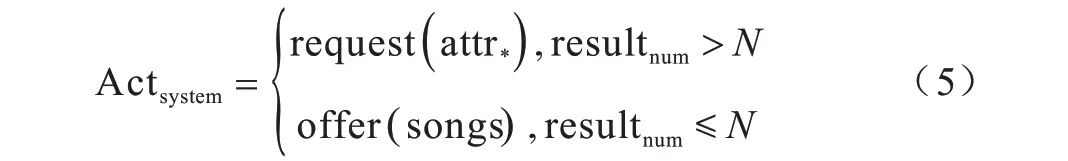
其中,attr*表示信息熵值最大的屬性槽。
2.3 融合算法
強化學習的方法通過定義五元組將當前時刻之后的狀態獎勵考慮進來,使得對話中系統的決策具有前瞻性(考慮后序狀態獎勵),能夠快速選擇最快抵達終止狀態的最優路徑,不需花費太多時間,且不同狀態的獎勵值可通過自定義的方式進行設定,但該方法所得的狀態之間的狀態值函數可能相等,所選擇的路徑可能是次優解;而基于屬性信息熵計算策略的計算方法考慮了音樂搜索結果列表,通過當前對話狀態得到對應的目標約束,進行曲庫搜索,然后計算音樂屬性槽的信息熵,求得考慮了當前輪次音樂搜索結果的對話決策。由于基于屬性的方法需要根據檢索列表進行曲庫搜索,數據集的屬性種類越多,響應時間越久。兩種方法都有自己的特點和優勢,因此本文提出基于貝爾曼方程求解的強化學習和屬性信息熵相結合的對話策略算法,融合兩種算法的優點,利用基于貝爾曼方程求解的強化學習算法幫助基于屬性信息熵的策略計算方法篩選檢索列表以縮短響應時間,利用基于屬性信息熵的策略方法幫助基于貝爾曼方程求解的強化學習算法排除次優解。本文根據基于貝爾曼方程求解的強化學習和屬性信息熵相結合的對話策略算法對對話策略模塊進行建模,算法的流程如圖2 所示。
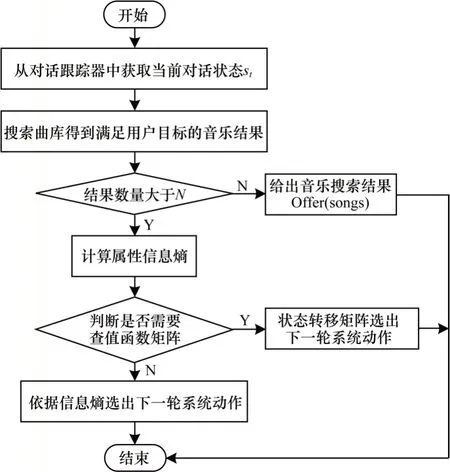
圖2 融合強化學習與屬性信息熵的對話策略流程Fig.2 Procedure of dialogue strategy combining reinforcement learning and attribute information entropy
融合算法步驟如下:
步驟1根據當前的對話狀態得到用戶的目標約束,通過目標約束搜索音樂曲庫得出歌曲結果列表。
步驟2判斷歌曲列表的數量resultnum,若resultnum>N,則計算屬性信息熵,若resultnum≤N,則給出音樂搜索結果,即Actsystem=offer(songs)。
步驟3計算屬性信息熵,判斷是否需要查詢狀態值函數矩陣v,若是,則通過狀態轉移矩陣選出下一輪的系統動作,否則依據信息熵選出下一輪系統動作。
步驟3 判斷是否需要查詢狀態值函數矩陣的具體邏輯如下:若信息熵大于0 的屬性數量為1,說明只有一個屬性attr△是有信息量的,因此系統直接依據信息熵給出下一輪的動作request(attr△);若信息熵大于0 的屬性數量大于1,則查詢計算出來的狀態值函數矩陣v選出下一輪的系統動作。
通過狀態值函數矩陣v計算下一輪系統動作的算法步驟如下:
步驟1查找狀態轉移矩陣P中對應當前狀態為s的列向量Ps,將狀態s的轉移概率向量Ps轉化為01 向量Ts(轉移概率>0 節點的值取1),使用Ts對狀態值函數矩陣v進行過濾,得到可能轉移的下一個向量s'和對應的狀態值。
步驟2下一個狀態s'使得v*=v(s')最大,將s與s'進行對比,找出s為0、s'為1 的槽位。若有多個槽位上的值不相同,則一一組合得出新的s',并過濾掉信息熵為0 的槽位,然后進行狀態值大小的比較,例如當前狀態s=S000000,查找到狀態值最大的下一狀態s′=S110000,得到第0 位和第1 位上的值不同,且信息熵都大于0,于是組合出新的s′={S100000,S010000},對比v(S100000)和v(S010000)的大小,得知v(S100000)>v(S010000),因此s′=S100000,下一輪的系統動作應為詢問第一個槽位song,即Actsystem=request(song);若v(S100000)=v(S010000),則以信息熵的大小來選取系統動作應詢問的槽位。
3 實驗
3.1 實驗設置
本文實驗的背景是基于多輪對話的音樂搜索任務,即用戶通過與音樂搜索系統進行多輪次的對話從而完成音樂的查詢。系統通過生成一個音樂查詢問題相關的目標,然后希望能夠經過盡量少的對話輪次搜索到目標歌曲。這個音樂搜索場景任務中共包含6 個槽,用于限定對話系統在數據庫中的查詢范圍,分別為歌曲名song、歌手singer、專輯album、作詞者lyricwriter、作曲者composer、歌曲標簽label。曲庫中包含618 319 首歌曲,而不同的槽有不同的取值空間,真實情況下的曲庫槽位情況如表5 所示。
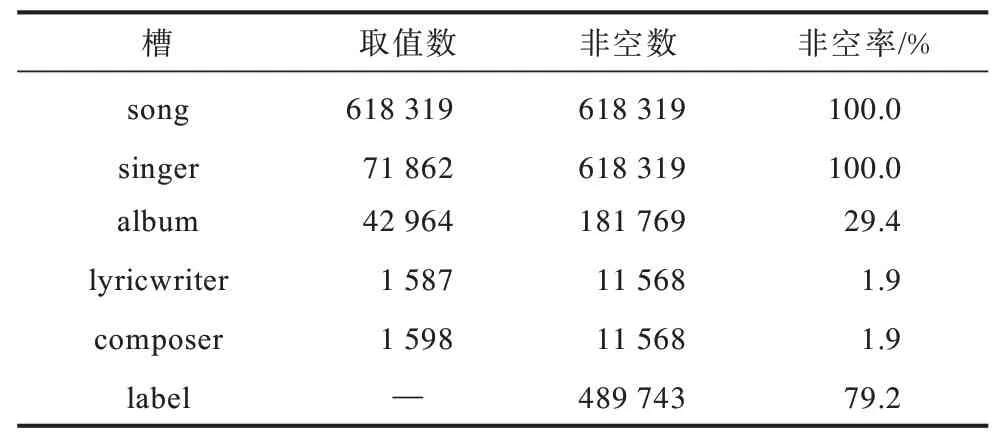
表5 曲庫中各個屬性的情況描述Table 5 Situation description of each attribute in the music database
系統隨機生成1 000 首目標歌曲,并將它們對應的6 個槽取值作為對話中的用戶目標。通過搭建系統-用戶交互模擬器,構建對話策略的測試環境。首先由模擬器隨機初始化用戶對話狀態,然后通過對話策略模塊給出系統的應答策略,模擬器根據給定的用戶目標和每一輪次填充指定的槽信息,從而模擬系統-用戶對話。
由于展示界面的大小限制,在一個頁面中只能為用戶展示滿足用戶目標約束的一定數量的歌曲列表,通常為10 首~20 首歌曲,表示為N。因此,系統根據搜索結果的歌曲數量,來確定下一輪的動作為繼續詢問request()還是給出歌曲列表offer(),可以通過式(6)進行描述:

為證明本文提出的融合強化學習和屬性信息熵的對話策略方法的有效性,實驗給出了融合算法與3 種對話策略算法的結果比較,分別是隨機選取系統詢問目標、基于填槽法的對話策略和基于信息熵的對話策略,3 種對比算法的具體描述如下:
1)隨機選取系統詢問目標
系統在未知槽中隨機選取下一輪詢問的槽信息,向用戶進行提問。
2)基于填槽法的對話策略
填槽法通過人工制定槽屬性優先級規則制定對話策略。用戶所知道的歌曲信息一般為大眾化屬性信息,例如歌曲名song、歌手singer 或專輯album,對于歌曲的作詞者lyricwriter、作曲者composer 和歌曲類型label 等屬性信息,用戶通常不能準確說出。基于此,在系統動作為繼續詢問request()時,通過為不同的槽制定不同的優先級,來制定系統的應答策略規則。各個音樂屬性的優先級順序為:song >sin ger >album >lyricwriter >composer >label。
填槽法將對話過程看作是填槽的過程,系統按照屬性優先級的順序向用戶進行發問,依次填充音樂的屬性槽,直至屬性信息能夠被全部填充或者按照約束查詢曲庫得到的搜索結果數量小于設定的N,則代表實現對話目標。
3)基于信息熵的對話策略
通過將每一輪已知槽信息轉化為知識庫查詢語句,得到歌曲的搜索結果,計算搜索結果中各個屬性的信息熵,選取信息熵最大的槽作為系統下一輪詢問的槽。
3.2 評價標準
在評價任務型對話系統中,對話策略模塊的有效性方法通常是從任務完成率和任務完成的智能程度的角度出發,因此本文指定的評價標準主要從兩個方面來衡量對話策略的有效性和智能性,一是查詢目標歌曲的成功率,二是完成任務所需的對話輪次。查詢目標歌曲的成功率通過對話結束時給出的歌曲搜索列表來計算,若目標歌曲在搜索列表的TopN中,則記為一次成功的查詢,實驗中設定N=10,任務完成的成功率計算公式如下:
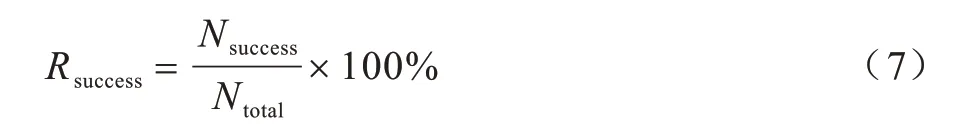
歌曲查詢任務完成的成功率越高,說明策略模塊的有效性也越高。
同時記錄完成歌曲查詢任務所需要的對話輪次Numturn,認為所需的對話輪次越少,對話策略的機制效率越高。
3.3 衰減因子γ 取值
本文設定衰減因子γ分別取值為0.0、0.2、0.5、0.8、1.0,并在音樂曲庫數據集上進行實驗,實驗結果如表6 所示。
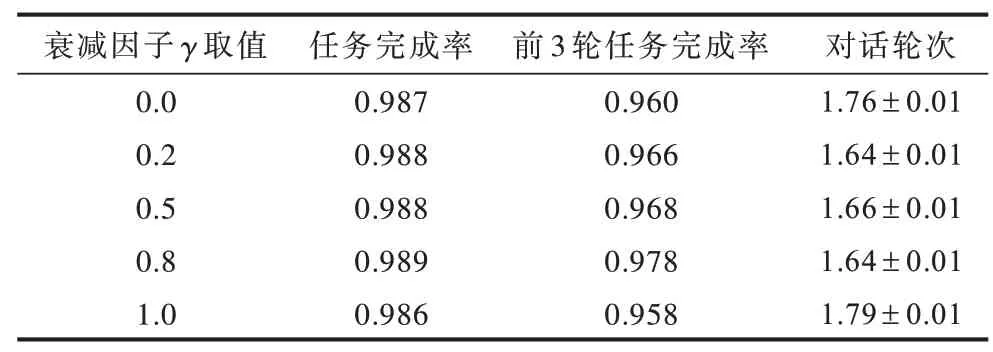
表6 實驗評價結果Table 6 Results of experimental evaluation
從表1 的實驗結果可以看出,雖然衰減因子γ對于融合強化學習算法的性能具有影響,但無論衰減因子γ取什么值,其結果都好于系統隨機引導以及基于規則的對話策略,且與基于信息熵的對話策略的性能接近。當γ取值為0.8 時融合強化學習算法結果最好,為方便比較,本文設定衰減因子γ取值為0.8。
3.4 實驗結果與分析
表7 所示為在音樂曲庫數據集上使用系統隨機引導、基于填槽法的對話策略、基于信息熵的對話策略和融合強化學習與信息熵的對話策略的實驗結果。
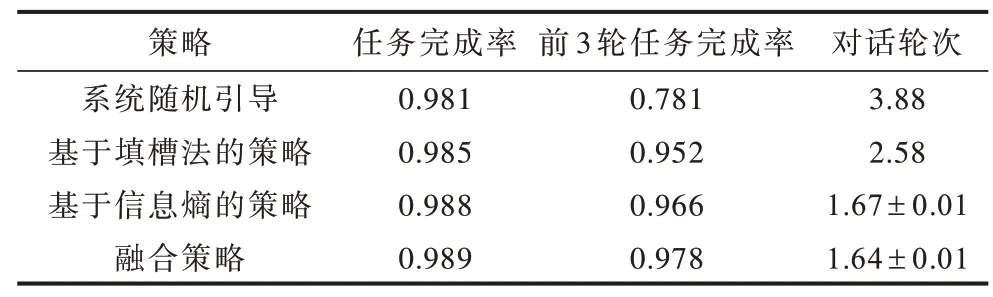
表7 4 種策略的實驗評價結果Table 7 Experimental evaluation results of four strategies
從表7 可以看出:
1)系統隨機引導與其他3 種改進算法相比,前3 輪任務完成率明顯較低,相差20%左右,這是因為在任務中每個槽位的重要程度不同,并且針對不同的搜索目標和不同結果列表的信息量不同,系統直接采用隨機的方式進行引導詢問,會導致任務完成的效率偏低。
2)與系統隨機引導的對話策略相比,基于人工制定屬性槽優先級的對話策略能夠顯著減少完成音樂搜索任務所需的對話輪次(從3.88 次到2.58 次),這是因為人工定義屬性槽的優先級,將領域知識通過制定規則的方式添加到算法中,從而提升了對話策略的智能程度。
3)考慮搜索結果屬性信息熵的對話策略,在前3 輪任務完成率和對話輪次兩個評價標準中均有顯著的提升。與基于人工制定槽屬性優先級的對話策略算法相比,基于屬性信息熵的對話策略方法由于考慮了每次搜索結果的屬性信息熵,從而動態地計算了屬性槽位的信息含量,提升了對話策略的效率。
4)融合強化學習和屬性信息熵的對話策略方法與基于信息熵的對話策略相比,在兩項評價指標上有略微的提升,通過個案分析得知,在搜索熱門歌手和歌曲時,由于曲庫存在同一首歌的多個版本,各個槽位信息無法有效地將歌曲進行完全劃分,因此結合基于表格的強化學習輔助進行判斷,能夠幫助系統做出更有效的決策。
4 結束語
在垂直領域的任務型對話系統中,通常沒有針對特定領域的對話數據進行模型訓練,從而導致對話策略在真實應用環境下的對話數據面臨冷啟動的問題。為此,本文提出了適用于知識庫搜索型對話系統的融合強化學習和屬性信息熵的對話策略,將對話決策過程抽象為一個馬爾科夫決策過程,利用強化學習來選擇下一步最優對話狀態,并引入屬性信息熵排除多個狀態值函數相同的最優狀態的情況。在音樂搜索領域數據集上的實驗結果驗證了本文方法的有效性。雖然本文方法可以解決對話策略在完全冷啟動場景下的問題,但該方法屬于離線學習,無法滿足對話系統隨著應用場景的變化不斷調整的需要。因此,構建支持在線學習和優化的策略學習模型,實時獲取用戶與系統進行交互的對話數據從而對模型進行優化,將是下一步的研究工作。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
