雙尺度網(wǎng)絡(luò)高分辨率樓面影像微小缺陷檢測(cè)
2021-03-19 12:42:28孫光民陳佳陽(yáng)李冰李煜閆冬
哈爾濱工程大學(xué)學(xué)報(bào) 2021年2期
孫光民, 陳佳陽(yáng), 李冰, 李煜, 閆冬
(1.北京工業(yè)大學(xué) 信息學(xué)部,北京 100124;2.中國(guó)煙草總公司 北京市公司,北京 100020)
隨著我國(guó)城市化進(jìn)程的加快,高層甚至超高層樓宇的數(shù)量快速增長(zhǎng)。這些建筑的外墻通常為磚混結(jié)構(gòu),利用水泥將緊密排列的磚塊粘附于建筑表面,從而起到保溫、美觀、抗腐蝕的作用。然而經(jīng)過(guò)長(zhǎng)時(shí)間的風(fēng)吹、暴曬和雨水侵蝕,磚塊很可能出現(xiàn)裂縫、松動(dòng)、甚至脫落等現(xiàn)象。若脫落的磚塊從高空墜下,將會(huì)對(duì)建筑物周邊的行人和車(chē)輛等造成極大的危害。因此,對(duì)樓面風(fēng)險(xiǎn)的排查越來(lái)越受到重視。目前,主要還是采用人工的方式進(jìn)行建筑外墻的缺陷檢測(cè),例如地面巡查或通過(guò)蜘蛛人實(shí)地勘察。但是這些人工檢測(cè)方法既耗費(fèi)大量的人力和物力,又不能保證在高空作業(yè)的工人的安全。故應(yīng)用計(jì)算機(jī)視覺(jué)和深度學(xué)習(xí)技術(shù)完成對(duì)樓面高清圖像中微小缺陷目標(biāo)的自動(dòng)檢測(cè),可以有效地節(jié)省人力、提高效率。
由于樓面缺陷檢測(cè)任務(wù)中待檢測(cè)的缺陷面積只有不到總體圖像面積的幾千分之一,故樓面缺陷檢測(cè)屬于小目標(biāo)檢測(cè),為目前計(jì)算機(jī)視覺(jué)領(lǐng)域的研究熱點(diǎn)。目前應(yīng)用比較廣泛的基于深度學(xué)習(xí)的目標(biāo)檢測(cè)器主要可以分為2類:第1類是兩步(two-stage)目標(biāo)檢測(cè)器,如Fast R-CNN[1],F(xiàn)aster R-CNN[2],Mask R-CNN[3]等,這些算法特點(diǎn)都是將目標(biāo)檢測(cè)分為2個(gè)階段:首先提取候選區(qū)域,然后再將其送入檢測(cè)網(wǎng)絡(luò)完成對(duì)目標(biāo)的定位與識(shí)別。第2類是單步(one-stage)目標(biāo)檢測(cè)算法,如單次多盒檢測(cè)器(single shot detection,SSD)[4]、你只看一次(you look only once,YOLO)[5],YOLO 9000[6],YOLO V3[7]等,此類算法不需要預(yù)先提取候選框,而是直接通過(guò)網(wǎng)絡(luò)中預(yù)設(shè)框來(lái)完成目標(biāo)位置的回歸和類別的判斷,是一種端到端的目標(biāo)檢測(cè)算法。然而在小目標(biāo)檢測(cè)場(chǎng)景下,由于目標(biāo)像素更少、可提取特征更不明顯,傳統(tǒng)的兩步和單步檢測(cè)器都難以取得較好的檢測(cè)效果。
目前針對(duì)小目標(biāo)檢測(cè)算法的優(yōu)化主要集中在模型的改進(jìn)上,即在輸入圖像尺寸不變的前提上,通過(guò)改進(jìn)模型結(jié)構(gòu)提升檢測(cè)器的特征提取能力以及其檢測(cè)精度。目前比較有效的改進(jìn)算法是特征金字塔網(wǎng)絡(luò)[8]。該網(wǎng)絡(luò)可嵌入到上述單步或2步檢測(cè)器中,其可將主體網(wǎng)絡(luò)生成的低層次特征圖與高層次特征圖以特定方式進(jìn)行融合,完成對(duì)特征金字塔的重構(gòu)。這樣操作后低層次的特征圖感受野范圍提升,其語(yǔ)義信息得到增強(qiáng),最終使得模型對(duì)小目標(biāo)檢測(cè)的精度有了很大提升。
雖然上述改進(jìn)可以提升模型檢測(cè)精度,但是這些模型處理的對(duì)象仍然是低分辨率圖像。隨著攝像設(shè)備硬件性能的提升,人們可以獲得更高分辨率的圖像。而與低分辨率圖像相比,小目標(biāo)在高分辨率圖像中可以用更多的像素表征,即可以被更加清晰的刻畫(huà)出來(lái)。雖然獲得了有效的數(shù)據(jù)支撐,但目前的檢測(cè)算法基本都不直接適用于分辨率高達(dá)幾千萬(wàn)像素的圖像。但如果將高分辨率圖像進(jìn)行下采樣以適應(yīng)檢測(cè)模型,又將丟失信息,很難對(duì)小目標(biāo)進(jìn)行檢測(cè)[9]。目前很多針對(duì)高分辨率圖像小目標(biāo)檢測(cè)問(wèn)題的研究和應(yīng)用大多集中在遙感圖像領(lǐng)域[10-11],其中比較具有代表性的是Adam Van Ette提出的基于窗口網(wǎng)絡(luò)衛(wèi)星影像的多尺度快速檢測(cè)算法(satellite imagery multiscale rapid detection with windowed networks,SIMRDWN)[12]。該算法利用快速檢測(cè)器對(duì)通過(guò)滑窗獲取的候選區(qū)域進(jìn)行檢測(cè),可以完成對(duì)任意尺寸高分辨率圖像的快速檢測(cè)任務(wù)。但是與衛(wèi)星遙感圖像不同的是,樓面圖像中缺陷樣式形態(tài)各異,難以統(tǒng)一描述,同時(shí)圖像中也存在大量復(fù)雜紋理區(qū)域會(huì)干擾檢測(cè),容易引發(fā)虛警。為了提升高清圖像中目標(biāo)的檢測(cè)速度和精度,本文提出了一種基于雙尺度建模的檢測(cè)框架,旨在基于少量訓(xùn)練樣本完成高精度高效率的墻面缺陷自動(dòng)檢測(cè)。
1 高分辨率墻面圖像缺陷檢測(cè)
利用高清晰度單反相機(jī)(SONY A7R2)和長(zhǎng)焦鏡頭(FE 100-400 mm F4.5-5.6 GM OSS)拍攝得到的墻面高清圖像的分辨率高達(dá)7952×5304像素,而待檢測(cè)的墻體缺陷如缺磚、碎磚等一般大小不超過(guò)100×100像素。同時(shí),缺、碎磚等缺陷的形狀差異較大,難以對(duì)其進(jìn)行統(tǒng)一的特征描述。而且缺陷的辨識(shí)特征主要在于其與周?chē)尘暗牟町悾鋬?nèi)部的紋理特征并不明顯。此外,樓面高分辨率圖像中的缺陷只占很小面積,絕大部分區(qū)域都是正常的。原始高分辨率圖像如圖1所示,其中圖1中的左側(cè)紅框內(nèi)是原始圖像的2個(gè)含有缺陷的分辨率為640×640像素的子區(qū)域。

圖1 包含缺陷的樓面高分辨率圖像Fig.1 High resolution image with defects
針對(duì)樓面圖像的上述特點(diǎn),本文提出一種基于雙尺度建模的高分辨率樓面圖像缺陷檢測(cè)算法。該方法首先將缺陷檢測(cè)任務(wù)在一大一小2個(gè)尺度上進(jìn)行分解,得到一個(gè)雙尺度下的任務(wù)組。在大尺度下,設(shè)置窗戶,空調(diào)、天空等非墻體分割任務(wù),通過(guò)結(jié)合傳統(tǒng)圖像處理技術(shù)和實(shí)例分割模型Mask R-CNN得到非墻體分割掩模;在小尺度下,設(shè)置缺陷檢測(cè)任務(wù),通過(guò)重疊式滑窗獲取候選區(qū)并送入SSD檢測(cè)器獲取切片缺陷檢測(cè)結(jié)果。根據(jù)非墻體與缺陷目標(biāo)的包含關(guān)系,將2個(gè)尺度下的分割掩模與檢測(cè)框進(jìn)行決策融合和后處理,最終完成對(duì)原始樓面高分辨率圖像中微小缺陷的檢測(cè)。本文提出的基于高分辨率樓面圖像的缺陷檢測(cè)算法的總體流程如圖2所示。
1.1 大尺度下的非墻體分割
在大尺度下,對(duì)面積較大的非墻體目標(biāo)進(jìn)行分割。由于非墻體不包含缺陷,故可以依據(jù)其掩模有效縮減需要缺陷檢測(cè)的區(qū)域并減少誤檢的發(fā)生。根據(jù)圖像處理中的高斯金字塔理論[13],圖像在不同尺度下的表征可以通過(guò)對(duì)原始圖像重復(fù)應(yīng)用高斯濾波及下采樣操作得到。首先應(yīng)用高斯模糊和8倍下采樣,從原始7 952×5 304的樓面高分辨率圖像得到994×663的低分辨率大尺度圖像,并設(shè)置天空、空調(diào)、窗戶作為該尺度下的分割對(duì)象。然后對(duì)不同的非墻體目標(biāo)分別應(yīng)用傳統(tǒng)圖像處理以及深度學(xué)習(xí)2種不同的算法進(jìn)行分割,得到不同非墻體目標(biāo)的掩模。最終將這些掩膜組合起來(lái),并通過(guò)上采樣得到原始尺度下的非墻體掩模。其中,應(yīng)用傳統(tǒng)圖像處理進(jìn)行天空的分割;應(yīng)用實(shí)例分割模型Mask R-CNN[3]進(jìn)行空調(diào)、窗戶的分割。大尺度下樓面圖像非墻體區(qū)域分割的算法流程如圖3所示。

圖2 樓面圖像缺陷檢測(cè)流程Fig.2 Pipeline of defects detection of building wall surface image
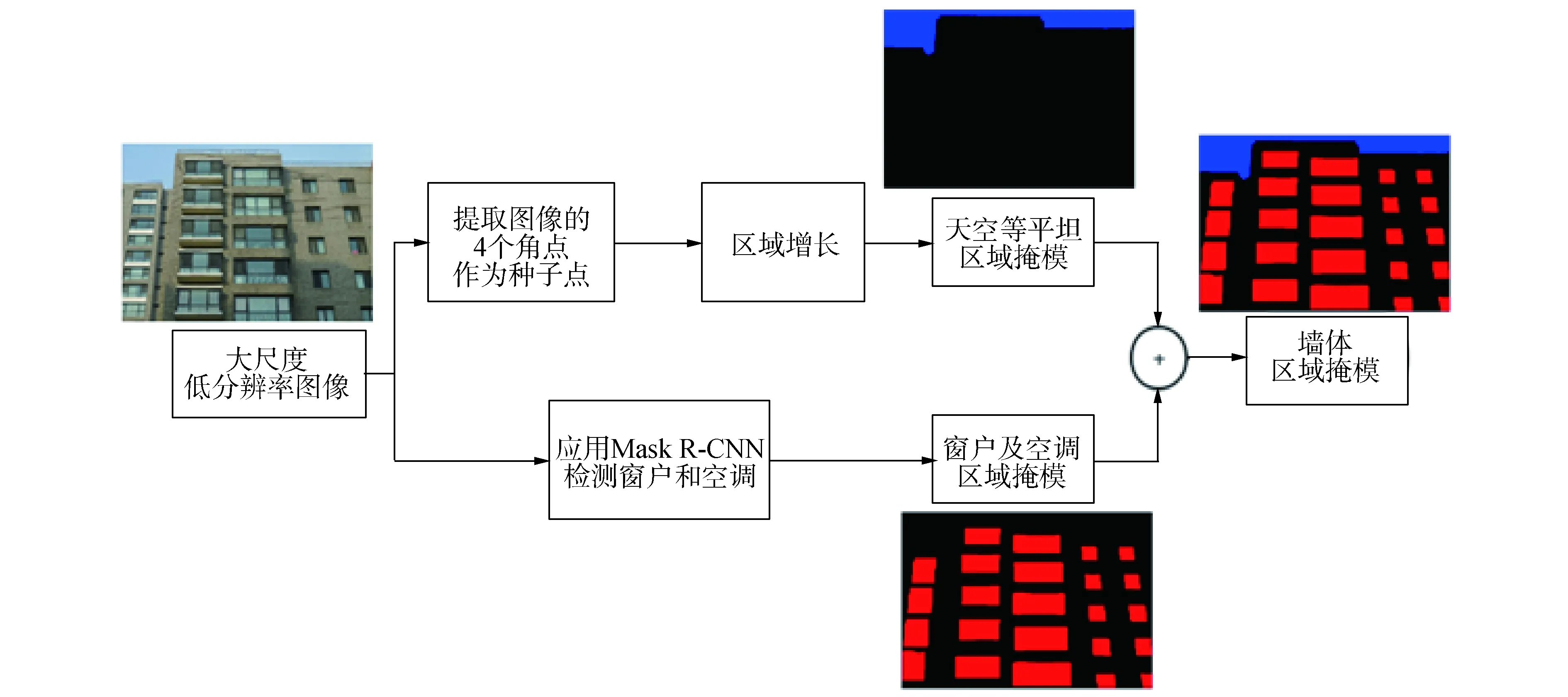
圖3 大尺度下的非墻體區(qū)域分割算法Fig.3 Non-wall region segmentation at large scale
由于天空顏色會(huì)隨著天氣、時(shí)間,拍攝像機(jī)等因素的變化而變化,故傳統(tǒng)顏色閾值分割方法中的閾值不易設(shè)定,算法應(yīng)用的場(chǎng)景受限。而樓面圖像中天空具有另外2個(gè)特征:1)其總體區(qū)域較為平坦;2)樓面圖像中的天空基本處于圖像的四周。因而針對(duì)這2個(gè)特點(diǎn),本文采用8鄰域區(qū)域生長(zhǎng)算法對(duì)天空區(qū)域進(jìn)行分割[14]。其中種子點(diǎn)選取為圖像的4個(gè)角點(diǎn),生長(zhǎng)準(zhǔn)則為灰度差值小于設(shè)定閾值。
除此,窗戶和空調(diào)通常也會(huì)頻繁出現(xiàn)于樓面圖像中,它們雖不包含待測(cè)缺陷,卻很容易造成檢測(cè)器的誤檢。因此為了提升檢測(cè)的效率以及精度,本文也提前對(duì)圖像中窗戶進(jìn)行篩選。由于室外拍攝環(huán)境復(fù)雜,窗內(nèi)雜物太多,拍攝角度多變等諸多因素的影響,傳統(tǒng)圖像處理很難對(duì)目標(biāo)進(jìn)行的統(tǒng)一的特征描述,故本文采用實(shí)例分割Mask R-CNN深度模型對(duì)其進(jìn)行處理。
將通過(guò)不同方式獲得的不同目標(biāo)的掩模通過(guò)相與操作進(jìn)行合并,最終得到非墻體的二值掩模,其中灰度值為255表示非墻體,0表示墻體。為了便于后續(xù)小尺度下的缺陷檢測(cè),需要對(duì)該低分辨率掩模進(jìn)行上采樣為原始分辨率。由于掩模生成本身并不精確,故本文選擇最鄰近插值作為掩膜上采樣的方式。
1.2 小尺度下的墻面缺陷檢測(cè)
在得到非墻體掩模后,在小尺度下進(jìn)行缺陷檢測(cè)。與大尺度圖片生成方式不同,本文直接采用圖像的原始尺度作為小尺度表征。由于目前的檢測(cè)器輸入皆為低分辨率圖像,故本文采用重疊式滑窗提取候選區(qū)域并送入檢測(cè)器檢測(cè)的方式完成小尺度下的缺陷檢測(cè)任務(wù)。其中圖像候選區(qū)域是否送入檢測(cè)器需要依據(jù)非墻體掩模上對(duì)應(yīng)位置的窗口區(qū)域的狀態(tài)進(jìn)行判斷。為了加快檢測(cè)速度,本文選擇SSD[4]模型作為缺陷檢測(cè)器,并采用Resnet50[15]作為其主干網(wǎng)絡(luò),同時(shí)引入了FPN[8]網(wǎng)絡(luò)架構(gòu)來(lái)提升其對(duì)于小目標(biāo)檢測(cè)的效果[16],其輸入的圖像分辨率為640×640。小尺度下缺陷檢測(cè)的算法流程如圖4所示,SSD缺陷檢測(cè)網(wǎng)絡(luò)的結(jié)構(gòu)如圖5所示。
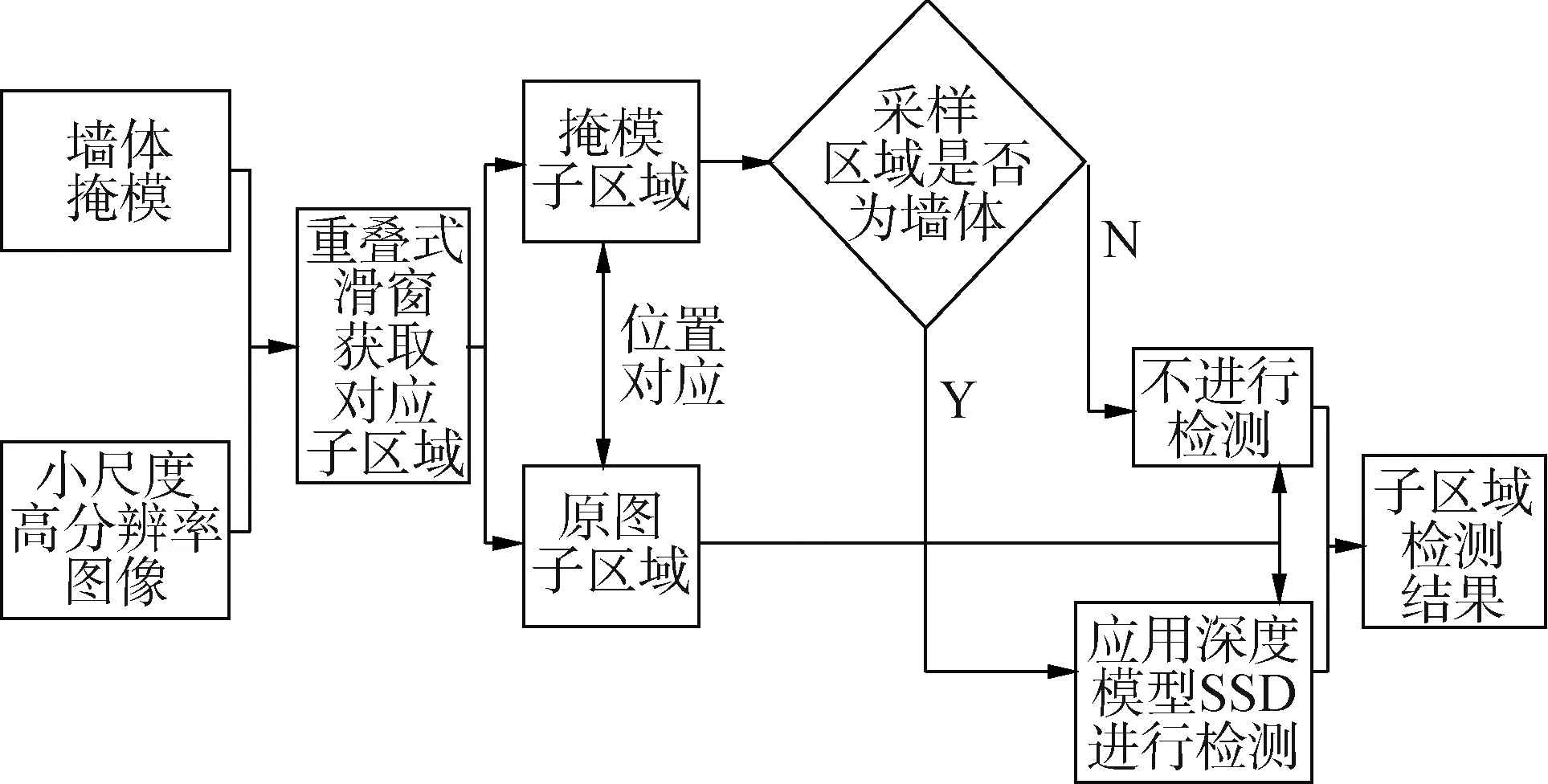
圖4 小尺度下的缺陷檢測(cè)算法Fig.4 Defects detection at small scale
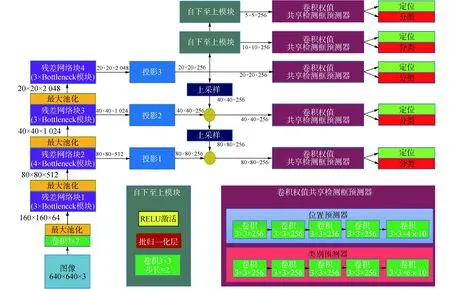
圖5 小尺度下的缺陷檢測(cè)器網(wǎng)絡(luò)架構(gòu)Fig.5 The architecture of the defect detector at the small scale
1.2.1 滑窗參數(shù)選擇
為了能夠平衡檢測(cè)的精度以及效率,采用重疊式滑窗提取待檢測(cè)區(qū)域。設(shè)重疊滑動(dòng)窗口寬度為W=640,與SSD模型輸入尺寸相同,滑動(dòng)步長(zhǎng)S∈[1,W]。通過(guò)分析,發(fā)現(xiàn)窗口的滑動(dòng)步長(zhǎng)S與目標(biāo)檢測(cè)任務(wù)有如下幾點(diǎn)關(guān)聯(lián):1)所有大小在(W-S)×(W-S)以下的缺陷將至少完整的出現(xiàn)在1個(gè)窗口內(nèi);2)所有像素在窗口中出現(xiàn)的平均次數(shù)為(W-S)×(W-S)次;3)當(dāng)S可以整除W的時(shí)候,所有像素在窗口中出現(xiàn)的次數(shù)是一樣的;4)當(dāng)S大于W的一半時(shí),像素出現(xiàn)次數(shù)不平均。由于樣本中所有待檢測(cè)缺陷的大小基本都小于(W/2)×(W/2),故根據(jù)上述4個(gè)特點(diǎn),選取滑動(dòng)步長(zhǎng)為窗長(zhǎng)的一半,即S=W/2,如此可以保證所有大小在320×320以下的缺陷至少出現(xiàn)在一塊完整的切片中,且所有的像素被窗口選取的次數(shù)均為4次。
1.2.2 區(qū)域篩選算法
當(dāng)滑窗在原圖上獲取子區(qū)域時(shí),也可以同時(shí)獲取對(duì)應(yīng)的掩膜子區(qū)域,并可以依據(jù)掩模子區(qū)域的狀態(tài)對(duì)原圖子區(qū)域進(jìn)行篩選,決定其是否送入檢測(cè)器進(jìn)行檢測(cè)。如果掩膜子區(qū)域內(nèi)絕大部分都是非墻體區(qū)域,那么就不對(duì)該子區(qū)域做后續(xù)檢測(cè),從而加快對(duì)子塊集的檢測(cè)速度。而由于非墻體掩膜并不精細(xì),且為了進(jìn)一步提升檢測(cè)的檢測(cè)效率,本文選擇定點(diǎn)采樣方式利用掩膜做近似篩選。該方法需要將窗口按照4×4分格,以網(wǎng)格線的交點(diǎn)作為取樣點(diǎn),則一個(gè)窗口內(nèi)部一共包含9個(gè)取樣點(diǎn)。如果9個(gè)點(diǎn)內(nèi)存在1個(gè)點(diǎn)屬于墻體,則對(duì)應(yīng)的原圖子區(qū)域送入檢測(cè);若9個(gè)點(diǎn)全部都是非墻體,則其不送入檢測(cè)。窗口內(nèi)取樣點(diǎn)的位置如圖6中的圓點(diǎn)所示。
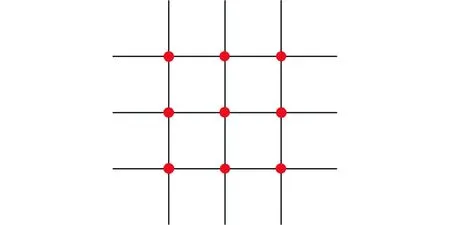
圖6 窗口內(nèi)采樣方式示意(圓點(diǎn))Fig.6 Sampling mode in window (dots)
1.2.3 檢測(cè)結(jié)果后處理
應(yīng)用訓(xùn)練好的缺陷檢測(cè)器對(duì)篩選后的原圖子區(qū)域進(jìn)行檢測(cè),即可得到每個(gè)子區(qū)域上的檢測(cè)結(jié)果。然后只需要將每個(gè)窗口內(nèi)的檢測(cè)框坐標(biāo)依據(jù)所在窗口的位置信息進(jìn)行調(diào)整,即可重新映射為原始高分辨率圖像上的檢測(cè)框。設(shè)子塊在原始圖像中的左上角點(diǎn)的位置被記錄為(X,Y),子塊內(nèi)的檢測(cè)結(jié)果為(x,y,w,h),那么依據(jù)簡(jiǎn)單的坐標(biāo)變換就可以得到目標(biāo)檢測(cè)框?qū)?yīng)于原圖像的4個(gè)參數(shù)為(X+x,Y+y,w,h)。然而由于窗口重疊式獲取區(qū)域,所以檢測(cè)器將對(duì)同一目標(biāo)進(jìn)行多次檢測(cè),最終導(dǎo)致圖像中同一個(gè)目標(biāo)對(duì)應(yīng)出現(xiàn)多個(gè)檢測(cè)框。為了避免太多相互覆蓋的檢測(cè)框的干擾,還需要對(duì)它們進(jìn)行非極大值抑制處理。
1.3 多尺度分割與檢測(cè)結(jié)果融合
完成不同尺度上的檢測(cè)任務(wù)后,需要對(duì)多尺度檢測(cè)結(jié)果進(jìn)行融合。盡管已經(jīng)借助過(guò)大尺度分割結(jié)果對(duì)小目標(biāo)檢測(cè)區(qū)域進(jìn)行了篩選,但是實(shí)際上由于滑動(dòng)窗口為矩形、掩模生成不精確、區(qū)域篩選算法設(shè)置寬松等因素的影響,篩選后的窗口內(nèi)不可避免地仍有部分非墻體區(qū)域存在。在這些缺陷目標(biāo)本不該出現(xiàn)的區(qū)域內(nèi)可能會(huì)出現(xiàn)虛警。為了提升檢測(cè)精度,將大尺度分割掩膜和小目標(biāo)檢測(cè)結(jié)果再次進(jìn)行融合,依據(jù)掩膜將非墻體區(qū)域包含的檢測(cè)框舍去。然而為了避免非墻體與墻體區(qū)域分界處的真實(shí)目標(biāo)不被舍棄,在融合前需要先對(duì)非墻體掩模進(jìn)行簡(jiǎn)單的形態(tài)學(xué)腐蝕處理。從而使其掩膜邊界處的目標(biāo)缺陷得以保留。
2 算法模型的訓(xùn)練
檢測(cè)算法中涉及的實(shí)例分割網(wǎng)絡(luò)及缺陷檢測(cè)網(wǎng)絡(luò)都需要在COCO[20]數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練。對(duì)于實(shí)例分割模型,利用預(yù)訓(xùn)練的Mask R-CNN在標(biāo)注好窗戶和空調(diào)的大尺度低分辨率數(shù)據(jù)集上進(jìn)行遷移學(xué)習(xí)[18-19]。對(duì)于小尺度下的缺陷檢測(cè)模型,利用預(yù)訓(xùn)練的SSD模型做遷移學(xué)習(xí)。但是與前者的標(biāo)準(zhǔn)訓(xùn)練方式不同,為了提升對(duì)微小缺陷的檢測(cè)精度,本文在數(shù)據(jù)集制作以及模型訓(xùn)練方式上都做了改進(jìn),下面將對(duì)其流程進(jìn)行介紹。其中所有實(shí)驗(yàn)均基于Tensorflow平臺(tái)的Google Object Detection API[17]完成。
2.1 數(shù)據(jù)集預(yù)處理及檢測(cè)器初次訓(xùn)練
初始樣本集的制作需要標(biāo)注樓面圖像中的缺陷的位置及種類,要求標(biāo)注矩形框緊貼檢測(cè)目標(biāo)的邊緣,得到初始標(biāo)注框(xi,yi,wi,hi),其中xi和yi分別為初始標(biāo)注框的左上角點(diǎn)的橫縱坐標(biāo),wi和hi分別為初始標(biāo)注框的寬度和高度。然而由于缺陷的特征主要表現(xiàn)在其與周邊環(huán)境的差異性,故對(duì)初始標(biāo)注框進(jìn)行修正,為缺陷主動(dòng)保留背景。設(shè)修正后的標(biāo)注框?yàn)?xc,yc,wc,hc):
wc=wi×(1+α)
(1)
hc=hi×(1+α)
(2)
xc=xi-0.5×wc×α
(3)
yc=yi-0.5×hc×α
(4)
式中α∈(0.2,0.8)為擴(kuò)展參數(shù)。通過(guò)實(shí)驗(yàn)分析,當(dāng)α取0.6時(shí),訓(xùn)練出來(lái)的模型檢測(cè)精度最高。
由于小尺度高分辨率圖像與檢測(cè)器輸入不匹配,故需要依據(jù)初始高分辨率數(shù)據(jù)集制作出合適的數(shù)據(jù)集,才能進(jìn)行檢測(cè)器的訓(xùn)練。首先將高分辨率圖像分為訓(xùn)練集、驗(yàn)證集和測(cè)試集;然后從各集合中的高分辨率圖像上裁剪包含缺陷的切片,得到對(duì)應(yīng)的3個(gè)切片集。這些切片要符合檢測(cè)器的輸入尺寸,且每一塊至少包含一個(gè)目標(biāo);最后利用訓(xùn)練切片集對(duì)模型進(jìn)行訓(xùn)練并保存在驗(yàn)證切片集上表現(xiàn)最優(yōu)的節(jié)點(diǎn)作為初次訓(xùn)練完成后的模型參數(shù)。
如果檢測(cè)器的輸入樣本較少,那么深度網(wǎng)絡(luò)一般難以通過(guò)直接訓(xùn)練得到很好的模型參數(shù)。通常可以采用遷移學(xué)習(xí)的方式解決小樣本問(wèn)題。遷移學(xué)習(xí)是指先在開(kāi)源的大數(shù)據(jù)集上對(duì)模型進(jìn)行預(yù)訓(xùn)練,然后再在自己的小樣本集上對(duì)模型進(jìn)行微調(diào)。除此還可以應(yīng)用數(shù)據(jù)擴(kuò)增技術(shù),例如對(duì)高分辨率圖像上的每一個(gè)目標(biāo)進(jìn)行多次隨機(jī)裁剪。由于樓面缺陷樣本較少,故采用遷移學(xué)習(xí)[18-19]的方式進(jìn)行模型的訓(xùn)練。首先讓模型在COCO[20]大數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,然后再在樓面缺陷小樣本集上進(jìn)行微調(diào),最后保存出驗(yàn)證集上最佳節(jié)點(diǎn)作為初次訓(xùn)練完成的模型參數(shù)。
2.2 引入負(fù)樣本的檢測(cè)器2次訓(xùn)練
然而由于算法最終處理對(duì)象是原始高分辨率圖像,故檢測(cè)算法效果的最終評(píng)價(jià)應(yīng)該在高分辨率圖像集上獲得。在高分辨率圖像中,除了待檢測(cè)缺陷之外,還有大量的會(huì)干擾檢測(cè)的物體。而由于初次訓(xùn)練使用的切片集只包含了小目標(biāo)附近的區(qū)域,而不包含干擾項(xiàng),導(dǎo)致訓(xùn)練好的模型無(wú)法對(duì)他們進(jìn)行區(qū)分,進(jìn)而產(chǎn)生大量虛警。
為了構(gòu)建更加全面的數(shù)據(jù)集,應(yīng)用初次訓(xùn)練模型對(duì)訓(xùn)練和驗(yàn)證的原始高分辨率圖集分別進(jìn)行檢測(cè),并將包含誤檢框的切片作為負(fù)樣本引入,生成新的訓(xùn)練和驗(yàn)證切片樣本集。這些負(fù)樣本切片的類別標(biāo)簽設(shè)定為“正常”,其檢測(cè)框標(biāo)簽則設(shè)定為整個(gè)切片區(qū)域,其數(shù)量與正樣本集數(shù)量的比例設(shè)定為1∶6。然后就可以利用新生成的數(shù)據(jù)集對(duì)初次訓(xùn)練模型進(jìn)行二次微調(diào)。由于引入了檢測(cè)器易于誤檢的樣本,檢測(cè)器將能更加關(guān)注這些樣本,并能更好地學(xué)習(xí)到區(qū)分正負(fù)樣本的特征。這種負(fù)反饋機(jī)制能夠?qū)δP陀?xùn)練起到矯正的作用,可以大大降低虛警的發(fā)生。需要注意的是,模型訓(xùn)練完成后并不需要輸出負(fù)樣本類別(正常),即負(fù)樣本類別只在訓(xùn)練時(shí)發(fā)揮作用。
3 實(shí)驗(yàn)結(jié)果及分析
3.1 分割模型與檢測(cè)模型的初次訓(xùn)練結(jié)果
實(shí)驗(yàn)所用樓面圖像采用電動(dòng)云臺(tái)對(duì)樓面進(jìn)行網(wǎng)格式拍攝,圖像分辨率為7 952×5 304。評(píng)價(jià)指標(biāo)采用COCO標(biāo)準(zhǔn)的平均精度均值(mean Average Precision,mAP)[20]。mAP理論上為各類別的PR曲線下面積的均值,COCO提供了一種近似計(jì)算方法,常用于評(píng)估目標(biāo)檢測(cè)模型的效果。
3.1.1 分割模型的訓(xùn)練及測(cè)試效果
用于訓(xùn)練實(shí)例分割模型Mask R-CNN的樣本共31張,圖像分辨率下采樣為994×663,分為訓(xùn)練集(25張)和驗(yàn)證集(6張),每張圖片中的窗戶和空調(diào)個(gè)數(shù)不等。保存出驗(yàn)證切片集上最高mAP節(jié)點(diǎn)處的模型作為最終分割模型,將其置信度閾值設(shè)定為0.5,得到的檢測(cè)效果示意如圖7所示,其中的空調(diào)和窗戶2種非墻體都被很好地分割了出來(lái)。

圖7 Mask-RCNN的檢測(cè)效果示意Fig.7 The training results of Mask RCNN
3.1.2 檢測(cè)模型的初次訓(xùn)練及測(cè)試效果
用于訓(xùn)練SSD模型的樣本共107張,圖像分辨率一般為7 952×5 304,分為訓(xùn)練集(88張)、驗(yàn)證集(9張)和測(cè)試集(10張),每張圖片中的缺陷個(gè)數(shù)不等。根據(jù)2.1節(jié)的樣本制作方法,得到分辨率為640×640切片圖集,其中訓(xùn)練集、驗(yàn)證集和測(cè)試集對(duì)應(yīng)的切片樣本數(shù)量分別為3 180、220和130張(10倍擴(kuò)增后)。然后利用在COCO數(shù)據(jù)集上預(yù)訓(xùn)練好的SSD模型在樓面缺陷切片樣本集上進(jìn)行遷移學(xué)習(xí),batch size設(shè)為4,學(xué)習(xí)率設(shè)為0.000 05,迭代30 000次。模型在驗(yàn)證切片集上的mAP隨迭代次數(shù)變化的曲線如圖所示,其中IOU閾值設(shè)定為0.5。在100 000步迭代后,模型在驗(yàn)證切片集上的mAP可達(dá)到0.7左右,之后趨于穩(wěn)定。保存出驗(yàn)證切片集上最高mAP節(jié)點(diǎn)處的模型作為初次訓(xùn)練模型,該模型在測(cè)試切片集上的mAP為0.714。將初次訓(xùn)練模型的置信度閾值設(shè)定為0.5,其部分檢測(cè)結(jié)果如圖8所示,其中模型成功定位出了切片上的缺陷位置,并給出了相應(yīng)的置信度。

圖8 SSD的模型檢測(cè)效果示意Fig.8 The training results of SSD
3.2 引入二次訓(xùn)練的算法檢測(cè)效果與分析
將初次訓(xùn)練模型置于檢測(cè)算法框架中,應(yīng)用所提檢測(cè)算法對(duì)訓(xùn)練和驗(yàn)證原始高分辨率圖集進(jìn)行檢測(cè)并計(jì)算出模型在高分辨率圖集上的mAP值。從表1和表2的第1行可以發(fā)現(xiàn),相較于初次訓(xùn)練模型在訓(xùn)練、驗(yàn)證和測(cè)試的切片集上的mAP,算法在對(duì)應(yīng)高分辨率圖集上的mAP都發(fā)生了嚴(yán)重的下降。通過(guò)觀察與分析檢測(cè)結(jié)果,認(rèn)為這一現(xiàn)象主要是由于過(guò)多的虛警造成的。為了抑制虛警,將得到檢測(cè)結(jié)果中未與真實(shí)框相交的檢測(cè)框作為誤檢,并以其為中心剪切圖片。接著將得到的切片中的檢測(cè)框設(shè)為整張圖像,類別設(shè)為normal(無(wú)缺陷),并將其與原始切片樣本混合,得到擴(kuò)增的訓(xùn)練和驗(yàn)證切片集分別為3 721和252張。最后在新數(shù)據(jù)集上對(duì)初次訓(xùn)練模型進(jìn)行再次微調(diào),得到2次訓(xùn)練模型作為最終檢測(cè)模型。通過(guò)對(duì)比表2中初次訓(xùn)練模型和2次訓(xùn)練模型在原始高分辨率圖像訓(xùn)練、驗(yàn)證和測(cè)試集上的mAP數(shù)值可以發(fā)現(xiàn),該方法可以有效地提升算法的檢測(cè)精度。經(jīng)過(guò)2次訓(xùn)練后的最終檢測(cè)模型在測(cè)試集上的mAP為0.480。

表1 不同小尺度檢測(cè)器在切片集上的mAP
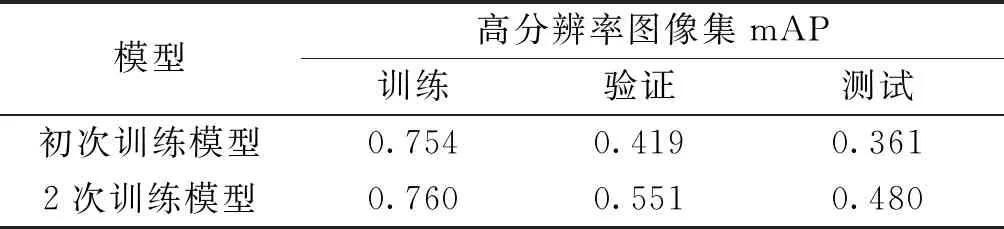
表2 采用不同小尺度檢測(cè)器的所提整體算法在高分辨率圖集上的mAP
分別將初次訓(xùn)練模型和二次訓(xùn)練模型置于總體檢測(cè)框架中,并應(yīng)用檢測(cè)算法對(duì)測(cè)試集進(jìn)行檢測(cè),其部分檢測(cè)結(jié)果如圖9所示,其中只有周?chē)鷺?biāo)有“缺陷”字樣的檢測(cè)框才是預(yù)測(cè)正確的結(jié)果。由圖可知,所提檢測(cè)算法在采用初次訓(xùn)練模型作為小尺度缺陷檢測(cè)器時(shí),其檢測(cè)結(jié)果中產(chǎn)生了很多誤檢,大部分集中在窗戶中疑似物的干擾。而當(dāng)用二次訓(xùn)練模型替換初次訓(xùn)練模型后,所提算法的檢測(cè)結(jié)果中的誤檢數(shù)量明顯變少,證明負(fù)樣本的引入的確抑制了虛警的發(fā)生。但是同時(shí)由于負(fù)樣本中有一些與真正缺陷很相近的正常物體,故這些難樣本的引入反而會(huì)對(duì)待檢測(cè)缺陷的特征的學(xué)習(xí)產(chǎn)生抑制作用,使得模型性能提升有所限制。

圖9 二次訓(xùn)練模型在某張驗(yàn)證集圖像上的檢測(cè)結(jié)果Fig.9 The comparison of detections before re-train and after re-train
3.3 單尺度框架與多尺度框架檢測(cè)效果對(duì)比
SIMRDWN[10]算法僅在單一的尺度下進(jìn)行缺陷檢測(cè),該算法直接將原始高分辨率大圖進(jìn)行切分送入小目標(biāo)檢測(cè)框架,不生成掩膜,不對(duì)窗戶和空調(diào)這些非墻體區(qū)域進(jìn)行切片過(guò)濾和檢測(cè)框2次篩選。
本次測(cè)試結(jié)果對(duì)比如圖10所示,其中圖10(a)展示的是SIMRDWN算法結(jié)果,圖10(b)為相應(yīng)的多尺度檢測(cè)結(jié)果對(duì)照。可以明顯看出單尺度測(cè)試結(jié)果中出現(xiàn)了將窗戶內(nèi)部誤認(rèn)為是墻體破損區(qū)域的檢測(cè)框,出現(xiàn)誤檢現(xiàn)象。非墻體區(qū)域?yàn)楸緳z測(cè)流程帶來(lái)了不必要的麻煩,所以針對(duì)缺陷目標(biāo)的特殊性,采用多尺度融合檢測(cè)的方法是十分必要且有效的。

圖10 單尺度(SIMRDWN)與雙尺度(所提算法)檢測(cè)效果對(duì)比Fig.10 The comparison of detections of single-scale(SIMRDWN) and multi-scale
本次實(shí)驗(yàn)中模型在高分辨率樓面圖像上的mAP值如表3所示,與多尺度融合算法(所提算法)框架相比,單尺度算法(SIMRDWN)的精度有明顯下降。同時(shí)由于在多尺度中待檢測(cè)切片經(jīng)過(guò)了篩選,檢測(cè)次數(shù)少,算法的時(shí)間花費(fèi)也較少,如表3所示。而由于硬件和模型的差別,并未計(jì)算掩膜生成時(shí)間,隨著硬件性能的提升,這部分時(shí)間也將大大縮短。
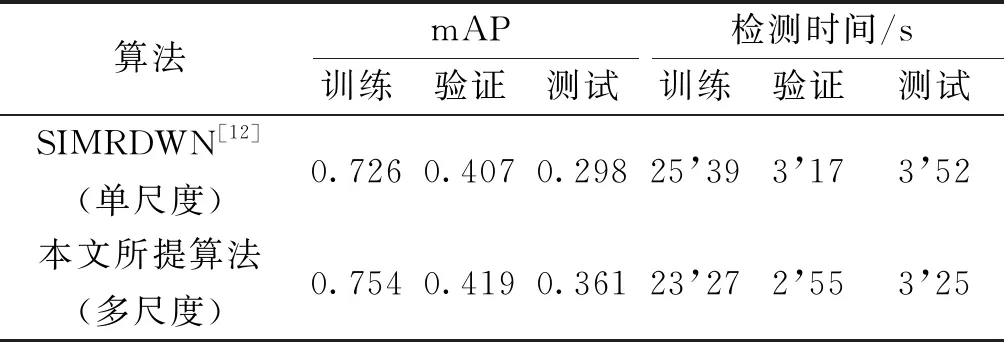
表3 不同算法在高分辨率圖集上的mAP和檢測(cè)時(shí)間對(duì)比
3.4 滑窗步長(zhǎng)的選擇實(shí)驗(yàn)
為了分析在獲取640×640大小的高分辨率圖像切片時(shí)采取不同滑動(dòng)窗口步長(zhǎng)對(duì)實(shí)驗(yàn)結(jié)果的影響,分別設(shè)置滑動(dòng)窗口步長(zhǎng)為窗長(zhǎng)的0.25、0.5和0.75進(jìn)行實(shí)驗(yàn),3種步長(zhǎng)的檢測(cè)算法在高分辨率圖集上的檢測(cè)時(shí)間和mAP如表4所示。
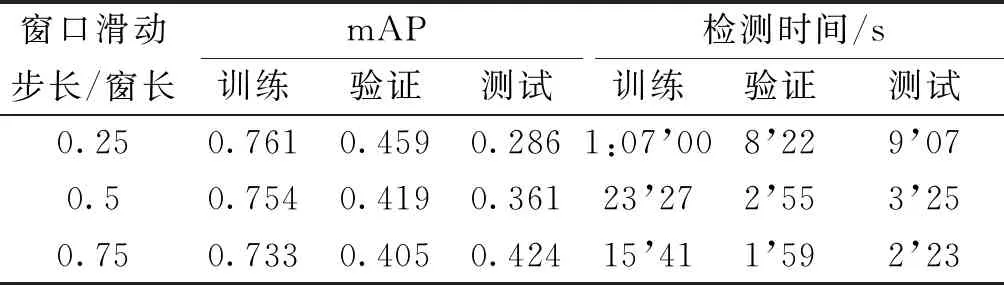
表4 采用不同滑動(dòng)步長(zhǎng)時(shí)所提算法的性能比較Table 4 Comparison of the methods of different strides
由表4可知,隨著滑動(dòng)窗口步長(zhǎng)的增大,檢測(cè)所需要的時(shí)間越來(lái)越少。其原因是步長(zhǎng)設(shè)置越小,一張高分辨率大圖所剪裁出的小圖片數(shù)量越多,調(diào)用缺陷檢測(cè)器的次數(shù)越多,耗時(shí)越長(zhǎng)。在檢測(cè)精度方面,訓(xùn)練集、驗(yàn)證集上的mAP都隨著滑動(dòng)步長(zhǎng)的增大而減小,其主要原因是候選框的稠密程度下降導(dǎo)致待檢測(cè)缺陷不易被檢測(cè)到。而與之相反,模型在測(cè)試集上的mAP卻呈上升趨勢(shì)。通過(guò)分析發(fā)現(xiàn),其主要原因是圖片中干擾項(xiàng)太多,減小候選框的稠密程度可以減少誤檢的發(fā)生。因此圖像集上的mAP變化是誤檢與漏檢的相互作用以及博弈的結(jié)果,為了兼顧檢測(cè)精度和效率,滑動(dòng)步長(zhǎng)推薦設(shè)置為0.5。
4 結(jié)論
1)在小尺度的缺陷檢測(cè)中,以負(fù)反饋的形式利用初次檢測(cè)的負(fù)樣本對(duì)模型進(jìn)行2次訓(xùn)練可以有效降低檢測(cè)器的虛警率。
2)在使用滑窗進(jìn)行檢測(cè)時(shí),步長(zhǎng)的選擇是對(duì)檢測(cè)精度和檢測(cè)速度的平衡。其取決于小尺度檢測(cè)器的精度,也取決于操作人員對(duì)系統(tǒng)效率的要求。后續(xù)可以探究自適應(yīng)步長(zhǎng)變化的研究,進(jìn)一步加快檢測(cè)速度。
3)提出的小目標(biāo)多尺度檢測(cè)框架能夠在復(fù)雜背景的高分辨率圖像中實(shí)現(xiàn)微小目標(biāo)的精確檢測(cè),且在精度和效率上都要優(yōu)于傳統(tǒng)單一尺度檢測(cè)框架。本文提出方法也適用于遙感圖像或醫(yī)學(xué)圖像中的目標(biāo)或病灶檢測(cè)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
