基于DDPG算法的路徑規劃研究
2021-03-22 17:05:34張義郭坤
電腦知識與技術 2021年4期
張義 郭坤


摘要:路徑規劃是人工智能領域的一個經典問題,在國防軍事、道路交通、機器人仿真等諸多領域有著廣泛應用,然而現有的路徑規劃算法大多存在著環境單一、離散的動作空間、需要人工構筑模型的問題。強化學習是一種無須人工提供訓練數據自行與環境交互的機器學習方法,深度強化學習的發展更使得其解決現實問題的能力得到進一步提升,本文將深度強化學習的DDPG(Deep Deterministic Policy Gradient)算法應用到路徑規劃領域,完成了連續空間、復雜環境的路徑規劃。
關鍵詞:路徑規劃;深度強化學習;DDPG;ActorCritic;連續動作空間
中圖分類號: TP301.6? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)04-0193-02
Abstract:Path planning is a classic problem in the field of artificial intelligence, which has been widely used in national defense, military, road traffic, robot simulation and other fields. However, most of the existing path planning algorithms have he problems of single environment, discrete action space, and need to build artificial models. Reinforcement learning is a machine learning method that interacts with the environment without providing training data manually, deep reinforcement learning more makes its ability to solve practical problems of the development of further ascension. In this paper, deep reinforcement learning algorithm DDPG (Deep Deterministic Policy Gradient) algorithm is applied in the field of path planning, which completes the task of path planning for continuous space, complex environment.
Key words:path planning;deep reinforcement learning; DDPG;Actor Critic;continuous action space
傳統算法如迪杰斯特拉算法[1]、A*算法[2]、人工勢場法[3]等。迪杰斯特拉算法是路徑規劃領域的經典算法,由迪杰斯特拉于1959年提出,迪杰斯特拉算法遍歷環境中的諸節點,采用貪心策略,每次擴展一個節點,遍歷結束可得起點到其余各點的最短路徑。A*算法在迪杰斯特拉算法的基礎上進行了改進,在節點擴展時加入啟發式規則,使得模型可以更快地收斂。雖然A*算法在諸多領域得到了諸多應用,但A*算法的應用場景局限在離散空間內。人工勢場法則模擬物理學中的電力勢場,在智能體與障礙之間設置斥力,智能體與目標之間設置引力,智能體沿著合力方向到達目標位置。勢場法可以完成連續空間的路徑規劃,然而各種場景的施力大小配比只能人工協調,最優配置難以求得,這種問題在復雜環境中尤為嚴重。強化學習是一種自主與環境交互的機器學習方式,強化學習無須人工提供訓練數據,通過不斷與環境交互獲得不同的回報來使模型收斂[4]。Mnih V在2013提出的DQN[5](DeepQNetwork)算法,為深度強化學習的發展奠定了基礎,自此不斷涌現出深度強化學習的諸多優秀算法。DDPG[6]算法結合了DQN、ActorCritic、PolicyGrient等策略,首先將深度強化學習引入到連續空間領域[7],本文采用DDPG算法實現連續復雜環境的路徑規劃。
1 基于DDPG算法的路徑規劃原理
1.1 DDPG算法
DDPG算法底層采用ActorCritic的結構,其結構圖如圖1所示。
將模型整體分為Actor和Critic兩部分,其中Actor為動作生成模型,以當前環境信息作為輸入,通過神經網絡計算生成一個動作值。Critic為評價模型,用以評價動作生成模型在當前環境下生成的動作,Critic模型將輸出一個評價值,用以協助Actor模型的收斂。此外DDPG也采用了PolicyGrident的學習方式,不同于常見的概率梯度,DDPG采用一種確定性的策略梯度,根據Actor生成的動作值直接選擇動作,而非采用softmax的映射方式依概率選擇動作。此外,DDPG采用DQN的結構理念,設計兩個結構相同參數異步更新的模型,利用時分誤差進行模型更新[8]。對于Policy模型,采用式(1)所示的模型進行更新。
本文為智能體配置掃描射線獲取環境信息,分別掃描環境中的墻體障礙、危險區域和安全出口,在本文中,前方設置5條射線,后方設置2條射線,總共組成21維的數據作為環境輸入。
1.2 環境回報
為了驗證本文算法處理復雜環境的能力,本文除了構建簡單的常見障礙之外,模擬環境中有某種險情發生的場景,在環境中構建了危險區域。對于普通障礙,對智能體只起到障礙作用,而智能體接觸危險區域將會死亡,回合結束,視為此次路徑規劃任務失敗。
為了使模型盡量在更少的決策次數內到達目標位置,設置智能體每多決策一步,給予一定的懲罰回報,設置Rstep=-1 對于普通的墻體障礙,對智能體只起到障礙作用,但是仍需防止智能體出現“撞墻”的行為,因此設置Rwall=-1 對于危險區域,智能體應該避開,設置Rdagenr =-50 安全出口為智能體的最終目標,應該設置全局最優回報,本文結合經驗與多次試驗結論,設定Rtarget =200
2實驗
2.1 環境搭建
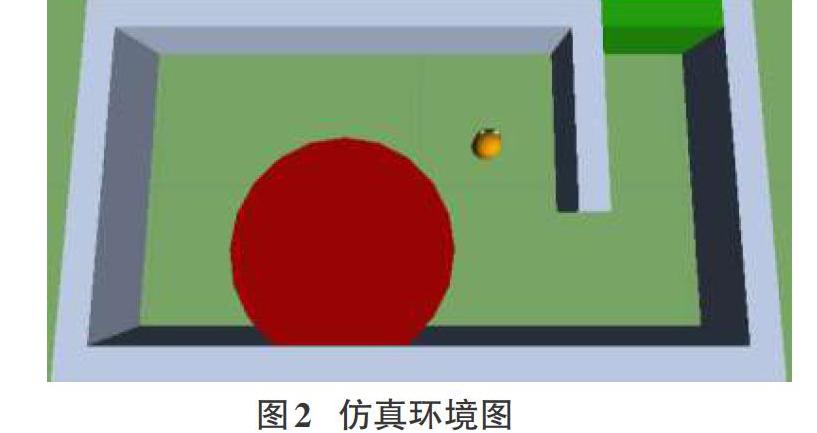
本文采用Unity 3D引擎進行環境,構建如圖2所示的環境。
利用Unity 3D引擎搭建如圖所示的環境,環境有20單位×10單位的矩形局域圍成,其中灰白色實體為墻體,紅色區域為危險區域,右上角綠色墻體部分為出口,圖中的黃色圓形實體為智能體。
2.2 模型訓練及結果分析
本文利用Python下深度學習框架Pytorch進行編程,運行環境為處理器Intel(R) Core 8750H,顯卡GTX1060。
模型在迭代500000回合后穩定在收斂狀態,此時智能體可以完成在環境中任意位置的路徑規劃。智能體路徑規劃效果圖如圖3所示。
訓練過程損失值變化如圖4所示。模型訓練過程中的平均回合回報(/1000步)變化圖如圖5所示。
由圖4可以看出,DDPG算法模型在訓練過程中逐步趨于收斂,說明利用深度強化學習算法DDPG進行路徑規劃具有可行性。結合圖5也可以看出,模型逐步向著回合回報增加的方向收斂,這說明模型在逐步克服路徑規劃過程產生的方向震蕩,最終平均回合回報趨于較高的平穩值,即代表所規劃的路線平滑且路程盡可能短。綜上所示,DDPG算法可以很好地完成路徑規劃任務。
3 結束語
本文將無須訓練數據的強化學習算法應用在路徑規劃領域,實現了連續、復雜環境下的路徑規劃任務。在諸多深度強化學習算法中,本文使用了在連續空間具有良好表現的DDPG算法來完成任務,實驗結果證明,DDPG算法應用在路徑規劃任務中的可行性與高效性。雖然本文取得了一定的成果,但是路徑規劃的維度是多方位的,動態環境下的路徑規劃將會是本文的一個拓展方向。
參考文獻:
[1] Dijkstra E W. A note on two problems in connexion with graphs[J]. Numerische mathematik, 1959, 1(1): 269-271.
[2] Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107.
[3] Borenstein J, Koren Y. Real-time obstacle avoidance for fast mobile robots in cluttered environments[C]. IEEE,1990:572-577.
[4] Lei X, Zhang Z, Dong P. Dynamic path planning of unknown environment based on deep reinforcement learning[J]. Journal of Robotics, 2018, 2018
[5] Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J]. arXiv preprint arXiv:1312.5602, 2013,
[6] Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J]. arXiv preprint arXiv:1509.02971, 2015,
[7] Bae H, Kim G, Kim J, et al. Multi-Robot Path Planning Method Using Reinforcement Learning[J]. Applied Sciences, 2019, 9(15): 3057.
[8] Lv L, Zhang S, Ding D, et al. Path planning via an improved DQN-based learning policy[J]. IEEE Access, 2019, 7: 67319-67330.
【通聯編輯:唐一東】
