可緩解類重疊問題的跨版本軟件缺陷預測方法
2021-03-23 09:33:24曲豫賓
吉林大學學報(理學版) 2021年2期
曲豫賓,陳 翔,李 龍
(1. 桂林電子科技大學 廣西可信軟件重點實驗室,廣西 桂林 541004; 2. 江蘇工程職業技術學院 信息工程學院,江蘇 南通 226001; 3. 南通大學 信息科學技術學院,江蘇 南通 226019)
軟件缺陷預測用于識別軟件開發過程中的軟件缺陷,軟件開發過程中產生的歷史數據構成了軟件缺陷預測分類器的訓練數據,這些數據可以從文件、類等多粒度進行標注[1-4]. 基于軟件開發過程,面向歷史數據的度量元用于構建分類模型,這些度量元包括基于代碼行數的度量元、Halstead科學度量以及McCabe環路復雜度等[4]. 傳統的項目內缺陷預測模型主要關注靜態度量元,基于度量元進行分類模型構建,基于潛在的有缺陷模塊應具有相同的統計分布特征. 但在實際軟件開發過程中,靜態度量元構建的分類器無法預測具有相同統計特征分布卻不同語義特征的代碼模塊,如JAVA代碼中Queue隊列的add,remove方法的先后順序雖然具有相同的統計分布特征,卻有明顯不同的語義特征. 通過使用自編碼網絡[5]、卷積神經網絡(CNN)[6]等深度學習框架能從源數據集中學習到語義特征,建立面向語義學習的軟件缺陷預測模型. 在實際訓練數據集標注過程中,擁有不同的數據標記卻在特征空間中有相同的特征,這種類重疊問題是由標注過程中多種因素導致的. 類重疊問題是數據挖掘以及機器學習中常見的問題,其影響了分類性能. 類重疊的訓練樣例模糊了分類邊界,增大了分類難度[7]. 很多應用領域都存在類重疊問題,如信用卡欺詐檢測和文本分類領域等. Chen等[8]提出了使用基于k近鄰的方法處理存在類重疊的樣例;文獻[7]提出使用改進的K-means聚類算法清理重疊樣例. 但這些策略都是基于傳統的靜態度量元進行的,而面向基于語義學習的軟件缺陷預測的類重疊問題研究目前報道較少.
基于此,本文將基于卷積神經網絡的深度學習框架應用到跨版本軟件缺陷預測中,提出一種面向跨版本軟件缺陷預測的深度學習框架,從前一個版本的歷史數據中根據抽象語法樹構建基于文件級別的特征語義向量;以該語義向量為基礎,改進數據抽樣策略,融合基于近鄰的樣例清理策略與基于K-means 算法的清理策略,對訓練數據集進行預處理,作為Logistic模型分類器的輸入訓練分類模型;將下一個版本軟件代碼作為測試數據集,用常見的AUC(area under curve)作為分類性能的評價指標,測試了該清理策略的有效性. 通過對實驗結果使用Friedman測試與Nemenyi后檢驗進行統計分析,證明該策略能解決類重疊問題,提升了基于深度語義學習特征的分類器性能.
1 面向深度語義學習的跨版本軟件缺陷預測
1.1 跨版本軟件缺陷預測中面向深度語義學習的整體框架
針對軟件缺陷預測過程中未充分使用源代碼語義特征以及訓練數據集中的類重疊問題,提出一種面向類重疊的跨版本軟件缺陷深度特征學習方法CnnSncr,該方法采用混合式最近鄰清理策略處理深度語義特征學習過程中的類重疊. 用該方法可自動地從源代碼中學習語義和結構特征,為分類器提供基于深度語義學習的特征向量. 該方法的整體流程如圖1所示.
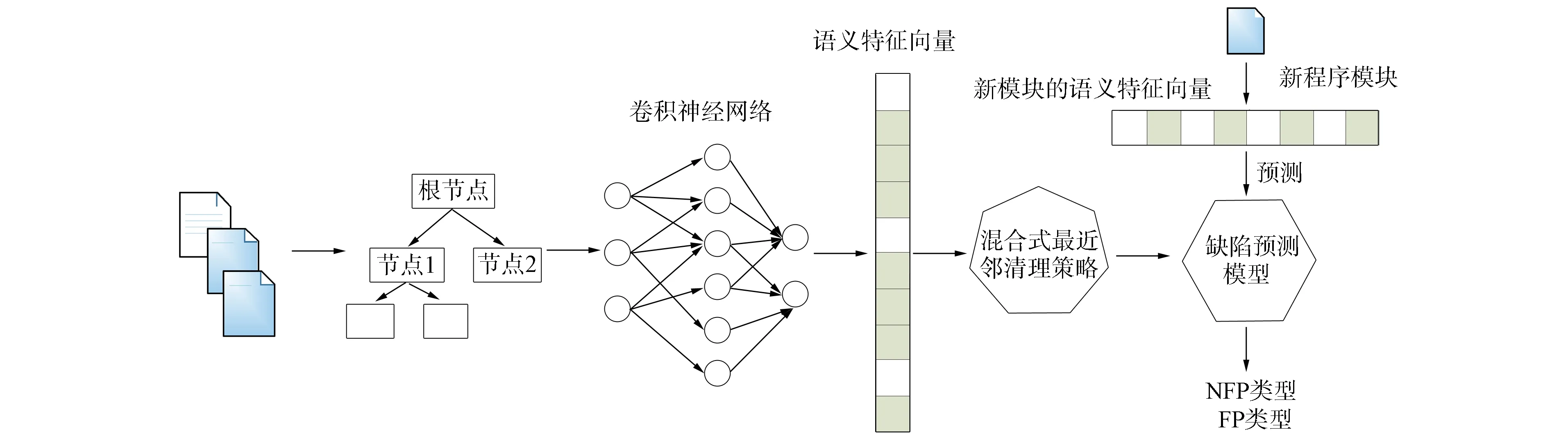
圖1 面向類重疊的跨版本軟件缺陷深度特征學習方法CnnSncr流程Fig.1 CnnSncr work flow of cross-version software defect deep feature learning method for class overlap
該方法首先從訓練數據集和測試數據集出發,構建抽象語法樹用軟件開發過程中發布的前一個版本的歷史數據作為訓練數據集,下一個版本的軟件開發數據作為測試數據集. 構建抽象語法樹過程中,選擇如圖2所示的具有代表性的語法樹節點[6]表示軟件模塊,每個軟件模塊構筑符號向量.
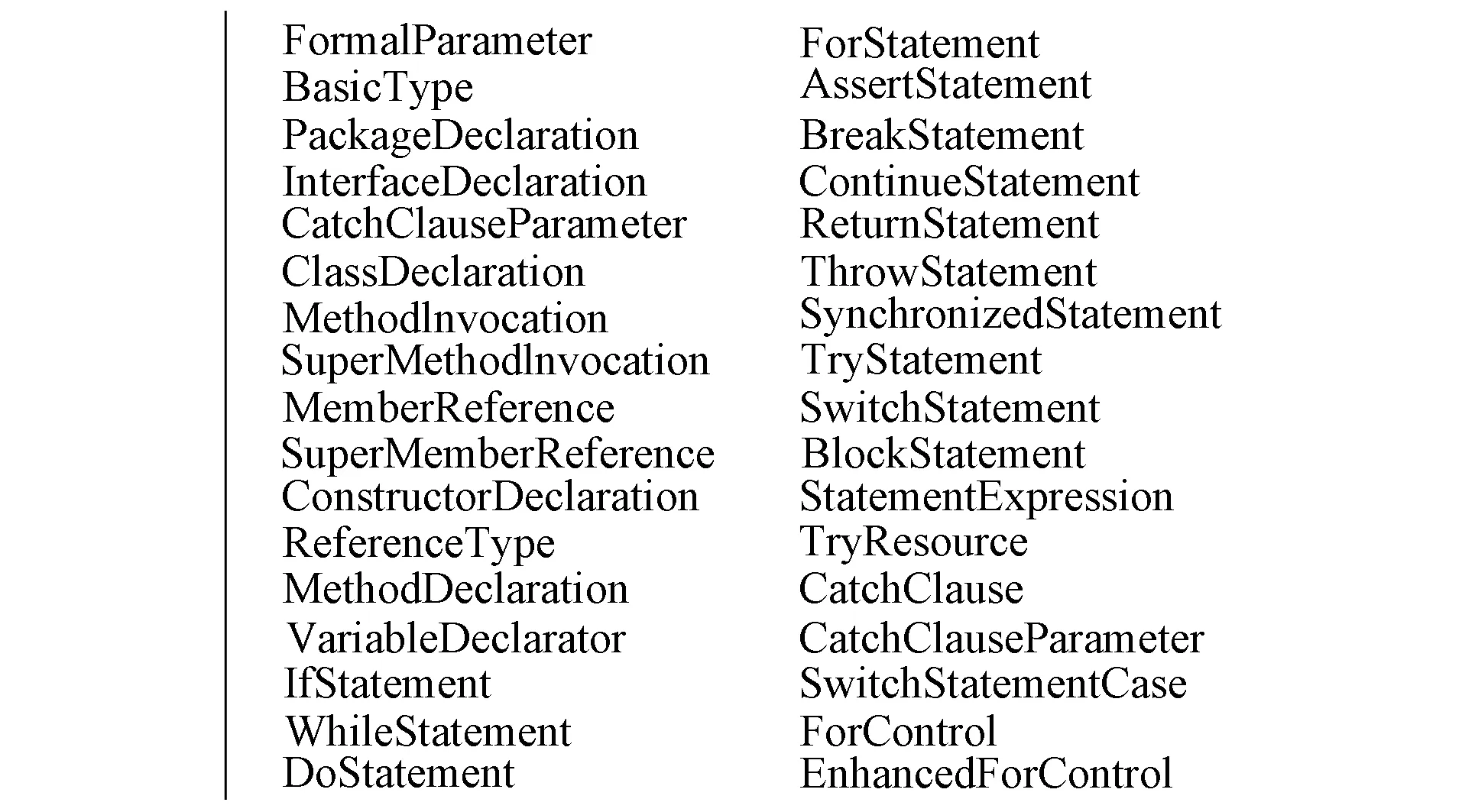
圖2 具有代表性的語法樹節點Fig.2 Representative syntax tree nodes
符號向量采用one-hot編碼方式進行編碼,先對輸入向量進行詞嵌入,作為卷積神經網絡的輸入,卷積神經網絡再從輸入向量中自動學習深度語義特征. 由于標注過程中存在噪聲,類重疊不可避免[7-8],因此需對深度語義特征進行預處理. 由于在軟件缺陷預測數據集中普遍存在類不平衡問題[9-10],因此需對訓練數據進行過采樣,而過采樣完的數據集可能會產生更多的類重疊. 從近鄰出發,對多數類和少數類同時進行清理,處理潛在的重疊軟件模塊向量. 將經過預處理的深度語義特征作為傳統分類器,如Logistic回歸分類器的輸入. 在Logistic回歸分類器上訓練分類模型,并對測試數據集進行測試.
1.2 基于卷積神經網絡的語義特征學習模型
卷積神經網絡具有深度特征提取的能力,基于源代碼使用one-hot編碼后的特征向量具有內在的語義和語法結構,通過引入卷積神經網絡能創建表征語義信息的新深度特征向量. 考慮到不同的源代碼之間文件大小差異較大,該卷積神經網絡框架既不同于文獻[8]使用的標準卷積神經網絡框架,也未采用在某些理論分析中使用的復雜學習框架[11-12]. 同時該框架與文獻[5]提出的基于深度信念網絡框架也有較大差異. 基于深度信念網絡的深度語義學習框架采用無監督學習模式,語義特征學習過程中訓練數據集并未參與梯度下降的優化過程. 本文提出的基于卷積神經網絡的語義特征學習模型采用有監督的深度語義學習模式,通過對訓練數據集的優化生成更適合當前項目的語義. 文獻[13]提出的采用代碼注釋嵌入的軟件缺陷語義學習框架與文獻[8]使用的標準卷積神經網絡框架均采用卷積神經網絡,在軟件缺陷預測相關研究中取得了較好的效果.
假設當前軟件項目有n個文件數目:X={x1,x2,…,xn},則軟件缺陷預測問題可被形式化為學習任務,該學習任務從訓練數據集中學習預測函數為
F:X→Y,yi∈Y={1,0},
(1)
其中yi∈Y,表示軟件模塊是否含有軟件缺陷. 深度特征語義向量生成總體過程如圖3所示.

圖3 深度特征語義向量生成過程Fig.3 Deep feature semantic vector generation process

將訓練過的詞嵌入向量作為卷積神經網絡的輸入. 在輸入方向設置多個一維卷積核,從詞嵌入向量中提取單詞的特征,并將輸出結果輸入到池化層. 為對優化過程中的參數進行約束,引入正則化,采用dropout方法在反向傳播誤差更新權值時隨機刪除部分神經元. 對池化層輸出展開為全連接層,多次迭代訓練得到語義特征向量. 訓練過程中采用小批量梯度下降算法[15],選用Adam優化器[16]. 基于該語義特征向量判斷當前模塊是否存在缺陷.
1.3 面向深度語義學習的混合式最近鄰清理策略
基于卷積神經網絡的深度語義學習模型,能從軟件開發過程中的源代碼學習到語義特征. 軟件缺陷模塊標注存在特征相同但標記不同的情況,稱為類重疊[7-8],類重疊問題也存在于文本分類[17]等領域. 文獻[7-8]針對軟件缺陷預測研究了類重疊問題對跨項目軟件缺陷預測等的性能,提出了用NCL(neighborhood cleaning learning)和IKMCCA(improvedK-means clustering cleaning approach)策略緩解該問題. 但這些策略并未針對深度語義特征中存在的類重疊問題進行研究,同時對普遍存在的類不平衡問題也僅使用了消除潛在缺陷模塊類的方式獲取數據集的平衡. 基于此,本文提出使用混合式的策略SNCR(special neighborhood cleaning rule)解決類重疊問題. 該策略的偽代碼如下.
算法1混合式最近鄰策略(SNCR).
步驟1) 輸入: 訓練數據集T={Cmax,Cmin},其中Cmax屬于多數類,Cmin屬于少數類,d表示有缺陷模塊與所有模塊數目的比值;
輸出: 清理完成的數據集T′={C?max,C?min};
步驟2) 遍歷Cmin集合中的每個樣例;
步驟3) 利用歐氏距離選擇k最近鄰;
步驟4) 選擇樣例xi(nn),生成隨機數δ∈{0,1};
步驟5) 利用當前樣例與xi(nn)生成新樣例xi1=xi+δ(xi(nn)-xi);

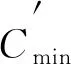
步驟8) 根據預定義的歐氏距離計算與當前樣例最近的Nx個樣例;
步驟9) 如果Nx中任意一個樣例包含于集合Cmax,則刪除該樣例;


步驟14) 使用標準K-means算法將數據集分為k簇;
步驟15) 循環遍歷每個簇;
步驟17) 如果當前比值 ?′>?,則刪除當前簇中少數類;
步驟18) 如果當前比值 ?′
步驟19) 合并所有簇中的剩余樣例為新的輸出集合T′.
該策略以生成的深度語義特征向量集合為輸入,根據集合中標記的不同,將樣例分為Cmax和Cmin兩類,算法過程主要分為如下三步:
1) 對少數類樣例循環遍歷,根據歐氏距離選擇k個最近鄰,并使用隨機種子數在某個樣例與最近鄰之間生成新的樣例,迭代完成過采樣,實現多數類與少數類之間的平衡,解決類不平衡問題;
本文提出SNCR策略的目的是由于軟件缺陷深度語義數據集包含大量數據,并且類重疊的問題不可避免,僅對多數類別進行欠采樣解決類別不平衡問題是不合理的. 首先利用過采樣使不同類型直接達到數據平衡. 同時,過采樣也可能導致更多的類重疊. 此時,對當前多數類和少數類執行最近鄰居學習,并消除潛在的類重疊實例. 由于深度語義數據量相對較大,因此除使用上述最近鄰方法查找潛在的類重疊實例外,還可以通過引入標準K-means算法分析當前數據集. 對數據集執行聚類分析,并刪除每個集群中的異常實例.
2 實 驗
本文實驗在至強E5-2670的CPU與16 GB內存的工作站上完成,同時在NVIDIA GeForce RTX 2070的GPU上訓練深度神經網絡并進行分析處理. 實驗中使用的相關分類器來源于scikit-learn,深度神經網絡庫采用TensorFlow 2.0穩定版本. 卷積神經網絡的輸入向量維數為93維,經過詞嵌入后輸出為20維. 源數據集作為訓練數據時,對數據集進行了隨機分層抽樣,共訓練1 000個批次,每個批次的樣例數目為1 024個.
2.1 實驗數據集
實驗采用的軟件缺陷預測數據集來源于PROMISE數據庫(http://openscience.us/repo/defect),該數據集為公開的數據集,廣泛應用于軟件缺陷預測中. 選擇該數據集中7個開源的JAVA軟件項目進行實驗,因為每個軟件項目的版本號、類名稱、相關標記都是確定的,與類名稱相對應的源代碼從GitHub上下載并進行分析處理. 實驗中所用7個項目的項目描述、版本號、缺陷模塊比例等信息列于表1. 為獲取項目中需用的訓練數據集和測試數據集,參考文獻[18]方法,將前一個版本的源代碼作為訓練數據集,將下一個相鄰版本的源代碼作為測試數據集. 本文實驗中未使用傳統基于統計的軟件缺陷特征.

表1 實驗所用數據集中項目信息
2.2 評價指標及數據統計分析方法
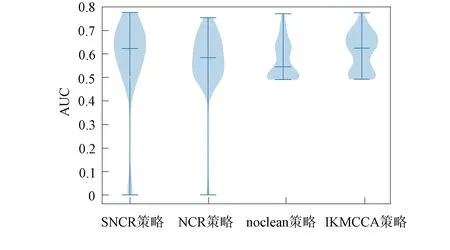
圖4 不同策略使用AUC指標對比的小提琴圖Fig.4 Comparison of violin plot of AUC index for different strategies
基于軟件缺陷預測數據集中常見的類不平衡問題,選擇AUC作為分類器性能的評價指標. AUC定義為ROC曲線與坐標軸所包圍的區域,最大值不能超過1,AUC值越接近1,則分類器檢測的真實性越高; 反之,當AUC接近最小值0.5時,則沒有應用價值. 本文首先使用Friedman測試確定不同數據處理策略之間是否存在統計學上的顯著差異,如果存在統計學上的顯著差異,則應用post-hoc Nemenyi測試比較差異.
2.3 實驗中用到的類重疊處理策略
為比較類重疊對基于深度語義的軟件缺陷預測分類性能的影響,將SNCR策略與IKMCCA策略以及NCR策略的性能進行對比. 為使實驗結果更具說服力,將以上3種數據預處理策略與無數據預處理的情況進行比較,該策略被記為noclean策略.
2.4 實驗結果分析
使用IKMCCA和SNCR策略時,算法中的超參數值p%被設定為少數類與多數類之比. 不同數據處理策略的性能對比小提琴圖如圖4所示. 由圖4可見,使用SNCR策略可獲得Logistic回歸模型分類器上AUC度量的最佳中值,即與noclean策略相比,清洗策略解決類重疊問題性能更優;與IKMCCA和NCR策略相比,SNCR策略在7個開源項目組成的數據集上性能更好.
評價指標的圖形顯示不能量化表明不同策略的直接差異,同時,為基于統計學比較差異訓練數據集上不同策略的性能,使用置信度為95%的非參數Friedman測試對實驗結果進行統計分析. 假設:
(H0) 基于深度學習學出的語義特征,不同針對類重疊問題的數據預處理方法不存在性能差異;
(H1) 基于深度學習學出的語義特征,不同針對類重疊問題的數據預處理方法存在性能差異.
設顯著性水平α=0.05,計算結果表明,計算值小于臨界值,因此條件(H0)不成立,從而這4種策略間存在統計差異. 為揭示不同策略間的差異,進一步采用post-hoc Nemenyi測試分析方法,使用4種數據處理策略的AUC指標結果列于表2.

表2 4種不同策略的AUC指標計算結果
綜上所述,類重疊問題的結果是語義特征向量在特征空間中重疊,這種模糊性削弱了分類器的邊界,并導致分類器性能下降. 因此,以解決深度語義特征學習和清除噪聲為目標,本文提出了一種SNCR策略,并通過實驗證實了該策略解決類重疊問題可有效提高分類器的性能. 在PROMISE公開數據集上進行測試的結果表明,采用混合式最近鄰清理策略能處理類不平衡問題與類重疊問題. 對數據的統計分析結果表明,該策略能提升基于深度語義學習的軟件缺陷預測性能,AUC指標最多在中值上提升14.8%. 軟件質量保障問題包括:軟件缺陷中的語義學習問題[18]、跨項目軟件缺陷預測問題[19]、軟件缺陷分析算法[20]、隨機測試方法[21]、惡意軟件分類[22]、基于機器學習的項目缺陷預測方法[23-24]等,其中基于機器學習的方法需要高質量的數據樣例,在訓練數據集中應該存在盡可能少的數據噪聲,采用本文提出的SNCR策略,能構建更高質量的訓練數據集,提升模型的準確度.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
