融合發音動作特征和聲學特征的病理語音檢測
2021-03-23 09:38:50薛珮蕓
計算機工程與設計 2021年3期
王 頗,白 靜,薛珮蕓
(太原理工大學 信息與計算機學院,山西 晉中 030600)
0 引 言
聽障患者普遍存在構音障礙問題,由于聽功能損失,患者缺乏聽覺對發聲的反饋作用,導致其發音部位不準確,發音動作不協調,進而出現異常發音[1]。對于聽障患者病理語音的檢測,語音信號處理技術提供了一種非入侵性的方法,通過提取語音的特征參數并進行模式識別,可以高效地對正常語音和病理語音進行分類,能夠輔助醫生對病理語音患者進行診斷和治療[2]。
目前,根據病理語音特征實現計算機自動診斷仍然是醫學工作者和語音研究工作者努力的方向。Fang Shih-Hau等[3]采用美國的MEEI數據庫,結合梅爾倒譜系數(Mel frequency cepstrum coefficient,MFCC)和深度神經網絡進行病理語音檢測。由于語音信號具有非平穩性和突變性,李海峰等[4]提出一種基于S變換的病理語音特征MSCC,使用荷蘭的NSNC病理數據庫驗證了所提方法的有效性。關于漢語病理語音的研究,龐宇峰等[5]采集臨床聲帶息肉患者和正常人的語音數據,分析基頻微擾、振幅微擾等特征差異。許遠靜等[6]使用自建庫,提取熵、Hurst參數、吸引子等非線性特征,結合隨機森林算法(random forest,RF)識別不同程度病態嗓音。以上研究表明病理語音檢測的特征比較豐富,但是這些特征集中于語音聲學特性的研究,忽略了語音產生過程中發音器官的運動特性。
近年來,三維電磁發音儀(electromagnetic articulograph,EMA)[7]在語音研究領的應用增多,Zhang Yan等[8]采集舌、唇、頜部的運動數據,分別以鼻梁和上唇為參考點,計算下唇、舌尖、舌中的相對位置作為發音動作特征(articulatory movement features,AMF),進行短時文本的說話人識別。蔡明琦等[9]指出相比聲學特征,語音的發音動作特征描述了發音過程中唇、舌等發音器官的位置變化,它們不受外界噪音和環境的影響,具有更高的魯棒性。因此本文分析病理語音的發音動作特征,提取發音動作特征以及聲學特征進行融合,使用核主成分分析法進行降維,在支持向量機(support vector machine,SVM)、隨機森林、多層感知機(multilayer perceptron,MLP)分類模型中,驗證發音動作特征和融合特征的有效性。
1 語音特征參數提取
1.1 發音動作特征
文中發音器官的運動數據使用三維電磁發音儀采集,該設備可以捕獲高精度的運動信號,并且不損害人體,是采集發音器官微小動作的專用設備。在EMA系統中,每個傳感器對應一個通道,數據采集前,對傳感器進行預熱、校準,然后將傳感器黏貼在受試者的唇部(上唇、下唇、左嘴角、右嘴角)、舌部(舌尖、舌中、舌后)、頜部進行數據采集,同時在鼻骨、左耳骨、右耳骨、下齒槽分別黏貼傳感器作為參考傳感器,用來消除發音過程中頭部轉動影響。發音動作數據采樣頻率為250 Hz,語音數據與發音動作數據同步采集,采樣頻率為16 KHz。EMA記錄了每個傳感器三維空間(X軸、Y軸、Z軸)坐標,X表示前后方向,Y表示左右方向,Z表示上下方向。發音器官的左右方向的運動幅度較小,因此使用X軸、Z軸的數據進行分析。
研究表明,聽障患者發音時舌部運動不到位是影響其發音的重要因素,王晴等[10]研究聽障患者的鼻韻母發音時,發現部分發音的舌位偏高或者偏低,與正常人發音的舌部運動存在差異。本文畫出正常人和聽障患者分別發單元音/a/時,舌尖和舌中在X軸、Z軸上的運動軌跡,如圖1和圖2所示。
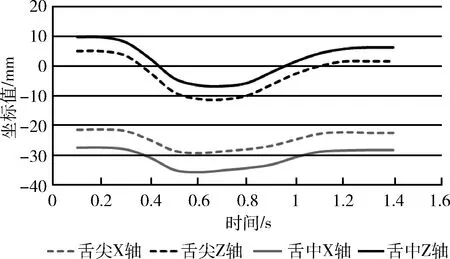
圖1 正常人發元音/a/的舌部運動軌跡
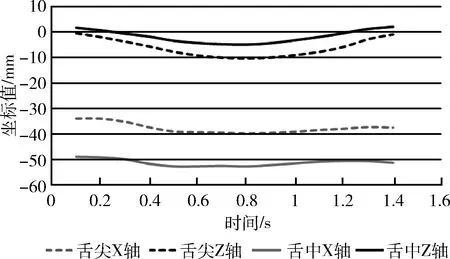
圖2 聽障患者發元音/a/的舌部運動軌跡
圖中可以看出聽障患者發音時舌尖、舌中的運動幅度比正常人較小,這和之前的研究相符合。因此提取舌尖、舌中部位的運動位移和速度作為特征,位移特征指相對于初始位置,傳感器的最大位移,計算公式如下
sX=max|x(t)-x(0)|
(1)
sZ=max|z(t)-z(0)|
(2)
式中:sX表示X軸最大位移,x(t)表示t時刻傳感器的X軸坐標值,x(0)表示初始時刻傳感器的X軸坐標值,sZ表示Z軸最大位移,z(t)表示t時刻傳感器的Z軸坐標,z(0)表示初始時刻傳感器的Z軸坐標。
速度指發音器官在每一時刻位移變化量,通過式(3)、式(4)進行計算,將最大速度、最小速度、平均速度和速度的方差作為特征
(3)
(4)
式中:vX表示X軸瞬時速度,x(t+Δt)表示t+Δt時刻的X軸坐標值,x(t)表示t時刻的X軸坐標值。vZ表示Z軸瞬時速度,z(t+Δt)表示t+Δt時刻的Z軸坐標值,z(t)表示t時刻的Z軸坐標值。
1.2 聲學特征
梅爾倒譜系數是語音識別領域常用的特征,它基于人耳的聽覺特性,在梅爾刻度下,人耳對聲音頻率的感知度成線性關系,它與頻率的關系可表示為
Mel(f)=2595lg(1+f/700)
(5)
式中:f表示實際的語音頻率,單位是Hz。
如果把聲道看作理想的諧振腔體,舌頭的運動會改變聲道的形狀,進而影響諧振頻率,即共振峰。在語音學中,第一共振峰與舌位高低呈負相關關系,第二共振峰與舌位前后呈正相關關系。由聽障患者發音動作特征可知患者發音時舌部運動不到位,這必然會影響語音的共振峰,因此本文提取共振峰特征進行病理語音檢測。
基頻反映了發音者音調的大小和音質的好壞,基頻的大小與聲帶的長度、厚度、張力有關,并且受到聲門上下之間的氣壓差效應的影響,是病理語音研究中的重要特征。聽障患者由于發音部位不準確、發音動作不協調,基頻特征與正常人存在差異。
1.3 特征融合
發音動作特征描述發音器官的運動特性,聲學特征描述語音的頻譜特性,兩種類型的特征表達的物理意義不同,將他們進行歸一化處理構成融合特征,即SVMFP特征。融合特征可以表示為
(6)

由于上述的融合特征可能包含冗余信息,本文使用核主成分分析法(kernel principal component analysis,KPCA)對其進行降維,降維后的特征表示為KSVMFP。KPCA是在PCA的基礎上提出,相比PCA,KPCA在處理非線性數據方面效果更好。它的基本原理是通過非線性函數將原始數據映射到高維空間,從而對高維空間的數據進行相應的線性分類。本文采用徑向基高斯核方法進行降維,核函數公式如下
(7)
σ取常數,在降維過程中需要對σ進行調節。
在降維過程中,將訓練樣本的n維特征表示成n個列向量的特征矩陣α,通過非線性映射Φ將其映射到高維空間中
Φ(α)=[Φ(α1),Φ(α2),…,Φ(αn)]
(8)
在高維空間進行降維變換
X=WTΦ(α)
(9)
求解Φ(α)之后得出非線性降維后的特征矩陣X。
2 多層感知機
聽障患者病理語音檢測的MLP拓撲如圖3所示。MLP的層次結構為5層,隱含層為3層,每層包括64個神經元。
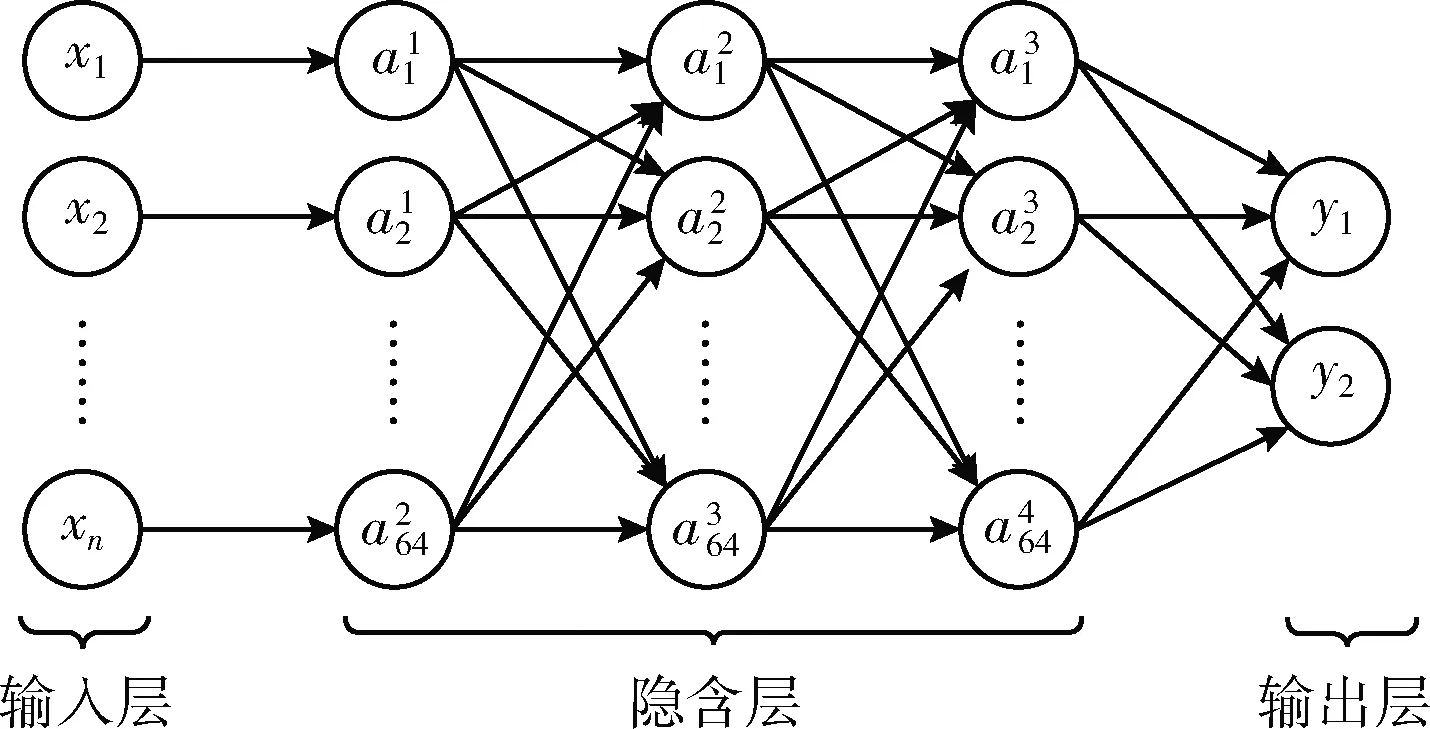
圖3 MLP拓撲
隱含層中神經元的輸入和輸出如下所示
al=σ(zl)
(10)
zl=Wlal-1+bl
(11)
式中:al表示第l層神經元輸出,σ表示激活函數,zl表示第l層神經元的輸入,W表示第l-1層神經元與第l層神經元之間權值組成的向量,bl表示第l層偏置組成的向量。
本文使用的激活函數為Leaky ReLU,如式(12)所示

(12)
相比ReLU[11],Leaky ReLU函數對負值輸入有很小的坡度,可以減少靜默神經元的出現,允許神經元緩慢學習;在正半區和ReLU具有相同的特性,當輸入信號超過閾值時,神經元進入激活狀態,可以選擇性響應部分輸入信號,屏蔽不相關信號,提取出重要的稀疏特征。
通常在模型的訓練過程中,使用交叉熵形式的代價函數描述模型的分類精度,形式如下
(13)
式中:y為預測概率值,y′為真實概率值。H(y)越小,模型的輸出值與真實值差距越小,分類越準確。通過訓練,H(y)逐漸減小,最終達到全局最優或局部最優。在神經網絡的參數訓練方法中,隨機梯度下降(stochastic gradient descent,SGD)是最常見的優化方法,但是它對所有的參數更新使用同樣的學習率,因此選擇合適的學習率比較困難,設置不同的學習率,可能產生差異較大的結果。本文使用Adagrad算法[12]自適應地訓練參數。
3 病理語音檢測流程圖
病理語音檢測流程如圖4所示,對病理語音數據庫中的數據預處理后,提取位移、速度兩種發音動作特征以及MFCC、基頻、共振峰3種聲學特征,然后將提取的特征歸一化,使用KPCA降維,結合MLP完成病理語音和正常語音的分類。
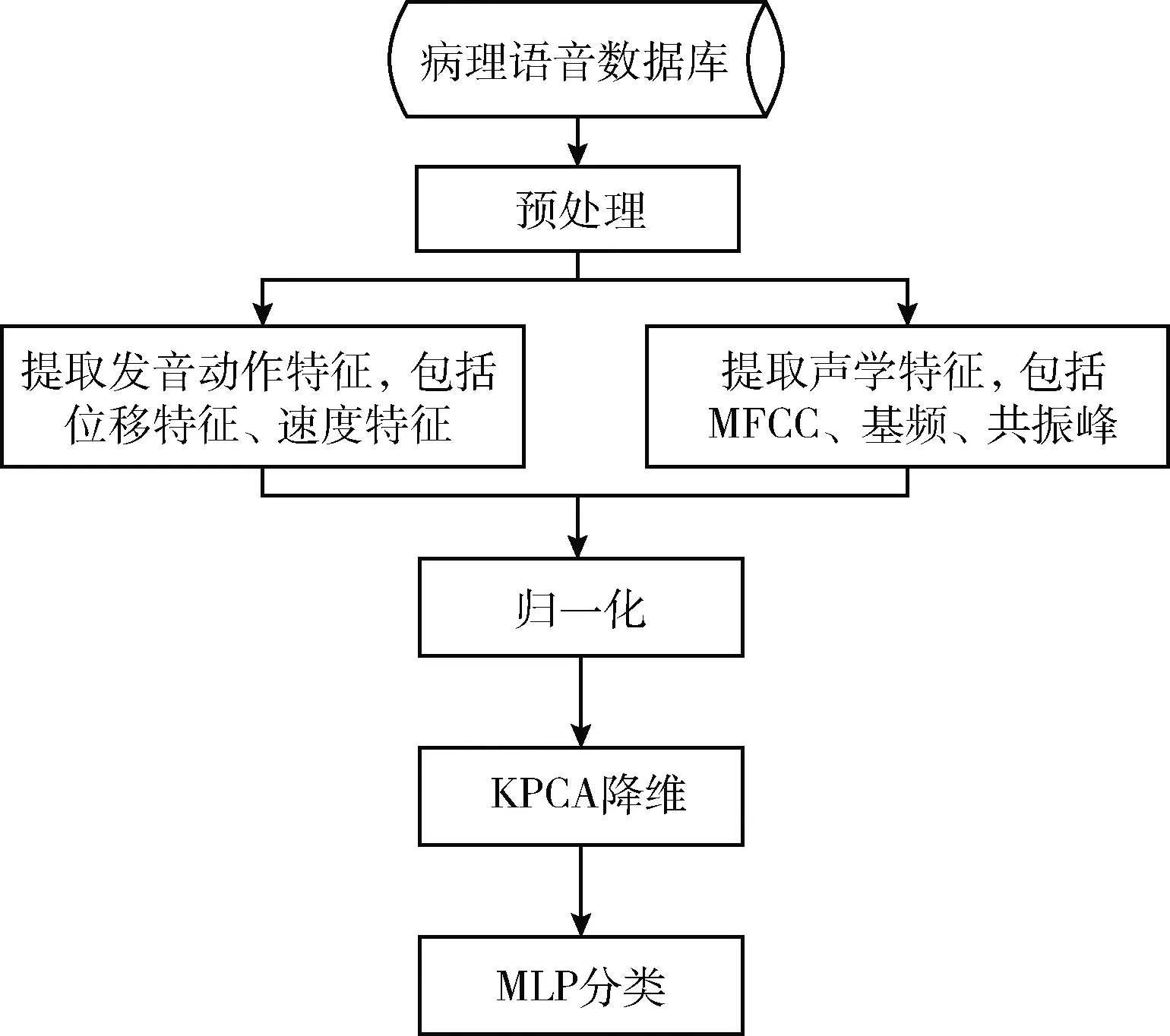
圖4 病理語音檢測流程
4 實 驗
4.1 實驗數據
實驗數據庫為實驗室自建庫,其中包括聽障學生和正常學生的數據,聽障學生在太原市聾啞學校隨機選取,男、女各5名,共10名,除聽力受損外,全身無其它畸變,能自主發音。正常學生為在校大學生,男、女各5名,共10名,普通話水平均為二級甲等及以上,測試期間均無呼吸道感染。數據庫語料為普通話水平測試用表的常規發音,本文對采集的數據進行篩選,結果見表1。

表1 病理語音檢測語料
4.2 實驗結果及分析
當測試語料為漢語字母和漢語單音節時,將發音動作特征和不同聲學特征輸入不同分類模型,測試不同特征和分類模型組合的分類性能。分類模型的參數設置如下:SVM的核函數為RBF核,使用鳥群算法[13]優化參數;MLP激活函數為Leaky ReLU,使用Adagrad優化網絡參數;RF中子樹的數量為100。實驗中字母的樣本總數為520,單音節的樣本總數為780。使用五折交叉驗證得出最后的實驗結果,采用靈敏度(sensitivity)、特異度(specificity)、識別率(accuracy)3個指標對分類結果進行評價。
4.2.1 單一特征的實驗結果
當測試語料為漢語字母和漢語單音節時,單一特征的檢測效果分別見表2和表3。
由表2可知,①在MLP中,MFCC的特異度比發音動作特征低,靈敏度和識別率比其它特征高;在SVM和RF中,MFCC的靈敏度、特異度、識別率比其它特征高;從整體上看,MFCC的檢測效果最佳。②在SVM中,發音動作特征的靈敏度、特異度、識別率比基頻和共振峰高;在RF中,發音動作特征的靈敏度比共振峰低,特異度比基頻低,識別率比基頻和共振峰高;在MLP中,發音動作特征的靈敏度比共振峰低,特異度和識別率比基頻和共振峰高;從整體上看,發音動作特征的檢測效果優于基頻和共振峰。③在SVM中,共振峰的靈敏度、特異度、識別率比基頻高,共振峰優于基頻;在RF中,基頻的靈敏度比共振峰低,特異度、識別率比共振峰高,基頻優于共振峰;在MLP中,共振峰的特異度比基頻低,靈敏度、識別率比基頻高,共振峰優于基頻。
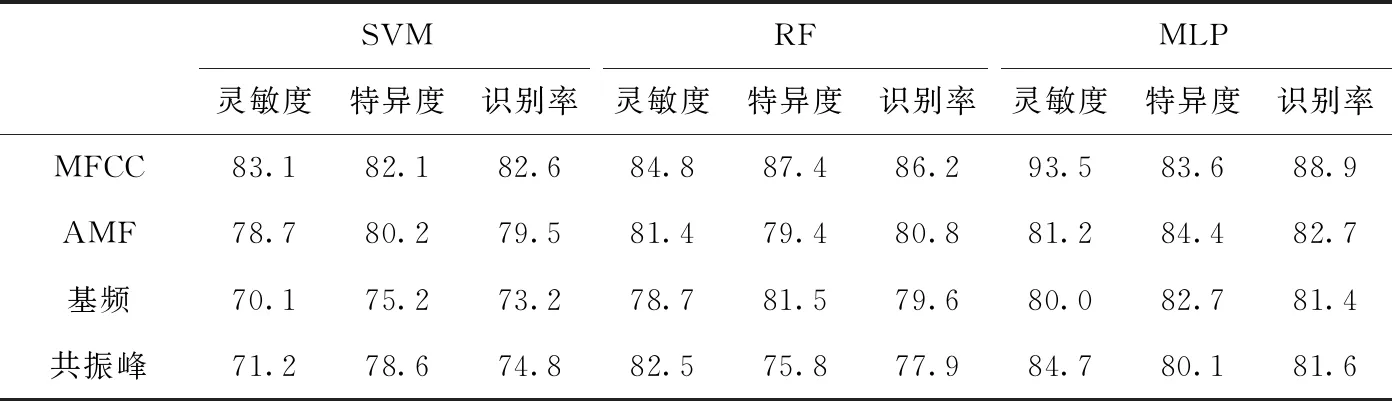
表2 漢語字母的單一特征檢測效果對比/%
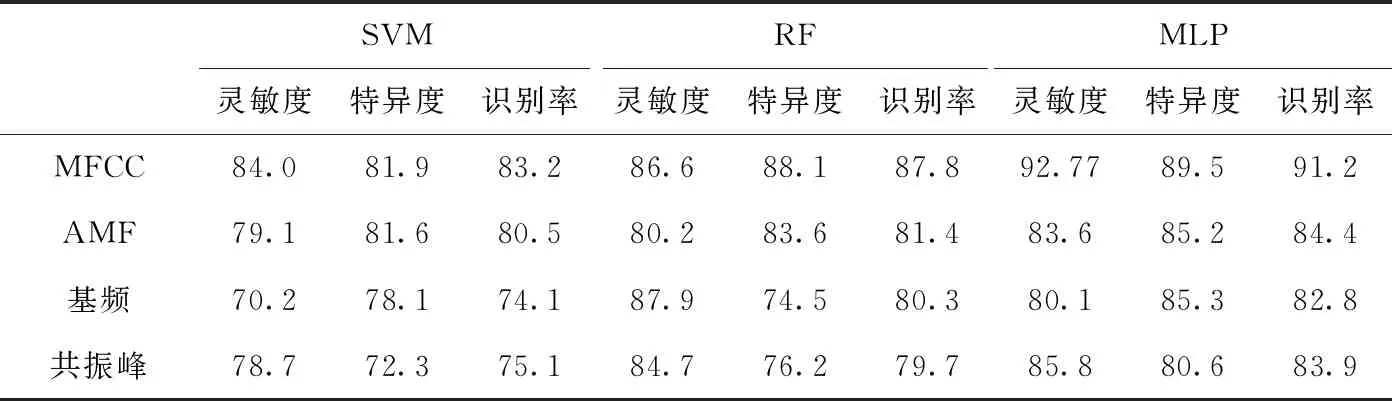
表3 漢語單音節的單一特征檢測效果對比/%
由表3可知,①在RF中,MFCC的靈敏度比基頻低,MFCC的特異度和識別率比其它特征高;在SVM和MLP中,MFCC的靈敏度、特異度、識別率比其它特征高;從整體上看,MFCC的檢測效果最佳。②在SVM中,發音動作特征的靈敏度、特異度、識別率比基頻和共振峰高;在RF中,發音動作特征的靈敏度比基頻低,特異度、識別率比基頻和共振峰高;在MLP中,發音動作特征的特異度比基頻低,靈敏度和識別率比基頻和共振峰高;從整體上看,發音動作特征的檢測效果優于基頻和共振峰。③在SVM中,共振峰的特異度比基頻低,靈敏度、識別率比基頻高,共振峰優于基頻;在RF中,基頻的特異度比共振峰低,靈敏度、識別率比共振峰高,基頻優于共振峰;在MLP中,共振峰的特異度比基頻低,靈敏度、識別率比基頻高,共振峰優于基頻。
表2和表3的結果表明,相比其它單一特征,MFCC在病理語音檢測中效果最佳,發音動作特征比MFCC的檢測效果差,但是比基頻和共振峰的檢測效果好,說明發音動作特征和聲學特征同樣有效。聲學特征表示語音不同方面的聲學特性,而發音動作特征能夠有效地表示發音器官在發音過程中的運動信息,兩類特征表達的物理意義不同,互為補充特征。此外,基頻和共振峰的檢測效果比較結果不固定,在RF中,基頻的檢測效果優于共振峰,在SVM和MLP中,共振峰的檢測效果優于基頻,說明單一特征對語音的表達不充分、魯棒性較差。
4.2.2 融合特征的實驗結果
為彌補單一特征表示語音特性的不足,本文將發音動作特征和聲學特征歸一化融合,并使用KPCA進行降維,特征歸一化和KPCA降維的檢測效果分別見表4和表5。

表4 漢語字母的融合特征檢測效果/%

表5 漢語單音節的融合特征檢測效果/%
對比表2和表4、表3和表5的結果,可以得出無論測試語料是漢語字母還是漢語單音節,在SVM、RF和MLP中,融合特征的靈敏度、特異度、識別率比單一特征高,說明融合特征的檢測效果優于單一特征,可以更充分地表示語音的特性。對比特征歸一化和KPCA降維的檢測效果得出,特征KPCA降維后檢測效果更佳,說明特征的歸一化融合存在信息冗余,經過非線性降維能夠消除冗余達到最佳的檢測效果。
此外,在表2、表3、表4、表5中,不同特征作為輸入時,對比SVM、RF、MLP的檢測結果,可以得出MLP的檢測效果最佳,說明MLP將特征進行抽象的轉換,具有更強的擬合能力,提高了病理語音的檢測效果。文中漢語字母的最佳識別率達到94.5%,漢語單音節的最佳識別率達到95.2%。
5 結束語
病理語音自動檢測技術的研究日益重要,它可以有效地減少病理語音診斷過程中人力物力的投入。目前,雖然聲學特征的研究成果豐富,但仍不能滿足臨床要求,并且單一特征對病理語音和正常語音的差異表示不足,因此,本文提出一種融合發音動作特征和聲學特征的方法用于聽障患者病理語音的檢測。實驗結果表明發音動作特征和聲學特征同樣有效,融合特征彌補了單一特征的不足,使用KPCA降維消除了特征之間的冗余信息,提高了檢測效果,本文的方法為醫學臨床的自動診斷技術提供了參考。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
