無人機與深度學習在建筑物實時檢測中的應用
2021-03-25 02:09:34張陽陽孫晨帆
軟件導刊 2021年3期
張陽陽,詹 煒,孫晨帆
(長江大學計算機科學學院,湖北荊州 434023)
0 引言
本文基于深度學習方法,通過無人機采集城市建筑圖像,經過篩選和標注構造數據集,在tensorflow 深度框架下構建神經網絡對建筑圖像數據集進行訓練,得到高魯棒性的檢測模型,從而實現對目標建筑物的實時檢測。
在深度學習技術出現以前,傳統的建筑監測方法主要是利用遙感影像數據檢測[1],由人工對遙感影像[2]進行解釋。對違建問題由群眾監督舉報,再由主管執法部門到現場確認,其缺點顯而易見:①取證難;②成本高,巡查速度慢、效率低;③發現、過程處理及事后監管難,易反復。識別違章建筑的關鍵是檢測建筑物的變化情況。早期建筑物變化檢測大都通過人工解釋,效率較低且存在建筑物遺漏問題。
20 世紀90 年代以來,學者通過遙感影像數據檢測城市建筑物變化。通過分析在相同地區不同時間段所獲取的遙感圖像中光譜的變化情況,比較不同時間段圖像的差異從而檢測發生變化的地物并區分變化類別[3]。該方法實現路線是:首先計算同區不同時段兩期影像的變化矢量,然后利用直方圖閾值、貝葉斯最小錯誤率、經驗公式、人工判別等閾值法設置變化量閾值,將遙感影像分為變化區域和未變化區域兩部分,最后通過分析變化區域內像素的變化方向對變化類別進行區分。基于遙感影像的城市建筑物變化檢測方法缺點是:①該方法是一種對比方法,需要規劃部門提供原始的建筑物規劃數據用于對比,規劃數據難以獲得;②遙感影像成本高,分辨率低;③對比算法的很多參數和閾值需要人工定義,影像檢測效果較差。
近年無人機航測航拍科技、深度學習和計算機視覺技術的蓬勃發展,為建筑的快速準確識別提供了新的檢測和監控技術手段[4],提高了城市建筑的識別效率[5],降低了管理成本,提升了城市建筑管理水平,為構建智慧城市提供了理論和技術支持。
本文針對傳統的城市建筑物檢測方法缺陷,創新性提出城市管理中應用無人機視覺數據深度學習識別技術的新方法,利用最前沿的深度學習算法[6]實時分析無人機拍攝的視頻流,自動識別目標區域各種建筑物或城市中的特定目標,為城市管理提供一種全新的技術手段[7]。該方法實施步驟如下:①編程操控無人機飛控平臺API 接口,設定飛行區域及參數,根據設定的參數引導無人機至目標區域內采集訓練所需要圖像數據,篩選有用的圖像數據建立深度神經網絡訓練所需的數據集;②設計合適的網絡結構,通過第①步制作的“城市管理平臺”數據集訓練深度神經網絡;③深度學習算法訓練的檢測器自動識別目標區域內的建筑物并標記,為后續城市管理提供決策支持,提高城管執法精準性和效率。
1 相關工作
目前,計算機視覺已廣泛覆蓋工業、醫療、軍事、農業、商業等領域,與人們的社會活動緊密相連。作為基礎的技術支持,深度學習和計算機視覺與人工智能的發展緊密相關。
深度學習和計算機視覺技術是人工智能技術的重要分支。計算機視覺用計算機模擬人視覺神經處理圖像,通過計算機設備實現人的視覺功能,從而認識、分析外界環境。簡而言之,物體識別、物體定位以及對于物體運動狀態進行判斷是深度視覺系統主要解決的3 個問題。計算機視覺作為計算機的眼睛,是機器認識外部環境、分析外部環境的一種方式。而認識、分析外部環境是實現人工智能不可或缺的重要部分。看見是第一步,只有看見才能進一步去分析然后做出判斷,進而代替人類完成各種任務。它與語音識別一起構成人工智能的感知智能,賦予機器探測外部世界的能力,進而做出判斷,采取行動,讓更復雜層面的智慧決策、自主行動成為可能。
深度學習視覺算法在檢測精度方面可以做到傳統視覺識別方法無法企及的高度。不同于傳統的機器學習,深度學習網絡包含了更多的隱層結構,通過多層隱層網絡的復雜連接,不斷加深網絡層數,可更加深入地挖掘訓練數據之間的內在聯系,實現復雜函數的近似逼近,通過建立魯棒性更高的模型對非標簽數據進行預測。深度網絡往往擁有比淺層網絡更好的擬合能力,其原因在于每個隱層都對上一層輸出進行了非線性變換,多次非線性變換使模型找到一個合適的表達。深度學習通過多種基礎的函數組成更加復雜的函數關系,以表達較為復雜的問題。
深度學習的出現大大提高了視覺識別準確率。計算機視覺[8]技術發展大致經歷兩個階段:①人們通過經驗歸納提取,進而設定機器識別物體的邏輯,通過人為設計合適的特征識別算法讓機器識別物品。由于認識物體的邏輯是人為設定的,不能窮舉各種復雜的情境,因而魯棒性較差,識別準確率較低;②深度學習的出現讓識別邏輯由人為設定變為反饋式自學習狀態,數據量的爆發式增長和計算機算力的大幅提升驅動了物體識別率提升。目前深度學習持續突破性發展,尤其在計算機視覺領域有重大突破。
得益于深度學習算法模型、數據量增加以及CPU、GPU等計算硬件支撐[9],計算機視覺技術得以更加高效地實現,并最終集成于多類產品和應用場景之中(如機器人、無人駕駛等)。當下,結合人工智能的深度學習技術,無人機越來越廣泛地應用于農業、商業、軍事、工業等行業[10],人們將其統稱為專業應用級無人機[11],該類無人機已經被應用在一些行業,如對城市建筑進行合理監控。該方法首先通過無人機獲取建筑圖像并進行數據處理,然后設計深度學習算法及網絡模型,最后運用建筑圖像的檢測模型對需要檢測的建筑物體進行識別和分類。這項技術可應用于高層建筑的違建檢測[12]、建筑的破損程度檢測、高層建筑火災檢測等眾多領域。這項技術的研究重點是對建筑進行快速有效識別,其難點在于:一是動態視頻識別過程中對光線變化、遮擋等干擾難度更大,這對機器實現圖像識別、濾除干擾提出了很高要求;二是動態視頻識別對機器識別速度要求較高。一些公司通過智能前端化方式來提升分析速度,即在智能前端攝像頭搭載強并行計算能力處理器,以提供更實時、更高效、不依賴無線網絡傳輸的智能服務。
深度學習具有較強的泛化能力和遷移能力[13],通過遷移學習保留其他數據集的有效特征,并對原始數據集采用翻轉、旋轉、縮放、隨機拼接等數據增強操作擴展數據集的豐富性,同時強化對建筑物特征的學習能力,提高神經網絡模型的魯棒性,從而使其有效克服光線的明暗變化、建筑物之間的遮擋等場景變化的差異所帶來的影響;數據集中無人機拍攝的高分辨率圖像樣本輸入神經網絡之前,先將像素縮小為224*224 大小,這一操作雖然損失了原始圖片中的部分特征,但大大減少了神經網絡的計算量。為了保證建筑物的檢測精度,在設計神經網絡結構時采用5 層卷積層的設計方式,有效提高了模型的檢測速度。
2 方法實現
2.1 實現框架
本文采用最前沿的人工智能及深度學習技術[14]建立模型。深度學習(Deep Learning)能夠自主地從訓練數據集上學習已有數據集的有用特征(Feature),特別是在一些不知道如何設計特征的場合,如建筑物特征等。深度學習本質上是通過構建具有多隱層的神經網絡模型,對海量訓練數據自主學習并從數據中提取出能夠描述被檢對象的主要特征,從而大幅增加模型的識別準確率。和傳統的機器學習相比,深度學習網絡模型最大的特點是多層網絡結構。
本文提出一種無人機視覺數據深度學習識別技術模型,模型實現框架如圖1 所示。

Fig.1 Implementation framework圖1 實現框架
2.2 實現方案
基于上述框架實現步驟如圖2 所示。

Fig.2 Implementation route圖2 實現路線
(1)基于無人機平臺建立訓練圖像數據集。對飛控平臺API 編程,設定目標飛行區域和參數;無人機圖像采集;按照統一格式提取每張圖像的關鍵信息并打標簽;按照規則建立圖像訓練及測試數據集以備用。
(2)訓練深度學習網絡。采用現有深度學習算法框架Tensorflow[15]設計深度學習網絡;將第(1)步建立的圖像數據集輸入到深度學習算法的訓練模塊中,進行大量有效的算法訓練。
(3)無人機采集待分析區域里的圖像數據。基于第(1)步的數據集和第(2)步的深度訓練網絡,自動檢測并識別目標區域中建筑物的變化情況并做標記,供管理部門參考。
2.2.1 建立城市建筑圖像數據集
(1)無人機飛行區域及參數API 編程。為避免無人機無規則“亂飛”(采集的圖像數據無效),采用大疆飛控平臺,調用大疆官方提供的飛控API 參數,通過程序設計設定飛行參數,劃定無人機飛行區域,設定高度、飛行速度、相機云臺傾斜角度、相機拍照頻率等關鍵數據采集,讓無人機按照既定參數飛行,采集有效圖像數據。
(2)如圖3 所示,按照樹結構建立可擴充的圖像數據集作為算法的訓練數據集。樹根分為違章建筑和占道經營兩個一級分支:①違章建筑分支下根據建筑物高度分為20m 以下、50m 以下和100m 以下3 個二級分支;②占道經營分支下建立一個二級分支;③每個二級分支下存儲500~1 000 張相關航拍圖像;④為保證算法的訓練效果,每張存入數據集的圖像都經過人工篩選和打標簽,否則不能入庫;⑤該數據集的各級分支都是可擴充的,方便項目延伸到其他應用。
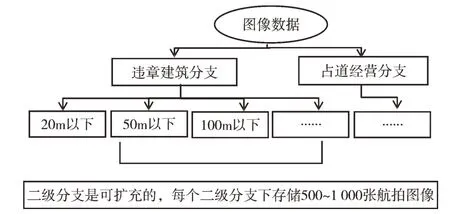
Fig.3 Branch structure of urban management image dataset圖3 城市管理圖像數據集分支結構
(3)標記數據集。用程序或人工為圖像集打標簽,為網絡訓練做數據準備,如圖4 所示。
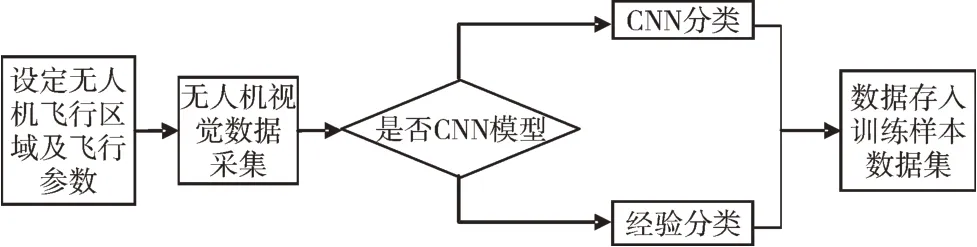
Fig.4 Annotation process of deep learning city management image dataset圖4 深度學習“城市管理”圖像數據集標注流程
2.2.2 深度學習網絡
采用卷積神經網絡(Convolutional Neural Nets,CNNs/ConvNets)進行數據集網絡訓練,提取圖像特征,其數據集網絡訓練過程如圖5 所示。

Fig.5 Network training process圖5 網絡訓練過程
深度學習網絡結構按不同的方向分為以下幾類:①典型生成型深度結構,其主要代表有深度置信網絡[16](DBN)。DBN 通過一系列限制型玻爾茲曼機組成,用來處理深度多層神經網絡架構在進行特征學習過程中產生的標簽數據需求量大、模型收斂速度較慢以及陷入局部極值等問題。DBN 可以同時對先驗概率和后驗概率進行估計,因為其網絡是對訓練數據以及標簽進行聯合學習得到的概率;②區分型模型。典型代表是CNNs,其結構不同于DBN,CNNs 只能對后驗概率進行估計,所以CNNs 多用來解決神經網絡的目標識別和分類問題;③混合型結構。當生成型深度結構用于分類模型問題時,網絡后期利用分區結構進行參數優化,所以稱作混合型結構。
通過上述分析可知,在圖像識別和目標檢測領域中卷積神經網絡(CNN)是最適合于深度學習的神經網絡結構,CNN 卷積神經網絡比普通神經網絡增加了隱藏層,其間包含了多個卷積層和下采樣層的組合。首先,卷積層能夠通過卷積核較好地提取輸入圖片的局部特征,卷積層具有進行權值共享的特性,能大大減少神經網絡在訓練過程中所需參數計算的數量;其次,下采樣層可以忽略目標的傾斜。旋轉之類的相對位置變化在不改變特征圖大小的同時還可進一步減少特征圖的分辨率,幫助神經網絡提取高層次的語義特征,提升檢測精度,避免過閉合情況發生。該卷積神經網絡主要層次結構如圖6 所示。
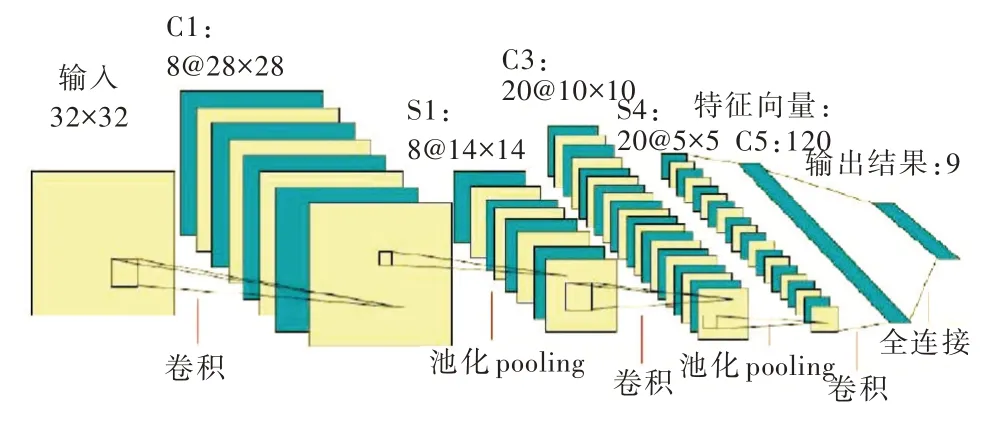
Fig.6 A typical convolution neural network structure圖6 典型的卷積神經網絡結構
在深度學習網絡中,通過大小不同的卷積核對上一層特征圖依次進行卷積操作可提取不同的目標局部特征,同時這些不同的局部特征圖共同作為神經網絡下一層采樣輸入數據。卷積l中第j個神經元公式如下:

其中,k表示卷積核,M表示輸入層的感受野,b為偏置,f(·)表示卷積網絡的激活參數。一個卷積層設計由多個特征圖構成,且各個特征之間權值共享,這樣可以顯著降低網絡中自由參數的數量。
下采樣層(又稱池化層)一般設計在卷積層的后面,可以采取最大池化和平均池化等算法將多個像素值壓縮成一個,其功能是提取特征以減少數據規模,降低網絡分辨率,從而實現畸變、位移穩健性,避免網絡過擬合發生。下采樣計算公式如下:
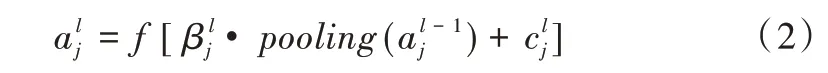
其中,pooling(·)代表池化函數,β代表權重系數。
卷積神經網絡訓練過程由前向傳播和反向傳播兩個階段組成。在前向傳播階段,信息從輸入層開始向前逐層傳播,經過多個卷積、池化、連接操作和全連接層直至網絡最后的輸出層,前向傳播過程中網絡通過下式計算:

其中,yi表示卷積網絡第i層的輸出,fi(·)表示卷積網絡第i層激活函數,wi為第i層卷積核的權值向量。
反向傳播過程中,計算實際輸出(預測值)與標簽信息(真實值)之間的差值,然后按照極小化誤差策略設計模型的誤差函數,反向傳播調整網絡各層參數的權值,采用隨機梯度下降法[17]等優化函數進行參數調整。
采用卷積神經網絡結構設計的深度學習神經網絡模型具有權值共享[18]、模型復雜度低和權值參數少的優點。相較于傳統圖像識別算法[19],該模型能夠避免復雜的人工手動特征提取以及數據重建過程,可通過深度神經網絡的正向和反向傳播過程自動學習特征[20],在數據集規模較大的目標檢測及識別項目中具有顯著優勢。
2.2.3 城市建筑圖像數據自動識別
建立樣本數據集和模型后即可自動識別,本文深度學習網絡如圖7 所示。
輸入層:輸入224×224×3 的圖像,其原因是彩色圖像有3 個通道。
卷積層1+下采樣:由96 個11×11×3 的濾波器、步長為4對輸入層進行卷積,卷積后得出96 個55×55 大小的特征圖。接著采用Maxpooling 方法進行特征圖下采樣,其下采樣窗口為3×3,步長Stride 設計為2,最終得出96 個27×27 大小的特征圖像。
卷積層2+下采樣:首先由256 個5×5×48 的濾波器對卷積層1 下采樣,需要注意的是該層為圖像兩邊各補充2 個像素點,所以按照公式(27-5+2×2+1)/1 的數據進行卷積,得出256 個27×27 的特征圖。然后采用Maxpooling 方法進行特征圖下采樣,其下采樣窗口為3×3,步長Stride 設計為2,最終得出256 個13×13 大小的特征圖像。
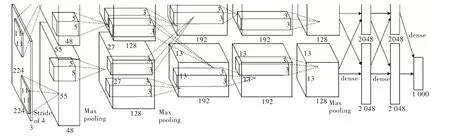
Fig.7 Deep learning network model圖7 深度學習網絡模型
卷積層3:用384 個3×3×256 的濾波器對卷積層2 下采樣后的特征圖像進行卷積操作,注意為圖像兩邊各補充1個像素點,采用公式(13-3+2×1+1)/1 得出384 個13×13 的特征圖,結果在兩個GPU 共同存儲,這是兩個GPU 進行的唯一一次數據交流。
卷積層4:除了卷積對象是卷積層3 的數據GPU 不進行數據交流,其余步驟和卷積層3一樣,得384個13×13特征圖。
卷積層5:用256 個3×3×192 的濾波器對卷積層4 的數據進行卷積,同時在這一步驟中會對圖像進行Padding 操作,為圖像兩邊各補充1 個像素點,得到256 個13×13 特征圖。然后采用Maxpooling 方法進行特征圖下采樣,其下采樣窗口為3×3,步長Stride 設計為2,最終得出256 個6×6 的特征圖。
全連接層1:將卷積層5 下采樣后的256 個6×6 特征圖的像素排成一列,即共有9 216 個元素作為輸入,然后調用神經網絡設計全連接層的參數將之維度下降到4 096 維。
全連接層2:將全連接層1 的特征數據通過全連接神經網絡后,輸出得到4 096 維特征數據。全連接層3:將全連接層2 的特征數據經過全連接神經網絡降維后,輸出得到1 000 維特征數據。
3 實驗結果
實驗平臺見表1,預測類別準確率見表2,訓練和驗證損失函數曲線見圖8,檢測結果見圖9。

Table 1 Experimental platform表1 實驗平臺

Table 2 Accuracy of prediction categories表2 預測類別準確率(%)
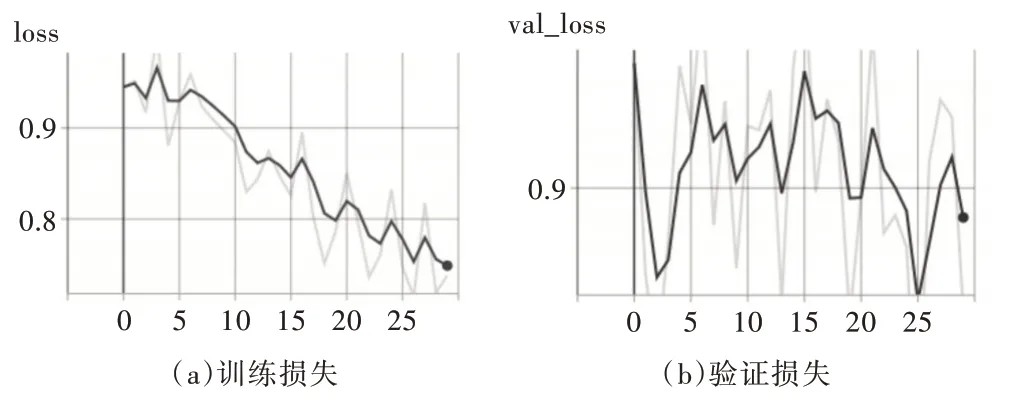
Fig.8 Training and validation loss function curve圖8 訓練和驗證損失函數曲線

Fig.9 Test results圖9 檢測結果
4 實驗分析
實驗使用烏班圖16.04 操作系統,tensorflow-GPU 版本深度學習開發環境,CPU 采用英特爾9900K,GPU 采用11G顯存的Nvdia RTX2080Ti,如表1 所示。經過30 個epoch 訓練之后檢測模型對所有類別的檢測平均準確率可以達到94%,尤其是對建筑的檢測率最高,達到98%,可以滿足建筑物檢測需求,但是對樹的檢測準確率只有92%,如圖8 所示。經過實驗數據分析,數據集中建筑物樣本分布更加平均,樣本數量更加豐富;樹樣本分布集中在部分圖片中,樣本分布密集且數量較少,所以導致樹的檢測率較低,這是后期數據集需要改進的地方。
5 結語
本文創新性地將“無人機”和“深度學習”兩大新興熱門技術應用到城市管理工作中。通過無人機飛控API 函數設計并編程實現劃定無人機飛行區域、高度、圖像數據采集頻率,避免“亂飛”,采集有效的無人機視覺數據;拓展深度學習應用領域,建立城市管理深度學習圖像數據集;設計適合城市管理需要的深度訓練和識別網絡,建立城市管理深度學習模型;利用無人機的飛行優勢,對城市中特定區域內的建筑進行識別,及時、準確、直觀地掌握城區建筑物現狀,有效拓展城市建筑管理執法視野和效率,使城市建設監管更加科學有效。
本文提出的設計框架和實施路線具有極強的通用性,除了檢測建筑,該技術還可以拓展到其他領域,如基于無人機平臺的城市交通擁堵自動識別;基于無人機航拍的人體異常行為檢測;基于無人機的農業病蟲害預防應用等。通過對不同場景下的數據進行訓練,實現無人機在不同場景的識別功能,發揮該模型豐富的應用潛能。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
