基于AdaBoost 的MOOC 學(xué)習(xí)成績預(yù)測模型研究
2021-03-25 02:09:58賈靖怡李玉斌姚巧紅袁子涵
軟件導(dǎo)刊 2021年3期
賈靖怡,李玉斌,姚巧紅,袁子涵
(遼寧師范大學(xué)計算機(jī)與信息技術(shù)學(xué)院,遼寧大連 116081)
0 引言
從最初的網(wǎng)絡(luò)課程、虛擬學(xué)習(xí)社區(qū)、精品課程到現(xiàn)在的視頻公開課、資源共享課以及大規(guī)模在線開放課程(MOOC),在線教育方式始終存在學(xué)生參與度低、輟學(xué)率高、學(xué)習(xí)效果不理想等問題[1-2]。為在輟學(xué)前識別出有風(fēng)險或問題傾向的學(xué)習(xí)者,從而進(jìn)行有針對性的指導(dǎo)、干預(yù)和預(yù)警,MOOC 環(huán)境下的學(xué)習(xí)預(yù)測研究成為熱點。預(yù)測研究的價值主要體現(xiàn)在3 個方面[3]:①教師可預(yù)測學(xué)習(xí)者可能遇到的問題,通過調(diào)整課程或教學(xué)方法提升學(xué)習(xí)體驗;②教師或機(jī)構(gòu)可使用預(yù)測結(jié)果決定課程設(shè)計及實施學(xué)習(xí)干預(yù);③學(xué)習(xí)者可獲得學(xué)習(xí)過程信息,使其反思自己是如何做的,從而提升學(xué)習(xí)表現(xiàn)。
當(dāng)前的MOOC 在線學(xué)習(xí)預(yù)測研究主要集中在學(xué)習(xí)者流失率、輟學(xué)率、退課率、完成率、學(xué)習(xí)參與度等方面[4-6],對學(xué)業(yè)成績、學(xué)習(xí)缺陷、認(rèn)知障礙等主題研究相對偏少。流失率、輟學(xué)率、退課率等主題研究雖然引起廣泛關(guān)注,但還處于初級階段,并不成熟,單從預(yù)測指標(biāo)數(shù)量就能窺見一斑。范逸洲等[7]在《MOOC 中學(xué)習(xí)者流失問題的預(yù)測分析——基于24 篇中英文文獻(xiàn)的綜述》中指出,有的研究預(yù)測指標(biāo)數(shù)僅4 項,有的多達(dá)37 項。因此,在MOOC 學(xué)習(xí)者預(yù)測研究上還需要更多的實證工作,構(gòu)建更加穩(wěn)健和精準(zhǔn)的預(yù)測模型,從而助力在線教育向更智能化方向發(fā)展。
1 成績預(yù)測研究綜述
MOOC 的主要特點之一就是注冊人數(shù)眾多,通常會有成千上萬的注冊者,可收集大量的信息了解課程情況,以便進(jìn)一步分析。目前,大多數(shù)平臺都記錄或存儲“學(xué)習(xí)者與平臺交互”“學(xué)習(xí)者與課程交互”“學(xué)習(xí)者與學(xué)習(xí)者或教師的社會性交互”數(shù)據(jù),分析這些數(shù)據(jù)不僅可發(fā)現(xiàn)問題,還可用來預(yù)測學(xué)習(xí)者學(xué)習(xí)情況與學(xué)習(xí)結(jié)果。
Yang 等[8]利用學(xué)生觀看授課視頻點擊流和以前的評估成績數(shù)據(jù),采用訓(xùn)練時間序列神經(jīng)網(wǎng)絡(luò)方法預(yù)測學(xué)習(xí)成績。對兩個MOOC 數(shù)據(jù)集的評估顯示,該算法比以往平均性能的基線高出60% 以上,比lasso 回歸基線高出15% 以上。當(dāng)學(xué)生回答較少問題時,該算法也具有較強(qiáng)的預(yù)測能力;Ren 等[9]采用個性化線性多元回歸(PLMR)模型,通過跟蹤學(xué)生在MOOC 上的參與情況預(yù)測學(xué)生下一階段表現(xiàn)。分析結(jié)果表明,最好的成績在課程進(jìn)行到一半時取得,評分前的測驗次數(shù)是相關(guān)性最高的變量;Sinha 等[10]基于每天的課程交互信息,包括學(xué)習(xí)者播放視頻數(shù)量、章節(jié)交互次數(shù)和論壇發(fā)帖數(shù)量,利用條件隨機(jī)域(CRF)概率框架對學(xué)習(xí)成績進(jìn)行預(yù)測。對交互特征組合進(jìn)行對比分析得到模型最佳精度為58.1%,召回率為66.0%,加權(quán)F-score 為56.0%,超過了應(yīng)用于每個序列位置的多個基線鑒別分類器;Brinton 等[11]提出帶有因數(shù)分解機(jī)和K-NN 的算法,目的是預(yù)測用戶在回答一個問題時第一次嘗試(CFA)是否正確,測試結(jié)果顯示該算法和預(yù)測指標(biāo)具有早期檢測能力;郝巧龍等[12]利用多元線性回歸分析構(gòu)建模型,識別出持續(xù)時間、學(xué)習(xí)進(jìn)度、觀看時長、筆記數(shù)、作業(yè)成績、發(fā)帖數(shù)、回帖數(shù)、得分帖數(shù)等預(yù)測變量;王鳳芹等[13]利用登錄次數(shù)、在線時間、視頻觀看時間、看帖數(shù)、發(fā)帖數(shù)、回帖數(shù)、在線測驗次數(shù)、每次在線測驗成績、作業(yè)提交次數(shù)、每次作業(yè)成績等10 個預(yù)測指標(biāo),驗證K 近鄰優(yōu)化算法在預(yù)測MOOC 學(xué)習(xí)成績的有效性;趙帥等[14]基于情感詞典統(tǒng)計學(xué)習(xí)者論壇討論發(fā)言中積極、消極情感詞語及詞頻,通過回歸分析方法研究情感指數(shù)是否能有效預(yù)測成績;金夢甜[15]構(gòu)建基于深度神經(jīng)因子分解機(jī)的學(xué)習(xí)效果預(yù)測模型。
上述研究雖然嘗試?yán)酶鞣N技術(shù)預(yù)測MOOC 學(xué)習(xí)結(jié)果,既有經(jīng)典的線性回歸方程模型,也有當(dāng)前非常流行的神經(jīng)網(wǎng)絡(luò),但至今沒有明確的主導(dǎo)預(yù)測技術(shù)。決策樹、神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)等這些基礎(chǔ)模型與集成增強(qiáng)方法一起使用,也許可以獲得更高的預(yù)測能力。從預(yù)測指標(biāo)來看,三大范疇(學(xué)習(xí)者與平臺交互、學(xué)習(xí)者與課程交互以及學(xué)習(xí)者的社會性交互)雖均有涉及,但主要是對時域(如在線時長、視頻觀看時間)和頻域(如發(fā)帖條數(shù)、登陸次數(shù))等“數(shù)量”型指標(biāo)的統(tǒng)計,體現(xiàn)內(nèi)容的“質(zhì)量”型指標(biāo)占比明顯偏低。以帖子為例,僅考慮條數(shù)、不考慮發(fā)帖內(nèi)容,一定會損失有價值的預(yù)測信息。另外,對“及格學(xué)習(xí)者”和“不及格學(xué)習(xí)者”預(yù)測,是用一套指標(biāo)還是應(yīng)該區(qū)別對待,似乎沒有明確結(jié)論。本文將結(jié)合這些問題開展研究設(shè)計與實證。
2 基于AdaBoost 預(yù)測建模
2.1 預(yù)測指標(biāo)
在文獻(xiàn)分析基礎(chǔ)上,本研究從“學(xué)習(xí)者與平臺交互”“學(xué)習(xí)者與課程交互”和“學(xué)習(xí)者與學(xué)習(xí)者或教師的社會性交互”三大范疇、“時域”和“頻域”兩個向度,匯集“登錄次數(shù)、在線時長、瀏覽課程資源次數(shù)、瀏覽課程資源時長、查看課程信息次數(shù)、查看課程信息時長、瀏覽視頻次數(shù)、作業(yè)提交次數(shù)、參與測驗次數(shù)、發(fā)布帖子條數(shù)、發(fā)布帖子字?jǐn)?shù)、回評帖子條數(shù)、回評帖子字?jǐn)?shù)”等13 個數(shù)量型指標(biāo),針對質(zhì)性指標(biāo)缺乏問題,構(gòu)建“登錄間隔、登錄間隔標(biāo)準(zhǔn)差、發(fā)布帖子質(zhì)量、回評帖子質(zhì)量”4 個質(zhì)量型指標(biāo),總計17 個預(yù)測指標(biāo),如表1 所示。
2.1.1 TF-IDF 累計值
TF-IDF 即詞頻逆文檔頻率,在自然語言處理中應(yīng)用十分廣泛,本研究用其衡量學(xué)者發(fā)帖質(zhì)量。TF 表示詞頻數(shù),指某個詞語在學(xué)習(xí)者帖子中出現(xiàn)的總次數(shù)。在文本分析過程中,由于出現(xiàn)次數(shù)最多、頻率最高的詞語不一定代表帖子的內(nèi)容特征,因此使用IDF 屬性。IDF 表示逆文檔詞頻,用以區(qū)分不同學(xué)習(xí)者帖子內(nèi)容的差異性。TF-IDF 計算公式如下:
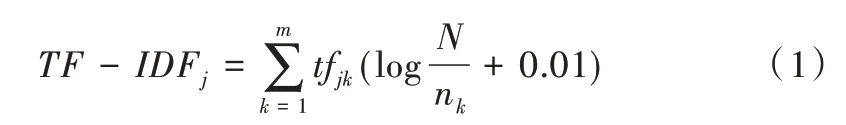
其中,TF -IDFi表示第j位學(xué)習(xí)者的TF-IDF 累計值;tfik是詞語k在第j位學(xué)習(xí)者帖子詞頻數(shù)量+0.01是詞語k在學(xué)習(xí)者帖子集合中的逆文檔詞頻值,N 為總帖子文檔數(shù)目,nk為包含詞語k的帖子文檔數(shù)量,m為整個帖子詞向量空間維度。在計算過程中,每位學(xué)習(xí)者帖子合并為一個文檔,使用結(jié)合jieba 中文分詞工具和Python 語言自行編寫的程序進(jìn)行處理。
2.1.2 Δt 均值和標(biāo)準(zhǔn)差
Δt 表示學(xué)習(xí)者兩次相鄰登錄的時間間隔。學(xué)習(xí)者多次登錄平臺后會有一系列的Δt 值。用Δt 的平均值表示學(xué)習(xí)者登錄間隔屬性,Δt 的標(biāo)準(zhǔn)差表示學(xué)習(xí)者登錄離散情況,反映一定的行為規(guī)律。

Table 1 Description of prediction indicators表1 預(yù)測指標(biāo)說明
Δt 均值計算公式如下:

Δt 標(biāo)準(zhǔn)差計算公式如下:
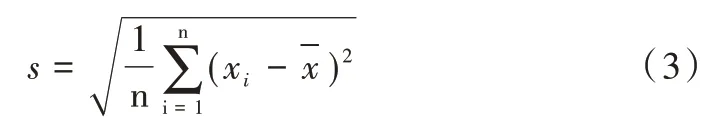
2.2 預(yù)測模型
AdaBoost 屬于集成學(xué)習(xí)Boosting 算法的一種。集成學(xué)習(xí)算法核心思想是在訓(xùn)練集上使用一系列基礎(chǔ)模型(如決策樹、支持向量機(jī)、神經(jīng)網(wǎng)絡(luò)等)進(jìn)行分類,然后采用一定的規(guī)則(如投票法)集成出一個模型,從而解決模型最優(yōu)化問題。AdaBoost 作為Boosting 最受歡迎的實現(xiàn)方法,具有極強(qiáng)的適應(yīng)能力[16]。因為AdaBoost 不僅根據(jù)基礎(chǔ)模型的準(zhǔn)度為每個模型附上權(quán)重值(α),還根據(jù)數(shù)學(xué)預(yù)測結(jié)果是否正確為每一個樣本附上權(quán)重值(Wi),并經(jīng)過多次迭代產(chǎn)生一個預(yù)測模型序列,最后采用加權(quán)平均法得到最終優(yōu)化的預(yù)測模型。算法如下:
輸入:訓(xùn)練集DT={(xi,yi)},i=1,2,…,n,yi∈{0,1}。其中,xi 為預(yù)測指標(biāo);yi 為學(xué)業(yè)成績能否及格,0=不及格,1=及格
輸出:預(yù)測模型:B(x)
(1)給訓(xùn)練集DT 每一個樣本附上初始權(quán)重:
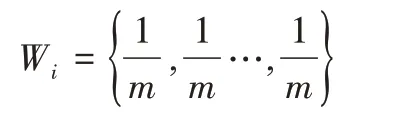
(2)for j=1 to k
(3)基于訓(xùn)練集DT 和初始權(quán)重Wi,訓(xùn)練出第一個學(xué)業(yè)成績預(yù)測基礎(chǔ)模型bk(x)
(4)計算模型bk(x)誤差率,公式如下:
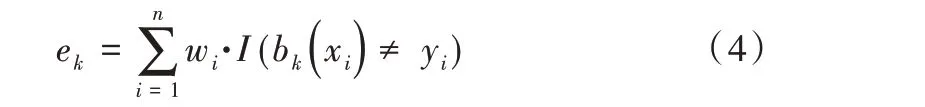
其中,如果預(yù)測結(jié)果正確,I(x)=1,否則I(x)=0
(5)計算分類bk(x)權(quán)重,公式如下:
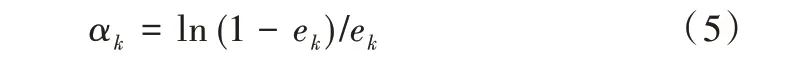
(6)根據(jù)公式(6)更新所有訓(xùn)練集的權(quán)重值,并歸一化Wi。
(7)end for
3 模型效果驗證
3.1 數(shù)據(jù)集
選取2017-2018 學(xué)年春季和秋季兩期參與中國大學(xué)MOOC 平臺《互聯(lián)網(wǎng)+教師知識個人管理》課程學(xué)習(xí)者相關(guān)數(shù)據(jù)進(jìn)行效果驗證。本課程兩期注冊總?cè)藬?shù)為11 126 人,導(dǎo)出其中有過發(fā)帖或回帖行為的319 位學(xué)習(xí)者數(shù)據(jù)作為研究樣本。在數(shù)據(jù)提取和清洗過程中,嚴(yán)格按照平臺提供的后臺數(shù)據(jù)說明文檔進(jìn)行。由于17 個預(yù)測指標(biāo)的量綱不同(如次數(shù)、時間、TF-IDF 值),不能直接計算,因此對數(shù)據(jù)進(jìn)行歸一化處理,轉(zhuǎn)換到從0 到1 的同一區(qū)間。
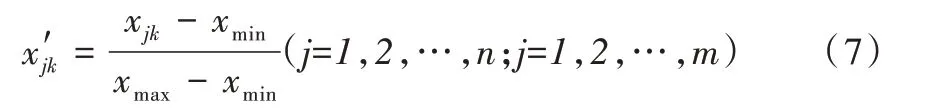
其中,xjk是原始數(shù)據(jù),是歸一化數(shù)據(jù),xmin是第k 個指標(biāo)的最小值,xmax是第k 個指標(biāo)的最大值。
3.2 實驗平臺
RapidMiner 是由RapidMiner 公司開發(fā)、維護(hù)的一個開源大數(shù)據(jù)挖掘GUI 軟件平臺,該平臺自帶1 500 多個函數(shù),可以搭建并部署數(shù)據(jù)挖掘與預(yù)測分析的各種流程。本實驗使用RapidMiner9.4 運行AdaBoost 算法模型,基礎(chǔ)模型是決策樹,實驗流程框架如圖1 所示。
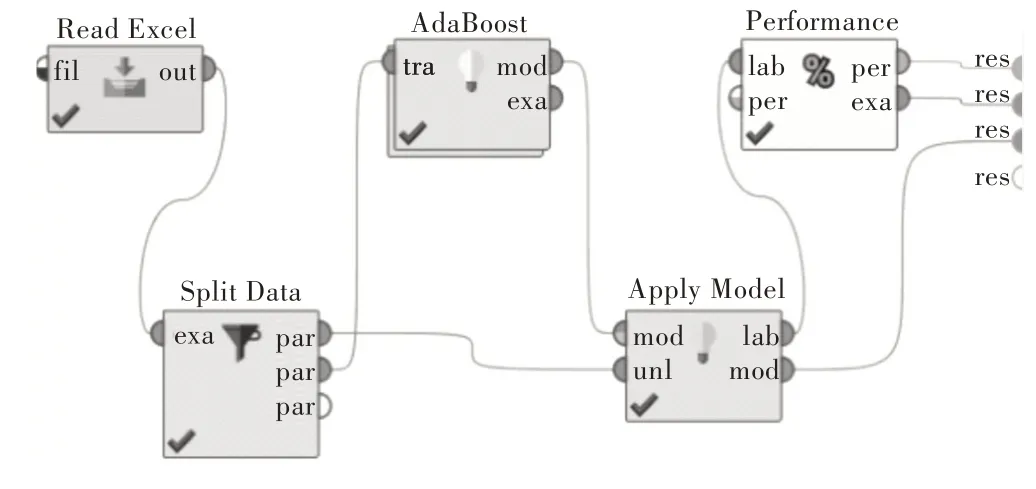
Fig.1 Experimental flow frame of AdaBoost algorithm圖1 AdaBoost 算法實驗流程框架
3.3 特征向量選擇
對及格學(xué)習(xí)者和不及格學(xué)習(xí)者預(yù)測,是用一套指標(biāo)還是區(qū)別對待,本研究通過特征向量選擇對預(yù)測指標(biāo)進(jìn)行分組并加以驗證。特征向量選擇方法主要有主成分分析、卡方檢驗、信息增益等。由于本研究的所有指標(biāo)經(jīng)過標(biāo)準(zhǔn)化后全部為無量綱數(shù)值型數(shù)據(jù),所以可以采用主成分分析法進(jìn)行選擇。首先把數(shù)據(jù)集導(dǎo)入SPSS22.0,然后調(diào)用Factor Analyze 過程進(jìn)行分析,設(shè)置特征值大于1,采用最大方差法分析相關(guān)性矩陣。分析結(jié)果顯示,KMO(Kaiser-Meyer-Olkin)檢驗統(tǒng)計量0.845,Bartlett 球形度檢驗的近似卡方值為4 787.54,主成分累計方差為79.16%,可以進(jìn)行指標(biāo)分組和精簡。依據(jù)各主成分因子負(fù)荷不同,形成A、B、C、D 4個特征指標(biāo)組,如表2 所示。
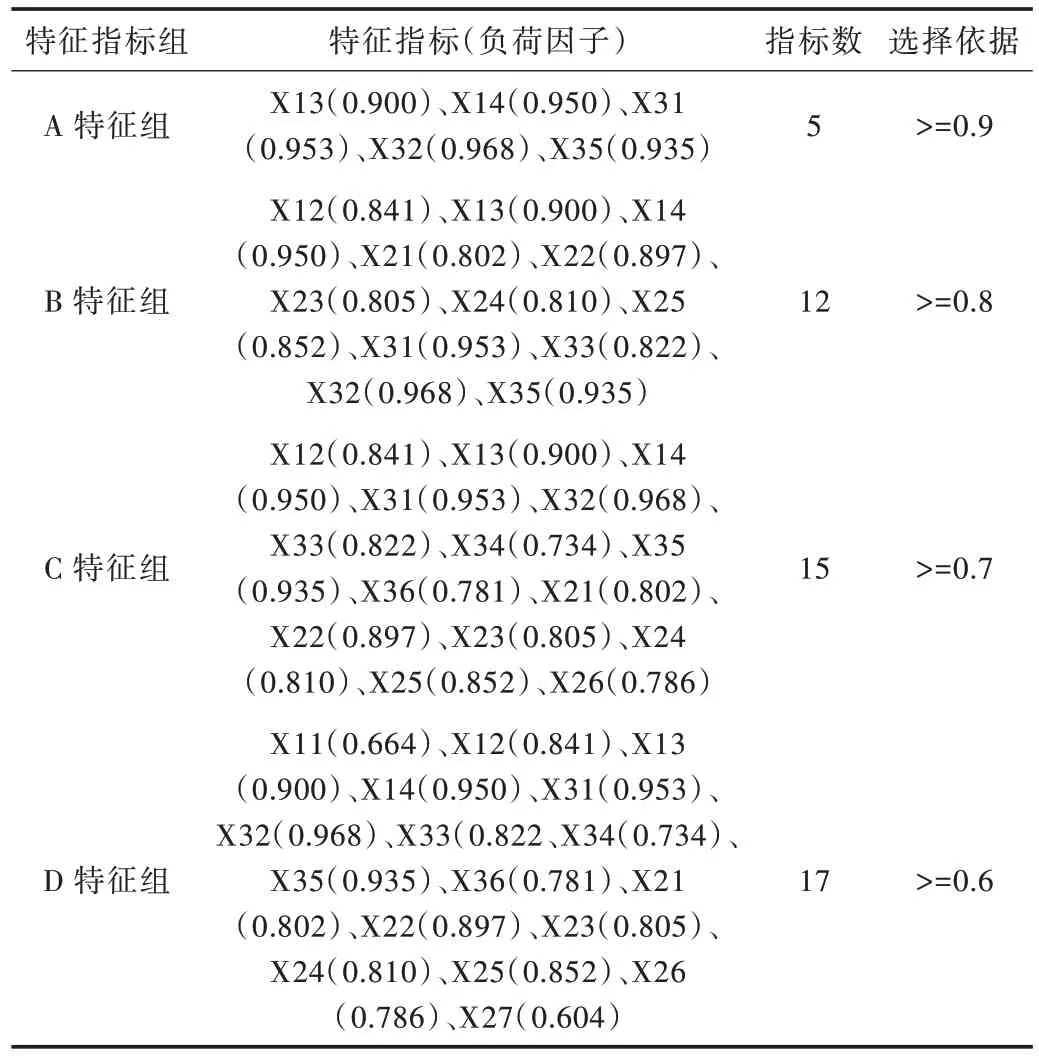
Table 2 Characteristic indicator groups表2 特征指標(biāo)組
3.4 實驗結(jié)果
基于實驗平臺輸出的混淆矩陣,通過正精度(TP/(TP+FP))、負(fù)精度(TN/(TN+FN))和綜合準(zhǔn)度((TP+TN)/(TP+TN+FP+FN))3 個指標(biāo),對本文提出的基于AdaBoost 挖掘算法的MOOC 學(xué)習(xí)成績預(yù)測模型進(jìn)行全面評估。其中,TP代表真及格類,TN 代表真不及格類,F(xiàn)N 代表假及格類,F(xiàn)P代表假不及格類,實驗結(jié)果如表3 所示。
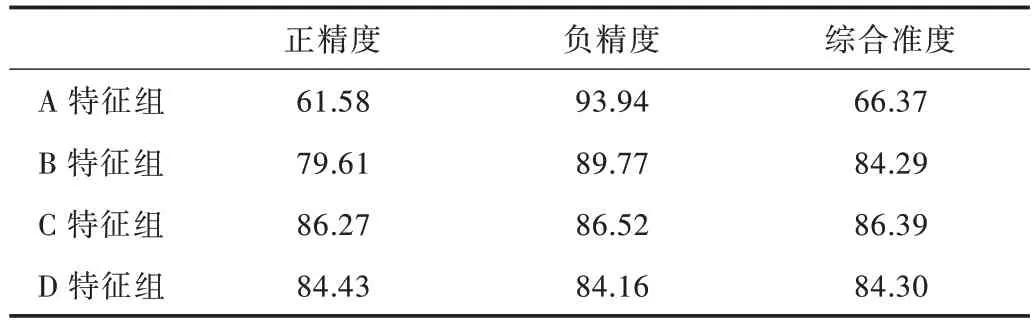
Table 3 Index of prediction ability of model表3 模型預(yù)測能力指標(biāo)(%)
綜合準(zhǔn)度用來衡量模型的綜合預(yù)測能力,對及格學(xué)習(xí)者和不及格學(xué)習(xí)者兩種情況的預(yù)測精準(zhǔn)度進(jìn)行檢測。從表3 可以看出,綜合預(yù)測能力指標(biāo)中C 特征組的綜合準(zhǔn)度為86.39%,預(yù)測能力最強(qiáng);B 特征組和D 特征組的預(yù)測能力基本一樣,A 特征組的預(yù)測能力最弱,綜合準(zhǔn)度為66.37%。
如果僅對“哪些學(xué)習(xí)者的學(xué)習(xí)成績可能會不及格”情況進(jìn)行預(yù)測,A 特征組的負(fù)精度為93.94%,數(shù)值最高,預(yù)測能力最強(qiáng),也就是說利用X13、X14、X31、X32、和X35 這5個指標(biāo)判斷效果最好。如果僅對“哪些學(xué)習(xí)者的學(xué)習(xí)成績可能會及格”情況進(jìn)行預(yù)測,C 特征組的正精度為86.27%,數(shù)值最高,預(yù)測能力最強(qiáng)。
4 結(jié)語
利用學(xué)習(xí)者數(shù)據(jù)挖掘出有價值信息,是當(dāng)前在線學(xué)習(xí)分析領(lǐng)域的研究熱點。本文從學(xué)習(xí)者與平臺交互、學(xué)習(xí)者與課程交互和學(xué)習(xí)者的社會性交互等多個方面匯集17 個特征指標(biāo),使用中國大學(xué)MOOC 平臺的《互聯(lián)網(wǎng)+教師知識個人管理》課程數(shù)據(jù),對基于AdaBoost 算法的MOOC 學(xué)習(xí)者學(xué)習(xí)結(jié)果預(yù)測模型進(jìn)行了驗證。
本文構(gòu)建的基于AdaBoost 算法的MOOC 學(xué)習(xí)者學(xué)習(xí)成績預(yù)測模型具有較強(qiáng)的預(yù)測能力,綜合預(yù)測精度為86.39%,具有實際應(yīng)用價值。對“哪些學(xué)習(xí)者的學(xué)習(xí)成績可能會及格”和“哪些學(xué)習(xí)者的學(xué)習(xí)成績可能會不及格”兩種情況進(jìn)行預(yù)測,應(yīng)該區(qū)別對待。對“不及格”情況進(jìn)行預(yù)測,使用“登錄間隔、登錄間隔標(biāo)準(zhǔn)差、發(fā)布帖子條數(shù)、發(fā)布帖子字?jǐn)?shù)、發(fā)布帖子質(zhì)量”等5 個指標(biāo),預(yù)測精度更高;對“及格”情況進(jìn)行預(yù)測,需要更多的預(yù)測指標(biāo),使用“在線時長、登錄間隔、登錄間隔標(biāo)準(zhǔn)差、瀏覽課程資源次數(shù)、瀏覽課程資源時長、查看課程信息次數(shù)、查看課程信息時長、瀏覽視頻次數(shù)、作業(yè)提交次數(shù)、發(fā)布帖子條數(shù)、發(fā)布帖子字?jǐn)?shù)、回評帖子條數(shù)、回評帖子字?jǐn)?shù)、發(fā)布帖子質(zhì)量、回評帖子質(zhì)量”等15 特征指標(biāo)預(yù)測效果更好,預(yù)測精度可達(dá)86.27%。TF-IDF 累計值、△t 標(biāo)準(zhǔn)差等體現(xiàn)質(zhì)量的“質(zhì)”型預(yù)測指標(biāo)不但具有很高的因子負(fù)荷,而且全部進(jìn)入預(yù)測模型,十分重要,今后應(yīng)重視這類指標(biāo)開發(fā)。
本研究不足之處是僅用一門課程數(shù)據(jù)對預(yù)測模型進(jìn)行驗證。為提高模型的泛化程度和穩(wěn)健性,還需要更多數(shù)據(jù)集驗證。另外,更多指標(biāo)雖然有助于提升模型預(yù)測精準(zhǔn)度,但不利于模型可解釋性,后續(xù)要進(jìn)一步尋求通過更少的指標(biāo)對“及格”情況進(jìn)行精準(zhǔn)預(yù)測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南化工(2021年6期)2021-12-21 07:31:42
內(nèi)蒙古教育(2021年20期)2021-03-08 01:09:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
計算機(jī)教育(2020年5期)2020-07-24 08:53:38
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
家庭影院技術(shù)(2019年11期)2019-12-09 09:14:30
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
教育與職業(yè)(2014年1期)2014-04-17 14:28:07
